mirror of
https://github.com/ClickHouse/ClickHouse.git
synced 2024-11-26 17:41:59 +00:00
Merge branch 'master' into async-loader-integration
This commit is contained in:
commit
432d359a2b
@ -8,6 +8,7 @@
|
||||
#include <functional>
|
||||
#include <iosfwd>
|
||||
|
||||
#include <base/defines.h>
|
||||
#include <base/types.h>
|
||||
#include <base/unaligned.h>
|
||||
|
||||
@ -274,6 +275,8 @@ struct CRC32Hash
|
||||
if (size == 0)
|
||||
return 0;
|
||||
|
||||
chassert(pos);
|
||||
|
||||
if (size < 8)
|
||||
{
|
||||
return static_cast<unsigned>(hashLessThan8(x.data, x.size));
|
||||
|
||||
@ -115,8 +115,15 @@
|
||||
/// because SIGABRT is easier to debug than SIGTRAP (the second one makes gdb crazy)
|
||||
#if !defined(chassert)
|
||||
#if defined(ABORT_ON_LOGICAL_ERROR)
|
||||
// clang-format off
|
||||
#include <base/types.h>
|
||||
namespace DB
|
||||
{
|
||||
void abortOnFailedAssertion(const String & description);
|
||||
}
|
||||
#define chassert(x) static_cast<bool>(x) ? void(0) : ::DB::abortOnFailedAssertion(#x)
|
||||
#define UNREACHABLE() abort()
|
||||
// clang-format off
|
||||
#else
|
||||
/// Here sizeof() trick is used to suppress unused warning for result,
|
||||
/// since simple "(void)x" will evaluate the expression, while
|
||||
|
||||
@ -57,7 +57,7 @@ public:
|
||||
URI();
|
||||
/// Creates an empty URI.
|
||||
|
||||
explicit URI(const std::string & uri, bool disable_url_encoding = false);
|
||||
explicit URI(const std::string & uri, bool enable_url_encoding = true);
|
||||
/// Parses an URI from the given string. Throws a
|
||||
/// SyntaxException if the uri is not valid.
|
||||
|
||||
@ -362,7 +362,7 @@ private:
|
||||
std::string _query;
|
||||
std::string _fragment;
|
||||
|
||||
bool _disable_url_encoding = false;
|
||||
bool _enable_url_encoding = true;
|
||||
};
|
||||
|
||||
|
||||
|
||||
@ -36,8 +36,8 @@ URI::URI():
|
||||
}
|
||||
|
||||
|
||||
URI::URI(const std::string& uri, bool decode_and_encode_path):
|
||||
_port(0), _disable_url_encoding(decode_and_encode_path)
|
||||
URI::URI(const std::string& uri, bool enable_url_encoding):
|
||||
_port(0), _enable_url_encoding(enable_url_encoding)
|
||||
{
|
||||
parse(uri);
|
||||
}
|
||||
@ -108,7 +108,7 @@ URI::URI(const URI& uri):
|
||||
_path(uri._path),
|
||||
_query(uri._query),
|
||||
_fragment(uri._fragment),
|
||||
_disable_url_encoding(uri._disable_url_encoding)
|
||||
_enable_url_encoding(uri._enable_url_encoding)
|
||||
{
|
||||
}
|
||||
|
||||
@ -121,7 +121,7 @@ URI::URI(const URI& baseURI, const std::string& relativeURI):
|
||||
_path(baseURI._path),
|
||||
_query(baseURI._query),
|
||||
_fragment(baseURI._fragment),
|
||||
_disable_url_encoding(baseURI._disable_url_encoding)
|
||||
_enable_url_encoding(baseURI._enable_url_encoding)
|
||||
{
|
||||
resolve(relativeURI);
|
||||
}
|
||||
@ -153,7 +153,7 @@ URI& URI::operator = (const URI& uri)
|
||||
_path = uri._path;
|
||||
_query = uri._query;
|
||||
_fragment = uri._fragment;
|
||||
_disable_url_encoding = uri._disable_url_encoding;
|
||||
_enable_url_encoding = uri._enable_url_encoding;
|
||||
}
|
||||
return *this;
|
||||
}
|
||||
@ -184,7 +184,7 @@ void URI::swap(URI& uri)
|
||||
std::swap(_path, uri._path);
|
||||
std::swap(_query, uri._query);
|
||||
std::swap(_fragment, uri._fragment);
|
||||
std::swap(_disable_url_encoding, uri._disable_url_encoding);
|
||||
std::swap(_enable_url_encoding, uri._enable_url_encoding);
|
||||
}
|
||||
|
||||
|
||||
@ -687,18 +687,18 @@ void URI::decode(const std::string& str, std::string& decodedStr, bool plusAsSpa
|
||||
|
||||
void URI::encodePath(std::string & encodedStr) const
|
||||
{
|
||||
if (_disable_url_encoding)
|
||||
encodedStr = _path;
|
||||
else
|
||||
if (_enable_url_encoding)
|
||||
encode(_path, RESERVED_PATH, encodedStr);
|
||||
else
|
||||
encodedStr = _path;
|
||||
}
|
||||
|
||||
void URI::decodePath(const std::string & encodedStr)
|
||||
{
|
||||
if (_disable_url_encoding)
|
||||
_path = encodedStr;
|
||||
else
|
||||
if (_enable_url_encoding)
|
||||
decode(encodedStr, _path);
|
||||
else
|
||||
_path = encodedStr;
|
||||
}
|
||||
|
||||
bool URI::isWellKnownPort() const
|
||||
|
||||
@ -17,7 +17,8 @@
|
||||
#ifndef METROHASH_PLATFORM_H
|
||||
#define METROHASH_PLATFORM_H
|
||||
|
||||
#include <stdint.h>
|
||||
#include <bit>
|
||||
#include <cstdint>
|
||||
#include <cstring>
|
||||
|
||||
// rotate right idiom recognized by most compilers
|
||||
@ -33,6 +34,11 @@ inline static uint64_t read_u64(const void * const ptr)
|
||||
// so we use memcpy() which is the most portable. clang & gcc usually translates `memcpy()` into a single `load` instruction
|
||||
// when hardware supports it, so using memcpy() is efficient too.
|
||||
memcpy(&result, ptr, sizeof(result));
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
result = std::byteswap(result);
|
||||
#endif
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
@ -40,6 +46,11 @@ inline static uint64_t read_u32(const void * const ptr)
|
||||
{
|
||||
uint32_t result;
|
||||
memcpy(&result, ptr, sizeof(result));
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
result = std::byteswap(result);
|
||||
#endif
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
@ -47,6 +58,11 @@ inline static uint64_t read_u16(const void * const ptr)
|
||||
{
|
||||
uint16_t result;
|
||||
memcpy(&result, ptr, sizeof(result));
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
result = std::byteswap(result);
|
||||
#endif
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
|
||||
@ -32,7 +32,7 @@ RUN arch=${TARGETARCH:-amd64} \
|
||||
esac
|
||||
|
||||
ARG REPOSITORY="https://s3.amazonaws.com/clickhouse-builds/22.4/31c367d3cd3aefd316778601ff6565119fe36682/package_release"
|
||||
ARG VERSION="23.7.1.2470"
|
||||
ARG VERSION="23.7.2.25"
|
||||
ARG PACKAGES="clickhouse-keeper"
|
||||
|
||||
# user/group precreated explicitly with fixed uid/gid on purpose.
|
||||
|
||||
@ -6,7 +6,7 @@ Usage:
|
||||
Build deb package with `clang-14` in `debug` mode:
|
||||
```
|
||||
$ mkdir deb/test_output
|
||||
$ ./packager --output-dir deb/test_output/ --package-type deb --compiler=clang-14 --build-type=debug
|
||||
$ ./packager --output-dir deb/test_output/ --package-type deb --compiler=clang-14 --debug-build
|
||||
$ ls -l deb/test_output
|
||||
-rw-r--r-- 1 root root 3730 clickhouse-client_22.2.2+debug_all.deb
|
||||
-rw-r--r-- 1 root root 84221888 clickhouse-common-static_22.2.2+debug_amd64.deb
|
||||
|
||||
@ -112,12 +112,12 @@ def run_docker_image_with_env(
|
||||
subprocess.check_call(cmd, shell=True)
|
||||
|
||||
|
||||
def is_release_build(build_type: str, package_type: str, sanitizer: str) -> bool:
|
||||
return build_type == "" and package_type == "deb" and sanitizer == ""
|
||||
def is_release_build(debug_build: bool, package_type: str, sanitizer: str) -> bool:
|
||||
return not debug_build and package_type == "deb" and sanitizer == ""
|
||||
|
||||
|
||||
def parse_env_variables(
|
||||
build_type: str,
|
||||
debug_build: bool,
|
||||
compiler: str,
|
||||
sanitizer: str,
|
||||
package_type: str,
|
||||
@ -240,7 +240,7 @@ def parse_env_variables(
|
||||
build_target = (
|
||||
f"{build_target} clickhouse-odbc-bridge clickhouse-library-bridge"
|
||||
)
|
||||
if is_release_build(build_type, package_type, sanitizer):
|
||||
if is_release_build(debug_build, package_type, sanitizer):
|
||||
cmake_flags.append("-DSPLIT_DEBUG_SYMBOLS=ON")
|
||||
result.append("WITH_PERFORMANCE=1")
|
||||
if is_cross_arm:
|
||||
@ -255,8 +255,8 @@ def parse_env_variables(
|
||||
|
||||
if sanitizer:
|
||||
result.append(f"SANITIZER={sanitizer}")
|
||||
if build_type:
|
||||
result.append(f"BUILD_TYPE={build_type.capitalize()}")
|
||||
if debug_build:
|
||||
result.append("BUILD_TYPE=Debug")
|
||||
else:
|
||||
result.append("BUILD_TYPE=None")
|
||||
|
||||
@ -361,7 +361,7 @@ def parse_args() -> argparse.Namespace:
|
||||
help="ClickHouse git repository",
|
||||
)
|
||||
parser.add_argument("--output-dir", type=dir_name, required=True)
|
||||
parser.add_argument("--build-type", choices=("debug", ""), default="")
|
||||
parser.add_argument("--debug-build", action="store_true")
|
||||
|
||||
parser.add_argument(
|
||||
"--compiler",
|
||||
@ -467,7 +467,7 @@ def main():
|
||||
build_image(image_with_version, dockerfile)
|
||||
|
||||
env_prepared = parse_env_variables(
|
||||
args.build_type,
|
||||
args.debug_build,
|
||||
args.compiler,
|
||||
args.sanitizer,
|
||||
args.package_type,
|
||||
|
||||
@ -33,7 +33,7 @@ RUN arch=${TARGETARCH:-amd64} \
|
||||
# lts / testing / prestable / etc
|
||||
ARG REPO_CHANNEL="stable"
|
||||
ARG REPOSITORY="https://packages.clickhouse.com/tgz/${REPO_CHANNEL}"
|
||||
ARG VERSION="23.7.1.2470"
|
||||
ARG VERSION="23.7.2.25"
|
||||
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
||||
|
||||
# user/group precreated explicitly with fixed uid/gid on purpose.
|
||||
|
||||
@ -23,7 +23,7 @@ RUN sed -i "s|http://archive.ubuntu.com|${apt_archive}|g" /etc/apt/sources.list
|
||||
|
||||
ARG REPO_CHANNEL="stable"
|
||||
ARG REPOSITORY="deb [signed-by=/usr/share/keyrings/clickhouse-keyring.gpg] https://packages.clickhouse.com/deb ${REPO_CHANNEL} main"
|
||||
ARG VERSION="23.7.1.2470"
|
||||
ARG VERSION="23.7.2.25"
|
||||
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
||||
|
||||
# set non-empty deb_location_url url to create a docker image
|
||||
|
||||
@ -95,6 +95,7 @@ RUN python3 -m pip install --no-cache-dir \
|
||||
pytest-timeout \
|
||||
pytest-xdist \
|
||||
pytz \
|
||||
pyyaml==5.3.1 \
|
||||
redis \
|
||||
requests-kerberos \
|
||||
tzlocal==2.1 \
|
||||
|
||||
@ -200,8 +200,8 @@ Templates:
|
||||
- [Server Setting](_description_templates/template-server-setting.md)
|
||||
- [Database or Table engine](_description_templates/template-engine.md)
|
||||
- [System table](_description_templates/template-system-table.md)
|
||||
- [Data type](_description_templates/data-type.md)
|
||||
- [Statement](_description_templates/statement.md)
|
||||
- [Data type](_description_templates/template-data-type.md)
|
||||
- [Statement](_description_templates/template-statement.md)
|
||||
|
||||
|
||||
<a name="how-to-build-docs"/>
|
||||
|
||||
31
docs/changelogs/v23.7.2.25-stable.md
Normal file
31
docs/changelogs/v23.7.2.25-stable.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_label: 2023
|
||||
---
|
||||
|
||||
# 2023 Changelog
|
||||
|
||||
### ClickHouse release v23.7.2.25-stable (8dd1107b032) FIXME as compared to v23.7.1.2470-stable (a70127baecc)
|
||||
|
||||
#### Backward Incompatible Change
|
||||
* Backported in [#52850](https://github.com/ClickHouse/ClickHouse/issues/52850): If a dynamic disk contains a name, it should be specified as `disk = disk(name = 'disk_name'`, ...) in disk function arguments. In previous version it could be specified as `disk = disk_<disk_name>(...)`, which is no longer supported. [#52820](https://github.com/ClickHouse/ClickHouse/pull/52820) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
|
||||
#### Build/Testing/Packaging Improvement
|
||||
* Backported in [#52913](https://github.com/ClickHouse/ClickHouse/issues/52913): Add `clickhouse-keeper-client` symlink to the clickhouse-server package. [#51882](https://github.com/ClickHouse/ClickHouse/pull/51882) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
|
||||
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||
|
||||
* Fix binary arithmetic for Nullable(IPv4) [#51642](https://github.com/ClickHouse/ClickHouse/pull/51642) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Support IPv4 and IPv6 as dictionary attributes [#51756](https://github.com/ClickHouse/ClickHouse/pull/51756) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* init and destroy ares channel on demand.. [#52634](https://github.com/ClickHouse/ClickHouse/pull/52634) ([Arthur Passos](https://github.com/arthurpassos)).
|
||||
* Fix crash in function `tuple` with one sparse column argument [#52659](https://github.com/ClickHouse/ClickHouse/pull/52659) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Fix data race in Keeper reconfiguration [#52804](https://github.com/ClickHouse/ClickHouse/pull/52804) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* clickhouse-keeper: fix implementation of server with poll() [#52833](https://github.com/ClickHouse/ClickHouse/pull/52833) ([Andy Fiddaman](https://github.com/citrus-it)).
|
||||
|
||||
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||
|
||||
* Rename setting disable_url_encoding to enable_url_encoding and add a test [#52656](https://github.com/ClickHouse/ClickHouse/pull/52656) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix bugs and better test for SYSTEM STOP LISTEN [#52680](https://github.com/ClickHouse/ClickHouse/pull/52680) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Increase min protocol version for sparse serialization [#52835](https://github.com/ClickHouse/ClickHouse/pull/52835) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Docker improvements [#52869](https://github.com/ClickHouse/ClickHouse/pull/52869) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
|
||||
@ -14,6 +14,20 @@ Supported platforms:
|
||||
- PowerPC 64 LE (experimental)
|
||||
- RISC-V 64 (experimental)
|
||||
|
||||
## Building in docker
|
||||
We use the docker image `clickhouse/binary-builder` for our CI builds. It contains everything necessary to build the binary and packages. There is a script `docker/packager/packager` to ease the image usage:
|
||||
|
||||
```bash
|
||||
# define a directory for the output artifacts
|
||||
output_dir="build_results"
|
||||
# a simplest build
|
||||
./docker/packager/packager --package-type=binary --output-dir "$output_dir"
|
||||
# build debian packages
|
||||
./docker/packager/packager --package-type=deb --output-dir "$output_dir"
|
||||
# by default, debian packages use thin LTO, so we can override it to speed up the build
|
||||
CMAKE_FLAGS='-DENABLE_THINLTO=' ./docker/packager/packager --package-type=deb --output-dir "./$(git rev-parse --show-cdup)/build_results"
|
||||
```
|
||||
|
||||
## Building on Ubuntu
|
||||
|
||||
The following tutorial is based on Ubuntu Linux.
|
||||
|
||||
@ -141,6 +141,10 @@ Runs [stateful functional tests](tests.md#functional-tests). Treat them in the s
|
||||
Runs [integration tests](tests.md#integration-tests).
|
||||
|
||||
|
||||
## Bugfix validate check
|
||||
Checks that either a new test (functional or integration) or there some changed tests that fail with the binary built on master branch. This check is triggered when pull request has "pr-bugfix" label.
|
||||
|
||||
|
||||
## Stress Test
|
||||
Runs stateless functional tests concurrently from several clients to detect
|
||||
concurrency-related errors. If it fails:
|
||||
|
||||
@ -35,7 +35,7 @@ The [system.clusters](../../operations/system-tables/clusters.md) system table c
|
||||
|
||||
When creating a new replica of the database, this replica creates tables by itself. If the replica has been unavailable for a long time and has lagged behind the replication log — it checks its local metadata with the current metadata in ZooKeeper, moves the extra tables with data to a separate non-replicated database (so as not to accidentally delete anything superfluous), creates the missing tables, updates the table names if they have been renamed. The data is replicated at the `ReplicatedMergeTree` level, i.e. if the table is not replicated, the data will not be replicated (the database is responsible only for metadata).
|
||||
|
||||
[`ALTER TABLE ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
||||
[`ALTER TABLE FREEZE|ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
||||
|
||||
## Usage Example {#usage-example}
|
||||
|
||||
|
||||
@ -60,6 +60,7 @@ Engines in the family:
|
||||
- [EmbeddedRocksDB](../../engines/table-engines/integrations/embedded-rocksdb.md)
|
||||
- [RabbitMQ](../../engines/table-engines/integrations/rabbitmq.md)
|
||||
- [PostgreSQL](../../engines/table-engines/integrations/postgresql.md)
|
||||
- [S3Queue](../../engines/table-engines/integrations/s3queue.md)
|
||||
|
||||
### Special Engines {#special-engines}
|
||||
|
||||
|
||||
@ -22,7 +22,7 @@ CREATE TABLE deltalake
|
||||
- `url` — Bucket url with path to the existing Delta Lake table.
|
||||
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file.
|
||||
|
||||
Engine parameters can be specified using [Named Collections](../../../operations/named-collections.md)
|
||||
Engine parameters can be specified using [Named Collections](/docs/en/operations/named-collections.md).
|
||||
|
||||
**Example**
|
||||
|
||||
|
||||
@ -22,7 +22,7 @@ CREATE TABLE hudi_table
|
||||
- `url` — Bucket url with the path to an existing Hudi table.
|
||||
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file.
|
||||
|
||||
Engine parameters can be specified using [Named Collections](../../../operations/named-collections.md)
|
||||
Engine parameters can be specified using [Named Collections](/docs/en/operations/named-collections.md).
|
||||
|
||||
**Example**
|
||||
|
||||
|
||||
@ -237,7 +237,7 @@ The following settings can be set before query execution or placed into configur
|
||||
- `s3_max_get_rps` — Maximum GET requests per second rate before throttling. Default value is `0` (unlimited).
|
||||
- `s3_max_get_burst` — Max number of requests that can be issued simultaneously before hitting request per second limit. By default (`0` value) equals to `s3_max_get_rps`.
|
||||
- `s3_upload_part_size_multiply_factor` - Multiply `s3_min_upload_part_size` by this factor each time `s3_multiply_parts_count_threshold` parts were uploaded from a single write to S3. Default values is `2`.
|
||||
- `s3_upload_part_size_multiply_parts_count_threshold` - Each time this number of parts was uploaded to S3 `s3_min_upload_part_size multiplied` by `s3_upload_part_size_multiply_factor`. Default value us `500`.
|
||||
- `s3_upload_part_size_multiply_parts_count_threshold` - Each time this number of parts was uploaded to S3, `s3_min_upload_part_size` is multiplied by `s3_upload_part_size_multiply_factor`. Default value is `500`.
|
||||
- `s3_max_inflight_parts_for_one_file` - Limits the number of put requests that can be run concurrently for one object. Its number should be limited. The value `0` means unlimited. Default value is `20`. Each in-flight part has a buffer with size `s3_min_upload_part_size` for the first `s3_upload_part_size_multiply_factor` parts and more when file is big enough, see `upload_part_size_multiply_factor`. With default settings one uploaded file consumes not more than `320Mb` for a file which is less than `8G`. The consumption is greater for a larger file.
|
||||
|
||||
Security consideration: if malicious user can specify arbitrary S3 URLs, `s3_max_redirects` must be set to zero to avoid [SSRF](https://en.wikipedia.org/wiki/Server-side_request_forgery) attacks; or alternatively, `remote_host_filter` must be specified in server configuration.
