mirror of
https://github.com/ClickHouse/ClickHouse.git
synced 2024-11-26 17:41:59 +00:00
Merge branch 'master' into azure_table_function_cluster
This commit is contained in:
commit
68a10e7cae
@ -35,7 +35,7 @@ The [system.clusters](../../operations/system-tables/clusters.md) system table c
|
|||||||
|
|
||||||
When creating a new replica of the database, this replica creates tables by itself. If the replica has been unavailable for a long time and has lagged behind the replication log — it checks its local metadata with the current metadata in ZooKeeper, moves the extra tables with data to a separate non-replicated database (so as not to accidentally delete anything superfluous), creates the missing tables, updates the table names if they have been renamed. The data is replicated at the `ReplicatedMergeTree` level, i.e. if the table is not replicated, the data will not be replicated (the database is responsible only for metadata).
|
When creating a new replica of the database, this replica creates tables by itself. If the replica has been unavailable for a long time and has lagged behind the replication log — it checks its local metadata with the current metadata in ZooKeeper, moves the extra tables with data to a separate non-replicated database (so as not to accidentally delete anything superfluous), creates the missing tables, updates the table names if they have been renamed. The data is replicated at the `ReplicatedMergeTree` level, i.e. if the table is not replicated, the data will not be replicated (the database is responsible only for metadata).
|
||||||
|
|
||||||
[`ALTER TABLE ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
[`ALTER TABLE FREEZE|ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
||||||
|
|
||||||
## Usage Example {#usage-example}
|
## Usage Example {#usage-example}
|
||||||
|
|
||||||
|
|||||||
@ -193,6 +193,19 @@ index creation, `L2Distance` is used as default. Parameter `NumTrees` is the num
|
|||||||
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
||||||
linearly) as well as larger index sizes.
|
linearly) as well as larger index sizes.
|
||||||
|
|
||||||
|
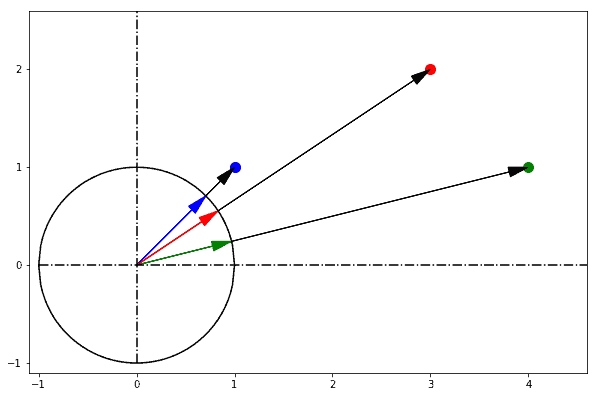
`L2Distance` is also called Euclidean distance, the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points.
|
||||||
|
For example: If we have point P(p1,p2), Q(q1,q2), their distance will be d(p,q)
|
||||||
|

|
||||||
|
|
||||||
|
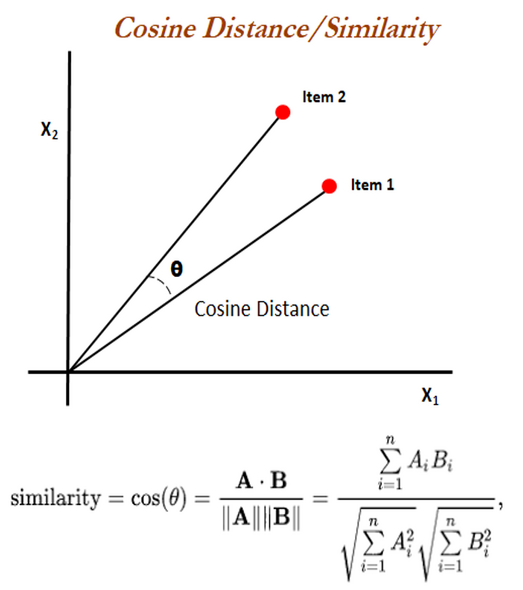
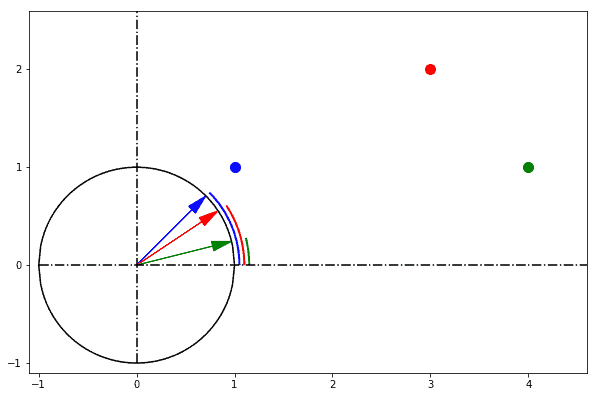
`cosineDistance` also called cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths.
|
||||||
|
|
||||||
|
|
||||||
|
The Euclidean distance corresponds to the L2-norm of a difference between vectors. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
|
||||||
|

|
||||||
|
In one sentence: cosine similarity care only about the angle between them, but do not care about the "distance" we normally think.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
:::note
|
:::note
|
||||||
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
||||||
[CONSTRAINT](/docs/en/sql-reference/statements/create/table.md#constraints) to avoid errors. For example, `CONSTRAINT constraint_name_1
|
[CONSTRAINT](/docs/en/sql-reference/statements/create/table.md#constraints) to avoid errors. For example, `CONSTRAINT constraint_name_1
|
||||||
|
|||||||
@ -0,0 +1 @@
|
|||||||
|
../../../en/operations/optimizing-performance/profile-guided-optimization.md
|
||||||
@ -0,0 +1 @@
|
|||||||
|
../../../en/operations/optimizing-performance/profile-guided-optimization.md
|
||||||
@ -208,10 +208,10 @@ void MemoryTracker::allocImpl(Int64 size, bool throw_if_memory_exceeded, MemoryT
|
|||||||
* we allow exception about memory limit exceeded to be thrown only on next allocation.
|
* we allow exception about memory limit exceeded to be thrown only on next allocation.
|
||||||
* So, we allow over-allocations.
|
* So, we allow over-allocations.
|
||||||
*/
|
*/
|
||||||
Int64 will_be = size + amount.fetch_add(size, std::memory_order_relaxed);
|
Int64 will_be = size ? size + amount.fetch_add(size, std::memory_order_relaxed) : amount.load(std::memory_order_relaxed);
|
||||||
|
|
||||||
auto metric_loaded = metric.load(std::memory_order_relaxed);
|
auto metric_loaded = metric.load(std::memory_order_relaxed);
|
||||||
if (metric_loaded != CurrentMetrics::end())
|
if (metric_loaded != CurrentMetrics::end() && size)
|
||||||
CurrentMetrics::add(metric_loaded, size);
|
CurrentMetrics::add(metric_loaded, size);
|
||||||
|
|
||||||
Int64 current_hard_limit = hard_limit.load(std::memory_order_relaxed);
|
Int64 current_hard_limit = hard_limit.load(std::memory_order_relaxed);
|
||||||
|
|||||||
@ -46,15 +46,6 @@
|
|||||||
|
|
||||||
#define DBMS_MIN_REVISION_WITH_CUSTOM_SERIALIZATION 54454
|
#define DBMS_MIN_REVISION_WITH_CUSTOM_SERIALIZATION 54454
|
||||||
|
|
||||||
/// Version of ClickHouse TCP protocol.
|
|
||||||
///
|
|
||||||
/// Should be incremented manually on protocol changes.
|
|
||||||
///
|
|
||||||
/// NOTE: DBMS_TCP_PROTOCOL_VERSION has nothing common with VERSION_REVISION,
|
|
||||||
/// later is just a number for server version (one number instead of commit SHA)
|
|
||||||
/// for simplicity (sometimes it may be more convenient in some use cases).
|
|
||||||
#define DBMS_TCP_PROTOCOL_VERSION 54464
|
|
||||||
|
|
||||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_INITIAL_QUERY_START_TIME 54449
|
#define DBMS_MIN_PROTOCOL_VERSION_WITH_INITIAL_QUERY_START_TIME 54449
|
||||||
|
|
||||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_PROFILE_EVENTS_IN_INSERT 54456
|
#define DBMS_MIN_PROTOCOL_VERSION_WITH_PROFILE_EVENTS_IN_INSERT 54456
|
||||||
@ -77,3 +68,14 @@
|
|||||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TOTAL_BYTES_IN_PROGRESS 54463
|
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TOTAL_BYTES_IN_PROGRESS 54463
|
||||||
|
|
||||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TIMEZONE_UPDATES 54464
|
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TIMEZONE_UPDATES 54464
|
||||||
|
|
||||||
|
#define DBMS_MIN_REVISION_WITH_SPARSE_SERIALIZATION 54465
|
||||||
|
|
||||||
|
/// Version of ClickHouse TCP protocol.
|
||||||
|
///
|
||||||
|
/// Should be incremented manually on protocol changes.
|
||||||
|
///
|
||||||
|
/// NOTE: DBMS_TCP_PROTOCOL_VERSION has nothing common with VERSION_REVISION,
|
||||||
|
/// later is just a number for server version (one number instead of commit SHA)
|
||||||
|
/// for simplicity (sometimes it may be more convenient in some use cases).
