mirror of
https://github.com/ClickHouse/ClickHouse.git
synced 2024-11-27 10:02:01 +00:00
Merge branch 'master' into improve-throttling-tests
This commit is contained in:
commit
a9ae102169
3
.github/workflows/backport_branches.yml
vendored
3
.github/workflows/backport_branches.yml
vendored
@ -3,6 +3,9 @@ name: BackportPR
|
|||||||
env:
|
env:
|
||||||
# Force the stdout and stderr streams to be unbuffered
|
# Force the stdout and stderr streams to be unbuffered
|
||||||
PYTHONUNBUFFERED: 1
|
PYTHONUNBUFFERED: 1
|
||||||
|
# Export system tables to ClickHouse Cloud
|
||||||
|
CLICKHOUSE_CI_LOGS_HOST: ${{ secrets.CLICKHOUSE_CI_LOGS_HOST }}
|
||||||
|
CLICKHOUSE_CI_LOGS_PASSWORD: ${{ secrets.CLICKHOUSE_CI_LOGS_PASSWORD }}
|
||||||
|
|
||||||
on: # yamllint disable-line rule:truthy
|
on: # yamllint disable-line rule:truthy
|
||||||
push:
|
push:
|
||||||
|
|||||||
3
.github/workflows/master.yml
vendored
3
.github/workflows/master.yml
vendored
@ -3,6 +3,9 @@ name: MasterCI
|
|||||||
env:
|
env:
|
||||||
# Force the stdout and stderr streams to be unbuffered
|
# Force the stdout and stderr streams to be unbuffered
|
||||||
PYTHONUNBUFFERED: 1
|
PYTHONUNBUFFERED: 1
|
||||||
|
# Export system tables to ClickHouse Cloud
|
||||||
|
CLICKHOUSE_CI_LOGS_HOST: ${{ secrets.CLICKHOUSE_CI_LOGS_HOST }}
|
||||||
|
CLICKHOUSE_CI_LOGS_PASSWORD: ${{ secrets.CLICKHOUSE_CI_LOGS_PASSWORD }}
|
||||||
|
|
||||||
on: # yamllint disable-line rule:truthy
|
on: # yamllint disable-line rule:truthy
|
||||||
push:
|
push:
|
||||||
|
|||||||
3
.github/workflows/pull_request.yml
vendored
3
.github/workflows/pull_request.yml
vendored
@ -3,6 +3,9 @@ name: PullRequestCI
|
|||||||
env:
|
env:
|
||||||
# Force the stdout and stderr streams to be unbuffered
|
# Force the stdout and stderr streams to be unbuffered
|
||||||
PYTHONUNBUFFERED: 1
|
PYTHONUNBUFFERED: 1
|
||||||
|
# Export system tables to ClickHouse Cloud
|
||||||
|
CLICKHOUSE_CI_LOGS_HOST: ${{ secrets.CLICKHOUSE_CI_LOGS_HOST }}
|
||||||
|
CLICKHOUSE_CI_LOGS_PASSWORD: ${{ secrets.CLICKHOUSE_CI_LOGS_PASSWORD }}
|
||||||
|
|
||||||
on: # yamllint disable-line rule:truthy
|
on: # yamllint disable-line rule:truthy
|
||||||
pull_request:
|
pull_request:
|
||||||
|
|||||||
3
.github/workflows/release_branches.yml
vendored
3
.github/workflows/release_branches.yml
vendored
@ -3,6 +3,9 @@ name: ReleaseBranchCI
|
|||||||
env:
|
env:
|
||||||
# Force the stdout and stderr streams to be unbuffered
|
# Force the stdout and stderr streams to be unbuffered
|
||||||
PYTHONUNBUFFERED: 1
|
PYTHONUNBUFFERED: 1
|
||||||
|
# Export system tables to ClickHouse Cloud
|
||||||
|
CLICKHOUSE_CI_LOGS_HOST: ${{ secrets.CLICKHOUSE_CI_LOGS_HOST }}
|
||||||
|
CLICKHOUSE_CI_LOGS_PASSWORD: ${{ secrets.CLICKHOUSE_CI_LOGS_PASSWORD }}
|
||||||
|
|
||||||
on: # yamllint disable-line rule:truthy
|
on: # yamllint disable-line rule:truthy
|
||||||
push:
|
push:
|
||||||
|
|||||||
4
.gitmodules
vendored
4
.gitmodules
vendored
@ -331,6 +331,10 @@
|
|||||||
[submodule "contrib/liburing"]
|
[submodule "contrib/liburing"]
|
||||||
path = contrib/liburing
|
path = contrib/liburing
|
||||||
url = https://github.com/axboe/liburing
|
url = https://github.com/axboe/liburing
|
||||||
|
[submodule "contrib/libarchive"]
|
||||||
|
path = contrib/libarchive
|
||||||
|
url = https://github.com/libarchive/libarchive.git
|
||||||
|
ignore = dirty
|
||||||
[submodule "contrib/libfiu"]
|
[submodule "contrib/libfiu"]
|
||||||
path = contrib/libfiu
|
path = contrib/libfiu
|
||||||
url = https://github.com/ClickHouse/libfiu.git
|
url = https://github.com/ClickHouse/libfiu.git
|
||||||
|
|||||||
@ -52,7 +52,6 @@
|
|||||||
* Add new setting `disable_url_encoding` that allows to disable decoding/encoding path in uri in URL engine. [#52337](https://github.com/ClickHouse/ClickHouse/pull/52337) ([Kruglov Pavel](https://github.com/Avogar)).
|
* Add new setting `disable_url_encoding` that allows to disable decoding/encoding path in uri in URL engine. [#52337](https://github.com/ClickHouse/ClickHouse/pull/52337) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||||
|
|
||||||
#### Performance Improvement
|
#### Performance Improvement
|
||||||
* Writing parquet files is 10x faster, it's multi-threaded now. Almost the same speed as reading. [#49367](https://github.com/ClickHouse/ClickHouse/pull/49367) ([Michael Kolupaev](https://github.com/al13n321)).
|
|
||||||
* Enable automatic selection of the sparse serialization format by default. It improves performance. The format is supported since version 22.1. After this change, downgrading to versions older than 22.1 might not be possible. You can turn off the usage of the sparse serialization format by providing the `ratio_of_defaults_for_sparse_serialization = 1` setting for your MergeTree tables. [#49631](https://github.com/ClickHouse/ClickHouse/pull/49631) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
* Enable automatic selection of the sparse serialization format by default. It improves performance. The format is supported since version 22.1. After this change, downgrading to versions older than 22.1 might not be possible. You can turn off the usage of the sparse serialization format by providing the `ratio_of_defaults_for_sparse_serialization = 1` setting for your MergeTree tables. [#49631](https://github.com/ClickHouse/ClickHouse/pull/49631) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||||
* Enable `move_all_conditions_to_prewhere` and `enable_multiple_prewhere_read_steps` settings by default. [#46365](https://github.com/ClickHouse/ClickHouse/pull/46365) ([Alexander Gololobov](https://github.com/davenger)).
|
* Enable `move_all_conditions_to_prewhere` and `enable_multiple_prewhere_read_steps` settings by default. [#46365](https://github.com/ClickHouse/ClickHouse/pull/46365) ([Alexander Gololobov](https://github.com/davenger)).
|
||||||
* Improves performance of some queries by tuning allocator. [#46416](https://github.com/ClickHouse/ClickHouse/pull/46416) ([Azat Khuzhin](https://github.com/azat)).
|
* Improves performance of some queries by tuning allocator. [#46416](https://github.com/ClickHouse/ClickHouse/pull/46416) ([Azat Khuzhin](https://github.com/azat)).
|
||||||
@ -114,6 +113,7 @@
|
|||||||
* Now interserver port will be closed only after tables are shut down. [#52498](https://github.com/ClickHouse/ClickHouse/pull/52498) ([alesapin](https://github.com/alesapin)).
|
* Now interserver port will be closed only after tables are shut down. [#52498](https://github.com/ClickHouse/ClickHouse/pull/52498) ([alesapin](https://github.com/alesapin)).
|
||||||
|
|
||||||
#### Experimental Feature
|
#### Experimental Feature
|
||||||
|
* Writing parquet files is 10x faster, it's multi-threaded now. Almost the same speed as reading. [#49367](https://github.com/ClickHouse/ClickHouse/pull/49367) ([Michael Kolupaev](https://github.com/al13n321)). This is controlled by the setting `output_format_parquet_use_custom_encoder` which is disabled by default, because the feature is non-ideal.
|
||||||
* Added support for [PRQL](https://prql-lang.org/) as a query language. [#50686](https://github.com/ClickHouse/ClickHouse/pull/50686) ([János Benjamin Antal](https://github.com/antaljanosbenjamin)).
|
* Added support for [PRQL](https://prql-lang.org/) as a query language. [#50686](https://github.com/ClickHouse/ClickHouse/pull/50686) ([János Benjamin Antal](https://github.com/antaljanosbenjamin)).
|
||||||
* Allow to add disk name for custom disks. Previously custom disks would use an internal generated disk name. Now it will be possible with `disk = disk_<name>(...)` (e.g. disk will have name `name`) . [#51552](https://github.com/ClickHouse/ClickHouse/pull/51552) ([Kseniia Sumarokova](https://github.com/kssenii)). This syntax can be changed in this release.
|
* Allow to add disk name for custom disks. Previously custom disks would use an internal generated disk name. Now it will be possible with `disk = disk_<name>(...)` (e.g. disk will have name `name`) . [#51552](https://github.com/ClickHouse/ClickHouse/pull/51552) ([Kseniia Sumarokova](https://github.com/kssenii)). This syntax can be changed in this release.
|
||||||
* (experimental MaterializedMySQL) Fixed crash when `mysqlxx::Pool::Entry` is used after it was disconnected. [#52063](https://github.com/ClickHouse/ClickHouse/pull/52063) ([Val Doroshchuk](https://github.com/valbok)).
|
* (experimental MaterializedMySQL) Fixed crash when `mysqlxx::Pool::Entry` is used after it was disconnected. [#52063](https://github.com/ClickHouse/ClickHouse/pull/52063) ([Val Doroshchuk](https://github.com/valbok)).
|
||||||
|
|||||||
@ -23,11 +23,8 @@ curl https://clickhouse.com/ | sh
|
|||||||
|
|
||||||
## Upcoming Events
|
## Upcoming Events
|
||||||
|
|
||||||
* [**v23.7 Release Webinar**](https://clickhouse.com/company/events/v23-7-community-release-call?utm_source=github&utm_medium=social&utm_campaign=release-webinar-2023-07) - Jul 27 - 23.7 is rapidly approaching. Original creator, co-founder, and CTO of ClickHouse Alexey Milovidov will walk us through the highlights of the release.
|
* [**v23.8 Community Call**](https://clickhouse.com/company/events/v23-8-community-release-call?utm_source=github&utm_medium=social&utm_campaign=release-webinar-2023-08) - Aug 31 - 23.8 is rapidly approaching. Original creator, co-founder, and CTO of ClickHouse Alexey Milovidov will walk us through the highlights of the release.
|
||||||
* [**ClickHouse Meetup in Boston**](https://www.meetup.com/clickhouse-boston-user-group/events/293913596) - Jul 18
|
* [**ClickHouse & AI - A Meetup in San Francisco**](https://www.meetup.com/clickhouse-silicon-valley-meetup-group/events/294472987) - Aug 8
|
||||||
* [**ClickHouse Meetup in NYC**](https://www.meetup.com/clickhouse-new-york-user-group/events/293913441) - Jul 19
|
|
||||||
* [**ClickHouse Meetup in Toronto**](https://www.meetup.com/clickhouse-toronto-user-group/events/294183127) - Jul 20
|
|
||||||
* [**ClickHouse Meetup in Singapore**](https://www.meetup.com/clickhouse-singapore-meetup-group/events/294428050/) - Jul 27
|
|
||||||
* [**ClickHouse Meetup in Paris**](https://www.meetup.com/clickhouse-france-user-group/events/294283460) - Sep 12
|
* [**ClickHouse Meetup in Paris**](https://www.meetup.com/clickhouse-france-user-group/events/294283460) - Sep 12
|
||||||
|
|
||||||
Also, keep an eye out for upcoming meetups around the world. Somewhere else you want us to be? Please feel free to reach out to tyler <at> clickhouse <dot> com.
|
Also, keep an eye out for upcoming meetups around the world. Somewhere else you want us to be? Please feel free to reach out to tyler <at> clickhouse <dot> com.
|
||||||
|
|||||||
@ -8,6 +8,7 @@
|
|||||||
#include <functional>
|
#include <functional>
|
||||||
#include <iosfwd>
|
#include <iosfwd>
|
||||||
|
|
||||||
|
#include <base/defines.h>
|
||||||
#include <base/types.h>
|
#include <base/types.h>
|
||||||
#include <base/unaligned.h>
|
#include <base/unaligned.h>
|
||||||
|
|
||||||
@ -274,6 +275,8 @@ struct CRC32Hash
|
|||||||
if (size == 0)
|
if (size == 0)
|
||||||
return 0;
|
return 0;
|
||||||
|
|
||||||
|
chassert(pos);
|
||||||
|
|
||||||
if (size < 8)
|
if (size < 8)
|
||||||
{
|
{
|
||||||
return static_cast<unsigned>(hashLessThan8(x.data, x.size));
|
return static_cast<unsigned>(hashLessThan8(x.data, x.size));
|
||||||
|
|||||||
@ -115,8 +115,15 @@
|
|||||||
/// because SIGABRT is easier to debug than SIGTRAP (the second one makes gdb crazy)
|
/// because SIGABRT is easier to debug than SIGTRAP (the second one makes gdb crazy)
|
||||||
#if !defined(chassert)
|
#if !defined(chassert)
|
||||||
#if defined(ABORT_ON_LOGICAL_ERROR)
|
#if defined(ABORT_ON_LOGICAL_ERROR)
|
||||||
|
// clang-format off
|
||||||
|
#include <base/types.h>
|
||||||
|
namespace DB
|
||||||
|
{
|
||||||
|
void abortOnFailedAssertion(const String & description);
|
||||||
|
}
|
||||||
#define chassert(x) static_cast<bool>(x) ? void(0) : ::DB::abortOnFailedAssertion(#x)
|
#define chassert(x) static_cast<bool>(x) ? void(0) : ::DB::abortOnFailedAssertion(#x)
|
||||||
#define UNREACHABLE() abort()
|
#define UNREACHABLE() abort()
|
||||||
|
// clang-format off
|
||||||
#else
|
#else
|
||||||
/// Here sizeof() trick is used to suppress unused warning for result,
|
/// Here sizeof() trick is used to suppress unused warning for result,
|
||||||
/// since simple "(void)x" will evaluate the expression, while
|
/// since simple "(void)x" will evaluate the expression, while
|
||||||
|
|||||||
@ -57,7 +57,7 @@ public:
|
|||||||
URI();
|
URI();
|
||||||
/// Creates an empty URI.
|
/// Creates an empty URI.
|
||||||
|
|
||||||
explicit URI(const std::string & uri, bool disable_url_encoding = false);
|
explicit URI(const std::string & uri, bool enable_url_encoding = true);
|
||||||
/// Parses an URI from the given string. Throws a
|
/// Parses an URI from the given string. Throws a
|
||||||
/// SyntaxException if the uri is not valid.
|
/// SyntaxException if the uri is not valid.
