mirror of
https://github.com/ClickHouse/ClickHouse.git
synced 2024-12-13 18:02:24 +00:00
Merge remote-tracking branch 'origin/parallelize-file-cache-metadata-download' into parallelize-file-cache-metadata-download
This commit is contained in:
commit
3d438ab91b
@ -57,7 +57,7 @@ public:
|
||||
URI();
|
||||
/// Creates an empty URI.
|
||||
|
||||
explicit URI(const std::string & uri, bool disable_url_encoding = false);
|
||||
explicit URI(const std::string & uri, bool enable_url_encoding = true);
|
||||
/// Parses an URI from the given string. Throws a
|
||||
/// SyntaxException if the uri is not valid.
|
||||
|
||||
@ -362,7 +362,7 @@ private:
|
||||
std::string _query;
|
||||
std::string _fragment;
|
||||
|
||||
bool _disable_url_encoding = false;
|
||||
bool _enable_url_encoding = true;
|
||||
};
|
||||
|
||||
|
||||
|
||||
@ -36,8 +36,8 @@ URI::URI():
|
||||
}
|
||||
|
||||
|
||||
URI::URI(const std::string& uri, bool decode_and_encode_path):
|
||||
_port(0), _disable_url_encoding(decode_and_encode_path)
|
||||
URI::URI(const std::string& uri, bool enable_url_encoding):
|
||||
_port(0), _enable_url_encoding(enable_url_encoding)
|
||||
{
|
||||
parse(uri);
|
||||
}
|
||||
@ -108,7 +108,7 @@ URI::URI(const URI& uri):
|
||||
_path(uri._path),
|
||||
_query(uri._query),
|
||||
_fragment(uri._fragment),
|
||||
_disable_url_encoding(uri._disable_url_encoding)
|
||||
_enable_url_encoding(uri._enable_url_encoding)
|
||||
{
|
||||
}
|
||||
|
||||
@ -121,7 +121,7 @@ URI::URI(const URI& baseURI, const std::string& relativeURI):
|
||||
_path(baseURI._path),
|
||||
_query(baseURI._query),
|
||||
_fragment(baseURI._fragment),
|
||||
_disable_url_encoding(baseURI._disable_url_encoding)
|
||||
_enable_url_encoding(baseURI._enable_url_encoding)
|
||||
{
|
||||
resolve(relativeURI);
|
||||
}
|
||||
@ -153,7 +153,7 @@ URI& URI::operator = (const URI& uri)
|
||||
_path = uri._path;
|
||||
_query = uri._query;
|
||||
_fragment = uri._fragment;
|
||||
_disable_url_encoding = uri._disable_url_encoding;
|
||||
_enable_url_encoding = uri._enable_url_encoding;
|
||||
}
|
||||
return *this;
|
||||
}
|
||||
@ -184,7 +184,7 @@ void URI::swap(URI& uri)
|
||||
std::swap(_path, uri._path);
|
||||
std::swap(_query, uri._query);
|
||||
std::swap(_fragment, uri._fragment);
|
||||
std::swap(_disable_url_encoding, uri._disable_url_encoding);
|
||||
std::swap(_enable_url_encoding, uri._enable_url_encoding);
|
||||
}
|
||||
|
||||
|
||||
@ -687,18 +687,18 @@ void URI::decode(const std::string& str, std::string& decodedStr, bool plusAsSpa
|
||||
|
||||
void URI::encodePath(std::string & encodedStr) const
|
||||
{
|
||||
if (_disable_url_encoding)
|
||||
encodedStr = _path;
|
||||
else
|
||||
if (_enable_url_encoding)
|
||||
encode(_path, RESERVED_PATH, encodedStr);
|
||||
else
|
||||
encodedStr = _path;
|
||||
}
|
||||
|
||||
void URI::decodePath(const std::string & encodedStr)
|
||||
{
|
||||
if (_disable_url_encoding)
|
||||
_path = encodedStr;
|
||||
else
|
||||
if (_enable_url_encoding)
|
||||
decode(encodedStr, _path);
|
||||
else
|
||||
_path = encodedStr;
|
||||
}
|
||||
|
||||
bool URI::isWellKnownPort() const
|
||||
|
||||
@ -17,7 +17,8 @@
|
||||
#ifndef METROHASH_PLATFORM_H
|
||||
#define METROHASH_PLATFORM_H
|
||||
|
||||
#include <stdint.h>
|
||||
#include <bit>
|
||||
#include <cstdint>
|
||||
#include <cstring>
|
||||
|
||||
// rotate right idiom recognized by most compilers
|
||||
@ -33,6 +34,11 @@ inline static uint64_t read_u64(const void * const ptr)
|
||||
// so we use memcpy() which is the most portable. clang & gcc usually translates `memcpy()` into a single `load` instruction
|
||||
// when hardware supports it, so using memcpy() is efficient too.
|
||||
memcpy(&result, ptr, sizeof(result));
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
result = std::byteswap(result);
|
||||
#endif
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
@ -40,6 +46,11 @@ inline static uint64_t read_u32(const void * const ptr)
|
||||
{
|
||||
uint32_t result;
|
||||
memcpy(&result, ptr, sizeof(result));
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
result = std::byteswap(result);
|
||||
#endif
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
@ -47,6 +58,11 @@ inline static uint64_t read_u16(const void * const ptr)
|
||||
{
|
||||
uint16_t result;
|
||||
memcpy(&result, ptr, sizeof(result));
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
result = std::byteswap(result);
|
||||
#endif
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
|
||||
@ -32,7 +32,7 @@ RUN arch=${TARGETARCH:-amd64} \
|
||||
esac
|
||||
|
||||
ARG REPOSITORY="https://s3.amazonaws.com/clickhouse-builds/22.4/31c367d3cd3aefd316778601ff6565119fe36682/package_release"
|
||||
ARG VERSION="23.7.1.2470"
|
||||
ARG VERSION="23.7.2.25"
|
||||
ARG PACKAGES="clickhouse-keeper"
|
||||
|
||||
# user/group precreated explicitly with fixed uid/gid on purpose.
|
||||
|
||||
@ -6,7 +6,7 @@ Usage:
|
||||
Build deb package with `clang-14` in `debug` mode:
|
||||
```
|
||||
$ mkdir deb/test_output
|
||||
$ ./packager --output-dir deb/test_output/ --package-type deb --compiler=clang-14 --build-type=debug
|
||||
$ ./packager --output-dir deb/test_output/ --package-type deb --compiler=clang-14 --debug-build
|
||||
$ ls -l deb/test_output
|
||||
-rw-r--r-- 1 root root 3730 clickhouse-client_22.2.2+debug_all.deb
|
||||
-rw-r--r-- 1 root root 84221888 clickhouse-common-static_22.2.2+debug_amd64.deb
|
||||
|
||||
@ -112,12 +112,12 @@ def run_docker_image_with_env(
|
||||
subprocess.check_call(cmd, shell=True)
|
||||
|
||||
|
||||
def is_release_build(build_type: str, package_type: str, sanitizer: str) -> bool:
|
||||
return build_type == "" and package_type == "deb" and sanitizer == ""
|
||||
def is_release_build(debug_build: bool, package_type: str, sanitizer: str) -> bool:
|
||||
return not debug_build and package_type == "deb" and sanitizer == ""
|
||||
|
||||
|
||||
def parse_env_variables(
|
||||
build_type: str,
|
||||
debug_build: bool,
|
||||
compiler: str,
|
||||
sanitizer: str,
|
||||
package_type: str,
|
||||
@ -240,7 +240,7 @@ def parse_env_variables(
|
||||
build_target = (
|
||||
f"{build_target} clickhouse-odbc-bridge clickhouse-library-bridge"
|
||||
)
|
||||
if is_release_build(build_type, package_type, sanitizer):
|
||||
if is_release_build(debug_build, package_type, sanitizer):
|
||||
cmake_flags.append("-DSPLIT_DEBUG_SYMBOLS=ON")
|
||||
result.append("WITH_PERFORMANCE=1")
|
||||
if is_cross_arm:
|
||||
@ -255,8 +255,8 @@ def parse_env_variables(
|
||||
|
||||
if sanitizer:
|
||||
result.append(f"SANITIZER={sanitizer}")
|
||||
if build_type:
|
||||
result.append(f"BUILD_TYPE={build_type.capitalize()}")
|
||||
if debug_build:
|
||||
result.append("BUILD_TYPE=Debug")
|
||||
else:
|
||||
result.append("BUILD_TYPE=None")
|
||||
|
||||
@ -361,7 +361,7 @@ def parse_args() -> argparse.Namespace:
|
||||
help="ClickHouse git repository",
|
||||
)
|
||||
parser.add_argument("--output-dir", type=dir_name, required=True)
|
||||
parser.add_argument("--build-type", choices=("debug", ""), default="")
|
||||
parser.add_argument("--debug-build", action="store_true")
|
||||
|
||||
parser.add_argument(
|
||||
"--compiler",
|
||||
@ -467,7 +467,7 @@ def main():
|
||||
build_image(image_with_version, dockerfile)
|
||||
|
||||
env_prepared = parse_env_variables(
|
||||
args.build_type,
|
||||
args.debug_build,
|
||||
args.compiler,
|
||||
args.sanitizer,
|
||||
args.package_type,
|
||||
|
||||
@ -33,7 +33,7 @@ RUN arch=${TARGETARCH:-amd64} \
|
||||
# lts / testing / prestable / etc
|
||||
ARG REPO_CHANNEL="stable"
|
||||
ARG REPOSITORY="https://packages.clickhouse.com/tgz/${REPO_CHANNEL}"
|
||||
ARG VERSION="23.7.1.2470"
|
||||
ARG VERSION="23.7.2.25"
|
||||
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
||||
|
||||
# user/group precreated explicitly with fixed uid/gid on purpose.
|
||||
|
||||
@ -23,7 +23,7 @@ RUN sed -i "s|http://archive.ubuntu.com|${apt_archive}|g" /etc/apt/sources.list
|
||||
|
||||
ARG REPO_CHANNEL="stable"
|
||||
ARG REPOSITORY="deb [signed-by=/usr/share/keyrings/clickhouse-keyring.gpg] https://packages.clickhouse.com/deb ${REPO_CHANNEL} main"
|
||||
ARG VERSION="23.7.1.2470"
|
||||
ARG VERSION="23.7.2.25"
|
||||
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
||||
|
||||
# set non-empty deb_location_url url to create a docker image
|
||||
|
||||
@ -95,6 +95,7 @@ RUN python3 -m pip install --no-cache-dir \
|
||||
pytest-timeout \
|
||||
pytest-xdist \
|
||||
pytz \
|
||||
pyyaml==5.3.1 \
|
||||
redis \
|
||||
requests-kerberos \
|
||||
tzlocal==2.1 \
|
||||
|
||||
31
docs/changelogs/v23.7.2.25-stable.md
Normal file
31
docs/changelogs/v23.7.2.25-stable.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_label: 2023
|
||||
---
|
||||
|
||||
# 2023 Changelog
|
||||
|
||||
### ClickHouse release v23.7.2.25-stable (8dd1107b032) FIXME as compared to v23.7.1.2470-stable (a70127baecc)
|
||||
|
||||
#### Backward Incompatible Change
|
||||
* Backported in [#52850](https://github.com/ClickHouse/ClickHouse/issues/52850): If a dynamic disk contains a name, it should be specified as `disk = disk(name = 'disk_name'`, ...) in disk function arguments. In previous version it could be specified as `disk = disk_<disk_name>(...)`, which is no longer supported. [#52820](https://github.com/ClickHouse/ClickHouse/pull/52820) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
|
||||
#### Build/Testing/Packaging Improvement
|
||||
* Backported in [#52913](https://github.com/ClickHouse/ClickHouse/issues/52913): Add `clickhouse-keeper-client` symlink to the clickhouse-server package. [#51882](https://github.com/ClickHouse/ClickHouse/pull/51882) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
|
||||
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||
|
||||
* Fix binary arithmetic for Nullable(IPv4) [#51642](https://github.com/ClickHouse/ClickHouse/pull/51642) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Support IPv4 and IPv6 as dictionary attributes [#51756](https://github.com/ClickHouse/ClickHouse/pull/51756) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* init and destroy ares channel on demand.. [#52634](https://github.com/ClickHouse/ClickHouse/pull/52634) ([Arthur Passos](https://github.com/arthurpassos)).
|
||||
* Fix crash in function `tuple` with one sparse column argument [#52659](https://github.com/ClickHouse/ClickHouse/pull/52659) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Fix data race in Keeper reconfiguration [#52804](https://github.com/ClickHouse/ClickHouse/pull/52804) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* clickhouse-keeper: fix implementation of server with poll() [#52833](https://github.com/ClickHouse/ClickHouse/pull/52833) ([Andy Fiddaman](https://github.com/citrus-it)).
|
||||
|
||||
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||
|
||||
* Rename setting disable_url_encoding to enable_url_encoding and add a test [#52656](https://github.com/ClickHouse/ClickHouse/pull/52656) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix bugs and better test for SYSTEM STOP LISTEN [#52680](https://github.com/ClickHouse/ClickHouse/pull/52680) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Increase min protocol version for sparse serialization [#52835](https://github.com/ClickHouse/ClickHouse/pull/52835) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Docker improvements [#52869](https://github.com/ClickHouse/ClickHouse/pull/52869) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
|
||||
@ -14,6 +14,20 @@ Supported platforms:
|
||||
- PowerPC 64 LE (experimental)
|
||||
- RISC-V 64 (experimental)
|
||||
|
||||
## Building in docker
|
||||
We use the docker image `clickhouse/binary-builder` for our CI builds. It contains everything necessary to build the binary and packages. There is a script `docker/packager/packager` to ease the image usage:
|
||||
|
||||
```bash
|
||||
# define a directory for the output artifacts
|
||||
output_dir="build_results"
|
||||
# a simplest build
|
||||
./docker/packager/packager --package-type=binary --output-dir "$output_dir"
|
||||
# build debian packages
|
||||
./docker/packager/packager --package-type=deb --output-dir "$output_dir"
|
||||
# by default, debian packages use thin LTO, so we can override it to speed up the build
|
||||
CMAKE_FLAGS='-DENABLE_THINLTO=' ./docker/packager/packager --package-type=deb --output-dir "./$(git rev-parse --show-cdup)/build_results"
|
||||
```
|
||||
|
||||
## Building on Ubuntu
|
||||
|
||||
The following tutorial is based on Ubuntu Linux.
|
||||
|
||||
@ -35,7 +35,7 @@ The [system.clusters](../../operations/system-tables/clusters.md) system table c
|
||||
|
||||
When creating a new replica of the database, this replica creates tables by itself. If the replica has been unavailable for a long time and has lagged behind the replication log — it checks its local metadata with the current metadata in ZooKeeper, moves the extra tables with data to a separate non-replicated database (so as not to accidentally delete anything superfluous), creates the missing tables, updates the table names if they have been renamed. The data is replicated at the `ReplicatedMergeTree` level, i.e. if the table is not replicated, the data will not be replicated (the database is responsible only for metadata).
|
||||
|
||||
[`ALTER TABLE ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
||||
[`ALTER TABLE FREEZE|ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
||||
|
||||
## Usage Example {#usage-example}
|
||||
|
||||
|
||||
@ -60,6 +60,7 @@ Engines in the family:
|
||||
- [EmbeddedRocksDB](../../engines/table-engines/integrations/embedded-rocksdb.md)
|
||||
- [RabbitMQ](../../engines/table-engines/integrations/rabbitmq.md)
|
||||
- [PostgreSQL](../../engines/table-engines/integrations/postgresql.md)
|
||||
- [S3Queue](../../engines/table-engines/integrations/s3queue.md)
|
||||
|
||||
### Special Engines {#special-engines}
|
||||
|
||||
|
||||
224
docs/en/engines/table-engines/integrations/s3queue.md
Normal file
224
docs/en/engines/table-engines/integrations/s3queue.md
Normal file
@ -0,0 +1,224 @@
|
||||
---
|
||||
slug: /en/engines/table-engines/integrations/s3queue
|
||||
sidebar_position: 7
|
||||
sidebar_label: S3Queue
|
||||
---
|
||||
|
||||
# S3Queue Table Engine
|
||||
This engine provides integration with [Amazon S3](https://aws.amazon.com/s3/) ecosystem and allows streaming import. This engine is similar to the [Kafka](../../../engines/table-engines/integrations/kafka.md), [RabbitMQ](../../../engines/table-engines/integrations/rabbitmq.md) engines, but provides S3-specific features.
|
||||
|
||||
## Create Table {#creating-a-table}
|
||||
|
||||
``` sql
|
||||
CREATE TABLE s3_queue_engine_table (name String, value UInt32)
|
||||
ENGINE = S3Queue(path [, NOSIGN | aws_access_key_id, aws_secret_access_key,] format, [compression])
|
||||
[SETTINGS]
|
||||
[mode = 'unordered',]
|
||||
[after_processing = 'keep',]
|
||||
[keeper_path = '',]
|
||||
[s3queue_loading_retries = 0,]
|
||||
[s3queue_polling_min_timeout_ms = 1000,]
|
||||
[s3queue_polling_max_timeout_ms = 10000,]
|
||||
[s3queue_polling_backoff_ms = 0,]
|
||||
[s3queue_tracked_files_limit = 1000,]
|
||||
[s3queue_tracked_file_ttl_sec = 0,]
|
||||
[s3queue_polling_size = 50,]
|
||||
```
|
||||
|
||||
**Engine parameters**
|
||||
|
||||
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings. For more information see [below](#wildcards-in-path).
|
||||
- `NOSIGN` - If this keyword is provided in place of credentials, all the requests will not be signed.
|
||||
- `format` — The [format](../../../interfaces/formats.md#formats) of the file.
|
||||
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file. For more information see [Using S3 for Data Storage](../mergetree-family/mergetree.md#table_engine-mergetree-s3).
|
||||
- `compression` — Compression type. Supported values: `none`, `gzip/gz`, `brotli/br`, `xz/LZMA`, `zstd/zst`. Parameter is optional. By default, it will autodetect compression by file extension.
|
||||
|
||||
**Example**
|
||||
|
||||
```sql
|
||||
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||
ENGINE=S3Queue('https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*', 'CSV', 'gzip')
|
||||
SETTINGS
|
||||
mode = 'ordred';
|
||||
```
|
||||
|
||||
Using named collections:
|
||||
|
||||
``` xml
|
||||
<clickhouse>
|
||||
<named_collections>
|
||||
<s3queue_conf>
|
||||
<url>'https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*</url>
|
||||
<access_key_id>test<access_key_id>
|
||||
<secret_access_key>test</secret_access_key>
|
||||
</s3queue_conf>
|
||||
</named_collections>
|
||||
</clickhouse>
|
||||
```
|
||||
|
||||
```sql
|
||||
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||
ENGINE=S3Queue(s3queue_conf, format = 'CSV', compression_method = 'gzip')
|
||||
SETTINGS
|
||||
mode = 'ordred';
|
||||
```
|
||||
|
||||
## Settings {#s3queue-settings}
|
||||
|
||||
### mode {#mode}
|
||||
|
||||
Possible values:
|
||||
|
||||
- unordered — With unordered mode, the set of all already processed files is tracked with persistent nodes in ZooKeeper.
|
||||
- ordered — With ordered mode, only the max name of the successfully consumed file, and the names of files that will be retried after unsuccessful loading attempt are being stored in ZooKeeper.
|
||||
|
||||
Default value: `unordered`.
|
||||
|
||||
### after_processing {#after_processing}
|
||||
|
||||
Delete or keep file after successful processing.
|
||||
Possible values:
|
||||
|
||||
- keep.
|
||||
- delete.
|
||||
|
||||
Default value: `keep`.
|
||||
|
||||
### keeper_path {#keeper_path}
|
||||
|
||||
The path in ZooKeeper can be specified as a table engine setting or default path can be formed from the global configuration-provided path and table UUID.
|
||||
Possible values:
|
||||
|
||||
- String.
|
||||
|
||||
Default value: `/`.
|
||||
|
||||
### s3queue_loading_retries {#s3queue_loading_retries}
|
||||
|
||||
Retry file loading up to specified number of times. By default, there are no retries.
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### s3queue_polling_min_timeout_ms {#s3queue_polling_min_timeout_ms}
|
||||
|
||||
Minimal timeout before next polling (in milliseconds).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `1000`.
|
||||
|
||||
### s3queue_polling_max_timeout_ms {#s3queue_polling_max_timeout_ms}
|
||||
|
||||
Maximum timeout before next polling (in milliseconds).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `10000`.
|
||||
|
||||
### s3queue_polling_backoff_ms {#s3queue_polling_backoff_ms}
|
||||
|
||||
Polling backoff (in milliseconds).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### s3queue_tracked_files_limit {#s3queue_tracked_files_limit}
|
||||
|
||||
Allows to limit the number of Zookeeper nodes if the 'unordered' mode is used, does nothing for 'ordered' mode.
|
||||
If limit reached the oldest processed files will be deleted from ZooKeeper node and processed again.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `1000`.
|
||||
|
||||
### s3queue_tracked_file_ttl_sec {#s3queue_tracked_file_ttl_sec}
|
||||
|
||||
Maximum number of seconds to store processed files in ZooKeeper node (store forever by default) for 'unordered' mode, does nothing for 'ordered' mode.
|
||||
After the specified number of seconds, the file will be re-imported.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### s3queue_polling_size {#s3queue_polling_size}
|
||||
|
||||
Maximum files to fetch from S3 with SELECT or in background task.
|
||||
Engine takes files for processing from S3 in batches.
|
||||
We limit the batch size to increase concurrency if multiple table engines with the same `keeper_path` consume files from the same path.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `50`.
|
||||
|
||||
|
||||
## S3-related Settings {#s3-settings}
|
||||
|
||||
Engine supports all s3 related settings. For more information about S3 settings see [here](../../../engines/table-engines/integrations/s3.md).
|
||||
|
||||
|
||||
## Description {#description}
|
||||
|
||||
`SELECT` is not particularly useful for streaming import (except for debugging), because each file can be imported only once. It is more practical to create real-time threads using [materialized views](../../../sql-reference/statements/create/view.md). To do this:
|
||||
|
||||
1. Use the engine to create a table for consuming from specified path in S3 and consider it a data stream.
|
||||
2. Create a table with the desired structure.
|
||||
3. Create a materialized view that converts data from the engine and puts it into a previously created table.
|
||||
|
||||
When the `MATERIALIZED VIEW` joins the engine, it starts collecting data in the background.
|
||||
|
||||
Example:
|
||||
|
||||
``` sql
|
||||
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||
ENGINE=S3Queue('https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*', 'CSV', 'gzip')
|
||||
SETTINGS
|
||||
mode = 'unordred',
|
||||
keeper_path = '/clickhouse/s3queue/';
|
||||
|
||||
CREATE TABLE stats (name String, value UInt32)
|
||||
ENGINE = MergeTree() ORDER BY name;
|
||||
|
||||
CREATE MATERIALIZED VIEW consumer TO stats
|
||||
AS SELECT name, value FROM s3queue_engine_table;
|
||||
|
||||
SELECT * FROM stats ORDER BY name;
|
||||
```
|
||||
|
||||
## Virtual columns {#virtual-columns}
|
||||
|
||||
- `_path` — Path to the file.
|
||||
- `_file` — Name of the file.
|
||||
|
||||
For more information about virtual columns see [here](../../../engines/table-engines/index.md#table_engines-virtual_columns).
|
||||
|
||||
|
||||
## Wildcards In Path {#wildcards-in-path}
|
||||
|
||||
`path` argument can specify multiple files using bash-like wildcards. For being processed file should exist and match to the whole path pattern. Listing of files is determined during `SELECT` (not at `CREATE` moment).
|
||||
|
||||
- `*` — Substitutes any number of any characters except `/` including empty string.
|
||||
- `?` — Substitutes any single character.
|
||||
- `{some_string,another_string,yet_another_one}` — Substitutes any of strings `'some_string', 'another_string', 'yet_another_one'`.
|
||||
- `{N..M}` — Substitutes any number in range from N to M including both borders. N and M can have leading zeroes e.g. `000..078`.
|
||||
|
||||
Constructions with `{}` are similar to the [remote](../../../sql-reference/table-functions/remote.md) table function.
|
||||
|
||||
:::note
|
||||
If the listing of files contains number ranges with leading zeros, use the construction with braces for each digit separately or use `?`.
|
||||
:::
|
||||
@ -193,6 +193,19 @@ index creation, `L2Distance` is used as default. Parameter `NumTrees` is the num
|
||||
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
||||
linearly) as well as larger index sizes.
|
||||
|
||||
`L2Distance` is also called Euclidean distance, the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points.
|
||||
For example: If we have point P(p1,p2), Q(q1,q2), their distance will be d(p,q)
|
||||

|
||||
|
||||
`cosineDistance` also called cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths.
|
||||
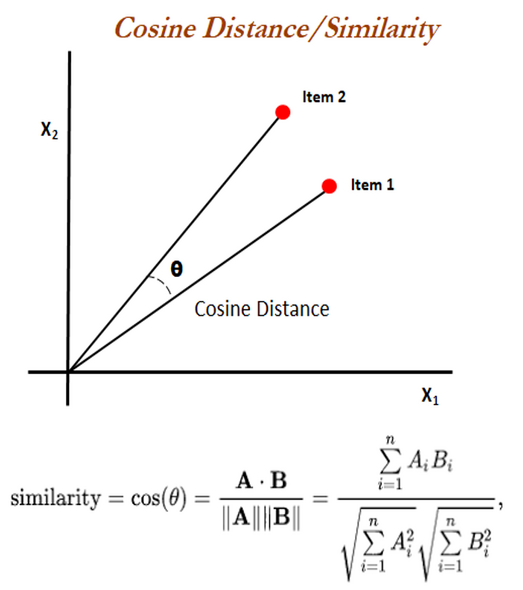
|
||||
|
||||
The Euclidean distance corresponds to the L2-norm of a difference between vectors. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
|
||||

|
||||
In one sentence: cosine similarity care only about the angle between them, but do not care about the "distance" we normally think.