|
||||||
|
#define DBMS_TCP_PROTOCOL_VERSION 54465
|
||||||
|
|||||||
@ -666,7 +666,7 @@ void DatabaseReplicated::checkQueryValid(const ASTPtr & query, ContextPtr query_
|
|||||||
{
|
{
|
||||||
for (const auto & command : query_alter->command_list->children)
|
for (const auto & command : query_alter->command_list->children)
|
||||||
{
|
{
|
||||||
if (!isSupportedAlterType(command->as<ASTAlterCommand&>().type))
|
if (!isSupportedAlterTypeForOnClusterDDLQuery(command->as<ASTAlterCommand&>().type))
|
||||||
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Unsupported type of ALTER query");
|
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Unsupported type of ALTER query");
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@ -1474,7 +1474,7 @@ bool DatabaseReplicated::shouldReplicateQuery(const ContextPtr & query_context,
|
|||||||
/// Some ALTERs are not replicated on database level
|
/// Some ALTERs are not replicated on database level
|
||||||
if (const auto * alter = query_ptr->as<const ASTAlterQuery>())
|
if (const auto * alter = query_ptr->as<const ASTAlterQuery>())
|
||||||
{
|
{
|
||||||
if (alter->isAttachAlter() || alter->isFetchAlter() || alter->isDropPartitionAlter() || is_keeper_map_table(query_ptr))
|
if (alter->isAttachAlter() || alter->isFetchAlter() || alter->isDropPartitionAlter() || is_keeper_map_table(query_ptr) || alter->isFreezeAlter())
|
||||||
return false;
|
return false;
|
||||||
|
|
||||||
if (has_many_shards() || !is_replicated_table(query_ptr))
|
if (has_many_shards() || !is_replicated_table(query_ptr))
|
||||||
|
|||||||
@ -74,19 +74,22 @@ CachedOnDiskReadBufferFromFile::CachedOnDiskReadBufferFromFile(
|
|||||||
}
|
}
|
||||||
|
|
||||||
void CachedOnDiskReadBufferFromFile::appendFilesystemCacheLog(
|
void CachedOnDiskReadBufferFromFile::appendFilesystemCacheLog(
|
||||||
const FileSegment::Range & file_segment_range, CachedOnDiskReadBufferFromFile::ReadType type)
|
const FileSegment & file_segment, CachedOnDiskReadBufferFromFile::ReadType type)
|
||||||
{
|
{
|
||||||
if (!cache_log)
|
if (!cache_log)
|
||||||
return;
|
return;
|
||||||
|
|
||||||
|
const auto range = file_segment.range();
|
||||||
FilesystemCacheLogElement elem
|
FilesystemCacheLogElement elem
|
||||||
{
|
{
|
||||||
.event_time = std::chrono::system_clock::to_time_t(std::chrono::system_clock::now()),
|
.event_time = std::chrono::system_clock::to_time_t(std::chrono::system_clock::now()),
|
||||||
.query_id = query_id,
|
.query_id = query_id,
|
||||||
.source_file_path = source_file_path,
|
.source_file_path = source_file_path,
|
||||||
.file_segment_range = { file_segment_range.left, file_segment_range.right },
|
.file_segment_range = { range.left, range.right },
|
||||||
.requested_range = { first_offset, read_until_position },
|
.requested_range = { first_offset, read_until_position },
|
||||||
.file_segment_size = file_segment_range.size(),
|
.file_segment_key = file_segment.key().toString(),
|
||||||
|
.file_segment_offset = file_segment.offset(),
|
||||||
|
.file_segment_size = range.size(),
|
||||||
.read_from_cache_attempted = true,
|
.read_from_cache_attempted = true,
|
||||||
.read_buffer_id = current_buffer_id,
|
.read_buffer_id = current_buffer_id,
|
||||||
.profile_counters = std::make_shared<ProfileEvents::Counters::Snapshot>(
|
.profile_counters = std::make_shared<ProfileEvents::Counters::Snapshot>(
|
||||||
@ -495,7 +498,7 @@ bool CachedOnDiskReadBufferFromFile::completeFileSegmentAndGetNext()
|
|||||||
auto completed_range = current_file_segment->range();
|
auto completed_range = current_file_segment->range();
|
||||||
|
|
||||||
if (cache_log)
|
if (cache_log)
|
||||||
appendFilesystemCacheLog(completed_range, read_type);
|
appendFilesystemCacheLog(*current_file_segment, read_type);
|
||||||
|
|
||||||
chassert(file_offset_of_buffer_end > completed_range.right);
|
chassert(file_offset_of_buffer_end > completed_range.right);
|
||||||
|
|
||||||
@ -518,7 +521,7 @@ CachedOnDiskReadBufferFromFile::~CachedOnDiskReadBufferFromFile()
|
|||||||
{
|
{
|
||||||
if (cache_log && file_segments && !file_segments->empty())
|
if (cache_log && file_segments && !file_segments->empty())
|
||||||
{
|
{
|
||||||
appendFilesystemCacheLog(file_segments->front().range(), read_type);
|
appendFilesystemCacheLog(file_segments->front(), read_type);
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@ -90,7 +90,7 @@ private:
|
|||||||
|
|
||||||
bool completeFileSegmentAndGetNext();
|
bool completeFileSegmentAndGetNext();
|
||||||
|
|
||||||
void appendFilesystemCacheLog(const FileSegment::Range & file_segment_range, ReadType read_type);
|
void appendFilesystemCacheLog(const FileSegment & file_segment, ReadType read_type);
|
||||||
|
|
||||||
bool writeCache(char * data, size_t size, size_t offset, FileSegment & file_segment);
|
bool writeCache(char * data, size_t size, size_t offset, FileSegment & file_segment);
|
||||||
|
|
||||||
|
|||||||
@ -109,6 +109,8 @@ void ReadBufferFromRemoteFSGather::appendUncachedReadInfo()
|
|||||||
.source_file_path = current_object.remote_path,
|
.source_file_path = current_object.remote_path,
|
||||||
.file_segment_range = { 0, current_object.bytes_size },
|
.file_segment_range = { 0, current_object.bytes_size },
|
||||||
.cache_type = FilesystemCacheLogElement::CacheType::READ_FROM_FS_BYPASSING_CACHE,
|
.cache_type = FilesystemCacheLogElement::CacheType::READ_FROM_FS_BYPASSING_CACHE,
|
||||||
|
.file_segment_key = {},
|
||||||
|
.file_segment_offset = {},
|
||||||
.file_segment_size = current_object.bytes_size,
|
.file_segment_size = current_object.bytes_size,
|
||||||
.read_from_cache_attempted = false,
|
.read_from_cache_attempted = false,
|
||||||
};
|
};
|
||||||
|
|||||||
@ -135,9 +135,19 @@ size_t NativeWriter::write(const Block & block)
|
|||||||
if (client_revision >= DBMS_MIN_REVISION_WITH_CUSTOM_SERIALIZATION)
|
if (client_revision >= DBMS_MIN_REVISION_WITH_CUSTOM_SERIALIZATION)
|
||||||
{
|
{
|
||||||
auto info = column.type->getSerializationInfo(*column.column);
|
auto info = column.type->getSerializationInfo(*column.column);
|
||||||
serialization = column.type->getSerialization(*info);
|
bool has_custom = false;
|
||||||
|
|
||||||
|
if (client_revision >= DBMS_MIN_REVISION_WITH_SPARSE_SERIALIZATION)
|
||||||
|
{
|
||||||
|
serialization = column.type->getSerialization(*info);
|
||||||
|
has_custom = info->hasCustomSerialization();
|
||||||
|
}
|
||||||
|
else
|
||||||
|
{
|
||||||
|
serialization = column.type->getDefaultSerialization();
|
||||||
|
column.column = recursiveRemoveSparse(column.column);
|
||||||
|
}
|
||||||
|
|
||||||
bool has_custom = info->hasCustomSerialization();
|
|
||||||
writeBinary(static_cast<UInt8>(has_custom), ostr);
|
writeBinary(static_cast<UInt8>(has_custom), ostr);
|
||||||
if (has_custom)
|
if (has_custom)
|
||||||
info->serialializeKindBinary(ostr);
|
info->serialializeKindBinary(ostr);
|
||||||
|
|||||||
@ -984,6 +984,8 @@ void Aggregator::executeOnBlockSmall(
|
|||||||
}
|
}
|
||||||
|
|
||||||
executeImpl(result, row_begin, row_end, key_columns, aggregate_instructions);
|
executeImpl(result, row_begin, row_end, key_columns, aggregate_instructions);
|
||||||
|
|
||||||
|
CurrentMemoryTracker::check();
|
||||||
}
|
}
|
||||||
|
|
||||||
void Aggregator::mergeOnBlockSmall(
|
void Aggregator::mergeOnBlockSmall(
|
||||||
@ -1023,6 +1025,8 @@ void Aggregator::mergeOnBlockSmall(
|
|||||||
#undef M
|
#undef M
|
||||||
else
|
else
|
||||||
throw Exception(ErrorCodes::UNKNOWN_AGGREGATED_DATA_VARIANT, "Unknown aggregated data variant.");
|
throw Exception(ErrorCodes::UNKNOWN_AGGREGATED_DATA_VARIANT, "Unknown aggregated data variant.");
|
||||||
|
|
||||||
|
CurrentMemoryTracker::check();
|
||||||
}
|
}
|
||||||
|
|
||||||
void Aggregator::executeImpl(
|
void Aggregator::executeImpl(
|
||||||
@ -1383,11 +1387,8 @@ void NO_INLINE Aggregator::executeWithoutKeyImpl(
|
|||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
void NO_INLINE Aggregator::executeOnIntervalWithoutKeyImpl(
|
void NO_INLINE Aggregator::executeOnIntervalWithoutKey(
|
||||||
AggregatedDataVariants & data_variants,
|
AggregatedDataVariants & data_variants, size_t row_begin, size_t row_end, AggregateFunctionInstruction * aggregate_instructions) const
|
||||||
size_t row_begin,
|
|
||||||
size_t row_end,
|
|
||||||
AggregateFunctionInstruction * aggregate_instructions) const
|
|
||||||
{
|
{
|
||||||
/// `data_variants` will destroy the states of aggregate functions in the destructor
|
/// `data_variants` will destroy the states of aggregate functions in the destructor
|
||||||
data_variants.aggregator = this;
|
data_variants.aggregator = this;
|
||||||
@ -1414,7 +1415,7 @@ void NO_INLINE Aggregator::executeOnIntervalWithoutKeyImpl(
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
void NO_INLINE Aggregator::mergeOnIntervalWithoutKeyImpl(
|
void NO_INLINE Aggregator::mergeOnIntervalWithoutKey(
|
||||||
AggregatedDataVariants & data_variants,
|
AggregatedDataVariants & data_variants,
|
||||||
size_t row_begin,
|
size_t row_begin,
|
||||||
size_t row_end,
|
size_t row_end,
|
||||||
@ -2921,6 +2922,7 @@ void NO_INLINE Aggregator::mergeBlockWithoutKeyStreamsImpl(
|
|||||||
AggregateColumnsConstData aggregate_columns = params.makeAggregateColumnsData(block);
|
AggregateColumnsConstData aggregate_columns = params.makeAggregateColumnsData(block);
|
||||||
mergeWithoutKeyStreamsImpl(result, 0, block.rows(), aggregate_columns);
|
mergeWithoutKeyStreamsImpl(result, 0, block.rows(), aggregate_columns);
|
||||||
}
|
}
|
||||||
|
|
||||||
void NO_INLINE Aggregator::mergeWithoutKeyStreamsImpl(
|
void NO_INLINE Aggregator::mergeWithoutKeyStreamsImpl(
|
||||||
AggregatedDataVariants & result,
|
AggregatedDataVariants & result,
|
||||||
size_t row_begin,
|
size_t row_begin,
|
||||||
@ -3139,6 +3141,8 @@ void Aggregator::mergeBlocks(BucketToBlocks bucket_to_blocks, AggregatedDataVari
|
|||||||
|
|
||||||
LOG_TRACE(log, "Merged partially aggregated single-level data.");
|
LOG_TRACE(log, "Merged partially aggregated single-level data.");
|
||||||
}
|
}
|
||||||
|
|
||||||
|
CurrentMemoryTracker::check();
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -1118,9 +1118,55 @@ public:
|
|||||||
AggregateColumns & aggregate_columns, /// Passed to not create them anew for each block
|
AggregateColumns & aggregate_columns, /// Passed to not create them anew for each block
|
||||||
bool & no_more_keys) const;
|
bool & no_more_keys) const;
|
||||||
|
|
||||||
|
/** This array serves two purposes.