|
||||||
|
|
||||||
@ -362,7 +362,7 @@ private:
|
|||||||
std::string _query;
|
std::string _query;
|
||||||
std::string _fragment;
|
std::string _fragment;
|
||||||
|
|
||||||
bool _disable_url_encoding = false;
|
bool _enable_url_encoding = true;
|
||||||
};
|
};
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -36,8 +36,8 @@ URI::URI():
|
|||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
URI::URI(const std::string& uri, bool decode_and_encode_path):
|
URI::URI(const std::string& uri, bool enable_url_encoding):
|
||||||
_port(0), _disable_url_encoding(decode_and_encode_path)
|
_port(0), _enable_url_encoding(enable_url_encoding)
|
||||||
{
|
{
|
||||||
parse(uri);
|
parse(uri);
|
||||||
}
|
}
|
||||||
@ -108,7 +108,7 @@ URI::URI(const URI& uri):
|
|||||||
_path(uri._path),
|
_path(uri._path),
|
||||||
_query(uri._query),
|
_query(uri._query),
|
||||||
_fragment(uri._fragment),
|
_fragment(uri._fragment),
|
||||||
_disable_url_encoding(uri._disable_url_encoding)
|
_enable_url_encoding(uri._enable_url_encoding)
|
||||||
{
|
{
|
||||||
}
|
}
|
||||||
|
|
||||||
@ -121,7 +121,7 @@ URI::URI(const URI& baseURI, const std::string& relativeURI):
|
|||||||
_path(baseURI._path),
|
_path(baseURI._path),
|
||||||
_query(baseURI._query),
|
_query(baseURI._query),
|
||||||
_fragment(baseURI._fragment),
|
_fragment(baseURI._fragment),
|
||||||
_disable_url_encoding(baseURI._disable_url_encoding)
|
_enable_url_encoding(baseURI._enable_url_encoding)
|
||||||
{
|
{
|
||||||
resolve(relativeURI);
|
resolve(relativeURI);
|
||||||
}
|
}
|
||||||
@ -153,7 +153,7 @@ URI& URI::operator = (const URI& uri)
|
|||||||
_path = uri._path;
|
_path = uri._path;
|
||||||
_query = uri._query;
|
_query = uri._query;
|
||||||
_fragment = uri._fragment;
|
_fragment = uri._fragment;
|
||||||
_disable_url_encoding = uri._disable_url_encoding;
|
_enable_url_encoding = uri._enable_url_encoding;
|
||||||
}
|
}
|
||||||
return *this;
|
return *this;
|
||||||
}
|
}
|
||||||
@ -184,7 +184,7 @@ void URI::swap(URI& uri)
|
|||||||
std::swap(_path, uri._path);
|
std::swap(_path, uri._path);
|
||||||
std::swap(_query, uri._query);
|
std::swap(_query, uri._query);
|
||||||
std::swap(_fragment, uri._fragment);
|
std::swap(_fragment, uri._fragment);
|
||||||
std::swap(_disable_url_encoding, uri._disable_url_encoding);
|
std::swap(_enable_url_encoding, uri._enable_url_encoding);
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
@ -687,18 +687,18 @@ void URI::decode(const std::string& str, std::string& decodedStr, bool plusAsSpa
|
|||||||
|
|
||||||
void URI::encodePath(std::string & encodedStr) const
|
void URI::encodePath(std::string & encodedStr) const
|
||||||
{
|
{
|
||||||
if (_disable_url_encoding)
|
if (_enable_url_encoding)
|
||||||
encodedStr = _path;
|
|
||||||
else
|
|
||||||
encode(_path, RESERVED_PATH, encodedStr);
|
encode(_path, RESERVED_PATH, encodedStr);
|
||||||
|
else
|
||||||
|
encodedStr = _path;
|
||||||
}
|
}
|
||||||
|
|
||||||
void URI::decodePath(const std::string & encodedStr)
|
void URI::decodePath(const std::string & encodedStr)
|
||||||
{
|
{
|
||||||
if (_disable_url_encoding)
|
if (_enable_url_encoding)
|
||||||
_path = encodedStr;
|
|
||||||
else
|
|
||||||
decode(encodedStr, _path);
|
decode(encodedStr, _path);
|
||||||
|
else
|
||||||
|
_path = encodedStr;
|
||||||
}
|
}
|
||||||
|
|
||||||
bool URI::isWellKnownPort() const
|
bool URI::isWellKnownPort() const
|
||||||
|
|||||||
1
contrib/CMakeLists.txt
vendored
1
contrib/CMakeLists.txt
vendored
@ -92,6 +92,7 @@ add_contrib (google-protobuf-cmake google-protobuf)
|
|||||||
add_contrib (openldap-cmake openldap)
|
add_contrib (openldap-cmake openldap)
|
||||||
add_contrib (grpc-cmake grpc)
|
add_contrib (grpc-cmake grpc)
|
||||||
add_contrib (msgpack-c-cmake msgpack-c)
|
add_contrib (msgpack-c-cmake msgpack-c)
|
||||||
|
add_contrib (libarchive-cmake libarchive)
|
||||||
|
|
||||||
add_contrib (corrosion-cmake corrosion)
|
add_contrib (corrosion-cmake corrosion)
|
||||||
|
|
||||||
|
|||||||
1
contrib/libarchive
vendored
Submodule
1
contrib/libarchive
vendored
Submodule
@ -0,0 +1 @@
|
|||||||
|
Subproject commit ee45796171324519f0c0bfd012018dd099296336
|
||||||
172
contrib/libarchive-cmake/CMakeLists.txt
Normal file
172
contrib/libarchive-cmake/CMakeLists.txt
Normal file
@ -0,0 +1,172 @@
|
|||||||
|
set (LIBRARY_DIR "${ClickHouse_SOURCE_DIR}/contrib/libarchive")
|
||||||
|
|
||||||
|
set(SRCS
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_acl.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_blake2sp_ref.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_blake2s_ref.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_check_magic.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_cmdline.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_cryptor.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_digest.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_disk_acl_darwin.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_disk_acl_freebsd.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_disk_acl_linux.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_disk_acl_sunos.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_entry.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_entry_copy_bhfi.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_entry_copy_stat.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_entry_link_resolver.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_entry_sparse.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_entry_stat.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_entry_strmode.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_entry_xattr.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_getdate.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_hmac.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_match.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_options.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_pack_dev.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_pathmatch.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_ppmd7.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_ppmd8.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_random.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_rb.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_add_passphrase.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_append_filter.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_data_into_fd.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_disk_entry_from_file.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_disk_posix.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_disk_set_standard_lookup.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_disk_windows.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_extract2.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_extract.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_open_fd.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_open_file.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_open_filename.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_open_memory.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_set_format.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_set_options.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_all.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_by_code.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_bzip2.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_compress.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_grzip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_gzip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_lrzip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_lz4.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_lzop.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_none.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_program.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_rpm.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_uu.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_xz.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_filter_zstd.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_7zip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_all.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_ar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_by_code.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_cab.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_cpio.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_empty.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_iso9660.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_lha.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_mtree.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_rar5.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_rar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_raw.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_tar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_warc.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_xar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_read_support_format_zip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_string.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_string_sprintf.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_util.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_version_details.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_virtual.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_windows.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_b64encode.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_by_name.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_bzip2.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_compress.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_grzip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_gzip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_lrzip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_lz4.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_lzop.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_none.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_program.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_uuencode.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_xz.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_add_filter_zstd.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_disk_posix.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_disk_set_standard_lookup.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_disk_windows.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_open_fd.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_open_file.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_open_filename.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_open_memory.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_7zip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_ar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_by_name.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_cpio_binary.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_cpio.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_cpio_newc.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_cpio_odc.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_filter_by_ext.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_gnutar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_iso9660.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_mtree.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_pax.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_raw.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_shar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_ustar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_v7tar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_warc.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_xar.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_format_zip.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_options.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/archive_write_set_passphrase.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/filter_fork_posix.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/filter_fork_windows.c"
|
||||||
|
"${LIBRARY_DIR}/libarchive/xxhash.c"
|
||||||
|
)
|
||||||
|
|
||||||
|
add_library(_libarchive ${SRCS})
|
||||||
|
target_include_directories(_libarchive PUBLIC
|
||||||
|
${CMAKE_CURRENT_SOURCE_DIR}
|
||||||
|
"${LIBRARY_DIR}/libarchive"
|
||||||
|
)
|
||||||
|
|
||||||
|
target_compile_definitions(_libarchive PUBLIC
|
||||||
|
HAVE_CONFIG_H
|
||||||
|
)
|
||||||
|
|
||||||
|
target_compile_options(_libarchive PRIVATE "-Wno-reserved-macro-identifier")
|
||||||
|
|
||||||
|
if (TARGET ch_contrib::xz)
|
||||||
|
target_compile_definitions(_libarchive PUBLIC HAVE_LZMA_H=1)
|
||||||
|
target_link_libraries(_libarchive PRIVATE ch_contrib::xz)
|
||||||
|
endif()
|
||||||
|
|
||||||
|
if (TARGET ch_contrib::zlib)
|
||||||
|
target_compile_definitions(_libarchive PUBLIC HAVE_ZLIB_H=1)
|
||||||
|
target_link_libraries(_libarchive PRIVATE ch_contrib::zlib)
|
||||||
|
endif()
|
||||||
|
|
||||||
|
if (OS_LINUX)
|
||||||
|
target_compile_definitions(
|
||||||
|
_libarchive PUBLIC
|
||||||
|
MAJOR_IN_SYSMACROS=1
|
||||||
|
HAVE_LINUX_FS_H=1
|
||||||
|
HAVE_STRUCT_STAT_ST_MTIM_TV_NSEC=1
|
||||||
|
HAVE_LINUX_TYPES_H=1
|
||||||
|
HAVE_SYS_STATFS_H=1
|
||||||
|
HAVE_FUTIMESAT=1
|
||||||
|
HAVE_ICONV=1
|
||||||
|
)
|
||||||
|
endif()
|
||||||
|
|
||||||
|
add_library(ch_contrib::libarchive ALIAS _libarchive)
|
||||||
1391
contrib/libarchive-cmake/config.h
Normal file
1391
contrib/libarchive-cmake/config.h
Normal file
File diff suppressed because it is too large
Load Diff
@ -17,7 +17,8 @@
|
|||||||
#ifndef METROHASH_PLATFORM_H
|
#ifndef METROHASH_PLATFORM_H
|
||||||
#define METROHASH_PLATFORM_H
|
#define METROHASH_PLATFORM_H
|
||||||
|
|
||||||
#include <stdint.h>
|
#include <bit>
|
||||||
|
#include <cstdint>
|
||||||
#include <cstring>
|
#include <cstring>
|
||||||
|
|
||||||
// rotate right idiom recognized by most compilers
|
// rotate right idiom recognized by most compilers
|
||||||
@ -33,6 +34,11 @@ inline static uint64_t read_u64(const void * const ptr)
|
|||||||
// so we use memcpy() which is the most portable. clang & gcc usually translates `memcpy()` into a single `load` instruction
|
// so we use memcpy() which is the most portable. clang & gcc usually translates `memcpy()` into a single `load` instruction
|
||||||
// when hardware supports it, so using memcpy() is efficient too.
|
// when hardware supports it, so using memcpy() is efficient too.
|
||||||
memcpy(&result, ptr, sizeof(result));
|
memcpy(&result, ptr, sizeof(result));
|
||||||
|
|
||||||
|
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||||
|
result = std::byteswap(result);
|
||||||
|
#endif
|
||||||
|
|
||||||
return result;
|
return result;
|
||||||
}
|
}
|
||||||
|
|
||||||
@ -40,6 +46,11 @@ inline static uint64_t read_u32(const void * const ptr)
|
|||||||
{
|
{
|
||||||
uint32_t result;
|
uint32_t result;
|
||||||
memcpy(&result, ptr, sizeof(result));
|
memcpy(&result, ptr, sizeof(result));
|
||||||
|
|
||||||
|
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||||
|
result = std::byteswap(result);
|
||||||
|
#endif
|
||||||
|
|
||||||
return result;
|
return result;
|
||||||
}
|
}
|
||||||
|
|
||||||
@ -47,6 +58,11 @@ inline static uint64_t read_u16(const void * const ptr)
|
|||||||
{
|
{
|
||||||
uint16_t result;
|
uint16_t result;
|
||||||
memcpy(&result, ptr, sizeof(result));
|
memcpy(&result, ptr, sizeof(result));
|
||||||
|
|
||||||
|
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||||
|
result = std::byteswap(result);
|
||||||
|
#endif
|
||||||
|
|
||||||
return result;
|
return result;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@ -161,5 +161,9 @@
|
|||||||
"docker/test/sqllogic": {
|
"docker/test/sqllogic": {
|
||||||
"name": "clickhouse/sqllogic-test",
|
"name": "clickhouse/sqllogic-test",
|
||||||
"dependent": []
|
"dependent": []
|
||||||
|
},
|
||||||
|
"docker/test/integration/nginx_dav": {
|
||||||
|
"name": "clickhouse/nginx-dav",
|
||||||
|
"dependent": []
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
@ -32,7 +32,7 @@ RUN arch=${TARGETARCH:-amd64} \
|
|||||||
esac
|
esac
|
||||||
|
|
||||||
ARG REPOSITORY="https://s3.amazonaws.com/clickhouse-builds/22.4/31c367d3cd3aefd316778601ff6565119fe36682/package_release"
|
ARG REPOSITORY="https://s3.amazonaws.com/clickhouse-builds/22.4/31c367d3cd3aefd316778601ff6565119fe36682/package_release"
|
||||||
ARG VERSION="23.7.1.2470"
|
ARG VERSION="23.7.4.5"
|
||||||
ARG PACKAGES="clickhouse-keeper"
|
ARG PACKAGES="clickhouse-keeper"