|
||||
|
||||
224
docs/en/engines/table-engines/integrations/s3queue.md
Normal file
224
docs/en/engines/table-engines/integrations/s3queue.md
Normal file
@ -0,0 +1,224 @@
|
||||
---
|
||||
slug: /en/engines/table-engines/integrations/s3queue
|
||||
sidebar_position: 7
|
||||
sidebar_label: S3Queue
|
||||
---
|
||||
|
||||
# S3Queue Table Engine
|
||||
This engine provides integration with [Amazon S3](https://aws.amazon.com/s3/) ecosystem and allows streaming import. This engine is similar to the [Kafka](../../../engines/table-engines/integrations/kafka.md), [RabbitMQ](../../../engines/table-engines/integrations/rabbitmq.md) engines, but provides S3-specific features.
|
||||
|
||||
## Create Table {#creating-a-table}
|
||||
|
||||
``` sql
|
||||
CREATE TABLE s3_queue_engine_table (name String, value UInt32)
|
||||
ENGINE = S3Queue(path [, NOSIGN | aws_access_key_id, aws_secret_access_key,] format, [compression])
|
||||
[SETTINGS]
|
||||
[mode = 'unordered',]
|
||||
[after_processing = 'keep',]
|
||||
[keeper_path = '',]
|
||||
[s3queue_loading_retries = 0,]
|
||||
[s3queue_polling_min_timeout_ms = 1000,]
|
||||
[s3queue_polling_max_timeout_ms = 10000,]
|
||||
[s3queue_polling_backoff_ms = 0,]
|
||||
[s3queue_tracked_files_limit = 1000,]
|
||||
[s3queue_tracked_file_ttl_sec = 0,]
|
||||
[s3queue_polling_size = 50,]
|
||||
```
|
||||
|
||||
**Engine parameters**
|
||||
|
||||
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings. For more information see [below](#wildcards-in-path).
|
||||
- `NOSIGN` - If this keyword is provided in place of credentials, all the requests will not be signed.
|
||||
- `format` — The [format](../../../interfaces/formats.md#formats) of the file.
|
||||
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file. For more information see [Using S3 for Data Storage](../mergetree-family/mergetree.md#table_engine-mergetree-s3).
|
||||
- `compression` — Compression type. Supported values: `none`, `gzip/gz`, `brotli/br`, `xz/LZMA`, `zstd/zst`. Parameter is optional. By default, it will autodetect compression by file extension.
|
||||
|
||||
**Example**
|
||||
|
||||
```sql
|
||||
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||
ENGINE=S3Queue('https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*', 'CSV', 'gzip')
|
||||
SETTINGS
|
||||
mode = 'ordred';
|
||||
```
|
||||
|
||||
Using named collections:
|
||||
|
||||
``` xml
|
||||
<clickhouse>
|
||||
<named_collections>
|
||||
<s3queue_conf>
|
||||
<url>'https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*</url>
|
||||
<access_key_id>test<access_key_id>
|
||||
<secret_access_key>test</secret_access_key>
|
||||
</s3queue_conf>
|
||||
</named_collections>
|
||||
</clickhouse>
|
||||
```
|
||||
|
||||
```sql
|
||||
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||
ENGINE=S3Queue(s3queue_conf, format = 'CSV', compression_method = 'gzip')
|
||||
SETTINGS
|
||||
mode = 'ordred';
|
||||
```
|
||||
|
||||
## Settings {#s3queue-settings}
|
||||
|
||||
### mode {#mode}
|
||||
|
||||
Possible values:
|
||||
|
||||
- unordered — With unordered mode, the set of all already processed files is tracked with persistent nodes in ZooKeeper.
|
||||
- ordered — With ordered mode, only the max name of the successfully consumed file, and the names of files that will be retried after unsuccessful loading attempt are being stored in ZooKeeper.
|
||||
|
||||
Default value: `unordered`.
|
||||
|
||||
### after_processing {#after_processing}
|
||||
|
||||
Delete or keep file after successful processing.
|
||||
Possible values:
|
||||
|
||||
- keep.
|
||||
- delete.
|
||||
|
||||
Default value: `keep`.
|
||||
|
||||
### keeper_path {#keeper_path}
|
||||
|
||||
The path in ZooKeeper can be specified as a table engine setting or default path can be formed from the global configuration-provided path and table UUID.
|
||||
Possible values:
|
||||
|
||||
- String.
|
||||
|
||||
Default value: `/`.
|
||||
|
||||
### s3queue_loading_retries {#s3queue_loading_retries}
|
||||
|
||||
Retry file loading up to specified number of times. By default, there are no retries.
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### s3queue_polling_min_timeout_ms {#s3queue_polling_min_timeout_ms}
|
||||
|
||||
Minimal timeout before next polling (in milliseconds).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `1000`.
|
||||
|
||||
### s3queue_polling_max_timeout_ms {#s3queue_polling_max_timeout_ms}
|
||||
|
||||
Maximum timeout before next polling (in milliseconds).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `10000`.
|
||||
|
||||
### s3queue_polling_backoff_ms {#s3queue_polling_backoff_ms}
|
||||
|
||||
Polling backoff (in milliseconds).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### s3queue_tracked_files_limit {#s3queue_tracked_files_limit}
|
||||
|
||||
Allows to limit the number of Zookeeper nodes if the 'unordered' mode is used, does nothing for 'ordered' mode.
|
||||
If limit reached the oldest processed files will be deleted from ZooKeeper node and processed again.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `1000`.
|
||||
|
||||
### s3queue_tracked_file_ttl_sec {#s3queue_tracked_file_ttl_sec}
|
||||
|
||||
Maximum number of seconds to store processed files in ZooKeeper node (store forever by default) for 'unordered' mode, does nothing for 'ordered' mode.
|
||||
After the specified number of seconds, the file will be re-imported.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### s3queue_polling_size {#s3queue_polling_size}
|
||||
|
||||
Maximum files to fetch from S3 with SELECT or in background task.
|
||||
Engine takes files for processing from S3 in batches.
|
||||
We limit the batch size to increase concurrency if multiple table engines with the same `keeper_path` consume files from the same path.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `50`.
|
||||
|
||||
|
||||
## S3-related Settings {#s3-settings}
|
||||
|
||||
Engine supports all s3 related settings. For more information about S3 settings see [here](../../../engines/table-engines/integrations/s3.md).
|
||||
|
||||
|
||||
## Description {#description}
|
||||
|
||||
`SELECT` is not particularly useful for streaming import (except for debugging), because each file can be imported only once. It is more practical to create real-time threads using [materialized views](../../../sql-reference/statements/create/view.md). To do this:
|
||||
|
||||
1. Use the engine to create a table for consuming from specified path in S3 and consider it a data stream.
|
||||
2. Create a table with the desired structure.
|
||||
3. Create a materialized view that converts data from the engine and puts it into a previously created table.
|
||||
|
||||
When the `MATERIALIZED VIEW` joins the engine, it starts collecting data in the background.
|
||||
|
||||
Example:
|
||||
|
||||
``` sql
|
||||
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||
ENGINE=S3Queue('https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*', 'CSV', 'gzip')
|
||||
SETTINGS
|
||||
mode = 'unordred',
|
||||
keeper_path = '/clickhouse/s3queue/';
|
||||
|
||||
CREATE TABLE stats (name String, value UInt32)
|
||||
ENGINE = MergeTree() ORDER BY name;
|
||||
|
||||
CREATE MATERIALIZED VIEW consumer TO stats
|
||||
AS SELECT name, value FROM s3queue_engine_table;
|
||||
|
||||
SELECT * FROM stats ORDER BY name;
|
||||
```
|
||||
|
||||
## Virtual columns {#virtual-columns}
|
||||
|
||||
- `_path` — Path to the file.
|
||||
- `_file` — Name of the file.
|
||||
|
||||
For more information about virtual columns see [here](../../../engines/table-engines/index.md#table_engines-virtual_columns).
|
||||
|
||||
|
||||
## Wildcards In Path {#wildcards-in-path}
|
||||
|
||||
`path` argument can specify multiple files using bash-like wildcards. For being processed file should exist and match to the whole path pattern. Listing of files is determined during `SELECT` (not at `CREATE` moment).
|
||||
|
||||
- `*` — Substitutes any number of any characters except `/` including empty string.
|
||||
- `?` — Substitutes any single character.
|
||||
- `{some_string,another_string,yet_another_one}` — Substitutes any of strings `'some_string', 'another_string', 'yet_another_one'`.
|
||||
- `{N..M}` — Substitutes any number in range from N to M including both borders. N and M can have leading zeroes e.g. `000..078`.
|
||||
|
||||
Constructions with `{}` are similar to the [remote](../../../sql-reference/table-functions/remote.md) table function.
|
||||
|
||||
:::note
|
||||
If the listing of files contains number ranges with leading zeros, use the construction with braces for each digit separately or use `?`.
|
||||
:::
|
||||
@ -193,6 +193,19 @@ index creation, `L2Distance` is used as default. Parameter `NumTrees` is the num
|
||||
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
||||
linearly) as well as larger index sizes.
|
||||
|
||||
`L2Distance` is also called Euclidean distance, the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points.
|
||||
For example: If we have point P(p1,p2), Q(q1,q2), their distance will be d(p,q)
|
||||

|
||||
|
||||
`cosineDistance` also called cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths.
|
||||
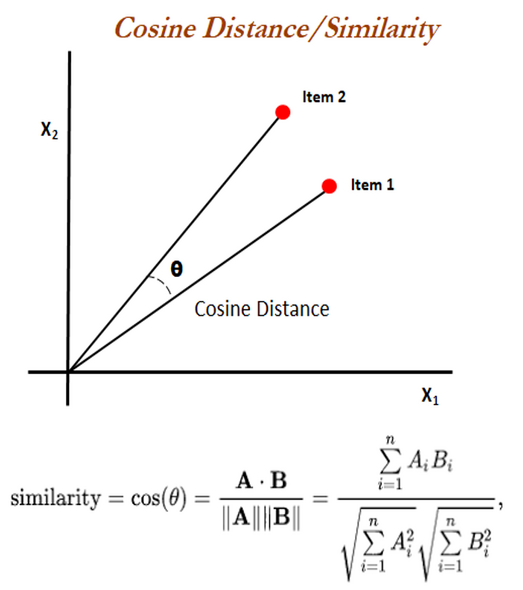
|
||||
|
||||
The Euclidean distance corresponds to the L2-norm of a difference between vectors. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
|
||||

|
||||
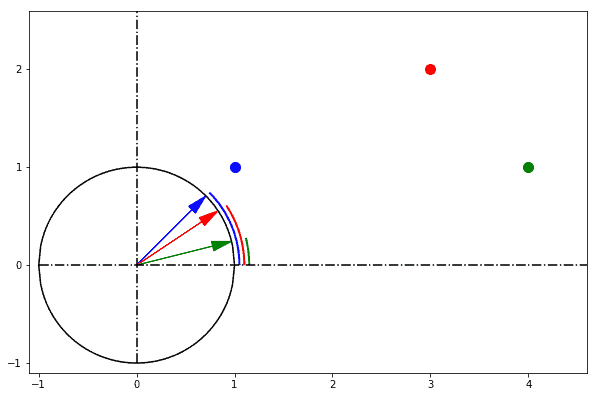
In one sentence: cosine similarity care only about the angle between them, but do not care about the "distance" we normally think.
|
||||
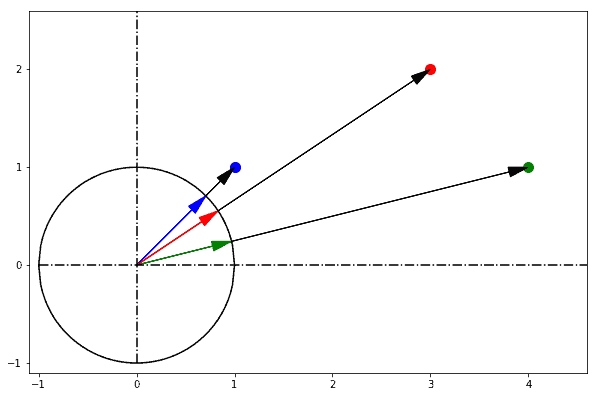
|
||||
|
||||
|
||||
:::note
|
||||
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
||||
[CONSTRAINT](/docs/en/sql-reference/statements/create/table.md#constraints) to avoid errors. For example, `CONSTRAINT constraint_name_1
|
||||
|
||||
@ -106,4 +106,4 @@ For partitioning by month, use the `toYYYYMM(date_column)` expression, where `da
|
||||
## Storage Settings {#storage-settings}
|
||||
|
||||
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
||||
- [disable_url_encoding](/docs/en/operations/settings/settings.md#disable_url_encoding) -allows to disable decoding/encoding path in uri. Disabled by default.
|
||||
- [enable_url_encoding](/docs/en/operations/settings/settings.md#enable_url_encoding) - allows to enable/disable decoding/encoding path in uri. Enabled by default.
|
||||
|
||||
@ -1723,6 +1723,34 @@ You can select data from a ClickHouse table and save them into some file in the
|
||||
``` bash
|
||||
$ clickhouse-client --query = "SELECT * FROM test.hits FORMAT CapnProto SETTINGS format_schema = 'schema:Message'"
|
||||
```
|
||||
|
||||
### Using autogenerated schema {#using-autogenerated-capn-proto-schema}
|
||||
|
||||
If you don't have an external CapnProto schema for your data, you can still output/input data in CapnProto format using autogenerated schema.
|
||||
For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format CapnProto SETTINGS format_capn_proto_use_autogenerated_schema=1
|
||||
```
|
||||
|
||||
In this case ClickHouse will autogenerate CapnProto schema according to the table structure using function [structureToCapnProtoSchema](../sql-reference/functions/other-functions.md#structure_to_capn_proto_schema) and will use this schema to serialize data in CapnProto format.
|
||||
|
||||
You can also read CapnProto file with autogenerated schema (in this case the file must be created using the same schema):
|
||||
|
||||
```bash
|
||||
$ cat hits.bin | clickhouse-client --query "INSERT INTO test.hits SETTINGS format_capn_proto_use_autogenerated_schema=1 FORMAT CapnProto"
|
||||
```
|
||||
|
||||
The setting [format_capn_proto_use_autogenerated_schema](../operations/settings/settings-formats.md#format_capn_proto_use_autogenerated_schema) is enabled by default and applies if [format_schema](../operations/settings/settings-formats.md#formatschema-format-schema) is not set.
|
||||
|
||||
You can also save autogenerated schema in the file during input/output using setting [output_format_schema](../operations/settings/settings-formats.md#outputformatschema-output-format-schema). For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format CapnProto SETTINGS format_capn_proto_use_autogenerated_schema=1, output_format_schema='path/to/schema/schema.capnp'
|
||||
```
|
||||
|
||||
In this case autogenerated CapnProto schema will be saved in file `path/to/schema/schema.capnp`.
|
||||
|
||||
## Prometheus {#prometheus}
|
||||
|
||||
Expose metrics in [Prometheus text-based exposition format](https://prometheus.io/docs/instrumenting/exposition_formats/#text-based-format).
|
||||
@ -1861,6 +1889,33 @@ ClickHouse inputs and outputs protobuf messages in the `length-delimited` format
|
||||
It means before every message should be written its length as a [varint](https://developers.google.com/protocol-buffers/docs/encoding#varints).
|
||||
See also [how to read/write length-delimited protobuf messages in popular languages](https://cwiki.apache.org/confluence/display/GEODE/Delimiting+Protobuf+Messages).
|
||||
|
||||
### Using autogenerated schema {#using-autogenerated-protobuf-schema}
|
||||
|
||||
If you don't have an external Protobuf schema for your data, you can still output/input data in Protobuf format using autogenerated schema.
|
||||
For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format Protobuf SETTINGS format_protobuf_use_autogenerated_schema=1
|
||||
```
|
||||
|
||||
In this case ClickHouse will autogenerate Protobuf schema according to the table structure using function [structureToProtobufSchema](../sql-reference/functions/other-functions.md#structure_to_protobuf_schema) and will use this schema to serialize data in Protobuf format.
|
||||
|
||||
You can also read Protobuf file with autogenerated schema (in this case the file must be created using the same schema):
|
||||
|
||||
```bash
|
||||
$ cat hits.bin | clickhouse-client --query "INSERT INTO test.hits SETTINGS format_protobuf_use_autogenerated_schema=1 FORMAT Protobuf"
|
||||
```
|
||||
|
||||
The setting [format_protobuf_use_autogenerated_schema](../operations/settings/settings-formats.md#format_protobuf_use_autogenerated_schema) is enabled by default and applies if [format_schema](../operations/settings/settings-formats.md#formatschema-format-schema) is not set.
|
||||
|
||||
You can also save autogenerated schema in the file during input/output using setting [output_format_schema](../operations/settings/settings-formats.md#outputformatschema-output-format-schema). For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format Protobuf SETTINGS format_protobuf_use_autogenerated_schema=1, output_format_schema='path/to/schema/schema.proto'
|
||||
```
|
||||
|
||||
In this case autogenerated Protobuf schema will be saved in file `path/to/schema/schema.capnp`.
|
||||
|
||||
## ProtobufSingle {#protobufsingle}
|
||||
|
||||
Same as [Protobuf](#protobuf) but for storing/parsing single Protobuf message without length delimiters.
|
||||
@ -2076,7 +2131,6 @@ To exchange data with Hadoop, you can use [HDFS table engine](/docs/en/engines/t
|
||||
|
||||
- [output_format_parquet_row_group_size](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_row_group_size) - row group size in rows while data output. Default value - `1000000`.
|
||||
- [output_format_parquet_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_string_as_string) - use Parquet String type instead of Binary for String columns. Default value - `false`.
|
||||
- [input_format_parquet_import_nested](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_import_nested) - allow inserting array of structs into [Nested](/docs/en/sql-reference/data-types/nested-data-structures/index.md) table in Parquet input format. Default value - `false`.
|
||||
- [input_format_parquet_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_case_insensitive_column_matching) - ignore case when matching Parquet columns with ClickHouse columns. Default value - `false`.
|
||||
- [input_format_parquet_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_allow_missing_columns) - allow missing columns while reading Parquet data. Default value - `false`.
|
||||
- [input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Parquet format. Default value - `false`.
|
||||
@ -2281,7 +2335,6 @@ $ clickhouse-client --query="SELECT * FROM {some_table} FORMAT Arrow" > {filenam
|
||||
|
||||
- [output_format_arrow_low_cardinality_as_dictionary](/docs/en/operations/settings/settings-formats.md/#output_format_arrow_low_cardinality_as_dictionary) - enable output ClickHouse LowCardinality type as Dictionary Arrow type. Default value - `false`.
|
||||
- [output_format_arrow_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_arrow_string_as_string) - use Arrow String type instead of Binary for String columns. Default value - `false`.
|
||||
- [input_format_arrow_import_nested](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_import_nested) - allow inserting array of structs into Nested table in Arrow input format. Default value - `false`.
|
||||
- [input_format_arrow_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_case_insensitive_column_matching) - ignore case when matching Arrow columns with ClickHouse columns. Default value - `false`.
|
||||
- [input_format_arrow_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_allow_missing_columns) - allow missing columns while reading Arrow data. Default value - `false`.
|
||||
- [input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Arrow format. Default value - `false`.
|
||||
@ -2347,7 +2400,6 @@ $ clickhouse-client --query="SELECT * FROM {some_table} FORMAT ORC" > {filename.
|
||||
|
||||
- [output_format_arrow_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_arrow_string_as_string) - use Arrow String type instead of Binary for String columns. Default value - `false`.
|
||||
- [output_format_orc_compression_method](/docs/en/operations/settings/settings-formats.md/#output_format_orc_compression_method) - compression method used in output ORC format. Default value - `none`.
|
||||
- [input_format_arrow_import_nested](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_import_nested) - allow inserting array of structs into Nested table in Arrow input format. Default value - `false`.
|
||||
- [input_format_arrow_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_case_insensitive_column_matching) - ignore case when matching Arrow columns with ClickHouse columns. Default value - `false`.
|
||||
- [input_format_arrow_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_allow_missing_columns) - allow missing columns while reading Arrow data. Default value - `false`.
|
||||
- [input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Arrow format. Default value - `false`.
|
||||
|
||||
@ -0,0 +1,26 @@
|
||||
---
|
||||
slug: /en/operations/optimizing-performance/profile-guided-optimization
|
||||
sidebar_position: 54
|
||||
sidebar_label: Profile Guided Optimization (PGO)
|
||||
---
|
||||
import SelfManaged from '@site/docs/en/_snippets/_self_managed_only_no_roadmap.md';
|
||||
|
||||
# Profile Guided Optimization
|
||||
|
||||
Profile-Guided Optimization (PGO) is a compiler optimization technique where a program is optimized based on the runtime profile.
|
||||
|
||||
According to the tests, PGO helps with achieving better performance for ClickHouse. According to the tests, we see improvements up to 15% in QPS on the ClickBench test suite. The more detailed results are available [here](https://pastebin.com/xbue3HMU). The performance benefits depend on your typical workload - you can get better or worse results.
|
||||
|
||||
More information about PGO in ClickHouse you can read in the corresponding GitHub [issue](https://github.com/ClickHouse/ClickHouse/issues/44567).
|
||||
|
||||
## How to build ClickHouse with PGO?
|
||||
|
||||
There are two major kinds of PGO: [Instrumentation](https://clang.llvm.org/docs/UsersManual.html#using-sampling-profilers) and [Sampling](https://clang.llvm.org/docs/UsersManual.html#using-sampling-profilers) (also known as AutoFDO). In this guide is described the Instrumentation PGO with ClickHouse.