|
||||
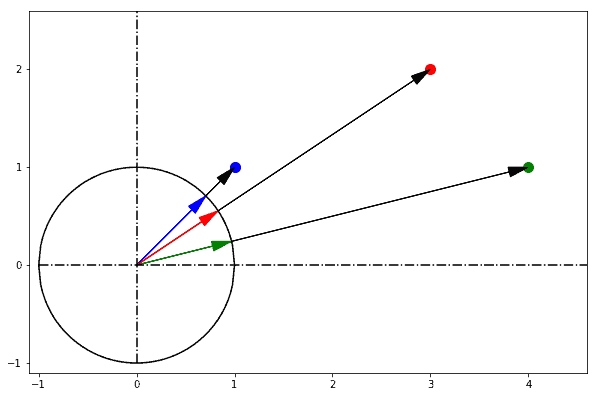
|
||||
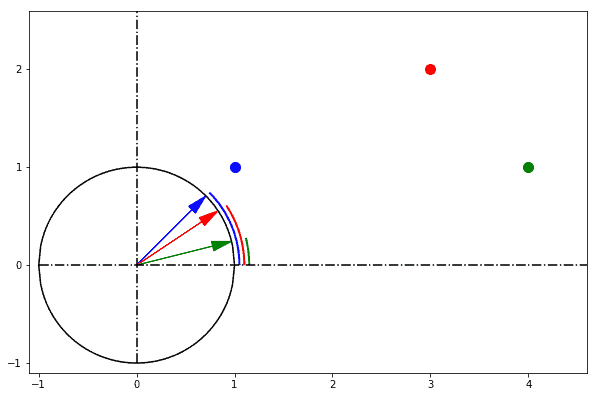
|
||||
|
||||
:::note
|
||||
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
||||
[CONSTRAINT](/docs/en/sql-reference/statements/create/table.md#constraints) to avoid errors. For example, `CONSTRAINT constraint_name_1
|
||||
|
||||
@ -106,4 +106,4 @@ For partitioning by month, use the `toYYYYMM(date_column)` expression, where `da
|
||||
## Storage Settings {#storage-settings}
|
||||
|
||||
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
||||
- [disable_url_encoding](/docs/en/operations/settings/settings.md#disable_url_encoding) -allows to disable decoding/encoding path in uri. Disabled by default.
|
||||
- [enable_url_encoding](/docs/en/operations/settings/settings.md#enable_url_encoding) - allows to enable/disable decoding/encoding path in uri. Enabled by default.
|
||||
|
||||
@ -1723,6 +1723,34 @@ You can select data from a ClickHouse table and save them into some file in the
|
||||
``` bash
|
||||
$ clickhouse-client --query = "SELECT * FROM test.hits FORMAT CapnProto SETTINGS format_schema = 'schema:Message'"
|
||||
```
|
||||
|
||||
### Using autogenerated schema {#using-autogenerated-capn-proto-schema}
|
||||
|
||||
If you don't have an external CapnProto schema for your data, you can still output/input data in CapnProto format using autogenerated schema.
|
||||
For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format CapnProto SETTINGS format_capn_proto_use_autogenerated_schema=1
|
||||
```
|
||||
|
||||
In this case ClickHouse will autogenerate CapnProto schema according to the table structure using function [structureToCapnProtoSchema](../sql-reference/functions/other-functions.md#structure_to_capn_proto_schema) and will use this schema to serialize data in CapnProto format.
|
||||
|
||||
You can also read CapnProto file with autogenerated schema (in this case the file must be created using the same schema):
|
||||
|
||||
```bash
|
||||
$ cat hits.bin | clickhouse-client --query "INSERT INTO test.hits SETTINGS format_capn_proto_use_autogenerated_schema=1 FORMAT CapnProto"
|
||||
```
|
||||
|
||||
The setting [format_capn_proto_use_autogenerated_schema](../operations/settings/settings-formats.md#format_capn_proto_use_autogenerated_schema) is enabled by default and applies if [format_schema](../operations/settings/settings-formats.md#formatschema-format-schema) is not set.
|
||||
|
||||
You can also save autogenerated schema in the file during input/output using setting [output_format_schema](../operations/settings/settings-formats.md#outputformatschema-output-format-schema). For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format CapnProto SETTINGS format_capn_proto_use_autogenerated_schema=1, output_format_schema='path/to/schema/schema.capnp'
|
||||
```
|
||||
|
||||
In this case autogenerated CapnProto schema will be saved in file `path/to/schema/schema.capnp`.
|
||||
|
||||
## Prometheus {#prometheus}
|
||||
|
||||
Expose metrics in [Prometheus text-based exposition format](https://prometheus.io/docs/instrumenting/exposition_formats/#text-based-format).
|
||||
@ -1861,6 +1889,33 @@ ClickHouse inputs and outputs protobuf messages in the `length-delimited` format
|
||||
It means before every message should be written its length as a [varint](https://developers.google.com/protocol-buffers/docs/encoding#varints).
|
||||
See also [how to read/write length-delimited protobuf messages in popular languages](https://cwiki.apache.org/confluence/display/GEODE/Delimiting+Protobuf+Messages).
|
||||
|
||||
### Using autogenerated schema {#using-autogenerated-protobuf-schema}
|
||||
|
||||
If you don't have an external Protobuf schema for your data, you can still output/input data in Protobuf format using autogenerated schema.
|
||||
For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format Protobuf SETTINGS format_protobuf_use_autogenerated_schema=1
|
||||
```
|
||||
|
||||
In this case ClickHouse will autogenerate Protobuf schema according to the table structure using function [structureToProtobufSchema](../sql-reference/functions/other-functions.md#structure_to_protobuf_schema) and will use this schema to serialize data in Protobuf format.
|
||||
|
||||
You can also read Protobuf file with autogenerated schema (in this case the file must be created using the same schema):
|
||||
|
||||
```bash
|
||||
$ cat hits.bin | clickhouse-client --query "INSERT INTO test.hits SETTINGS format_protobuf_use_autogenerated_schema=1 FORMAT Protobuf"
|
||||
```
|
||||
|
||||
The setting [format_protobuf_use_autogenerated_schema](../operations/settings/settings-formats.md#format_protobuf_use_autogenerated_schema) is enabled by default and applies if [format_schema](../operations/settings/settings-formats.md#formatschema-format-schema) is not set.
|
||||
|
||||
You can also save autogenerated schema in the file during input/output using setting [output_format_schema](../operations/settings/settings-formats.md#outputformatschema-output-format-schema). For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format Protobuf SETTINGS format_protobuf_use_autogenerated_schema=1, output_format_schema='path/to/schema/schema.proto'
|
||||
```
|
||||
|
||||
In this case autogenerated Protobuf schema will be saved in file `path/to/schema/schema.capnp`.
|
||||
|
||||
## ProtobufSingle {#protobufsingle}
|
||||
|
||||
Same as [Protobuf](#protobuf) but for storing/parsing single Protobuf message without length delimiters.
|
||||
|
||||
@ -0,0 +1,26 @@
|
||||
---
|
||||
slug: /en/operations/optimizing-performance/profile-guided-optimization
|
||||
sidebar_position: 54
|
||||
sidebar_label: Profile Guided Optimization (PGO)
|
||||
---
|
||||
import SelfManaged from '@site/docs/en/_snippets/_self_managed_only_no_roadmap.md';
|
||||
|
||||
# Profile Guided Optimization
|
||||
|
||||
Profile-Guided Optimization (PGO) is a compiler optimization technique where a program is optimized based on the runtime profile.
|
||||
|
||||
According to the tests, PGO helps with achieving better performance for ClickHouse. According to the tests, we see improvements up to 15% in QPS on the ClickBench test suite. The more detailed results are available [here](https://pastebin.com/xbue3HMU). The performance benefits depend on your typical workload - you can get better or worse results.
|
||||
|
||||
More information about PGO in ClickHouse you can read in the corresponding GitHub [issue](https://github.com/ClickHouse/ClickHouse/issues/44567).
|
||||
|
||||
## How to build ClickHouse with PGO?
|
||||
|
||||
There are two major kinds of PGO: [Instrumentation](https://clang.llvm.org/docs/UsersManual.html#using-sampling-profilers) and [Sampling](https://clang.llvm.org/docs/UsersManual.html#using-sampling-profilers) (also known as AutoFDO). In this guide is described the Instrumentation PGO with ClickHouse.
|
||||
|
||||
1. Build ClickHouse in Instrumented mode. In Clang it can be done via passing `-fprofile-instr-generate` option to `CXXFLAGS`.
|
||||
2. Run instrumented ClickHouse on a sample workload. Here you need to use your usual workload. One of the approaches could be using [ClickBench](https://github.com/ClickHouse/ClickBench) as a sample workload. ClickHouse in the instrumentation mode could work slowly so be ready for that and do not run instrumented ClickHouse in performance-critical environments.
|
||||
3. Recompile ClickHouse once again with `-fprofile-instr-use` compiler flags and profiles that are collected from the previous step.
|
||||
|
||||
A more detailed guide on how to apply PGO is in the Clang [documentation](https://clang.llvm.org/docs/UsersManual.html#profile-guided-optimization).
|
||||
|
||||
If you are going to collect a sample workload directly from a production environment, we recommend trying to use Sampling PGO.
|
||||
@ -321,6 +321,10 @@ If both `input_format_allow_errors_num` and `input_format_allow_errors_ratio` ar
|
||||
|
||||
This parameter is useful when you are using formats that require a schema definition, such as [Cap’n Proto](https://capnproto.org/) or [Protobuf](https://developers.google.com/protocol-buffers/). The value depends on the format.
|
||||
|
||||
## output_format_schema {#output-format-schema}
|
||||
|
||||
The path to the file where the automatically generated schema will be saved in [Cap’n Proto](../../interfaces/formats.md#capnproto-capnproto) or [Protobuf](../../interfaces/formats.md#protobuf-protobuf) formats.
|
||||
|
||||
## output_format_enable_streaming {#output_format_enable_streaming}
|
||||
|
||||
Enable streaming in output formats that support it.
|
||||
@ -1330,6 +1334,11 @@ When serializing Nullable columns with Google wrappers, serialize default values
|
||||
|
||||
Disabled by default.
|
||||
|
||||
### format_protobuf_use_autogenerated_schema {#format_capn_proto_use_autogenerated_schema}
|
||||
|
||||
Use autogenerated Protobuf schema when [format_schema](#formatschema-format-schema) is not set.
|
||||
The schema is generated from ClickHouse table structure using function [structureToProtobufSchema](../../sql-reference/functions/other-functions.md#structure_to_protobuf_schema)
|
||||
|
||||
## Avro format settings {#avro-format-settings}
|
||||
|
||||
### input_format_avro_allow_missing_fields {#input_format_avro_allow_missing_fields}
|
||||
@ -1626,6 +1635,11 @@ Possible values:
|
||||
|
||||
Default value: `'by_values'`.
|
||||
|
||||
### format_capn_proto_use_autogenerated_schema {#format_capn_proto_use_autogenerated_schema}
|
||||
|
||||
Use autogenerated CapnProto schema when [format_schema](#formatschema-format-schema) is not set.
|
||||
The schema is generated from ClickHouse table structure using function [structureToCapnProtoSchema](../../sql-reference/functions/other-functions.md#structure_to_capnproto_schema)
|
||||
|
||||
## MySQLDump format settings {#musqldump-format-settings}
|
||||
|
||||
### input_format_mysql_dump_table_name (#input_format_mysql_dump_table_name)
|
||||
|
||||
@ -3468,11 +3468,11 @@ Possible values:
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
## disable_url_encoding {#disable_url_encoding}
|
||||
## enable_url_encoding {#enable_url_encoding}
|
||||
|
||||
Allows to disable decoding/encoding path in uri in [URL](../../engines/table-engines/special/url.md) engine tables.
|
||||
Allows to enable/disable decoding/encoding path in uri in [URL](../../engines/table-engines/special/url.md) engine tables.
|
||||
|
||||
Disabled by default.
|
||||
Enabled by default.
|
||||
|
||||
## database_atomic_wait_for_drop_and_detach_synchronously {#database_atomic_wait_for_drop_and_detach_synchronously}
|
||||
|
||||
@ -4578,3 +4578,28 @@ Type: Int64
|
||||
|
||||
Default: 0
|
||||
|
||||
## precise_float_parsing {#precise_float_parsing}
|
||||
|
||||
Switches [Float32/Float64](../../sql-reference/data-types/float.md) parsing algorithms:
|
||||
* If the value is `1`, then precise method is used. It is slower than fast method, but it always returns a number that is the closest machine representable number to the input.
|
||||
* Otherwise, fast method is used (default). It usually returns the same value as precise, but in rare cases result may differ by one or two least significant digits.
|
||||
|
||||
Possible values: `0`, `1`.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
Example:
|
||||
|
||||
```sql
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 0;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7090999999999998 │ 15008753.000000002 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 1;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7091 │ 15008753 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
```
|
||||
|
||||
@ -48,7 +48,7 @@ Columns:
|
||||
- `read_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of rows read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_rows` includes the total number of rows read at all replicas. Each replica sends it’s `read_rows` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
||||
- `read_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of bytes read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_bytes` includes the total number of rows read at all replicas. Each replica sends it’s `read_bytes` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
||||
- `written_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written rows. For other queries, the column value is 0.
|
||||
- `written_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written bytes. For other queries, the column value is 0.
|
||||
- `written_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written bytes (uncompressed). For other queries, the column value is 0.
|
||||
- `result_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Number of rows in a result of the `SELECT` query, or a number of rows in the `INSERT` query.
|
||||
- `result_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — RAM volume in bytes used to store a query result.
|
||||
- `memory_usage` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Memory consumption by the query.
|
||||
|
||||
@ -2552,3 +2552,187 @@ Result:
|
||||
|
||||
This function can be used together with [generateRandom](../../sql-reference/table-functions/generate.md) to generate completely random tables.
|
||||
|
||||
## structureToCapnProtoSchema {#structure_to_capn_proto_schema}
|
||||
|
||||
Converts ClickHouse table structure to CapnProto schema.
|
||||
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
structureToCapnProtoSchema(structure)
|
||||
```
|
||||
|
||||
**Arguments**
|
||||
|
||||
- `structure` — Table structure in a format `column1_name column1_type, column2_name column2_type, ...`.
|
||||
- `root_struct_name` — Name for root struct in CapnProto schema. Default value - `Message`;
|
||||
|
||||
**Returned value**
|
||||
|
||||
- CapnProto schema
|
||||
|
||||
Type: [String](../../sql-reference/data-types/string.md).
|
||||
|
||||
**Examples**
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToCapnProtoSchema('column1 String, column2 UInt32, column3 Array(String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
@0xf96402dd754d0eb7;
|
||||
|
||||
struct Message
|
||||
{
|
||||
column1 @0 : Data;
|
||||
column2 @1 : UInt32;
|
||||
column3 @2 : List(Data);
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToCapnProtoSchema('column1 Nullable(String), column2 Tuple(element1 UInt32, element2 Array(String)), column3 Map(String, String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
@0xd1c8320fecad2b7f;
|
||||
|
||||
struct Message
|
||||
{
|
||||
struct Column1
|
||||
{
|
||||
union
|
||||
{
|
||||
value @0 : Data;
|
||||
null @1 : Void;
|
||||
}
|
||||
}
|
||||
column1 @0 : Column1;
|
||||
struct Column2
|
||||
{
|
||||
element1 @0 : UInt32;
|
||||
element2 @1 : List(Data);
|
||||
}
|
||||
column2 @1 : Column2;
|
||||
struct Column3
|
||||
{
|
||||
struct Entry
|
||||
{
|
||||
key @0 : Data;
|
||||
value @1 : Data;
|
||||
}
|
||||
entries @0 : List(Entry);
|
||||
}
|
||||
column3 @2 : Column3;
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToCapnProtoSchema('column1 String, column2 UInt32', 'Root') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
@0x96ab2d4ab133c6e1;
|
||||
|
||||
struct Root
|
||||
{
|
||||
column1 @0 : Data;
|
||||
column2 @1 : UInt32;
|
||||
}
|
||||
```
|
||||
|
||||
## structureToProtobufSchema {#structure_to_protobuf_schema}
|
||||
|
||||
Converts ClickHouse table structure to Protobuf schema.
|
||||
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
structureToProtobufSchema(structure)
|
||||
```
|
||||
|
||||
**Arguments**
|
||||
|
||||
- `structure` — Table structure in a format `column1_name column1_type, column2_name column2_type, ...`.
|
||||
- `root_message_name` — Name for root message in Protobuf schema. Default value - `Message`;
|
||||
|
||||
**Returned value**
|
||||
|
||||
- Protobuf schema
|
||||
|
||||
Type: [String](../../sql-reference/data-types/string.md).
|
||||
|
||||
**Examples**
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToProtobufSchema('column1 String, column2 UInt32, column3 Array(String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
syntax = "proto3";
|
||||
|
||||
message Message
|
||||
{
|
||||
bytes column1 = 1;
|
||||
uint32 column2 = 2;
|
||||
repeated bytes column3 = 3;
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToProtobufSchema('column1 Nullable(String), column2 Tuple(element1 UInt32, element2 Array(String)), column3 Map(String, String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
syntax = "proto3";
|
||||
|
||||
message Message
|
||||
{
|
||||
bytes column1 = 1;
|
||||
message Column2
|
||||
{
|
||||
uint32 element1 = 1;
|
||||
repeated bytes element2 = 2;
|
||||
}
|
||||
Column2 column2 = 2;
|
||||
map<string, bytes> column3 = 3;
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToProtobufSchema('column1 String, column2 UInt32', 'Root') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
syntax = "proto3";
|
||||
|
||||
message Root
|
||||
{
|
||||
bytes column1 = 1;
|
||||
uint32 column2 = 2;
|
||||
}
|
||||
```
|
||||
|
||||
@ -314,6 +314,22 @@ Provides possibility to start background fetch tasks from replication queues whi
|
||||
SYSTEM START REPLICATION QUEUES [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
||||
```
|
||||
|
||||
### STOP PULLING REPLICATION LOG
|
||||
|
||||
Stops loading new entries from replication log to replication queue in a `ReplicatedMergeTree` table.
|
||||
|
||||
``` sql
|
||||
SYSTEM STOP PULLING REPLICATION LOG [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
||||
```
|
||||
|
||||
### START PULLING REPLICATION LOG
|
||||
|
||||
Cancels `SYSTEM STOP PULLING REPLICATION LOG`.
|
||||
|
||||
``` sql
|
||||
SYSTEM START PULLING REPLICATION LOG [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
||||
```
|
||||
|
||||
### SYNC REPLICA
|
||||
|
||||
Wait until a `ReplicatedMergeTree` table will be synced with other replicas in a cluster, but no more than `receive_timeout` seconds.
|
||||
|
||||
@ -56,7 +56,7 @@ Character `|` inside patterns is used to specify failover addresses. They are it
|
||||
## Storage Settings {#storage-settings}
|
||||
|
||||
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
||||
- [disable_url_encoding](/docs/en/operations/settings/settings.md#disable_url_encoding) - allows to disable decoding/encoding path in uri. Disabled by default.
|
||||
- [enable_url_encoding](/docs/en/operations/settings/settings.md#enable_url_encoding) - allows to enable/disable decoding/encoding path in uri. Enabled by default.
|
||||
|
||||
**See Also**
|
||||
|
||||
|
||||
@ -0,0 +1 @@
|
||||
../../../en/operations/optimizing-performance/profile-guided-optimization.md
|
||||
@ -4213,3 +4213,29 @@ SELECT *, timezone() FROM test_tz WHERE d = '2000-01-01 00:00:00' SETTINGS sessi
|
||||
- Запрос: `SELECT * FROM file('sample.csv')`
|
||||
|
||||
Если чтение и обработка `sample.csv` прошли успешно, файл будет переименован в `processed_sample_1683473210851438.csv`.
|
||||
|
||||
## precise_float_parsing {#precise_float_parsing}
|
||||
|
||||
Позволяет выбрать алгоритм, используемый при парсинге [Float32/Float64](../../sql-reference/data-types/float.md):
|
||||
* Если установлено значение `1`, то используется точный метод. Он более медленный, но всегда возвращает число, наиболее близкое к входному значению.
|
||||
* В противном случае используется быстрый метод (поведение по умолчанию). Обычно результат его работы совпадает с результатом, полученным точным методом, однако в редких случаях он может отличаться на 1 или 2 наименее значимых цифры.
|
||||
|
||||
Возможные значения: `0`, `1`.
|
||||
|
||||
Значение по умолчанию: `0`.
|
||||
|
||||
Пример:
|
||||
|
||||
```sql
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 0;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7090999999999998 │ 15008753.000000002 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 1;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7091 │ 15008753 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
```
|
||||
|
||||
@ -0,0 +1 @@
|
||||
../../../en/operations/optimizing-performance/profile-guided-optimization.md
|
||||
@ -55,6 +55,9 @@ contents:
|
||||
- src: clickhouse
|
||||
dst: /usr/bin/clickhouse-keeper
|
||||
type: symlink
|
||||
- src: clickhouse
|
||||
dst: /usr/bin/clickhouse-keeper-client
|
||||
type: symlink
|
||||
- src: root/usr/bin/clickhouse-report
|
||||
dst: /usr/bin/clickhouse-report
|
||||
- src: root/usr/bin/clickhouse-server
|
||||
|
||||
@ -168,6 +168,7 @@ enum class AccessType
|
||||
M(SYSTEM_TTL_MERGES, "SYSTEM STOP TTL MERGES, SYSTEM START TTL MERGES, STOP TTL MERGES, START TTL MERGES", TABLE, SYSTEM) \
|
||||
M(SYSTEM_FETCHES, "SYSTEM STOP FETCHES, SYSTEM START FETCHES, STOP FETCHES, START FETCHES", TABLE, SYSTEM) \
|
||||
M(SYSTEM_MOVES, "SYSTEM STOP MOVES, SYSTEM START MOVES, STOP MOVES, START MOVES", TABLE, SYSTEM) \
|
||||
M(SYSTEM_PULLING_REPLICATION_LOG, "SYSTEM STOP PULLING REPLICATION LOG, SYSTEM START PULLING REPLICATION LOG", TABLE, SYSTEM) \
|
||||
M(SYSTEM_DISTRIBUTED_SENDS, "SYSTEM STOP DISTRIBUTED SENDS, SYSTEM START DISTRIBUTED SENDS, STOP DISTRIBUTED SENDS, START DISTRIBUTED SENDS", TABLE, SYSTEM_SENDS) \
|
||||
M(SYSTEM_REPLICATED_SENDS, "SYSTEM STOP REPLICATED SENDS, SYSTEM START REPLICATED SENDS, STOP REPLICATED SENDS, START REPLICATED SENDS", TABLE, SYSTEM_SENDS) \
|
||||
M(SYSTEM_SENDS, "SYSTEM STOP SENDS, SYSTEM START SENDS, STOP SENDS, START SENDS", GROUP, SYSTEM) \
|
||||
|
||||
@ -51,7 +51,7 @@ TEST(AccessRights, Union)
|
||||
"CREATE DICTIONARY, DROP DATABASE, DROP TABLE, DROP VIEW, DROP DICTIONARY, UNDROP TABLE, "
|
||||
"TRUNCATE, OPTIMIZE, BACKUP, CREATE ROW POLICY, ALTER ROW POLICY, DROP ROW POLICY, "
|
||||
"SHOW ROW POLICIES, SYSTEM MERGES, SYSTEM TTL MERGES, SYSTEM FETCHES, "
|
||||
"SYSTEM MOVES, SYSTEM SENDS, SYSTEM REPLICATION QUEUES, "
|
||||
"SYSTEM MOVES, SYSTEM PULLING REPLICATION LOG, SYSTEM SENDS, SYSTEM REPLICATION QUEUES, "
|
||||
"SYSTEM DROP REPLICA, SYSTEM SYNC REPLICA, SYSTEM RESTART REPLICA, "
|
||||
"SYSTEM RESTORE REPLICA, SYSTEM WAIT LOADING PARTS, SYSTEM SYNC DATABASE REPLICA, SYSTEM FLUSH DISTRIBUTED, dictGet ON db1.*, GRANT NAMED COLLECTION ADMIN ON db1");
|
||||
}
|
||||
|
||||
@ -0,0 +1,221 @@
|
||||
#include <Analyzer/Passes/OptimizeDateOrDateTimeConverterWithPreimagePass.h>
|
||||
|
||||
#include <Functions/FunctionFactory.h>
|
||||
|
||||
#include <Analyzer/InDepthQueryTreeVisitor.h>
|
||||
#include <Analyzer/ColumnNode.h>
|
||||
#include <Analyzer/ConstantNode.h>
|
||||
#include <Analyzer/FunctionNode.h>
|
||||
#include <Common/DateLUT.h>
|
||||
#include <Common/DateLUTImpl.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
namespace ErrorCodes
|
||||
{
|
||||
extern const int LOGICAL_ERROR;
|
||||
}
|
||||
|
||||
namespace
|
||||
{
|
||||
|
||||
class OptimizeDateOrDateTimeConverterWithPreimageVisitor : public InDepthQueryTreeVisitorWithContext<OptimizeDateOrDateTimeConverterWithPreimageVisitor>
|
||||
{
|
||||
public:
|
||||
using Base = InDepthQueryTreeVisitorWithContext<OptimizeDateOrDateTimeConverterWithPreimageVisitor>;
|
||||
|
||||
explicit OptimizeDateOrDateTimeConverterWithPreimageVisitor(ContextPtr context)
|
||||
: Base(std::move(context))
|
||||
{}
|
||||
|
||||
static bool needChildVisit(QueryTreeNodePtr & node, QueryTreeNodePtr & /*child*/)
|
||||
{
|
||||
const static std::unordered_set<String> relations = {
|
||||
"equals",
|
||||
"notEquals",
|
||||
"less",
|
||||
"greater",
|
||||
"lessOrEquals",
|
||||
"greaterOrEquals",
|
||||
};
|
||||
|
||||
if (const auto * function = node->as<FunctionNode>())
|
||||
{
|
||||
return !relations.contains(function->getFunctionName());
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
void enterImpl(QueryTreeNodePtr & node) const
|
||||
{
|
||||
const static std::unordered_map<String, String> swap_relations = {
|
||||
{"equals", "equals"},
|
||||
{"notEquals", "notEquals"},
|
||||
{"less", "greater"},
|
||||
{"greater", "less"},
|
||||
{"lessOrEquals", "greaterOrEquals"},
|
||||
{"greaterOrEquals", "lessOrEquals"},
|
||||
};
|
||||
|
||||
const auto * function = node->as<FunctionNode>();
|
||||
|
||||
if (!function || !swap_relations.contains(function->getFunctionName())) return;
|
||||
|
||||
if (function->getArguments().getNodes().size() != 2) return;
|
||||
|
||||
size_t func_id = function->getArguments().getNodes().size();
|
||||
|
||||
for (size_t i = 0; i < function->getArguments().getNodes().size(); i++)
|
||||
{
|
||||
if (const auto * func = function->getArguments().getNodes()[i]->as<FunctionNode>())
|
||||
{
|
||||
func_id = i;
|
||||
}
|
||||
}
|
||||
|
||||
if (func_id == function->getArguments().getNodes().size()) return;
|
||||
|
||||
size_t literal_id = 1 - func_id;
|
||||
const auto * literal = function->getArguments().getNodes()[literal_id]->as<ConstantNode>();
|
||||
|
||||
if (!literal || literal->getValue().getType() != Field::Types::UInt64) return;
|
||||
|
||||
String comparator = literal_id > func_id ? function->getFunctionName(): swap_relations.at(function->getFunctionName());
|
||||
|
||||
const auto * func_node = function->getArguments().getNodes()[func_id]->as<FunctionNode>();
|
||||
/// Currently we only handle single-argument functions.