|
||||||
|
|
||||||
# user/group precreated explicitly with fixed uid/gid on purpose.
|
# user/group precreated explicitly with fixed uid/gid on purpose.
|
||||||
|
|||||||
@ -6,7 +6,7 @@ Usage:
|
|||||||
Build deb package with `clang-14` in `debug` mode:
|
Build deb package with `clang-14` in `debug` mode:
|
||||||
```
|
```
|
||||||
$ mkdir deb/test_output
|
$ mkdir deb/test_output
|
||||||
$ ./packager --output-dir deb/test_output/ --package-type deb --compiler=clang-14 --build-type=debug
|
$ ./packager --output-dir deb/test_output/ --package-type deb --compiler=clang-14 --debug-build
|
||||||
$ ls -l deb/test_output
|
$ ls -l deb/test_output
|
||||||
-rw-r--r-- 1 root root 3730 clickhouse-client_22.2.2+debug_all.deb
|
-rw-r--r-- 1 root root 3730 clickhouse-client_22.2.2+debug_all.deb
|
||||||
-rw-r--r-- 1 root root 84221888 clickhouse-common-static_22.2.2+debug_amd64.deb
|
-rw-r--r-- 1 root root 84221888 clickhouse-common-static_22.2.2+debug_amd64.deb
|
||||||
|
|||||||
@ -22,7 +22,7 @@ def check_image_exists_locally(image_name: str) -> bool:
|
|||||||
output = subprocess.check_output(
|
output = subprocess.check_output(
|
||||||
f"docker images -q {image_name} 2> /dev/null", shell=True
|
f"docker images -q {image_name} 2> /dev/null", shell=True
|
||||||
)
|
)
|
||||||
return output != ""
|
return output != b""
|
||||||
except subprocess.CalledProcessError:
|
except subprocess.CalledProcessError:
|
||||||
return False
|
return False
|
||||||
|
|
||||||
@ -46,7 +46,7 @@ def build_image(image_name: str, filepath: Path) -> None:
|
|||||||
)
|
)
|
||||||
|
|
||||||
|
|
||||||
def pre_build(repo_path: Path, env_variables: List[str]):
|
def pre_build(repo_path: Path, env_variables: List[str]) -> None:
|
||||||
if "WITH_PERFORMANCE=1" in env_variables:
|
if "WITH_PERFORMANCE=1" in env_variables:
|
||||||
current_branch = subprocess.check_output(
|
current_branch = subprocess.check_output(
|
||||||
"git branch --show-current", shell=True, encoding="utf-8"
|
"git branch --show-current", shell=True, encoding="utf-8"
|
||||||
@ -81,8 +81,9 @@ def run_docker_image_with_env(
|
|||||||
env_variables: List[str],
|
env_variables: List[str],
|
||||||
ch_root: Path,
|
ch_root: Path,
|
||||||
ccache_dir: Optional[Path],
|
ccache_dir: Optional[Path],
|
||||||
):
|
) -> None:
|
||||||
output_dir.mkdir(parents=True, exist_ok=True)
|
output_dir.mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
env_part = " -e ".join(env_variables)
|
env_part = " -e ".join(env_variables)
|
||||||
if env_part:
|
if env_part:
|
||||||
env_part = " -e " + env_part
|
env_part = " -e " + env_part
|
||||||
@ -112,12 +113,12 @@ def run_docker_image_with_env(
|
|||||||
subprocess.check_call(cmd, shell=True)
|
subprocess.check_call(cmd, shell=True)
|
||||||
|
|
||||||
|
|
||||||
def is_release_build(build_type: str, package_type: str, sanitizer: str) -> bool:
|
def is_release_build(debug_build: bool, package_type: str, sanitizer: str) -> bool:
|
||||||
return build_type == "" and package_type == "deb" and sanitizer == ""
|
return not debug_build and package_type == "deb" and sanitizer == ""
|
||||||
|
|
||||||
|
|
||||||
def parse_env_variables(
|
def parse_env_variables(
|
||||||
build_type: str,
|
debug_build: bool,
|
||||||
compiler: str,
|
compiler: str,
|
||||||
sanitizer: str,
|
sanitizer: str,
|
||||||
package_type: str,
|
package_type: str,
|
||||||
@ -129,9 +130,10 @@ def parse_env_variables(
|
|||||||
version: str,
|
version: str,
|
||||||
official: bool,
|
official: bool,
|
||||||
additional_pkgs: bool,
|
additional_pkgs: bool,
|
||||||
|
with_profiler: bool,
|
||||||
with_coverage: bool,
|
with_coverage: bool,
|
||||||
with_binaries: str,
|
with_binaries: str,
|
||||||
):
|
) -> List[str]:
|
||||||
DARWIN_SUFFIX = "-darwin"
|
DARWIN_SUFFIX = "-darwin"
|
||||||
DARWIN_ARM_SUFFIX = "-darwin-aarch64"
|
DARWIN_ARM_SUFFIX = "-darwin-aarch64"
|
||||||
ARM_SUFFIX = "-aarch64"
|
ARM_SUFFIX = "-aarch64"
|
||||||
@ -240,7 +242,7 @@ def parse_env_variables(
|
|||||||
build_target = (
|
build_target = (
|
||||||
f"{build_target} clickhouse-odbc-bridge clickhouse-library-bridge"
|
f"{build_target} clickhouse-odbc-bridge clickhouse-library-bridge"
|
||||||
)
|
)
|
||||||
if is_release_build(build_type, package_type, sanitizer):
|
if is_release_build(debug_build, package_type, sanitizer):
|
||||||
cmake_flags.append("-DSPLIT_DEBUG_SYMBOLS=ON")
|
cmake_flags.append("-DSPLIT_DEBUG_SYMBOLS=ON")
|
||||||
result.append("WITH_PERFORMANCE=1")
|
result.append("WITH_PERFORMANCE=1")
|
||||||
if is_cross_arm:
|
if is_cross_arm:
|
||||||
@ -255,8 +257,8 @@ def parse_env_variables(
|
|||||||
|
|
||||||
if sanitizer:
|
if sanitizer:
|
||||||
result.append(f"SANITIZER={sanitizer}")
|
result.append(f"SANITIZER={sanitizer}")
|
||||||
if build_type:
|
if debug_build:
|
||||||
result.append(f"BUILD_TYPE={build_type.capitalize()}")
|
result.append("BUILD_TYPE=Debug")
|
||||||
else:
|
else:
|
||||||
result.append("BUILD_TYPE=None")
|
result.append("BUILD_TYPE=None")
|
||||||
|
|
||||||
@ -322,6 +324,9 @@ def parse_env_variables(
|
|||||||
# utils are not included into clickhouse-bundle, so build everything
|
# utils are not included into clickhouse-bundle, so build everything
|
||||||
build_target = "all"
|
build_target = "all"
|
||||||
|
|
||||||
|
if with_profiler:
|
||||||
|
cmake_flags.append("-DENABLE_BUILD_PROFILING=1")
|
||||||
|
|
||||||
if with_coverage:
|
if with_coverage:
|
||||||
cmake_flags.append("-DWITH_COVERAGE=1")
|
cmake_flags.append("-DWITH_COVERAGE=1")
|
||||||
|
|
||||||
@ -361,7 +366,7 @@ def parse_args() -> argparse.Namespace:
|
|||||||
help="ClickHouse git repository",
|
help="ClickHouse git repository",
|
||||||
)
|
)
|
||||||
parser.add_argument("--output-dir", type=dir_name, required=True)
|
parser.add_argument("--output-dir", type=dir_name, required=True)
|
||||||
parser.add_argument("--build-type", choices=("debug", ""), default="")
|
parser.add_argument("--debug-build", action="store_true")
|
||||||
|
|
||||||
parser.add_argument(
|
parser.add_argument(
|
||||||
"--compiler",
|
"--compiler",
|
||||||
@ -416,6 +421,7 @@ def parse_args() -> argparse.Namespace:
|
|||||||
parser.add_argument("--version")
|
parser.add_argument("--version")
|
||||||
parser.add_argument("--official", action="store_true")
|
parser.add_argument("--official", action="store_true")
|
||||||
parser.add_argument("--additional-pkgs", action="store_true")
|
parser.add_argument("--additional-pkgs", action="store_true")
|
||||||
|
parser.add_argument("--with-profiler", action="store_true")
|
||||||
parser.add_argument("--with-coverage", action="store_true")
|
parser.add_argument("--with-coverage", action="store_true")
|
||||||
parser.add_argument(
|
parser.add_argument(
|
||||||
"--with-binaries", choices=("programs", "tests", ""), default=""
|
"--with-binaries", choices=("programs", "tests", ""), default=""
|
||||||
@ -451,7 +457,7 @@ def parse_args() -> argparse.Namespace:
|
|||||||
return args
|
return args
|
||||||
|
|
||||||
|
|
||||||
def main():
|
def main() -> None:
|
||||||
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(message)s")
|
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(message)s")
|
||||||
args = parse_args()
|
args = parse_args()
|
||||||
|
|
||||||
@ -467,7 +473,7 @@ def main():
|
|||||||
build_image(image_with_version, dockerfile)
|
build_image(image_with_version, dockerfile)
|
||||||
|
|
||||||
env_prepared = parse_env_variables(
|
env_prepared = parse_env_variables(
|
||||||
args.build_type,
|
args.debug_build,
|
||||||
args.compiler,
|
args.compiler,
|
||||||
args.sanitizer,
|
args.sanitizer,
|
||||||
args.package_type,
|
args.package_type,
|
||||||
@ -479,6 +485,7 @@ def main():
|
|||||||
args.version,
|
args.version,
|
||||||
args.official,
|
args.official,
|
||||||
args.additional_pkgs,
|
args.additional_pkgs,
|
||||||
|
args.with_profiler,
|
||||||
args.with_coverage,
|
args.with_coverage,
|
||||||
args.with_binaries,
|
args.with_binaries,
|
||||||
)
|
)
|
||||||
|
|||||||
@ -33,7 +33,7 @@ RUN arch=${TARGETARCH:-amd64} \
|
|||||||
# lts / testing / prestable / etc
|
# lts / testing / prestable / etc
|
||||||
ARG REPO_CHANNEL="stable"
|
ARG REPO_CHANNEL="stable"
|
||||||
ARG REPOSITORY="https://packages.clickhouse.com/tgz/${REPO_CHANNEL}"
|
ARG REPOSITORY="https://packages.clickhouse.com/tgz/${REPO_CHANNEL}"
|
||||||
ARG VERSION="23.7.1.2470"
|
ARG VERSION="23.7.4.5"
|
||||||
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
||||||
|
|
||||||
# user/group precreated explicitly with fixed uid/gid on purpose.
|
# user/group precreated explicitly with fixed uid/gid on purpose.
|
||||||
|
|||||||
@ -23,7 +23,7 @@ RUN sed -i "s|http://archive.ubuntu.com|${apt_archive}|g" /etc/apt/sources.list
|
|||||||
|
|
||||||
ARG REPO_CHANNEL="stable"
|
ARG REPO_CHANNEL="stable"
|
||||||
ARG REPOSITORY="deb [signed-by=/usr/share/keyrings/clickhouse-keyring.gpg] https://packages.clickhouse.com/deb ${REPO_CHANNEL} main"
|
ARG REPOSITORY="deb [signed-by=/usr/share/keyrings/clickhouse-keyring.gpg] https://packages.clickhouse.com/deb ${REPO_CHANNEL} main"
|
||||||
ARG VERSION="23.7.1.2470"
|
ARG VERSION="23.7.4.5"
|
||||||
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
||||||
|
|
||||||
# set non-empty deb_location_url url to create a docker image
|
# set non-empty deb_location_url url to create a docker image
|
||||||
|
|||||||
@ -19,13 +19,13 @@ RUN apt-get update \
|
|||||||
# and MEMORY_LIMIT_EXCEEDED exceptions in Functional tests (total memory limit in Functional tests is ~55.24 GiB).
|
# and MEMORY_LIMIT_EXCEEDED exceptions in Functional tests (total memory limit in Functional tests is ~55.24 GiB).
|
||||||
# TSAN will flush shadow memory when reaching this limit.
|
# TSAN will flush shadow memory when reaching this limit.
|
||||||
# It may cause false-negatives, but it's better than OOM.
|
# It may cause false-negatives, but it's better than OOM.
|
||||||
RUN echo "TSAN_OPTIONS='verbosity=1000 halt_on_error=1 history_size=7 memory_limit_mb=46080 second_deadlock_stack=1'" >> /etc/environment
|
RUN echo "TSAN_OPTIONS='verbosity=1000 halt_on_error=1 abort_on_error=1 history_size=7 memory_limit_mb=46080 second_deadlock_stack=1'" >> /etc/environment
|
||||||
RUN echo "UBSAN_OPTIONS='print_stacktrace=1'" >> /etc/environment
|
RUN echo "UBSAN_OPTIONS='print_stacktrace=1'" >> /etc/environment
|
||||||
RUN echo "MSAN_OPTIONS='abort_on_error=1 poison_in_dtor=1'" >> /etc/environment
|
RUN echo "MSAN_OPTIONS='abort_on_error=1 poison_in_dtor=1'" >> /etc/environment
|
||||||
RUN echo "LSAN_OPTIONS='suppressions=/usr/share/clickhouse-test/config/lsan_suppressions.txt'" >> /etc/environment
|
RUN echo "LSAN_OPTIONS='suppressions=/usr/share/clickhouse-test/config/lsan_suppressions.txt'" >> /etc/environment
|
||||||
# Sanitizer options for current shell (not current, but the one that will be spawned on "docker run")
|
# Sanitizer options for current shell (not current, but the one that will be spawned on "docker run")
|
||||||
# (but w/o verbosity for TSAN, otherwise test.reference will not match)
|
# (but w/o verbosity for TSAN, otherwise test.reference will not match)
|
||||||
ENV TSAN_OPTIONS='halt_on_error=1 history_size=7 memory_limit_mb=46080 second_deadlock_stack=1'
|
ENV TSAN_OPTIONS='halt_on_error=1 abort_on_error=1 history_size=7 memory_limit_mb=46080 second_deadlock_stack=1'
|
||||||
ENV UBSAN_OPTIONS='print_stacktrace=1'
|
ENV UBSAN_OPTIONS='print_stacktrace=1'
|
||||||
ENV MSAN_OPTIONS='abort_on_error=1 poison_in_dtor=1'
|
ENV MSAN_OPTIONS='abort_on_error=1 poison_in_dtor=1'
|
||||||
|
|
||||||
|
|||||||
6
docker/test/integration/nginx_dav/Dockerfile
Normal file
6
docker/test/integration/nginx_dav/Dockerfile
Normal file
@ -0,0 +1,6 @@
|
|||||||
|
FROM nginx:alpine-slim
|
||||||
|
|
||||||
|
COPY default.conf /etc/nginx/conf.d/
|
||||||
|
|
||||||
|
RUN mkdir /usr/share/nginx/files/ \
|
||||||
|
&& chown nginx: /usr/share/nginx/files/ -R
|
||||||
25
docker/test/integration/nginx_dav/default.conf
Normal file
25
docker/test/integration/nginx_dav/default.conf
Normal file
@ -0,0 +1,25 @@
|
|||||||
|
server {
|
||||||
|
listen 80;
|
||||||
|
|
||||||
|
#root /usr/share/nginx/test.com;
|
||||||
|
index index.html index.htm;
|
||||||
|
|
||||||
|
server_name test.com localhost;
|
||||||
|
|
||||||
|
location / {
|
||||||
|
expires max;
|
||||||
|
root /usr/share/nginx/files;
|
||||||
|
client_max_body_size 20m;
|
||||||
|
client_body_temp_path /usr/share/nginx/tmp;
|
||||||
|
dav_methods PUT; # Allowed methods, only PUT is necessary
|
||||||
|
|
||||||
|
create_full_put_path on; # nginx automatically creates nested directories
|
||||||
|
dav_access user:rw group:r all:r; # access permissions for files
|
||||||
|
|
||||||
|
limit_except GET {
|
||||||
|
allow all;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
error_page 405 =200 $uri;
|
||||||
|
}
|
||||||
@ -95,6 +95,7 @@ RUN python3 -m pip install --no-cache-dir \
|
|||||||
pytest-timeout \
|
pytest-timeout \
|
||||||
pytest-xdist \
|
pytest-xdist \
|
||||||
pytz \
|
pytz \
|
||||||
|
pyyaml==5.3.1 \
|
||||||
redis \
|
redis \
|
||||||
requests-kerberos \
|
requests-kerberos \
|
||||||
tzlocal==2.1 \
|
tzlocal==2.1 \
|
||||||
@ -129,7 +130,7 @@ COPY misc/ /misc/
|
|||||||
|
|
||||||
# Same options as in test/base/Dockerfile
|
# Same options as in test/base/Dockerfile
|
||||||
# (in case you need to override them in tests)
|
# (in case you need to override them in tests)
|
||||||
ENV TSAN_OPTIONS='halt_on_error=1 history_size=7 memory_limit_mb=46080 second_deadlock_stack=1'
|
ENV TSAN_OPTIONS='halt_on_error=1 abort_on_error=1 history_size=7 memory_limit_mb=46080 second_deadlock_stack=1'
|
||||||
ENV UBSAN_OPTIONS='print_stacktrace=1'
|
ENV UBSAN_OPTIONS='print_stacktrace=1'
|
||||||
ENV MSAN_OPTIONS='abort_on_error=1 poison_in_dtor=1'
|
ENV MSAN_OPTIONS='abort_on_error=1 poison_in_dtor=1'
|
||||||
|
|
||||||
|
|||||||
@ -12,3 +12,5 @@ services:
|
|||||||
- type: ${HDFS_FS:-tmpfs}
|
- type: ${HDFS_FS:-tmpfs}
|
||||||
source: ${HDFS_LOGS:-}
|
source: ${HDFS_LOGS:-}
|
||||||
target: /usr/local/hadoop/logs
|
target: /usr/local/hadoop/logs
|
||||||
|
sysctls:
|
||||||
|
net.ipv4.ip_local_port_range: '55000 65535'
|
||||||
|
|||||||
@ -31,6 +31,8 @@ services:
|
|||||||
- kafka_zookeeper
|
- kafka_zookeeper
|
||||||
security_opt:
|
security_opt:
|
||||||
- label:disable
|
- label:disable
|
||||||
|
sysctls:
|
||||||
|
net.ipv4.ip_local_port_range: '55000 65535'
|
||||||
|
|
||||||
schema-registry:
|
schema-registry:
|
||||||
image: confluentinc/cp-schema-registry:5.2.0
|
image: confluentinc/cp-schema-registry:5.2.0
|
||||||
|
|||||||
@ -20,6 +20,8 @@ services:
|
|||||||
depends_on:
|
depends_on:
|
||||||
- hdfskerberos
|
- hdfskerberos
|
||||||
entrypoint: /etc/bootstrap.sh -d
|
entrypoint: /etc/bootstrap.sh -d
|
||||||
|
sysctls:
|
||||||
|
net.ipv4.ip_local_port_range: '55000 65535'
|
||||||
|
|
||||||
hdfskerberos:
|
hdfskerberos:
|
||||||
image: clickhouse/kerberos-kdc:${DOCKER_KERBEROS_KDC_TAG:-latest}
|
image: clickhouse/kerberos-kdc:${DOCKER_KERBEROS_KDC_TAG:-latest}
|
||||||
@ -29,3 +31,5 @@ services:
|
|||||||
- ${KERBERIZED_HDFS_DIR}/../../kerberos_image_config.sh:/config.sh
|
- ${KERBERIZED_HDFS_DIR}/../../kerberos_image_config.sh:/config.sh
|
||||||
- /dev/urandom:/dev/random
|
- /dev/urandom:/dev/random
|
||||||
expose: [88, 749]
|
expose: [88, 749]
|
||||||
|
sysctls:
|
||||||
|
net.ipv4.ip_local_port_range: '55000 65535'
|
||||||
|
|||||||
@ -48,6 +48,8 @@ services:
|
|||||||
- kafka_kerberos
|
- kafka_kerberos
|
||||||
security_opt:
|
security_opt:
|
||||||
- label:disable
|
- label:disable
|
||||||
|
sysctls:
|
||||||
|
net.ipv4.ip_local_port_range: '55000 65535'
|
||||||
|
|
||||||
kafka_kerberos:
|
kafka_kerberos:
|
||||||
image: clickhouse/kerberos-kdc:${DOCKER_KERBEROS_KDC_TAG:-latest}
|
image: clickhouse/kerberos-kdc:${DOCKER_KERBEROS_KDC_TAG:-latest}
|
||||||
|
|||||||
@ -13,4 +13,3 @@ services:
|
|||||||
- ${MEILI_SECURE_EXTERNAL_PORT:-7700}:${MEILI_SECURE_INTERNAL_PORT:-7700}
|
- ${MEILI_SECURE_EXTERNAL_PORT:-7700}:${MEILI_SECURE_INTERNAL_PORT:-7700}
|
||||||
environment:
|
environment:
|
||||||
MEILI_MASTER_KEY: "password"
|
MEILI_MASTER_KEY: "password"
|
||||||
|
|
||||||
|
|||||||
@ -14,7 +14,7 @@ services:
|
|||||||
MINIO_ACCESS_KEY: minio
|
MINIO_ACCESS_KEY: minio
|
||||||
MINIO_SECRET_KEY: minio123
|
MINIO_SECRET_KEY: minio123
|
||||||
MINIO_PROMETHEUS_AUTH_TYPE: public
|
MINIO_PROMETHEUS_AUTH_TYPE: public
|
||||||
command: server --address :9001 --certs-dir /certs /data1-1
|
command: server --console-address 127.0.0.1:19001 --address :9001 --certs-dir /certs /data1-1
|
||||||
depends_on:
|
depends_on:
|
||||||
- proxy1
|
- proxy1
|
||||||
- proxy2
|
- proxy2
|
||||||
|
|||||||
@ -5,7 +5,7 @@ services:
|
|||||||
# Files will be put into /usr/share/nginx/files.
|
# Files will be put into /usr/share/nginx/files.
|
||||||
|
|
||||||
nginx:
|
nginx:
|
||||||
image: kssenii/nginx-test:1.1
|
image: clickhouse/nginx-dav:${DOCKER_NGINX_DAV_TAG:-latest}
|
||||||
restart: always
|
restart: always
|
||||||
ports:
|
ports:
|
||||||
- 80:80
|
- 80:80
|
||||||
|
|||||||
@ -12,9 +12,9 @@ services:
|
|||||||
timeout: 5s
|
timeout: 5s
|
||||||
retries: 5
|
retries: 5
|
||||||
networks:
|
networks:
|
||||||
default:
|
default:
|
||||||
aliases:
|
aliases:
|
||||||
- postgre-sql.local
|
- postgre-sql.local
|
||||||
environment:
|
environment:
|
||||||
POSTGRES_HOST_AUTH_METHOD: "trust"
|
POSTGRES_HOST_AUTH_METHOD: "trust"
|
||||||
POSTGRES_PASSWORD: mysecretpassword
|
POSTGRES_PASSWORD: mysecretpassword
|
||||||
|
|||||||
@ -12,7 +12,7 @@ services:
|
|||||||
command: ["zkServer.sh", "start-foreground"]
|
command: ["zkServer.sh", "start-foreground"]
|
||||||
entrypoint: /zookeeper-ssl-entrypoint.sh
|
entrypoint: /zookeeper-ssl-entrypoint.sh
|
||||||
volumes:
|
volumes:
|
||||||
- type: bind
|
- type: bind
|
||||||
source: /misc/zookeeper-ssl-entrypoint.sh
|
source: /misc/zookeeper-ssl-entrypoint.sh
|
||||||
target: /zookeeper-ssl-entrypoint.sh
|
target: /zookeeper-ssl-entrypoint.sh
|
||||||
- type: bind
|
- type: bind
|
||||||
@ -37,7 +37,7 @@ services:
|
|||||||
command: ["zkServer.sh", "start-foreground"]
|
command: ["zkServer.sh", "start-foreground"]
|
||||||
entrypoint: /zookeeper-ssl-entrypoint.sh
|
entrypoint: /zookeeper-ssl-entrypoint.sh
|
||||||
volumes:
|
volumes:
|
||||||
- type: bind
|
- type: bind
|
||||||
source: /misc/zookeeper-ssl-entrypoint.sh
|
source: /misc/zookeeper-ssl-entrypoint.sh
|
||||||
target: /zookeeper-ssl-entrypoint.sh
|
target: /zookeeper-ssl-entrypoint.sh
|
||||||
- type: bind
|
- type: bind
|
||||||
@ -61,7 +61,7 @@ services:
|
|||||||
command: ["zkServer.sh", "start-foreground"]
|
command: ["zkServer.sh", "start-foreground"]
|
||||||
entrypoint: /zookeeper-ssl-entrypoint.sh
|
entrypoint: /zookeeper-ssl-entrypoint.sh
|
||||||
volumes:
|
volumes:
|
||||||
- type: bind
|
- type: bind
|
||||||
source: /misc/zookeeper-ssl-entrypoint.sh
|
source: /misc/zookeeper-ssl-entrypoint.sh
|
||||||
target: /zookeeper-ssl-entrypoint.sh
|
target: /zookeeper-ssl-entrypoint.sh
|
||||||
- type: bind
|
- type: bind
|
||||||
|
|||||||
@ -64,15 +64,16 @@ export CLICKHOUSE_ODBC_BRIDGE_BINARY_PATH=/clickhouse-odbc-bridge
|
|||||||
export CLICKHOUSE_LIBRARY_BRIDGE_BINARY_PATH=/clickhouse-library-bridge
|
export CLICKHOUSE_LIBRARY_BRIDGE_BINARY_PATH=/clickhouse-library-bridge
|
||||||
|
|
||||||
export DOCKER_BASE_TAG=${DOCKER_BASE_TAG:=latest}
|
export DOCKER_BASE_TAG=${DOCKER_BASE_TAG:=latest}
|
||||||
export DOCKER_HELPER_TAG=${DOCKER_HELPER_TAG:=latest}
|
|
||||||
export DOCKER_MYSQL_GOLANG_CLIENT_TAG=${DOCKER_MYSQL_GOLANG_CLIENT_TAG:=latest}
|
|
||||||
export DOCKER_DOTNET_CLIENT_TAG=${DOCKER_DOTNET_CLIENT_TAG:=latest}
|
export DOCKER_DOTNET_CLIENT_TAG=${DOCKER_DOTNET_CLIENT_TAG:=latest}
|
||||||
|
export DOCKER_HELPER_TAG=${DOCKER_HELPER_TAG:=latest}
|
||||||
|
export DOCKER_KERBERIZED_HADOOP_TAG=${DOCKER_KERBERIZED_HADOOP_TAG:=latest}
|
||||||
|
export DOCKER_KERBEROS_KDC_TAG=${DOCKER_KERBEROS_KDC_TAG:=latest}
|
||||||
|
export DOCKER_MYSQL_GOLANG_CLIENT_TAG=${DOCKER_MYSQL_GOLANG_CLIENT_TAG:=latest}
|
||||||
export DOCKER_MYSQL_JAVA_CLIENT_TAG=${DOCKER_MYSQL_JAVA_CLIENT_TAG:=latest}
|
export DOCKER_MYSQL_JAVA_CLIENT_TAG=${DOCKER_MYSQL_JAVA_CLIENT_TAG:=latest}
|
||||||
export DOCKER_MYSQL_JS_CLIENT_TAG=${DOCKER_MYSQL_JS_CLIENT_TAG:=latest}
|
export DOCKER_MYSQL_JS_CLIENT_TAG=${DOCKER_MYSQL_JS_CLIENT_TAG:=latest}
|
||||||
export DOCKER_MYSQL_PHP_CLIENT_TAG=${DOCKER_MYSQL_PHP_CLIENT_TAG:=latest}
|
export DOCKER_MYSQL_PHP_CLIENT_TAG=${DOCKER_MYSQL_PHP_CLIENT_TAG:=latest}
|
||||||
|
export DOCKER_NGINX_DAV_TAG=${DOCKER_NGINX_DAV_TAG:=latest}
|
||||||
export DOCKER_POSTGRESQL_JAVA_CLIENT_TAG=${DOCKER_POSTGRESQL_JAVA_CLIENT_TAG:=latest}
|
export DOCKER_POSTGRESQL_JAVA_CLIENT_TAG=${DOCKER_POSTGRESQL_JAVA_CLIENT_TAG:=latest}
|
||||||
export DOCKER_KERBEROS_KDC_TAG=${DOCKER_KERBEROS_KDC_TAG:=latest}
|
|
||||||
export DOCKER_KERBERIZED_HADOOP_TAG=${DOCKER_KERBERIZED_HADOOP_TAG:=latest}
|
|
||||||
|
|
||||||
cd /ClickHouse/tests/integration
|
cd /ClickHouse/tests/integration
|
||||||
exec "$@"
|
exec "$@"
|
||||||
|
|||||||
@ -3,7 +3,7 @@
|
|||||||
<default>
|
<default>
|
||||||
<allow_introspection_functions>1</allow_introspection_functions>
|
<allow_introspection_functions>1</allow_introspection_functions>
|
||||||
<log_queries>1</log_queries>
|
<log_queries>1</log_queries>
|
||||||
<metrics_perf_events_enabled>1</metrics_perf_events_enabled>
|
<metrics_perf_events_enabled>0</metrics_perf_events_enabled>
|
||||||
<!--
|
<!--
|
||||||
If a test takes too long by mistake, the entire test task can
|
If a test takes too long by mistake, the entire test task can
|
||||||
time out and the author won't get a proper message. Put some cap
|
time out and the author won't get a proper message. Put some cap
|
||||||
|
|||||||
@ -369,6 +369,7 @@ for query_index in queries_to_run:
|
|||||||
"max_execution_time": args.prewarm_max_query_seconds,
|
"max_execution_time": args.prewarm_max_query_seconds,
|
||||||
"query_profiler_real_time_period_ns": 10000000,
|
"query_profiler_real_time_period_ns": 10000000,
|
||||||
"query_profiler_cpu_time_period_ns": 10000000,
|
"query_profiler_cpu_time_period_ns": 10000000,
|
||||||
|
"metrics_perf_events_enabled": 1,
|
||||||
"memory_profiler_step": "4Mi",
|
"memory_profiler_step": "4Mi",
|
||||||
},
|
},
|
||||||
)
|
)
|
||||||
@ -503,6 +504,7 @@ for query_index in queries_to_run:
|
|||||||
settings={
|
settings={
|
||||||
"query_profiler_real_time_period_ns": 10000000,
|
"query_profiler_real_time_period_ns": 10000000,
|
||||||
"query_profiler_cpu_time_period_ns": 10000000,
|
"query_profiler_cpu_time_period_ns": 10000000,
|
||||||
|
"metrics_perf_events_enabled": 1,
|
||||||
},
|
},
|
||||||
)
|
)
|
||||||
print(
|
print(
|
||||||
|
|||||||
@ -96,5 +96,4 @@ rg -Fa "Fatal" /var/log/clickhouse-server/clickhouse-server.log ||:
|
|||||||
zstd < /var/log/clickhouse-server/clickhouse-server.log > /test_output/clickhouse-server.log.zst &
|
zstd < /var/log/clickhouse-server/clickhouse-server.log > /test_output/clickhouse-server.log.zst &
|
||||||
|
|
||||||
# Compressed (FIXME: remove once only github actions will be left)
|
# Compressed (FIXME: remove once only github actions will be left)
|
||||||
rm /var/log/clickhouse-server/clickhouse-server.log
|
|
||||||
mv /var/log/clickhouse-server/stderr.log /test_output/ ||:
|
mv /var/log/clickhouse-server/stderr.log /test_output/ ||:
|
||||||
|
|||||||
@ -41,6 +41,8 @@ RUN apt-get update -y \
|
|||||||
zstd \
|
zstd \
|
||||||
file \
|
file \
|
||||||
pv \
|
pv \
|
||||||
|
zip \
|
||||||
|
p7zip-full \
|
||||||
&& apt-get clean
|
&& apt-get clean
|
||||||
|
|
||||||
RUN pip3 install numpy scipy pandas Jinja2
|
RUN pip3 install numpy scipy pandas Jinja2
|
||||||
|
|||||||
@ -200,8 +200,8 @@ Templates:
|
|||||||
- [Server Setting](_description_templates/template-server-setting.md)
|
- [Server Setting](_description_templates/template-server-setting.md)
|
||||||
- [Database or Table engine](_description_templates/template-engine.md)
|
- [Database or Table engine](_description_templates/template-engine.md)
|
||||||
- [System table](_description_templates/template-system-table.md)
|
- [System table](_description_templates/template-system-table.md)
|
||||||
- [Data type](_description_templates/data-type.md)
|
- [Data type](_description_templates/template-data-type.md)
|
||||||
- [Statement](_description_templates/statement.md)
|
- [Statement](_description_templates/template-statement.md)
|
||||||
|
|
||||||
|
|
||||||
<a name="how-to-build-docs"/>
|
<a name="how-to-build-docs"/>
|
||||||
|
|||||||
31
docs/changelogs/v23.7.2.25-stable.md
Normal file
31
docs/changelogs/v23.7.2.25-stable.md
Normal file
@ -0,0 +1,31 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
sidebar_label: 2023
|
||||||
|
---
|
||||||
|
|
||||||
|
# 2023 Changelog
|
||||||
|
|
||||||
|
### ClickHouse release v23.7.2.25-stable (8dd1107b032) FIXME as compared to v23.7.1.2470-stable (a70127baecc)
|
||||||
|
|
||||||
|
#### Backward Incompatible Change
|
||||||
|
* Backported in [#52850](https://github.com/ClickHouse/ClickHouse/issues/52850): If a dynamic disk contains a name, it should be specified as `disk = disk(name = 'disk_name'`, ...) in disk function arguments. In previous version it could be specified as `disk = disk_<disk_name>(...)`, which is no longer supported. [#52820](https://github.com/ClickHouse/ClickHouse/pull/52820) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||||
|
|
||||||
|
#### Build/Testing/Packaging Improvement
|
||||||
|
* Backported in [#52913](https://github.com/ClickHouse/ClickHouse/issues/52913): Add `clickhouse-keeper-client` symlink to the clickhouse-server package. [#51882](https://github.com/ClickHouse/ClickHouse/pull/51882) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||||
|
|
||||||
|
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||||
|
|
||||||
|
* Fix binary arithmetic for Nullable(IPv4) [#51642](https://github.com/ClickHouse/ClickHouse/pull/51642) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||||
|
* Support IPv4 and IPv6 as dictionary attributes [#51756](https://github.com/ClickHouse/ClickHouse/pull/51756) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||||
|
* init and destroy ares channel on demand.. [#52634](https://github.com/ClickHouse/ClickHouse/pull/52634) ([Arthur Passos](https://github.com/arthurpassos)).
|
||||||
|
* Fix crash in function `tuple` with one sparse column argument [#52659](https://github.com/ClickHouse/ClickHouse/pull/52659) ([Anton Popov](https://github.com/CurtizJ)).
|
||||||
|
* Fix data race in Keeper reconfiguration [#52804](https://github.com/ClickHouse/ClickHouse/pull/52804) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||||
|
* clickhouse-keeper: fix implementation of server with poll() [#52833](https://github.com/ClickHouse/ClickHouse/pull/52833) ([Andy Fiddaman](https://github.com/citrus-it)).
|
||||||
|
|
||||||
|
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||||
|
|
||||||
|
* Rename setting disable_url_encoding to enable_url_encoding and add a test [#52656](https://github.com/ClickHouse/ClickHouse/pull/52656) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||||
|
* Fix bugs and better test for SYSTEM STOP LISTEN [#52680](https://github.com/ClickHouse/ClickHouse/pull/52680) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||||
|
* Increase min protocol version for sparse serialization [#52835](https://github.com/ClickHouse/ClickHouse/pull/52835) ([Anton Popov](https://github.com/CurtizJ)).
|
||||||
|
* Docker improvements [#52869](https://github.com/ClickHouse/ClickHouse/pull/52869) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||||
|
|
||||||
23
docs/changelogs/v23.7.3.14-stable.md
Normal file
23
docs/changelogs/v23.7.3.14-stable.md
Normal file
@ -0,0 +1,23 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
sidebar_label: 2023
|
||||||
|
---
|
||||||
|
|
||||||
|
# 2023 Changelog
|
||||||
|
|
||||||
|
### ClickHouse release v23.7.3.14-stable (bd9a510550c) FIXME as compared to v23.7.2.25-stable (8dd1107b032)
|
||||||
|
|
||||||
|
#### Build/Testing/Packaging Improvement
|
||||||
|
* Backported in [#53025](https://github.com/ClickHouse/ClickHouse/issues/53025): Packing inline cache into docker images sometimes causes strange special effects. Since we don't use it at all, it's good to go. [#53008](https://github.com/ClickHouse/ClickHouse/pull/53008) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||||
|
|
||||||
|
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||||
|
|
||||||
|
* Fix named collections on cluster 23.7 [#52687](https://github.com/ClickHouse/ClickHouse/pull/52687) ([Al Korgun](https://github.com/alkorgun)).
|
||||||
|
* Fix password leak in show create mysql table [#52962](https://github.com/ClickHouse/ClickHouse/pull/52962) ([Duc Canh Le](https://github.com/canhld94)).
|
||||||
|
* Fix ZstdDeflatingWriteBuffer truncating the output sometimes [#53064](https://github.com/ClickHouse/ClickHouse/pull/53064) ([Michael Kolupaev](https://github.com/al13n321)).