|
||||||
|
*
|
||||||
|
* Function arguments are collected side by side, and they do not need to be collected from different places. Also the array is made zero-terminated.
|
||||||
|
* The inner loop (for the case without_key) is almost twice as compact; performance gain of about 30%.
|
||||||
|
*/
|
||||||
|
struct AggregateFunctionInstruction
|
||||||
|
{
|
||||||
|
const IAggregateFunction * that{};
|
||||||
|
size_t state_offset{};
|
||||||
|
const IColumn ** arguments{};
|
||||||
|
const IAggregateFunction * batch_that{};
|
||||||
|
const IColumn ** batch_arguments{};
|
||||||
|
const UInt64 * offsets{};
|
||||||
|
bool has_sparse_arguments = false;
|
||||||
|
};
|
||||||
|
|
||||||
|
/// Used for optimize_aggregation_in_order:
|
||||||
|
/// - No two-level aggregation
|
||||||
|
/// - No external aggregation
|
||||||
|
/// - No without_key support (it is implemented using executeOnIntervalWithoutKey())
|
||||||
|
void executeOnBlockSmall(
|
||||||
|
AggregatedDataVariants & result,
|
||||||
|
size_t row_begin,
|
||||||
|
size_t row_end,
|
||||||
|
ColumnRawPtrs & key_columns,
|
||||||
|
AggregateFunctionInstruction * aggregate_instructions) const;
|
||||||
|
|
||||||
|
void executeOnIntervalWithoutKey(
|
||||||
|
AggregatedDataVariants & data_variants,
|
||||||
|
size_t row_begin,
|
||||||
|
size_t row_end,
|
||||||
|
AggregateFunctionInstruction * aggregate_instructions) const;
|
||||||
|
|
||||||
/// Used for aggregate projection.
|
/// Used for aggregate projection.
|
||||||
bool mergeOnBlock(Block block, AggregatedDataVariants & result, bool & no_more_keys) const;
|
bool mergeOnBlock(Block block, AggregatedDataVariants & result, bool & no_more_keys) const;
|
||||||
|
|
||||||
|
void mergeOnBlockSmall(
|
||||||
|
AggregatedDataVariants & result,
|
||||||
|
size_t row_begin,
|
||||||
|
size_t row_end,
|
||||||
|
const AggregateColumnsConstData & aggregate_columns_data,
|
||||||
|
const ColumnRawPtrs & key_columns) const;
|
||||||
|
|
||||||
|
void mergeOnIntervalWithoutKey(
|
||||||
|
AggregatedDataVariants & data_variants,
|
||||||
|
size_t row_begin,
|
||||||
|
size_t row_end,
|
||||||
|
const AggregateColumnsConstData & aggregate_columns_data) const;
|
||||||
|
|
||||||
/** Convert the aggregation data structure into a block.
|
/** Convert the aggregation data structure into a block.
|
||||||
* If overflow_row = true, then aggregates for rows that are not included in max_rows_to_group_by are put in the first block.
|
* If overflow_row = true, then aggregates for rows that are not included in max_rows_to_group_by are put in the first block.
|
||||||
*
|
*
|
||||||
@ -1178,22 +1224,6 @@ private:
|
|||||||
|
|
||||||
AggregateFunctionsPlainPtrs aggregate_functions;
|
AggregateFunctionsPlainPtrs aggregate_functions;
|
||||||
|
|
||||||
/** This array serves two purposes.
|
|
||||||
*
|
|
||||||
* Function arguments are collected side by side, and they do not need to be collected from different places. Also the array is made zero-terminated.
|
|
||||||
* The inner loop (for the case without_key) is almost twice as compact; performance gain of about 30%.
|
|
||||||
*/
|
|
||||||
struct AggregateFunctionInstruction
|
|
||||||
{
|
|
||||||
const IAggregateFunction * that{};
|
|
||||||
size_t state_offset{};
|
|
||||||
const IColumn ** arguments{};
|
|
||||||
const IAggregateFunction * batch_that{};
|
|
||||||
const IColumn ** batch_arguments{};
|
|
||||||
const UInt64 * offsets{};
|
|
||||||
bool has_sparse_arguments = false;
|
|
||||||
};
|
|
||||||
|
|
||||||
using AggregateFunctionInstructions = std::vector<AggregateFunctionInstruction>;
|
using AggregateFunctionInstructions = std::vector<AggregateFunctionInstruction>;
|
||||||
using NestedColumnsHolder = std::vector<std::vector<const IColumn *>>;
|
using NestedColumnsHolder = std::vector<std::vector<const IColumn *>>;
|
||||||
|
|
||||||
@ -1239,26 +1269,6 @@ private:
|
|||||||
*/
|
*/
|
||||||
void destroyAllAggregateStates(AggregatedDataVariants & result) const;
|
void destroyAllAggregateStates(AggregatedDataVariants & result) const;
|
||||||
|
|
||||||
|
|
||||||
/// Used for optimize_aggregation_in_order:
|
|
||||||
/// - No two-level aggregation
|
|
||||||
/// - No external aggregation
|
|
||||||
/// - No without_key support (it is implemented using executeOnIntervalWithoutKeyImpl())
|
|
||||||
void executeOnBlockSmall(
|
|
||||||
AggregatedDataVariants & result,
|
|
||||||
size_t row_begin,
|
|
||||||
size_t row_end,
|
|
||||||
ColumnRawPtrs & key_columns,
|
|
||||||
AggregateFunctionInstruction * aggregate_instructions) const;
|
|
||||||
void mergeOnBlockSmall(
|
|
||||||
AggregatedDataVariants & result,
|
|
||||||
size_t row_begin,
|
|
||||||
size_t row_end,
|
|
||||||
const AggregateColumnsConstData & aggregate_columns_data,
|
|
||||||
const ColumnRawPtrs & key_columns) const;
|
|
||||||
|
|
||||||
void mergeOnBlockImpl(Block block, AggregatedDataVariants & result, bool no_more_keys) const;
|
|
||||||
|
|
||||||
void executeImpl(
|
void executeImpl(
|
||||||
AggregatedDataVariants & result,
|
AggregatedDataVariants & result,
|
||||||
size_t row_begin,
|
size_t row_begin,
|
||||||
@ -1300,17 +1310,6 @@ private:
|
|||||||
AggregateFunctionInstruction * aggregate_instructions,
|
AggregateFunctionInstruction * aggregate_instructions,
|
||||||
Arena * arena) const;
|
Arena * arena) const;
|
||||||
|
|
||||||
void executeOnIntervalWithoutKeyImpl(
|
|
||||||
AggregatedDataVariants & data_variants,
|
|
||||||
size_t row_begin,
|
|
||||||
size_t row_end,
|
|
||||||
AggregateFunctionInstruction * aggregate_instructions) const;
|
|
||||||
void mergeOnIntervalWithoutKeyImpl(
|
|
||||||
AggregatedDataVariants & data_variants,
|
|
||||||
size_t row_begin,
|
|
||||||
size_t row_end,
|
|
||||||
const AggregateColumnsConstData & aggregate_columns_data) const;
|
|
||||||
|
|
||||||
template <typename Method>
|
template <typename Method>
|
||||||
void writeToTemporaryFileImpl(
|
void writeToTemporaryFileImpl(
|
||||||
AggregatedDataVariants & data_variants,
|
AggregatedDataVariants & data_variants,
|
||||||
|
|||||||
@ -806,6 +806,13 @@ bool FileCache::tryReserve(FileSegment & file_segment, const size_t size)
|
|||||||
return true;
|
return true;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
void FileCache::removeKey(const Key & key)
|
||||||
|
{
|
||||||
|
assertInitialized();
|
||||||
|
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::THROW);
|
||||||
|
locked_key->removeAll();
|
||||||
|
}
|
||||||
|
|
||||||
void FileCache::removeKeyIfExists(const Key & key)
|
void FileCache::removeKeyIfExists(const Key & key)
|
||||||
{
|
{
|
||||||
assertInitialized();
|
assertInitialized();
|
||||||
@ -818,7 +825,14 @@ void FileCache::removeKeyIfExists(const Key & key)
|
|||||||
/// But if we have multiple replicated zero-copy tables on the same server
|
/// But if we have multiple replicated zero-copy tables on the same server
|
||||||
/// it became possible to start removing something from cache when it is used
|
/// it became possible to start removing something from cache when it is used
|
||||||
/// by other "zero-copy" tables. That is why it's not an error.
|
/// by other "zero-copy" tables. That is why it's not an error.
|
||||||
locked_key->removeAllReleasable();
|
locked_key->removeAll(/* if_releasable */true);
|
||||||
|
}
|
||||||
|
|
||||||
|
void FileCache::removeFileSegment(const Key & key, size_t offset)
|
||||||
|
{
|
||||||
|
assertInitialized();
|
||||||
|
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::THROW);
|
||||||
|
locked_key->removeFileSegment(offset);
|
||||||
}
|
}
|
||||||
|
|
||||||
void FileCache::removePathIfExists(const String & path)
|
void FileCache::removePathIfExists(const String & path)
|
||||||
@ -830,22 +844,12 @@ void FileCache::removeAllReleasable()
|
|||||||
{
|
{
|
||||||
assertInitialized();
|
assertInitialized();
|
||||||
|
|
||||||
auto lock = lockCache();
|
metadata.iterate([](LockedKey & locked_key) { locked_key.removeAll(/* if_releasable */true); });
|
||||||
|
|
||||||
main_priority->iterate([&](LockedKey & locked_key, const FileSegmentMetadataPtr & segment_metadata)
|
|
||||||
{
|
|
||||||
if (segment_metadata->releasable())
|
|
||||||
{
|
|
||||||
auto file_segment = segment_metadata->file_segment;
|
|
||||||
locked_key.removeFileSegment(file_segment->offset(), file_segment->lock());
|
|
||||||
return PriorityIterationResult::REMOVE_AND_CONTINUE;
|
|
||||||
}
|
|
||||||
return PriorityIterationResult::CONTINUE;
|
|
||||||
}, lock);
|
|
||||||
|
|
||||||
if (stash)
|
if (stash)
|
||||||
{
|
{
|
||||||
/// Remove all access information.