|
||||
if (!func_node || func_node->getArguments().getNodes().size() != 1) return;
|
||||
|
||||
const auto * column_id = func_node->getArguments().getNodes()[0]->as<ColumnNode>();
|
||||
if (!column_id) return;
|
||||
|
||||
const auto * column_type = column_id->getColumnType().get();
|
||||
if (!isDateOrDate32(column_type) && !isDateTime(column_type) && !isDateTime64(column_type)) return;
|
||||
|
||||
const auto & converter = FunctionFactory::instance().tryGet(func_node->getFunctionName(), getContext());
|
||||
if (!converter) return;
|
||||
|
||||
ColumnsWithTypeAndName args;
|
||||
args.emplace_back(column_id->getColumnType(), "tmp");
|
||||
auto converter_base = converter->build(args);
|
||||
if (!converter_base || !converter_base->hasInformationAboutPreimage()) return;
|
||||
|
||||
auto preimage_range = converter_base->getPreimage(*(column_id->getColumnType()), literal->getValue());
|
||||
if (!preimage_range) return;
|
||||
|
||||
const auto new_node = generateOptimizedDateFilter(comparator, *column_id, *preimage_range);
|
||||
|
||||
if (!new_node) return;
|
||||
|
||||
node = new_node;
|
||||
}
|
||||
|
||||
private:
|
||||
QueryTreeNodePtr generateOptimizedDateFilter(const String & comparator, const ColumnNode & column_node, const std::pair<Field, Field>& range) const
|
||||
{
|
||||
const DateLUTImpl & date_lut = DateLUT::instance("UTC");
|
||||
|
||||
String start_date_or_date_time;
|
||||
String end_date_or_date_time;
|
||||
|
||||
if (isDateOrDate32(column_node.getColumnType().get()))
|
||||
{
|
||||
start_date_or_date_time = date_lut.dateToString(range.first.get<DateLUTImpl::Time>());
|
||||
end_date_or_date_time = date_lut.dateToString(range.second.get<DateLUTImpl::Time>());
|
||||
}
|
||||
else if (isDateTime(column_node.getColumnType().get()) || isDateTime64(column_node.getColumnType().get()))
|
||||
{
|
||||
start_date_or_date_time = date_lut.timeToString(range.first.get<DateLUTImpl::Time>());
|
||||
end_date_or_date_time = date_lut.timeToString(range.second.get<DateLUTImpl::Time>());
|
||||
}
|
||||
else [[unlikely]] return {};
|
||||
|
||||
if (comparator == "equals")
|
||||
{
|
||||
const auto lhs = std::make_shared<FunctionNode>("greaterOrEquals");
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(start_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*lhs, lhs->getFunctionName());
|
||||
|
||||
const auto rhs = std::make_shared<FunctionNode>("less");
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*rhs, rhs->getFunctionName());
|
||||
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("and");
|
||||
new_date_filter->getArguments().getNodes() = {lhs, rhs};
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "notEquals")
|
||||
{
|
||||
const auto lhs = std::make_shared<FunctionNode>("less");
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(start_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*lhs, lhs->getFunctionName());
|
||||
|
||||
const auto rhs = std::make_shared<FunctionNode>("greaterOrEquals");
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*rhs, rhs->getFunctionName());
|
||||
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("or");
|
||||
new_date_filter->getArguments().getNodes() = {lhs, rhs};
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "greater")
|
||||
{
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("greaterOrEquals");
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "lessOrEquals")
|
||||
{
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("less");
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "less" || comparator == "greaterOrEquals")
|
||||
{
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>(comparator);
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(start_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else [[unlikely]]
|
||||
{
|
||||
throw Exception(ErrorCodes::LOGICAL_ERROR,
|
||||
"Expected equals, notEquals, less, lessOrEquals, greater, greaterOrEquals. Actual {}",
|
||||
comparator);
|
||||
}
|
||||
}
|
||||
|
||||
void resolveOrdinaryFunctionNode(FunctionNode & function_node, const String & function_name) const
|
||||
{
|
||||
auto function = FunctionFactory::instance().get(function_name, getContext());
|
||||
function_node.resolveAsFunction(function->build(function_node.getArgumentColumns()));
|
||||
}
|
||||
};
|
||||
|
||||
}
|
||||
|
||||
void OptimizeDateOrDateTimeConverterWithPreimagePass::run(QueryTreeNodePtr query_tree_node, ContextPtr context)
|
||||
{
|
||||
OptimizeDateOrDateTimeConverterWithPreimageVisitor visitor(std::move(context));
|
||||
visitor.visit(query_tree_node);
|
||||
}
|
||||
|
||||
}
|
||||
@ -0,0 +1,24 @@
|
||||
#pragma once
|
||||
|
||||
#include <Analyzer/IQueryTreePass.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
/** Replace predicate having Date/DateTime converters with their preimages to improve performance.
|
||||
* Given a Date column c, toYear(c) = 2023 -> c >= '2023-01-01' AND c < '2024-01-01'
|
||||
* Or if c is a DateTime column, toYear(c) = 2023 -> c >= '2023-01-01 00:00:00' AND c < '2024-01-01 00:00:00'.
|
||||
* The similar optimization also applies to other converters.
|
||||
*/
|
||||
class OptimizeDateOrDateTimeConverterWithPreimagePass final : public IQueryTreePass
|
||||
{
|
||||
public:
|
||||
String getName() override { return "OptimizeDateOrDateTimeConverterWithPreimagePass"; }
|
||||
|
||||
String getDescription() override { return "Replace predicate having Date/DateTime converters with their preimages"; }
|
||||
|
||||
void run(QueryTreeNodePtr query_tree_node, ContextPtr context) override;
|
||||
|
||||
};
|
||||
|
||||
}
|
||||
@ -42,6 +42,7 @@
|
||||
#include <Analyzer/Passes/CrossToInnerJoinPass.h>
|
||||
#include <Analyzer/Passes/ShardNumColumnToFunctionPass.h>
|
||||
#include <Analyzer/Passes/ConvertQueryToCNFPass.h>
|
||||
#include <Analyzer/Passes/OptimizeDateOrDateTimeConverterWithPreimagePass.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
@ -278,6 +279,7 @@ void addQueryTreePasses(QueryTreePassManager & manager)
|
||||
manager.addPass(std::make_unique<AutoFinalOnQueryPass>());
|
||||
manager.addPass(std::make_unique<CrossToInnerJoinPass>());
|
||||
manager.addPass(std::make_unique<ShardNumColumnToFunctionPass>());
|
||||
manager.addPass(std::make_unique<OptimizeDateOrDateTimeConverterWithPreimagePass>());
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@ -248,6 +248,7 @@ add_object_library(clickhouse_storages_distributed Storages/Distributed)
|
||||
add_object_library(clickhouse_storages_mergetree Storages/MergeTree)
|
||||
add_object_library(clickhouse_storages_liveview Storages/LiveView)
|
||||
add_object_library(clickhouse_storages_windowview Storages/WindowView)
|
||||
add_object_library(clickhouse_storages_s3queue Storages/S3Queue)
|
||||
add_object_library(clickhouse_client Client)
|
||||
add_object_library(clickhouse_bridge BridgeHelper)
|
||||
add_object_library(clickhouse_server Server)
|
||||
|
||||
@ -564,15 +564,22 @@ void ColumnNullable::updatePermutationImpl(IColumn::PermutationSortDirection dir
|
||||
else
|
||||
getNestedColumn().updatePermutation(direction, stability, limit, null_direction_hint, res, new_ranges);
|
||||
|
||||
equal_ranges = std::move(new_ranges);
|
||||
|
||||
if (unlikely(stability == PermutationSortStability::Stable))
|
||||
{
|
||||
for (auto & null_range : null_ranges)
|
||||
::sort(res.begin() + null_range.first, res.begin() + null_range.second);
|
||||
}
|
||||
|
||||
std::move(null_ranges.begin(), null_ranges.end(), std::back_inserter(equal_ranges));
|
||||
if (is_nulls_last || null_ranges.empty())
|
||||
{
|
||||
equal_ranges = std::move(new_ranges);
|
||||
std::move(null_ranges.begin(), null_ranges.end(), std::back_inserter(equal_ranges));
|
||||
}
|
||||
else
|
||||
{
|
||||
equal_ranges = std::move(null_ranges);
|
||||
std::move(new_ranges.begin(), new_ranges.end(), std::back_inserter(equal_ranges));
|
||||
}
|
||||
}
|
||||
|
||||
void ColumnNullable::getPermutation(IColumn::PermutationSortDirection direction, IColumn::PermutationSortStability stability,
|
||||
|
||||
@ -208,10 +208,10 @@ void MemoryTracker::allocImpl(Int64 size, bool throw_if_memory_exceeded, MemoryT
|
||||
* we allow exception about memory limit exceeded to be thrown only on next allocation.
|
||||
* So, we allow over-allocations.
|
||||
*/
|
||||
Int64 will_be = size + amount.fetch_add(size, std::memory_order_relaxed);
|
||||
Int64 will_be = size ? size + amount.fetch_add(size, std::memory_order_relaxed) : amount.load(std::memory_order_relaxed);
|
||||
|
||||
auto metric_loaded = metric.load(std::memory_order_relaxed);
|
||||
if (metric_loaded != CurrentMetrics::end())
|
||||
if (metric_loaded != CurrentMetrics::end() && size)
|
||||
CurrentMetrics::add(metric_loaded, size);
|
||||
|
||||
Int64 current_hard_limit = hard_limit.load(std::memory_order_relaxed);
|
||||
|
||||
@ -45,6 +45,25 @@ size_t shortest_literal_length(const Literals & literals)
|
||||
return shortest;
|
||||
}
|
||||
|
||||
const char * skipNameCapturingGroup(const char * pos, size_t offset, const char * end)
|
||||
{
|
||||
const char special = *(pos + offset) == '<' ? '>' : '\'';
|
||||
offset ++;
|
||||
while (pos + offset < end)
|
||||
{
|
||||
const char cur = *(pos + offset);
|
||||
if (cur == special)
|
||||
{
|
||||
return pos + offset;
|
||||
}
|
||||
if (('0' <= cur && cur <= '9') || ('a' <= cur && cur <= 'z') || ('A' <= cur && cur <= 'Z'))
|
||||
offset ++;
|
||||
else
|
||||
return pos;
|
||||
}
|
||||
return pos;
|
||||
}
|
||||
|
||||
const char * analyzeImpl(
|
||||
std::string_view regexp,
|
||||
const char * pos,
|
||||
@ -247,10 +266,15 @@ const char * analyzeImpl(
|
||||
break;
|
||||
}
|
||||
}
|
||||
/// (?:regex) means non-capturing parentheses group
|
||||
if (pos + 2 < end && pos[1] == '?' && pos[2] == ':')
|
||||
{
|
||||
pos += 2;
|
||||
}
|
||||
if (pos + 3 < end && pos[1] == '?' && (pos[2] == '<' || pos[2] == '\'' || (pos[2] == 'P' && pos[3] == '<')))
|
||||
{
|
||||
pos = skipNameCapturingGroup(pos, pos[2] == 'P' ? 3: 2, end);
|
||||
}
|
||||
Literal group_required_substr;
|
||||
bool group_is_trival = true;
|
||||
Literals group_alters;
|
||||
|
||||
@ -47,4 +47,8 @@ TEST(OptimizeRE, analyze)
|
||||
test_f("abc|(:?xx|yy|zz|x?)def", "", {"abc", "def"});
|
||||
test_f("abc|(:?xx|yy|zz|x?){1,2}def", "", {"abc", "def"});
|
||||
test_f(R"(\\A(?:(?:[-0-9_a-z]+(?:\\.[-0-9_a-z]+)*)/k8s1)\\z)", "/k8s1");
|
||||
test_f("[a-zA-Z]+(?P<num>\\d+)", "");
|
||||
test_f("[a-zA-Z]+(?<num>\\d+)", "");
|
||||
test_f("[a-zA-Z]+(?'num'\\d+)", "");
|
||||
test_f("[a-zA-Z]+(?x<num>\\d+)", "x<num>");
|
||||
}
|
||||
|
||||
@ -46,15 +46,6 @@
|
||||
|
||||
#define DBMS_MIN_REVISION_WITH_CUSTOM_SERIALIZATION 54454
|
||||
|
||||
/// Version of ClickHouse TCP protocol.
|
||||
///
|
||||
/// Should be incremented manually on protocol changes.
|
||||
///
|
||||
/// NOTE: DBMS_TCP_PROTOCOL_VERSION has nothing common with VERSION_REVISION,
|
||||
/// later is just a number for server version (one number instead of commit SHA)
|
||||
/// for simplicity (sometimes it may be more convenient in some use cases).
|
||||
#define DBMS_TCP_PROTOCOL_VERSION 54464
|
||||
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_INITIAL_QUERY_START_TIME 54449
|
||||
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_PROFILE_EVENTS_IN_INSERT 54456
|
||||
@ -77,3 +68,14 @@
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TOTAL_BYTES_IN_PROGRESS 54463
|
||||
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TIMEZONE_UPDATES 54464
|
||||
|
||||
#define DBMS_MIN_REVISION_WITH_SPARSE_SERIALIZATION 54465
|
||||
|
||||
/// Version of ClickHouse TCP protocol.
|
||||
///
|
||||
/// Should be incremented manually on protocol changes.
|
||||
///
|
||||
/// NOTE: DBMS_TCP_PROTOCOL_VERSION has nothing common with VERSION_REVISION,
|
||||
/// later is just a number for server version (one number instead of commit SHA)
|
||||
/// for simplicity (sometimes it may be more convenient in some use cases).
|
||||
#define DBMS_TCP_PROTOCOL_VERSION 54465
|
||||
|
||||
@ -104,6 +104,7 @@ class IColumn;
|
||||
M(UInt64, s3_retry_attempts, 10, "Setting for Aws::Client::RetryStrategy, Aws::Client does retries itself, 0 means no retries", 0) \
|
||||
M(UInt64, s3_request_timeout_ms, 3000, "Idleness timeout for sending and receiving data to/from S3. Fail if a single TCP read or write call blocks for this long.", 0) \
|
||||
M(Bool, enable_s3_requests_logging, false, "Enable very explicit logging of S3 requests. Makes sense for debug only.", 0) \
|
||||
M(String, s3queue_default_zookeeper_path, "/s3queue/", "Default zookeeper path prefix for S3Queue engine", 0) \
|
||||
M(UInt64, hdfs_replication, 0, "The actual number of replications can be specified when the hdfs file is created.", 0) \
|
||||
M(Bool, hdfs_truncate_on_insert, false, "Enables or disables truncate before insert in s3 engine tables", 0) \
|
||||
M(Bool, hdfs_create_new_file_on_insert, false, "Enables or disables creating a new file on each insert in hdfs engine tables", 0) \
|
||||
@ -626,7 +627,7 @@ class IColumn;
|
||||
M(Bool, engine_file_allow_create_multiple_files, false, "Enables or disables creating a new file on each insert in file engine tables if format has suffix.", 0) \
|
||||
M(Bool, engine_file_skip_empty_files, false, "Allows to skip empty files in file table engine", 0) \
|
||||
M(Bool, engine_url_skip_empty_files, false, "Allows to skip empty files in url table engine", 0) \
|
||||
M(Bool, disable_url_encoding, false, " Allows to disable decoding/encoding path in uri in URL table engine", 0) \
|
||||
M(Bool, enable_url_encoding, true, " Allows to enable/disable decoding/encoding path in uri in URL table engine", 0) \
|
||||
M(Bool, allow_experimental_database_replicated, false, "Allow to create databases with Replicated engine", 0) \
|
||||
M(UInt64, database_replicated_initial_query_timeout_sec, 300, "How long initial DDL query should wait for Replicated database to precess previous DDL queue entries", 0) \
|
||||
M(Bool, database_replicated_enforce_synchronous_settings, false, "Enforces synchronous waiting for some queries (see also database_atomic_wait_for_drop_and_detach_synchronously, mutation_sync, alter_sync). Not recommended to enable these settings.", 0) \
|
||||
@ -1011,6 +1012,10 @@ class IColumn;
|
||||
\
|
||||
M(CapnProtoEnumComparingMode, format_capn_proto_enum_comparising_mode, FormatSettings::CapnProtoEnumComparingMode::BY_VALUES, "How to map ClickHouse Enum and CapnProto Enum", 0) \
|
||||
\
|
||||
M(Bool, format_capn_proto_use_autogenerated_schema, true, "Use autogenerated CapnProto schema when format_schema is not set", 0) \
|
||||
M(Bool, format_protobuf_use_autogenerated_schema, true, "Use autogenerated Protobuf when format_schema is not set", 0) \
|
||||
M(String, output_format_schema, "", "The path to the file where the automatically generated schema will be saved", 0) \
|
||||
\
|
||||
M(String, input_format_mysql_dump_table_name, "", "Name of the table in MySQL dump from which to read data", 0) \
|
||||
M(Bool, input_format_mysql_dump_map_column_names, true, "Match columns from table in MySQL dump and columns from ClickHouse table by names", 0) \
|
||||
\
|
||||
@ -1027,7 +1032,8 @@ class IColumn;
|
||||
M(Bool, regexp_dict_allow_hyperscan, true, "Allow regexp_tree dictionary using Hyperscan library.", 0) \
|
||||
\
|
||||
M(Bool, dictionary_use_async_executor, false, "Execute a pipeline for reading from a dictionary with several threads. It's supported only by DIRECT dictionary with CLICKHOUSE source.", 0) \
|
||||
M(Bool, input_format_csv_allow_variable_number_of_columns, false, "Ignore extra columns in CSV input (if file has more columns than expected) and treat missing fields in CSV input as default values", 0) \
|
||||
M(Bool, input_format_csv_allow_variable_number_of_columns, false, "Ignore extra columns in CSV input (if file has more columns than expected) and treat missing fields in CSV input as default values", 0) \
|
||||
M(Bool, precise_float_parsing, false, "Prefer more precise (but slower) float parsing algorithm", 0) \
|
||||
|
||||
// End of FORMAT_FACTORY_SETTINGS
|
||||
// Please add settings non-related to formats into the COMMON_SETTINGS above.
|
||||
|
||||
@ -175,4 +175,11 @@ IMPLEMENT_SETTING_ENUM(ORCCompression, ErrorCodes::BAD_ARGUMENTS,
|
||||
{"zlib", FormatSettings::ORCCompression::ZLIB},
|
||||
{"lz4", FormatSettings::ORCCompression::LZ4}})
|
||||
|
||||
IMPLEMENT_SETTING_ENUM(S3QueueMode, ErrorCodes::BAD_ARGUMENTS,
|
||||
{{"ordered", S3QueueMode::ORDERED},
|
||||
{"unordered", S3QueueMode::UNORDERED}})
|
||||
|
||||
IMPLEMENT_SETTING_ENUM(S3QueueAction, ErrorCodes::BAD_ARGUMENTS,
|
||||
{{"keep", S3QueueAction::KEEP},
|
||||
{"delete", S3QueueAction::DELETE}})
|
||||
}
|
||||
|
||||
@ -221,4 +221,21 @@ enum class ParallelReplicasCustomKeyFilterType : uint8_t
|
||||
DECLARE_SETTING_ENUM(ParallelReplicasCustomKeyFilterType)
|
||||
|
||||
DECLARE_SETTING_ENUM(LocalFSReadMethod)
|
||||
|
||||
enum class S3QueueMode
|
||||
{
|
||||
ORDERED,
|
||||
UNORDERED,
|
||||
};
|
||||
|
||||
DECLARE_SETTING_ENUM(S3QueueMode)
|
||||
|
||||
enum class S3QueueAction
|
||||
{
|
||||
KEEP,
|
||||
DELETE,
|
||||
};
|
||||
|
||||
DECLARE_SETTING_ENUM(S3QueueAction)
|
||||
|
||||
}
|
||||
|
||||
@ -666,7 +666,7 @@ void DatabaseReplicated::checkQueryValid(const ASTPtr & query, ContextPtr query_
|
||||
{
|
||||
for (const auto & command : query_alter->command_list->children)
|
||||
{
|
||||
if (!isSupportedAlterType(command->as<ASTAlterCommand&>().type))
|
||||
if (!isSupportedAlterTypeForOnClusterDDLQuery(command->as<ASTAlterCommand&>().type))
|
||||
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Unsupported type of ALTER query");
|
||||
}
|
||||
}
|
||||
@ -1474,7 +1474,7 @@ bool DatabaseReplicated::shouldReplicateQuery(const ContextPtr & query_context,
|
||||
/// Some ALTERs are not replicated on database level
|
||||
if (const auto * alter = query_ptr->as<const ASTAlterQuery>())
|
||||
{
|
||||
if (alter->isAttachAlter() || alter->isFetchAlter() || alter->isDropPartitionAlter() || is_keeper_map_table(query_ptr))
|
||||
if (alter->isAttachAlter() || alter->isFetchAlter() || alter->isDropPartitionAlter() || is_keeper_map_table(query_ptr) || alter->isFreezeAlter())
|
||||
return false;
|
||||
|
||||
if (has_many_shards() || !is_replicated_table(query_ptr))
|
||||
|
||||
@ -74,19 +74,22 @@ CachedOnDiskReadBufferFromFile::CachedOnDiskReadBufferFromFile(
|
||||
}
|
||||
|
||||
void CachedOnDiskReadBufferFromFile::appendFilesystemCacheLog(
|
||||
const FileSegment::Range & file_segment_range, CachedOnDiskReadBufferFromFile::ReadType type)
|
||||
const FileSegment & file_segment, CachedOnDiskReadBufferFromFile::ReadType type)
|
||||
{
|
||||
if (!cache_log)
|
||||
return;
|
||||
|
||||
const auto range = file_segment.range();
|
||||
FilesystemCacheLogElement elem
|
||||
{
|
||||
.event_time = std::chrono::system_clock::to_time_t(std::chrono::system_clock::now()),
|
||||
.query_id = query_id,
|
||||
.source_file_path = source_file_path,
|
||||
.file_segment_range = { file_segment_range.left, file_segment_range.right },
|
||||
.file_segment_range = { range.left, range.right },
|
||||
.requested_range = { first_offset, read_until_position },
|
||||
.file_segment_size = file_segment_range.size(),
|
||||
.file_segment_key = file_segment.key().toString(),
|
||||
.file_segment_offset = file_segment.offset(),
|
||||
.file_segment_size = range.size(),
|
||||
.read_from_cache_attempted = true,
|
||||
.read_buffer_id = current_buffer_id,
|
||||
.profile_counters = std::make_shared<ProfileEvents::Counters::Snapshot>(
|
||||
@ -495,7 +498,7 @@ bool CachedOnDiskReadBufferFromFile::completeFileSegmentAndGetNext()
|
||||
auto completed_range = current_file_segment->range();
|
||||
|
||||
if (cache_log)
|
||||
appendFilesystemCacheLog(completed_range, read_type);
|
||||
appendFilesystemCacheLog(*current_file_segment, read_type);
|
||||
|
||||
chassert(file_offset_of_buffer_end > completed_range.right);
|
||||
|
||||
@ -518,7 +521,7 @@ CachedOnDiskReadBufferFromFile::~CachedOnDiskReadBufferFromFile()
|
||||
{
|
||||
if (cache_log && file_segments && !file_segments->empty())
|
||||
{
|
||||
appendFilesystemCacheLog(file_segments->front().range(), read_type);
|
||||
appendFilesystemCacheLog(file_segments->front(), read_type);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@ -90,7 +90,7 @@ private:
|
||||
|
||||
bool completeFileSegmentAndGetNext();
|
||||
|
||||
void appendFilesystemCacheLog(const FileSegment::Range & file_segment_range, ReadType read_type);
|
||||
void appendFilesystemCacheLog(const FileSegment & file_segment, ReadType read_type);
|
||||
|
||||
bool writeCache(char * data, size_t size, size_t offset, FileSegment & file_segment);
|
||||
|
||||
|
||||
@ -109,6 +109,8 @@ void ReadBufferFromRemoteFSGather::appendUncachedReadInfo()
|
||||
.source_file_path = current_object.remote_path,
|
||||
.file_segment_range = { 0, current_object.bytes_size },
|
||||
.cache_type = FilesystemCacheLogElement::CacheType::READ_FROM_FS_BYPASSING_CACHE,
|
||||
.file_segment_key = {},
|
||||
.file_segment_offset = {},
|
||||
.file_segment_size = current_object.bytes_size,
|
||||
.read_from_cache_attempted = false,
|
||||
};
|
||||
|
||||
@ -14,7 +14,7 @@ namespace ErrorCodes
|
||||
}
|
||||
|
||||
WriteBufferFromTemporaryFile::WriteBufferFromTemporaryFile(TemporaryFileOnDiskHolder && tmp_file_)
|
||||
: WriteBufferFromFile(tmp_file_->getPath(), DBMS_DEFAULT_BUFFER_SIZE, O_RDWR | O_TRUNC | O_CREAT, /* throttler= */ {}, 0600)
|
||||
: WriteBufferFromFile(tmp_file_->getAbsolutePath(), DBMS_DEFAULT_BUFFER_SIZE, O_RDWR | O_TRUNC | O_CREAT, /* throttler= */ {}, 0600)
|
||||
, tmp_file(std::move(tmp_file_))
|
||||
{
|
||||
}
|
||||
|
||||
@ -54,7 +54,7 @@ TemporaryFileOnDisk::TemporaryFileOnDisk(const DiskPtr & disk_, const String & p
|
||||
throw Exception(ErrorCodes::LOGICAL_ERROR, "Temporary file name is empty");
|
||||
}
|
||||
|
||||
String TemporaryFileOnDisk::getPath() const
|
||||
String TemporaryFileOnDisk::getAbsolutePath() const
|
||||
{
|
||||
return std::filesystem::path(disk->getPath()) / relative_path;
|
||||
}
|
||||
|
||||
@ -22,7 +22,10 @@ public:
|
||||
~TemporaryFileOnDisk();
|
||||
|
||||
DiskPtr getDisk() const { return disk; }
|
||||
String getPath() const;
|
||||
/// Return absolute path (disk + relative_path)
|
||||
String getAbsolutePath() const;
|
||||
/// Return relative path (without disk)
|
||||
const String & getRelativePath() const { return relative_path; }
|
||||
|
||||
private:
|
||||
DiskPtr disk;
|
||||
|
||||
@ -143,12 +143,14 @@ FormatSettings getFormatSettings(ContextPtr context, const Settings & settings)
|
||||
format_settings.protobuf.input_flatten_google_wrappers = settings.input_format_protobuf_flatten_google_wrappers;
|
||||
format_settings.protobuf.output_nullables_with_google_wrappers = settings.output_format_protobuf_nullables_with_google_wrappers;
|
||||
format_settings.protobuf.skip_fields_with_unsupported_types_in_schema_inference = settings.input_format_protobuf_skip_fields_with_unsupported_types_in_schema_inference;
|
||||
format_settings.protobuf.use_autogenerated_schema = settings.format_protobuf_use_autogenerated_schema;
|
||||
format_settings.regexp.escaping_rule = settings.format_regexp_escaping_rule;
|
||||
format_settings.regexp.regexp = settings.format_regexp;
|
||||
format_settings.regexp.skip_unmatched = settings.format_regexp_skip_unmatched;
|
||||
format_settings.schema.format_schema = settings.format_schema;
|
||||
format_settings.schema.format_schema_path = context->getFormatSchemaPath();
|
||||
format_settings.schema.is_server = context->hasGlobalContext() && (context->getGlobalContext()->getApplicationType() == Context::ApplicationType::SERVER);
|
||||
format_settings.schema.output_format_schema = settings.output_format_schema;
|
||||
format_settings.skip_unknown_fields = settings.input_format_skip_unknown_fields;
|
||||
format_settings.template_settings.resultset_format = settings.format_template_resultset;
|
||||
format_settings.template_settings.row_between_delimiter = settings.format_template_rows_between_delimiter;
|
||||
@ -190,6 +192,7 @@ FormatSettings getFormatSettings(ContextPtr context, const Settings & settings)
|
||||
format_settings.defaults_for_omitted_fields = settings.input_format_defaults_for_omitted_fields;
|
||||
format_settings.capn_proto.enum_comparing_mode = settings.format_capn_proto_enum_comparising_mode;
|
||||
format_settings.capn_proto.skip_fields_with_unsupported_types_in_schema_inference = settings.input_format_capn_proto_skip_fields_with_unsupported_types_in_schema_inference;
|
||||
format_settings.capn_proto.use_autogenerated_schema = settings.format_capn_proto_use_autogenerated_schema;
|
||||
format_settings.seekable_read = settings.input_format_allow_seeks;
|
||||
format_settings.msgpack.number_of_columns = settings.input_format_msgpack_number_of_columns;
|
||||
format_settings.msgpack.output_uuid_representation = settings.output_format_msgpack_uuid_representation;
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
#include <Formats/FormatSchemaInfo.h>
|
||||
#include <Interpreters/Context.h>
|
||||
#include <Common/Exception.h>
|
||||
#include <Common/filesystemHelpers.h>
|
||||
#include <Disks/IO/WriteBufferFromTemporaryFile.h>
|
||||
#include <filesystem>
|
||||
|
||||
|
||||
@ -105,4 +107,84 @@ FormatSchemaInfo::FormatSchemaInfo(const FormatSettings & settings, const String
|
||||
{
|
||||
}
|
||||
|
||||
template <typename SchemaGenerator>
|
||||
MaybeAutogeneratedFormatSchemaInfo<SchemaGenerator>::MaybeAutogeneratedFormatSchemaInfo(
|
||||
const FormatSettings & settings, const String & format, const Block & header, bool use_autogenerated_schema)
|
||||
{
|
||||
if (!use_autogenerated_schema || !settings.schema.format_schema.empty())
|
||||
{
|
||||
schema_info = std::make_unique<FormatSchemaInfo>(settings, format, true);
|
||||
return;
|
||||
}
|
||||
|
||||
String schema_path;
|
||||
fs::path default_schema_directory_path(fs::canonical(settings.schema.format_schema_path) / "");
|
||||
fs::path path;
|
||||
if (!settings.schema.output_format_schema.empty())
|
||||
{
|
||||
schema_path = settings.schema.output_format_schema;
|
||||
path = schema_path;
|
||||
if (path.is_absolute())
|
||||
{
|
||||
if (settings.schema.is_server)
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS, "Absolute path in the 'output_format_schema' setting is prohibited: {}", path.string());
|
||||
}
|
||||
else if (path.has_parent_path() && !fs::weakly_canonical(default_schema_directory_path / path).string().starts_with(fs::weakly_canonical(default_schema_directory_path).string()))
|
||||
{
|
||||
if (settings.schema.is_server)
|
||||
throw Exception(
|
||||
ErrorCodes::BAD_ARGUMENTS,
|
||||
"Path in the 'format_schema' setting shouldn't go outside the 'format_schema_path' directory: {} ({} not in {})",
|
||||
default_schema_directory_path.string(),
|
||||
path.string(),
|
||||
default_schema_directory_path.string());
|
||||
path = default_schema_directory_path / path;
|
||||
}
|
||||
else
|
||||
{
|
||||
path = default_schema_directory_path / path;
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
if (settings.schema.is_server)
|
||||
{
|
||||
tmp_file_path = PocoTemporaryFile::tempName(default_schema_directory_path.string()) + '.' + getFormatSchemaDefaultFileExtension(format);
|
||||
schema_path = fs::path(tmp_file_path).filename();
|
||||
}
|
||||
else
|
||||
{
|
||||
tmp_file_path = PocoTemporaryFile::tempName() + '.' + getFormatSchemaDefaultFileExtension(format);
|
||||
schema_path = tmp_file_path;
|
||||
}
|
||||
|
||||
path = tmp_file_path;
|
||||
}
|
||||
|
||||
WriteBufferFromFile buf(path.string());
|
||||
SchemaGenerator::writeSchema(buf, "Message", header.getNamesAndTypesList());
|
||||
buf.finalize();
|
||||
|
||||
schema_info = std::make_unique<FormatSchemaInfo>(schema_path + ":Message", format, true, settings.schema.is_server, settings.schema.format_schema_path);
|
||||
}
|
||||
|
||||
template <typename SchemaGenerator>
|
||||
MaybeAutogeneratedFormatSchemaInfo<SchemaGenerator>::~MaybeAutogeneratedFormatSchemaInfo()
|
||||
{
|
||||
if (!tmp_file_path.empty())
|
||||
{
|
||||
try
|
||||
{
|
||||
fs::remove(tmp_file_path);
|
||||
}
|
||||
catch (...)