|
||||
|
||||
1. Build ClickHouse in Instrumented mode. In Clang it can be done via passing `-fprofile-instr-generate` option to `CXXFLAGS`.
|
||||
2. Run instrumented ClickHouse on a sample workload. Here you need to use your usual workload. One of the approaches could be using [ClickBench](https://github.com/ClickHouse/ClickBench) as a sample workload. ClickHouse in the instrumentation mode could work slowly so be ready for that and do not run instrumented ClickHouse in performance-critical environments.
|
||||
3. Recompile ClickHouse once again with `-fprofile-instr-use` compiler flags and profiles that are collected from the previous step.
|
||||
|
||||
A more detailed guide on how to apply PGO is in the Clang [documentation](https://clang.llvm.org/docs/UsersManual.html#profile-guided-optimization).
|
||||
|
||||
If you are going to collect a sample workload directly from a production environment, we recommend trying to use Sampling PGO.
|
||||
@ -321,6 +321,10 @@ If both `input_format_allow_errors_num` and `input_format_allow_errors_ratio` ar
|
||||
|
||||
This parameter is useful when you are using formats that require a schema definition, such as [Cap’n Proto](https://capnproto.org/) or [Protobuf](https://developers.google.com/protocol-buffers/). The value depends on the format.
|
||||
|
||||
## output_format_schema {#output-format-schema}
|
||||
|
||||
The path to the file where the automatically generated schema will be saved in [Cap’n Proto](../../interfaces/formats.md#capnproto-capnproto) or [Protobuf](../../interfaces/formats.md#protobuf-protobuf) formats.
|
||||
|
||||
## output_format_enable_streaming {#output_format_enable_streaming}
|
||||
|
||||
Enable streaming in output formats that support it.
|
||||
@ -1108,17 +1112,6 @@ Default value: 1.
|
||||
|
||||
## Arrow format settings {#arrow-format-settings}
|
||||
|
||||
### input_format_arrow_import_nested {#input_format_arrow_import_nested}
|
||||
|
||||
Enables or disables the ability to insert the data into [Nested](../../sql-reference/data-types/nested-data-structures/index.md) columns as an array of structs in [Arrow](../../interfaces/formats.md/#data_types-matching-arrow) input format.
|
||||
|
||||
Possible values:
|
||||
|
||||
- 0 — Data can not be inserted into `Nested` columns as an array of structs.
|
||||
- 1 — Data can be inserted into `Nested` columns as an array of structs.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### input_format_arrow_case_insensitive_column_matching {#input_format_arrow_case_insensitive_column_matching}
|
||||
|
||||
Ignore case when matching Arrow column names with ClickHouse column names.
|
||||
@ -1168,17 +1161,6 @@ Default value: `lz4_frame`.
|
||||
|
||||
## ORC format settings {#orc-format-settings}
|
||||
|
||||
### input_format_orc_import_nested {#input_format_orc_import_nested}
|
||||
|
||||
Enables or disables the ability to insert the data into [Nested](../../sql-reference/data-types/nested-data-structures/index.md) columns as an array of structs in [ORC](../../interfaces/formats.md/#data-format-orc) input format.
|
||||
|
||||
Possible values:
|
||||
|
||||
- 0 — Data can not be inserted into `Nested` columns as an array of structs.
|
||||
- 1 — Data can be inserted into `Nested` columns as an array of structs.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### input_format_orc_row_batch_size {#input_format_orc_row_batch_size}
|
||||
|
||||
Batch size when reading ORC stripes.
|
||||
@ -1217,17 +1199,6 @@ Default value: `none`.
|
||||
|
||||
## Parquet format settings {#parquet-format-settings}
|
||||
|
||||
### input_format_parquet_import_nested {#input_format_parquet_import_nested}
|
||||
|
||||
Enables or disables the ability to insert the data into [Nested](../../sql-reference/data-types/nested-data-structures/index.md) columns as an array of structs in [Parquet](../../interfaces/formats.md/#data-format-parquet) input format.
|
||||
|
||||
Possible values:
|
||||
|
||||
- 0 — Data can not be inserted into `Nested` columns as an array of structs.
|
||||
- 1 — Data can be inserted into `Nested` columns as an array of structs.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### input_format_parquet_case_insensitive_column_matching {#input_format_parquet_case_insensitive_column_matching}
|
||||
|
||||
Ignore case when matching Parquet column names with ClickHouse column names.
|
||||
@ -1330,6 +1301,11 @@ When serializing Nullable columns with Google wrappers, serialize default values
|
||||
|
||||
Disabled by default.
|
||||
|
||||
### format_protobuf_use_autogenerated_schema {#format_capn_proto_use_autogenerated_schema}
|
||||
|
||||
Use autogenerated Protobuf schema when [format_schema](#formatschema-format-schema) is not set.
|
||||
The schema is generated from ClickHouse table structure using function [structureToProtobufSchema](../../sql-reference/functions/other-functions.md#structure_to_protobuf_schema)
|
||||
|
||||
## Avro format settings {#avro-format-settings}
|
||||
|
||||
### input_format_avro_allow_missing_fields {#input_format_avro_allow_missing_fields}
|
||||
@ -1626,6 +1602,11 @@ Possible values:
|
||||
|
||||
Default value: `'by_values'`.
|
||||
|
||||
### format_capn_proto_use_autogenerated_schema {#format_capn_proto_use_autogenerated_schema}
|
||||
|
||||
Use autogenerated CapnProto schema when [format_schema](#formatschema-format-schema) is not set.
|
||||
The schema is generated from ClickHouse table structure using function [structureToCapnProtoSchema](../../sql-reference/functions/other-functions.md#structure_to_capnproto_schema)
|
||||
|
||||
## MySQLDump format settings {#musqldump-format-settings}
|
||||
|
||||
### input_format_mysql_dump_table_name (#input_format_mysql_dump_table_name)
|
||||
|
||||
@ -3468,11 +3468,11 @@ Possible values:
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
## disable_url_encoding {#disable_url_encoding}
|
||||
## enable_url_encoding {#enable_url_encoding}
|
||||
|
||||
Allows to disable decoding/encoding path in uri in [URL](../../engines/table-engines/special/url.md) engine tables.
|
||||
Allows to enable/disable decoding/encoding path in uri in [URL](../../engines/table-engines/special/url.md) engine tables.
|
||||
|
||||
Disabled by default.
|
||||
Enabled by default.
|
||||
|
||||
## database_atomic_wait_for_drop_and_detach_synchronously {#database_atomic_wait_for_drop_and_detach_synchronously}
|
||||
|
||||
@ -4578,3 +4578,28 @@ Type: Int64
|
||||
|
||||
Default: 0
|
||||
|
||||
## precise_float_parsing {#precise_float_parsing}
|
||||
|
||||
Switches [Float32/Float64](../../sql-reference/data-types/float.md) parsing algorithms:
|
||||
* If the value is `1`, then precise method is used. It is slower than fast method, but it always returns a number that is the closest machine representable number to the input.
|
||||
* Otherwise, fast method is used (default). It usually returns the same value as precise, but in rare cases result may differ by one or two least significant digits.
|
||||
|
||||
Possible values: `0`, `1`.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
Example:
|
||||
|
||||
```sql
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 0;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7090999999999998 │ 15008753.000000002 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 1;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7091 │ 15008753 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
```
|
||||
|
||||
@ -48,7 +48,7 @@ Columns:
|
||||
- `read_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of rows read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_rows` includes the total number of rows read at all replicas. Each replica sends it’s `read_rows` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
||||
- `read_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of bytes read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_bytes` includes the total number of rows read at all replicas. Each replica sends it’s `read_bytes` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
||||
- `written_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written rows. For other queries, the column value is 0.
|
||||
- `written_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written bytes. For other queries, the column value is 0.
|
||||
- `written_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written bytes (uncompressed). For other queries, the column value is 0.
|
||||
- `result_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Number of rows in a result of the `SELECT` query, or a number of rows in the `INSERT` query.
|
||||
- `result_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — RAM volume in bytes used to store a query result.
|
||||
- `memory_usage` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Memory consumption by the query.
|
||||
|
||||
@ -2552,3 +2552,187 @@ Result:
|
||||
|
||||
This function can be used together with [generateRandom](../../sql-reference/table-functions/generate.md) to generate completely random tables.
|
||||
|
||||
## structureToCapnProtoSchema {#structure_to_capn_proto_schema}
|
||||
|
||||
Converts ClickHouse table structure to CapnProto schema.
|
||||
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
structureToCapnProtoSchema(structure)
|
||||
```
|
||||
|
||||
**Arguments**
|
||||
|
||||
- `structure` — Table structure in a format `column1_name column1_type, column2_name column2_type, ...`.
|
||||
- `root_struct_name` — Name for root struct in CapnProto schema. Default value - `Message`;
|
||||
|
||||
**Returned value**
|
||||
|
||||
- CapnProto schema
|
||||
|
||||
Type: [String](../../sql-reference/data-types/string.md).
|
||||
|
||||
**Examples**
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToCapnProtoSchema('column1 String, column2 UInt32, column3 Array(String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
@0xf96402dd754d0eb7;
|
||||
|
||||
struct Message
|
||||
{
|
||||
column1 @0 : Data;
|
||||
column2 @1 : UInt32;
|
||||
column3 @2 : List(Data);
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToCapnProtoSchema('column1 Nullable(String), column2 Tuple(element1 UInt32, element2 Array(String)), column3 Map(String, String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
@0xd1c8320fecad2b7f;
|
||||
|
||||
struct Message
|
||||
{
|
||||
struct Column1
|
||||
{
|
||||
union
|
||||
{
|
||||
value @0 : Data;
|
||||
null @1 : Void;
|
||||
}
|
||||
}
|
||||
column1 @0 : Column1;
|
||||
struct Column2
|
||||
{
|
||||
element1 @0 : UInt32;
|
||||
element2 @1 : List(Data);
|
||||
}
|
||||
column2 @1 : Column2;
|
||||
struct Column3
|
||||
{
|
||||
struct Entry
|
||||
{
|
||||
key @0 : Data;
|
||||
value @1 : Data;
|
||||
}
|
||||
entries @0 : List(Entry);
|
||||
}
|
||||
column3 @2 : Column3;
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToCapnProtoSchema('column1 String, column2 UInt32', 'Root') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
@0x96ab2d4ab133c6e1;
|
||||
|
||||
struct Root
|
||||
{
|
||||
column1 @0 : Data;
|
||||
column2 @1 : UInt32;
|
||||
}
|
||||
```
|
||||
|
||||
## structureToProtobufSchema {#structure_to_protobuf_schema}
|
||||
|
||||
Converts ClickHouse table structure to Protobuf schema.
|
||||
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
structureToProtobufSchema(structure)
|
||||
```
|
||||
|
||||
**Arguments**
|
||||
|
||||
- `structure` — Table structure in a format `column1_name column1_type, column2_name column2_type, ...`.
|
||||
- `root_message_name` — Name for root message in Protobuf schema. Default value - `Message`;
|
||||
|
||||
**Returned value**
|
||||
|
||||
- Protobuf schema
|
||||
|
||||
Type: [String](../../sql-reference/data-types/string.md).
|
||||
|
||||
**Examples**
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToProtobufSchema('column1 String, column2 UInt32, column3 Array(String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
syntax = "proto3";
|
||||
|
||||
message Message
|
||||
{
|
||||
bytes column1 = 1;
|
||||
uint32 column2 = 2;
|
||||
repeated bytes column3 = 3;
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToProtobufSchema('column1 Nullable(String), column2 Tuple(element1 UInt32, element2 Array(String)), column3 Map(String, String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
syntax = "proto3";
|
||||
|
||||
message Message
|
||||
{
|
||||
bytes column1 = 1;
|
||||
message Column2
|
||||
{
|
||||
uint32 element1 = 1;
|
||||
repeated bytes element2 = 2;
|
||||
}
|
||||
Column2 column2 = 2;
|
||||
map<string, bytes> column3 = 3;
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToProtobufSchema('column1 String, column2 UInt32', 'Root') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
syntax = "proto3";
|
||||
|
||||
message Root
|
||||
{
|
||||
bytes column1 = 1;
|
||||
uint32 column2 = 2;
|
||||
}
|
||||
```
|
||||
|
||||
@ -36,6 +36,8 @@ These `ALTER` statements modify entities related to role-based access control:
|
||||
|
||||
[ALTER TABLE ... MODIFY COMMENT](/docs/en/sql-reference/statements/alter/comment.md) statement adds, modifies, or removes comments to the table, regardless if it was set before or not.
|
||||
|
||||
[ALTER NAMED COLLECTION](/docs/en/sql-reference/statements/alter/named-collection.md) statement modifies [Named Collections](/docs/en/operations/named-collections.md).
|
||||
|
||||
## Mutations
|
||||
|
||||
`ALTER` queries that are intended to manipulate table data are implemented with a mechanism called “mutations”, most notably [ALTER TABLE … DELETE](/docs/en/sql-reference/statements/alter/delete.md) and [ALTER TABLE … UPDATE](/docs/en/sql-reference/statements/alter/update.md). They are asynchronous background processes similar to merges in [MergeTree](/docs/en/engines/table-engines/mergetree-family/index.md) tables that to produce new “mutated” versions of parts.
|
||||
|
||||
30
docs/en/sql-reference/statements/alter/named-collection.md
Normal file
30
docs/en/sql-reference/statements/alter/named-collection.md
Normal file
@ -0,0 +1,30 @@
|
||||
---
|
||||
slug: /en/sql-reference/statements/alter/named-collection
|
||||
sidebar_label: NAMED COLLECTION
|
||||
---
|
||||
|
||||
# ALTER NAMED COLLECTION
|
||||
|
||||
This query intends to modify already existing named collections.
|
||||
|
||||
**Syntax**
|
||||
|
||||
```sql
|
||||
ALTER NAMED COLLECTION [IF EXISTS] name [ON CLUSTER cluster]
|
||||
[ SET
|
||||
key_name1 = 'some value',
|
||||
key_name2 = 'some value',
|
||||
key_name3 = 'some value',
|
||||
... ] |
|
||||
[ DELETE key_name4, key_name5, ... ]
|
||||
```
|
||||
|
||||
**Example**
|
||||
|
||||
```sql
|
||||
CREATE NAMED COLLECTION foobar AS a = '1', b = '2';
|
||||
|
||||
ALTER NAMED COLLECTION foobar SET a = '2', c = '3';
|
||||
|
||||
ALTER NAMED COLLECTION foobar DELETE b;
|
||||
```
|
||||
@ -8,13 +8,14 @@ sidebar_label: CREATE
|
||||
|
||||
Create queries make a new entity of one of the following kinds:
|
||||
|
||||
- [DATABASE](../../../sql-reference/statements/create/database.md)
|
||||
- [TABLE](../../../sql-reference/statements/create/table.md)
|
||||
- [VIEW](../../../sql-reference/statements/create/view.md)
|
||||
- [DICTIONARY](../../../sql-reference/statements/create/dictionary.md)
|
||||
- [FUNCTION](../../../sql-reference/statements/create/function.md)
|
||||
- [USER](../../../sql-reference/statements/create/user.md)
|
||||
- [ROLE](../../../sql-reference/statements/create/role.md)
|
||||
- [ROW POLICY](../../../sql-reference/statements/create/row-policy.md)
|
||||
- [QUOTA](../../../sql-reference/statements/create/quota.md)
|
||||
- [SETTINGS PROFILE](../../../sql-reference/statements/create/settings-profile.md)
|
||||
- [DATABASE](/docs/en/sql-reference/statements/create/database.md)
|
||||
- [TABLE](/docs/en/sql-reference/statements/create/table.md)
|
||||
- [VIEW](/docs/en/sql-reference/statements/create/view.md)
|
||||
- [DICTIONARY](/docs/en/sql-reference/statements/create/dictionary.md)
|
||||
- [FUNCTION](/docs/en/sql-reference/statements/create/function.md)
|
||||
- [USER](/docs/en/sql-reference/statements/create/user.md)
|
||||
- [ROLE](/docs/en/sql-reference/statements/create/role.md)
|
||||
- [ROW POLICY](/docs/en/sql-reference/statements/create/row-policy.md)
|
||||
- [QUOTA](/docs/en/sql-reference/statements/create/quota.md)
|
||||
- [SETTINGS PROFILE](/docs/en/sql-reference/statements/create/settings-profile.md)
|
||||
- [NAMED COLLECTION](/docs/en/sql-reference/statements/create/named-collection.md)
|
||||
|
||||
34
docs/en/sql-reference/statements/create/named-collection.md
Normal file
34
docs/en/sql-reference/statements/create/named-collection.md
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
slug: /en/sql-reference/statements/create/named-collection
|
||||
sidebar_label: NAMED COLLECTION
|
||||
---
|
||||
|
||||
# CREATE NAMED COLLECTION
|
||||
|
||||
Creates a new named collection.
|
||||
|
||||
**Syntax**
|
||||
|
||||
```sql
|
||||
CREATE NAMED COLLECTION [IF NOT EXISTS] name [ON CLUSTER cluster] AS
|
||||
key_name1 = 'some value',
|
||||
key_name2 = 'some value',
|
||||
key_name3 = 'some value',
|
||||
...
|
||||
```
|
||||
|
||||
**Example**
|
||||
|
||||
```sql
|
||||
CREATE NAMED COLLECTION foobar AS a = '1', b = '2';
|
||||
```
|
||||
|
||||
**Related statements**
|
||||
|
||||
- [CREATE NAMED COLLECTION](https://clickhouse.com/docs/en/sql-reference/statements/alter/named-collection)
|
||||
- [DROP NAMED COLLECTION](https://clickhouse.com/docs/en/sql-reference/statements/drop#drop-function)
|
||||
|
||||
|
||||
**See Also**
|
||||
|
||||
- [Named collections guide](/docs/en/operations/named-collections.md)
|
||||
@ -119,3 +119,20 @@ DROP FUNCTION [IF EXISTS] function_name [on CLUSTER cluster]
|
||||
CREATE FUNCTION linear_equation AS (x, k, b) -> k*x + b;
|
||||
DROP FUNCTION linear_equation;
|
||||
```
|
||||
|
||||
## DROP NAMED COLLECTION
|
||||
|
||||
Deletes a named collection.
|
||||
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
DROP NAMED COLLECTION [IF EXISTS] name [on CLUSTER cluster]
|
||||
```
|
||||
|
||||
**Example**
|
||||
|
||||
``` sql
|
||||
CREATE NAMED COLLECTION foobar AS a = '1', b = '2';
|
||||
DROP NAMED COLLECTION foobar;
|
||||
```
|
||||
|
||||
@ -314,6 +314,22 @@ Provides possibility to start background fetch tasks from replication queues whi
|
||||
SYSTEM START REPLICATION QUEUES [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
||||
```
|
||||
|
||||
### STOP PULLING REPLICATION LOG
|
||||
|
||||
Stops loading new entries from replication log to replication queue in a `ReplicatedMergeTree` table.
|
||||
|
||||
``` sql
|
||||
SYSTEM STOP PULLING REPLICATION LOG [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
||||
```
|
||||
|
||||
### START PULLING REPLICATION LOG
|
||||
|
||||
Cancels `SYSTEM STOP PULLING REPLICATION LOG`.
|
||||
|
||||
``` sql
|
||||
SYSTEM START PULLING REPLICATION LOG [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
||||
```
|
||||
|
||||
### SYNC REPLICA
|
||||
|
||||
Wait until a `ReplicatedMergeTree` table will be synced with other replicas in a cluster, but no more than `receive_timeout` seconds.
|
||||
|
||||
@ -21,7 +21,7 @@ iceberg(url [,aws_access_key_id, aws_secret_access_key] [,format] [,structure])
|
||||
- `format` — The [format](/docs/en/interfaces/formats.md/#formats) of the file. By default `Parquet` is used.
|
||||
- `structure` — Structure of the table. Format `'column1_name column1_type, column2_name column2_type, ...'`.
|
||||
|
||||
Engine parameters can be specified using [Named Collections](../../operations/named-collections.md)
|
||||
Engine parameters can be specified using [Named Collections](/docs/en/operations/named-collections.md).
|
||||
|
||||
**Returned value**
|
||||
|
||||
|
||||
@ -56,7 +56,7 @@ Character `|` inside patterns is used to specify failover addresses. They are it
|
||||
## Storage Settings {#storage-settings}
|
||||
|
||||
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
||||
- [disable_url_encoding](/docs/en/operations/settings/settings.md#disable_url_encoding) - allows to disable decoding/encoding path in uri. Disabled by default.
|
||||
- [enable_url_encoding](/docs/en/operations/settings/settings.md#enable_url_encoding) - allows to enable/disable decoding/encoding path in uri. Enabled by default.
|
||||
|
||||
**See Also**
|
||||
|
||||
|
||||
@ -1353,8 +1353,6 @@ ClickHouse поддерживает настраиваемую точность
|
||||
$ cat {filename} | clickhouse-client --query="INSERT INTO {some_table} FORMAT Parquet"
|
||||
```
|
||||
|
||||
Чтобы вставить данные в колонки типа [Nested](../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур, нужно включить настройку [input_format_parquet_import_nested](../operations/settings/settings.md#input_format_parquet_import_nested).