|
/// Remove all access information.
|
||||||
|
auto lock = lockCache();
|
||||||
stash->records.clear();
|
stash->records.clear();
|
||||||
stash->queue->removeAll(lock);
|
stash->queue->removeAll(lock);
|
||||||
}
|
}
|
||||||
@ -914,7 +918,7 @@ void FileCache::loadMetadata()
|
|||||||
continue;
|
continue;
|
||||||
}
|
}
|
||||||
|
|
||||||
const auto key = Key(unhexUInt<UInt128>(key_directory.filename().string().data()));
|
const auto key = Key::fromKeyString(key_directory.filename().string());
|
||||||
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::CREATE_EMPTY, /* is_initial_load */true);
|
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::CREATE_EMPTY, /* is_initial_load */true);
|
||||||
|
|
||||||
for (fs::directory_iterator offset_it{key_directory}; offset_it != fs::directory_iterator(); ++offset_it)
|
for (fs::directory_iterator offset_it{key_directory}; offset_it != fs::directory_iterator(); ++offset_it)
|
||||||
@ -1069,7 +1073,7 @@ FileSegmentsHolderPtr FileCache::getSnapshot()
|
|||||||
FileSegmentsHolderPtr FileCache::getSnapshot(const Key & key)
|
FileSegmentsHolderPtr FileCache::getSnapshot(const Key & key)
|
||||||
{
|
{
|
||||||
FileSegments file_segments;
|
FileSegments file_segments;
|
||||||
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::THROW);
|
auto locked_key = metadata.lockKeyMetadata(key, CacheMetadata::KeyNotFoundPolicy::THROW_LOGICAL);
|
||||||
for (const auto & [_, file_segment_metadata] : *locked_key->getKeyMetadata())
|
for (const auto & [_, file_segment_metadata] : *locked_key->getKeyMetadata())
|
||||||
file_segments.push_back(FileSegment::getSnapshot(file_segment_metadata->file_segment));
|
file_segments.push_back(FileSegment::getSnapshot(file_segment_metadata->file_segment));
|
||||||
return std::make_unique<FileSegmentsHolder>(std::move(file_segments));
|
return std::make_unique<FileSegmentsHolder>(std::move(file_segments));
|
||||||
|
|||||||
@ -83,13 +83,19 @@ public:
|
|||||||
|
|
||||||
FileSegmentsHolderPtr set(const Key & key, size_t offset, size_t size, const CreateFileSegmentSettings & settings);
|
FileSegmentsHolderPtr set(const Key & key, size_t offset, size_t size, const CreateFileSegmentSettings & settings);
|
||||||
|
|
||||||
/// Remove files by `key`. Removes files which might be used at the moment.
|
/// Remove file segment by `key` and `offset`. Throws if file segment does not exist.
|
||||||
|
void removeFileSegment(const Key & key, size_t offset);
|
||||||
|
|
||||||
|
/// Remove files by `key`. Throws if key does not exist.
|
||||||
|
void removeKey(const Key & key);
|
||||||
|
|
||||||
|
/// Remove files by `key`.
|
||||||
void removeKeyIfExists(const Key & key);
|
void removeKeyIfExists(const Key & key);
|
||||||
|
|
||||||
/// Removes files by `path`. Removes files which might be used at the moment.
|
/// Removes files by `path`.
|
||||||
void removePathIfExists(const String & path);
|
void removePathIfExists(const String & path);
|
||||||
|
|
||||||
/// Remove files by `key`. Will not remove files which are used at the moment.
|
/// Remove files by `key`.
|
||||||
void removeAllReleasable();
|
void removeAllReleasable();
|
||||||
|
|
||||||
std::vector<String> tryGetCachePaths(const Key & key);
|
std::vector<String> tryGetCachePaths(const Key & key);
|
||||||
|
|||||||
@ -7,6 +7,10 @@
|
|||||||
|
|
||||||
namespace DB
|
namespace DB
|
||||||
{
|
{
|
||||||
|
namespace ErrorCodes
|
||||||
|
{
|
||||||
|
extern const int BAD_ARGUMENTS;
|
||||||
|
}
|
||||||
|
|
||||||
FileCacheKey::FileCacheKey(const std::string & path)
|
FileCacheKey::FileCacheKey(const std::string & path)
|
||||||
: key(sipHash128(path.data(), path.size()))
|
: key(sipHash128(path.data(), path.size()))
|
||||||
@ -28,4 +32,11 @@ FileCacheKey FileCacheKey::random()
|
|||||||
return FileCacheKey(UUIDHelpers::generateV4().toUnderType());
|
return FileCacheKey(UUIDHelpers::generateV4().toUnderType());
|
||||||
}
|
}
|
||||||
|
|
||||||
|
FileCacheKey FileCacheKey::fromKeyString(const std::string & key_str)
|
||||||
|
{
|
||||||
|
if (key_str.size() != 32)
|
||||||
|
throw Exception(ErrorCodes::BAD_ARGUMENTS, "Invalid cache key hex: {}", key_str);
|
||||||
|
return FileCacheKey(unhexUInt<UInt128>(key_str.data()));
|
||||||
|
}
|
||||||
|
|
||||||
}
|
}
|
||||||
|
|||||||
@ -21,6 +21,8 @@ struct FileCacheKey
|
|||||||
static FileCacheKey random();
|
static FileCacheKey random();
|
||||||
|
|
||||||
bool operator==(const FileCacheKey & other) const { return key == other.key; }
|
bool operator==(const FileCacheKey & other) const { return key == other.key; }
|
||||||
|
|
||||||
|
static FileCacheKey fromKeyString(const std::string & key_str);
|
||||||
};
|
};
|
||||||
|
|
||||||
using FileCacheKeyAndOffset = std::pair<FileCacheKey, size_t>;
|
using FileCacheKeyAndOffset = std::pair<FileCacheKey, size_t>;
|
||||||
|
|||||||
@ -25,6 +25,7 @@ namespace DB
|
|||||||
namespace ErrorCodes
|
namespace ErrorCodes
|
||||||
{
|
{
|
||||||
extern const int LOGICAL_ERROR;
|
extern const int LOGICAL_ERROR;
|
||||||
|
extern const int BAD_ARGUMENTS;
|
||||||
}
|
}
|
||||||
|
|
||||||
FileSegmentMetadata::FileSegmentMetadata(FileSegmentPtr && file_segment_)
|
FileSegmentMetadata::FileSegmentMetadata(FileSegmentPtr && file_segment_)
|
||||||
@ -191,6 +192,8 @@ LockedKeyPtr CacheMetadata::lockKeyMetadata(
|
|||||||
if (it == end())
|
if (it == end())
|
||||||
{
|
{
|
||||||
if (key_not_found_policy == KeyNotFoundPolicy::THROW)
|
if (key_not_found_policy == KeyNotFoundPolicy::THROW)
|
||||||
|
throw Exception(ErrorCodes::BAD_ARGUMENTS, "No such key `{}` in cache", key);
|
||||||
|
else if (key_not_found_policy == KeyNotFoundPolicy::THROW_LOGICAL)
|
||||||
throw Exception(ErrorCodes::LOGICAL_ERROR, "No such key `{}` in cache", key);
|
throw Exception(ErrorCodes::LOGICAL_ERROR, "No such key `{}` in cache", key);
|
||||||
else if (key_not_found_policy == KeyNotFoundPolicy::RETURN_NULL)
|
else if (key_not_found_policy == KeyNotFoundPolicy::RETURN_NULL)
|
||||||
return nullptr;
|
return nullptr;
|
||||||
@ -215,6 +218,8 @@ LockedKeyPtr CacheMetadata::lockKeyMetadata(
|
|||||||
return locked_metadata;
|
return locked_metadata;
|
||||||
|
|
||||||
if (key_not_found_policy == KeyNotFoundPolicy::THROW)
|
if (key_not_found_policy == KeyNotFoundPolicy::THROW)
|
||||||
|
throw Exception(ErrorCodes::BAD_ARGUMENTS, "No such key `{}` in cache", key);
|
||||||
|
else if (key_not_found_policy == KeyNotFoundPolicy::THROW_LOGICAL)
|
||||||
throw Exception(ErrorCodes::LOGICAL_ERROR, "No such key `{}` in cache", key);
|
throw Exception(ErrorCodes::LOGICAL_ERROR, "No such key `{}` in cache", key);
|
||||||
|
|
||||||
if (key_not_found_policy == KeyNotFoundPolicy::RETURN_NULL)
|
if (key_not_found_policy == KeyNotFoundPolicy::RETURN_NULL)
|
||||||
@ -561,11 +566,11 @@ bool LockedKey::isLastOwnerOfFileSegment(size_t offset) const
|
|||||||
return file_segment_metadata->file_segment.use_count() == 2;
|
return file_segment_metadata->file_segment.use_count() == 2;
|
||||||
}
|
}
|
||||||
|
|
||||||
void LockedKey::removeAllReleasable()
|
void LockedKey::removeAll(bool if_releasable)
|
||||||
{
|
{
|
||||||
for (auto it = key_metadata->begin(); it != key_metadata->end();)
|
for (auto it = key_metadata->begin(); it != key_metadata->end();)
|
||||||
{
|
{
|
||||||
if (!it->second->releasable())
|
if (if_releasable && !it->second->releasable())
|
||||||
{
|
{
|
||||||
++it;
|
++it;
|
||||||
continue;
|
continue;
|
||||||
@ -586,17 +591,32 @@ void LockedKey::removeAllReleasable()
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