|
||||||
|
|
||||||
|
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||||
|
|
||||||
|
* Suspicious DISTINCT crashes from sqlancer [#52636](https://github.com/ClickHouse/ClickHouse/pull/52636) ([Igor Nikonov](https://github.com/devcrafter)).
|
||||||
|
* Fix Parquet stats for Float32 and Float64 [#53067](https://github.com/ClickHouse/ClickHouse/pull/53067) ([Michael Kolupaev](https://github.com/al13n321)).
|
||||||
|
|
||||||
17
docs/changelogs/v23.7.4.5-stable.md
Normal file
17
docs/changelogs/v23.7.4.5-stable.md
Normal file
@ -0,0 +1,17 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
sidebar_label: 2023
|
||||||
|
---
|
||||||
|
|
||||||
|
# 2023 Changelog
|
||||||
|
|
||||||
|
### ClickHouse release v23.7.4.5-stable (bd2fcd44553) FIXME as compared to v23.7.3.14-stable (bd9a510550c)
|
||||||
|
|
||||||
|
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||||
|
|
||||||
|
* Disable the new parquet encoder [#53130](https://github.com/ClickHouse/ClickHouse/pull/53130) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||||
|
|
||||||
|
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||||
|
|
||||||
|
* Revert changes in `ZstdDeflatingAppendableWriteBuffer` [#53111](https://github.com/ClickHouse/ClickHouse/pull/53111) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||||
|
|
||||||
@ -14,6 +14,20 @@ Supported platforms:
|
|||||||
- PowerPC 64 LE (experimental)
|
- PowerPC 64 LE (experimental)
|
||||||
- RISC-V 64 (experimental)
|
- RISC-V 64 (experimental)
|
||||||
|
|
||||||
|
## Building in docker
|
||||||
|
We use the docker image `clickhouse/binary-builder` for our CI builds. It contains everything necessary to build the binary and packages. There is a script `docker/packager/packager` to ease the image usage:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# define a directory for the output artifacts
|
||||||
|
output_dir="build_results"
|
||||||
|
# a simplest build
|
||||||
|
./docker/packager/packager --package-type=binary --output-dir "$output_dir"
|
||||||
|
# build debian packages
|
||||||
|
./docker/packager/packager --package-type=deb --output-dir "$output_dir"
|
||||||
|
# by default, debian packages use thin LTO, so we can override it to speed up the build
|
||||||
|
CMAKE_FLAGS='-DENABLE_THINLTO=' ./docker/packager/packager --package-type=deb --output-dir "./$(git rev-parse --show-cdup)/build_results"
|
||||||
|
```
|
||||||
|
|
||||||
## Building on Ubuntu
|
## Building on Ubuntu
|
||||||
|
|
||||||
The following tutorial is based on Ubuntu Linux.
|
The following tutorial is based on Ubuntu Linux.
|
||||||
@ -28,20 +42,20 @@ sudo apt-get install git cmake ccache python3 ninja-build nasm yasm gawk lsb-rel
|
|||||||
|
|
||||||
### Install and Use the Clang compiler
|
### Install and Use the Clang compiler
|
||||||
|
|
||||||
On Ubuntu/Debian you can use LLVM's automatic installation script, see [here](https://apt.llvm.org/).
|
On Ubuntu/Debian, you can use LLVM's automatic installation script; see [here](https://apt.llvm.org/).
|
||||||
|
|
||||||
``` bash
|
``` bash
|
||||||
sudo bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
|
sudo bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
|
||||||
```
|
```
|
||||||
|
|
||||||
Note: in case of troubles, you can also use this:
|
Note: in case of trouble, you can also use this:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
sudo apt-get install software-properties-common
|
sudo apt-get install software-properties-common
|
||||||
sudo add-apt-repository -y ppa:ubuntu-toolchain-r/test
|
sudo add-apt-repository -y ppa:ubuntu-toolchain-r/test
|
||||||
```
|
```
|
||||||
|
|
||||||
For other Linux distribution - check the availability of LLVM's [prebuild packages](https://releases.llvm.org/download.html).
|
For other Linux distributions - check the availability of LLVM's [prebuild packages](https://releases.llvm.org/download.html).
|
||||||
|
|
||||||
As of April 2023, clang-16 or higher will work.
|
As of April 2023, clang-16 or higher will work.
|
||||||
GCC as a compiler is not supported.
|
GCC as a compiler is not supported.
|
||||||
@ -78,8 +92,12 @@ cmake -S . -B build
|
|||||||
cmake --build build # or: `cd build; ninja`
|
cmake --build build # or: `cd build; ninja`
|
||||||
```
|
```
|
||||||
|
|
||||||
|
:::tip
|
||||||
|
In case `cmake` isn't able to detect the number of available logical cores, the build will be done by one thread. To overcome this, you can tweak `cmake` to use a specific number of threads with `-j` flag, for example, `cmake --build build -j 16`. Alternatively, you can generate build files with a specific number of jobs in advance to avoid always setting the flag: `cmake -DPARALLEL_COMPILE_JOBS=16 -S . -B build`, where `16` is the desired number of threads.
|
||||||
|
:::
|
||||||
|
|
||||||
To create an executable, run `cmake --build build --target clickhouse` (or: `cd build; ninja clickhouse`).
|
To create an executable, run `cmake --build build --target clickhouse` (or: `cd build; ninja clickhouse`).
|
||||||
This will create executable `build/programs/clickhouse` which can be used with `client` or `server` arguments.
|
This will create an executable `build/programs/clickhouse`, which can be used with `client` or `server` arguments.
|
||||||
|
|
||||||
## Building on Any Linux {#how-to-build-clickhouse-on-any-linux}
|
## Building on Any Linux {#how-to-build-clickhouse-on-any-linux}
|
||||||
|
|
||||||
@ -93,7 +111,7 @@ The build requires the following components:
|
|||||||
- Yasm
|
- Yasm
|
||||||
- Gawk
|
- Gawk
|
||||||
|
|
||||||
If all the components are installed, you may build in the same way as the steps above.
|
If all the components are installed, you may build it in the same way as the steps above.
|
||||||
|
|
||||||
Example for OpenSUSE Tumbleweed:
|
Example for OpenSUSE Tumbleweed:
|
||||||
|
|
||||||
@ -109,7 +127,7 @@ Example for Fedora Rawhide:
|
|||||||
|
|
||||||
``` bash
|
``` bash
|
||||||
sudo yum update
|
sudo yum update
|
||||||
sudo yum --nogpg install git cmake make clang python3 ccache nasm yasm gawk
|
sudo yum --nogpg install git cmake make clang python3 ccache lld nasm yasm gawk
|
||||||
git clone --recursive https://github.com/ClickHouse/ClickHouse.git
|
git clone --recursive https://github.com/ClickHouse/ClickHouse.git
|
||||||
mkdir build
|
mkdir build
|
||||||
cmake -S . -B build
|
cmake -S . -B build
|
||||||
|
|||||||
@ -141,6 +141,10 @@ Runs [stateful functional tests](tests.md#functional-tests). Treat them in the s
|
|||||||
Runs [integration tests](tests.md#integration-tests).
|
Runs [integration tests](tests.md#integration-tests).
|
||||||
|
|
||||||
|
|
||||||
|
## Bugfix validate check
|
||||||
|
Checks that either a new test (functional or integration) or there some changed tests that fail with the binary built on master branch. This check is triggered when pull request has "pr-bugfix" label.
|
||||||
|
|
||||||
|
|
||||||
## Stress Test
|
## Stress Test
|
||||||
Runs stateless functional tests concurrently from several clients to detect
|
Runs stateless functional tests concurrently from several clients to detect
|
||||||
concurrency-related errors. If it fails:
|
concurrency-related errors. If it fails:
|
||||||
|
|||||||
@ -35,7 +35,7 @@ The [system.clusters](../../operations/system-tables/clusters.md) system table c
|
|||||||
|
|
||||||
When creating a new replica of the database, this replica creates tables by itself. If the replica has been unavailable for a long time and has lagged behind the replication log — it checks its local metadata with the current metadata in ZooKeeper, moves the extra tables with data to a separate non-replicated database (so as not to accidentally delete anything superfluous), creates the missing tables, updates the table names if they have been renamed. The data is replicated at the `ReplicatedMergeTree` level, i.e. if the table is not replicated, the data will not be replicated (the database is responsible only for metadata).
|
When creating a new replica of the database, this replica creates tables by itself. If the replica has been unavailable for a long time and has lagged behind the replication log — it checks its local metadata with the current metadata in ZooKeeper, moves the extra tables with data to a separate non-replicated database (so as not to accidentally delete anything superfluous), creates the missing tables, updates the table names if they have been renamed. The data is replicated at the `ReplicatedMergeTree` level, i.e. if the table is not replicated, the data will not be replicated (the database is responsible only for metadata).
|
||||||
|
|
||||||
[`ALTER TABLE ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
[`ALTER TABLE FREEZE|ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
||||||
|
|
||||||
## Usage Example {#usage-example}
|
## Usage Example {#usage-example}
|
||||||
|
|
||||||
|
|||||||
@ -60,6 +60,7 @@ Engines in the family:
|
|||||||
- [EmbeddedRocksDB](../../engines/table-engines/integrations/embedded-rocksdb.md)
|
- [EmbeddedRocksDB](../../engines/table-engines/integrations/embedded-rocksdb.md)
|
||||||
- [RabbitMQ](../../engines/table-engines/integrations/rabbitmq.md)
|
- [RabbitMQ](../../engines/table-engines/integrations/rabbitmq.md)
|
||||||
- [PostgreSQL](../../engines/table-engines/integrations/postgresql.md)
|
- [PostgreSQL](../../engines/table-engines/integrations/postgresql.md)
|
||||||
|
- [S3Queue](../../engines/table-engines/integrations/s3queue.md)
|
||||||
|
|
||||||
### Special Engines {#special-engines}
|
### Special Engines {#special-engines}
|
||||||
|
|
||||||
|
|||||||
@ -21,7 +21,7 @@ CREATE TABLE azure_blob_storage_table (name String, value UInt32)
|
|||||||
|
|
||||||
- `connection_string|storage_account_url` — connection_string includes account name & key ([Create connection string](https://learn.microsoft.com/en-us/azure/storage/common/storage-configure-connection-string?toc=%2Fazure%2Fstorage%2Fblobs%2Ftoc.json&bc=%2Fazure%2Fstorage%2Fblobs%2Fbreadcrumb%2Ftoc.json#configure-a-connection-string-for-an-azure-storage-account)) or you could also provide the storage account url here and account name & account key as separate parameters (see parameters account_name & account_key)
|
- `connection_string|storage_account_url` — connection_string includes account name & key ([Create connection string](https://learn.microsoft.com/en-us/azure/storage/common/storage-configure-connection-string?toc=%2Fazure%2Fstorage%2Fblobs%2Ftoc.json&bc=%2Fazure%2Fstorage%2Fblobs%2Fbreadcrumb%2Ftoc.json#configure-a-connection-string-for-an-azure-storage-account)) or you could also provide the storage account url here and account name & account key as separate parameters (see parameters account_name & account_key)
|
||||||
- `container_name` - Container name
|
- `container_name` - Container name
|
||||||
- `blobpath` - file path. Supports following wildcards in readonly mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings.
|
- `blobpath` - file path. Supports following wildcards in readonly mode: `*`, `**`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings.
|
||||||
- `account_name` - if storage_account_url is used, then account name can be specified here
|
- `account_name` - if storage_account_url is used, then account name can be specified here
|
||||||
- `account_key` - if storage_account_url is used, then account key can be specified here
|
- `account_key` - if storage_account_url is used, then account key can be specified here
|
||||||
- `format` — The [format](/docs/en/interfaces/formats.md) of the file.
|
- `format` — The [format](/docs/en/interfaces/formats.md) of the file.
|
||||||
|
|||||||
@ -22,7 +22,7 @@ CREATE TABLE deltalake
|
|||||||
- `url` — Bucket url with path to the existing Delta Lake table.
|
- `url` — Bucket url with path to the existing Delta Lake table.
|
||||||
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file.
|
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file.
|
||||||
|
|
||||||
Engine parameters can be specified using [Named Collections](../../../operations/named-collections.md)
|
Engine parameters can be specified using [Named Collections](/docs/en/operations/named-collections.md).
|
||||||
|
|
||||||
**Example**
|
**Example**
|
||||||
|
|
||||||
|
|||||||
@ -22,7 +22,7 @@ CREATE TABLE hudi_table
|
|||||||
- `url` — Bucket url with the path to an existing Hudi table.
|
- `url` — Bucket url with the path to an existing Hudi table.
|
||||||
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file.
|
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file.
|
||||||
|
|
||||||
Engine parameters can be specified using [Named Collections](../../../operations/named-collections.md)
|
Engine parameters can be specified using [Named Collections](/docs/en/operations/named-collections.md).
|
||||||
|
|
||||||
**Example**
|
**Example**
|
||||||
|
|
||||||
|
|||||||
@ -37,7 +37,7 @@ CREATE TABLE s3_engine_table (name String, value UInt32)
|
|||||||
|
|
||||||
### Engine parameters
|
### Engine parameters
|
||||||
|
|
||||||
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings. For more information see [below](#wildcards-in-path).
|
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `**`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings. For more information see [below](#wildcards-in-path).
|
||||||
- `NOSIGN` - If this keyword is provided in place of credentials, all the requests will not be signed.
|
- `NOSIGN` - If this keyword is provided in place of credentials, all the requests will not be signed.
|
||||||
- `format` — The [format](../../../interfaces/formats.md#formats) of the file.
|
- `format` — The [format](../../../interfaces/formats.md#formats) of the file.
|
||||||
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file. For more information see [Using S3 for Data Storage](../mergetree-family/mergetree.md#table_engine-mergetree-s3).
|
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file. For more information see [Using S3 for Data Storage](../mergetree-family/mergetree.md#table_engine-mergetree-s3).
|
||||||
@ -164,6 +164,7 @@ For more information about virtual columns see [here](../../../engines/table-eng
|
|||||||
`path` argument can specify multiple files using bash-like wildcards. For being processed file should exist and match to the whole path pattern. Listing of files is determined during `SELECT` (not at `CREATE` moment).
|
`path` argument can specify multiple files using bash-like wildcards. For being processed file should exist and match to the whole path pattern. Listing of files is determined during `SELECT` (not at `CREATE` moment).
|
||||||
|
|
||||||
- `*` — Substitutes any number of any characters except `/` including empty string.
|
- `*` — Substitutes any number of any characters except `/` including empty string.
|
||||||
|
- `**` — Substitutes any number of any character include `/` including empty string.
|
||||||
- `?` — Substitutes any single character.
|
- `?` — Substitutes any single character.
|
||||||
- `{some_string,another_string,yet_another_one}` — Substitutes any of strings `'some_string', 'another_string', 'yet_another_one'`.
|
- `{some_string,another_string,yet_another_one}` — Substitutes any of strings `'some_string', 'another_string', 'yet_another_one'`.
|
||||||
- `{N..M}` — Substitutes any number in range from N to M including both borders. N and M can have leading zeroes e.g. `000..078`.
|
- `{N..M}` — Substitutes any number in range from N to M including both borders. N and M can have leading zeroes e.g. `000..078`.
|
||||||
@ -237,7 +238,7 @@ The following settings can be set before query execution or placed into configur
|
|||||||
- `s3_max_get_rps` — Maximum GET requests per second rate before throttling. Default value is `0` (unlimited).
|
- `s3_max_get_rps` — Maximum GET requests per second rate before throttling. Default value is `0` (unlimited).
|
||||||
- `s3_max_get_burst` — Max number of requests that can be issued simultaneously before hitting request per second limit. By default (`0` value) equals to `s3_max_get_rps`.
|
- `s3_max_get_burst` — Max number of requests that can be issued simultaneously before hitting request per second limit. By default (`0` value) equals to `s3_max_get_rps`.
|
||||||
- `s3_upload_part_size_multiply_factor` - Multiply `s3_min_upload_part_size` by this factor each time `s3_multiply_parts_count_threshold` parts were uploaded from a single write to S3. Default values is `2`.
|
- `s3_upload_part_size_multiply_factor` - Multiply `s3_min_upload_part_size` by this factor each time `s3_multiply_parts_count_threshold` parts were uploaded from a single write to S3. Default values is `2`.
|
||||||
- `s3_upload_part_size_multiply_parts_count_threshold` - Each time this number of parts was uploaded to S3 `s3_min_upload_part_size multiplied` by `s3_upload_part_size_multiply_factor`. Default value us `500`.
|
- `s3_upload_part_size_multiply_parts_count_threshold` - Each time this number of parts was uploaded to S3, `s3_min_upload_part_size` is multiplied by `s3_upload_part_size_multiply_factor`. Default value is `500`.