|
||||
|
||||
Чтобы получить данные из таблицы ClickHouse и сохранить их в файл формата Parquet, используйте команду следующего вида:
|
||||
|
||||
``` bash
|
||||
@ -1413,8 +1411,6 @@ ClickHouse поддерживает настраиваемую точность
|
||||
$ cat filename.arrow | clickhouse-client --query="INSERT INTO some_table FORMAT Arrow"
|
||||
```
|
||||
|
||||
Чтобы вставить данные в колонки типа [Nested](../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур, нужно включить настройку [input_format_arrow_import_nested](../operations/settings/settings.md#input_format_arrow_import_nested).
|
||||
|
||||
### Вывод данных {#selecting-data-arrow}
|
||||
|
||||
Чтобы получить данные из таблицы ClickHouse и сохранить их в файл формата Arrow, используйте команду следующего вида:
|
||||
@ -1471,8 +1467,6 @@ ClickHouse поддерживает настраиваемую точность
|
||||
$ cat filename.orc | clickhouse-client --query="INSERT INTO some_table FORMAT ORC"
|
||||
```
|
||||
|
||||
Чтобы вставить данные в колонки типа [Nested](../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур, нужно включить настройку [input_format_orc_import_nested](../operations/settings/settings.md#input_format_orc_import_nested).
|
||||
|
||||
### Вывод данных {#selecting-data-2}
|
||||
|
||||
Чтобы получить данные из таблицы ClickHouse и сохранить их в файл формата ORC, используйте команду следующего вида:
|
||||
|
||||
@ -0,0 +1 @@
|
||||
../../../en/operations/optimizing-performance/profile-guided-optimization.md
|
||||
@ -238,39 +238,6 @@ ClickHouse применяет настройку в тех случаях, ко
|
||||
|
||||
В случае превышения `input_format_allow_errors_ratio` ClickHouse генерирует исключение.
|
||||
|
||||
## input_format_parquet_import_nested {#input_format_parquet_import_nested}
|
||||
|
||||
Включает или отключает возможность вставки данных в колонки типа [Nested](../../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур в формате ввода [Parquet](../../interfaces/formats.md#data-format-parquet).
|
||||
|
||||
Возможные значения:
|
||||
|
||||
- 0 — данные не могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
||||
- 0 — данные могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
||||
|
||||
Значение по умолчанию: `0`.
|
||||
|
||||
## input_format_arrow_import_nested {#input_format_arrow_import_nested}
|
||||
|
||||
Включает или отключает возможность вставки данных в колонки типа [Nested](../../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур в формате ввода [Arrow](../../interfaces/formats.md#data_types-matching-arrow).
|
||||
|
||||
Возможные значения:
|
||||
|
||||
- 0 — данные не могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
||||
- 0 — данные могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
||||
|
||||
Значение по умолчанию: `0`.
|
||||
|
||||
## input_format_orc_import_nested {#input_format_orc_import_nested}
|
||||
|
||||
Включает или отключает возможность вставки данных в колонки типа [Nested](../../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур в формате ввода [ORC](../../interfaces/formats.md#data-format-orc).
|
||||
|
||||
Возможные значения:
|
||||
|
||||
- 0 — данные не могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
||||
- 0 — данные могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
||||
|
||||
Значение по умолчанию: `0`.
|
||||
|
||||
## input_format_values_interpret_expressions {#settings-input_format_values_interpret_expressions}
|
||||
|
||||
Включает или отключает парсер SQL, если потоковый парсер не может проанализировать данные. Этот параметр используется только для формата [Values](../../interfaces/formats.md#data-format-values) при вставке данных. Дополнительные сведения о парсерах читайте в разделе [Синтаксис](../../sql-reference/syntax.md).
|
||||
@ -4213,3 +4180,29 @@ SELECT *, timezone() FROM test_tz WHERE d = '2000-01-01 00:00:00' SETTINGS sessi
|
||||
- Запрос: `SELECT * FROM file('sample.csv')`
|
||||
|
||||
Если чтение и обработка `sample.csv` прошли успешно, файл будет переименован в `processed_sample_1683473210851438.csv`.
|
||||
|
||||
## precise_float_parsing {#precise_float_parsing}
|
||||
|
||||
Позволяет выбрать алгоритм, используемый при парсинге [Float32/Float64](../../sql-reference/data-types/float.md):
|
||||
* Если установлено значение `1`, то используется точный метод. Он более медленный, но всегда возвращает число, наиболее близкое к входному значению.
|
||||
* В противном случае используется быстрый метод (поведение по умолчанию). Обычно результат его работы совпадает с результатом, полученным точным методом, однако в редких случаях он может отличаться на 1 или 2 наименее значимых цифры.
|
||||
|
||||
Возможные значения: `0`, `1`.
|
||||
|
||||
Значение по умолчанию: `0`.
|
||||
|
||||
Пример:
|
||||
|
||||
```sql
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 0;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7090999999999998 │ 15008753.000000002 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 1;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7091 │ 15008753 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
```
|
||||
|
||||
@ -0,0 +1 @@
|
||||
../../../en/operations/optimizing-performance/profile-guided-optimization.md
|
||||
@ -55,6 +55,9 @@ contents:
|
||||
- src: clickhouse
|
||||
dst: /usr/bin/clickhouse-keeper
|
||||
type: symlink
|
||||
- src: clickhouse
|
||||
dst: /usr/bin/clickhouse-keeper-client
|
||||
type: symlink
|
||||
- src: root/usr/bin/clickhouse-report
|
||||
dst: /usr/bin/clickhouse-report
|
||||
- src: root/usr/bin/clickhouse-server
|
||||
|
||||
@ -77,7 +77,7 @@ void SetCommand::execute(const ASTKeeperQuery * query, KeeperClient * client) co
|
||||
client->zookeeper->set(
|
||||
client->getAbsolutePath(query->args[0].safeGet<String>()),
|
||||
query->args[1].safeGet<String>(),
|
||||
static_cast<Int32>(query->args[2].safeGet<Int64>()));
|
||||
static_cast<Int32>(query->args[2].get<Int32>()));
|
||||
}
|
||||
|
||||
bool CreateCommand::parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const
|
||||
|
||||
@ -1657,6 +1657,7 @@ try
|
||||
database_catalog.initializeAndLoadTemporaryDatabase();
|
||||
auto system_startup_tasks = loadMetadataSystem(global_context);
|
||||
maybeConvertSystemDatabase(global_context, system_startup_tasks);
|
||||
waitLoad(AsyncLoaderPoolId::Foreground, system_startup_tasks);
|
||||
/// After attaching system databases we can initialize system log.
|
||||
global_context->initializeSystemLogs();
|
||||
global_context->setSystemZooKeeperLogAfterInitializationIfNeeded();
|
||||
@ -1676,7 +1677,6 @@ try
|
||||
auto load_metadata = loadMetadata(global_context, default_database, server_settings.async_load_databases);
|
||||
/// If we need to convert database engines, disable async tables loading
|
||||
convertDatabasesEnginesIfNeed(load_metadata, global_context);
|
||||
waitLoad(AsyncLoaderPoolId::Foreground, system_startup_tasks);
|
||||
database_catalog.startupBackgroundCleanup();
|
||||
/// After loading validate that default database exists
|
||||
database_catalog.assertDatabaseExists(default_database);
|
||||
|
||||
@ -6,6 +6,7 @@
|
||||
#include <Access/DiskAccessStorage.h>
|
||||
#include <Access/LDAPAccessStorage.h>
|
||||
#include <Access/ContextAccess.h>
|
||||
#include <Access/EnabledSettings.h>
|
||||
#include <Access/EnabledRolesInfo.h>
|
||||
#include <Access/RoleCache.h>
|
||||
#include <Access/RowPolicyCache.h>
|
||||
@ -729,6 +730,14 @@ std::shared_ptr<const EnabledRoles> AccessControl::getEnabledRoles(
|
||||
}
|
||||
|
||||
|
||||
std::shared_ptr<const EnabledRolesInfo> AccessControl::getEnabledRolesInfo(
|
||||
const std::vector<UUID> & current_roles,
|
||||
const std::vector<UUID> & current_roles_with_admin_option) const
|
||||
{
|
||||
return getEnabledRoles(current_roles, current_roles_with_admin_option)->getRolesInfo();
|
||||
}
|
||||
|
||||
|
||||
std::shared_ptr<const EnabledRowPolicies> AccessControl::getEnabledRowPolicies(const UUID & user_id, const boost::container::flat_set<UUID> & enabled_roles) const
|
||||
{
|
||||
return row_policy_cache->getEnabledRowPolicies(user_id, enabled_roles);
|
||||
@ -772,6 +781,15 @@ std::shared_ptr<const EnabledSettings> AccessControl::getEnabledSettings(
|
||||
return settings_profiles_cache->getEnabledSettings(user_id, settings_from_user, enabled_roles, settings_from_enabled_roles);
|
||||
}
|
||||
|
||||
std::shared_ptr<const SettingsProfilesInfo> AccessControl::getEnabledSettingsInfo(
|
||||
const UUID & user_id,
|
||||
const SettingsProfileElements & settings_from_user,
|
||||
const boost::container::flat_set<UUID> & enabled_roles,
|
||||
const SettingsProfileElements & settings_from_enabled_roles) const
|
||||
{
|
||||
return getEnabledSettings(user_id, settings_from_user, enabled_roles, settings_from_enabled_roles)->getInfo();
|
||||
}
|
||||
|
||||
std::shared_ptr<const SettingsProfilesInfo> AccessControl::getSettingsProfileInfo(const UUID & profile_id)
|
||||
{
|
||||
return settings_profiles_cache->getSettingsProfileInfo(profile_id);
|
||||
|
||||
@ -29,6 +29,7 @@ class ContextAccessParams;
|
||||
struct User;
|
||||
using UserPtr = std::shared_ptr<const User>;
|
||||
class EnabledRoles;
|
||||
struct EnabledRolesInfo;
|
||||
class RoleCache;
|
||||
class EnabledRowPolicies;
|
||||
class RowPolicyCache;
|
||||
@ -187,6 +188,10 @@ public:
|
||||
const std::vector<UUID> & current_roles,
|
||||
const std::vector<UUID> & current_roles_with_admin_option) const;
|
||||
|
||||
std::shared_ptr<const EnabledRolesInfo> getEnabledRolesInfo(
|
||||
const std::vector<UUID> & current_roles,
|
||||
const std::vector<UUID> & current_roles_with_admin_option) const;
|
||||
|
||||
std::shared_ptr<const EnabledRowPolicies> getEnabledRowPolicies(
|
||||
const UUID & user_id,
|
||||
const boost::container::flat_set<UUID> & enabled_roles) const;
|
||||
@ -209,6 +214,12 @@ public:
|
||||
const boost::container::flat_set<UUID> & enabled_roles,
|
||||
const SettingsProfileElements & settings_from_enabled_roles) const;
|
||||
|
||||
std::shared_ptr<const SettingsProfilesInfo> getEnabledSettingsInfo(
|
||||
const UUID & user_id,
|
||||
const SettingsProfileElements & settings_from_user,
|
||||
const boost::container::flat_set<UUID> & enabled_roles,
|
||||
const SettingsProfileElements & settings_from_enabled_roles) const;
|
||||
|
||||
std::shared_ptr<const SettingsProfilesInfo> getSettingsProfileInfo(const UUID & profile_id);
|
||||
|
||||
const ExternalAuthenticators & getExternalAuthenticators() const;
|
||||
|
||||
@ -168,6 +168,7 @@ enum class AccessType
|
||||
M(SYSTEM_TTL_MERGES, "SYSTEM STOP TTL MERGES, SYSTEM START TTL MERGES, STOP TTL MERGES, START TTL MERGES", TABLE, SYSTEM) \
|
||||
M(SYSTEM_FETCHES, "SYSTEM STOP FETCHES, SYSTEM START FETCHES, STOP FETCHES, START FETCHES", TABLE, SYSTEM) \
|
||||
M(SYSTEM_MOVES, "SYSTEM STOP MOVES, SYSTEM START MOVES, STOP MOVES, START MOVES", TABLE, SYSTEM) \
|
||||
M(SYSTEM_PULLING_REPLICATION_LOG, "SYSTEM STOP PULLING REPLICATION LOG, SYSTEM START PULLING REPLICATION LOG", TABLE, SYSTEM) \
|
||||
M(SYSTEM_DISTRIBUTED_SENDS, "SYSTEM STOP DISTRIBUTED SENDS, SYSTEM START DISTRIBUTED SENDS, STOP DISTRIBUTED SENDS, START DISTRIBUTED SENDS", TABLE, SYSTEM_SENDS) \
|
||||
M(SYSTEM_REPLICATED_SENDS, "SYSTEM STOP REPLICATED SENDS, SYSTEM START REPLICATED SENDS, STOP REPLICATED SENDS, START REPLICATED SENDS", TABLE, SYSTEM_SENDS) \
|
||||
M(SYSTEM_SENDS, "SYSTEM STOP SENDS, SYSTEM START SENDS, STOP SENDS, START SENDS", GROUP, SYSTEM) \
|
||||
|
||||
@ -51,7 +51,7 @@ TEST(AccessRights, Union)
|
||||
"CREATE DICTIONARY, DROP DATABASE, DROP TABLE, DROP VIEW, DROP DICTIONARY, UNDROP TABLE, "
|
||||
"TRUNCATE, OPTIMIZE, BACKUP, CREATE ROW POLICY, ALTER ROW POLICY, DROP ROW POLICY, "
|
||||
"SHOW ROW POLICIES, SYSTEM MERGES, SYSTEM TTL MERGES, SYSTEM FETCHES, "
|
||||
"SYSTEM MOVES, SYSTEM SENDS, SYSTEM REPLICATION QUEUES, "
|
||||
"SYSTEM MOVES, SYSTEM PULLING REPLICATION LOG, SYSTEM SENDS, SYSTEM REPLICATION QUEUES, "
|
||||
"SYSTEM DROP REPLICA, SYSTEM SYNC REPLICA, SYSTEM RESTART REPLICA, "
|
||||
"SYSTEM RESTORE REPLICA, SYSTEM WAIT LOADING PARTS, SYSTEM SYNC DATABASE REPLICA, SYSTEM FLUSH DISTRIBUTED, dictGet ON db1.*, GRANT NAMED COLLECTION ADMIN ON db1");
|
||||
}
|
||||
|
||||
@ -0,0 +1,221 @@
|
||||
#include <Analyzer/Passes/OptimizeDateOrDateTimeConverterWithPreimagePass.h>
|
||||
|
||||
#include <Functions/FunctionFactory.h>
|
||||
|
||||
#include <Analyzer/InDepthQueryTreeVisitor.h>
|
||||
#include <Analyzer/ColumnNode.h>
|
||||
#include <Analyzer/ConstantNode.h>
|
||||
#include <Analyzer/FunctionNode.h>
|
||||
#include <Common/DateLUT.h>
|
||||
#include <Common/DateLUTImpl.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
namespace ErrorCodes
|
||||
{
|
||||
extern const int LOGICAL_ERROR;
|
||||
}
|
||||
|
||||
namespace
|
||||
{
|
||||
|
||||
class OptimizeDateOrDateTimeConverterWithPreimageVisitor : public InDepthQueryTreeVisitorWithContext<OptimizeDateOrDateTimeConverterWithPreimageVisitor>
|
||||
{
|
||||
public:
|
||||
using Base = InDepthQueryTreeVisitorWithContext<OptimizeDateOrDateTimeConverterWithPreimageVisitor>;
|
||||
|
||||
explicit OptimizeDateOrDateTimeConverterWithPreimageVisitor(ContextPtr context)
|
||||
: Base(std::move(context))
|
||||
{}
|
||||
|
||||
static bool needChildVisit(QueryTreeNodePtr & node, QueryTreeNodePtr & /*child*/)
|
||||
{
|
||||
const static std::unordered_set<String> relations = {
|
||||
"equals",
|
||||
"notEquals",
|
||||
"less",
|
||||
"greater",
|
||||
"lessOrEquals",
|
||||
"greaterOrEquals",
|
||||
};
|
||||
|
||||
if (const auto * function = node->as<FunctionNode>())
|
||||
{
|
||||
return !relations.contains(function->getFunctionName());
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
void enterImpl(QueryTreeNodePtr & node) const
|
||||
{
|
||||
const static std::unordered_map<String, String> swap_relations = {
|
||||
{"equals", "equals"},
|
||||
{"notEquals", "notEquals"},
|
||||
{"less", "greater"},
|
||||
{"greater", "less"},
|
||||
{"lessOrEquals", "greaterOrEquals"},
|
||||
{"greaterOrEquals", "lessOrEquals"},
|
||||
};
|
||||
|
||||
const auto * function = node->as<FunctionNode>();
|
||||
|
||||
if (!function || !swap_relations.contains(function->getFunctionName())) return;
|
||||
|
||||
if (function->getArguments().getNodes().size() != 2) return;
|
||||
|
||||
size_t func_id = function->getArguments().getNodes().size();
|
||||
|
||||
for (size_t i = 0; i < function->getArguments().getNodes().size(); i++)
|
||||
{
|
||||
if (const auto * func = function->getArguments().getNodes()[i]->as<FunctionNode>())
|
||||
{
|
||||
func_id = i;
|
||||
}
|
||||
}
|
||||
|
||||
if (func_id == function->getArguments().getNodes().size()) return;
|
||||
|
||||
size_t literal_id = 1 - func_id;
|
||||
const auto * literal = function->getArguments().getNodes()[literal_id]->as<ConstantNode>();
|
||||
|
||||
if (!literal || literal->getValue().getType() != Field::Types::UInt64) return;
|
||||
|
||||
String comparator = literal_id > func_id ? function->getFunctionName(): swap_relations.at(function->getFunctionName());
|
||||
|
||||
const auto * func_node = function->getArguments().getNodes()[func_id]->as<FunctionNode>();
|
||||
/// Currently we only handle single-argument functions.
|
||||
if (!func_node || func_node->getArguments().getNodes().size() != 1) return;
|
||||
|
||||
const auto * column_id = func_node->getArguments().getNodes()[0]->as<ColumnNode>();
|
||||
if (!column_id) return;
|
||||
|
||||
const auto * column_type = column_id->getColumnType().get();
|
||||
if (!isDateOrDate32(column_type) && !isDateTime(column_type) && !isDateTime64(column_type)) return;
|
||||
|
||||
const auto & converter = FunctionFactory::instance().tryGet(func_node->getFunctionName(), getContext());
|
||||
if (!converter) return;
|
||||
|
||||
ColumnsWithTypeAndName args;
|
||||
args.emplace_back(column_id->getColumnType(), "tmp");
|
||||
auto converter_base = converter->build(args);
|
||||
if (!converter_base || !converter_base->hasInformationAboutPreimage()) return;
|
||||
|
||||
auto preimage_range = converter_base->getPreimage(*(column_id->getColumnType()), literal->getValue());
|
||||
if (!preimage_range) return;
|
||||
|
||||
const auto new_node = generateOptimizedDateFilter(comparator, *column_id, *preimage_range);
|
||||
|
||||
if (!new_node) return;
|
||||
|
||||
node = new_node;
|
||||
}
|
||||
|
||||
private:
|
||||
QueryTreeNodePtr generateOptimizedDateFilter(const String & comparator, const ColumnNode & column_node, const std::pair<Field, Field>& range) const
|
||||
{
|
||||
const DateLUTImpl & date_lut = DateLUT::instance("UTC");
|
||||
|
||||
String start_date_or_date_time;
|
||||
String end_date_or_date_time;
|
||||
|
||||
if (isDateOrDate32(column_node.getColumnType().get()))
|
||||
{
|
||||
start_date_or_date_time = date_lut.dateToString(range.first.get<DateLUTImpl::Time>());
|
||||
end_date_or_date_time = date_lut.dateToString(range.second.get<DateLUTImpl::Time>());
|
||||
}
|
||||
else if (isDateTime(column_node.getColumnType().get()) || isDateTime64(column_node.getColumnType().get()))
|
||||
{
|
||||
start_date_or_date_time = date_lut.timeToString(range.first.get<DateLUTImpl::Time>());
|
||||
end_date_or_date_time = date_lut.timeToString(range.second.get<DateLUTImpl::Time>());
|
||||
}
|
||||
else [[unlikely]] return {};
|
||||
|
||||
if (comparator == "equals")
|
||||
{
|
||||
const auto lhs = std::make_shared<FunctionNode>("greaterOrEquals");
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(start_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*lhs, lhs->getFunctionName());
|
||||
|
||||
const auto rhs = std::make_shared<FunctionNode>("less");
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*rhs, rhs->getFunctionName());
|
||||
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("and");
|
||||
new_date_filter->getArguments().getNodes() = {lhs, rhs};
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "notEquals")
|
||||
{
|
||||
const auto lhs = std::make_shared<FunctionNode>("less");
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(start_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*lhs, lhs->getFunctionName());
|
||||
|
||||
const auto rhs = std::make_shared<FunctionNode>("greaterOrEquals");
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*rhs, rhs->getFunctionName());
|
||||
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("or");
|
||||
new_date_filter->getArguments().getNodes() = {lhs, rhs};
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "greater")
|
||||
{
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("greaterOrEquals");
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "lessOrEquals")
|
||||
{
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("less");
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "less" || comparator == "greaterOrEquals")
|
||||
{
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>(comparator);
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(start_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else [[unlikely]]
|
||||
{
|
||||
throw Exception(ErrorCodes::LOGICAL_ERROR,
|
||||
"Expected equals, notEquals, less, lessOrEquals, greater, greaterOrEquals. Actual {}",
|
||||
comparator);
|
||||
}
|
||||
}
|
||||
|
||||
void resolveOrdinaryFunctionNode(FunctionNode & function_node, const String & function_name) const
|
||||
{
|
||||
auto function = FunctionFactory::instance().get(function_name, getContext());
|
||||
function_node.resolveAsFunction(function->build(function_node.getArgumentColumns()));
|
||||
}
|
||||
};
|
||||
|
||||
}
|
||||
|
||||
void OptimizeDateOrDateTimeConverterWithPreimagePass::run(QueryTreeNodePtr query_tree_node, ContextPtr context)
|
||||
{
|
||||
OptimizeDateOrDateTimeConverterWithPreimageVisitor visitor(std::move(context));
|
||||
visitor.visit(query_tree_node);
|
||||
}
|
||||
|
||||
}
|
||||
@ -0,0 +1,24 @@
|
||||
#pragma once
|
||||
|
||||
#include <Analyzer/IQueryTreePass.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
/** Replace predicate having Date/DateTime converters with their preimages to improve performance.