|
||||
{
|
||||
tryLogCurrentException("MaybeAutogeneratedFormatSchemaInfo", "Cannot delete temporary schema file");
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
template class MaybeAutogeneratedFormatSchemaInfo<StructureToCapnProtoSchema>;
|
||||
template class MaybeAutogeneratedFormatSchemaInfo<StructureToProtobufSchema>;
|
||||
|
||||
}
|
||||
|
||||
@ -2,6 +2,8 @@
|
||||
|
||||
#include <base/types.h>
|
||||
#include <Formats/FormatSettings.h>
|
||||
#include <Formats/StructureToCapnProtoSchema.h>
|
||||
#include <Formats/StructureToProtobufSchema.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
@ -30,4 +32,23 @@ private:
|
||||
String message_name;
|
||||
};
|
||||
|
||||
|
||||
template <typename SchemaGenerator>
|
||||
class MaybeAutogeneratedFormatSchemaInfo
|
||||
{
|
||||
public:
|
||||
MaybeAutogeneratedFormatSchemaInfo(const FormatSettings & settings, const String & format, const Block & header, bool use_autogenerated_schema);
|
||||
|
||||
~MaybeAutogeneratedFormatSchemaInfo();
|
||||
|
||||
const FormatSchemaInfo & getSchemaInfo() const { return *schema_info; }
|
||||
private:
|
||||
|
||||
std::unique_ptr<FormatSchemaInfo> schema_info;
|
||||
String tmp_file_path;
|
||||
};
|
||||
|
||||
using CapnProtoSchemaInfo = MaybeAutogeneratedFormatSchemaInfo<StructureToCapnProtoSchema>;
|
||||
using ProtobufSchemaInfo = MaybeAutogeneratedFormatSchemaInfo<StructureToProtobufSchema>;
|
||||
|
||||
}
|
||||
|
||||
@ -276,6 +276,7 @@ struct FormatSettings
|
||||
*/
|
||||
bool allow_multiple_rows_without_delimiter = false;
|
||||
bool skip_fields_with_unsupported_types_in_schema_inference = false;
|
||||
bool use_autogenerated_schema = true;
|
||||
} protobuf;
|
||||
|
||||
struct
|
||||
@ -297,6 +298,7 @@ struct FormatSettings
|
||||
std::string format_schema;
|
||||
std::string format_schema_path;
|
||||
bool is_server = false;
|
||||
std::string output_format_schema;
|
||||
} schema;
|
||||
|
||||
struct
|
||||
@ -359,6 +361,7 @@ struct FormatSettings
|
||||
{
|
||||
CapnProtoEnumComparingMode enum_comparing_mode = CapnProtoEnumComparingMode::BY_VALUES;
|
||||
bool skip_fields_with_unsupported_types_in_schema_inference = false;
|
||||
bool use_autogenerated_schema = true;
|
||||
} capn_proto;
|
||||
|
||||
enum class MsgPackUUIDRepresentation
|
||||
|
||||
@ -135,9 +135,19 @@ size_t NativeWriter::write(const Block & block)
|
||||
if (client_revision >= DBMS_MIN_REVISION_WITH_CUSTOM_SERIALIZATION)
|
||||
{
|
||||
auto info = column.type->getSerializationInfo(*column.column);
|
||||
serialization = column.type->getSerialization(*info);
|
||||
bool has_custom = false;
|
||||
|
||||
if (client_revision >= DBMS_MIN_REVISION_WITH_SPARSE_SERIALIZATION)
|
||||
{
|
||||
serialization = column.type->getSerialization(*info);
|
||||
has_custom = info->hasCustomSerialization();
|
||||
}
|
||||
else
|
||||
{
|
||||
serialization = column.type->getDefaultSerialization();
|
||||
column.column = recursiveRemoveSparse(column.column);
|
||||
}
|
||||
|
||||
bool has_custom = info->hasCustomSerialization();
|
||||
writeBinary(static_cast<UInt8>(has_custom), ostr);
|
||||
if (has_custom)
|
||||
info->serialializeKindBinary(ostr);
|
||||
|
||||
@ -3029,7 +3029,7 @@ namespace
|
||||
if (!message_serializer)
|
||||
{
|
||||
throw Exception(ErrorCodes::NO_COLUMNS_SERIALIZED_TO_PROTOBUF_FIELDS,
|
||||
"Not found matches between the names of the columns {{}} and the fields {{}} of the message {} in the protobuf schema",
|
||||
"Not found matches between the names of the columns ({}) and the fields ({}) of the message {} in the protobuf schema",
|
||||
boost::algorithm::join(column_names, ", "), boost::algorithm::join(getFieldNames(message_descriptor), ", "),
|
||||
quoteString(message_descriptor.full_name()));
|
||||
}
|
||||
@ -3647,7 +3647,7 @@ namespace
|
||||
if (!message_serializer)
|
||||
{
|
||||
throw Exception(ErrorCodes::NO_COLUMNS_SERIALIZED_TO_PROTOBUF_FIELDS,
|
||||
"Not found matches between the names of the tuple's elements {{}} and the fields {{}} "
|
||||
"Not found matches between the names of the tuple's elements ({}) and the fields ({}) "
|
||||
"of the message {} in the protobuf schema",
|
||||
boost::algorithm::join(tuple_data_type.getElementNames(), ", "),
|
||||
boost::algorithm::join(getFieldNames(*field_descriptor.message_type()), ", "),
|
||||
|
||||
236
src/Formats/StructureToCapnProtoSchema.cpp
Normal file
236
src/Formats/StructureToCapnProtoSchema.cpp
Normal file
@ -0,0 +1,236 @@
|
||||
#include <Formats/StructureToCapnProtoSchema.h>
|
||||
#include <Formats/StructureToFormatSchemaUtils.h>
|
||||
#include <Columns/ColumnString.h>
|
||||
#include <DataTypes/DataTypeNullable.h>
|
||||
#include <DataTypes/DataTypeLowCardinality.h>
|
||||
#include <DataTypes/DataTypeArray.h>
|
||||
#include <DataTypes/DataTypeMap.h>
|
||||
#include <DataTypes/DataTypeTuple.h>
|
||||
#include <DataTypes/DataTypeEnum.h>
|
||||
#include <Common/StringUtils/StringUtils.h>
|
||||
#include <Common/randomSeed.h>
|
||||
#include <pcg_random.hpp>
|
||||
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
using namespace StructureToFormatSchemaUtils;
|
||||
|
||||
namespace ErrorCodes
|
||||
{
|
||||
extern const int BAD_ARGUMENTS;
|
||||
}
|
||||
|
||||
namespace
|
||||
{
|
||||
|
||||
const std::unordered_map<TypeIndex, String> capn_proto_simple_type_names =
|
||||
{
|
||||
{TypeIndex::Int8, "Int8"},
|
||||
{TypeIndex::UInt8, "UInt8"},
|
||||
{TypeIndex::Int16, "Int16"},
|
||||
{TypeIndex::UInt16, "UInt16"},
|
||||
{TypeIndex::Int32, "Int32"},
|
||||
{TypeIndex::UInt32, "UInt32"},
|
||||
{TypeIndex::Int64, "Int64"},
|
||||
{TypeIndex::UInt64, "UInt64"},
|
||||
{TypeIndex::Int128, "Data"},
|
||||
{TypeIndex::UInt128, "Data"},
|
||||
{TypeIndex::Int256, "Data"},
|
||||
{TypeIndex::UInt256, "Data"},
|
||||
{TypeIndex::Float32, "Float32"},
|
||||
{TypeIndex::Float64, "Float64"},
|
||||
{TypeIndex::Decimal32, "Int32"},
|
||||
{TypeIndex::Decimal64, "Int64"},
|
||||
{TypeIndex::Decimal128, "Data"},
|
||||
{TypeIndex::Decimal256, "Data"},
|
||||
{TypeIndex::String, "Data"},
|
||||
{TypeIndex::FixedString, "Data"},
|
||||
{TypeIndex::UUID, "Data"},
|
||||
{TypeIndex::Date, "UInt16"},
|
||||
{TypeIndex::Date32, "Int32"},
|
||||
{TypeIndex::DateTime, "UInt32"},
|
||||
{TypeIndex::DateTime64, "Int64"},
|
||||
{TypeIndex::IPv4, "UInt32"},
|
||||
{TypeIndex::IPv6, "Data"},
|
||||
};
|
||||
|
||||
void writeCapnProtoHeader(WriteBuffer & buf)
|
||||
{
|
||||
pcg64 rng(randomSeed());
|
||||
size_t id = rng() | (1ull << 63); /// First bit should be 1
|
||||
writeString(fmt::format("@0x{};\n\n", getHexUIntLowercase(id)), buf);
|
||||
}
|
||||
|
||||
void writeFieldDefinition(WriteBuffer & buf, const String & type_name, const String & column_name, size_t & field_index, size_t indent)
|
||||
{
|
||||
writeIndent(buf, indent);
|
||||
writeString(fmt::format("{} @{} : {};\n", getSchemaFieldName(column_name), field_index++, type_name), buf);
|
||||
}
|
||||
|
||||
void startEnum(WriteBuffer & buf, const String & enum_name, size_t indent)
|
||||
{
|
||||
startNested(buf, enum_name, "enum", indent);
|
||||
}
|
||||
|
||||
void startUnion(WriteBuffer & buf, size_t indent)
|
||||
{
|
||||
startNested(buf, "", "union", indent);
|
||||
}
|
||||
|
||||
void startStruct(WriteBuffer & buf, const String & struct_name, size_t indent)
|
||||
{
|
||||
startNested(buf, struct_name, "struct", indent);
|
||||
}
|
||||
|
||||
String prepareAndGetCapnProtoTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent);
|
||||
|
||||
void writeField(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t & field_index, size_t indent)
|
||||
{
|
||||
auto field_type_name = prepareAndGetCapnProtoTypeName(buf, data_type, column_name, indent);
|
||||
writeFieldDefinition(buf, field_type_name, column_name, field_index, indent);
|
||||
}
|
||||
|
||||
String prepareArrayAndGetCapnProtoTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
const auto & nested_type = assert_cast<const DataTypeArray &>(*data_type).getNestedType();
|
||||
auto nested_type_name = prepareAndGetCapnProtoTypeName(buf, nested_type, column_name, indent);
|
||||
return "List(" + nested_type_name + ")";
|
||||
}
|
||||
|
||||
String prepareNullableAndGetCapnProtoTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
/// Nullable is represented as a struct with union with 2 fields:
|
||||
///
|
||||
/// struct Nullable
|
||||
/// {
|
||||
/// union
|
||||
/// {
|
||||
/// value @0 : Value;
|
||||
/// null @1 : Void;
|
||||
/// }
|
||||
/// }
|
||||
auto struct_name = getSchemaMessageName(column_name);
|
||||
startStruct(buf, struct_name, indent);
|
||||
auto nested_type_name = prepareAndGetCapnProtoTypeName(buf, assert_cast<const DataTypeNullable &>(*data_type).getNestedType(), column_name, indent);
|
||||
startUnion(buf, indent + 1);
|
||||
size_t field_index = 0;
|
||||
writeFieldDefinition(buf, nested_type_name, "value", field_index, indent + 2);
|
||||
writeFieldDefinition(buf, "Void", "null", field_index, indent + 2);
|
||||
endNested(buf, indent + 1);
|
||||
endNested(buf, indent);
|
||||
return struct_name;
|
||||
}
|
||||
|
||||
String prepareTupleAndGetCapnProtoTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
const auto & tuple_type = assert_cast<const DataTypeTuple &>(*data_type);
|
||||
auto nested_names_and_types = getCollectedTupleElements(tuple_type);
|
||||
|
||||
String struct_name = getSchemaMessageName(column_name);
|
||||
startStruct(buf, struct_name, indent);
|
||||
size_t nested_field_index = 0;
|
||||
for (const auto & [name, type] : nested_names_and_types)
|
||||
writeField(buf, type, name, nested_field_index, indent + 1);
|
||||
endNested(buf, indent);
|
||||
return struct_name;
|
||||
}
|
||||
|
||||
String prepareMapAndGetCapnProtoTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
/// We output/input Map type as follow CapnProto schema
|
||||
///
|
||||
/// struct Map
|
||||
/// {
|
||||
/// struct Entry
|
||||
/// {
|
||||
/// key @0: Key;
|
||||
/// value @1: Value;
|
||||
/// }
|
||||
/// entries @0 :List(Entry);
|
||||
/// }
|
||||
const auto & map_type = assert_cast<const DataTypeMap &>(*data_type);
|
||||
const auto & key_type = map_type.getKeyType();
|
||||
const auto & value_type = map_type.getValueType();
|
||||
|
||||
String struct_name = getSchemaMessageName(column_name);
|
||||
startStruct(buf, struct_name, indent);
|
||||
startStruct(buf, "Entry", indent + 1);
|
||||
auto key_type_name = prepareAndGetCapnProtoTypeName(buf, key_type, "key", indent + 2);
|
||||
auto value_type_name = prepareAndGetCapnProtoTypeName(buf, value_type, "value", indent + 2);
|
||||
size_t field_index = 0;
|
||||
writeFieldDefinition(buf, key_type_name, "key", field_index, indent + 2);
|
||||
writeFieldDefinition(buf, value_type_name, "value", field_index, indent + 2);
|
||||
endNested(buf, indent + 1);
|
||||
field_index = 0;
|
||||
writeFieldDefinition(buf, "List(Entry)", "entries", field_index, indent + 1);
|
||||
endNested(buf, indent);
|
||||
return struct_name;
|
||||
}
|
||||
|
||||
template <typename EnumType>
|
||||
String prepareEnumAndGetCapnProtoTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
const auto & enum_type = assert_cast<const DataTypeEnum<EnumType> &>(*data_type);
|
||||
String enum_name = getSchemaMessageName(column_name);
|
||||
startEnum(buf, enum_name, indent);
|
||||
const auto & names = enum_type.getAllRegisteredNames();
|
||||
for (size_t i = 0; i != names.size(); ++i)
|
||||
{
|
||||
writeIndent(buf, indent + 1);
|
||||
writeString(fmt::format("{} @{};\n", names[i], std::to_string(i)), buf);
|
||||
}
|
||||
endNested(buf, indent);
|
||||
return enum_name;
|
||||
}
|
||||
|
||||
String prepareAndGetCapnProtoTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
TypeIndex type_id = data_type->getTypeId();
|
||||
|
||||
switch (data_type->getTypeId())
|
||||
{
|
||||
case TypeIndex::Nullable:
|
||||
return prepareNullableAndGetCapnProtoTypeName(buf, data_type, column_name, indent);
|
||||
case TypeIndex::LowCardinality:
|
||||
return prepareAndGetCapnProtoTypeName(buf, assert_cast<const DataTypeLowCardinality &>(*data_type).getDictionaryType(), column_name, indent);
|
||||
case TypeIndex::Array:
|
||||
return prepareArrayAndGetCapnProtoTypeName(buf, data_type, column_name, indent);
|
||||
case TypeIndex::Tuple:
|
||||
return prepareTupleAndGetCapnProtoTypeName(buf, data_type, column_name, indent);
|
||||
case TypeIndex::Map:
|
||||
return prepareMapAndGetCapnProtoTypeName(buf, data_type, column_name, indent);
|
||||
case TypeIndex::Enum8:
|
||||
return prepareEnumAndGetCapnProtoTypeName<Int8>(buf, data_type, column_name, indent);
|
||||
case TypeIndex::Enum16:
|
||||
return prepareEnumAndGetCapnProtoTypeName<Int16>(buf, data_type, column_name, indent);
|
||||
default:
|
||||
{
|
||||
if (isBool(data_type))
|
||||
return "Bool";
|
||||
|
||||
auto it = capn_proto_simple_type_names.find(type_id);
|
||||
if (it == capn_proto_simple_type_names.end())
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS, "CapnProto type name is not found for type {}", data_type->getName());
|
||||
return it->second;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void StructureToCapnProtoSchema::writeSchema(WriteBuffer & buf, const String & message_name, const NamesAndTypesList & names_and_types_)
|
||||
{
|
||||
auto names_and_types = collectNested(names_and_types_);
|
||||
writeCapnProtoHeader(buf);
|
||||
startStruct(buf, getSchemaMessageName(message_name), 0);
|
||||
|
||||
size_t field_index = 0;
|
||||
for (const auto & [column_name, data_type] : names_and_types)
|
||||
writeField(buf, data_type, column_name, field_index, 1);
|
||||
|
||||
endNested(buf, 0);
|
||||
}
|
||||
|
||||
}
|
||||
16
src/Formats/StructureToCapnProtoSchema.h
Normal file
16
src/Formats/StructureToCapnProtoSchema.h
Normal file
@ -0,0 +1,16 @@
|
||||
#pragma once
|
||||
|
||||
#include <IO/WriteBuffer.h>
|
||||
#include <Core/NamesAndTypes.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
struct StructureToCapnProtoSchema
|
||||
{
|
||||
static constexpr auto name = "structureToCapnProtoSchema";
|
||||
|
||||
static void writeSchema(WriteBuffer & buf, const String & message_name, const NamesAndTypesList & names_and_types_);
|
||||
};
|
||||
|
||||
}
|
||||
117
src/Formats/StructureToFormatSchemaUtils.cpp
Normal file
117
src/Formats/StructureToFormatSchemaUtils.cpp
Normal file
@ -0,0 +1,117 @@
|
||||
#include <Formats/StructureToFormatSchemaUtils.h>
|
||||
#include <IO/WriteHelpers.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
namespace StructureToFormatSchemaUtils
|
||||
{
|
||||
|
||||
void writeIndent(WriteBuffer & buf, size_t indent)
|
||||
{
|
||||
writeChar(' ', indent * 4, buf);
|
||||
}
|
||||
|
||||
void startNested(WriteBuffer & buf, const String & nested_name, const String & nested_type, size_t indent)
|
||||
{
|
||||
writeIndent(buf, indent);
|
||||
writeString(nested_type, buf);
|
||||
if (!nested_name.empty())
|
||||
{
|
||||
writeChar(' ', buf);
|
||||
writeString(nested_name, buf);
|
||||
}
|
||||
writeChar('\n', buf);
|
||||
writeIndent(buf, indent);
|
||||
writeCString("{\n", buf);
|
||||
}
|
||||
|
||||
void endNested(WriteBuffer & buf, size_t indent)
|
||||
{
|
||||
writeIndent(buf, indent);
|
||||
writeCString("}\n", buf);
|
||||
}
|
||||
|
||||
String getSchemaFieldName(const String & column_name)
|
||||
{
|
||||
String result = column_name;
|
||||
/// Replace all first uppercase letters to lower-case,
|
||||
/// because fields in CapnProto schema must begin with a lower-case letter.
|
||||
/// Don't replace all letters to lower-case to remain camelCase field names.
|
||||
for (auto & symbol : result)
|
||||
{
|
||||
if (islower(symbol))
|
||||
break;
|
||||
symbol = tolower(symbol);
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
String getSchemaMessageName(const String & column_name)
|
||||
{
|
||||
String result = column_name;
|
||||
if (!column_name.empty() && isalpha(column_name[0]))
|
||||
result[0] = toupper(column_name[0]);
|
||||
return result;
|
||||
}
|
||||
|
||||
namespace
|
||||
{
|
||||
std::pair<String, String> splitName(const String & name)
|
||||
{
|
||||
const auto * begin = name.data();
|
||||
const auto * end = name.data() + name.size();
|
||||
const auto * it = find_first_symbols<'_', '.'>(begin, end);
|
||||
String first = String(begin, it);
|
||||
String second = it == end ? "" : String(it + 1, end);
|
||||
return {std::move(first), std::move(second)};
|
||||
}
|
||||
}
|
||||
|
||||
NamesAndTypesList collectNested(const NamesAndTypesList & names_and_types)
|
||||
{
|
||||
/// Find all columns with dots '.' or underscores '_' and move them into a tuple.