|
||||||
- `s3_max_inflight_parts_for_one_file` - Limits the number of put requests that can be run concurrently for one object. Its number should be limited. The value `0` means unlimited. Default value is `20`. Each in-flight part has a buffer with size `s3_min_upload_part_size` for the first `s3_upload_part_size_multiply_factor` parts and more when file is big enough, see `upload_part_size_multiply_factor`. With default settings one uploaded file consumes not more than `320Mb` for a file which is less than `8G`. The consumption is greater for a larger file.
|
- `s3_max_inflight_parts_for_one_file` - Limits the number of put requests that can be run concurrently for one object. Its number should be limited. The value `0` means unlimited. Default value is `20`. Each in-flight part has a buffer with size `s3_min_upload_part_size` for the first `s3_upload_part_size_multiply_factor` parts and more when file is big enough, see `upload_part_size_multiply_factor`. With default settings one uploaded file consumes not more than `320Mb` for a file which is less than `8G`. The consumption is greater for a larger file.
|
||||||
|
|
||||||
Security consideration: if malicious user can specify arbitrary S3 URLs, `s3_max_redirects` must be set to zero to avoid [SSRF](https://en.wikipedia.org/wiki/Server-side_request_forgery) attacks; or alternatively, `remote_host_filter` must be specified in server configuration.
|
Security consideration: if malicious user can specify arbitrary S3 URLs, `s3_max_redirects` must be set to zero to avoid [SSRF](https://en.wikipedia.org/wiki/Server-side_request_forgery) attacks; or alternatively, `remote_host_filter` must be specified in server configuration.
|
||||||
|
|||||||
225
docs/en/engines/table-engines/integrations/s3queue.md
Normal file
225
docs/en/engines/table-engines/integrations/s3queue.md
Normal file
@ -0,0 +1,225 @@
|
|||||||
|
---
|
||||||
|
slug: /en/engines/table-engines/integrations/s3queue
|
||||||
|
sidebar_position: 7
|
||||||
|
sidebar_label: S3Queue
|
||||||
|
---
|
||||||
|
|
||||||
|
# S3Queue Table Engine
|
||||||
|
This engine provides integration with [Amazon S3](https://aws.amazon.com/s3/) ecosystem and allows streaming import. This engine is similar to the [Kafka](../../../engines/table-engines/integrations/kafka.md), [RabbitMQ](../../../engines/table-engines/integrations/rabbitmq.md) engines, but provides S3-specific features.
|
||||||
|
|
||||||
|
## Create Table {#creating-a-table}
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
CREATE TABLE s3_queue_engine_table (name String, value UInt32)
|
||||||
|
ENGINE = S3Queue(path [, NOSIGN | aws_access_key_id, aws_secret_access_key,] format, [compression])
|
||||||
|
[SETTINGS]
|
||||||
|
[mode = 'unordered',]
|
||||||
|
[after_processing = 'keep',]
|
||||||
|
[keeper_path = '',]
|
||||||
|
[s3queue_loading_retries = 0,]
|
||||||
|
[s3queue_polling_min_timeout_ms = 1000,]
|
||||||
|
[s3queue_polling_max_timeout_ms = 10000,]
|
||||||
|
[s3queue_polling_backoff_ms = 0,]
|
||||||
|
[s3queue_tracked_files_limit = 1000,]
|
||||||
|
[s3queue_tracked_file_ttl_sec = 0,]
|
||||||
|
[s3queue_polling_size = 50,]
|
||||||
|
```
|
||||||
|
|
||||||
|
**Engine parameters**
|
||||||
|
|
||||||
|
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `**`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings. For more information see [below](#wildcards-in-path).
|
||||||
|
- `NOSIGN` - If this keyword is provided in place of credentials, all the requests will not be signed.
|
||||||
|
- `format` — The [format](../../../interfaces/formats.md#formats) of the file.
|
||||||
|
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file. For more information see [Using S3 for Data Storage](../mergetree-family/mergetree.md#table_engine-mergetree-s3).
|
||||||
|
- `compression` — Compression type. Supported values: `none`, `gzip/gz`, `brotli/br`, `xz/LZMA`, `zstd/zst`. Parameter is optional. By default, it will autodetect compression by file extension.
|
||||||
|
|
||||||
|
**Example**
|
||||||
|
|
||||||
|
```sql
|
||||||
|
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||||
|
ENGINE=S3Queue('https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*', 'CSV', 'gzip')
|
||||||
|
SETTINGS
|
||||||
|
mode = 'ordred';
|
||||||
|
```
|
||||||
|
|
||||||
|
Using named collections:
|
||||||
|
|
||||||
|
``` xml
|
||||||
|
<clickhouse>
|
||||||
|
<named_collections>
|
||||||
|
<s3queue_conf>
|
||||||
|
<url>'https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*</url>
|
||||||
|
<access_key_id>test<access_key_id>
|
||||||
|
<secret_access_key>test</secret_access_key>
|
||||||
|
</s3queue_conf>
|
||||||
|
</named_collections>
|
||||||
|
</clickhouse>
|
||||||
|
```
|
||||||
|
|
||||||
|
```sql
|
||||||
|
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||||
|
ENGINE=S3Queue(s3queue_conf, format = 'CSV', compression_method = 'gzip')
|
||||||
|
SETTINGS
|
||||||
|
mode = 'ordred';
|
||||||
|
```
|
||||||
|
|
||||||
|
## Settings {#s3queue-settings}
|
||||||
|
|
||||||
|
### mode {#mode}
|
||||||
|
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- unordered — With unordered mode, the set of all already processed files is tracked with persistent nodes in ZooKeeper.
|
||||||
|
- ordered — With ordered mode, only the max name of the successfully consumed file, and the names of files that will be retried after unsuccessful loading attempt are being stored in ZooKeeper.
|
||||||
|
|
||||||
|
Default value: `unordered`.
|
||||||
|
|
||||||
|
### after_processing {#after_processing}
|
||||||
|
|
||||||
|
Delete or keep file after successful processing.
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- keep.
|
||||||
|
- delete.
|
||||||
|
|
||||||
|
Default value: `keep`.
|
||||||
|
|
||||||
|
### keeper_path {#keeper_path}
|
||||||
|
|
||||||
|
The path in ZooKeeper can be specified as a table engine setting or default path can be formed from the global configuration-provided path and table UUID.
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- String.
|
||||||
|
|
||||||
|
Default value: `/`.
|
||||||
|
|
||||||
|
### s3queue_loading_retries {#s3queue_loading_retries}
|
||||||
|
|
||||||
|
Retry file loading up to specified number of times. By default, there are no retries.
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- Positive integer.
|
||||||
|
|
||||||
|
Default value: `0`.
|
||||||
|
|
||||||
|
### s3queue_polling_min_timeout_ms {#s3queue_polling_min_timeout_ms}
|
||||||
|
|
||||||
|
Minimal timeout before next polling (in milliseconds).
|
||||||
|
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- Positive integer.
|
||||||
|
|
||||||
|
Default value: `1000`.
|
||||||
|
|
||||||
|
### s3queue_polling_max_timeout_ms {#s3queue_polling_max_timeout_ms}
|
||||||
|
|
||||||
|
Maximum timeout before next polling (in milliseconds).
|
||||||
|
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- Positive integer.
|
||||||
|
|
||||||
|
Default value: `10000`.
|
||||||
|
|
||||||
|
### s3queue_polling_backoff_ms {#s3queue_polling_backoff_ms}
|
||||||
|
|
||||||
|
Polling backoff (in milliseconds).
|
||||||
|
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- Positive integer.
|
||||||
|
|
||||||
|
Default value: `0`.
|
||||||
|
|
||||||
|
### s3queue_tracked_files_limit {#s3queue_tracked_files_limit}
|
||||||
|
|
||||||
|
Allows to limit the number of Zookeeper nodes if the 'unordered' mode is used, does nothing for 'ordered' mode.
|
||||||
|
If limit reached the oldest processed files will be deleted from ZooKeeper node and processed again.
|
||||||
|
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- Positive integer.
|
||||||
|
|
||||||
|
Default value: `1000`.
|
||||||
|
|
||||||
|
### s3queue_tracked_file_ttl_sec {#s3queue_tracked_file_ttl_sec}
|
||||||
|
|
||||||
|
Maximum number of seconds to store processed files in ZooKeeper node (store forever by default) for 'unordered' mode, does nothing for 'ordered' mode.
|
||||||
|
After the specified number of seconds, the file will be re-imported.
|
||||||
|
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- Positive integer.
|
||||||
|
|
||||||
|
Default value: `0`.
|
||||||
|
|
||||||
|
### s3queue_polling_size {#s3queue_polling_size}
|
||||||
|
|
||||||
|
Maximum files to fetch from S3 with SELECT or in background task.
|
||||||
|
Engine takes files for processing from S3 in batches.
|
||||||
|
We limit the batch size to increase concurrency if multiple table engines with the same `keeper_path` consume files from the same path.
|
||||||
|
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- Positive integer.
|
||||||
|
|
||||||
|
Default value: `50`.
|
||||||
|
|
||||||
|
|
||||||
|
## S3-related Settings {#s3-settings}
|
||||||
|
|
||||||
|
Engine supports all s3 related settings. For more information about S3 settings see [here](../../../engines/table-engines/integrations/s3.md).
|
||||||
|
|
||||||
|
|
||||||
|
## Description {#description}
|
||||||
|
|
||||||
|
`SELECT` is not particularly useful for streaming import (except for debugging), because each file can be imported only once. It is more practical to create real-time threads using [materialized views](../../../sql-reference/statements/create/view.md). To do this:
|
||||||
|
|
||||||
|
1. Use the engine to create a table for consuming from specified path in S3 and consider it a data stream.
|
||||||
|
2. Create a table with the desired structure.
|
||||||
|
3. Create a materialized view that converts data from the engine and puts it into a previously created table.
|
||||||
|
|
||||||
|
When the `MATERIALIZED VIEW` joins the engine, it starts collecting data in the background.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||||
|
ENGINE=S3Queue('https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*', 'CSV', 'gzip')
|
||||||
|
SETTINGS
|
||||||
|
mode = 'unordred',
|
||||||
|
keeper_path = '/clickhouse/s3queue/';
|
||||||
|
|
||||||
|
CREATE TABLE stats (name String, value UInt32)
|
||||||
|
ENGINE = MergeTree() ORDER BY name;
|
||||||
|
|
||||||
|
CREATE MATERIALIZED VIEW consumer TO stats
|
||||||
|
AS SELECT name, value FROM s3queue_engine_table;
|
||||||
|
|
||||||
|
SELECT * FROM stats ORDER BY name;
|
||||||
|
```
|
||||||
|
|
||||||
|
## Virtual columns {#virtual-columns}
|
||||||
|
|
||||||
|
- `_path` — Path to the file.
|
||||||
|
- `_file` — Name of the file.
|
||||||
|
|
||||||
|
For more information about virtual columns see [here](../../../engines/table-engines/index.md#table_engines-virtual_columns).
|
||||||
|
|
||||||
|
|
||||||
|
## Wildcards In Path {#wildcards-in-path}
|
||||||
|
|
||||||
|
`path` argument can specify multiple files using bash-like wildcards. For being processed file should exist and match to the whole path pattern. Listing of files is determined during `SELECT` (not at `CREATE` moment).
|
||||||
|
|
||||||
|
- `*` — Substitutes any number of any characters except `/` including empty string.
|
||||||
|
- `**` — Substitutes any number of any characters include `/` including empty string.
|
||||||
|
- `?` — Substitutes any single character.
|
||||||
|
- `{some_string,another_string,yet_another_one}` — Substitutes any of strings `'some_string', 'another_string', 'yet_another_one'`.
|
||||||
|
- `{N..M}` — Substitutes any number in range from N to M including both borders. N and M can have leading zeroes e.g. `000..078`.
|
||||||
|
|
||||||
|
Constructions with `{}` are similar to the [remote](../../../sql-reference/table-functions/remote.md) table function.
|
||||||
|
|
||||||
|
:::note
|
||||||
|
If the listing of files contains number ranges with leading zeros, use the construction with braces for each digit separately or use `?`.
|
||||||
|
:::
|
||||||
@ -193,6 +193,19 @@ index creation, `L2Distance` is used as default. Parameter `NumTrees` is the num
|
|||||||
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
||||||
linearly) as well as larger index sizes.
|
linearly) as well as larger index sizes.
|
||||||
|
|
||||||
|
`L2Distance` is also called Euclidean distance, the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points.
|
||||||
|
For example: If we have point P(p1,p2), Q(q1,q2), their distance will be d(p,q)
|
||||||
|

|
||||||
|
|
||||||
|
`cosineDistance` also called cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths.
|
||||||
|
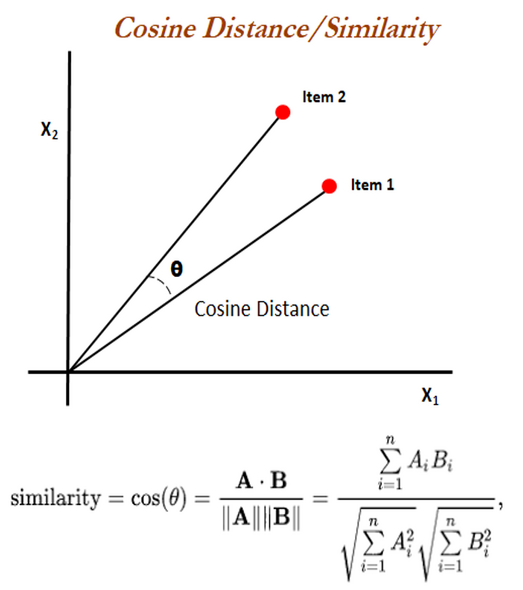
|
||||||
|
|
||||||
|
The Euclidean distance corresponds to the L2-norm of a difference between vectors. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
|
||||||
|

|
||||||
|
In one sentence: cosine similarity care only about the angle between them, but do not care about the "distance" we normally think.
|
||||||
|
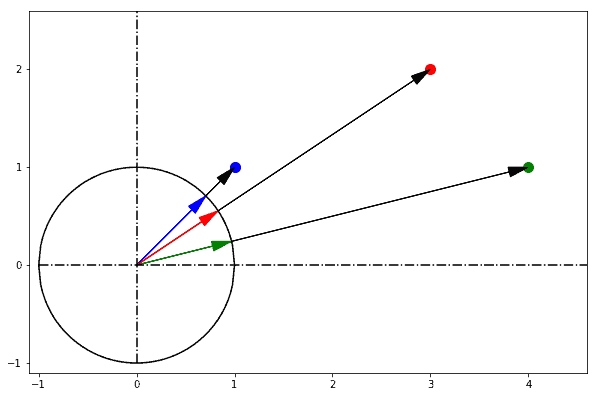
|
||||||
|
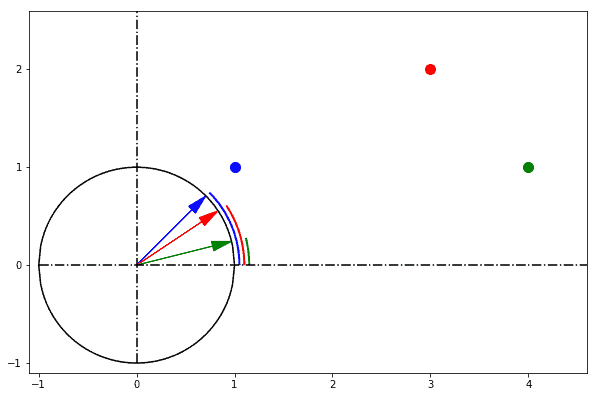
|
||||||
|
|
||||||
:::note
|
:::note
|
||||||
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
||||||
[CONSTRAINT](/docs/en/sql-reference/statements/create/table.md#constraints) to avoid errors. For example, `CONSTRAINT constraint_name_1
|
[CONSTRAINT](/docs/en/sql-reference/statements/create/table.md#constraints) to avoid errors. For example, `CONSTRAINT constraint_name_1
|
||||||
|
|||||||
@ -13,7 +13,7 @@ A recommended alternative to the Buffer Table Engine is enabling [asynchronous i
|
|||||||
:::
|
:::
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes)
|
Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes [,flush_time [,flush_rows [,flush_bytes]]])
|
||||||
```
|
```
|
||||||
|
|
||||||
### Engine parameters:
|
### Engine parameters:
|
||||||
|
|||||||
@ -106,4 +106,4 @@ For partitioning by month, use the `toYYYYMM(date_column)` expression, where `da
|
|||||||
## Storage Settings {#storage-settings}
|
## Storage Settings {#storage-settings}
|
||||||
|
|
||||||
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
||||||
- [disable_url_encoding](/docs/en/operations/settings/settings.md#disable_url_encoding) -allows to disable decoding/encoding path in uri. Disabled by default.