|
||||
* Given a Date column c, toYear(c) = 2023 -> c >= '2023-01-01' AND c < '2024-01-01'
|
||||
* Or if c is a DateTime column, toYear(c) = 2023 -> c >= '2023-01-01 00:00:00' AND c < '2024-01-01 00:00:00'.
|
||||
* The similar optimization also applies to other converters.
|
||||
*/
|
||||
class OptimizeDateOrDateTimeConverterWithPreimagePass final : public IQueryTreePass
|
||||
{
|
||||
public:
|
||||
String getName() override { return "OptimizeDateOrDateTimeConverterWithPreimagePass"; }
|
||||
|
||||
String getDescription() override { return "Replace predicate having Date/DateTime converters with their preimages"; }
|
||||
|
||||
void run(QueryTreeNodePtr query_tree_node, ContextPtr context) override;
|
||||
|
||||
};
|
||||
|
||||
}
|
||||
@ -6887,13 +6887,12 @@ void QueryAnalyzer::resolveQuery(const QueryTreeNodePtr & query_node, Identifier
|
||||
scope.scope_node->formatASTForErrorMessage());
|
||||
}
|
||||
|
||||
std::erase_if(with_nodes, [](const QueryTreeNodePtr & node)
|
||||
{
|
||||
auto * subquery_node = node->as<QueryNode>();
|
||||
auto * union_node = node->as<UnionNode>();
|
||||
|
||||
return (subquery_node && subquery_node->isCTE()) || (union_node && union_node->isCTE());
|
||||
});
|
||||
/** WITH section can be safely removed, because WITH section only can provide aliases to query expressions
|
||||
* and CTE for other sections to use.
|
||||
*
|
||||
* Example: WITH 1 AS constant, (x -> x + 1) AS lambda, a AS (SELECT * FROM test_table);
|
||||
*/
|
||||
query_node_typed.getWith().getNodes().clear();
|
||||
|
||||
for (auto & window_node : query_node_typed.getWindow().getNodes())
|
||||
{
|
||||
@ -6952,9 +6951,6 @@ void QueryAnalyzer::resolveQuery(const QueryTreeNodePtr & query_node, Identifier
|
||||
scope.scope_node->formatASTForErrorMessage());
|
||||
}
|
||||
|
||||
if (query_node_typed.hasWith())
|
||||
resolveExpressionNodeList(query_node_typed.getWithNode(), scope, true /*allow_lambda_expression*/, false /*allow_table_expression*/);
|
||||
|
||||
if (query_node_typed.getPrewhere())
|
||||
resolveExpressionNode(query_node_typed.getPrewhere(), scope, false /*allow_lambda_expression*/, false /*allow_table_expression*/);
|
||||
|
||||
@ -7123,13 +7119,6 @@ void QueryAnalyzer::resolveQuery(const QueryTreeNodePtr & query_node, Identifier
|
||||
scope.scope_node->formatASTForErrorMessage());
|
||||
}
|
||||
|
||||
/** WITH section can be safely removed, because WITH section only can provide aliases to query expressions
|
||||
* and CTE for other sections to use.
|
||||
*
|
||||
* Example: WITH 1 AS constant, (x -> x + 1) AS lambda, a AS (SELECT * FROM test_table);
|
||||
*/
|
||||
query_node_typed.getWith().getNodes().clear();
|
||||
|
||||
/** WINDOW section can be safely removed, because WINDOW section can only provide window definition to window functions.
|
||||
*
|
||||
* Example: SELECT count(*) OVER w FROM test_table WINDOW w AS (PARTITION BY id);
|
||||
|
||||
@ -42,6 +42,7 @@
|
||||
#include <Analyzer/Passes/CrossToInnerJoinPass.h>
|
||||
#include <Analyzer/Passes/ShardNumColumnToFunctionPass.h>
|
||||
#include <Analyzer/Passes/ConvertQueryToCNFPass.h>
|
||||
#include <Analyzer/Passes/OptimizeDateOrDateTimeConverterWithPreimagePass.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
@ -278,6 +279,7 @@ void addQueryTreePasses(QueryTreePassManager & manager)
|
||||
manager.addPass(std::make_unique<AutoFinalOnQueryPass>());
|
||||
manager.addPass(std::make_unique<CrossToInnerJoinPass>());
|
||||
manager.addPass(std::make_unique<ShardNumColumnToFunctionPass>());
|
||||
manager.addPass(std::make_unique<OptimizeDateOrDateTimeConverterWithPreimagePass>());
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@ -77,10 +77,12 @@ BackupEntriesCollector::BackupEntriesCollector(
|
||||
const ASTBackupQuery::Elements & backup_query_elements_,
|
||||
const BackupSettings & backup_settings_,
|
||||
std::shared_ptr<IBackupCoordination> backup_coordination_,
|
||||
const ReadSettings & read_settings_,
|
||||
const ContextPtr & context_)
|
||||
: backup_query_elements(backup_query_elements_)
|
||||
, backup_settings(backup_settings_)
|
||||
, backup_coordination(backup_coordination_)
|
||||
, read_settings(read_settings_)
|
||||
, context(context_)
|
||||
, on_cluster_first_sync_timeout(context->getConfigRef().getUInt64("backups.on_cluster_first_sync_timeout", 180000))
|
||||
, consistent_metadata_snapshot_timeout(context->getConfigRef().getUInt64("backups.consistent_metadata_snapshot_timeout", 600000))
|
||||
|
||||
@ -30,6 +30,7 @@ public:
|
||||
BackupEntriesCollector(const ASTBackupQuery::Elements & backup_query_elements_,
|
||||
const BackupSettings & backup_settings_,
|
||||
std::shared_ptr<IBackupCoordination> backup_coordination_,
|
||||
const ReadSettings & read_settings_,
|
||||
const ContextPtr & context_);
|
||||
~BackupEntriesCollector();
|
||||
|
||||
@ -40,6 +41,7 @@ public:
|
||||
|
||||
const BackupSettings & getBackupSettings() const { return backup_settings; }
|
||||
std::shared_ptr<IBackupCoordination> getBackupCoordination() const { return backup_coordination; }
|
||||
const ReadSettings & getReadSettings() const { return read_settings; }
|
||||
ContextPtr getContext() const { return context; }
|
||||
|
||||
/// Adds a backup entry which will be later returned by run().
|
||||
@ -93,6 +95,7 @@ private:
|
||||
const ASTBackupQuery::Elements backup_query_elements;
|
||||
const BackupSettings backup_settings;
|
||||
std::shared_ptr<IBackupCoordination> backup_coordination;
|
||||
const ReadSettings read_settings;
|
||||
ContextPtr context;
|
||||
std::chrono::milliseconds on_cluster_first_sync_timeout;
|
||||
std::chrono::milliseconds consistent_metadata_snapshot_timeout;
|
||||
|
||||
@ -57,7 +57,7 @@ UInt64 BackupEntryFromImmutableFile::getSize() const
|
||||
return *file_size;
|
||||
}
|
||||
|
||||
UInt128 BackupEntryFromImmutableFile::getChecksum() const
|
||||
UInt128 BackupEntryFromImmutableFile::getChecksum(const ReadSettings & read_settings) const
|
||||
{
|
||||
{
|
||||
std::lock_guard lock{size_and_checksum_mutex};
|
||||
@ -73,7 +73,7 @@ UInt128 BackupEntryFromImmutableFile::getChecksum() const
|
||||
}
|
||||
}
|
||||
|
||||
auto calculated_checksum = BackupEntryWithChecksumCalculation<IBackupEntry>::getChecksum();
|
||||
auto calculated_checksum = BackupEntryWithChecksumCalculation<IBackupEntry>::getChecksum(read_settings);
|
||||
|
||||
{
|
||||
std::lock_guard lock{size_and_checksum_mutex};
|
||||
@ -86,13 +86,13 @@ UInt128 BackupEntryFromImmutableFile::getChecksum() const
|
||||
}
|
||||
}
|
||||
|
||||
std::optional<UInt128> BackupEntryFromImmutableFile::getPartialChecksum(size_t prefix_length) const
|
||||
std::optional<UInt128> BackupEntryFromImmutableFile::getPartialChecksum(size_t prefix_length, const ReadSettings & read_settings) const
|
||||
{
|
||||
if (prefix_length == 0)
|
||||
return 0;
|
||||
|
||||
if (prefix_length >= getSize())
|
||||
return getChecksum();
|
||||
return getChecksum(read_settings);
|
||||
|
||||
/// For immutable files we don't use partial checksums.
|
||||
return std::nullopt;
|
||||
|
||||
@ -27,8 +27,8 @@ public:
|
||||
std::unique_ptr<SeekableReadBuffer> getReadBuffer(const ReadSettings & read_settings) const override;
|
||||
|
||||
UInt64 getSize() const override;
|
||||
UInt128 getChecksum() const override;
|
||||
std::optional<UInt128> getPartialChecksum(size_t prefix_length) const override;
|
||||
UInt128 getChecksum(const ReadSettings & read_settings) const override;
|
||||
std::optional<UInt128> getPartialChecksum(size_t prefix_length, const ReadSettings & read_settings) const override;
|
||||
|
||||
DataSourceDescription getDataSourceDescription() const override { return data_source_description; }
|
||||
bool isEncryptedByDisk() const override { return copy_encrypted; }
|
||||
|
||||
@ -11,17 +11,17 @@ namespace DB
|
||||
{
|
||||
namespace
|
||||
{
|
||||
String readFile(const String & file_path)
|
||||
String readFile(const String & file_path, const ReadSettings & read_settings)
|
||||
{
|
||||
auto buf = createReadBufferFromFileBase(file_path, /* settings= */ {});
|
||||
auto buf = createReadBufferFromFileBase(file_path, read_settings);
|
||||
String s;
|
||||
readStringUntilEOF(s, *buf);
|
||||
return s;
|
||||
}
|
||||
|
||||
String readFile(const DiskPtr & disk, const String & file_path, bool copy_encrypted)
|
||||
String readFile(const DiskPtr & disk, const String & file_path, const ReadSettings & read_settings, bool copy_encrypted)
|
||||
{
|
||||
auto buf = copy_encrypted ? disk->readEncryptedFile(file_path, {}) : disk->readFile(file_path);
|
||||
auto buf = copy_encrypted ? disk->readEncryptedFile(file_path, read_settings) : disk->readFile(file_path, read_settings);
|
||||
String s;
|
||||
readStringUntilEOF(s, *buf);
|
||||
return s;
|
||||
@ -29,19 +29,19 @@ namespace
|
||||
}
|
||||
|
||||
|
||||
BackupEntryFromSmallFile::BackupEntryFromSmallFile(const String & file_path_)
|
||||
BackupEntryFromSmallFile::BackupEntryFromSmallFile(const String & file_path_, const ReadSettings & read_settings_)
|
||||
: file_path(file_path_)
|
||||
, data_source_description(DiskLocal::getLocalDataSourceDescription(file_path_))
|
||||
, data(readFile(file_path_))
|
||||
, data(readFile(file_path_, read_settings_))
|
||||
{
|
||||
}
|
||||
|
||||
BackupEntryFromSmallFile::BackupEntryFromSmallFile(const DiskPtr & disk_, const String & file_path_, bool copy_encrypted_)
|
||||
BackupEntryFromSmallFile::BackupEntryFromSmallFile(const DiskPtr & disk_, const String & file_path_, const ReadSettings & read_settings_, bool copy_encrypted_)
|
||||
: disk(disk_)
|
||||
, file_path(file_path_)
|
||||
, data_source_description(disk_->getDataSourceDescription())
|
||||
, copy_encrypted(copy_encrypted_ && data_source_description.is_encrypted)
|
||||
, data(readFile(disk_, file_path, copy_encrypted))
|
||||
, data(readFile(disk_, file_path, read_settings_, copy_encrypted))
|
||||
{
|
||||
}
|
||||
|
||||
|
||||
@ -13,8 +13,8 @@ using DiskPtr = std::shared_ptr<IDisk>;
|
||||
class BackupEntryFromSmallFile : public BackupEntryWithChecksumCalculation<IBackupEntry>
|
||||
{
|
||||
public:
|
||||
explicit BackupEntryFromSmallFile(const String & file_path_);
|
||||
BackupEntryFromSmallFile(const DiskPtr & disk_, const String & file_path_, bool copy_encrypted_ = false);
|
||||
explicit BackupEntryFromSmallFile(const String & file_path_, const ReadSettings & read_settings_);
|
||||
BackupEntryFromSmallFile(const DiskPtr & disk_, const String & file_path_, const ReadSettings & read_settings_, bool copy_encrypted_ = false);
|
||||
|
||||
std::unique_ptr<SeekableReadBuffer> getReadBuffer(const ReadSettings &) const override;
|
||||
UInt64 getSize() const override { return data.size(); }
|
||||
|
||||
@ -6,7 +6,7 @@ namespace DB
|
||||
{
|
||||
|
||||
template <typename Base>
|
||||
UInt128 BackupEntryWithChecksumCalculation<Base>::getChecksum() const
|
||||
UInt128 BackupEntryWithChecksumCalculation<Base>::getChecksum(const ReadSettings & read_settings) const
|
||||
{
|
||||
{
|
||||
std::lock_guard lock{checksum_calculation_mutex};
|
||||
@ -26,7 +26,7 @@ UInt128 BackupEntryWithChecksumCalculation<Base>::getChecksum() const
|
||||
}
|
||||
else
|
||||
{
|
||||
auto read_buffer = this->getReadBuffer(ReadSettings{}.adjustBufferSize(size));
|
||||
auto read_buffer = this->getReadBuffer(read_settings.adjustBufferSize(size));
|
||||
HashingReadBuffer hashing_read_buffer(*read_buffer);
|
||||
hashing_read_buffer.ignoreAll();
|
||||
calculated_checksum = hashing_read_buffer.getHash();
|
||||
@ -37,23 +37,20 @@ UInt128 BackupEntryWithChecksumCalculation<Base>::getChecksum() const
|
||||
}
|
||||
|
||||
template <typename Base>
|
||||
std::optional<UInt128> BackupEntryWithChecksumCalculation<Base>::getPartialChecksum(size_t prefix_length) const
|
||||
std::optional<UInt128> BackupEntryWithChecksumCalculation<Base>::getPartialChecksum(size_t prefix_length, const ReadSettings & read_settings) const
|
||||
{
|
||||
if (prefix_length == 0)
|
||||
return 0;
|
||||
|
||||
size_t size = this->getSize();
|
||||
if (prefix_length >= size)
|
||||
return this->getChecksum();
|
||||
return this->getChecksum(read_settings);
|
||||
|
||||
std::lock_guard lock{checksum_calculation_mutex};
|
||||
|
||||
ReadSettings read_settings;
|
||||
if (calculated_checksum)
|
||||
read_settings.adjustBufferSize(calculated_checksum ? prefix_length : size);
|
||||
|
||||
auto read_buffer = this->getReadBuffer(read_settings);
|
||||
auto read_buffer = this->getReadBuffer(read_settings.adjustBufferSize(calculated_checksum ? prefix_length : size));
|
||||
HashingReadBuffer hashing_read_buffer(*read_buffer);
|
||||
|
||||
hashing_read_buffer.ignore(prefix_length);
|
||||
auto partial_checksum = hashing_read_buffer.getHash();
|
||||
|
||||
|
||||
@ -11,8 +11,8 @@ template <typename Base>
|
||||
class BackupEntryWithChecksumCalculation : public Base
|
||||
{
|
||||
public:
|
||||
UInt128 getChecksum() const override;
|
||||
std::optional<UInt128> getPartialChecksum(size_t prefix_length) const override;
|
||||
UInt128 getChecksum(const ReadSettings & read_settings) const override;
|
||||
std::optional<UInt128> getPartialChecksum(size_t prefix_length, const ReadSettings & read_settings) const override;
|
||||
|
||||
private:
|
||||
mutable std::optional<UInt128> calculated_checksum;
|
||||
|
||||
@ -17,8 +17,8 @@ public:
|
||||
|
||||
std::unique_ptr<SeekableReadBuffer> getReadBuffer(const ReadSettings & read_settings) const override { return entry->getReadBuffer(read_settings); }
|
||||
UInt64 getSize() const override { return entry->getSize(); }
|
||||
UInt128 getChecksum() const override { return entry->getChecksum(); }
|
||||
std::optional<UInt128> getPartialChecksum(size_t prefix_length) const override { return entry->getPartialChecksum(prefix_length); }
|
||||
UInt128 getChecksum(const ReadSettings & read_settings) const override { return entry->getChecksum(read_settings); }
|
||||
std::optional<UInt128> getPartialChecksum(size_t prefix_length, const ReadSettings & read_settings) const override { return entry->getPartialChecksum(prefix_length, read_settings); }
|
||||
DataSourceDescription getDataSourceDescription() const override { return entry->getDataSourceDescription(); }
|
||||
bool isEncryptedByDisk() const override { return entry->isEncryptedByDisk(); }
|
||||
bool isFromFile() const override { return entry->isFromFile(); }
|
||||
|
||||
@ -3,6 +3,8 @@
|
||||
#include <Backups/IBackup.h>
|
||||
#include <Backups/BackupInfo.h>
|
||||
#include <Core/Types.h>
|
||||
#include <IO/ReadSettings.h>
|
||||
#include <IO/WriteSettings.h>
|
||||
#include <Parsers/IAST_fwd.h>
|
||||
#include <boost/noncopyable.hpp>
|
||||
#include <memory>
|
||||
@ -37,6 +39,8 @@ public:
|
||||
std::optional<UUID> backup_uuid;
|
||||
bool deduplicate_files = true;
|
||||
bool allow_s3_native_copy = true;
|
||||
ReadSettings read_settings;
|
||||
WriteSettings write_settings;
|
||||
};
|
||||
|
||||
static BackupFactory & instance();
|
||||
|
||||
@ -57,12 +57,12 @@ namespace
|
||||
|
||||
/// Calculate checksum for backup entry if it's empty.
|
||||
/// Also able to calculate additional checksum of some prefix.
|
||||
ChecksumsForNewEntry calculateNewEntryChecksumsIfNeeded(const BackupEntryPtr & entry, size_t prefix_size)
|
||||
ChecksumsForNewEntry calculateNewEntryChecksumsIfNeeded(const BackupEntryPtr & entry, size_t prefix_size, const ReadSettings & read_settings)
|
||||
{
|
||||
ChecksumsForNewEntry res;
|
||||
/// The partial checksum should be calculated before the full checksum to enable optimization in BackupEntryWithChecksumCalculation.
|
||||
res.prefix_checksum = entry->getPartialChecksum(prefix_size);
|
||||
res.full_checksum = entry->getChecksum();
|
||||
res.prefix_checksum = entry->getPartialChecksum(prefix_size, read_settings);
|
||||
res.full_checksum = entry->getChecksum(read_settings);
|
||||
return res;
|
||||
}
|
||||
|
||||
@ -93,7 +93,12 @@ String BackupFileInfo::describe() const
|
||||
}
|
||||
|
||||
|
||||
BackupFileInfo buildFileInfoForBackupEntry(const String & file_name, const BackupEntryPtr & backup_entry, const BackupPtr & base_backup, Poco::Logger * log)
|
||||
BackupFileInfo buildFileInfoForBackupEntry(
|
||||
const String & file_name,
|
||||
const BackupEntryPtr & backup_entry,
|
||||
const BackupPtr & base_backup,
|
||||
const ReadSettings & read_settings,
|
||||
Poco::Logger * log)
|
||||
{
|
||||
auto adjusted_path = removeLeadingSlash(file_name);
|
||||
|
||||
@ -126,7 +131,7 @@ BackupFileInfo buildFileInfoForBackupEntry(const String & file_name, const Backu
|
||||
/// File with the same name but smaller size exist in previous backup
|
||||
if (check_base == CheckBackupResult::HasPrefix)
|
||||
{
|
||||
auto checksums = calculateNewEntryChecksumsIfNeeded(backup_entry, base_backup_file_info->first);
|
||||
auto checksums = calculateNewEntryChecksumsIfNeeded(backup_entry, base_backup_file_info->first, read_settings);
|
||||
info.checksum = checksums.full_checksum;
|
||||
|
||||
/// We have prefix of this file in backup with the same checksum.