KeyMetadata::iterator LockedKey::removeFileSegment(size_t offset)
|
||||||
|
{
|
||||||
|
auto it = key_metadata->find(offset);
|
||||||
|
if (it == key_metadata->end())
|
||||||
|
throw Exception(ErrorCodes::BAD_ARGUMENTS, "There is no offset {}", offset);
|
||||||
|
|
||||||
|
auto file_segment = it->second->file_segment;
|
||||||
|
return removeFileSegmentImpl(it, file_segment->lock());
|
||||||
|
}
|
||||||
|
|
||||||
KeyMetadata::iterator LockedKey::removeFileSegment(size_t offset, const FileSegmentGuard::Lock & segment_lock)
|
KeyMetadata::iterator LockedKey::removeFileSegment(size_t offset, const FileSegmentGuard::Lock & segment_lock)
|
||||||
{
|
{
|
||||||
auto it = key_metadata->find(offset);
|
auto it = key_metadata->find(offset);
|
||||||
if (it == key_metadata->end())
|
if (it == key_metadata->end())
|
||||||
throw Exception(ErrorCodes::LOGICAL_ERROR, "There is no offset {}", offset);
|
throw Exception(ErrorCodes::LOGICAL_ERROR, "There is no offset {}", offset);
|
||||||
|
|
||||||
|
return removeFileSegmentImpl(it, segment_lock);
|
||||||
|
}
|
||||||
|
|
||||||
|
KeyMetadata::iterator LockedKey::removeFileSegmentImpl(KeyMetadata::iterator it, const FileSegmentGuard::Lock & segment_lock)
|
||||||
|
{
|
||||||
auto file_segment = it->second->file_segment;
|
auto file_segment = it->second->file_segment;
|
||||||
|
|
||||||
LOG_DEBUG(
|
LOG_DEBUG(
|
||||||
key_metadata->log, "Remove from cache. Key: {}, offset: {}, size: {}",
|
key_metadata->log, "Remove from cache. Key: {}, offset: {}, size: {}",
|
||||||
getKey(), offset, file_segment->reserved_size);
|
getKey(), file_segment->offset(), file_segment->reserved_size);
|
||||||
|
|
||||||
chassert(file_segment->assertCorrectnessUnlocked(segment_lock));
|
chassert(file_segment->assertCorrectnessUnlocked(segment_lock));
|
||||||
|
|
||||||
|
|||||||
@ -87,7 +87,7 @@ struct CacheMetadata : public std::unordered_map<FileCacheKey, KeyMetadataPtr>,
|
|||||||
{
|
{
|
||||||
public:
|
public:
|
||||||
using Key = FileCacheKey;
|
using Key = FileCacheKey;
|
||||||
using IterateCacheMetadataFunc = std::function<void(const LockedKey &)>;
|
using IterateCacheMetadataFunc = std::function<void(LockedKey &)>;
|
||||||
|
|
||||||
explicit CacheMetadata(const std::string & path_);
|
explicit CacheMetadata(const std::string & path_);
|
||||||
|
|
||||||
@ -106,6 +106,7 @@ public:
|
|||||||
enum class KeyNotFoundPolicy
|
enum class KeyNotFoundPolicy
|
||||||
{
|
{
|
||||||
THROW,
|
THROW,
|
||||||
|
THROW_LOGICAL,
|
||||||
CREATE_EMPTY,
|
CREATE_EMPTY,
|
||||||
RETURN_NULL,
|
RETURN_NULL,
|
||||||
};
|
};
|
||||||
@ -169,9 +170,10 @@ struct LockedKey : private boost::noncopyable
|
|||||||
std::shared_ptr<const KeyMetadata> getKeyMetadata() const { return key_metadata; }
|
std::shared_ptr<const KeyMetadata> getKeyMetadata() const { return key_metadata; }
|
||||||
std::shared_ptr<KeyMetadata> getKeyMetadata() { return key_metadata; }
|
std::shared_ptr<KeyMetadata> getKeyMetadata() { return key_metadata; }
|
||||||
|
|
||||||
void removeAllReleasable();
|
void removeAll(bool if_releasable = true);
|
||||||
|
|
||||||
KeyMetadata::iterator removeFileSegment(size_t offset, const FileSegmentGuard::Lock &);
|
KeyMetadata::iterator removeFileSegment(size_t offset, const FileSegmentGuard::Lock &);
|
||||||
|
KeyMetadata::iterator removeFileSegment(size_t offset);
|
||||||
|
|
||||||
void shrinkFileSegmentToDownloadedSize(size_t offset, const FileSegmentGuard::Lock &);
|
void shrinkFileSegmentToDownloadedSize(size_t offset, const FileSegmentGuard::Lock &);
|
||||||
|
|
||||||
@ -188,6 +190,8 @@ struct LockedKey : private boost::noncopyable
|
|||||||
std::string toString() const;
|
std::string toString() const;
|
||||||
|
|
||||||
private:
|
private:
|
||||||
|
KeyMetadata::iterator removeFileSegmentImpl(KeyMetadata::iterator it, const FileSegmentGuard::Lock &);
|
||||||
|
|
||||||
const std::shared_ptr<KeyMetadata> key_metadata;
|
const std::shared_ptr<KeyMetadata> key_metadata;
|
||||||
KeyGuard::Lock lock; /// `lock` must be destructed before `key_metadata`.
|
KeyGuard::Lock lock; /// `lock` must be destructed before `key_metadata`.
|
||||||
};
|
};
|
||||||
|
|||||||
@ -40,6 +40,8 @@ NamesAndTypesList FilesystemCacheLogElement::getNamesAndTypes()
|
|||||||
{"source_file_path", std::make_shared<DataTypeString>()},
|
{"source_file_path", std::make_shared<DataTypeString>()},
|
||||||
{"file_segment_range", std::make_shared<DataTypeTuple>(types)},
|
{"file_segment_range", std::make_shared<DataTypeTuple>(types)},
|
||||||
{"total_requested_range", std::make_shared<DataTypeTuple>(types)},
|
{"total_requested_range", std::make_shared<DataTypeTuple>(types)},
|
||||||
|
{"key", std::make_shared<DataTypeString>()},
|
||||||
|
{"offset", std::make_shared<DataTypeUInt64>()},
|
||||||
{"size", std::make_shared<DataTypeUInt64>()},
|
{"size", std::make_shared<DataTypeUInt64>()},
|
||||||
{"read_type", std::make_shared<DataTypeString>()},
|
{"read_type", std::make_shared<DataTypeString>()},
|
||||||
{"read_from_cache_attempted", std::make_shared<DataTypeUInt8>()},
|
{"read_from_cache_attempted", std::make_shared<DataTypeUInt8>()},
|
||||||
@ -60,6 +62,8 @@ void FilesystemCacheLogElement::appendToBlock(MutableColumns & columns) const
|
|||||||
columns[i++]->insert(source_file_path);
|
columns[i++]->insert(source_file_path);
|
||||||
columns[i++]->insert(Tuple{file_segment_range.first, file_segment_range.second});
|
columns[i++]->insert(Tuple{file_segment_range.first, file_segment_range.second});
|
||||||
columns[i++]->insert(Tuple{requested_range.first, requested_range.second});
|
columns[i++]->insert(Tuple{requested_range.first, requested_range.second});
|
||||||
|
columns[i++]->insert(file_segment_key);
|
||||||
|
columns[i++]->insert(file_segment_offset);
|
||||||
columns[i++]->insert(file_segment_size);
|
columns[i++]->insert(file_segment_size);
|
||||||
columns[i++]->insert(typeToString(cache_type));
|
columns[i++]->insert(typeToString(cache_type));
|
||||||
columns[i++]->insert(read_from_cache_attempted);
|
columns[i++]->insert(read_from_cache_attempted);
|
||||||
|
|||||||
@ -11,16 +11,7 @@
|
|||||||
|
|
||||||
namespace DB
|
namespace DB
|
||||||
{
|
{
|
||||||
///
|
|
||||||
/// -------- Column --------- Type ------
|
|
||||||
/// | event_date | DateTime |
|
|
||||||
/// | event_time | UInt64 |
|
|
||||||
/// | query_id | String |
|
|
||||||
/// | remote_file_path | String |
|
|
||||||
/// | segment_range | Tuple |
|
|
||||||
/// | read_type | String |
|
|
||||||
/// -------------------------------------
|
|
||||||
///
|
|
||||||
struct FilesystemCacheLogElement
|
struct FilesystemCacheLogElement
|
||||||
{
|
{
|
||||||
enum class CacheType
|
enum class CacheType
|
||||||
@ -39,6 +30,8 @@ struct FilesystemCacheLogElement
|
|||||||
std::pair<size_t, size_t> file_segment_range{};
|
std::pair<size_t, size_t> file_segment_range{};
|
||||||
std::pair<size_t, size_t> requested_range{};
|
std::pair<size_t, size_t> requested_range{};
|
||||||
CacheType cache_type{};
|
CacheType cache_type{};
|
||||||
|
std::string file_segment_key;
|
||||||
|
size_t file_segment_offset;
|
||||||
size_t file_segment_size;
|
size_t file_segment_size;
|
||||||
bool read_from_cache_attempted;
|
bool read_from_cache_attempted;
|
||||||
String read_buffer_id;
|
String read_buffer_id;
|
||||||
|
|||||||
@ -371,7 +371,18 @@ BlockIO InterpreterSystemQuery::execute()
|
|||||||
else
|
else
|
||||||
{
|
{
|
||||||
auto cache = FileCacheFactory::instance().getByName(query.filesystem_cache_name).cache;
|
auto cache = FileCacheFactory::instance().getByName(query.filesystem_cache_name).cache;