|
- [enable_url_encoding](/docs/en/operations/settings/settings.md#enable_url_encoding) - allows to enable/disable decoding/encoding path in uri. Enabled by default.
|
||||||
|
|||||||
@ -1723,6 +1723,34 @@ You can select data from a ClickHouse table and save them into some file in the
|
|||||||
``` bash
|
``` bash
|
||||||
$ clickhouse-client --query = "SELECT * FROM test.hits FORMAT CapnProto SETTINGS format_schema = 'schema:Message'"
|
$ clickhouse-client --query = "SELECT * FROM test.hits FORMAT CapnProto SETTINGS format_schema = 'schema:Message'"
|
||||||
```
|
```
|
||||||
|
|
||||||
|
### Using autogenerated schema {#using-autogenerated-capn-proto-schema}
|
||||||
|
|
||||||
|
If you don't have an external CapnProto schema for your data, you can still output/input data in CapnProto format using autogenerated schema.
|
||||||
|
For example:
|
||||||
|
|
||||||
|
```sql
|
||||||
|
SELECT * FROM test.hits format CapnProto SETTINGS format_capn_proto_use_autogenerated_schema=1
|
||||||
|
```
|
||||||
|
|
||||||
|
In this case ClickHouse will autogenerate CapnProto schema according to the table structure using function [structureToCapnProtoSchema](../sql-reference/functions/other-functions.md#structure_to_capn_proto_schema) and will use this schema to serialize data in CapnProto format.
|
||||||
|
|
||||||
|
You can also read CapnProto file with autogenerated schema (in this case the file must be created using the same schema):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ cat hits.bin | clickhouse-client --query "INSERT INTO test.hits SETTINGS format_capn_proto_use_autogenerated_schema=1 FORMAT CapnProto"
|
||||||
|
```
|
||||||
|
|
||||||
|
The setting [format_capn_proto_use_autogenerated_schema](../operations/settings/settings-formats.md#format_capn_proto_use_autogenerated_schema) is enabled by default and applies if [format_schema](../operations/settings/settings-formats.md#formatschema-format-schema) is not set.
|
||||||
|
|
||||||
|
You can also save autogenerated schema in the file during input/output using setting [output_format_schema](../operations/settings/settings-formats.md#outputformatschema-output-format-schema). For example:
|
||||||
|
|
||||||
|
```sql
|
||||||
|
SELECT * FROM test.hits format CapnProto SETTINGS format_capn_proto_use_autogenerated_schema=1, output_format_schema='path/to/schema/schema.capnp'
|
||||||
|
```
|
||||||
|
|
||||||
|
In this case autogenerated CapnProto schema will be saved in file `path/to/schema/schema.capnp`.
|
||||||
|
|
||||||
## Prometheus {#prometheus}
|
## Prometheus {#prometheus}
|
||||||
|
|
||||||
Expose metrics in [Prometheus text-based exposition format](https://prometheus.io/docs/instrumenting/exposition_formats/#text-based-format).
|
Expose metrics in [Prometheus text-based exposition format](https://prometheus.io/docs/instrumenting/exposition_formats/#text-based-format).
|
||||||
@ -1861,6 +1889,33 @@ ClickHouse inputs and outputs protobuf messages in the `length-delimited` format
|
|||||||
It means before every message should be written its length as a [varint](https://developers.google.com/protocol-buffers/docs/encoding#varints).
|
It means before every message should be written its length as a [varint](https://developers.google.com/protocol-buffers/docs/encoding#varints).
|
||||||
See also [how to read/write length-delimited protobuf messages in popular languages](https://cwiki.apache.org/confluence/display/GEODE/Delimiting+Protobuf+Messages).
|
See also [how to read/write length-delimited protobuf messages in popular languages](https://cwiki.apache.org/confluence/display/GEODE/Delimiting+Protobuf+Messages).
|
||||||
|
|
||||||
|
### Using autogenerated schema {#using-autogenerated-protobuf-schema}
|
||||||
|
|
||||||
|
If you don't have an external Protobuf schema for your data, you can still output/input data in Protobuf format using autogenerated schema.
|
||||||
|
For example:
|
||||||
|
|
||||||
|
```sql
|
||||||
|
SELECT * FROM test.hits format Protobuf SETTINGS format_protobuf_use_autogenerated_schema=1
|
||||||
|
```
|
||||||
|
|
||||||
|
In this case ClickHouse will autogenerate Protobuf schema according to the table structure using function [structureToProtobufSchema](../sql-reference/functions/other-functions.md#structure_to_protobuf_schema) and will use this schema to serialize data in Protobuf format.
|
||||||
|
|
||||||
|
You can also read Protobuf file with autogenerated schema (in this case the file must be created using the same schema):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ cat hits.bin | clickhouse-client --query "INSERT INTO test.hits SETTINGS format_protobuf_use_autogenerated_schema=1 FORMAT Protobuf"
|
||||||
|
```
|
||||||
|
|
||||||
|
The setting [format_protobuf_use_autogenerated_schema](../operations/settings/settings-formats.md#format_protobuf_use_autogenerated_schema) is enabled by default and applies if [format_schema](../operations/settings/settings-formats.md#formatschema-format-schema) is not set.
|
||||||
|
|
||||||
|
You can also save autogenerated schema in the file during input/output using setting [output_format_schema](../operations/settings/settings-formats.md#outputformatschema-output-format-schema). For example:
|
||||||
|
|
||||||
|
```sql
|
||||||
|
SELECT * FROM test.hits format Protobuf SETTINGS format_protobuf_use_autogenerated_schema=1, output_format_schema='path/to/schema/schema.proto'
|
||||||
|
```
|
||||||
|
|
||||||
|
In this case autogenerated Protobuf schema will be saved in file `path/to/schema/schema.capnp`.
|
||||||
|
|
||||||
## ProtobufSingle {#protobufsingle}
|
## ProtobufSingle {#protobufsingle}
|
||||||
|
|
||||||
Same as [Protobuf](#protobuf) but for storing/parsing single Protobuf message without length delimiters.
|
Same as [Protobuf](#protobuf) but for storing/parsing single Protobuf message without length delimiters.
|
||||||
@ -2076,7 +2131,6 @@ To exchange data with Hadoop, you can use [HDFS table engine](/docs/en/engines/t
|
|||||||
|
|
||||||
- [output_format_parquet_row_group_size](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_row_group_size) - row group size in rows while data output. Default value - `1000000`.
|
- [output_format_parquet_row_group_size](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_row_group_size) - row group size in rows while data output. Default value - `1000000`.
|
||||||
- [output_format_parquet_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_string_as_string) - use Parquet String type instead of Binary for String columns. Default value - `false`.
|
- [output_format_parquet_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_string_as_string) - use Parquet String type instead of Binary for String columns. Default value - `false`.
|
||||||
- [input_format_parquet_import_nested](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_import_nested) - allow inserting array of structs into [Nested](/docs/en/sql-reference/data-types/nested-data-structures/index.md) table in Parquet input format. Default value - `false`.
|
|
||||||
- [input_format_parquet_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_case_insensitive_column_matching) - ignore case when matching Parquet columns with ClickHouse columns. Default value - `false`.
|
- [input_format_parquet_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_case_insensitive_column_matching) - ignore case when matching Parquet columns with ClickHouse columns. Default value - `false`.
|
||||||
- [input_format_parquet_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_allow_missing_columns) - allow missing columns while reading Parquet data. Default value - `false`.
|
- [input_format_parquet_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_allow_missing_columns) - allow missing columns while reading Parquet data. Default value - `false`.
|
||||||
- [input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Parquet format. Default value - `false`.
|
- [input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Parquet format. Default value - `false`.
|
||||||
@ -2281,7 +2335,6 @@ $ clickhouse-client --query="SELECT * FROM {some_table} FORMAT Arrow" > {filenam
|
|||||||
|
|
||||||
- [output_format_arrow_low_cardinality_as_dictionary](/docs/en/operations/settings/settings-formats.md/#output_format_arrow_low_cardinality_as_dictionary) - enable output ClickHouse LowCardinality type as Dictionary Arrow type. Default value - `false`.
|
- [output_format_arrow_low_cardinality_as_dictionary](/docs/en/operations/settings/settings-formats.md/#output_format_arrow_low_cardinality_as_dictionary) - enable output ClickHouse LowCardinality type as Dictionary Arrow type. Default value - `false`.
|
||||||
- [output_format_arrow_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_arrow_string_as_string) - use Arrow String type instead of Binary for String columns. Default value - `false`.
|
- [output_format_arrow_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_arrow_string_as_string) - use Arrow String type instead of Binary for String columns. Default value - `false`.
|
||||||
- [input_format_arrow_import_nested](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_import_nested) - allow inserting array of structs into Nested table in Arrow input format. Default value - `false`.
|
|
||||||
- [input_format_arrow_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_case_insensitive_column_matching) - ignore case when matching Arrow columns with ClickHouse columns. Default value - `false`.
|
- [input_format_arrow_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_case_insensitive_column_matching) - ignore case when matching Arrow columns with ClickHouse columns. Default value - `false`.
|
||||||
- [input_format_arrow_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_allow_missing_columns) - allow missing columns while reading Arrow data. Default value - `false`.
|
- [input_format_arrow_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_allow_missing_columns) - allow missing columns while reading Arrow data. Default value - `false`.
|
||||||
- [input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Arrow format. Default value - `false`.
|
- [input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Arrow format. Default value - `false`.
|
||||||
@ -2347,7 +2400,6 @@ $ clickhouse-client --query="SELECT * FROM {some_table} FORMAT ORC" > {filename.
|
|||||||
|
|
||||||
- [output_format_arrow_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_arrow_string_as_string) - use Arrow String type instead of Binary for String columns. Default value - `false`.
|
- [output_format_arrow_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_arrow_string_as_string) - use Arrow String type instead of Binary for String columns. Default value - `false`.
|
||||||
- [output_format_orc_compression_method](/docs/en/operations/settings/settings-formats.md/#output_format_orc_compression_method) - compression method used in output ORC format. Default value - `none`.
|
- [output_format_orc_compression_method](/docs/en/operations/settings/settings-formats.md/#output_format_orc_compression_method) - compression method used in output ORC format. Default value - `none`.
|
||||||
- [input_format_arrow_import_nested](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_import_nested) - allow inserting array of structs into Nested table in Arrow input format. Default value - `false`.
|
|
||||||
- [input_format_arrow_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_case_insensitive_column_matching) - ignore case when matching Arrow columns with ClickHouse columns. Default value - `false`.
|
- [input_format_arrow_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_case_insensitive_column_matching) - ignore case when matching Arrow columns with ClickHouse columns. Default value - `false`.
|
||||||
- [input_format_arrow_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_allow_missing_columns) - allow missing columns while reading Arrow data. Default value - `false`.
|
- [input_format_arrow_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_allow_missing_columns) - allow missing columns while reading Arrow data. Default value - `false`.
|
||||||
- [input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Arrow format. Default value - `false`.
|
- [input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_arrow_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Arrow format. Default value - `false`.
|
||||||
|
|||||||
@ -84,6 +84,7 @@ The BACKUP and RESTORE statements take a list of DATABASE and TABLE names, a des
|
|||||||
- `password` for the file on disk
|
- `password` for the file on disk
|
||||||
- `base_backup`: the destination of the previous backup of this source. For example, `Disk('backups', '1.zip')`
|
- `base_backup`: the destination of the previous backup of this source. For example, `Disk('backups', '1.zip')`
|
||||||
- `structure_only`: if enabled, allows to only backup or restore the CREATE statements without the data of tables
|
- `structure_only`: if enabled, allows to only backup or restore the CREATE statements without the data of tables
|
||||||
|
- `storage_policy`: storage policy for the tables being restored. See [Using Multiple Block Devices for Data Storage](../engines/table-engines/mergetree-family/mergetree.md#table_engine-mergetree-multiple-volumes). This setting is only applicable to the `RESTORE` command. The specified storage policy applies only to tables with an engine from the `MergeTree` family.
|
||||||
- `s3_storage_class`: the storage class used for S3 backup. For example, `STANDARD`
|
- `s3_storage_class`: the storage class used for S3 backup. For example, `STANDARD`
|
||||||
|
|
||||||
### Usage examples
|
### Usage examples
|
||||||
|
|||||||
@ -0,0 +1,26 @@
|
|||||||
|
---
|
||||||
|
slug: /en/operations/optimizing-performance/profile-guided-optimization
|
||||||
|
sidebar_position: 54
|
||||||
|
sidebar_label: Profile Guided Optimization (PGO)
|
||||||
|
---
|
||||||
|
import SelfManaged from '@site/docs/en/_snippets/_self_managed_only_no_roadmap.md';
|
||||||
|
|
||||||
|
# Profile Guided Optimization
|
||||||
|
|
||||||
|
Profile-Guided Optimization (PGO) is a compiler optimization technique where a program is optimized based on the runtime profile.
|
||||||
|
|
||||||
|
According to the tests, PGO helps with achieving better performance for ClickHouse. According to the tests, we see improvements up to 15% in QPS on the ClickBench test suite. The more detailed results are available [here](https://pastebin.com/xbue3HMU). The performance benefits depend on your typical workload - you can get better or worse results.
|
||||||
|
|
||||||
|
More information about PGO in ClickHouse you can read in the corresponding GitHub [issue](https://github.com/ClickHouse/ClickHouse/issues/44567).
|
||||||
|
|
||||||
|
## How to build ClickHouse with PGO?
|
||||||
|
|
||||||
|
There are two major kinds of PGO: [Instrumentation](https://clang.llvm.org/docs/UsersManual.html#using-sampling-profilers) and [Sampling](https://clang.llvm.org/docs/UsersManual.html#using-sampling-profilers) (also known as AutoFDO). In this guide is described the Instrumentation PGO with ClickHouse.
|
||||||
|
|
||||||
|
1. Build ClickHouse in Instrumented mode. In Clang it can be done via passing `-fprofile-instr-generate` option to `CXXFLAGS`.
|
||||||
|
2. Run instrumented ClickHouse on a sample workload. Here you need to use your usual workload. One of the approaches could be using [ClickBench](https://github.com/ClickHouse/ClickBench) as a sample workload. ClickHouse in the instrumentation mode could work slowly so be ready for that and do not run instrumented ClickHouse in performance-critical environments.
|
||||||
|
3. Recompile ClickHouse once again with `-fprofile-instr-use` compiler flags and profiles that are collected from the previous step.
|
||||||
|
|
||||||
|
A more detailed guide on how to apply PGO is in the Clang [documentation](https://clang.llvm.org/docs/UsersManual.html#profile-guided-optimization).
|
||||||
|
|
||||||
|
If you are going to collect a sample workload directly from a production environment, we recommend trying to use Sampling PGO.
|
||||||
@ -7,6 +7,10 @@ pagination_next: en/operations/settings/settings
|
|||||||
|
|
||||||
# Settings Overview
|
# Settings Overview
|
||||||
|
|
||||||
|
:::note
|
||||||
|
XML-based Settings Profiles and [configuration files](https://clickhouse.com/docs/en/operations/configuration-files) are currently not supported for ClickHouse Cloud. To specify settings for your ClickHouse Cloud service, you must use [SQL-driven Settings Profiles](https://clickhouse.com/docs/en/operations/access-rights#settings-profiles-management).
|
||||||
|
:::
|
||||||
|
|
||||||
There are two main groups of ClickHouse settings:
|
There are two main groups of ClickHouse settings:
|
||||||
|
|
||||||
- Global server settings
|
- Global server settings
|
||||||
|
|||||||
@ -298,7 +298,7 @@ Default value: `THROW`.
|
|||||||
- [JOIN clause](../../sql-reference/statements/select/join.md#select-join)
|
- [JOIN clause](../../sql-reference/statements/select/join.md#select-join)
|
||||||
- [Join table engine](../../engines/table-engines/special/join.md)
|
- [Join table engine](../../engines/table-engines/special/join.md)
|
||||||
|
|
||||||
## max_partitions_per_insert_block {#max-partitions-per-insert-block}
|
## max_partitions_per_insert_block {#settings-max_partitions_per_insert_block}
|
||||||
|
|
||||||
Limits the maximum number of partitions in a single inserted block.
|
Limits the maximum number of partitions in a single inserted block.
|
||||||
|
|
||||||
@ -309,9 +309,18 @@ Default value: 100.