|
||||
@ -146,7 +151,7 @@ BackupFileInfo buildFileInfoForBackupEntry(const String & file_name, const Backu
|
||||
{
|
||||
/// We have full file or have nothing, first of all let's get checksum
|
||||
/// of current file
|
||||
auto checksums = calculateNewEntryChecksumsIfNeeded(backup_entry, 0);
|
||||
auto checksums = calculateNewEntryChecksumsIfNeeded(backup_entry, 0, read_settings);
|
||||
info.checksum = checksums.full_checksum;
|
||||
|
||||
if (info.checksum == base_backup_file_info->second)
|
||||
@ -169,7 +174,7 @@ BackupFileInfo buildFileInfoForBackupEntry(const String & file_name, const Backu
|
||||
}
|
||||
else
|
||||
{
|
||||
auto checksums = calculateNewEntryChecksumsIfNeeded(backup_entry, 0);
|
||||
auto checksums = calculateNewEntryChecksumsIfNeeded(backup_entry, 0, read_settings);
|
||||
info.checksum = checksums.full_checksum;
|
||||
}
|
||||
|
||||
@ -188,7 +193,7 @@ BackupFileInfo buildFileInfoForBackupEntry(const String & file_name, const Backu
|
||||
return info;
|
||||
}
|
||||
|
||||
BackupFileInfos buildFileInfosForBackupEntries(const BackupEntries & backup_entries, const BackupPtr & base_backup, ThreadPool & thread_pool)
|
||||
BackupFileInfos buildFileInfosForBackupEntries(const BackupEntries & backup_entries, const BackupPtr & base_backup, const ReadSettings & read_settings, ThreadPool & thread_pool)
|
||||
{
|
||||
BackupFileInfos infos;
|
||||
infos.resize(backup_entries.size());
|
||||
@ -210,7 +215,7 @@ BackupFileInfos buildFileInfosForBackupEntries(const BackupEntries & backup_entr
|
||||
++num_active_jobs;
|
||||
}
|
||||
|
||||
auto job = [&mutex, &num_active_jobs, &event, &exception, &infos, &backup_entries, &base_backup, &thread_group, i, log](bool async)
|
||||
auto job = [&mutex, &num_active_jobs, &event, &exception, &infos, &backup_entries, &read_settings, &base_backup, &thread_group, i, log](bool async)
|
||||
{
|
||||
SCOPE_EXIT_SAFE({
|
||||
std::lock_guard lock{mutex};
|
||||
@ -237,7 +242,7 @@ BackupFileInfos buildFileInfosForBackupEntries(const BackupEntries & backup_entr
|
||||
return;
|
||||
}
|
||||
|
||||
infos[i] = buildFileInfoForBackupEntry(name, entry, base_backup, log);
|
||||
infos[i] = buildFileInfoForBackupEntry(name, entry, base_backup, read_settings, log);
|
||||
}
|
||||
catch (...)
|
||||
{
|
||||
|
||||
@ -13,6 +13,7 @@ class IBackupEntry;
|
||||
using BackupPtr = std::shared_ptr<const IBackup>;
|
||||
using BackupEntryPtr = std::shared_ptr<const IBackupEntry>;
|
||||
using BackupEntries = std::vector<std::pair<String, BackupEntryPtr>>;
|
||||
struct ReadSettings;
|
||||
|
||||
|
||||
/// Information about a file stored in a backup.
|
||||
@ -66,9 +67,9 @@ struct BackupFileInfo
|
||||
using BackupFileInfos = std::vector<BackupFileInfo>;
|
||||
|
||||
/// Builds a BackupFileInfo for a specified backup entry.
|
||||
BackupFileInfo buildFileInfoForBackupEntry(const String & file_name, const BackupEntryPtr & backup_entry, const BackupPtr & base_backup, Poco::Logger * log);
|
||||
BackupFileInfo buildFileInfoForBackupEntry(const String & file_name, const BackupEntryPtr & backup_entry, const BackupPtr & base_backup, const ReadSettings & read_settings, Poco::Logger * log);
|
||||
|
||||
/// Builds a vector of BackupFileInfos for specified backup entries.
|
||||
BackupFileInfos buildFileInfosForBackupEntries(const BackupEntries & backup_entries, const BackupPtr & base_backup, ThreadPool & thread_pool);
|
||||
BackupFileInfos buildFileInfosForBackupEntries(const BackupEntries & backup_entries, const BackupPtr & base_backup, const ReadSettings & read_settings, ThreadPool & thread_pool);
|
||||
|
||||
}
|
||||
|
||||
@ -4,17 +4,16 @@
|
||||
#include <IO/copyData.h>
|
||||
#include <IO/WriteBufferFromFileBase.h>
|
||||
#include <IO/ReadBufferFromFileBase.h>
|
||||
#include <Interpreters/Context.h>
|
||||
#include <Common/logger_useful.h>
|
||||
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
BackupReaderDefault::BackupReaderDefault(Poco::Logger * log_, const ContextPtr & context_)
|
||||
BackupReaderDefault::BackupReaderDefault(const ReadSettings & read_settings_, const WriteSettings & write_settings_, Poco::Logger * log_)
|
||||
: log(log_)
|
||||
, read_settings(context_->getBackupReadSettings())
|
||||
, write_settings(context_->getWriteSettings())
|
||||
, read_settings(read_settings_)
|
||||
, write_settings(write_settings_)
|
||||
, write_buffer_size(DBMS_DEFAULT_BUFFER_SIZE)
|
||||
{
|
||||
}
|
||||
@ -37,10 +36,10 @@ void BackupReaderDefault::copyFileToDisk(const String & path_in_backup, size_t f
|
||||
write_buffer->finalize();
|
||||
}
|
||||
|
||||
BackupWriterDefault::BackupWriterDefault(Poco::Logger * log_, const ContextPtr & context_)
|
||||
BackupWriterDefault::BackupWriterDefault(const ReadSettings & read_settings_, const WriteSettings & write_settings_, Poco::Logger * log_)
|
||||
: log(log_)
|
||||
, read_settings(context_->getBackupReadSettings())
|
||||
, write_settings(context_->getWriteSettings())
|
||||
, read_settings(read_settings_)
|
||||
, write_settings(write_settings_)
|
||||
, write_buffer_size(DBMS_DEFAULT_BUFFER_SIZE)
|
||||
{
|
||||
}
|
||||
|
||||
@ -3,7 +3,6 @@
|
||||
#include <Backups/BackupIO.h>
|
||||
#include <IO/ReadSettings.h>
|
||||
#include <IO/WriteSettings.h>
|
||||
#include <Interpreters/Context_fwd.h>
|
||||
|
||||
|
||||
namespace DB
|
||||
@ -19,7 +18,7 @@ enum class WriteMode;
|
||||
class BackupReaderDefault : public IBackupReader
|
||||
{
|
||||
public:
|
||||
BackupReaderDefault(Poco::Logger * log_, const ContextPtr & context_);
|
||||
BackupReaderDefault(const ReadSettings & read_settings_, const WriteSettings & write_settings_, Poco::Logger * log_);
|
||||
~BackupReaderDefault() override = default;
|
||||
|
||||
/// The function copyFileToDisk() can be much faster than reading the file with readFile() and then writing it to some disk.
|
||||
@ -46,7 +45,7 @@ protected:
|
||||
class BackupWriterDefault : public IBackupWriter
|
||||
{
|
||||
public:
|
||||
BackupWriterDefault(Poco::Logger * log_, const ContextPtr & context_);
|
||||
BackupWriterDefault(const ReadSettings & read_settings_, const WriteSettings & write_settings_, Poco::Logger * log_);
|
||||
~BackupWriterDefault() override = default;
|
||||
|
||||
bool fileContentsEqual(const String & file_name, const String & expected_file_contents) override;
|
||||
|
||||
@ -8,8 +8,8 @@
|
||||
namespace DB
|
||||
{
|
||||
|
||||
BackupReaderDisk::BackupReaderDisk(const DiskPtr & disk_, const String & root_path_, const ContextPtr & context_)
|
||||
: BackupReaderDefault(&Poco::Logger::get("BackupReaderDisk"), context_)
|
||||
BackupReaderDisk::BackupReaderDisk(const DiskPtr & disk_, const String & root_path_, const ReadSettings & read_settings_, const WriteSettings & write_settings_)
|
||||
: BackupReaderDefault(read_settings_, write_settings_, &Poco::Logger::get("BackupReaderDisk"))
|
||||
, disk(disk_)
|
||||
, root_path(root_path_)
|
||||
, data_source_description(disk->getDataSourceDescription())
|
||||
@ -56,8 +56,8 @@ void BackupReaderDisk::copyFileToDisk(const String & path_in_backup, size_t file
|
||||
}
|
||||
|
||||
|
||||
BackupWriterDisk::BackupWriterDisk(const DiskPtr & disk_, const String & root_path_, const ContextPtr & context_)
|
||||
: BackupWriterDefault(&Poco::Logger::get("BackupWriterDisk"), context_)
|
||||
BackupWriterDisk::BackupWriterDisk(const DiskPtr & disk_, const String & root_path_, const ReadSettings & read_settings_, const WriteSettings & write_settings_)
|
||||
: BackupWriterDefault(read_settings_, write_settings_, &Poco::Logger::get("BackupWriterDisk"))
|
||||
, disk(disk_)
|
||||
, root_path(root_path_)
|
||||
, data_source_description(disk->getDataSourceDescription())
|
||||
|
||||
@ -13,7 +13,7 @@ using DiskPtr = std::shared_ptr<IDisk>;
|
||||
class BackupReaderDisk : public BackupReaderDefault
|
||||
{
|
||||
public:
|
||||
BackupReaderDisk(const DiskPtr & disk_, const String & root_path_, const ContextPtr & context_);
|
||||
BackupReaderDisk(const DiskPtr & disk_, const String & root_path_, const ReadSettings & read_settings_, const WriteSettings & write_settings_);
|
||||
~BackupReaderDisk() override;
|
||||
|
||||
bool fileExists(const String & file_name) override;
|
||||
@ -33,7 +33,7 @@ private:
|
||||
class BackupWriterDisk : public BackupWriterDefault
|
||||
{
|
||||
public:
|
||||
BackupWriterDisk(const DiskPtr & disk_, const String & root_path_, const ContextPtr & context_);
|
||||
BackupWriterDisk(const DiskPtr & disk_, const String & root_path_, const ReadSettings & read_settings_, const WriteSettings & write_settings_);
|
||||
~BackupWriterDisk() override;
|
||||
|
||||
bool fileExists(const String & file_name) override;
|
||||
|
||||
@ -16,8 +16,8 @@ namespace ErrorCodes
|
||||
extern const int LOGICAL_ERROR;
|
||||
}
|
||||
|
||||
BackupReaderFile::BackupReaderFile(const String & root_path_, const ContextPtr & context_)
|
||||
: BackupReaderDefault(&Poco::Logger::get("BackupReaderFile"), context_)
|
||||
BackupReaderFile::BackupReaderFile(const String & root_path_, const ReadSettings & read_settings_, const WriteSettings & write_settings_)
|
||||
: BackupReaderDefault(read_settings_, write_settings_, &Poco::Logger::get("BackupReaderFile"))
|
||||
, root_path(root_path_)
|
||||
, data_source_description(DiskLocal::getLocalDataSourceDescription(root_path))
|
||||
{
|
||||
@ -74,8 +74,8 @@ void BackupReaderFile::copyFileToDisk(const String & path_in_backup, size_t file
|
||||
}
|
||||
|
||||
|
||||
BackupWriterFile::BackupWriterFile(const String & root_path_, const ContextPtr & context_)
|
||||
: BackupWriterDefault(&Poco::Logger::get("BackupWriterFile"), context_)
|
||||
BackupWriterFile::BackupWriterFile(const String & root_path_, const ReadSettings & read_settings_, const WriteSettings & write_settings_)
|
||||
: BackupWriterDefault(read_settings_, write_settings_, &Poco::Logger::get("BackupWriterFile"))
|
||||
, root_path(root_path_)
|
||||
, data_source_description(DiskLocal::getLocalDataSourceDescription(root_path))
|
||||
{
|
||||
|
||||
@ -11,7 +11,7 @@ namespace DB
|
||||
class BackupReaderFile : public BackupReaderDefault
|
||||
{
|
||||
public:
|
||||
explicit BackupReaderFile(const String & root_path_, const ContextPtr & context_);
|
||||
explicit BackupReaderFile(const String & root_path_, const ReadSettings & read_settings_, const WriteSettings & write_settings_);
|
||||
|
||||
bool fileExists(const String & file_name) override;
|
||||
UInt64 getFileSize(const String & file_name) override;
|
||||
@ -29,7 +29,7 @@ private:
|
||||
class BackupWriterFile : public BackupWriterDefault
|
||||
{
|
||||
public:
|
||||
BackupWriterFile(const String & root_path_, const ContextPtr & context_);
|
||||
BackupWriterFile(const String & root_path_, const ReadSettings & read_settings_, const WriteSettings & write_settings_);
|
||||
|
||||
bool fileExists(const String & file_name) override;
|
||||
UInt64 getFileSize(const String & file_name) override;
|
||||
|
||||
@ -101,8 +101,14 @@ namespace
|
||||
|
||||
|
||||
BackupReaderS3::BackupReaderS3(
|
||||
const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const ContextPtr & context_)
|
||||
: BackupReaderDefault(&Poco::Logger::get("BackupReaderS3"), context_)
|
||||
const S3::URI & s3_uri_,
|
||||
const String & access_key_id_,
|
||||
const String & secret_access_key_,
|
||||
bool allow_s3_native_copy,
|
||||
const ReadSettings & read_settings_,
|
||||
const WriteSettings & write_settings_,
|
||||
const ContextPtr & context_)
|
||||
: BackupReaderDefault(read_settings_, write_settings_, &Poco::Logger::get("BackupReaderS3"))
|
||||
, s3_uri(s3_uri_)
|
||||
, client(makeS3Client(s3_uri_, access_key_id_, secret_access_key_, context_))
|
||||
, request_settings(context_->getStorageS3Settings().getSettings(s3_uri.uri.toString()).request_settings)
|
||||
@ -178,8 +184,15 @@ void BackupReaderS3::copyFileToDisk(const String & path_in_backup, size_t file_s
|
||||
|
||||
|
||||
BackupWriterS3::BackupWriterS3(
|
||||
const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const String & storage_class_name, const ContextPtr & context_)
|
||||
: BackupWriterDefault(&Poco::Logger::get("BackupWriterS3"), context_)
|
||||
const S3::URI & s3_uri_,
|
||||
const String & access_key_id_,
|
||||
const String & secret_access_key_,
|
||||
bool allow_s3_native_copy,
|
||||
const String & storage_class_name,
|
||||
const ReadSettings & read_settings_,
|
||||
const WriteSettings & write_settings_,
|
||||
const ContextPtr & context_)
|
||||
: BackupWriterDefault(read_settings_, write_settings_, &Poco::Logger::get("BackupWriterS3"))
|
||||
, s3_uri(s3_uri_)
|
||||
, client(makeS3Client(s3_uri_, access_key_id_, secret_access_key_, context_))
|
||||
, request_settings(context_->getStorageS3Settings().getSettings(s3_uri.uri.toString()).request_settings)
|
||||
|
||||
@ -17,7 +17,7 @@ namespace DB
|
||||
class BackupReaderS3 : public BackupReaderDefault
|
||||
{
|
||||
public:
|
||||
BackupReaderS3(const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const ContextPtr & context_);
|
||||
BackupReaderS3(const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const ReadSettings & read_settings_, const WriteSettings & write_settings_, const ContextPtr & context_);
|
||||
~BackupReaderS3() override;
|
||||
|
||||
bool fileExists(const String & file_name) override;
|
||||
@ -38,7 +38,7 @@ private:
|
||||
class BackupWriterS3 : public BackupWriterDefault
|
||||
{
|
||||
public:
|
||||
BackupWriterS3(const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const String & storage_class_name, const ContextPtr & context_);
|
||||
BackupWriterS3(const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const String & storage_class_name, const ReadSettings & read_settings_, const WriteSettings & write_settings_, const ContextPtr & context_);
|
||||
~BackupWriterS3() override;
|
||||
|
||||
bool fileExists(const String & file_name) override;
|
||||
|
||||
@ -27,6 +27,7 @@ namespace ErrorCodes
|
||||
M(Bool, decrypt_files_from_encrypted_disks) \
|
||||
M(Bool, deduplicate_files) \
|
||||
M(Bool, allow_s3_native_copy) \
|
||||
M(Bool, read_from_filesystem_cache) \
|
||||
M(UInt64, shard_num) \
|
||||
M(UInt64, replica_num) \
|
||||
M(Bool, internal) \
|
||||
|
||||
@ -44,6 +44,10 @@ struct BackupSettings
|
||||
/// Whether native copy is allowed (optimization for cloud storages, that sometimes could have bugs)
|
||||
bool allow_s3_native_copy = true;
|
||||
|
||||
/// Allow to use the filesystem cache in passive mode - benefit from the existing cache entries,
|
||||
/// but don't put more entries into the cache.
|
||||
bool read_from_filesystem_cache = true;
|
||||
|
||||
/// 1-based shard index to store in the backup. 0 means all shards.
|
||||
/// Can only be used with BACKUP ON CLUSTER.
|
||||
size_t shard_num = 0;
|
||||
|
||||
@ -178,6 +178,42 @@ namespace
|
||||
{
|
||||
return status == BackupStatus::RESTORING;
|
||||
}
|
||||
|
||||
/// We use slightly different read and write settings for backup/restore
|
||||
/// with a separate throttler and limited usage of filesystem cache.
|
||||
ReadSettings getReadSettingsForBackup(const ContextPtr & context, const BackupSettings & backup_settings)
|
||||
{
|
||||
auto read_settings = context->getReadSettings();
|
||||
read_settings.remote_throttler = context->getBackupsThrottler();
|
||||
read_settings.local_throttler = context->getBackupsThrottler();
|
||||
read_settings.enable_filesystem_cache = backup_settings.read_from_filesystem_cache;
|
||||
read_settings.read_from_filesystem_cache_if_exists_otherwise_bypass_cache = backup_settings.read_from_filesystem_cache;
|
||||
return read_settings;
|
||||
}
|
||||
|
||||
WriteSettings getWriteSettingsForBackup(const ContextPtr & context)
|
||||
{
|
||||
auto write_settings = context->getWriteSettings();
|
||||
write_settings.enable_filesystem_cache_on_write_operations = false;
|
||||
return write_settings;
|
||||
}
|
||||
|
||||
ReadSettings getReadSettingsForRestore(const ContextPtr & context)
|
||||
{
|
||||
auto read_settings = context->getReadSettings();
|
||||
read_settings.remote_throttler = context->getBackupsThrottler();
|
||||
read_settings.local_throttler = context->getBackupsThrottler();
|
||||
read_settings.enable_filesystem_cache = false;
|
||||
read_settings.read_from_filesystem_cache_if_exists_otherwise_bypass_cache = false;
|
||||
return read_settings;
|
||||
}
|
||||
|
||||
WriteSettings getWriteSettingsForRestore(const ContextPtr & context)
|
||||
{
|
||||
auto write_settings = context->getWriteSettings();
|
||||
write_settings.enable_filesystem_cache_on_write_operations = false;
|
||||
return write_settings;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@ -350,6 +386,8 @@ void BackupsWorker::doBackup(
|
||||
backup_create_params.backup_uuid = backup_settings.backup_uuid;
|
||||
backup_create_params.deduplicate_files = backup_settings.deduplicate_files;
|
||||
backup_create_params.allow_s3_native_copy = backup_settings.allow_s3_native_copy;
|
||||
backup_create_params.read_settings = getReadSettingsForBackup(context, backup_settings);
|
||||
backup_create_params.write_settings = getWriteSettingsForBackup(context);
|
||||
BackupMutablePtr backup = BackupFactory::instance().createBackup(backup_create_params);
|
||||
|
||||
/// Write the backup.
|
||||
@ -378,12 +416,12 @@ void BackupsWorker::doBackup(
|
||||
/// Prepare backup entries.
|
||||
BackupEntries backup_entries;
|
||||
{
|
||||
BackupEntriesCollector backup_entries_collector{backup_query->elements, backup_settings, backup_coordination, context};
|
||||
BackupEntriesCollector backup_entries_collector{backup_query->elements, backup_settings, backup_coordination, backup_create_params.read_settings, context};
|
||||
backup_entries = backup_entries_collector.run();
|
||||
}
|
||||
|
||||
/// Write the backup entries to the backup.
|
||||
buildFileInfosForBackupEntries(backup, backup_entries, backup_coordination);
|
||||
buildFileInfosForBackupEntries(backup, backup_entries, backup_create_params.read_settings, backup_coordination);
|
||||
writeBackupEntries(backup, std::move(backup_entries), backup_id, backup_coordination, backup_settings.internal);
|
||||
|
||||
/// We have written our backup entries, we need to tell other hosts (they could be waiting for it).