|
||||||
cache->removeAllReleasable();
|
if (query.key_to_drop.empty())
|
||||||
|
{
|
||||||
|
cache->removeAllReleasable();
|
||||||
|
}
|
||||||
|
else
|
||||||
|
{
|
||||||
|
auto key = FileCacheKey::fromKeyString(query.key_to_drop);
|
||||||
|
if (query.offset_to_drop.has_value())
|
||||||
|
cache->removeFileSegment(key, query.offset_to_drop.value());
|
||||||
|
else
|
||||||
|
cache->removeKey(key);
|
||||||
|
}
|
||||||
}
|
}
|
||||||
break;
|
break;
|
||||||
}
|
}
|
||||||
|
|||||||
@ -48,6 +48,11 @@ namespace ErrorCodes
|
|||||||
extern const int NOT_IMPLEMENTED;
|
extern const int NOT_IMPLEMENTED;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
namespace ActionLocks
|
||||||
|
{
|
||||||
|
extern const StorageActionBlockType PartsMerge;
|
||||||
|
}
|
||||||
|
|
||||||
namespace
|
namespace
|
||||||
{
|
{
|
||||||
class StorageWithComment : public IAST
|
class StorageWithComment : public IAST
|
||||||
@ -560,6 +565,10 @@ void SystemLog<LogElement>::prepareTable()
|
|||||||
|
|
||||||
rename->elements.emplace_back(std::move(elem));
|
rename->elements.emplace_back(std::move(elem));
|
||||||
|
|
||||||
|
ActionLock merges_lock;
|
||||||
|
if (DatabaseCatalog::instance().getDatabase(table_id.database_name)->getUUID() == UUIDHelpers::Nil)
|
||||||
|
merges_lock = table->getActionLock(ActionLocks::PartsMerge);
|
||||||
|
|
||||||
auto query_context = Context::createCopy(context);
|
auto query_context = Context::createCopy(context);
|
||||||
/// As this operation is performed automatically we don't want it to fail because of user dependencies on log tables
|
/// As this operation is performed automatically we don't want it to fail because of user dependencies on log tables
|
||||||
query_context->setSetting("check_table_dependencies", Field{false});
|
query_context->setSetting("check_table_dependencies", Field{false});
|
||||||
|
|||||||
@ -49,7 +49,7 @@ static ZooKeeperRetriesInfo getRetriesInfo()
|
|||||||
);
|
);
|
||||||
}
|
}
|
||||||
|
|
||||||
bool isSupportedAlterType(int type)
|
bool isSupportedAlterTypeForOnClusterDDLQuery(int type)
|
||||||
{
|
{
|
||||||
assert(type != ASTAlterCommand::NO_TYPE);
|
assert(type != ASTAlterCommand::NO_TYPE);
|
||||||
static const std::unordered_set<int> unsupported_alter_types{
|
static const std::unordered_set<int> unsupported_alter_types{
|
||||||
@ -90,7 +90,7 @@ BlockIO executeDDLQueryOnCluster(const ASTPtr & query_ptr_, ContextPtr context,
|
|||||||
{
|
{
|
||||||
for (const auto & command : query_alter->command_list->children)
|
for (const auto & command : query_alter->command_list->children)
|
||||||
{
|
{
|
||||||
if (!isSupportedAlterType(command->as<ASTAlterCommand&>().type))
|
if (!isSupportedAlterTypeForOnClusterDDLQuery(command->as<ASTAlterCommand&>().type))
|
||||||
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Unsupported type of ALTER query");
|
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Unsupported type of ALTER query");
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
@ -21,7 +21,7 @@ class Cluster;
|
|||||||
using ClusterPtr = std::shared_ptr<Cluster>;
|
using ClusterPtr = std::shared_ptr<Cluster>;
|
||||||
|
|
||||||
/// Returns true if provided ALTER type can be executed ON CLUSTER
|
/// Returns true if provided ALTER type can be executed ON CLUSTER
|
||||||
bool isSupportedAlterType(int type);
|
bool isSupportedAlterTypeForOnClusterDDLQuery(int type);
|
||||||
|
|
||||||
struct DDLQueryOnClusterParams
|
struct DDLQueryOnClusterParams
|
||||||
{
|
{
|
||||||
|
|||||||
@ -13,7 +13,7 @@ namespace ErrorCodes
|
|||||||
|
|
||||||
String ASTAlterCommand::getID(char delim) const
|
String ASTAlterCommand::getID(char delim) const
|
||||||
{
|
{
|
||||||
return String("AlterCommand") + delim + typeToString(type);
|
return fmt::format("AlterCommand{}{}", delim, type);
|
||||||
}
|
}
|
||||||
|
|
||||||
ASTPtr ASTAlterCommand::clone() const
|
ASTPtr ASTAlterCommand::clone() const
|
||||||
@ -80,53 +80,6 @@ ASTPtr ASTAlterCommand::clone() const
|
|||||||
return res;
|
return res;
|
||||||
}
|
}
|
||||||
|
|
||||||
const char * ASTAlterCommand::typeToString(ASTAlterCommand::Type type)
|
|
||||||
{
|
|
||||||
switch (type)
|
|
||||||
{
|
|
||||||
case ADD_COLUMN: return "ADD_COLUMN";
|
|
||||||
case DROP_COLUMN: return "DROP_COLUMN";
|
|
||||||
case MODIFY_COLUMN: return "MODIFY_COLUMN";
|
|
||||||
case COMMENT_COLUMN: return "COMMENT_COLUMN";
|
|
||||||
case RENAME_COLUMN: return "RENAME_COLUMN";
|
|
||||||
case MATERIALIZE_COLUMN: return "MATERIALIZE_COLUMN";
|
|
||||||
case MODIFY_ORDER_BY: return "MODIFY_ORDER_BY";
|
|
||||||
case MODIFY_SAMPLE_BY: return "MODIFY_SAMPLE_BY";
|
|
||||||
case MODIFY_TTL: return "MODIFY_TTL";
|
|
||||||
case MATERIALIZE_TTL: return "MATERIALIZE_TTL";
|
|
||||||
case MODIFY_SETTING: return "MODIFY_SETTING";
|
|
||||||
case RESET_SETTING: return "RESET_SETTING";
|
|
||||||
case MODIFY_QUERY: return "MODIFY_QUERY";
|
|
||||||
case REMOVE_TTL: return "REMOVE_TTL";
|
|
||||||
case REMOVE_SAMPLE_BY: return "REMOVE_SAMPLE_BY";
|
|
||||||
case ADD_INDEX: return "ADD_INDEX";
|
|
||||||
case DROP_INDEX: return "DROP_INDEX";
|
|
||||||
case MATERIALIZE_INDEX: return "MATERIALIZE_INDEX";
|
|
||||||
case ADD_CONSTRAINT: return "ADD_CONSTRAINT";
|
|
||||||
case DROP_CONSTRAINT: return "DROP_CONSTRAINT";
|
|
||||||
case ADD_PROJECTION: return "ADD_PROJECTION";
|
|
||||||
case DROP_PROJECTION: return "DROP_PROJECTION";
|
|
||||||
case MATERIALIZE_PROJECTION: return "MATERIALIZE_PROJECTION";
|
|
||||||
case DROP_PARTITION: return "DROP_PARTITION";
|
|
||||||
case DROP_DETACHED_PARTITION: return "DROP_DETACHED_PARTITION";
|
|
||||||
case ATTACH_PARTITION: return "ATTACH_PARTITION";
|
|
||||||
case MOVE_PARTITION: return "MOVE_PARTITION";
|
|
||||||
case REPLACE_PARTITION: return "REPLACE_PARTITION";
|
|
||||||
case FETCH_PARTITION: return "FETCH_PARTITION";
|
|
||||||
case FREEZE_PARTITION: return "FREEZE_PARTITION";
|
|
||||||
case FREEZE_ALL: return "FREEZE_ALL";
|
|
||||||
case UNFREEZE_PARTITION: return "UNFREEZE_PARTITION";
|
|
||||||
case UNFREEZE_ALL: return "UNFREEZE_ALL";
|
|
||||||
case DELETE: return "DELETE";
|
|
||||||
case UPDATE: return "UPDATE";
|
|
||||||
case NO_TYPE: return "NO_TYPE";
|
|
||||||
case LIVE_VIEW_REFRESH: return "LIVE_VIEW_REFRESH";
|
|
||||||
case MODIFY_DATABASE_SETTING: return "MODIFY_DATABASE_SETTING";
|
|
||||||
case MODIFY_COMMENT: return "MODIFY_COMMENT";
|
|
||||||
}
|
|
||||||
UNREACHABLE();
|
|
||||||
}
|
|
||||||
|
|
||||||
void ASTAlterCommand::formatImpl(const FormatSettings & settings, FormatState & state, FormatStateStacked frame) const
|
void ASTAlterCommand::formatImpl(const FormatSettings & settings, FormatState & state, FormatStateStacked frame) const
|
||||||
{
|
{
|
||||||
if (type == ASTAlterCommand::ADD_COLUMN)
|
if (type == ASTAlterCommand::ADD_COLUMN)
|
||||||
|
|||||||
@ -208,8 +208,6 @@ public:
|
|||||||
|
|
||||||
ASTPtr clone() const override;
|
ASTPtr clone() const override;
|
||||||
|
|
||||||
static const char * typeToString(Type type);
|
|
||||||
|
|
||||||
protected:
|
protected:
|
||||||
void formatImpl(const FormatSettings & settings, FormatState & state, FormatStateStacked frame) const override;
|
void formatImpl(const FormatSettings & settings, FormatState & state, FormatStateStacked frame) const override;
|
||||||
};
|
};
|
||||||
|
|||||||
@ -210,7 +210,15 @@ void ASTSystemQuery::formatImpl(const FormatSettings & settings, FormatState &,
|
|||||||
else if (type == Type::DROP_FILESYSTEM_CACHE)
|
else if (type == Type::DROP_FILESYSTEM_CACHE)