|
||||
/// For example if we have columns 'a.b UInt32, a.c UInt32, x_y String' we will
|
||||
/// change it to 'a Tuple(b UInt32, c UInt32), x Tuple(y String)'
|
||||
NamesAndTypesList result;
|
||||
std::unordered_map<String, NamesAndTypesList> nested;
|
||||
for (const auto & [name, type] : names_and_types)
|
||||
{
|
||||
auto [field_name, nested_name] = splitName(name);
|
||||
if (nested_name.empty())
|
||||
result.emplace_back(name, type);
|
||||
else
|
||||
nested[field_name].emplace_back(nested_name, type);
|
||||
}
|
||||
|
||||
for (const auto & [field_name, elements]: nested)
|
||||
result.emplace_back(field_name, std::make_shared<DataTypeTuple>(elements.getTypes(), elements.getNames()));
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
NamesAndTypesList getCollectedTupleElements(const DataTypeTuple & tuple_type)
|
||||
{
|
||||
const auto & nested_types = tuple_type.getElements();
|
||||
Names nested_names;
|
||||
if (tuple_type.haveExplicitNames())
|
||||
{
|
||||
nested_names = tuple_type.getElementNames();
|
||||
}
|
||||
else
|
||||
{
|
||||
nested_names.reserve(nested_types.size());
|
||||
for (size_t i = 0; i != nested_types.size(); ++i)
|
||||
nested_names.push_back("e" + std::to_string(i + 1));
|
||||
}
|
||||
|
||||
NamesAndTypesList result;
|
||||
for (size_t i = 0; i != nested_names.size(); ++i)
|
||||
result.emplace_back(nested_names[i], nested_types[i]);
|
||||
|
||||
return collectNested(result);
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
27
src/Formats/StructureToFormatSchemaUtils.h
Normal file
27
src/Formats/StructureToFormatSchemaUtils.h
Normal file
@ -0,0 +1,27 @@
|
||||
#pragma once
|
||||
|
||||
#include <Core/NamesAndTypes.h>
|
||||
#include <DataTypes/NestedUtils.h>
|
||||
#include <DataTypes/DataTypeTuple.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
namespace StructureToFormatSchemaUtils
|
||||
{
|
||||
void writeIndent(WriteBuffer & buf, size_t indent);
|
||||
|
||||
void startNested(WriteBuffer & buf, const String & nested_name, const String & nested_type, size_t indent);
|
||||
|
||||
void endNested(WriteBuffer & buf, size_t indent);
|
||||
|
||||
String getSchemaFieldName(const String & column_name);
|
||||
|
||||
String getSchemaMessageName(const String & column_name);
|
||||
|
||||
NamesAndTypesList collectNested(const NamesAndTypesList & names_and_types);
|
||||
|
||||
NamesAndTypesList getCollectedTupleElements(const DataTypeTuple & tuple_type);
|
||||
}
|
||||
|
||||
}
|
||||
214
src/Formats/StructureToProtobufSchema.cpp
Normal file
214
src/Formats/StructureToProtobufSchema.cpp
Normal file
@ -0,0 +1,214 @@
|
||||
#include <Formats/StructureToProtobufSchema.h>
|
||||
#include <Formats/StructureToFormatSchemaUtils.h>
|
||||
#include <Columns/ColumnString.h>
|
||||
#include <DataTypes/DataTypeNullable.h>
|
||||
#include <DataTypes/DataTypeLowCardinality.h>
|
||||
#include <DataTypes/DataTypeArray.h>
|
||||
#include <DataTypes/DataTypeMap.h>
|
||||
#include <DataTypes/DataTypeTuple.h>
|
||||
#include <DataTypes/DataTypeEnum.h>
|
||||
#include <Common/StringUtils/StringUtils.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
using namespace StructureToFormatSchemaUtils;
|
||||
|
||||
namespace ErrorCodes
|
||||
{
|
||||
extern const int BAD_ARGUMENTS;
|
||||
}
|
||||
|
||||
namespace
|
||||
{
|
||||
|
||||
const std::unordered_map<TypeIndex, String> protobuf_simple_type_names =
|
||||
{
|
||||
{TypeIndex::Int8, "int32"},
|
||||
{TypeIndex::UInt8, "uint32"},
|
||||
{TypeIndex::Int16, "int32"},
|
||||
{TypeIndex::UInt16, "uint32"},
|
||||
{TypeIndex::Int32, "int32"},
|
||||
{TypeIndex::UInt32, "uint32"},
|
||||
{TypeIndex::Int64, "int64"},
|
||||
{TypeIndex::UInt64, "uint64"},
|
||||
{TypeIndex::Int128, "bytes"},
|
||||
{TypeIndex::UInt128, "bytes"},
|
||||
{TypeIndex::Int256, "bytes"},
|
||||
{TypeIndex::UInt256, "bytes"},
|
||||
{TypeIndex::Float32, "float"},
|
||||
{TypeIndex::Float64, "double"},
|
||||
{TypeIndex::Decimal32, "bytes"},
|
||||
{TypeIndex::Decimal64, "bytes"},
|
||||
{TypeIndex::Decimal128, "bytes"},
|
||||
{TypeIndex::Decimal256, "bytes"},
|
||||
{TypeIndex::String, "bytes"},
|
||||
{TypeIndex::FixedString, "bytes"},
|
||||
{TypeIndex::UUID, "bytes"},
|
||||
{TypeIndex::Date, "uint32"},
|
||||
{TypeIndex::Date32, "int32"},
|
||||
{TypeIndex::DateTime, "uint32"},
|
||||
{TypeIndex::DateTime64, "uint64"},
|
||||
{TypeIndex::IPv4, "uint32"},
|
||||
{TypeIndex::IPv6, "bytes"},
|
||||
};
|
||||
|
||||
void writeProtobufHeader(WriteBuffer & buf)
|
||||
{
|
||||
writeCString("syntax = \"proto3\";\n\n", buf);
|
||||
}
|
||||
|
||||
void startEnum(WriteBuffer & buf, const String & enum_name, size_t indent)
|
||||
{
|
||||
startNested(buf, enum_name, "enum", indent);
|
||||
}
|
||||
|
||||
void startMessage(WriteBuffer & buf, const String & message_name, size_t indent)
|
||||
{
|
||||
startNested(buf, message_name, "message", indent);
|
||||
}
|
||||
|
||||
void writeFieldDefinition(WriteBuffer & buf, const String & type_name, const String & column_name, size_t & field_index, size_t indent)
|
||||
{
|
||||
writeIndent(buf, indent);
|
||||
writeString(fmt::format("{} {} = {};\n", type_name, getSchemaFieldName(column_name), field_index++), buf);
|
||||
}
|
||||
|
||||
String prepareAndGetProtobufTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent);
|
||||
|
||||
void writeProtobufField(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t & field_index, size_t indent)
|
||||
{
|
||||
auto field_type_name = prepareAndGetProtobufTypeName(buf, data_type, column_name, indent);
|
||||
writeFieldDefinition(buf, field_type_name, column_name, field_index, indent);
|
||||
}
|
||||
|
||||
String prepareArrayAndGetProtobufTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
const auto & nested_type = assert_cast<const DataTypeArray &>(*data_type).getNestedType();
|
||||
/// Simple case when we can just use 'repeated <nested_type>'.
|
||||
if (!isArray(nested_type) && !isMap(nested_type))
|
||||
{
|
||||
auto nested_type_name = prepareAndGetProtobufTypeName(buf, nested_type, column_name, indent);
|
||||
return "repeated " + nested_type_name;
|
||||
}
|
||||
|
||||
/// Protobuf doesn't support multidimensional repeated fields and repeated maps.
|
||||
/// When we have Array(Array(...)) or Array(Map(...)) we should place nested type into a nested Message with one field.
|
||||
String message_name = getSchemaMessageName(column_name);
|
||||
startMessage(buf, message_name, indent);
|
||||
size_t nested_field_index = 1;
|
||||
writeProtobufField(buf, nested_type, column_name, nested_field_index, indent + 1);
|
||||
endNested(buf, indent);
|
||||
return "repeated " + message_name;
|
||||
}
|
||||
|
||||
String prepareTupleAndGetProtobufTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
const auto & tuple_type = assert_cast<const DataTypeTuple &>(*data_type);
|
||||
auto nested_names_and_types = getCollectedTupleElements(tuple_type);
|
||||
|
||||
String message_name = getSchemaMessageName(column_name);
|
||||
startMessage(buf, message_name, indent);
|
||||
size_t nested_field_index = 1;
|
||||
for (const auto & [name, type] : nested_names_and_types)
|
||||
writeProtobufField(buf, type, name, nested_field_index, indent + 1);
|
||||
endNested(buf, indent);
|
||||
return message_name;
|
||||
}
|
||||
|
||||
String prepareMapAndGetProtobufTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
const auto & map_type = assert_cast<const DataTypeMap &>(*data_type);
|
||||
const auto & key_type = map_type.getKeyType();
|
||||
const auto & value_type = map_type.getValueType();
|
||||
auto it = protobuf_simple_type_names.find(key_type->getTypeId());
|
||||
if (it == protobuf_simple_type_names.end())
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS, "Type {} is not supported for conversion into Map key in Protobuf schema", data_type->getName());
|
||||
auto key_type_name = it->second;
|
||||
/// Protobuf map type doesn't support "bytes" type as a key. Change it to "string"
|
||||
if (key_type_name == "bytes")
|
||||
key_type_name = "string";
|
||||
|
||||
/// Special cases when value type is Array or Map, because Protobuf
|
||||
/// doesn't support syntax "map<Key, repeated Value>" and "map<Key, map<..., ...>>"
|
||||
/// In this case we should place it into a nested Message with one field.
|
||||
String value_type_name;
|
||||
if (isArray(value_type) || isMap(value_type))
|
||||
{
|
||||
value_type_name = getSchemaMessageName(column_name) + "Value";
|
||||
startMessage(buf, value_type_name, indent);
|
||||
size_t nested_field_index = 1;
|
||||
writeProtobufField(buf, value_type, column_name + "Value", nested_field_index, indent + 1);
|
||||
endNested(buf, indent);
|
||||
}
|
||||
else
|
||||
{
|
||||
value_type_name = prepareAndGetProtobufTypeName(buf, value_type, column_name + "Value", indent);
|
||||
}
|
||||
|
||||
return fmt::format("map<{}, {}>", key_type_name, value_type_name);
|
||||
}
|
||||
|
||||
template <typename EnumType>
|
||||
String prepareEnumAndGetProtobufTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
const auto & enum_type = assert_cast<const DataTypeEnum<EnumType> &>(*data_type);
|
||||
String enum_name = getSchemaMessageName(column_name);
|
||||
startEnum(buf, enum_name, indent);
|
||||
const auto & names = enum_type.getAllRegisteredNames();
|
||||
for (size_t i = 0; i != names.size(); ++i)
|
||||
{
|
||||
writeIndent(buf, indent + 1);
|
||||
writeString(fmt::format("{} = {};\n", names[i], std::to_string(i)), buf);
|
||||
}
|
||||
endNested(buf, indent);
|
||||
return enum_name;
|
||||
}
|
||||
|
||||
String prepareAndGetProtobufTypeName(WriteBuffer & buf, const DataTypePtr & data_type, const String & column_name, size_t indent)
|
||||
{
|
||||
TypeIndex type_id = data_type->getTypeId();
|
||||
|
||||
switch (data_type->getTypeId())
|
||||
{
|
||||
case TypeIndex::Nullable:
|
||||
return prepareAndGetProtobufTypeName(buf, assert_cast<const DataTypeNullable &>(*data_type).getNestedType(), column_name, indent);
|
||||
case TypeIndex::LowCardinality:
|
||||
return prepareAndGetProtobufTypeName(buf, assert_cast<const DataTypeLowCardinality &>(*data_type).getDictionaryType(), column_name, indent);
|
||||
case TypeIndex::Array:
|
||||
return prepareArrayAndGetProtobufTypeName(buf, data_type, column_name, indent);
|
||||
case TypeIndex::Tuple:
|
||||
return prepareTupleAndGetProtobufTypeName(buf, data_type, column_name, indent);
|
||||
case TypeIndex::Map:
|
||||
return prepareMapAndGetProtobufTypeName(buf, data_type, column_name, indent);
|
||||
case TypeIndex::Enum8:
|
||||
return prepareEnumAndGetProtobufTypeName<Int8>(buf, data_type, column_name, indent);
|
||||
case TypeIndex::Enum16:
|
||||
return prepareEnumAndGetProtobufTypeName<Int16>(buf, data_type, column_name, indent);
|
||||
default:
|
||||
{
|
||||
if (isBool(data_type))
|
||||
return "bool";
|
||||
|
||||
auto it = protobuf_simple_type_names.find(type_id);
|
||||
if (it == protobuf_simple_type_names.end())
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS, "Type {} is not supported for conversion into Protobuf schema", data_type->getName());
|
||||
return it->second;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void StructureToProtobufSchema::writeSchema(WriteBuffer & buf, const String & message_name, const NamesAndTypesList & names_and_types_)
|
||||
{
|
||||
auto names_and_types = collectNested(names_and_types_);
|
||||
writeProtobufHeader(buf);
|
||||
startMessage(buf, getSchemaMessageName(message_name), 0);
|
||||
size_t field_index = 1;
|
||||
for (const auto & [column_name, data_type] : names_and_types)
|
||||
writeProtobufField(buf, data_type, column_name, field_index, 1);
|
||||
endNested(buf, 0);
|
||||
}
|
||||
|
||||
}
|
||||
16
src/Formats/StructureToProtobufSchema.h
Normal file
16
src/Formats/StructureToProtobufSchema.h
Normal file
@ -0,0 +1,16 @@
|
||||
#pragma once
|
||||
|
||||
#include <IO/WriteBuffer.h>
|
||||
#include <Core/NamesAndTypes.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
struct StructureToProtobufSchema
|
||||
{
|
||||
static constexpr auto name = "structureToProtobufSchema";
|
||||
|
||||
static void writeSchema(WriteBuffer & buf, const String & message_name, const NamesAndTypesList & names_and_types_);
|
||||
};
|
||||
|
||||
}
|
||||
@ -1040,13 +1040,21 @@ inline void convertFromTime<DataTypeDateTime>(DataTypeDateTime::FieldType & x, t
|
||||
/** Conversion of strings to numbers, dates, datetimes: through parsing.
|
||||
*/
|
||||
template <typename DataType>
|
||||
void parseImpl(typename DataType::FieldType & x, ReadBuffer & rb, const DateLUTImpl *)
|
||||
void parseImpl(typename DataType::FieldType & x, ReadBuffer & rb, const DateLUTImpl *, bool precise_float_parsing)
|
||||
{
|
||||
readText(x, rb);
|
||||
if constexpr (std::is_floating_point_v<typename DataType::FieldType>)
|
||||
{
|
||||
if (precise_float_parsing)
|
||||
readFloatTextPrecise(x, rb);
|
||||
else
|
||||
readFloatTextFast(x, rb);
|
||||
}
|
||||
else
|
||||
readText(x, rb);
|
||||
}
|
||||
|
||||
template <>
|
||||
inline void parseImpl<DataTypeDate>(DataTypeDate::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone)
|
||||
inline void parseImpl<DataTypeDate>(DataTypeDate::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone, bool)
|
||||
{
|
||||
DayNum tmp(0);
|
||||
readDateText(tmp, rb, *time_zone);
|
||||
@ -1054,7 +1062,7 @@ inline void parseImpl<DataTypeDate>(DataTypeDate::FieldType & x, ReadBuffer & rb
|
||||
}
|
||||
|
||||
template <>
|
||||
inline void parseImpl<DataTypeDate32>(DataTypeDate32::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone)
|
||||
inline void parseImpl<DataTypeDate32>(DataTypeDate32::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone, bool)
|
||||
{
|
||||
ExtendedDayNum tmp(0);
|
||||
readDateText(tmp, rb, *time_zone);
|
||||
@ -1064,7 +1072,7 @@ inline void parseImpl<DataTypeDate32>(DataTypeDate32::FieldType & x, ReadBuffer
|
||||
|
||||
// NOTE: no need of extra overload of DateTime64, since readDateTimeText64 has different signature and that case is explicitly handled in the calling code.
|
||||
template <>
|
||||
inline void parseImpl<DataTypeDateTime>(DataTypeDateTime::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone)
|
||||
inline void parseImpl<DataTypeDateTime>(DataTypeDateTime::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone, bool)
|
||||
{
|
||||
time_t time = 0;
|
||||
readDateTimeText(time, rb, *time_zone);
|
||||
@ -1072,7 +1080,7 @@ inline void parseImpl<DataTypeDateTime>(DataTypeDateTime::FieldType & x, ReadBuf
|
||||
}
|
||||
|
||||
template <>
|
||||
inline void parseImpl<DataTypeUUID>(DataTypeUUID::FieldType & x, ReadBuffer & rb, const DateLUTImpl *)
|
||||
inline void parseImpl<DataTypeUUID>(DataTypeUUID::FieldType & x, ReadBuffer & rb, const DateLUTImpl *, bool)
|
||||
{
|
||||
UUID tmp;
|
||||
readUUIDText(tmp, rb);
|
||||
@ -1080,7 +1088,7 @@ inline void parseImpl<DataTypeUUID>(DataTypeUUID::FieldType & x, ReadBuffer & rb
|
||||
}
|
||||
|
||||
template <>
|
||||
inline void parseImpl<DataTypeIPv4>(DataTypeIPv4::FieldType & x, ReadBuffer & rb, const DateLUTImpl *)
|
||||
inline void parseImpl<DataTypeIPv4>(DataTypeIPv4::FieldType & x, ReadBuffer & rb, const DateLUTImpl *, bool)
|
||||
{
|
||||
IPv4 tmp;
|
||||
readIPv4Text(tmp, rb);
|
||||
@ -1088,7 +1096,7 @@ inline void parseImpl<DataTypeIPv4>(DataTypeIPv4::FieldType & x, ReadBuffer & rb
|
||||
}
|
||||
|
||||
template <>
|
||||
inline void parseImpl<DataTypeIPv6>(DataTypeIPv6::FieldType & x, ReadBuffer & rb, const DateLUTImpl *)
|
||||
inline void parseImpl<DataTypeIPv6>(DataTypeIPv6::FieldType & x, ReadBuffer & rb, const DateLUTImpl *, bool)
|
||||
{
|
||||
IPv6 tmp;
|
||||
readIPv6Text(tmp, rb);
|
||||
@ -1096,16 +1104,21 @@ inline void parseImpl<DataTypeIPv6>(DataTypeIPv6::FieldType & x, ReadBuffer & rb
|
||||
}
|
||||
|
||||
template <typename DataType>
|
||||
bool tryParseImpl(typename DataType::FieldType & x, ReadBuffer & rb, const DateLUTImpl *)
|
||||
bool tryParseImpl(typename DataType::FieldType & x, ReadBuffer & rb, const DateLUTImpl *, bool precise_float_parsing)
|
||||
{
|
||||
if constexpr (std::is_floating_point_v<typename DataType::FieldType>)
|
||||
return tryReadFloatText(x, rb);
|
||||
{
|
||||
if (precise_float_parsing)
|
||||
return tryReadFloatTextPrecise(x, rb);
|
||||
else
|
||||
return tryReadFloatTextFast(x, rb);
|
||||
}
|
||||
else /*if constexpr (is_integer_v<typename DataType::FieldType>)*/
|
||||
return tryReadIntText(x, rb);
|
||||
}
|
||||
|
||||
template <>
|
||||
inline bool tryParseImpl<DataTypeDate>(DataTypeDate::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone)
|
||||
inline bool tryParseImpl<DataTypeDate>(DataTypeDate::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone, bool)
|
||||
{
|
||||
DayNum tmp(0);
|
||||
if (!tryReadDateText(tmp, rb, *time_zone))
|
||||
@ -1115,7 +1128,7 @@ inline bool tryParseImpl<DataTypeDate>(DataTypeDate::FieldType & x, ReadBuffer &
|
||||
}
|
||||
|
||||
template <>
|
||||
inline bool tryParseImpl<DataTypeDate32>(DataTypeDate32::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone)
|
||||
inline bool tryParseImpl<DataTypeDate32>(DataTypeDate32::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone, bool)
|
||||
{
|
||||
ExtendedDayNum tmp(0);
|
||||
if (!tryReadDateText(tmp, rb, *time_zone))
|
||||
@ -1125,7 +1138,7 @@ inline bool tryParseImpl<DataTypeDate32>(DataTypeDate32::FieldType & x, ReadBuff
|
||||
}
|
||||
|
||||
template <>
|
||||
inline bool tryParseImpl<DataTypeDateTime>(DataTypeDateTime::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone)
|
||||
inline bool tryParseImpl<DataTypeDateTime>(DataTypeDateTime::FieldType & x, ReadBuffer & rb, const DateLUTImpl * time_zone, bool)
|
||||
{
|
||||
time_t tmp = 0;
|
||||
if (!tryReadDateTimeText(tmp, rb, *time_zone))
|
||||
@ -1135,7 +1148,7 @@ inline bool tryParseImpl<DataTypeDateTime>(DataTypeDateTime::FieldType & x, Read
|
||||
}
|
||||
|
||||
template <>
|
||||
inline bool tryParseImpl<DataTypeUUID>(DataTypeUUID::FieldType & x, ReadBuffer & rb, const DateLUTImpl *)
|
||||
inline bool tryParseImpl<DataTypeUUID>(DataTypeUUID::FieldType & x, ReadBuffer & rb, const DateLUTImpl *, bool)
|
||||
{
|
||||
UUID tmp;
|
||||
if (!tryReadUUIDText(tmp, rb))
|
||||
@ -1146,7 +1159,7 @@ inline bool tryParseImpl<DataTypeUUID>(DataTypeUUID::FieldType & x, ReadBuffer &
|
||||
}
|
||||
|
||||
template <>
|
||||
inline bool tryParseImpl<DataTypeIPv4>(DataTypeIPv4::FieldType & x, ReadBuffer & rb, const DateLUTImpl *)
|
||||
inline bool tryParseImpl<DataTypeIPv4>(DataTypeIPv4::FieldType & x, ReadBuffer & rb, const DateLUTImpl *, bool)
|
||||
{
|
||||
IPv4 tmp;
|
||||
if (!tryReadIPv4Text(tmp, rb))
|
||||
@ -1157,7 +1170,7 @@ inline bool tryParseImpl<DataTypeIPv4>(DataTypeIPv4::FieldType & x, ReadBuffer &
|
||||
}
|
||||
|
||||
template <>
|
||||
inline bool tryParseImpl<DataTypeIPv6>(DataTypeIPv6::FieldType & x, ReadBuffer & rb, const DateLUTImpl *)
|
||||
inline bool tryParseImpl<DataTypeIPv6>(DataTypeIPv6::FieldType & x, ReadBuffer & rb, const DateLUTImpl *, bool)
|
||||
{
|
||||
IPv6 tmp;
|
||||
if (!tryReadIPv6Text(tmp, rb))
|
||||
@ -1336,6 +1349,16 @@ struct ConvertThroughParsing
|
||||
|
||||
size_t current_offset = 0;
|
||||
|
||||
bool precise_float_parsing = false;
|
||||
|
||||
if (DB::CurrentThread::isInitialized())
|
||||
{
|
||||
const DB::ContextPtr query_context = DB::CurrentThread::get().getQueryContext();
|
||||
|
||||
if (query_context)
|
||||
precise_float_parsing = query_context->getSettingsRef().precise_float_parsing;
|
||||
}
|
||||
|
||||
for (size_t i = 0; i < size; ++i)
|
||||
{
|
||||
size_t next_offset = std::is_same_v<FromDataType, DataTypeString> ? (*offsets)[i] : (current_offset + fixed_string_size);
|
||||
@ -1402,7 +1425,7 @@ struct ConvertThroughParsing
|
||||
}
|
||||
}
|
||||
|
||||
parseImpl<ToDataType>(vec_to[i], read_buffer, local_time_zone);
|
||||
parseImpl<ToDataType>(vec_to[i], read_buffer, local_time_zone, precise_float_parsing);
|
||||
} while (false);
|
||||
}
|
||||
}
|
||||
@ -1472,7 +1495,7 @@ struct ConvertThroughParsing
|
||||
}
|
||||
}
|
||||
|
||||
parsed = tryParseImpl<ToDataType>(vec_to[i], read_buffer, local_time_zone);
|
||||
parsed = tryParseImpl<ToDataType>(vec_to[i], read_buffer, local_time_zone, precise_float_parsing);
|
||||
} while (false);
|
||||
}
|
||||
}
|
||||
|
||||
@ -153,15 +153,10 @@ struct IntHash64Impl
|
||||
template<typename T, typename HashFunction>
|
||||
T combineHashesFunc(T t1, T t2)
|
||||
{
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
T tmp;
|
||||
reverseMemcpy(&tmp, &t1, sizeof(T));
|
||||
t1 = tmp;
|
||||
reverseMemcpy(&tmp, &t2, sizeof(T));
|
||||
t2 = tmp;
|
||||
#endif
|
||||
T hashes[] = {t1, t2};
|
||||
return HashFunction::apply(reinterpret_cast<const char *>(hashes), 2 * sizeof(T));
|
||||
transformEndianness<std::endian::little>(t1);
|
||||
transformEndianness<std::endian::little>(t2);
|
||||
const T hashes[] {t1, t2};
|
||||
return HashFunction::apply(reinterpret_cast<const char *>(hashes), sizeof(hashes));
|
||||
}
|
||||
|
||||
|
||||
@ -184,21 +179,14 @@ struct HalfMD5Impl
|
||||
MD5_Update(&ctx, reinterpret_cast<const unsigned char *>(begin), size);
|
||||
MD5_Final(buf.char_data, &ctx);
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
return buf.uint64_data; /// No need to flip bytes on big endian machines
|
||||
#else
|
||||
return std::byteswap(buf.uint64_data); /// Compatibility with existing code. Cast need for old poco AND macos where UInt64 != uint64_t
|
||||
#endif
|
||||
/// Compatibility with existing code. Cast need for old poco AND macos where UInt64 != uint64_t
|
||||
transformEndianness<std::endian::big>(buf.uint64_data);
|
||||
return buf.uint64_data;
|
||||
}
|
||||
|
||||
static UInt64 combineHashes(UInt64 h1, UInt64 h2)
|
||||
{
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
h1 = std::byteswap(h1);
|
||||
h2 = std::byteswap(h2);
|
||||
#endif
|
||||
UInt64 hashes[] = {h1, h2};
|
||||
return apply(reinterpret_cast<const char *>(hashes), 16);
|
||||
return combineHashesFunc<UInt64, HalfMD5Impl>(h1, h2);
|
||||
}
|
||||
|
||||
/// If true, it will use intHash32 or intHash64 to hash POD types. This behaviour is intended for better performance of some functions.