|
||||
@ -433,12 +471,12 @@ void BackupsWorker::doBackup(
|
||||
}
|
||||
|
||||
|
||||
void BackupsWorker::buildFileInfosForBackupEntries(const BackupPtr & backup, const BackupEntries & backup_entries, std::shared_ptr<IBackupCoordination> backup_coordination)
|
||||
void BackupsWorker::buildFileInfosForBackupEntries(const BackupPtr & backup, const BackupEntries & backup_entries, const ReadSettings & read_settings, std::shared_ptr<IBackupCoordination> backup_coordination)
|
||||
{
|
||||
LOG_TRACE(log, "{}", Stage::BUILDING_FILE_INFOS);
|
||||
backup_coordination->setStage(Stage::BUILDING_FILE_INFOS, "");
|
||||
backup_coordination->waitForStage(Stage::BUILDING_FILE_INFOS);
|
||||
backup_coordination->addFileInfos(::DB::buildFileInfosForBackupEntries(backup_entries, backup->getBaseBackup(), *backups_thread_pool));
|
||||
backup_coordination->addFileInfos(::DB::buildFileInfosForBackupEntries(backup_entries, backup->getBaseBackup(), read_settings, *backups_thread_pool));
|
||||
}
|
||||
|
||||
|
||||
@ -650,6 +688,8 @@ void BackupsWorker::doRestore(
|
||||
backup_open_params.base_backup_info = restore_settings.base_backup_info;
|
||||
backup_open_params.password = restore_settings.password;
|
||||
backup_open_params.allow_s3_native_copy = restore_settings.allow_s3_native_copy;
|
||||
backup_open_params.read_settings = getReadSettingsForRestore(context);
|
||||
backup_open_params.write_settings = getWriteSettingsForRestore(context);
|
||||
BackupPtr backup = BackupFactory::instance().createBackup(backup_open_params);
|
||||
|
||||
String current_database = context->getCurrentDatabase();
|
||||
|
||||
@ -24,6 +24,7 @@ using BackupPtr = std::shared_ptr<const IBackup>;
|
||||
class IBackupEntry;
|
||||
using BackupEntries = std::vector<std::pair<String, std::shared_ptr<const IBackupEntry>>>;
|
||||
using DataRestoreTasks = std::vector<std::function<void()>>;
|
||||
struct ReadSettings;
|
||||
|
||||
/// Manager of backups and restores: executes backups and restores' threads in the background.
|
||||
/// Keeps information about backups and restores started in this session.
|
||||
@ -107,7 +108,7 @@ private:
|
||||
bool called_async);
|
||||
|
||||
/// Builds file infos for specified backup entries.
|
||||
void buildFileInfosForBackupEntries(const BackupPtr & backup, const BackupEntries & backup_entries, std::shared_ptr<IBackupCoordination> backup_coordination);
|
||||
void buildFileInfosForBackupEntries(const BackupPtr & backup, const BackupEntries & backup_entries, const ReadSettings & read_settings, std::shared_ptr<IBackupCoordination> backup_coordination);
|
||||
|
||||
/// Write backup entries to an opened backup.
|
||||
void writeBackupEntries(BackupMutablePtr backup, BackupEntries && backup_entries, const OperationID & backup_id, std::shared_ptr<IBackupCoordination> backup_coordination, bool internal);
|
||||
|
||||
@ -19,8 +19,8 @@ public:
|
||||
|
||||
std::unique_ptr<SeekableReadBuffer> getReadBuffer(const ReadSettings & read_settings) const override { return getInternalBackupEntry()->getReadBuffer(read_settings); }
|
||||
UInt64 getSize() const override { return getInternalBackupEntry()->getSize(); }
|
||||
UInt128 getChecksum() const override { return getInternalBackupEntry()->getChecksum(); }
|
||||
std::optional<UInt128> getPartialChecksum(size_t prefix_length) const override { return getInternalBackupEntry()->getPartialChecksum(prefix_length); }
|
||||
UInt128 getChecksum(const ReadSettings & read_settings) const override { return getInternalBackupEntry()->getChecksum(read_settings); }
|
||||
std::optional<UInt128> getPartialChecksum(size_t prefix_length, const ReadSettings & read_settings) const override { return getInternalBackupEntry()->getPartialChecksum(prefix_length, read_settings); }
|
||||
DataSourceDescription getDataSourceDescription() const override { return getInternalBackupEntry()->getDataSourceDescription(); }
|
||||
bool isEncryptedByDisk() const override { return getInternalBackupEntry()->isEncryptedByDisk(); }
|
||||
bool isFromFile() const override { return getInternalBackupEntry()->isFromFile(); }
|
||||
|
||||
@ -21,11 +21,11 @@ public:
|
||||
virtual UInt64 getSize() const = 0;
|
||||
|
||||
/// Returns the checksum of the data.
|
||||
virtual UInt128 getChecksum() const = 0;
|
||||
virtual UInt128 getChecksum(const ReadSettings & read_settings) const = 0;
|
||||
|
||||
/// Returns a partial checksum, i.e. the checksum calculated for a prefix part of the data.
|
||||
/// Can return nullopt if the partial checksum is too difficult to calculate.
|
||||
virtual std::optional<UInt128> getPartialChecksum(size_t /* prefix_length */) const { return {}; }
|
||||
virtual std::optional<UInt128> getPartialChecksum(size_t /* prefix_length */, const ReadSettings &) const { return {}; }
|
||||
|
||||
/// Returns a read buffer for reading the data.
|
||||
virtual std::unique_ptr<SeekableReadBuffer> getReadBuffer(const ReadSettings & read_settings) const = 0;
|
||||
|
||||
@ -107,12 +107,27 @@ void registerBackupEngineS3(BackupFactory & factory)
|
||||
|
||||
if (params.open_mode == IBackup::OpenMode::READ)
|
||||
{
|
||||
auto reader = std::make_shared<BackupReaderS3>(S3::URI{s3_uri}, access_key_id, secret_access_key, params.allow_s3_native_copy, params.context);
|
||||
auto reader = std::make_shared<BackupReaderS3>(S3::URI{s3_uri},
|
||||
access_key_id,
|
||||
secret_access_key,
|
||||
params.allow_s3_native_copy,
|
||||
params.read_settings,
|
||||
params.write_settings,
|
||||
params.context);
|
||||
|
||||
return std::make_unique<BackupImpl>(backup_name_for_logging, archive_params, params.base_backup_info, reader, params.context);
|
||||
}
|
||||
else
|
||||
{
|
||||
auto writer = std::make_shared<BackupWriterS3>(S3::URI{s3_uri}, access_key_id, secret_access_key, params.allow_s3_native_copy, params.s3_storage_class, params.context);
|
||||
auto writer = std::make_shared<BackupWriterS3>(S3::URI{s3_uri},
|
||||
access_key_id,
|
||||
secret_access_key,
|
||||
params.allow_s3_native_copy,
|
||||
params.s3_storage_class,
|
||||
params.read_settings,
|
||||
params.write_settings,
|
||||
params.context);
|
||||
|
||||
return std::make_unique<BackupImpl>(
|
||||
backup_name_for_logging,
|
||||
archive_params,
|
||||
|
||||
@ -169,18 +169,18 @@ void registerBackupEnginesFileAndDisk(BackupFactory & factory)
|
||||
{
|
||||
std::shared_ptr<IBackupReader> reader;
|
||||
if (engine_name == "File")
|
||||
reader = std::make_shared<BackupReaderFile>(path, params.context);
|
||||
reader = std::make_shared<BackupReaderFile>(path, params.read_settings, params.write_settings);
|
||||
else
|
||||
reader = std::make_shared<BackupReaderDisk>(disk, path, params.context);
|
||||
reader = std::make_shared<BackupReaderDisk>(disk, path, params.read_settings, params.write_settings);
|
||||
return std::make_unique<BackupImpl>(backup_name_for_logging, archive_params, params.base_backup_info, reader, params.context);
|
||||
}
|
||||
else
|
||||
{
|
||||
std::shared_ptr<IBackupWriter> writer;
|
||||
if (engine_name == "File")
|
||||
writer = std::make_shared<BackupWriterFile>(path, params.context);
|
||||
writer = std::make_shared<BackupWriterFile>(path, params.read_settings, params.write_settings);
|
||||
else
|
||||
writer = std::make_shared<BackupWriterDisk>(disk, path, params.context);
|
||||
writer = std::make_shared<BackupWriterDisk>(disk, path, params.read_settings, params.write_settings);
|
||||
return std::make_unique<BackupImpl>(
|
||||
backup_name_for_logging,
|
||||
archive_params,
|
||||
|
||||
@ -69,14 +69,14 @@ protected:
|
||||
|
||||
static String getChecksum(const BackupEntryPtr & backup_entry)
|
||||
{
|
||||
return getHexUIntUppercase(backup_entry->getChecksum());
|
||||
return getHexUIntUppercase(backup_entry->getChecksum({}));
|
||||
}
|
||||
|
||||
static const constexpr std::string_view NO_CHECKSUM = "no checksum";
|
||||
|
||||
static String getPartialChecksum(const BackupEntryPtr & backup_entry, size_t prefix_length)
|
||||
{
|
||||
auto partial_checksum = backup_entry->getPartialChecksum(prefix_length);
|
||||
auto partial_checksum = backup_entry->getPartialChecksum(prefix_length, {});
|
||||
if (!partial_checksum)
|
||||
return String{NO_CHECKSUM};
|
||||
return getHexUIntUppercase(*partial_checksum);
|
||||
@ -218,7 +218,7 @@ TEST_F(BackupEntriesTest, PartialChecksumBeforeFullChecksum)
|
||||
TEST_F(BackupEntriesTest, BackupEntryFromSmallFile)
|
||||
{
|
||||
writeFile(local_disk, "a.txt");
|
||||
auto entry = std::make_shared<BackupEntryFromSmallFile>(local_disk, "a.txt");
|
||||
auto entry = std::make_shared<BackupEntryFromSmallFile>(local_disk, "a.txt", ReadSettings{});
|
||||
|
||||
local_disk->removeFile("a.txt");
|
||||
|
||||
@ -239,7 +239,7 @@ TEST_F(BackupEntriesTest, DecryptedEntriesFromEncryptedDisk)
|
||||
std::pair<BackupEntryPtr, bool /* partial_checksum_allowed */> test_cases[]
|
||||
= {{std::make_shared<BackupEntryFromImmutableFile>(encrypted_disk, "a.txt"), false},
|
||||
{std::make_shared<BackupEntryFromAppendOnlyFile>(encrypted_disk, "a.txt"), true},
|
||||
{std::make_shared<BackupEntryFromSmallFile>(encrypted_disk, "a.txt"), true}};
|
||||
{std::make_shared<BackupEntryFromSmallFile>(encrypted_disk, "a.txt", ReadSettings{}), true}};
|
||||
for (const auto & [entry, partial_checksum_allowed] : test_cases)
|
||||
{
|
||||
EXPECT_EQ(entry->getSize(), 9);
|
||||
@ -258,7 +258,7 @@ TEST_F(BackupEntriesTest, DecryptedEntriesFromEncryptedDisk)
|
||||
BackupEntryPtr entries[]
|
||||
= {std::make_shared<BackupEntryFromImmutableFile>(encrypted_disk, "empty.txt"),
|
||||
std::make_shared<BackupEntryFromAppendOnlyFile>(encrypted_disk, "empty.txt"),
|
||||
std::make_shared<BackupEntryFromSmallFile>(encrypted_disk, "empty.txt")};
|
||||
std::make_shared<BackupEntryFromSmallFile>(encrypted_disk, "empty.txt", ReadSettings{})};
|
||||
for (const auto & entry : entries)
|
||||
{
|
||||
EXPECT_EQ(entry->getSize(), 0);
|
||||
@ -288,7 +288,7 @@ TEST_F(BackupEntriesTest, EncryptedEntriesFromEncryptedDisk)
|
||||
BackupEntryPtr entries[]
|
||||
= {std::make_shared<BackupEntryFromImmutableFile>(encrypted_disk, "a.txt", /* copy_encrypted= */ true),
|
||||
std::make_shared<BackupEntryFromAppendOnlyFile>(encrypted_disk, "a.txt", /* copy_encrypted= */ true),
|
||||
std::make_shared<BackupEntryFromSmallFile>(encrypted_disk, "a.txt", /* copy_encrypted= */ true)};
|
||||
std::make_shared<BackupEntryFromSmallFile>(encrypted_disk, "a.txt", ReadSettings{}, /* copy_encrypted= */ true)};
|
||||
|
||||
auto encrypted_checksum = getChecksum(entries[0]);
|
||||
EXPECT_NE(encrypted_checksum, NO_CHECKSUM);
|
||||
@ -322,7 +322,7 @@ TEST_F(BackupEntriesTest, EncryptedEntriesFromEncryptedDisk)
|
||||
BackupEntryPtr entries[]
|
||||
= {std::make_shared<BackupEntryFromImmutableFile>(encrypted_disk, "empty.txt", /* copy_encrypted= */ true),
|
||||
std::make_shared<BackupEntryFromAppendOnlyFile>(encrypted_disk, "empty.txt", /* copy_encrypted= */ true),
|
||||
std::make_shared<BackupEntryFromSmallFile>(encrypted_disk, "empty.txt", /* copy_encrypted= */ true)};
|
||||
std::make_shared<BackupEntryFromSmallFile>(encrypted_disk, "empty.txt", ReadSettings{}, /* copy_encrypted= */ true)};
|
||||
for (const auto & entry : entries)
|
||||
{
|
||||
EXPECT_EQ(entry->getSize(), 0);
|
||||
|
||||
@ -248,6 +248,7 @@ add_object_library(clickhouse_storages_distributed Storages/Distributed)
|
||||
add_object_library(clickhouse_storages_mergetree Storages/MergeTree)
|
||||
add_object_library(clickhouse_storages_liveview Storages/LiveView)
|
||||
add_object_library(clickhouse_storages_windowview Storages/WindowView)
|
||||
add_object_library(clickhouse_storages_s3queue Storages/S3Queue)
|
||||
add_object_library(clickhouse_client Client)
|
||||
add_object_library(clickhouse_bridge BridgeHelper)
|
||||
add_object_library(clickhouse_server Server)
|
||||
|
||||
@ -564,16 +564,23 @@ void ColumnNullable::updatePermutationImpl(IColumn::PermutationSortDirection dir
|
||||
else
|
||||
getNestedColumn().updatePermutation(direction, stability, limit, null_direction_hint, res, new_ranges);
|
||||
|
||||
equal_ranges = std::move(new_ranges);
|
||||
|
||||
if (unlikely(stability == PermutationSortStability::Stable))
|
||||
{
|
||||
for (auto & null_range : null_ranges)
|
||||
::sort(res.begin() + null_range.first, res.begin() + null_range.second);
|
||||
}
|
||||
|
||||
if (is_nulls_last || null_ranges.empty())
|
||||
{
|
||||
equal_ranges = std::move(new_ranges);
|
||||
std::move(null_ranges.begin(), null_ranges.end(), std::back_inserter(equal_ranges));
|
||||
}
|
||||
else
|
||||
{
|
||||
equal_ranges = std::move(null_ranges);
|
||||
std::move(new_ranges.begin(), new_ranges.end(), std::back_inserter(equal_ranges));
|
||||
}
|
||||
}
|
||||
|
||||
void ColumnNullable::getPermutation(IColumn::PermutationSortDirection direction, IColumn::PermutationSortStability stability,
|
||||
size_t limit, int null_direction_hint, Permutation & res) const
|
||||
|
||||
@ -439,7 +439,7 @@ void ColumnSparse::compareColumn(const IColumn & rhs, size_t rhs_row_num,
|
||||
PaddedPODArray<UInt64> * row_indexes, PaddedPODArray<Int8> & compare_results,
|
||||
int direction, int nan_direction_hint) const
|
||||
{
|
||||
if (row_indexes)
|
||||
if (row_indexes || !typeid_cast<const ColumnSparse *>(&rhs))
|
||||
{
|
||||
/// TODO: implement without conversion to full column.
|
||||
auto this_full = convertToFullColumnIfSparse();
|
||||
|
||||
@ -583,6 +583,7 @@
|
||||
M(698, INVALID_REDIS_STORAGE_TYPE) \
|
||||
M(699, INVALID_REDIS_TABLE_STRUCTURE) \
|
||||
M(700, USER_SESSION_LIMIT_EXCEEDED) \
|
||||
M(701, CLUSTER_DOESNT_EXIST) \
|
||||
\
|
||||
M(999, KEEPER_EXCEPTION) \
|
||||
M(1000, POCO_EXCEPTION) \
|
||||
|
||||
@ -33,6 +33,9 @@ void HTTPHeaderFilter::setValuesFromConfig(const Poco::Util::AbstractConfigurati
|
||||
{
|
||||
std::lock_guard guard(mutex);
|
||||
|
||||
forbidden_headers.clear();
|
||||
forbidden_headers_regexp.clear();
|
||||
|
||||
if (config.has("http_forbid_headers"))
|
||||
{
|
||||
std::vector<std::string> keys;
|
||||
@ -46,11 +49,6 @@ void HTTPHeaderFilter::setValuesFromConfig(const Poco::Util::AbstractConfigurati
|
||||
forbidden_headers.insert(config.getString("http_forbid_headers." + key));
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
forbidden_headers.clear();
|
||||
forbidden_headers_regexp.clear();
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@ -208,10 +208,10 @@ void MemoryTracker::allocImpl(Int64 size, bool throw_if_memory_exceeded, MemoryT
|
||||
* we allow exception about memory limit exceeded to be thrown only on next allocation.
|
||||
* So, we allow over-allocations.
|
||||
*/
|
||||
Int64 will_be = size + amount.fetch_add(size, std::memory_order_relaxed);
|
||||
Int64 will_be = size ? size + amount.fetch_add(size, std::memory_order_relaxed) : amount.load(std::memory_order_relaxed);
|
||||
|
||||
auto metric_loaded = metric.load(std::memory_order_relaxed);
|
||||
if (metric_loaded != CurrentMetrics::end())
|
||||
if (metric_loaded != CurrentMetrics::end() && size)
|
||||
CurrentMetrics::add(metric_loaded, size);
|
||||
|
||||
Int64 current_hard_limit = hard_limit.load(std::memory_order_relaxed);
|
||||
|
||||
@ -8,6 +8,7 @@
|
||||
#include <Parsers/formatAST.h>
|
||||
#include <Parsers/ASTCreateNamedCollectionQuery.h>
|
||||
#include <Parsers/ASTAlterNamedCollectionQuery.h>
|
||||
#include <Parsers/ASTDropNamedCollectionQuery.h>
|
||||
#include <Parsers/ASTSetQuery.h>
|
||||
#include <Parsers/ASTCreateQuery.h>
|
||||
#include <Parsers/parseQuery.h>
|
||||
@ -225,24 +226,15 @@ public:
|
||||
|
||||
void remove(const std::string & collection_name)
|
||||
{
|
||||
if (!removeIfExists(collection_name))
|
||||
auto collection_path = getMetadataPath(collection_name);
|
||||
if (!fs::exists(collection_path))
|
||||
{
|
||||
throw Exception(
|
||||
ErrorCodes::NAMED_COLLECTION_DOESNT_EXIST,
|
||||
"Cannot remove collection `{}`, because it doesn't exist",
|
||||
collection_name);
|
||||
}
|
||||
}
|
||||
|
||||
bool removeIfExists(const std::string & collection_name)
|
||||
{
|
||||
auto collection_path = getMetadataPath(collection_name);
|
||||
if (fs::exists(collection_path))
|
||||
{
|
||||
fs::remove(collection_path);
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
private:
|
||||
@ -393,36 +385,64 @@ void loadIfNot()
|
||||
return loadIfNotUnlocked(lock);
|
||||
}
|
||||
|
||||
void removeFromSQL(const std::string & collection_name, ContextPtr context)
|
||||
void removeFromSQL(const ASTDropNamedCollectionQuery & query, ContextPtr context)
|
||||
{
|
||||
auto lock = lockNamedCollectionsTransaction();
|
||||
loadIfNotUnlocked(lock);
|
||||
LoadFromSQL(context).remove(collection_name);
|
||||
NamedCollectionFactory::instance().remove(collection_name);
|
||||
auto & instance = NamedCollectionFactory::instance();
|
||||
if (!instance.exists(query.collection_name))
|
||||
{
|
||||
if (!query.if_exists)
|
||||
{
|
||||
throw Exception(
|
||||
ErrorCodes::NAMED_COLLECTION_DOESNT_EXIST,
|
||||
"Cannot remove collection `{}`, because it doesn't exist",
|
||||
query.collection_name);
|
||||
}
|
||||
|
||||
void removeIfExistsFromSQL(const std::string & collection_name, ContextPtr context)
|
||||
{
|
||||
auto lock = lockNamedCollectionsTransaction();
|
||||
loadIfNotUnlocked(lock);
|
||||
LoadFromSQL(context).removeIfExists(collection_name);
|
||||
NamedCollectionFactory::instance().removeIfExists(collection_name);
|
||||
return;
|
||||
}
|
||||
LoadFromSQL(context).remove(query.collection_name);
|
||||
instance.remove(query.collection_name);
|
||||
}
|
||||
|
||||
void createFromSQL(const ASTCreateNamedCollectionQuery & query, ContextPtr context)
|
||||
{
|
||||
auto lock = lockNamedCollectionsTransaction();
|
||||
loadIfNotUnlocked(lock);
|
||||
NamedCollectionFactory::instance().add(query.collection_name, LoadFromSQL(context).create(query));
|
||||
auto & instance = NamedCollectionFactory::instance();
|
||||
if (instance.exists(query.collection_name))
|
||||
{
|
||||
if (!query.if_not_exists)
|
||||
{
|
||||
throw Exception(
|
||||
ErrorCodes::NAMED_COLLECTION_ALREADY_EXISTS,
|
||||
"A named collection `{}` already exists",
|
||||
query.collection_name);
|
||||
}
|
||||
return;
|
||||
}
|
||||
instance.add(query.collection_name, LoadFromSQL(context).create(query));
|
||||
}
|
||||
|
||||
void updateFromSQL(const ASTAlterNamedCollectionQuery & query, ContextPtr context)
|
||||
{
|
||||
auto lock = lockNamedCollectionsTransaction();
|
||||
loadIfNotUnlocked(lock);
|
||||
auto & instance = NamedCollectionFactory::instance();
|
||||
if (!instance.exists(query.collection_name))
|
||||
{
|
||||
if (!query.if_exists)
|
||||
{
|
||||
throw Exception(
|
||||
ErrorCodes::NAMED_COLLECTION_DOESNT_EXIST,
|
||||
"Cannot remove collection `{}`, because it doesn't exist",
|
||||
query.collection_name);
|
||||
}
|
||||
return;
|
||||
}
|
||||
LoadFromSQL(context).update(query);
|
||||
|
||||
auto collection = NamedCollectionFactory::instance().getMutable(query.collection_name);
|
||||
auto collection = instance.getMutable(query.collection_name);
|
||||
auto collection_lock = collection->lock();
|
||||
|
||||
for (const auto & [name, value] : query.changes)
|
||||
|
||||
@ -8,6 +8,7 @@ namespace DB
|
||||
|
||||
class ASTCreateNamedCollectionQuery;
|
||||
class ASTAlterNamedCollectionQuery;
|
||||
class ASTDropNamedCollectionQuery;
|
||||
|
||||
namespace NamedCollectionUtils
|
||||
{
|
||||
@ -26,8 +27,7 @@ void reloadFromConfig(const Poco::Util::AbstractConfiguration & config);
|
||||
void loadFromSQL(ContextPtr context);
|
||||
|
||||
/// Remove collection as well as its metadata from `context->getPath() / named_collections /`.