|
||||||
{
|
{
|
||||||
if (!filesystem_cache_name.empty())
|
if (!filesystem_cache_name.empty())
|
||||||
|
{
|
||||||
settings.ostr << (settings.hilite ? hilite_none : "") << " " << filesystem_cache_name;
|
settings.ostr << (settings.hilite ? hilite_none : "") << " " << filesystem_cache_name;
|
||||||
|
if (!key_to_drop.empty())
|
||||||
|
{
|
||||||
|
settings.ostr << (settings.hilite ? hilite_none : "") << " KEY " << key_to_drop;
|
||||||
|
if (offset_to_drop.has_value())
|
||||||
|
settings.ostr << (settings.hilite ? hilite_none : "") << " OFFSET " << offset_to_drop.value();
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
else if (type == Type::UNFREEZE)
|
else if (type == Type::UNFREEZE)
|
||||||
{
|
{
|
||||||
|
|||||||
@ -108,6 +108,8 @@ public:
|
|||||||
UInt64 seconds{};
|
UInt64 seconds{};
|
||||||
|
|
||||||
String filesystem_cache_name;
|
String filesystem_cache_name;
|
||||||
|
std::string key_to_drop;
|
||||||
|
std::optional<size_t> offset_to_drop;
|
||||||
|
|
||||||
String backup_name;
|
String backup_name;
|
||||||
|
|
||||||
|
|||||||
@ -405,7 +405,15 @@ bool ParserSystemQuery::parseImpl(IParser::Pos & pos, ASTPtr & node, Expected &
|
|||||||
ParserLiteral path_parser;
|
ParserLiteral path_parser;
|
||||||
ASTPtr ast;
|
ASTPtr ast;
|
||||||
if (path_parser.parse(pos, ast, expected))
|
if (path_parser.parse(pos, ast, expected))
|
||||||
|
{
|
||||||
res->filesystem_cache_name = ast->as<ASTLiteral>()->value.safeGet<String>();
|
res->filesystem_cache_name = ast->as<ASTLiteral>()->value.safeGet<String>();
|
||||||
|
if (ParserKeyword{"KEY"}.ignore(pos, expected) && ParserIdentifier().parse(pos, ast, expected))
|
||||||
|
{
|
||||||
|
res->key_to_drop = ast->as<ASTIdentifier>()->name();
|
||||||
|
if (ParserKeyword{"OFFSET"}.ignore(pos, expected) && ParserLiteral().parse(pos, ast, expected))
|
||||||
|
res->offset_to_drop = ast->as<ASTLiteral>()->value.safeGet<UInt64>();
|
||||||
|
}
|
||||||
|
}
|
||||||
if (!parseQueryWithOnCluster(res, pos, expected))
|
if (!parseQueryWithOnCluster(res, pos, expected))
|
||||||
return false;
|
return false;
|
||||||
break;
|
break;
|
||||||
|
|||||||
@ -159,14 +159,14 @@ void AggregatingInOrderTransform::consume(Chunk chunk)
|
|||||||
if (group_by_key)
|
if (group_by_key)
|
||||||
params->aggregator.mergeOnBlockSmall(variants, key_begin, key_end, aggregate_columns_data, key_columns_raw);
|
params->aggregator.mergeOnBlockSmall(variants, key_begin, key_end, aggregate_columns_data, key_columns_raw);
|
||||||
else
|
else
|
||||||
params->aggregator.mergeOnIntervalWithoutKeyImpl(variants, key_begin, key_end, aggregate_columns_data);
|
params->aggregator.mergeOnIntervalWithoutKey(variants, key_begin, key_end, aggregate_columns_data);
|
||||||
}
|
}
|
||||||
else
|
else
|
||||||
{
|
{
|
||||||
if (group_by_key)
|
if (group_by_key)
|
||||||
params->aggregator.executeOnBlockSmall(variants, key_begin, key_end, key_columns_raw, aggregate_function_instructions.data());
|
params->aggregator.executeOnBlockSmall(variants, key_begin, key_end, key_columns_raw, aggregate_function_instructions.data());
|
||||||
else
|
else
|
||||||
params->aggregator.executeOnIntervalWithoutKeyImpl(variants, key_begin, key_end, aggregate_function_instructions.data());
|
params->aggregator.executeOnIntervalWithoutKey(variants, key_begin, key_end, aggregate_function_instructions.data());
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@ -125,9 +125,6 @@ void localBackup(
|
|||||||
size_t try_no = 0;
|
size_t try_no = 0;
|
||||||
const size_t max_tries = 10;
|
const size_t max_tries = 10;
|
||||||
|
|
||||||
CleanupOnFail cleanup(disk_transaction ? std::function<void()>([]{}) :
|
|
||||||
[disk, destination_path]() { disk->removeRecursive(destination_path); });
|
|
||||||
|
|
||||||
/** Files in the directory can be permanently added and deleted.
|
/** Files in the directory can be permanently added and deleted.
|
||||||
* If some file is deleted during an attempt to make a backup, then try again,
|
* If some file is deleted during an attempt to make a backup, then try again,
|
||||||
* because it's important to take into account any new files that might appear.
|
* because it's important to take into account any new files that might appear.
|
||||||
@ -136,10 +133,30 @@ void localBackup(
|
|||||||
{
|
{
|
||||||
try
|
try
|
||||||
{
|
{
|
||||||
if (copy_instead_of_hardlinks && !disk_transaction)
|
if (disk_transaction)
|
||||||
disk->copyDirectoryContent(source_path, disk, destination_path);
|
{
|
||||||
else
|
|
||||||
localBackupImpl(disk, disk_transaction.get(), source_path, destination_path, make_source_readonly, 0, max_level, copy_instead_of_hardlinks, files_to_copy_intead_of_hardlinks);
|
localBackupImpl(disk, disk_transaction.get(), source_path, destination_path, make_source_readonly, 0, max_level, copy_instead_of_hardlinks, files_to_copy_intead_of_hardlinks);
|
||||||
|
}
|
||||||
|
else if (copy_instead_of_hardlinks)
|
||||||
|
{
|
||||||
|
CleanupOnFail cleanup([disk, destination_path]() { disk->removeRecursive(destination_path); });
|
||||||
|
disk->copyDirectoryContent(source_path, disk, destination_path);
|
||||||
|
cleanup.success();
|
||||||
|
}
|
||||||
|
else
|
||||||
|
{
|
||||||
|
std::function<void()> cleaner;
|
||||||
|
if (disk->supportZeroCopyReplication())
|
||||||
|
/// Note: this code will create garbage on s3. We should always remove `copy_instead_of_hardlinks` files.
|
||||||
|
/// The third argument should be a list of exceptions, but (looks like) it is ignored for keep_all_shared_data = true.
|
||||||
|
cleaner = [disk, destination_path]() { disk->removeSharedRecursive(destination_path, /*keep_all_shared_data*/ true, {}); };
|
||||||
|
else
|
||||||
|
cleaner = [disk, destination_path]() { disk->removeRecursive(destination_path); };
|
||||||
|
|
||||||
|
CleanupOnFail cleanup(std::move(cleaner));
|
||||||
|
localBackupImpl(disk, disk_transaction.get(), source_path, destination_path, make_source_readonly, 0, max_level, false, files_to_copy_intead_of_hardlinks);
|
||||||
|
cleanup.success();
|
||||||
|
}
|
||||||
}
|
}
|
||||||
catch (const DB::ErrnoException & e)
|
catch (const DB::ErrnoException & e)
|
||||||
{
|
{
|
||||||
@ -166,8 +183,6 @@ void localBackup(
|
|||||||
|
|
||||||
break;
|
break;
|
||||||
}
|
}
|
||||||
|
|
||||||
cleanup.success();
|
|
||||||
}
|
}
|
||||||
|
|
||||||
}
|
}
|
||||||
|
|||||||
@ -1154,16 +1154,25 @@ MergeMutateSelectedEntryPtr StorageMergeTree::selectPartsToMutate(
|
|||||||
}
|
}
|
||||||
|
|
||||||
TransactionID first_mutation_tid = mutations_begin_it->second.tid;
|
TransactionID first_mutation_tid = mutations_begin_it->second.tid;
|
||||||
MergeTreeTransactionPtr txn = tryGetTransactionForMutation(mutations_begin_it->second, log);
|
MergeTreeTransactionPtr txn;
|
||||||
assert(txn || first_mutation_tid.isPrehistoric());
|
|
||||||
|
|
||||||
if (txn)
|
if (!first_mutation_tid.isPrehistoric())
|
||||||
{
|
{
|
||||||
|
|
||||||
/// Mutate visible parts only
|
/// Mutate visible parts only
|
||||||
/// NOTE Do not mutate visible parts in Outdated state, because it does not make sense:
|
/// NOTE Do not mutate visible parts in Outdated state, because it does not make sense:
|
||||||
/// mutation will fail anyway due to serialization error.
|
/// mutation will fail anyway due to serialization error.
|
||||||
if (!part->version.isVisible(*txn))
|
|
||||||
|
/// It's possible that both mutation and transaction are already finished,
|
||||||
|
/// because that part should not be mutated because it was not visible for that transaction.