|
||||
@ -311,15 +299,8 @@ struct SipHash64Impl
|
||||
static constexpr auto name = "sipHash64";
|
||||
using ReturnType = UInt64;
|
||||
|
||||
static UInt64 apply(const char * begin, size_t size)
|
||||
{
|
||||
return sipHash64(begin, size);
|
||||
}
|
||||
|
||||
static UInt64 combineHashes(UInt64 h1, UInt64 h2)
|
||||
{
|
||||
return combineHashesFunc<UInt64, SipHash64Impl>(h1, h2);
|
||||
}
|
||||
static UInt64 apply(const char * begin, size_t size) { return sipHash64(begin, size); }
|
||||
static UInt64 combineHashes(UInt64 h1, UInt64 h2) { return combineHashesFunc<UInt64, SipHash64Impl>(h1, h2); }
|
||||
|
||||
static constexpr bool use_int_hash_for_pods = false;
|
||||
};
|
||||
@ -336,12 +317,10 @@ struct SipHash64KeyedImpl
|
||||
|
||||
static UInt64 combineHashesKeyed(const Key & key, UInt64 h1, UInt64 h2)
|
||||
{
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
h1 = std::byteswap(h1);
|
||||
h2 = std::byteswap(h2);
|
||||
#endif
|
||||
UInt64 hashes[] = {h1, h2};
|
||||
return applyKeyed(key, reinterpret_cast<const char *>(hashes), 2 * sizeof(UInt64));
|
||||
transformEndianness<std::endian::little>(h1);
|
||||
transformEndianness<std::endian::little>(h2);
|
||||
const UInt64 hashes[]{h1, h2};
|
||||
return applyKeyed(key, reinterpret_cast<const char *>(hashes), sizeof(hashes));
|
||||
}
|
||||
|
||||
static constexpr bool use_int_hash_for_pods = false;
|
||||
@ -353,15 +332,8 @@ struct SipHash128Impl
|
||||
|
||||
using ReturnType = UInt128;
|
||||
|
||||
static UInt128 combineHashes(UInt128 h1, UInt128 h2)
|
||||
{
|
||||
return combineHashesFunc<UInt128, SipHash128Impl>(h1, h2);
|
||||
}
|
||||
|
||||
static UInt128 apply(const char * data, const size_t size)
|
||||
{
|
||||
return sipHash128(data, size);
|
||||
}
|
||||
static UInt128 combineHashes(UInt128 h1, UInt128 h2) { return combineHashesFunc<UInt128, SipHash128Impl>(h1, h2); }
|
||||
static UInt128 apply(const char * data, const size_t size) { return sipHash128(data, size); }
|
||||
|
||||
static constexpr bool use_int_hash_for_pods = false;
|
||||
};
|
||||
@ -378,15 +350,10 @@ struct SipHash128KeyedImpl
|
||||
|
||||
static UInt128 combineHashesKeyed(const Key & key, UInt128 h1, UInt128 h2)
|
||||
{
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
UInt128 tmp;
|
||||
reverseMemcpy(&tmp, &h1, sizeof(UInt128));
|
||||
h1 = tmp;
|
||||
reverseMemcpy(&tmp, &h2, sizeof(UInt128));
|
||||
h2 = tmp;
|
||||
#endif
|
||||
UInt128 hashes[] = {h1, h2};
|
||||
return applyKeyed(key, reinterpret_cast<const char *>(hashes), 2 * sizeof(UInt128));
|
||||
transformEndianness<std::endian::little>(h1);
|
||||
transformEndianness<std::endian::little>(h2);
|
||||
const UInt128 hashes[]{h1, h2};
|
||||
return applyKeyed(key, reinterpret_cast<const char *>(hashes), sizeof(hashes));
|
||||
}
|
||||
|
||||
static constexpr bool use_int_hash_for_pods = false;
|
||||
@ -531,10 +498,7 @@ struct MurmurHash3Impl64
|
||||
return h[0] ^ h[1];
|
||||
}
|
||||
|
||||
static UInt64 combineHashes(UInt64 h1, UInt64 h2)
|
||||
{
|
||||
return IntHash64Impl::apply(h1) ^ h2;
|
||||
}
|
||||
static UInt64 combineHashes(UInt64 h1, UInt64 h2) { return IntHash64Impl::apply(h1) ^ h2; }
|
||||
|
||||
static constexpr bool use_int_hash_for_pods = false;
|
||||
};
|
||||
@ -552,10 +516,7 @@ struct MurmurHash3Impl128
|
||||
return *reinterpret_cast<UInt128 *>(bytes);
|
||||
}
|
||||
|
||||
static UInt128 combineHashes(UInt128 h1, UInt128 h2)
|
||||
{
|
||||
return combineHashesFunc<UInt128, MurmurHash3Impl128>(h1, h2);
|
||||
}
|
||||
static UInt128 combineHashes(UInt128 h1, UInt128 h2) { return combineHashesFunc<UInt128, MurmurHash3Impl128>(h1, h2); }
|
||||
|
||||
static constexpr bool use_int_hash_for_pods = false;
|
||||
};
|
||||
@ -1040,11 +1001,10 @@ private:
|
||||
if (const ColVecType * col_from = checkAndGetColumn<ColVecType>(column))
|
||||
{
|
||||
const typename ColVecType::Container & vec_from = col_from->getData();
|
||||
size_t size = vec_from.size();
|
||||
const size_t size = vec_from.size();
|
||||
for (size_t i = 0; i < size; ++i)
|
||||
{
|
||||
ToType hash;
|
||||
|
||||
if constexpr (Impl::use_int_hash_for_pods)
|
||||
{
|
||||
if constexpr (std::is_same_v<ToType, UInt64>)
|
||||
@ -1058,13 +1018,8 @@ private:
|
||||
hash = JavaHashImpl::apply(vec_from[i]);
|
||||
else
|
||||
{
|
||||
FromType value = vec_from[i];
|
||||
if constexpr (std::endian::native == std::endian::big)
|
||||
{
|
||||
FromType value_reversed;
|
||||
reverseMemcpy(&value_reversed, &value, sizeof(value));
|
||||
value = value_reversed;
|
||||
}
|
||||
auto value = vec_from[i];
|
||||
transformEndianness<std::endian::little>(value);
|
||||
hash = apply(key, reinterpret_cast<const char *>(&value), sizeof(value));
|
||||
}
|
||||
}
|
||||
@ -1078,8 +1033,8 @@ private:
|
||||
else if (auto col_from_const = checkAndGetColumnConst<ColVecType>(column))
|
||||
{
|
||||
auto value = col_from_const->template getValue<FromType>();
|
||||
ToType hash;
|
||||
|
||||
ToType hash;
|
||||
if constexpr (Impl::use_int_hash_for_pods)
|
||||
{
|
||||
if constexpr (std::is_same_v<ToType, UInt64>)
|
||||
@ -1093,17 +1048,12 @@ private:
|
||||
hash = JavaHashImpl::apply(value);
|
||||
else
|
||||
{
|
||||
if constexpr (std::endian::native == std::endian::big)
|
||||
{
|
||||
FromType value_reversed;
|
||||
reverseMemcpy(&value_reversed, &value, sizeof(value));
|
||||
value = value_reversed;
|
||||
}
|
||||
transformEndianness<std::endian::little>(value);
|
||||
hash = apply(key, reinterpret_cast<const char *>(&value), sizeof(value));
|
||||
}
|
||||
}
|
||||
|
||||
size_t size = vec_to.size();
|
||||
const size_t size = vec_to.size();
|
||||
if constexpr (first)
|
||||
vec_to.assign(size, hash);
|
||||
else
|
||||
@ -1120,6 +1070,16 @@ private:
|
||||
{
|
||||
using ColVecType = ColumnVectorOrDecimal<FromType>;
|
||||
|
||||
static const auto to_little_endian = [](auto & value)
|
||||
{
|
||||
// IPv6 addresses are parsed into four 32-bit components in big-endian ordering on both platforms, so no change is necessary.
|
||||
// Reference: `parseIPv6orIPv4` in src/Common/formatIPv6.h.
|
||||
if constexpr (std::endian::native == std::endian::big && std::is_same_v<std::remove_reference_t<decltype(value)>, IPv6>)
|
||||
return;
|
||||
|
||||
transformEndianness<std::endian::little>(value);
|
||||
};
|
||||
|
||||
if (const ColVecType * col_from = checkAndGetColumn<ColVecType>(column))
|
||||
{
|
||||
const typename ColVecType::Container & vec_from = col_from->getData();
|
||||
@ -1131,9 +1091,10 @@ private:
|
||||
hash = apply(key, reinterpret_cast<const char *>(&vec_from[i]), sizeof(vec_from[i]));
|
||||
else
|
||||
{
|
||||
char tmp_buffer[sizeof(vec_from[i])];
|
||||
reverseMemcpy(tmp_buffer, &vec_from[i], sizeof(vec_from[i]));
|
||||
hash = apply(key, reinterpret_cast<const char *>(tmp_buffer), sizeof(vec_from[i]));
|
||||
auto value = vec_from[i];
|
||||
to_little_endian(value);
|
||||
|
||||
hash = apply(key, reinterpret_cast<const char *>(&value), sizeof(value));
|
||||
}
|
||||
if constexpr (first)
|
||||
vec_to[i] = hash;
|
||||
@ -1144,17 +1105,10 @@ private:
|
||||
else if (auto col_from_const = checkAndGetColumnConst<ColVecType>(column))
|
||||
{
|
||||
auto value = col_from_const->template getValue<FromType>();
|
||||
to_little_endian(value);
|
||||
|
||||
ToType hash;
|
||||
if constexpr (std::endian::native == std::endian::little)
|
||||
hash = apply(key, reinterpret_cast<const char *>(&value), sizeof(value));
|
||||
else
|
||||
{
|
||||
char tmp_buffer[sizeof(value)];
|
||||
reverseMemcpy(tmp_buffer, &value, sizeof(value));
|
||||
hash = apply(key, reinterpret_cast<const char *>(tmp_buffer), sizeof(value));
|
||||
}
|
||||
size_t size = vec_to.size();
|
||||
const auto hash = apply(key, reinterpret_cast<const char *>(&value), sizeof(value));
|
||||
const size_t size = vec_to.size();
|
||||
if constexpr (first)
|
||||
vec_to.assign(size, hash);
|
||||
else
|
||||
@ -1423,6 +1377,9 @@ public:
|
||||
|
||||
if constexpr (std::is_same_v<ToType, UInt128>) /// backward-compatible
|
||||
{
|
||||
if (std::endian::native == std::endian::big)
|
||||
std::ranges::for_each(col_to->getData(), transformEndianness<std::endian::little, ToType>);
|
||||
|
||||
auto col_to_fixed_string = ColumnFixedString::create(sizeof(UInt128));
|
||||
const auto & data = col_to->getData();
|
||||
auto & chars = col_to_fixed_string->getChars();
|
||||
@ -1676,21 +1633,8 @@ struct ImplWyHash64
|
||||
static constexpr auto name = "wyHash64";
|
||||
using ReturnType = UInt64;
|
||||
|
||||
static UInt64 apply(const char * s, const size_t len)
|
||||
{
|
||||
return wyhash(s, len, 0, _wyp);
|
||||
}
|
||||
static UInt64 combineHashes(UInt64 h1, UInt64 h2)
|
||||
{
|
||||
union
|
||||
{
|
||||
UInt64 u64[2];
|
||||
char chars[16];
|
||||
};
|
||||
u64[0] = h1;
|
||||
u64[1] = h2;
|
||||
return apply(chars, 16);
|
||||
}
|
||||
static UInt64 apply(const char * s, const size_t len) { return wyhash(s, len, 0, _wyp); }
|
||||
static UInt64 combineHashes(UInt64 h1, UInt64 h2) { return combineHashesFunc<UInt64, ImplWyHash64>(h1, h2); }
|
||||
|
||||
static constexpr bool use_int_hash_for_pods = false;
|
||||
};
|
||||
|
||||
@ -510,11 +510,12 @@ ColumnPtr FunctionArrayIntersect::execute(const UnpackedArrays & arrays, Mutable
|
||||
map.clear();
|
||||
|
||||
bool all_has_nullable = all_nullable;
|
||||
bool current_has_nullable = false;
|
||||
|
||||
for (size_t arg_num = 0; arg_num < args; ++arg_num)
|
||||
{
|
||||
const auto & arg = arrays.args[arg_num];
|
||||
bool current_has_nullable = false;
|
||||
current_has_nullable = false;
|
||||
|
||||
size_t off;
|
||||
// const array has only one row
|
||||
@ -549,44 +550,93 @@ ColumnPtr FunctionArrayIntersect::execute(const UnpackedArrays & arrays, Mutable
|
||||
}
|
||||
}
|
||||
|
||||
prev_off[arg_num] = off;
|
||||
if (arg.is_const)
|
||||
prev_off[arg_num] = 0;
|
||||
|
||||
// We update offsets for all the arrays except the first one. Offsets for the first array would be updated later.
|
||||
// It is needed to iterate the first array again so that the elements in the result would have fixed order.
|
||||
if (arg_num)
|
||||
{
|
||||
prev_off[arg_num] = off;
|
||||
if (arg.is_const)
|
||||
prev_off[arg_num] = 0;
|
||||
}
|
||||
if (!current_has_nullable)
|
||||
all_has_nullable = false;
|
||||
}
|
||||
|
||||
if (all_has_nullable)
|
||||
{
|
||||
++result_offset;
|
||||
result_data.insertDefault();
|
||||
null_map.push_back(1);
|
||||
}
|
||||
// We have NULL in output only once if it should be there
|
||||
bool null_added = false;
|
||||
const auto & arg = arrays.args[0];
|
||||
size_t off;
|
||||
// const array has only one row
|
||||
if (arg.is_const)
|
||||
off = (*arg.offsets)[0];
|
||||
else
|
||||
off = (*arg.offsets)[row];
|
||||
|
||||
for (const auto & pair : map)
|
||||
for (auto i : collections::range(prev_off[0], off))
|
||||
{
|
||||
if (pair.getMapped() == args)
|
||||
all_has_nullable = all_nullable;
|
||||
typename Map::LookupResult pair = nullptr;
|
||||
|
||||
if (arg.null_map && (*arg.null_map)[i])
|
||||
{
|
||||
current_has_nullable = true;
|
||||
if (all_has_nullable && !null_added)
|
||||
{
|
||||
++result_offset;
|
||||
result_data.insertDefault();
|
||||
null_map.push_back(1);
|
||||
null_added = true;
|
||||
}
|
||||
if (null_added)
|
||||
continue;
|
||||
}
|
||||
else if constexpr (is_numeric_column)
|
||||
{
|
||||
pair = map.find(columns[0]->getElement(i));
|
||||
}
|
||||
else if constexpr (std::is_same_v<ColumnType, ColumnString> || std::is_same_v<ColumnType, ColumnFixedString>)
|
||||
pair = map.find(columns[0]->getDataAt(i));
|
||||
else
|
||||
{
|
||||
const char * data = nullptr;
|
||||
pair = map.find(columns[0]->serializeValueIntoArena(i, arena, data));
|
||||
}
|
||||
prev_off[0] = off;
|
||||
if (arg.is_const)
|
||||
prev_off[0] = 0;
|
||||
|
||||
if (!current_has_nullable)
|
||||
all_has_nullable = false;
|
||||
|
||||
if (pair && pair->getMapped() == args)
|
||||
{
|
||||
// We increase pair->getMapped() here to not skip duplicate values from the first array.
|
||||
++pair->getMapped();
|
||||
++result_offset;
|
||||
if constexpr (is_numeric_column)
|
||||
result_data.insertValue(pair.getKey());
|
||||
{
|
||||
result_data.insertValue(pair->getKey());
|
||||
}
|
||||
else if constexpr (std::is_same_v<ColumnType, ColumnString> || std::is_same_v<ColumnType, ColumnFixedString>)
|
||||
result_data.insertData(pair.getKey().data, pair.getKey().size);
|
||||
{
|
||||
result_data.insertData(pair->getKey().data, pair->getKey().size);
|
||||
}
|
||||
else
|
||||
result_data.deserializeAndInsertFromArena(pair.getKey().data);
|
||||
|
||||
{
|
||||
result_data.deserializeAndInsertFromArena(pair->getKey().data);
|
||||
}
|
||||
if (all_nullable)
|
||||
null_map.push_back(0);
|
||||
}
|
||||
}
|
||||
result_offsets.getElement(row) = result_offset;
|
||||
}
|
||||
|
||||
}
|
||||
ColumnPtr result_column = std::move(result_data_ptr);
|
||||
if (all_nullable)
|
||||
result_column = ColumnNullable::create(result_column, std::move(null_map_column));
|
||||
return ColumnArray::create(result_column, std::move(result_offsets_ptr));
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
145
src/Functions/structureToFormatSchema.cpp
Normal file
145
src/Functions/structureToFormatSchema.cpp
Normal file
@ -0,0 +1,145 @@
|
||||
#include <Columns/ColumnString.h>
|
||||
#include <DataTypes/DataTypeString.h>
|
||||
#include <DataTypes/DataTypeEnum.h>
|
||||
#include <Functions/FunctionFactory.h>
|
||||
#include <Functions/IFunction.h>
|
||||
#include <Interpreters/parseColumnsListForTableFunction.h>
|
||||
#include <Interpreters/Context.h>
|
||||
#include <IO/WriteBufferFromVector.h>
|
||||
#include <Formats/StructureToCapnProtoSchema.h>
|
||||
#include <Formats/StructureToProtobufSchema.h>
|
||||
|
||||
#include <Common/randomSeed.h>
|
||||
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
namespace ErrorCodes
|
||||
{
|
||||
extern const int NUMBER_OF_ARGUMENTS_DOESNT_MATCH;
|
||||
extern const int ILLEGAL_TYPE_OF_ARGUMENT;
|
||||
}
|
||||
|
||||
template <class Impl>
|
||||
class FunctionStructureToFormatSchema : public IFunction
|
||||
{
|
||||
public:
|
||||
|
||||
static constexpr auto name = Impl::name;
|
||||
explicit FunctionStructureToFormatSchema(ContextPtr context_) : context(std::move(context_))
|
||||
{
|
||||
}
|
||||
|
||||
static FunctionPtr create(ContextPtr ctx)
|
||||
{
|
||||
return std::make_shared<FunctionStructureToFormatSchema>(std::move(ctx));
|
||||
}
|
||||
|
||||
String getName() const override { return name; }
|
||||
|
||||
size_t getNumberOfArguments() const override { return 0; }
|
||||
bool isVariadic() const override { return true; }
|
||||
|
||||
bool isSuitableForShortCircuitArgumentsExecution(const DataTypesWithConstInfo & /*arguments*/) const override { return false; }
|
||||
ColumnNumbers getArgumentsThatAreAlwaysConstant() const override { return {0, 1}; }
|
||||
bool useDefaultImplementationForConstants() const override { return false; }
|
||||
bool useDefaultImplementationForNulls() const override { return false; }
|
||||
|
||||
DataTypePtr getReturnTypeImpl(const DataTypes & arguments) const override
|
||||
{
|
||||
if (arguments.empty() || arguments.size() > 2)
|
||||
throw Exception(
|
||||
ErrorCodes::NUMBER_OF_ARGUMENTS_DOESNT_MATCH,
|
||||
"Number of arguments for function {} doesn't match: passed {}, expected 1 or 2",
|
||||
getName(), arguments.size());
|
||||
|
||||
if (!isString(arguments[0]))
|
||||
{
|
||||
throw Exception(
|
||||
ErrorCodes::ILLEGAL_TYPE_OF_ARGUMENT,
|
||||
"Illegal type {} of the first argument of function {}, expected constant string",
|
||||
arguments[0]->getName(),
|
||||
getName());
|
||||
}
|
||||
|
||||
if (arguments.size() > 1 && !isString(arguments[1]))
|
||||
{
|
||||
throw Exception(
|
||||
ErrorCodes::ILLEGAL_TYPE_OF_ARGUMENT,
|
||||
"Illegal type {} of the second argument of function {}, expected constant string",
|
||||
arguments[1]->getName(),
|
||||
getName());
|
||||
}
|
||||
|
||||
return std::make_shared<DataTypeString>();
|
||||
}
|
||||
|
||||
ColumnPtr executeImpl(const ColumnsWithTypeAndName & arguments, const DataTypePtr &, size_t input_rows_count) const override
|
||||
{
|
||||
if (arguments.empty() || arguments.size() > 2)
|
||||
throw Exception(
|
||||
ErrorCodes::NUMBER_OF_ARGUMENTS_DOESNT_MATCH,
|
||||
"Number of arguments for function {} doesn't match: passed {}, expected 1 or 2",
|
||||
getName(), arguments.size());
|
||||
|
||||
String structure = arguments[0].column->getDataAt(0).toString();
|
||||
String message_name = arguments.size() == 2 ? arguments[1].column->getDataAt(0).toString() : "Message";
|
||||
auto columns_list = parseColumnsListFromString(structure, context);
|
||||
auto col_res = ColumnString::create();
|
||||
auto & data = assert_cast<ColumnString &>(*col_res).getChars();
|
||||
WriteBufferFromVector buf(data);
|
||||
Impl::writeSchema(buf, message_name, columns_list.getAll());
|
||||
buf.finalize();
|
||||
auto & offsets = assert_cast<ColumnString &>(*col_res).getOffsets();
|
||||
offsets.push_back(data.size());
|
||||
return ColumnConst::create(std::move(col_res), input_rows_count);
|
||||
}
|
||||
|
||||
private:
|
||||
ContextPtr context;
|
||||
};
|
||||
|
||||
|
||||
REGISTER_FUNCTION(StructureToCapnProtoSchema)
|
||||
{
|
||||
factory.registerFunction<FunctionStructureToFormatSchema<StructureToCapnProtoSchema>>(FunctionDocumentation
|
||||
{
|
||||
.description=R"(
|
||||
Function that converts ClickHouse table structure to CapnProto format schema
|
||||
)",
|
||||
.examples{
|
||||
{"random", "SELECT structureToCapnProtoSchema('s String, x UInt32', 'MessageName') format TSVRaw", "struct MessageName\n"
|
||||
"{\n"
|
||||
" s @0 : Data;\n"
|
||||
" x @1 : UInt32;\n"
|
||||
"}"},
|
||||
},
|
||||
.categories{"Other"}
|
||||
},
|
||||
FunctionFactory::CaseSensitive);
|
||||
}
|
||||
|
||||
|
||||
REGISTER_FUNCTION(StructureToProtobufSchema)
|
||||
{
|
||||
factory.registerFunction<FunctionStructureToFormatSchema<StructureToProtobufSchema>>(FunctionDocumentation
|
||||
{
|
||||
.description=R"(
|
||||
Function that converts ClickHouse table structure to Protobuf format schema
|
||||
)",
|
||||
.examples{
|
||||
{"random", "SELECT structureToCapnProtoSchema('s String, x UInt32', 'MessageName') format TSVRaw", "syntax = \"proto3\";\n"
|
||||
"\n"
|
||||
"message MessageName\n"
|
||||
"{\n"
|
||||
" bytes s = 1;\n"
|
||||
" uint32 x = 2;\n"
|
||||
"}"},
|
||||
},
|
||||
.categories{"Other"}
|
||||
},
|
||||
FunctionFactory::CaseSensitive);
|
||||
}
|
||||
|
||||
}
|
||||
@ -529,6 +529,11 @@ void tryReadIntTextUnsafe(T & x, ReadBuffer & buf)
|
||||
template <typename T> void readFloatText(T & x, ReadBuffer & in);
|
||||
template <typename T> bool tryReadFloatText(T & x, ReadBuffer & in);
|
||||
|
||||
template <typename T> void readFloatTextPrecise(T & x, ReadBuffer & in);
|
||||
template <typename T> bool tryReadFloatTextPrecise(T & x, ReadBuffer & in);
|
||||
template <typename T> void readFloatTextFast(T & x, ReadBuffer & in);
|
||||
template <typename T> bool tryReadFloatTextFast(T & x, ReadBuffer & in);
|
||||
|
||||
|
||||
/// simple: all until '\n' or '\t'
|
||||
void readString(String & s, ReadBuffer & buf);
|
||||
|
||||
@ -16,6 +16,7 @@ namespace ActionLocks
|
||||
extern const StorageActionBlockType DistributedSend = 5;
|
||||
extern const StorageActionBlockType PartsTTLMerge = 6;
|
||||
extern const StorageActionBlockType PartsMove = 7;
|
||||
extern const StorageActionBlockType PullReplicationLog = 8;
|
||||
}
|
||||
|
||||
|
||||
|
||||
@ -984,6 +984,8 @@ void Aggregator::executeOnBlockSmall(
|
||||
}
|
||||
|
||||
executeImpl(result, row_begin, row_end, key_columns, aggregate_instructions);
|
||||
|
||||
CurrentMemoryTracker::check();
|
||||
}
|
||||
|
||||
void Aggregator::mergeOnBlockSmall(
|
||||
@ -1023,6 +1025,8 @@ void Aggregator::mergeOnBlockSmall(
|
||||
#undef M
|
||||
else
|
||||
throw Exception(ErrorCodes::UNKNOWN_AGGREGATED_DATA_VARIANT, "Unknown aggregated data variant.");
|
||||
|
||||
CurrentMemoryTracker::check();
|
||||
}
|
||||
|
||||
void Aggregator::executeImpl(
|
||||
@ -1383,11 +1387,8 @@ void NO_INLINE Aggregator::executeWithoutKeyImpl(
|
||||
}
|
||||
|
||||
|
||||
void NO_INLINE Aggregator::executeOnIntervalWithoutKeyImpl(
|
||||
AggregatedDataVariants & data_variants,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
AggregateFunctionInstruction * aggregate_instructions) const
|
||||
void NO_INLINE Aggregator::executeOnIntervalWithoutKey(
|
||||
AggregatedDataVariants & data_variants, size_t row_begin, size_t row_end, AggregateFunctionInstruction * aggregate_instructions) const
|
||||
{
|
||||
/// `data_variants` will destroy the states of aggregate functions in the destructor
|
||||
data_variants.aggregator = this;
|
||||
@ -1414,7 +1415,7 @@ void NO_INLINE Aggregator::executeOnIntervalWithoutKeyImpl(
|
||||
}
|
||||
}
|
||||
|
||||
void NO_INLINE Aggregator::mergeOnIntervalWithoutKeyImpl(
|
||||
void NO_INLINE Aggregator::mergeOnIntervalWithoutKey(
|
||||
AggregatedDataVariants & data_variants,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
@ -2921,6 +2922,7 @@ void NO_INLINE Aggregator::mergeBlockWithoutKeyStreamsImpl(
|
||||
AggregateColumnsConstData aggregate_columns = params.makeAggregateColumnsData(block);
|
||||
mergeWithoutKeyStreamsImpl(result, 0, block.rows(), aggregate_columns);
|
||||
}
|
||||
|
||||
void NO_INLINE Aggregator::mergeWithoutKeyStreamsImpl(
|
||||
AggregatedDataVariants & result,
|
||||
size_t row_begin,
|
||||
@ -3139,6 +3141,8 @@ void Aggregator::mergeBlocks(BucketToBlocks bucket_to_blocks, AggregatedDataVari
|
||||
|
||||
LOG_TRACE(log, "Merged partially aggregated single-level data.");
|
||||
}
|
||||
|
||||
CurrentMemoryTracker::check();
|
||||
}
|
||||
|
||||
|
||||
|
||||
@ -1118,9 +1118,55 @@ public:
|
||||
AggregateColumns & aggregate_columns, /// Passed to not create them anew for each block
|
||||
bool & no_more_keys) const;
|
||||
|
||||
/** This array serves two purposes.