|
||||
void removeFromSQL(const std::string & collection_name, ContextPtr context);
|
||||
void removeIfExistsFromSQL(const std::string & collection_name, ContextPtr context);
|
||||
void removeFromSQL(const ASTDropNamedCollectionQuery & query, ContextPtr context);
|
||||
|
||||
/// Create a new collection from AST and put it to `context->getPath() / named_collections /`.
|
||||
void createFromSQL(const ASTCreateNamedCollectionQuery & query, ContextPtr context);
|
||||
|
||||
@ -45,6 +45,25 @@ size_t shortest_literal_length(const Literals & literals)
|
||||
return shortest;
|
||||
}
|
||||
|
||||
const char * skipNameCapturingGroup(const char * pos, size_t offset, const char * end)
|
||||
{
|
||||
const char special = *(pos + offset) == '<' ? '>' : '\'';
|
||||
offset ++;
|
||||
while (pos + offset < end)
|
||||
{
|
||||
const char cur = *(pos + offset);
|
||||
if (cur == special)
|
||||
{
|
||||
return pos + offset;
|
||||
}
|
||||
if (('0' <= cur && cur <= '9') || ('a' <= cur && cur <= 'z') || ('A' <= cur && cur <= 'Z'))
|
||||
offset ++;
|
||||
else
|
||||
return pos;
|
||||
}
|
||||
return pos;
|
||||
}
|
||||
|
||||
const char * analyzeImpl(
|
||||
std::string_view regexp,
|
||||
const char * pos,
|
||||
@ -247,10 +266,15 @@ const char * analyzeImpl(
|
||||
break;
|
||||
}
|
||||
}
|
||||
/// (?:regex) means non-capturing parentheses group
|
||||
if (pos + 2 < end && pos[1] == '?' && pos[2] == ':')
|
||||
{
|
||||
pos += 2;
|
||||
}
|
||||
if (pos + 3 < end && pos[1] == '?' && (pos[2] == '<' || pos[2] == '\'' || (pos[2] == 'P' && pos[3] == '<')))
|
||||
{
|
||||
pos = skipNameCapturingGroup(pos, pos[2] == 'P' ? 3: 2, end);
|
||||
}
|
||||
Literal group_required_substr;
|
||||
bool group_is_trival = true;
|
||||
Literals group_alters;
|
||||
|
||||
@ -101,6 +101,10 @@ void ProgressIndication::writeFinalProgress()
|
||||
<< formatReadableSizeWithDecimalSuffix(progress.read_bytes * 1000000000.0 / elapsed_ns) << "/s.)";
|
||||
else
|
||||
std::cout << ". ";
|
||||
|
||||
auto peak_memory_usage = getMemoryUsage().peak;
|
||||
if (peak_memory_usage >= 0)
|
||||
std::cout << "\nPeak memory usage: " << formatReadableSizeWithBinarySuffix(peak_memory_usage) << ".";
|
||||
}
|
||||
|
||||
void ProgressIndication::writeProgress(WriteBufferFromFileDescriptor & message)
|
||||
|
||||
@ -70,6 +70,8 @@ ThreadGroup::ThreadGroup()
|
||||
ThreadStatus::ThreadStatus(bool check_current_thread_on_destruction_)
|
||||
: thread_id{getThreadId()}, check_current_thread_on_destruction(check_current_thread_on_destruction_)
|
||||
{
|
||||
chassert(!current_thread);
|
||||
|
||||
last_rusage = std::make_unique<RUsageCounters>();
|
||||
|
||||
memory_tracker.setDescription("(for thread)");
|
||||
@ -123,6 +125,7 @@ ThreadStatus::ThreadStatus(bool check_current_thread_on_destruction_)
|
||||
|
||||
ThreadGroupPtr ThreadStatus::getThreadGroup() const
|
||||
{
|
||||
chassert(current_thread == this);
|
||||
return thread_group;
|
||||
}
|
||||
|
||||
|
||||
@ -47,4 +47,8 @@ TEST(OptimizeRE, analyze)
|
||||
test_f("abc|(:?xx|yy|zz|x?)def", "", {"abc", "def"});
|
||||
test_f("abc|(:?xx|yy|zz|x?){1,2}def", "", {"abc", "def"});
|
||||
test_f(R"(\\A(?:(?:[-0-9_a-z]+(?:\\.[-0-9_a-z]+)*)/k8s1)\\z)", "/k8s1");
|
||||
test_f("[a-zA-Z]+(?P<num>\\d+)", "");
|
||||
test_f("[a-zA-Z]+(?<num>\\d+)", "");
|
||||
test_f("[a-zA-Z]+(?'num'\\d+)", "");
|
||||
test_f("[a-zA-Z]+(?x<num>\\d+)", "x<num>");
|
||||
}
|
||||
|
||||
@ -218,7 +218,7 @@ void KeeperSnapshotManagerS3::uploadSnapshotImpl(const SnapshotFileInfo & snapsh
|
||||
}
|
||||
catch (...)
|
||||
{
|
||||
LOG_INFO(log, "Failed to delete lock file for {} from S3", snapshot_path);
|
||||
LOG_INFO(log, "Failed to delete lock file for {} from S3", snapshot_file_info.path);
|
||||
tryLogCurrentException(__PRETTY_FUNCTION__);
|
||||
}
|
||||
});
|
||||
|
||||
@ -46,15 +46,6 @@
|
||||
|
||||
#define DBMS_MIN_REVISION_WITH_CUSTOM_SERIALIZATION 54454
|
||||
|
||||
/// Version of ClickHouse TCP protocol.
|
||||
///
|
||||
/// Should be incremented manually on protocol changes.
|
||||
///
|
||||
/// NOTE: DBMS_TCP_PROTOCOL_VERSION has nothing common with VERSION_REVISION,
|
||||
/// later is just a number for server version (one number instead of commit SHA)
|
||||
/// for simplicity (sometimes it may be more convenient in some use cases).
|
||||
#define DBMS_TCP_PROTOCOL_VERSION 54464
|
||||
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_INITIAL_QUERY_START_TIME 54449
|
||||
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_PROFILE_EVENTS_IN_INSERT 54456
|
||||
@ -77,3 +68,14 @@
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TOTAL_BYTES_IN_PROGRESS 54463
|
||||
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TIMEZONE_UPDATES 54464
|
||||
|
||||
#define DBMS_MIN_REVISION_WITH_SPARSE_SERIALIZATION 54465
|
||||
|
||||
/// Version of ClickHouse TCP protocol.
|
||||
///
|
||||
/// Should be incremented manually on protocol changes.
|
||||
///
|
||||
/// NOTE: DBMS_TCP_PROTOCOL_VERSION has nothing common with VERSION_REVISION,
|
||||
/// later is just a number for server version (one number instead of commit SHA)
|
||||
/// for simplicity (sometimes it may be more convenient in some use cases).
|
||||
#define DBMS_TCP_PROTOCOL_VERSION 54465
|
||||
|
||||
@ -78,7 +78,7 @@ class IColumn;
|
||||
M(UInt64, s3_min_upload_part_size, 16*1024*1024, "The minimum size of part to upload during multipart upload to S3.", 0) \
|
||||
M(UInt64, s3_max_upload_part_size, 5ull*1024*1024*1024, "The maximum size of part to upload during multipart upload to S3.", 0) \
|
||||
M(UInt64, s3_upload_part_size_multiply_factor, 2, "Multiply s3_min_upload_part_size by this factor each time s3_multiply_parts_count_threshold parts were uploaded from a single write to S3.", 0) \
|
||||
M(UInt64, s3_upload_part_size_multiply_parts_count_threshold, 500, "Each time this number of parts was uploaded to S3 s3_min_upload_part_size multiplied by s3_upload_part_size_multiply_factor.", 0) \
|
||||
M(UInt64, s3_upload_part_size_multiply_parts_count_threshold, 500, "Each time this number of parts was uploaded to S3, s3_min_upload_part_size is multiplied by s3_upload_part_size_multiply_factor.", 0) \
|
||||
M(UInt64, s3_max_inflight_parts_for_one_file, 20, "The maximum number of a concurrent loaded parts in multipart upload request. 0 means unlimited. You ", 0) \
|
||||
M(UInt64, s3_max_single_part_upload_size, 32*1024*1024, "The maximum size of object to upload using singlepart upload to S3.", 0) \
|
||||
M(UInt64, azure_max_single_part_upload_size, 100*1024*1024, "The maximum size of object to upload using singlepart upload to Azure blob storage.", 0) \
|
||||
@ -104,6 +104,7 @@ class IColumn;
|
||||
M(UInt64, s3_retry_attempts, 10, "Setting for Aws::Client::RetryStrategy, Aws::Client does retries itself, 0 means no retries", 0) \
|
||||
M(UInt64, s3_request_timeout_ms, 3000, "Idleness timeout for sending and receiving data to/from S3. Fail if a single TCP read or write call blocks for this long.", 0) \
|
||||
M(Bool, enable_s3_requests_logging, false, "Enable very explicit logging of S3 requests. Makes sense for debug only.", 0) \
|
||||
M(String, s3queue_default_zookeeper_path, "/s3queue/", "Default zookeeper path prefix for S3Queue engine", 0) \
|
||||
M(UInt64, hdfs_replication, 0, "The actual number of replications can be specified when the hdfs file is created.", 0) \
|
||||
M(Bool, hdfs_truncate_on_insert, false, "Enables or disables truncate before insert in s3 engine tables", 0) \
|
||||
M(Bool, hdfs_create_new_file_on_insert, false, "Enables or disables creating a new file on each insert in hdfs engine tables", 0) \
|
||||
@ -626,7 +627,7 @@ class IColumn;
|
||||
M(Bool, engine_file_allow_create_multiple_files, false, "Enables or disables creating a new file on each insert in file engine tables if format has suffix.", 0) \
|
||||
M(Bool, engine_file_skip_empty_files, false, "Allows to skip empty files in file table engine", 0) \
|
||||
M(Bool, engine_url_skip_empty_files, false, "Allows to skip empty files in url table engine", 0) \
|
||||
M(Bool, disable_url_encoding, false, " Allows to disable decoding/encoding path in uri in URL table engine", 0) \
|
||||
M(Bool, enable_url_encoding, true, " Allows to enable/disable decoding/encoding path in uri in URL table engine", 0) \
|
||||
M(Bool, allow_experimental_database_replicated, false, "Allow to create databases with Replicated engine", 0) \
|
||||
M(UInt64, database_replicated_initial_query_timeout_sec, 300, "How long initial DDL query should wait for Replicated database to precess previous DDL queue entries", 0) \
|
||||
M(Bool, database_replicated_enforce_synchronous_settings, false, "Enforces synchronous waiting for some queries (see also database_atomic_wait_for_drop_and_detach_synchronously, mutation_sync, alter_sync). Not recommended to enable these settings.", 0) \
|
||||
@ -837,6 +838,9 @@ class IColumn;
|
||||
MAKE_OBSOLETE(M, Seconds, drain_timeout, 3) \
|
||||
MAKE_OBSOLETE(M, UInt64, backup_threads, 16) \
|
||||
MAKE_OBSOLETE(M, UInt64, restore_threads, 16) \
|
||||
MAKE_OBSOLETE(M, Bool, input_format_arrow_import_nested, false) \
|
||||
MAKE_OBSOLETE(M, Bool, input_format_parquet_import_nested, false) \
|
||||
MAKE_OBSOLETE(M, Bool, input_format_orc_import_nested, false) \
|
||||
MAKE_OBSOLETE(M, Bool, optimize_duplicate_order_by_and_distinct, false) \
|
||||
|
||||
/** The section above is for obsolete settings. Do not add anything there. */
|
||||
@ -858,12 +862,9 @@ class IColumn;
|
||||
M(Bool, input_format_tsv_empty_as_default, false, "Treat empty fields in TSV input as default values.", 0) \
|
||||
M(Bool, input_format_tsv_enum_as_number, false, "Treat inserted enum values in TSV formats as enum indices.", 0) \
|
||||
M(Bool, input_format_null_as_default, true, "Initialize null fields with default values if the data type of this field is not nullable and it is supported by the input format", 0) \
|
||||
M(Bool, input_format_arrow_import_nested, false, "Allow to insert array of structs into Nested table in Arrow input format.", 0) \
|
||||
M(Bool, input_format_arrow_case_insensitive_column_matching, false, "Ignore case when matching Arrow columns with CH columns.", 0) \
|
||||
M(Bool, input_format_orc_import_nested, false, "Allow to insert array of structs into Nested table in ORC input format.", 0) \
|
||||
M(Int64, input_format_orc_row_batch_size, 100'000, "Batch size when reading ORC stripes.", 0) \
|
||||
M(Bool, input_format_orc_case_insensitive_column_matching, false, "Ignore case when matching ORC columns with CH columns.", 0) \
|
||||
M(Bool, input_format_parquet_import_nested, false, "Allow to insert array of structs into Nested table in Parquet input format.", 0) \
|
||||
M(Bool, input_format_parquet_case_insensitive_column_matching, false, "Ignore case when matching Parquet columns with CH columns.", 0) \
|
||||
M(Bool, input_format_parquet_preserve_order, false, "Avoid reordering rows when reading from Parquet files. Usually makes it much slower.", 0) \
|
||||
M(Bool, input_format_allow_seeks, true, "Allow seeks while reading in ORC/Parquet/Arrow input formats", 0) \
|
||||
@ -1011,6 +1012,10 @@ class IColumn;
|
||||
\
|
||||
M(CapnProtoEnumComparingMode, format_capn_proto_enum_comparising_mode, FormatSettings::CapnProtoEnumComparingMode::BY_VALUES, "How to map ClickHouse Enum and CapnProto Enum", 0) \
|
||||
\
|
||||
M(Bool, format_capn_proto_use_autogenerated_schema, true, "Use autogenerated CapnProto schema when format_schema is not set", 0) \
|
||||
M(Bool, format_protobuf_use_autogenerated_schema, true, "Use autogenerated Protobuf when format_schema is not set", 0) \
|
||||
M(String, output_format_schema, "", "The path to the file where the automatically generated schema will be saved", 0) \
|
||||
\
|
||||
M(String, input_format_mysql_dump_table_name, "", "Name of the table in MySQL dump from which to read data", 0) \
|
||||
M(Bool, input_format_mysql_dump_map_column_names, true, "Match columns from table in MySQL dump and columns from ClickHouse table by names", 0) \
|
||||
\
|
||||
@ -1028,6 +1033,7 @@ class IColumn;
|
||||
\
|
||||
M(Bool, dictionary_use_async_executor, false, "Execute a pipeline for reading from a dictionary with several threads. It's supported only by DIRECT dictionary with CLICKHOUSE source.", 0) \
|
||||
M(Bool, input_format_csv_allow_variable_number_of_columns, false, "Ignore extra columns in CSV input (if file has more columns than expected) and treat missing fields in CSV input as default values", 0) \
|
||||
M(Bool, precise_float_parsing, false, "Prefer more precise (but slower) float parsing algorithm", 0) \
|
||||
|
||||
// End of FORMAT_FACTORY_SETTINGS
|
||||
// Please add settings non-related to formats into the COMMON_SETTINGS above.
|
||||
|
||||
@ -175,4 +175,11 @@ IMPLEMENT_SETTING_ENUM(ORCCompression, ErrorCodes::BAD_ARGUMENTS,
|
||||
{"zlib", FormatSettings::ORCCompression::ZLIB},
|
||||
{"lz4", FormatSettings::ORCCompression::LZ4}})
|
||||
|
||||
IMPLEMENT_SETTING_ENUM(S3QueueMode, ErrorCodes::BAD_ARGUMENTS,
|
||||
{{"ordered", S3QueueMode::ORDERED},
|
||||
{"unordered", S3QueueMode::UNORDERED}})
|
||||
|
||||
IMPLEMENT_SETTING_ENUM(S3QueueAction, ErrorCodes::BAD_ARGUMENTS,
|
||||
{{"keep", S3QueueAction::KEEP},
|
||||
{"delete", S3QueueAction::DELETE}})
|
||||
}
|
||||
|
||||
@ -221,4 +221,21 @@ enum class ParallelReplicasCustomKeyFilterType : uint8_t
|
||||
DECLARE_SETTING_ENUM(ParallelReplicasCustomKeyFilterType)
|
||||
|
||||
DECLARE_SETTING_ENUM(LocalFSReadMethod)
|
||||
|
||||
enum class S3QueueMode
|
||||
{
|
||||
ORDERED,
|
||||
UNORDERED,
|
||||
};
|
||||
|
||||
DECLARE_SETTING_ENUM(S3QueueMode)
|
||||
|
||||
enum class S3QueueAction
|
||||
{
|
||||
KEEP,
|
||||
DELETE,
|
||||
};
|
||||
|
||||
DECLARE_SETTING_ENUM(S3QueueAction)
|
||||
|
||||
}
|
||||
|
||||
@ -107,9 +107,6 @@ DatabasePtr DatabaseFactory::get(const ASTCreateQuery & create, const String & m
|
||||
{
|
||||
cckMetadataPathForOrdinary(create, metadata_path);
|
||||
|
||||
/// Creates store/xxx/ for Atomic
|
||||
fs::create_directories(fs::path(metadata_path).parent_path());
|
||||
|
||||
DatabasePtr impl = getImpl(create, metadata_path, context);
|
||||
|
||||
if (impl && context->hasQueryContext() && context->getSettingsRef().log_queries)
|
||||
|
||||
@ -670,7 +670,7 @@ void DatabaseReplicated::checkQueryValid(const ASTPtr & query, ContextPtr query_
|
||||
{
|
||||
for (const auto & command : query_alter->command_list->children)
|
||||
{
|
||||
if (!isSupportedAlterType(command->as<ASTAlterCommand&>().type))
|
||||
if (!isSupportedAlterTypeForOnClusterDDLQuery(command->as<ASTAlterCommand&>().type))
|
||||
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Unsupported type of ALTER query");
|
||||
}
|
||||
}
|
||||
@ -1478,7 +1478,7 @@ bool DatabaseReplicated::shouldReplicateQuery(const ContextPtr & query_context,
|
||||
/// Some ALTERs are not replicated on database level
|
||||
if (const auto * alter = query_ptr->as<const ASTAlterQuery>())
|
||||
{
|
||||
if (alter->isAttachAlter() || alter->isFetchAlter() || alter->isDropPartitionAlter() || is_keeper_map_table(query_ptr))
|
||||
if (alter->isAttachAlter() || alter->isFetchAlter() || alter->isDropPartitionAlter() || is_keeper_map_table(query_ptr) || alter->isFreezeAlter())
|
||||
return false;
|
||||
|
||||
if (has_many_shards() || !is_replicated_table(query_ptr))
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user