|
||||||
|
if (!part->version.isVisible(first_mutation_tid.start_csn, first_mutation_tid))
|
||||||
continue;
|
continue;
|
||||||
|
|
||||||
|
txn = tryGetTransactionForMutation(mutations_begin_it->second, log);
|
||||||
|
if (!txn)
|
||||||
|
throw Exception(ErrorCodes::LOGICAL_ERROR, "Cannot find transaction {} that has started mutation {} "
|
||||||
|
"that is going to be applied to part {}",
|
||||||
|
first_mutation_tid, mutations_begin_it->second.file_name, part->name);
|
||||||
}
|
}
|
||||||
|
|
||||||
auto commands = std::make_shared<MutationCommands>();
|
auto commands = std::make_shared<MutationCommands>();
|
||||||
|
|||||||
@ -275,15 +275,6 @@ Pipe StorageSystemStackTrace::read(
|
|||||||
|
|
||||||
Block sample_block = storage_snapshot->metadata->getSampleBlock();
|
Block sample_block = storage_snapshot->metadata->getSampleBlock();
|
||||||
|
|
||||||
std::vector<UInt8> columns_mask(sample_block.columns());
|
|
||||||
for (size_t i = 0, size = columns_mask.size(); i < size; ++i)
|
|
||||||
{
|
|
||||||
if (names_set.contains(sample_block.getByPosition(i).name))
|
|
||||||
{
|
|
||||||
columns_mask[i] = 1;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
bool send_signal = names_set.contains("trace") || names_set.contains("query_id");
|
bool send_signal = names_set.contains("trace") || names_set.contains("query_id");
|
||||||
bool read_thread_names = names_set.contains("thread_name");
|
bool read_thread_names = names_set.contains("thread_name");
|
||||||
|
|
||||||
|
|||||||
@ -761,7 +761,7 @@ def test_multiple_tables_streaming_sync(started_cluster, mode):
|
|||||||
@pytest.mark.parametrize("mode", AVAILABLE_MODES)
|
@pytest.mark.parametrize("mode", AVAILABLE_MODES)
|
||||||
def test_multiple_tables_streaming_sync_distributed(started_cluster, mode):
|
def test_multiple_tables_streaming_sync_distributed(started_cluster, mode):
|
||||||
files_to_generate = 100
|
files_to_generate = 100
|
||||||
poll_size = 10
|
poll_size = 2
|
||||||
prefix = f"test_multiple_{mode}"
|
prefix = f"test_multiple_{mode}"
|
||||||
bucket = started_cluster.minio_restricted_bucket
|
bucket = started_cluster.minio_restricted_bucket
|
||||||
instance = started_cluster.instances["instance"]
|
instance = started_cluster.instances["instance"]
|
||||||
@ -785,7 +785,12 @@ def test_multiple_tables_streaming_sync_distributed(started_cluster, mode):
|
|||||||
CREATE TABLE test.s3_queue_persistent ({table_format})
|
CREATE TABLE test.s3_queue_persistent ({table_format})
|
||||||
ENGINE = MergeTree()
|
ENGINE = MergeTree()
|
||||||
ORDER BY column1;
|
ORDER BY column1;
|
||||||
|
"""
|
||||||
|
)
|
||||||
|
|
||||||
|
for inst in [instance, instance_2]:
|
||||||
|
inst.query(
|
||||||
|
f"""
|
||||||
CREATE MATERIALIZED VIEW test.persistent_s3_queue_mv TO test.s3_queue_persistent AS
|
CREATE MATERIALIZED VIEW test.persistent_s3_queue_mv TO test.s3_queue_persistent AS
|
||||||
SELECT
|
SELECT
|
||||||
*
|
*
|
||||||
@ -800,7 +805,7 @@ def test_multiple_tables_streaming_sync_distributed(started_cluster, mode):
|
|||||||
def get_count(node, table_name):
|
def get_count(node, table_name):
|
||||||
return int(run_query(node, f"SELECT count() FROM {table_name}"))
|
return int(run_query(node, f"SELECT count() FROM {table_name}"))
|
||||||
|
|
||||||
for _ in range(100):
|
for _ in range(150):
|
||||||
if (
|
if (
|
||||||
get_count(instance, "test.s3_queue_persistent")
|
get_count(instance, "test.s3_queue_persistent")
|
||||||
+ get_count(instance_2, "test.s3_queue_persistent")
|
+ get_count(instance_2, "test.s3_queue_persistent")
|
||||||
@ -816,11 +821,12 @@ def test_multiple_tables_streaming_sync_distributed(started_cluster, mode):
|
|||||||
list(map(int, l.split())) for l in run_query(instance_2, get_query).splitlines()
|
list(map(int, l.split())) for l in run_query(instance_2, get_query).splitlines()
|
||||||
]
|
]
|
||||||
|
|
||||||
|
assert len(res1) + len(res2) == files_to_generate
|
||||||
|
|
||||||
# Checking that all engines have made progress
|
# Checking that all engines have made progress
|
||||||
assert len(res1) > 0
|
assert len(res1) > 0
|
||||||
assert len(res2) > 0
|
assert len(res2) > 0
|
||||||
|
|
||||||
assert len(res1) + len(res2) == files_to_generate
|
|
||||||
assert {tuple(v) for v in res1 + res2} == set([tuple(i) for i in total_values])
|
assert {tuple(v) for v in res1 + res2} == set([tuple(i) for i in total_values])
|
||||||
|
|
||||||
# Checking that all files were processed only once
|
# Checking that all files were processed only once
|
||||||
|
|||||||
@ -36,7 +36,7 @@ def gen_data(q):
|
|||||||
|
|
||||||
pattern = ''' or toString(number) = '{}'\n'''
|
pattern = ''' or toString(number) = '{}'\n'''
|
||||||
|
|
||||||
for i in range(1, 4 * 1024):
|
for i in range(0, 1024 * 2):
|
||||||
yield pattern.format(str(i).zfill(1024 - len(pattern) + 2)).encode()
|
yield pattern.format(str(i).zfill(1024 - len(pattern) + 2)).encode()
|
||||||
|
|
||||||
s = requests.Session()
|
s = requests.Session()
|
||||||
|
|||||||
@ -36,3 +36,5 @@ tx14 10 22 all_1_14_2_18
|
|||||||
tx14 10 42 all_1_14_2_18
|
tx14 10 42 all_1_14_2_18
|
||||||
tx14 10 62 all_1_14_2_18
|
tx14 10 62 all_1_14_2_18
|
||||||
tx14 10 82 all_1_14_2_18
|
tx14 10 82 all_1_14_2_18
|
||||||
|
11 2 all_2_2_0
|
||||||
|
11 10 all_1_1_0_3
|
||||||
|
|||||||
@ -94,3 +94,16 @@ tx 14 "begin transaction"
|
|||||||
tx 14 "select 10, n, _part from mt order by n" | accept_both_parts
|
tx 14 "select 10, n, _part from mt order by n" | accept_both_parts
|
||||||
|
|
||||||
$CLICKHOUSE_CLIENT --database_atomic_wait_for_drop_and_detach_synchronously=0 -q "drop table mt"
|
$CLICKHOUSE_CLIENT --database_atomic_wait_for_drop_and_detach_synchronously=0 -q "drop table mt"
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT -q "create table mt (n int) engine=MergeTree order by tuple()"
|
||||||
|
$CLICKHOUSE_CLIENT --implicit_transaction=1 -q "insert into mt values (1)"
|
||||||
|
|
||||||
|
tx 15 "begin transaction"
|
||||||
|
tx 16 "begin transaction"
|
||||||
|
tx 16 "insert into mt values (2)"
|
||||||
|
tx 15 "alter table mt update n = 10*n where 1"
|
||||||
|
tx 15 "commit"
|
||||||
|
tx 16 "commit"
|
||||||
|
$CLICKHOUSE_CLIENT --implicit_transaction=1 -q "select 11, n, _part from mt order by n"
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT -q "drop table mt"
|
||||||
|
|||||||
@ -0,0 +1 @@
|
|||||||
|
1
|
||||||
9
tests/queries/0_stateless/02790_client_max_opening_fd.sh
Executable file
9
tests/queries/0_stateless/02790_client_max_opening_fd.sh
Executable file
@ -0,0 +1,9 @@
|
|||||||
|
#!/usr/bin/env bash
|
||||||
|
|
||||||
|
CUR_DIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
|
||||||
|
# shellcheck source=../shell_config.sh
|
||||||
|
. "$CUR_DIR"/../shell_config.sh
|
||||||
|
|
||||||
|
# Ensure that clickhouse-client does not open a large number of files.
|
||||||
|
ulimit -n 1024
|
||||||
|
${CLICKHOUSE_CLIENT} --query "SELECT 1"
|
||||||
@ -0,0 +1,12 @@
|
|||||||
|
DROP TABLE IF EXISTS v;
|
||||||
|
|
||||||
|
create view v (s LowCardinality(String), n UInt8) as select 'test' as s, toUInt8(number) as n from numbers(10000000);
|
||||||
|
|
||||||
|
-- this is what allows mem usage to go really high
|
||||||
|
set max_block_size=10000000000;
|
||||||
|
|
||||||
|
set max_memory_usage = '1Gi';
|
||||||
|
|
||||||
|
select s, sum(n) from v group by s format Null;
|
||||||
|
|
||||||
|
DROP TABLE v;
|
||||||
@ -0,0 +1,5 @@
|
|||||||
|
OK
|
||||||
|
1
|
||||||
|
0
|
||||||
|
1
|
||||||
|
0
|
||||||
71
tests/queries/0_stateless/02808_filesystem_cache_drop_query.sh
Executable file
71
tests/queries/0_stateless/02808_filesystem_cache_drop_query.sh
Executable file
@ -0,0 +1,71 @@
|
|||||||
|
#!/usr/bin/env bash
|
||||||
|
# Tags: no-fasttest, no-parallel, no-s3-storage, no-random-settings
|
||||||
|
|
||||||
|
# set -x
|
||||||
|
|
||||||
|
CUR_DIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
|
||||||
|
# shellcheck source=../shell_config.sh
|
||||||
|
. "$CUR_DIR"/../shell_config.sh
|
||||||
|
|
||||||
|
|
||||||
|
disk_name="${CLICKHOUSE_TEST_UNIQUE_NAME}"
|
||||||
|
$CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
DROP TABLE IF EXISTS test;
|
||||||
|
CREATE TABLE test (a Int32, b String)
|
||||||
|
ENGINE = MergeTree() ORDER BY tuple()
|
||||||
|
SETTINGS disk = disk(name = '$disk_name', type = cache, max_size = '100Ki', path = ${CLICKHOUSE_TEST_UNIQUE_NAME}, disk = s3_disk);
|
||||||
|
|
||||||
|
INSERT INTO test SELECT 1, 'test';
|
||||||
|
"""
|
||||||
|
|
||||||
|
query_id=$RANDOM
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT --query_id "$query_id" --query "SELECT * FROM test FORMAT Null SETTINGS enable_filesystem_cache_log = 1"
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SYSTEM DROP FILESYSTEM CACHE '$disk_name' KEY kek;
|
||||||
|
""" 2>&1 | grep -q "Invalid cache key hex: kek" && echo "OK" || echo "FAIL"
|
||||||
|
|
||||||
|
${CLICKHOUSE_CLIENT} -q " system flush logs"
|
||||||
|
|
||||||
|
key=$($CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SELECT key FROM system.filesystem_cache_log WHERE query_id = '$query_id' ORDER BY size DESC LIMIT 1;
|
||||||
|
""")
|
||||||
|
|
||||||
|
offset=$($CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SELECT offset FROM system.filesystem_cache_log WHERE query_id = '$query_id' ORDER BY size DESC LIMIT 1;
|
||||||
|
""")
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SELECT count() FROM system.filesystem_cache WHERE key = '$key' AND file_segment_range_begin = $offset;
|
||||||
|
"""
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SYSTEM DROP FILESYSTEM CACHE '$disk_name' KEY $key OFFSET $offset;
|
||||||
|
"""
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SELECT count() FROM system.filesystem_cache WHERE key = '$key' AND file_segment_range_begin = $offset;
|
||||||
|
"""
|
||||||
|
|
||||||
|
query_id=$RANDOM$RANDOM
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT --query_id "$query_id" --query "SELECT * FROM test FORMAT Null SETTINGS enable_filesystem_cache_log = 1"
|
||||||
|
|
||||||
|
${CLICKHOUSE_CLIENT} -q " system flush logs"
|
||||||
|
|
||||||
|
key=$($CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SELECT key FROM system.filesystem_cache_log WHERE query_id = '$query_id' ORDER BY size DESC LIMIT 1;
|
||||||
|
""")
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SELECT count() FROM system.filesystem_cache WHERE key = '$key';
|
||||||
|
"""
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SYSTEM DROP FILESYSTEM CACHE '$disk_name' KEY $key
|
||||||
|
"""
|
||||||
|
|
||||||
|
$CLICKHOUSE_CLIENT -nm --query """
|
||||||
|
SELECT count() FROM system.filesystem_cache WHERE key = '$key';
|
||||||
|
"""
|
||||||
Loading…
Reference in New Issue
Block a user