|
||||
*
|
||||
* Function arguments are collected side by side, and they do not need to be collected from different places. Also the array is made zero-terminated.
|
||||
* The inner loop (for the case without_key) is almost twice as compact; performance gain of about 30%.
|
||||
*/
|
||||
struct AggregateFunctionInstruction
|
||||
{
|
||||
const IAggregateFunction * that{};
|
||||
size_t state_offset{};
|
||||
const IColumn ** arguments{};
|
||||
const IAggregateFunction * batch_that{};
|
||||
const IColumn ** batch_arguments{};
|
||||
const UInt64 * offsets{};
|
||||
bool has_sparse_arguments = false;
|
||||
};
|
||||
|
||||
/// Used for optimize_aggregation_in_order:
|
||||
/// - No two-level aggregation
|
||||
/// - No external aggregation
|
||||
/// - No without_key support (it is implemented using executeOnIntervalWithoutKey())
|
||||
void executeOnBlockSmall(
|
||||
AggregatedDataVariants & result,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
ColumnRawPtrs & key_columns,
|
||||
AggregateFunctionInstruction * aggregate_instructions) const;
|
||||
|
||||
void executeOnIntervalWithoutKey(
|
||||
AggregatedDataVariants & data_variants,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
AggregateFunctionInstruction * aggregate_instructions) const;
|
||||
|
||||
/// Used for aggregate projection.
|
||||
bool mergeOnBlock(Block block, AggregatedDataVariants & result, bool & no_more_keys) const;
|
||||
|
||||
void mergeOnBlockSmall(
|
||||
AggregatedDataVariants & result,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
const AggregateColumnsConstData & aggregate_columns_data,
|
||||
const ColumnRawPtrs & key_columns) const;
|
||||
|
||||
void mergeOnIntervalWithoutKey(
|
||||
AggregatedDataVariants & data_variants,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
const AggregateColumnsConstData & aggregate_columns_data) const;
|
||||
|
||||
/** Convert the aggregation data structure into a block.
|
||||
* If overflow_row = true, then aggregates for rows that are not included in max_rows_to_group_by are put in the first block.
|
||||
*
|
||||
@ -1178,22 +1224,6 @@ private:
|
||||
|
||||
AggregateFunctionsPlainPtrs aggregate_functions;
|
||||
|
||||
/** This array serves two purposes.
|
||||
*
|
||||
* Function arguments are collected side by side, and they do not need to be collected from different places. Also the array is made zero-terminated.
|
||||
* The inner loop (for the case without_key) is almost twice as compact; performance gain of about 30%.
|
||||
*/
|
||||
struct AggregateFunctionInstruction
|
||||
{
|
||||
const IAggregateFunction * that{};
|
||||
size_t state_offset{};
|
||||
const IColumn ** arguments{};
|
||||
const IAggregateFunction * batch_that{};
|
||||
const IColumn ** batch_arguments{};
|
||||
const UInt64 * offsets{};
|
||||
bool has_sparse_arguments = false;
|
||||
};
|
||||
|
||||
using AggregateFunctionInstructions = std::vector<AggregateFunctionInstruction>;
|
||||
using NestedColumnsHolder = std::vector<std::vector<const IColumn *>>;
|
||||
|
||||
@ -1239,26 +1269,6 @@ private:
|
||||
*/
|
||||
void destroyAllAggregateStates(AggregatedDataVariants & result) const;
|
||||
|
||||
|
||||
/// Used for optimize_aggregation_in_order:
|
||||
/// - No two-level aggregation
|
||||
/// - No external aggregation
|
||||
/// - No without_key support (it is implemented using executeOnIntervalWithoutKeyImpl())
|
||||
void executeOnBlockSmall(
|
||||
AggregatedDataVariants & result,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
ColumnRawPtrs & key_columns,
|
||||
AggregateFunctionInstruction * aggregate_instructions) const;
|
||||
void mergeOnBlockSmall(
|
||||
AggregatedDataVariants & result,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
const AggregateColumnsConstData & aggregate_columns_data,
|
||||
const ColumnRawPtrs & key_columns) const;
|
||||
|
||||
void mergeOnBlockImpl(Block block, AggregatedDataVariants & result, bool no_more_keys) const;
|
||||
|
||||
void executeImpl(
|
||||
AggregatedDataVariants & result,
|
||||
size_t row_begin,
|
||||
@ -1300,17 +1310,6 @@ private:
|
||||
AggregateFunctionInstruction * aggregate_instructions,
|
||||
Arena * arena) const;
|
||||
|
||||
void executeOnIntervalWithoutKeyImpl(
|
||||
AggregatedDataVariants & data_variants,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
AggregateFunctionInstruction * aggregate_instructions) const;
|
||||
void mergeOnIntervalWithoutKeyImpl(
|
||||
AggregatedDataVariants & data_variants,
|
||||
size_t row_begin,
|
||||
size_t row_end,
|
||||
const AggregateColumnsConstData & aggregate_columns_data) const;
|
||||
|
||||
template <typename Method>
|
||||
void writeToTemporaryFileImpl(
|
||||
AggregatedDataVariants & data_variants,
|
||||
|
||||
@ -806,6 +806,13 @@ bool FileCache::tryReserve(FileSegment & file_segment, const size_t size)
|
||||
return true;
|
||||
}
|
||||
|
||||
void FileCache::removeKey(const Key & key)
|
||||
{
|
||||
assertInitialized();
|
||||
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::THROW);
|
||||
locked_key->removeAll();
|
||||
}
|
||||
|
||||
void FileCache::removeKeyIfExists(const Key & key)
|
||||
{
|
||||
assertInitialized();
|
||||
@ -818,7 +825,14 @@ void FileCache::removeKeyIfExists(const Key & key)
|
||||
/// But if we have multiple replicated zero-copy tables on the same server
|
||||
/// it became possible to start removing something from cache when it is used
|
||||
/// by other "zero-copy" tables. That is why it's not an error.
|
||||
locked_key->removeAllReleasable();
|
||||
locked_key->removeAll(/* if_releasable */true);
|
||||
}
|
||||
|
||||
void FileCache::removeFileSegment(const Key & key, size_t offset)
|
||||
{
|
||||
assertInitialized();
|
||||
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::THROW);
|
||||
locked_key->removeFileSegment(offset);
|
||||
}
|
||||
|
||||
void FileCache::removePathIfExists(const String & path)
|
||||
@ -830,22 +844,12 @@ void FileCache::removeAllReleasable()
|
||||
{
|
||||
assertInitialized();
|
||||
|
||||
auto lock = lockCache();
|
||||
|
||||
main_priority->iterate([&](LockedKey & locked_key, const FileSegmentMetadataPtr & segment_metadata)
|
||||
{
|
||||
if (segment_metadata->releasable())
|
||||
{
|
||||
auto file_segment = segment_metadata->file_segment;
|
||||
locked_key.removeFileSegment(file_segment->offset(), file_segment->lock());
|
||||
return PriorityIterationResult::REMOVE_AND_CONTINUE;
|
||||
}
|
||||
return PriorityIterationResult::CONTINUE;
|
||||
}, lock);
|
||||
metadata.iterate([](LockedKey & locked_key) { locked_key.removeAll(/* if_releasable */true); });
|
||||
|
||||
if (stash)
|
||||
{
|
||||
/// Remove all access information.
|
||||
auto lock = lockCache();
|
||||
stash->records.clear();
|
||||
stash->queue->removeAll(lock);
|
||||
}
|
||||
@ -951,7 +955,7 @@ void FileCache::loadMetadataForKeys(const fs::path & keys_dir)
|
||||
return;
|
||||
}
|
||||
|
||||
size_t offset = 0, size = 0;
|
||||
UInt64 offset = 0, size = 0;
|
||||
for (; key_it != fs::directory_iterator(); key_it++)
|
||||
{
|
||||
const fs::path key_directory = key_it->path();
|
||||
@ -972,7 +976,7 @@ void FileCache::loadMetadataForKeys(const fs::path & keys_dir)
|
||||
continue;
|
||||
}
|
||||
|
||||
const auto key = Key(unhexUInt<UInt128>(key_directory.filename().string().data()));
|
||||
const auto key = Key::fromKeyString(key_directory.filename().string());
|
||||
auto key_metadata = metadata.getKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::CREATE_EMPTY, /* is_initial_load */true);
|
||||
|
||||
const size_t size_limit = main_priority->getSizeLimit();
|
||||
@ -1124,7 +1128,7 @@ FileSegmentsHolderPtr FileCache::getSnapshot()
|
||||
FileSegmentsHolderPtr FileCache::getSnapshot(const Key & key)
|
||||
{
|
||||
FileSegments file_segments;
|
||||
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::THROW);
|
||||
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::THROW_LOGICAL);
|
||||
for (const auto & [_, file_segment_metadata] : *locked_key->getKeyMetadata())
|
||||
file_segments.push_back(FileSegment::getSnapshot(file_segment_metadata->file_segment));
|
||||
return std::make_unique<FileSegmentsHolder>(std::move(file_segments));
|
||||
|
||||
@ -83,13 +83,19 @@ public:
|
||||
|
||||
FileSegmentsHolderPtr set(const Key & key, size_t offset, size_t size, const CreateFileSegmentSettings & settings);
|
||||
|
||||
/// Remove files by `key`. Removes files which might be used at the moment.
|
||||
/// Remove file segment by `key` and `offset`. Throws if file segment does not exist.
|
||||
void removeFileSegment(const Key & key, size_t offset);
|
||||
|
||||
/// Remove files by `key`. Throws if key does not exist.
|
||||
void removeKey(const Key & key);
|
||||
|
||||
/// Remove files by `key`.
|
||||
void removeKeyIfExists(const Key & key);
|
||||
|
||||
/// Removes files by `path`. Removes files which might be used at the moment.
|
||||
/// Removes files by `path`.
|
||||
void removePathIfExists(const String & path);
|
||||
|
||||
/// Remove files by `key`. Will not remove files which are used at the moment.
|
||||
/// Remove files by `key`.
|
||||
void removeAllReleasable();
|
||||
|
||||
std::vector<String> tryGetCachePaths(const Key & key);
|
||||
|
||||
@ -7,6 +7,10 @@
|
||||
|
||||
namespace DB
|
||||
{
|
||||
namespace ErrorCodes
|
||||
{
|
||||
extern const int BAD_ARGUMENTS;
|
||||
}
|
||||
|
||||
FileCacheKey::FileCacheKey(const std::string & path)
|
||||
: key(sipHash128(path.data(), path.size()))
|
||||
@ -28,4 +32,11 @@ FileCacheKey FileCacheKey::random()
|
||||
return FileCacheKey(UUIDHelpers::generateV4().toUnderType());
|
||||
}
|
||||
|
||||
FileCacheKey FileCacheKey::fromKeyString(const std::string & key_str)
|
||||
{
|
||||
if (key_str.size() != 32)
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS, "Invalid cache key hex: {}", key_str);
|
||||
return FileCacheKey(unhexUInt<UInt128>(key_str.data()));
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@ -21,6 +21,8 @@ struct FileCacheKey
|
||||
static FileCacheKey random();
|
||||
|
||||
bool operator==(const FileCacheKey & other) const { return key == other.key; }
|
||||
|
||||
static FileCacheKey fromKeyString(const std::string & key_str);
|
||||
};
|
||||
|
||||
using FileCacheKeyAndOffset = std::pair<FileCacheKey, size_t>;
|
||||
|
||||
@ -258,6 +258,9 @@ void FileSegment::resetDownloader()
|
||||
|
||||
void FileSegment::resetDownloaderUnlocked(const FileSegmentGuard::Lock &)
|
||||
{
|
||||
if (downloader_id.empty())
|
||||
return;
|
||||
|
||||
LOG_TEST(log, "Resetting downloader from {}", downloader_id);
|
||||
downloader_id.clear();
|
||||
}
|
||||
@ -266,7 +269,6 @@ void FileSegment::assertIsDownloaderUnlocked(const std::string & operation, cons
|
||||
{
|
||||
auto caller = getCallerId();
|
||||
auto current_downloader = getDownloaderUnlocked(lock);
|
||||
LOG_TEST(log, "Downloader id: {}, caller id: {}, operation: {}", current_downloader, caller, operation);
|
||||
|
||||
if (caller != current_downloader)
|
||||
{
|
||||
|
||||
@ -25,6 +25,7 @@ namespace DB
|
||||
namespace ErrorCodes
|
||||
{
|
||||
extern const int LOGICAL_ERROR;
|
||||
extern const int BAD_ARGUMENTS;
|
||||
}
|
||||
|
||||
FileSegmentMetadata::FileSegmentMetadata(FileSegmentPtr && file_segment_)
|
||||
@ -197,6 +198,8 @@ LockedKeyPtr CacheMetadata::lockKeyMetadata(
|
||||
return locked_metadata;
|
||||
|
||||
if (key_not_found_policy == KeyNotFoundPolicy::THROW)
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS, "No such key `{}` in cache", key);
|
||||
else if (key_not_found_policy == KeyNotFoundPolicy::THROW_LOGICAL)
|
||||
throw Exception(ErrorCodes::LOGICAL_ERROR, "No such key `{}` in cache", key);
|
||||
|
||||
if (key_not_found_policy == KeyNotFoundPolicy::RETURN_NULL)
|
||||
@ -566,11 +569,11 @@ bool LockedKey::isLastOwnerOfFileSegment(size_t offset) const
|
||||
return file_segment_metadata->file_segment.use_count() == 2;
|
||||
}
|
||||
|
||||
void LockedKey::removeAllReleasable()
|
||||
void LockedKey::removeAll(bool if_releasable)
|
||||
{
|
||||
for (auto it = key_metadata->begin(); it != key_metadata->end();)
|
||||
{
|
||||
if (!it->second->releasable())
|
||||
if (if_releasable && !it->second->releasable())
|
||||
{
|
||||
++it;
|
||||
continue;
|
||||
@ -591,17 +594,32 @@ void LockedKey::removeAllReleasable()
|
||||
}
|
||||
}
|
||||
|
||||
KeyMetadata::iterator LockedKey::removeFileSegment(size_t offset)
|
||||
{
|
||||
auto it = key_metadata->find(offset);
|
||||
if (it == key_metadata->end())
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS, "There is no offset {}", offset);
|
||||
|
||||
auto file_segment = it->second->file_segment;
|
||||
return removeFileSegmentImpl(it, file_segment->lock());
|
||||
}
|
||||
|
||||
KeyMetadata::iterator LockedKey::removeFileSegment(size_t offset, const FileSegmentGuard::Lock & segment_lock)
|
||||
{
|
||||
auto it = key_metadata->find(offset);
|
||||
if (it == key_metadata->end())
|
||||
throw Exception(ErrorCodes::LOGICAL_ERROR, "There is no offset {}", offset);
|
||||
|
||||
return removeFileSegmentImpl(it, segment_lock);
|
||||
}
|
||||
|
||||
KeyMetadata::iterator LockedKey::removeFileSegmentImpl(KeyMetadata::iterator it, const FileSegmentGuard::Lock & segment_lock)
|
||||
{
|
||||
auto file_segment = it->second->file_segment;
|
||||
|
||||
LOG_DEBUG(
|
||||
key_metadata->log, "Remove from cache. Key: {}, offset: {}, size: {}",
|
||||
getKey(), offset, file_segment->reserved_size);
|
||||
getKey(), file_segment->offset(), file_segment->reserved_size);
|
||||
|
||||
chassert(file_segment->assertCorrectnessUnlocked(segment_lock));
|
||||
|
||||
|
||||
@ -87,7 +87,7 @@ struct CacheMetadata : public std::unordered_map<FileCacheKey, KeyMetadataPtr>,
|
||||
{
|
||||
public:
|
||||
using Key = FileCacheKey;
|
||||
using IterateCacheMetadataFunc = std::function<void(const LockedKey &)>;
|
||||
using IterateCacheMetadataFunc = std::function<void(LockedKey &)>;
|
||||
|
||||
explicit CacheMetadata(const std::string & path_);
|
||||
|
||||
@ -106,6 +106,7 @@ public:
|
||||
enum class KeyNotFoundPolicy
|
||||
{
|
||||
THROW,
|
||||
THROW_LOGICAL,
|
||||
CREATE_EMPTY,
|
||||
RETURN_NULL,
|
||||
};
|
||||
@ -174,9 +175,10 @@ struct LockedKey : private boost::noncopyable
|
||||
std::shared_ptr<const KeyMetadata> getKeyMetadata() const { return key_metadata; }
|
||||
std::shared_ptr<KeyMetadata> getKeyMetadata() { return key_metadata; }
|
||||
|
||||
void removeAllReleasable();
|
||||
void removeAll(bool if_releasable = true);
|
||||
|
||||
KeyMetadata::iterator removeFileSegment(size_t offset, const FileSegmentGuard::Lock &);
|
||||
KeyMetadata::iterator removeFileSegment(size_t offset);
|
||||
|
||||
void shrinkFileSegmentToDownloadedSize(size_t offset, const FileSegmentGuard::Lock &);
|
||||
|
||||
@ -193,6 +195,8 @@ struct LockedKey : private boost::noncopyable
|
||||
std::string toString() const;
|
||||
|
||||
private:
|
||||
KeyMetadata::iterator removeFileSegmentImpl(KeyMetadata::iterator it, const FileSegmentGuard::Lock &);
|
||||
|
||||
const std::shared_ptr<KeyMetadata> key_metadata;
|
||||
KeyGuard::Lock lock; /// `lock` must be destructed before `key_metadata`.
|
||||
};
|
||||
|
||||
@ -40,6 +40,8 @@ NamesAndTypesList FilesystemCacheLogElement::getNamesAndTypes()
|
||||
{"source_file_path", std::make_shared<DataTypeString>()},
|
||||
{"file_segment_range", std::make_shared<DataTypeTuple>(types)},
|
||||
{"total_requested_range", std::make_shared<DataTypeTuple>(types)},
|
||||
{"key", std::make_shared<DataTypeString>()},
|
||||
{"offset", std::make_shared<DataTypeUInt64>()},
|
||||
{"size", std::make_shared<DataTypeUInt64>()},
|
||||
{"read_type", std::make_shared<DataTypeString>()},
|
||||
{"read_from_cache_attempted", std::make_shared<DataTypeUInt8>()},
|
||||
@ -60,6 +62,8 @@ void FilesystemCacheLogElement::appendToBlock(MutableColumns & columns) const
|
||||
columns[i++]->insert(source_file_path);
|
||||
columns[i++]->insert(Tuple{file_segment_range.first, file_segment_range.second});
|
||||
columns[i++]->insert(Tuple{requested_range.first, requested_range.second});
|
||||
columns[i++]->insert(file_segment_key);
|
||||
columns[i++]->insert(file_segment_offset);
|
||||
columns[i++]->insert(file_segment_size);
|
||||
columns[i++]->insert(typeToString(cache_type));
|
||||
columns[i++]->insert(read_from_cache_attempted);
|
||||
|
||||
@ -11,16 +11,7 @@
|
||||
|
||||
namespace DB
|
||||
{
|
||||
///
|
||||
/// -------- Column --------- Type ------
|
||||
/// | event_date | DateTime |
|
||||
/// | event_time | UInt64 |
|
||||
/// | query_id | String |
|
||||
/// | remote_file_path | String |
|
||||
/// | segment_range | Tuple |
|
||||
/// | read_type | String |
|
||||
/// -------------------------------------
|
||||
///
|
||||
|
||||
struct FilesystemCacheLogElement
|
||||
{
|
||||
enum class CacheType
|
||||
@ -39,6 +30,8 @@ struct FilesystemCacheLogElement
|
||||
std::pair<size_t, size_t> file_segment_range{};
|
||||
std::pair<size_t, size_t> requested_range{};
|
||||
CacheType cache_type{};
|
||||
std::string file_segment_key;
|
||||
size_t file_segment_offset;
|
||||
size_t file_segment_size;
|
||||
bool read_from_cache_attempted;
|
||||
String read_buffer_id;
|
||||
|
||||
@ -89,13 +89,14 @@ namespace ErrorCodes
|
||||
|
||||
namespace ActionLocks
|
||||
{
|
||||
extern StorageActionBlockType PartsMerge;
|
||||
extern StorageActionBlockType PartsFetch;
|
||||
extern StorageActionBlockType PartsSend;
|
||||
extern StorageActionBlockType ReplicationQueue;
|
||||
extern StorageActionBlockType DistributedSend;
|
||||
extern StorageActionBlockType PartsTTLMerge;
|
||||
extern StorageActionBlockType PartsMove;
|
||||
extern const StorageActionBlockType PartsMerge;
|
||||
extern const StorageActionBlockType PartsFetch;
|
||||
extern const StorageActionBlockType PartsSend;
|
||||
extern const StorageActionBlockType ReplicationQueue;
|
||||
extern const StorageActionBlockType DistributedSend;
|
||||
extern const StorageActionBlockType PartsTTLMerge;
|
||||
extern const StorageActionBlockType PartsMove;
|
||||
extern const StorageActionBlockType PullReplicationLog;
|
||||
}
|
||||
|
||||
|
||||
@ -155,6 +156,8 @@ AccessType getRequiredAccessType(StorageActionBlockType action_type)
|
||||
return AccessType::SYSTEM_TTL_MERGES;
|
||||
else if (action_type == ActionLocks::PartsMove)
|
||||
return AccessType::SYSTEM_MOVES;
|
||||
else if (action_type == ActionLocks::PullReplicationLog)
|
||||
return AccessType::SYSTEM_PULLING_REPLICATION_LOG;
|
||||
else
|
||||
throw Exception(ErrorCodes::LOGICAL_ERROR, "Unknown action type: {}", std::to_string(action_type));
|
||||
}
|
||||
@ -371,7 +374,18 @@ BlockIO InterpreterSystemQuery::execute()
|
||||
else
|
||||
{
|
||||
auto cache = FileCacheFactory::instance().getByName(query.filesystem_cache_name).cache;
|
||||
cache->removeAllReleasable();
|
||||
if (query.key_to_drop.empty())
|
||||
{
|
||||
cache->removeAllReleasable();
|
||||
}
|
||||
else
|
||||
{
|
||||
auto key = FileCacheKey::fromKeyString(query.key_to_drop);
|
||||
if (query.offset_to_drop.has_value())
|
||||
cache->removeFileSegment(key, query.offset_to_drop.value());
|
||||
else
|
||||
cache->removeKey(key);
|
||||
}
|
||||
}
|
||||
break;
|
||||
}
|
||||
@ -502,6 +516,12 @@ BlockIO InterpreterSystemQuery::execute()
|
||||
case Type::START_DISTRIBUTED_SENDS:
|
||||
startStopAction(ActionLocks::DistributedSend, true);
|
||||
break;
|
||||
case Type::STOP_PULLING_REPLICATION_LOG:
|
||||
startStopAction(ActionLocks::PullReplicationLog, false);
|
||||
break;
|
||||
case Type::START_PULLING_REPLICATION_LOG:
|
||||
startStopAction(ActionLocks::PullReplicationLog, true);
|
||||
break;
|
||||
case Type::DROP_REPLICA:
|
||||
dropReplica(query);
|
||||
break;
|
||||
@ -1079,6 +1099,15 @@ AccessRightsElements InterpreterSystemQuery::getRequiredAccessForDDLOnCluster()
|
||||
required_access.emplace_back(AccessType::SYSTEM_MOVES, query.getDatabase(), query.getTable());
|
||||
break;
|
||||
}
|
||||
case Type::STOP_PULLING_REPLICATION_LOG:
|
||||
case Type::START_PULLING_REPLICATION_LOG:
|
||||
{
|
||||
if (!query.table)
|
||||
required_access.emplace_back(AccessType::SYSTEM_PULLING_REPLICATION_LOG);
|
||||
else
|
||||
required_access.emplace_back(AccessType::SYSTEM_PULLING_REPLICATION_LOG, query.getDatabase(), query.getTable());
|
||||
break;
|
||||
}
|
||||
case Type::STOP_FETCHES:
|
||||
case Type::START_FETCHES:
|
||||
{
|
||||
|
||||
@ -1034,7 +1034,7 @@ std::shared_ptr<Block> MergeJoin::loadRightBlock(size_t pos) const
|
||||
{
|
||||
auto load_func = [&]() -> std::shared_ptr<Block>
|
||||
{
|
||||
TemporaryFileStreamLegacy input(flushed_right_blocks[pos]->getPath(), materializeBlock(right_sample_block));
|
||||
TemporaryFileStreamLegacy input(flushed_right_blocks[pos]->getAbsolutePath(), materializeBlock(right_sample_block));
|
||||
return std::make_shared<Block>(input.block_in->read());
|
||||
};
|
||||
|
||||
|
||||
@ -39,7 +39,7 @@ namespace
|
||||
TemporaryFileOnDiskHolder flushToFile(const DiskPtr & disk, const Block & header, QueryPipelineBuilder pipeline, const String & codec)
|
||||
{
|
||||
auto tmp_file = std::make_unique<TemporaryFileOnDisk>(disk, CurrentMetrics::TemporaryFilesForJoin);
|
||||
auto write_stat = TemporaryFileStreamLegacy::write(tmp_file->getPath(), header, std::move(pipeline), codec);
|
||||
auto write_stat = TemporaryFileStreamLegacy::write(tmp_file->getAbsolutePath(), header, std::move(pipeline), codec);
|
||||
|
||||
ProfileEvents::increment(ProfileEvents::ExternalProcessingCompressedBytesTotal, write_stat.compressed_bytes);
|
||||
ProfileEvents::increment(ProfileEvents::ExternalProcessingUncompressedBytesTotal, write_stat.uncompressed_bytes);
|
||||
@ -267,7 +267,7 @@ SortedBlocksWriter::SortedFiles SortedBlocksWriter::finishMerge(std::function<vo
|
||||
|
||||
Pipe SortedBlocksWriter::streamFromFile(const TmpFilePtr & file) const
|
||||
{
|
||||
return Pipe(std::make_shared<TemporaryFileLazySource>(file->getPath(), materializeBlock(sample_block)));
|
||||
return Pipe(std::make_shared<TemporaryFileLazySource>(file->getAbsolutePath(), materializeBlock(sample_block)));
|
||||
}
|
||||
|
||||
|
||||
|
||||
@ -48,6 +48,11 @@ namespace ErrorCodes
|
||||
extern const int NOT_IMPLEMENTED;
|
||||
}
|
||||
|
||||
namespace ActionLocks
|
||||
{
|
||||
extern const StorageActionBlockType PartsMerge;
|
||||
}
|
||||
|
||||
namespace
|
||||
{
|
||||
class StorageWithComment : public IAST
|
||||
@ -560,6 +565,10 @@ void SystemLog<LogElement>::prepareTable()
|
||||
|
||||
rename->elements.emplace_back(std::move(elem));
|
||||
|
||||
ActionLock merges_lock;
|
||||
if (DatabaseCatalog::instance().getDatabase(table_id.database_name)->getUUID() == UUIDHelpers::Nil)
|
||||
merges_lock = table->getActionLock(ActionLocks::PartsMerge);
|
||||
|
||||
auto query_context = Context::createCopy(context);
|
||||
/// As this operation is performed automatically we don't want it to fail because of user dependencies on log tables
|
||||
query_context->setSetting("check_table_dependencies", Field{false});
|
||||
|
||||
@ -235,9 +235,9 @@ TemporaryFileStream::TemporaryFileStream(TemporaryFileOnDiskHolder file_, const
|
||||
: parent(parent_)
|
||||
, header(header_)
|
||||
, file(std::move(file_))
|
||||
, out_writer(std::make_unique<OutputWriter>(std::make_unique<WriteBufferFromFile>(file->getPath()), header))
|
||||
, out_writer(std::make_unique<OutputWriter>(std::make_unique<WriteBufferFromFile>(file->getAbsolutePath()), header))
|
||||
{
|
||||
LOG_TEST(&Poco::Logger::get("TemporaryFileStream"), "Writing to temporary file {}", file->getPath());
|
||||
LOG_TEST(&Poco::Logger::get("TemporaryFileStream"), "Writing to temporary file {}", file->getAbsolutePath());
|
||||
}
|
||||
|
||||
TemporaryFileStream::TemporaryFileStream(FileSegmentsHolderPtr segments_, const Block & header_, TemporaryDataOnDisk * parent_)
|
||||
@ -365,7 +365,7 @@ void TemporaryFileStream::release()
|
||||
String TemporaryFileStream::getPath() const
|
||||
{
|
||||
if (file)
|
||||
return file->getPath();
|
||||
return file->getAbsolutePath();
|
||||
if (segment_holder && !segment_holder->empty())
|
||||
return segment_holder->front().getPathInLocalCache();
|
||||
|
||||
|
||||
@ -91,34 +91,30 @@ void WindowFrame::toString(WriteBuffer & buf) const
|
||||
void WindowFrame::checkValid() const
|
||||
{
|
||||
// Check the validity of offsets.
|
||||
if (type == WindowFrame::FrameType::ROWS
|
||||
|| type == WindowFrame::FrameType::GROUPS)
|
||||
if (begin_type == BoundaryType::Offset
|
||||
&& !((begin_offset.getType() == Field::Types::UInt64
|
||||
|| begin_offset.getType() == Field::Types::Int64)
|
||||
&& begin_offset.get<Int64>() >= 0
|
||||
&& begin_offset.get<Int64>() < INT_MAX))
|
||||
{
|
||||
if (begin_type == BoundaryType::Offset
|
||||
&& !((begin_offset.getType() == Field::Types::UInt64
|
||||
|| begin_offset.getType() == Field::Types::Int64)
|
||||
&& begin_offset.get<Int64>() >= 0
|
||||
&& begin_offset.get<Int64>() < INT_MAX))
|
||||
{
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS,
|
||||
"Frame start offset for '{}' frame must be a nonnegative 32-bit integer, '{}' of type '{}' given",
|
||||
type,
|
||||
applyVisitor(FieldVisitorToString(), begin_offset),
|
||||
begin_offset.getType());
|
||||
}
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS,
|
||||
"Frame start offset for '{}' frame must be a nonnegative 32-bit integer, '{}' of type '{}' given",
|
||||
type,
|
||||
applyVisitor(FieldVisitorToString(), begin_offset),
|
||||
begin_offset.getType());
|
||||
}
|
||||
|
||||
if (end_type == BoundaryType::Offset
|
||||
&& !((end_offset.getType() == Field::Types::UInt64
|
||||
|| end_offset.getType() == Field::Types::Int64)
|
||||
&& end_offset.get<Int64>() >= 0
|
||||
&& end_offset.get<Int64>() < INT_MAX))
|
||||
{
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS,
|
||||
"Frame end offset for '{}' frame must be a nonnegative 32-bit integer, '{}' of type '{}' given",
|
||||
type,
|
||||
applyVisitor(FieldVisitorToString(), end_offset),
|
||||
end_offset.getType());
|
||||
}
|
||||
if (end_type == BoundaryType::Offset
|
||||
&& !((end_offset.getType() == Field::Types::UInt64
|
||||
|| end_offset.getType() == Field::Types::Int64)
|
||||
&& end_offset.get<Int64>() >= 0
|
||||
&& end_offset.get<Int64>() < INT_MAX))
|
||||
{
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS,
|
||||
"Frame end offset for '{}' frame must be a nonnegative 32-bit integer, '{}' of type '{}' given",
|
||||
type,
|
||||
applyVisitor(FieldVisitorToString(), end_offset),
|
||||
end_offset.getType());
|
||||
}
|
||||
|
||||
// Check relative positioning of offsets.
|
||||
|
||||
@ -49,7 +49,7 @@ static ZooKeeperRetriesInfo getRetriesInfo()
|
||||
);
|
||||
}
|
||||
|
||||
bool isSupportedAlterType(int type)
|
||||
bool isSupportedAlterTypeForOnClusterDDLQuery(int type)
|
||||
{
|
||||
assert(type != ASTAlterCommand::NO_TYPE);
|
||||
static const std::unordered_set<int> unsupported_alter_types{
|
||||
@ -90,7 +90,7 @@ BlockIO executeDDLQueryOnCluster(const ASTPtr & query_ptr_, ContextPtr context,
|
||||
{
|
||||
for (const auto & command : query_alter->command_list->children)
|
||||
{
|
||||
if (!isSupportedAlterType(command->as<ASTAlterCommand&>().type))
|
||||
if (!isSupportedAlterTypeForOnClusterDDLQuery(command->as<ASTAlterCommand&>().type))
|
||||
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Unsupported type of ALTER query");
|
||||
}
|
||||
}
|
||||
|
||||
@ -21,7 +21,7 @@ class Cluster;
|
||||
using ClusterPtr = std::shared_ptr<Cluster>;
|
||||
|
||||
/// Returns true if provided ALTER type can be executed ON CLUSTER
|
||||
bool isSupportedAlterType(int type);
|
||||
bool isSupportedAlterTypeForOnClusterDDLQuery(int type);
|
||||
|
||||
struct DDLQueryOnClusterParams
|
||||
{
|
||||
|
||||
@ -45,10 +45,10 @@ namespace ErrorCodes
|
||||
|
||||
namespace ActionLocks
|
||||
{
|
||||
extern StorageActionBlockType PartsMerge;
|
||||
extern StorageActionBlockType PartsFetch;
|
||||
extern StorageActionBlockType PartsSend;
|
||||
extern StorageActionBlockType DistributedSend;
|
||||
extern const StorageActionBlockType PartsMerge;
|
||||
extern const StorageActionBlockType PartsFetch;
|
||||
extern const StorageActionBlockType PartsSend;
|
||||
extern const StorageActionBlockType DistributedSend;
|
||||
}
|
||||
|
||||
static void executeCreateQuery(
|
||||
|
||||
@ -13,7 +13,7 @@ namespace ErrorCodes
|
||||
|
||||
String ASTAlterCommand::getID(char delim) const
|
||||
{
|
||||
return String("AlterCommand") + delim + typeToString(type);
|
||||
return fmt::format("AlterCommand{}{}", delim, type);
|
||||
}
|
||||
|
||||
ASTPtr ASTAlterCommand::clone() const
|
||||
@ -80,53 +80,6 @@ ASTPtr ASTAlterCommand::clone() const
|
||||
return res;
|
||||
}
|
||||
|
||||
const char * ASTAlterCommand::typeToString(ASTAlterCommand::Type type)
|
||||
{
|
||||
switch (type)
|
||||
{
|
||||
case ADD_COLUMN: return "ADD_COLUMN";
|
||||
case DROP_COLUMN: return "DROP_COLUMN";
|
||||
case MODIFY_COLUMN: return "MODIFY_COLUMN";
|
||||
case COMMENT_COLUMN: return "COMMENT_COLUMN";
|
||||
case RENAME_COLUMN: return "RENAME_COLUMN";
|
||||
case MATERIALIZE_COLUMN: return "MATERIALIZE_COLUMN";
|
||||
case MODIFY_ORDER_BY: return "MODIFY_ORDER_BY";
|
||||
case MODIFY_SAMPLE_BY: return "MODIFY_SAMPLE_BY";
|
||||
case MODIFY_TTL: return "MODIFY_TTL";
|
||||
case MATERIALIZE_TTL: return "MATERIALIZE_TTL";
|
||||
case MODIFY_SETTING: return "MODIFY_SETTING";
|
||||
case RESET_SETTING: return "RESET_SETTING";
|
||||
case MODIFY_QUERY: return "MODIFY_QUERY";
|
||||
case REMOVE_TTL: return "REMOVE_TTL";
|
||||
case REMOVE_SAMPLE_BY: return "REMOVE_SAMPLE_BY";
|
||||
case ADD_INDEX: return "ADD_INDEX";
|
||||
case DROP_INDEX: return "DROP_INDEX";
|
||||
case MATERIALIZE_INDEX: return "MATERIALIZE_INDEX";
|
||||
case ADD_CONSTRAINT: return "ADD_CONSTRAINT";
|
||||
case DROP_CONSTRAINT: return "DROP_CONSTRAINT";
|
||||
case ADD_PROJECTION: return "ADD_PROJECTION";
|
||||
case DROP_PROJECTION: return "DROP_PROJECTION";
|
||||
case MATERIALIZE_PROJECTION: return "MATERIALIZE_PROJECTION";
|
||||
case DROP_PARTITION: return "DROP_PARTITION";
|
||||
case DROP_DETACHED_PARTITION: return "DROP_DETACHED_PARTITION";
|
||||
case ATTACH_PARTITION: return "ATTACH_PARTITION";
|
||||
case MOVE_PARTITION: return "MOVE_PARTITION";
|
||||
case REPLACE_PARTITION: return "REPLACE_PARTITION";
|
||||
case FETCH_PARTITION: return "FETCH_PARTITION";
|
||||
case FREEZE_PARTITION: return "FREEZE_PARTITION";
|
||||
case FREEZE_ALL: return "FREEZE_ALL";
|
||||
case UNFREEZE_PARTITION: return "UNFREEZE_PARTITION";
|
||||
case UNFREEZE_ALL: return "UNFREEZE_ALL";
|
||||
case DELETE: return "DELETE";
|
||||
case UPDATE: return "UPDATE";
|
||||
case NO_TYPE: return "NO_TYPE";
|
||||
case LIVE_VIEW_REFRESH: return "LIVE_VIEW_REFRESH";
|
||||
case MODIFY_DATABASE_SETTING: return "MODIFY_DATABASE_SETTING";
|
||||
case MODIFY_COMMENT: return "MODIFY_COMMENT";
|
||||
}
|
||||
UNREACHABLE();
|
||||
}
|
||||
|
||||
void ASTAlterCommand::formatImpl(const FormatSettings & settings, FormatState & state, FormatStateStacked frame) const
|
||||
{
|
||||
if (type == ASTAlterCommand::ADD_COLUMN)
|
||||
|
||||
@ -208,8 +208,6 @@ public:
|
||||
|
||||
ASTPtr clone() const override;
|
||||
|
||||
static const char * typeToString(Type type);
|
||||
|
||||
protected:
|
||||
void formatImpl(const FormatSettings & settings, FormatState & state, FormatStateStacked frame) const override;
|
||||
};
|
||||
|
||||
@ -162,7 +162,9 @@ void ASTSystemQuery::formatImpl(const FormatSettings & settings, FormatState &,
|
||||
|| type == Type::STOP_REPLICATION_QUEUES
|
||||
|| type == Type::START_REPLICATION_QUEUES
|
||||
|| type == Type::STOP_DISTRIBUTED_SENDS
|
||||
|| type == Type::START_DISTRIBUTED_SENDS)
|
||||
|| type == Type::START_DISTRIBUTED_SENDS
|
||||
|| type == Type::STOP_PULLING_REPLICATION_LOG
|
||||
|| type == Type::START_PULLING_REPLICATION_LOG)
|
||||
{
|
||||
if (table)
|
||||
print_database_table();
|
||||
@ -210,7 +212,15 @@ void ASTSystemQuery::formatImpl(const FormatSettings & settings, FormatState &,
|
||||
else if (type == Type::DROP_FILESYSTEM_CACHE)
|
||||
{
|
||||
if (!filesystem_cache_name.empty())
|
||||
{
|
||||
settings.ostr << (settings.hilite ? hilite_none : "") << " " << filesystem_cache_name;
|
||||
if (!key_to_drop.empty())
|
||||
{
|
||||
settings.ostr << (settings.hilite ? hilite_none : "") << " KEY " << key_to_drop;
|
||||
if (offset_to_drop.has_value())
|
||||
settings.ostr << (settings.hilite ? hilite_none : "") << " OFFSET " << offset_to_drop.value();
|
||||
}
|
||||
}
|
||||
}
|
||||
else if (type == Type::UNFREEZE)
|
||||
{
|
||||
|
||||
@ -80,6 +80,8 @@ public:
|
||||
UNFREEZE,
|
||||
ENABLE_FAILPOINT,
|
||||
DISABLE_FAILPOINT,
|
||||
STOP_PULLING_REPLICATION_LOG,
|
||||
START_PULLING_REPLICATION_LOG,
|
||||
END
|
||||
};
|
||||
|
||||
@ -108,6 +110,8 @@ public:
|
||||
UInt64 seconds{};
|
||||
|
||||
String filesystem_cache_name;
|
||||
std::string key_to_drop;
|
||||
std::optional<size_t> offset_to_drop;
|
||||
|
||||
String backup_name;
|
||||
|
||||
|
||||
@ -379,6 +379,8 @@ bool ParserSystemQuery::parseImpl(IParser::Pos & pos, ASTPtr & node, Expected &
|
||||
case Type::START_REPLICATED_SENDS:
|
||||
case Type::STOP_REPLICATION_QUEUES:
|
||||
case Type::START_REPLICATION_QUEUES:
|
||||
case Type::STOP_PULLING_REPLICATION_LOG:
|
||||
case Type::START_PULLING_REPLICATION_LOG:
|
||||
if (!parseQueryWithOnCluster(res, pos, expected))
|
||||
return false;
|
||||
parseDatabaseAndTableAsAST(pos, expected, res->database, res->table);
|
||||
@ -405,7 +407,15 @@ bool ParserSystemQuery::parseImpl(IParser::Pos & pos, ASTPtr & node, Expected &
|
||||
ParserLiteral path_parser;
|
||||
ASTPtr ast;
|
||||
if (path_parser.parse(pos, ast, expected))
|
||||
{
|
||||
res->filesystem_cache_name = ast->as<ASTLiteral>()->value.safeGet<String>();
|
||||
if (ParserKeyword{"KEY"}.ignore(pos, expected) && ParserIdentifier().parse(pos, ast, expected))
|
||||
{
|
||||
res->key_to_drop = ast->as<ASTIdentifier>()->name();
|
||||
if (ParserKeyword{"OFFSET"}.ignore(pos, expected) && ParserLiteral().parse(pos, ast, expected))
|
||||
res->offset_to_drop = ast->as<ASTLiteral>()->value.safeGet<UInt64>();
|
||||
}
|
||||
}
|
||||
if (!parseQueryWithOnCluster(res, pos, expected))
|
||||
return false;
|
||||
break;
|
||||
|
||||
@ -17,12 +17,12 @@ namespace ErrorCodes
|
||||
extern const int INCORRECT_DATA;
|
||||
}
|
||||
|
||||
CapnProtoRowInputFormat::CapnProtoRowInputFormat(ReadBuffer & in_, Block header_, Params params_, const FormatSchemaInfo & info, const FormatSettings & format_settings)
|
||||
CapnProtoRowInputFormat::CapnProtoRowInputFormat(ReadBuffer & in_, Block header_, Params params_, const CapnProtoSchemaInfo & info, const FormatSettings & format_settings)
|
||||
: IRowInputFormat(std::move(header_), in_, std::move(params_))
|
||||
, parser(std::make_shared<CapnProtoSchemaParser>())
|
||||
{
|
||||
// Parse the schema and fetch the root object
|
||||
schema = parser->getMessageSchema(info);
|
||||
schema = parser->getMessageSchema(info.getSchemaInfo());
|
||||
const auto & header = getPort().getHeader();
|
||||
serializer = std::make_unique<CapnProtoSerializer>(header.getDataTypes(), header.getNames(), schema, format_settings.capn_proto);
|
||||
}
|
||||
@ -106,8 +106,12 @@ void registerInputFormatCapnProto(FormatFactory & factory)
|
||||
"CapnProto",
|
||||
[](ReadBuffer & buf, const Block & sample, IRowInputFormat::Params params, const FormatSettings & settings)
|
||||
{
|
||||
return std::make_shared<CapnProtoRowInputFormat>(buf, sample, std::move(params),
|
||||
FormatSchemaInfo(settings, "CapnProto", true), settings);
|
||||
return std::make_shared<CapnProtoRowInputFormat>(
|
||||
buf,
|
||||
sample,
|
||||
std::move(params),
|
||||
CapnProtoSchemaInfo(settings, "CapnProto", sample, settings.capn_proto.use_autogenerated_schema),
|
||||
settings);
|
||||
});
|
||||
factory.markFormatSupportsSubsetOfColumns("CapnProto");
|
||||
factory.registerFileExtension("capnp", "CapnProto");
|
||||
|
||||
@ -24,7 +24,7 @@ class ReadBuffer;
|
||||
class CapnProtoRowInputFormat final : public IRowInputFormat
|
||||
{
|
||||
public:
|
||||
CapnProtoRowInputFormat(ReadBuffer & in_, Block header, Params params_, const FormatSchemaInfo & info, const FormatSettings & format_settings_);
|
||||
CapnProtoRowInputFormat(ReadBuffer & in_, Block header, Params params_, const CapnProtoSchemaInfo & info, const FormatSettings & format_settings);
|
||||
|
||||
String getName() const override { return "CapnProtoRowInputFormat"; }
|
||||
|
||||
|
||||
@ -23,14 +23,14 @@ void CapnProtoOutputStream::write(const void * buffer, size_t size)
|
||||
CapnProtoRowOutputFormat::CapnProtoRowOutputFormat(
|
||||
WriteBuffer & out_,
|
||||
const Block & header_,
|
||||
const FormatSchemaInfo & info,
|
||||
const CapnProtoSchemaInfo & info,
|
||||
const FormatSettings & format_settings)
|
||||
: IRowOutputFormat(header_, out_)
|
||||
, column_names(header_.getNames())
|
||||
, column_types(header_.getDataTypes())
|
||||
, output_stream(std::make_unique<CapnProtoOutputStream>(out_))
|
||||
{
|
||||
schema = schema_parser.getMessageSchema(info);
|
||||
schema = schema_parser.getMessageSchema(info.getSchemaInfo());
|
||||
const auto & header = getPort(PortKind::Main).getHeader();
|
||||
serializer = std::make_unique<CapnProtoSerializer>(header.getDataTypes(), header.getNames(), schema, format_settings.capn_proto);
|
||||
capnp::MallocMessageBuilder message;
|
||||
@ -52,7 +52,11 @@ void registerOutputFormatCapnProto(FormatFactory & factory)
|
||||
const Block & sample,
|
||||
const FormatSettings & format_settings)
|
||||
{
|
||||
return std::make_shared<CapnProtoRowOutputFormat>(buf, sample, FormatSchemaInfo(format_settings, "CapnProto", true), format_settings);
|
||||
return std::make_shared<CapnProtoRowOutputFormat>(
|
||||
buf,
|
||||
sample,
|
||||
CapnProtoSchemaInfo(format_settings, "CapnProto", sample, format_settings.capn_proto.use_autogenerated_schema),
|
||||
format_settings);
|
||||
});
|
||||
}
|
||||
|
||||
|
||||
@ -31,8 +31,8 @@ public:
|
||||
CapnProtoRowOutputFormat(
|
||||
WriteBuffer & out_,
|
||||
const Block & header_,
|
||||
const FormatSchemaInfo & info,
|
||||
const FormatSettings & format_settings_);
|
||||
const CapnProtoSchemaInfo & info,
|
||||
const FormatSettings & format_settings);
|
||||
|
||||
String getName() const override { return "CapnProtoRowOutputFormat"; }
|
||||
|
||||
|
||||
@ -14,7 +14,7 @@ ProtobufListInputFormat::ProtobufListInputFormat(
|
||||
ReadBuffer & in_,
|
||||
const Block & header_,
|
||||
const Params & params_,
|
||||
const FormatSchemaInfo & schema_info_,
|
||||
const ProtobufSchemaInfo & schema_info_,
|
||||
bool flatten_google_wrappers_)
|
||||
: IRowInputFormat(header_, in_, params_)
|
||||
, reader(std::make_unique<ProtobufReader>(in_))
|
||||
@ -22,7 +22,7 @@ ProtobufListInputFormat::ProtobufListInputFormat(
|
||||
header_.getNames(),
|
||||
header_.getDataTypes(),
|
||||
missing_column_indices,
|
||||
*ProtobufSchemas::instance().getMessageTypeForFormatSchema(schema_info_, ProtobufSchemas::WithEnvelope::Yes),
|
||||
*ProtobufSchemas::instance().getMessageTypeForFormatSchema(schema_info_.getSchemaInfo(), ProtobufSchemas::WithEnvelope::Yes),
|
||||
/* with_length_delimiter = */ true,
|
||||
/* with_envelope = */ true,
|
||||
flatten_google_wrappers_,
|
||||
@ -84,7 +84,7 @@ void registerInputFormatProtobufList(FormatFactory & factory)
|
||||
const FormatSettings & settings)
|
||||
{
|
||||
return std::make_shared<ProtobufListInputFormat>(buf, sample, std::move(params),
|
||||
FormatSchemaInfo(settings, "Protobuf", true), settings.protobuf.input_flatten_google_wrappers);
|
||||
ProtobufSchemaInfo(settings, "Protobuf", sample, settings.protobuf.use_autogenerated_schema), settings.protobuf.input_flatten_google_wrappers);
|
||||
});
|
||||
factory.markFormatSupportsSubsetOfColumns("ProtobufList");
|
||||
factory.registerAdditionalInfoForSchemaCacheGetter(
|
||||
|
||||
@ -28,7 +28,7 @@ public:
|
||||
ReadBuffer & in_,
|
||||
const Block & header_,
|
||||
const Params & params_,
|
||||
const FormatSchemaInfo & schema_info_,
|
||||
const ProtobufSchemaInfo & schema_info_,
|
||||
bool flatten_google_wrappers_);
|
||||
|
||||
String getName() const override { return "ProtobufListInputFormat"; }
|
||||
|
||||
@ -2,7 +2,6 @@
|
||||
|
||||
#if USE_PROTOBUF
|
||||
# include <Formats/FormatFactory.h>
|
||||
# include <Formats/FormatSchemaInfo.h>
|
||||
# include <Formats/ProtobufWriter.h>
|
||||
# include <Formats/ProtobufSerializer.h>
|
||||
# include <Formats/ProtobufSchemas.h>
|
||||
@ -13,14 +12,14 @@ namespace DB
|
||||
ProtobufListOutputFormat::ProtobufListOutputFormat(
|
||||
WriteBuffer & out_,
|
||||
const Block & header_,
|
||||
const FormatSchemaInfo & schema_info_,
|
||||
const ProtobufSchemaInfo & schema_info_,
|
||||
bool defaults_for_nullable_google_wrappers_)
|
||||
: IRowOutputFormat(header_, out_)
|
||||
, writer(std::make_unique<ProtobufWriter>(out))
|
||||
, serializer(ProtobufSerializer::create(
|
||||
header_.getNames(),
|
||||
header_.getDataTypes(),
|
||||
*ProtobufSchemas::instance().getMessageTypeForFormatSchema(schema_info_, ProtobufSchemas::WithEnvelope::Yes),
|
||||
*ProtobufSchemas::instance().getMessageTypeForFormatSchema(schema_info_.getSchemaInfo(), ProtobufSchemas::WithEnvelope::Yes),
|
||||
/* with_length_delimiter = */ true,
|
||||
/* with_envelope = */ true,
|
||||
defaults_for_nullable_google_wrappers_,
|
||||
@ -55,7 +54,7 @@ void registerOutputFormatProtobufList(FormatFactory & factory)
|
||||
const FormatSettings & settings)
|
||||
{
|
||||
return std::make_shared<ProtobufListOutputFormat>(
|
||||
buf, header, FormatSchemaInfo(settings, "Protobuf", true),
|
||||
buf, header, ProtobufSchemaInfo(settings, "Protobuf", header, settings.protobuf.use_autogenerated_schema),
|
||||
settings.protobuf.output_nullables_with_google_wrappers);
|
||||
});
|
||||
}
|
||||
|
||||
@ -4,10 +4,10 @@
|
||||
|
||||
#if USE_PROTOBUF
|
||||
# include <Processors/Formats/IRowOutputFormat.h>
|
||||
# include <Formats/FormatSchemaInfo.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
class FormatSchemaInfo;
|
||||
class ProtobufWriter;
|
||||
class ProtobufSerializer;
|
||||
|
||||
@ -26,7 +26,7 @@ public:
|
||||
ProtobufListOutputFormat(
|
||||
WriteBuffer & out_,
|
||||
const Block & header_,
|
||||
const FormatSchemaInfo & schema_info_,
|
||||
const ProtobufSchemaInfo & schema_info_,
|
||||
bool defaults_for_nullable_google_wrappers_);
|
||||
|
||||
String getName() const override { return "ProtobufListOutputFormat"; }
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user