|
|||||||
|
|
||||||
**Details**
|
**Details**
|
||||||
|
|
||||||
When inserting data, ClickHouse calculates the number of partitions in the inserted block. If the number of partitions is more than `max_partitions_per_insert_block`, ClickHouse throws an exception with the following text:
|
When inserting data, ClickHouse calculates the number of partitions in the inserted block. If the number of partitions is more than `max_partitions_per_insert_block`, ClickHouse either logs a warning or throws an exception based on `throw_on_max_partitions_per_insert_block`. Exceptions have the following text:
|
||||||
|
|
||||||
> “Too many partitions for single INSERT block (more than” + toString(max_parts) + “). The limit is controlled by ‘max_partitions_per_insert_block’ setting. A large number of partitions is a common misconception. It will lead to severe negative performance impact, including slow server startup, slow INSERT queries and slow SELECT queries. Recommended total number of partitions for a table is under 1000..10000. Please note, that partitioning is not intended to speed up SELECT queries (ORDER BY key is sufficient to make range queries fast). Partitions are intended for data manipulation (DROP PARTITION, etc).”
|
> “Too many partitions for a single INSERT block (`partitions_count` partitions, limit is ” + toString(max_partitions) + “). The limit is controlled by the ‘max_partitions_per_insert_block’ setting. A large number of partitions is a common misconception. It will lead to severe negative performance impact, including slow server startup, slow INSERT queries and slow SELECT queries. Recommended total number of partitions for a table is under 1000..10000. Please note, that partitioning is not intended to speed up SELECT queries (ORDER BY key is sufficient to make range queries fast). Partitions are intended for data manipulation (DROP PARTITION, etc).”
|
||||||
|
|
||||||
|
## throw_on_max_partitions_per_insert_block {#settings-throw_on_max_partition_per_insert_block}
|
||||||
|
|
||||||
|
Allows you to control behaviour when `max_partitions_per_insert_block` is reached.
|
||||||
|
|
||||||
|
- `true` - When an insert block reaches `max_partitions_per_insert_block`, an exception is raised.
|
||||||
|
- `false` - Logs a warning when `max_partitions_per_insert_block` is reached.
|
||||||
|
|
||||||
|
Default value: `true`
|
||||||
|
|
||||||
## max_temporary_data_on_disk_size_for_user {#settings_max_temporary_data_on_disk_size_for_user}
|
## max_temporary_data_on_disk_size_for_user {#settings_max_temporary_data_on_disk_size_for_user}
|
||||||
|
|
||||||
|
|||||||
@ -321,6 +321,10 @@ If both `input_format_allow_errors_num` and `input_format_allow_errors_ratio` ar
|
|||||||
|
|
||||||
This parameter is useful when you are using formats that require a schema definition, such as [Cap’n Proto](https://capnproto.org/) or [Protobuf](https://developers.google.com/protocol-buffers/). The value depends on the format.
|
This parameter is useful when you are using formats that require a schema definition, such as [Cap’n Proto](https://capnproto.org/) or [Protobuf](https://developers.google.com/protocol-buffers/). The value depends on the format.
|
||||||
|
|
||||||
|
## output_format_schema {#output-format-schema}
|
||||||
|
|
||||||
|
The path to the file where the automatically generated schema will be saved in [Cap’n Proto](../../interfaces/formats.md#capnproto-capnproto) or [Protobuf](../../interfaces/formats.md#protobuf-protobuf) formats.
|
||||||
|
|
||||||
## output_format_enable_streaming {#output_format_enable_streaming}
|
## output_format_enable_streaming {#output_format_enable_streaming}
|
||||||
|
|
||||||
Enable streaming in output formats that support it.
|
Enable streaming in output formats that support it.
|
||||||
@ -1108,17 +1112,6 @@ Default value: 1.
|
|||||||
|
|
||||||
## Arrow format settings {#arrow-format-settings}
|
## Arrow format settings {#arrow-format-settings}
|
||||||
|
|
||||||
### input_format_arrow_import_nested {#input_format_arrow_import_nested}
|
|
||||||
|
|
||||||
Enables or disables the ability to insert the data into [Nested](../../sql-reference/data-types/nested-data-structures/index.md) columns as an array of structs in [Arrow](../../interfaces/formats.md/#data_types-matching-arrow) input format.
|
|
||||||
|
|
||||||
Possible values:
|
|
||||||
|
|
||||||
- 0 — Data can not be inserted into `Nested` columns as an array of structs.
|
|
||||||
- 1 — Data can be inserted into `Nested` columns as an array of structs.
|
|
||||||
|
|
||||||
Default value: `0`.
|
|
||||||
|
|
||||||
### input_format_arrow_case_insensitive_column_matching {#input_format_arrow_case_insensitive_column_matching}
|
### input_format_arrow_case_insensitive_column_matching {#input_format_arrow_case_insensitive_column_matching}
|
||||||
|
|
||||||
Ignore case when matching Arrow column names with ClickHouse column names.
|
Ignore case when matching Arrow column names with ClickHouse column names.
|
||||||
@ -1168,17 +1161,6 @@ Default value: `lz4_frame`.
|
|||||||
|
|
||||||
## ORC format settings {#orc-format-settings}
|
## ORC format settings {#orc-format-settings}
|
||||||
|
|
||||||
### input_format_orc_import_nested {#input_format_orc_import_nested}
|
|
||||||
|
|
||||||
Enables or disables the ability to insert the data into [Nested](../../sql-reference/data-types/nested-data-structures/index.md) columns as an array of structs in [ORC](../../interfaces/formats.md/#data-format-orc) input format.
|
|
||||||
|
|
||||||
Possible values:
|
|
||||||
|
|
||||||
- 0 — Data can not be inserted into `Nested` columns as an array of structs.
|
|
||||||
- 1 — Data can be inserted into `Nested` columns as an array of structs.
|
|
||||||
|
|
||||||
Default value: `0`.
|
|
||||||
|
|
||||||
### input_format_orc_row_batch_size {#input_format_orc_row_batch_size}
|
### input_format_orc_row_batch_size {#input_format_orc_row_batch_size}
|
||||||
|
|
||||||
Batch size when reading ORC stripes.
|
Batch size when reading ORC stripes.
|
||||||
@ -1217,17 +1199,6 @@ Default value: `none`.
|
|||||||
|
|
||||||
## Parquet format settings {#parquet-format-settings}
|
## Parquet format settings {#parquet-format-settings}
|
||||||
|
|
||||||
### input_format_parquet_import_nested {#input_format_parquet_import_nested}
|
|
||||||
|
|
||||||
Enables or disables the ability to insert the data into [Nested](../../sql-reference/data-types/nested-data-structures/index.md) columns as an array of structs in [Parquet](../../interfaces/formats.md/#data-format-parquet) input format.
|
|
||||||
|
|
||||||
Possible values:
|
|
||||||
|
|
||||||
- 0 — Data can not be inserted into `Nested` columns as an array of structs.
|
|
||||||
- 1 — Data can be inserted into `Nested` columns as an array of structs.
|
|
||||||
|
|
||||||
Default value: `0`.
|
|
||||||
|
|
||||||
### input_format_parquet_case_insensitive_column_matching {#input_format_parquet_case_insensitive_column_matching}
|
### input_format_parquet_case_insensitive_column_matching {#input_format_parquet_case_insensitive_column_matching}
|
||||||
|
|
||||||
Ignore case when matching Parquet column names with ClickHouse column names.
|
Ignore case when matching Parquet column names with ClickHouse column names.
|
||||||
@ -1330,6 +1301,11 @@ When serializing Nullable columns with Google wrappers, serialize default values
|
|||||||
|
|
||||||
Disabled by default.
|
Disabled by default.
|
||||||
|
|
||||||
|
### format_protobuf_use_autogenerated_schema {#format_capn_proto_use_autogenerated_schema}
|
||||||
|
|
||||||
|
Use autogenerated Protobuf schema when [format_schema](#formatschema-format-schema) is not set.
|
||||||
|
The schema is generated from ClickHouse table structure using function [structureToProtobufSchema](../../sql-reference/functions/other-functions.md#structure_to_protobuf_schema)
|
||||||
|
|
||||||
## Avro format settings {#avro-format-settings}
|
## Avro format settings {#avro-format-settings}
|
||||||
|
|
||||||
### input_format_avro_allow_missing_fields {#input_format_avro_allow_missing_fields}
|
### input_format_avro_allow_missing_fields {#input_format_avro_allow_missing_fields}
|
||||||
@ -1626,6 +1602,11 @@ Possible values:
|
|||||||
|
|
||||||
Default value: `'by_values'`.
|
Default value: `'by_values'`.
|
||||||
|
|
||||||
|
### format_capn_proto_use_autogenerated_schema {#format_capn_proto_use_autogenerated_schema}
|
||||||
|
|
||||||
|
Use autogenerated CapnProto schema when [format_schema](#formatschema-format-schema) is not set.
|
||||||
|
The schema is generated from ClickHouse table structure using function [structureToCapnProtoSchema](../../sql-reference/functions/other-functions.md#structure_to_capnproto_schema)
|
||||||
|
|
||||||
## MySQLDump format settings {#musqldump-format-settings}
|
## MySQLDump format settings {#musqldump-format-settings}
|
||||||
|
|
||||||
### input_format_mysql_dump_table_name (#input_format_mysql_dump_table_name)
|
### input_format_mysql_dump_table_name (#input_format_mysql_dump_table_name)
|
||||||
|
|||||||
@ -3468,11 +3468,11 @@ Possible values:
|
|||||||
|
|
||||||
Default value: `0`.
|
Default value: `0`.
|
||||||
|
|
||||||
## disable_url_encoding {#disable_url_encoding}
|
## enable_url_encoding {#enable_url_encoding}
|
||||||
|
|
||||||
Allows to disable decoding/encoding path in uri in [URL](../../engines/table-engines/special/url.md) engine tables.
|
Allows to enable/disable decoding/encoding path in uri in [URL](../../engines/table-engines/special/url.md) engine tables.
|
||||||
|
|
||||||
Disabled by default.
|
Enabled by default.
|
||||||
|
|
||||||
## database_atomic_wait_for_drop_and_detach_synchronously {#database_atomic_wait_for_drop_and_detach_synchronously}
|
## database_atomic_wait_for_drop_and_detach_synchronously {#database_atomic_wait_for_drop_and_detach_synchronously}
|
||||||
|
|
||||||
@ -4578,3 +4578,39 @@ Type: Int64
|
|||||||
|
|
||||||
Default: 0
|
Default: 0
|
||||||
|
|
||||||
|
## rewrite_count_distinct_if_with_count_distinct_implementation
|
||||||
|
|
||||||
|
Allows you to rewrite `countDistcintIf` with [count_distinct_implementation](#settings-count_distinct_implementation) setting.
|
||||||
|
|
||||||
|
Possible values:
|
||||||
|
|
||||||
|
- true — Allow.
|
||||||
|
- false — Disallow.
|
||||||
|
|
||||||
|
Default value: `false`.
|
||||||
|
|
||||||
|
## precise_float_parsing {#precise_float_parsing}
|
||||||
|
|
||||||
|
Switches [Float32/Float64](../../sql-reference/data-types/float.md) parsing algorithms:
|
||||||
|
* If the value is `1`, then precise method is used. It is slower than fast method, but it always returns a number that is the closest machine representable number to the input.
|
||||||
|
* Otherwise, fast method is used (default). It usually returns the same value as precise, but in rare cases result may differ by one or two least significant digits.
|
||||||
|
|
||||||
|
Possible values: `0`, `1`.
|
||||||
|
|
||||||
|
Default value: `0`.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
```sql
|
||||||
|
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 0;
|
||||||
|
|
||||||
|
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||||
|
│ 1.7090999999999998 │ 15008753.000000002 │
|
||||||
|
└─────────────────────┴──────────────────────────┘
|
||||||
|
|
||||||
|
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 1;
|
||||||
|
|
||||||
|
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||||
|
│ 1.7091 │ 15008753 │
|
||||||
|
└─────────────────────┴──────────────────────────┘
|
||||||
|
```
|
||||||
|
|||||||
@ -48,7 +48,7 @@ Columns:
|
|||||||
- `read_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of rows read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_rows` includes the total number of rows read at all replicas. Each replica sends it’s `read_rows` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
- `read_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of rows read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_rows` includes the total number of rows read at all replicas. Each replica sends it’s `read_rows` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
||||||
- `read_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of bytes read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_bytes` includes the total number of rows read at all replicas. Each replica sends it’s `read_bytes` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
- `read_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of bytes read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_bytes` includes the total number of rows read at all replicas. Each replica sends it’s `read_bytes` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
||||||
- `written_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written rows. For other queries, the column value is 0.
|
- `written_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written rows. For other queries, the column value is 0.
|
||||||
- `written_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written bytes. For other queries, the column value is 0.
|
- `written_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written bytes (uncompressed). For other queries, the column value is 0.
|
||||||
- `result_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Number of rows in a result of the `SELECT` query, or a number of rows in the `INSERT` query.
|
- `result_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Number of rows in a result of the `SELECT` query, or a number of rows in the `INSERT` query.
|
||||||
- `result_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — RAM volume in bytes used to store a query result.
|
- `result_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — RAM volume in bytes used to store a query result.
|
||||||
- `memory_usage` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Memory consumption by the query.
|
- `memory_usage` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Memory consumption by the query.
|
||||||
|
|||||||
@ -11,7 +11,7 @@ A client application to interact with clickhouse-keeper by its native protocol.
|
|||||||
|
|
||||||
- `-q QUERY`, `--query=QUERY` — Query to execute. If this parameter is not passed, `clickhouse-keeper-client` will start in interactive mode.
|
- `-q QUERY`, `--query=QUERY` — Query to execute. If this parameter is not passed, `clickhouse-keeper-client` will start in interactive mode.
|
||||||
- `-h HOST`, `--host=HOST` — Server host. Default value: `localhost`.
|
- `-h HOST`, `--host=HOST` — Server host. Default value: `localhost`.
|
||||||
- `-p N`, `--port=N` — Server port. Default value: 2181
|
- `-p N`, `--port=N` — Server port. Default value: 9181
|
||||||
- `--connection-timeout=TIMEOUT` — Set connection timeout in seconds. Default value: 10s.
|
- `--connection-timeout=TIMEOUT` — Set connection timeout in seconds. Default value: 10s.
|
||||||
- `--session-timeout=TIMEOUT` — Set session timeout in seconds. Default value: 10s.
|
- `--session-timeout=TIMEOUT` — Set session timeout in seconds. Default value: 10s.
|
||||||
- `--operation-timeout=TIMEOUT` — Set operation timeout in seconds. Default value: 10s.
|
- `--operation-timeout=TIMEOUT` — Set operation timeout in seconds. Default value: 10s.
|
||||||
@ -21,8 +21,8 @@ A client application to interact with clickhouse-keeper by its native protocol.
|
|||||||
## Example {#clickhouse-keeper-client-example}
|
## Example {#clickhouse-keeper-client-example}
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
./clickhouse-keeper-client -h localhost:2181 --connection-timeout 30 --session-timeout 30 --operation-timeout 30
|
./clickhouse-keeper-client -h localhost:9181 --connection-timeout 30 --session-timeout 30 --operation-timeout 30
|
||||||
Connected to ZooKeeper at [::1]:2181 with session_id 137
|
Connected to ZooKeeper at [::1]:9181 with session_id 137
|
||||||
/ :) ls
|
/ :) ls
|
||||||
keeper foo bar
|
keeper foo bar
|
||||||
/ :) cd keeper
|
/ :) cd keeper
|
||||||
|
|||||||
@ -34,7 +34,13 @@ The binary you just downloaded can run all sorts of ClickHouse tools and utiliti
|
|||||||
|
|
||||||
A common use of `clickhouse-local` is to run ad-hoc queries on files: where you don't have to insert the data into a table. `clickhouse-local` can stream the data from a file into a temporary table and execute your SQL.
|
A common use of `clickhouse-local` is to run ad-hoc queries on files: where you don't have to insert the data into a table. `clickhouse-local` can stream the data from a file into a temporary table and execute your SQL.
|
||||||
|
|
||||||
If the file is sitting on the same machine as `clickhouse-local`, use the `file` table engine. The following `reviews.tsv` file contains a sampling of Amazon product reviews:
|
If the file is sitting on the same machine as `clickhouse-local`, you can simple specify the file to load. The following `reviews.tsv` file contains a sampling of Amazon product reviews:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
./clickhouse local -q "SELECT * FROM 'reviews.tsv'"
|
||||||
|
```
|
||||||
|
|
||||||
|
This command is a shortcut of:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
./clickhouse local -q "SELECT * FROM file('reviews.tsv')"
|
./clickhouse local -q "SELECT * FROM file('reviews.tsv')"
|
||||||
|
|||||||
@ -6,42 +6,42 @@ sidebar_label: UUID
|
|||||||
|
|
||||||
# UUID
|
# UUID
|
||||||
|
|
||||||
A universally unique identifier (UUID) is a 16-byte number used to identify records. For detailed information about the UUID, see [Wikipedia](https://en.wikipedia.org/wiki/Universally_unique_identifier).
|
A Universally Unique Identifier (UUID) is a 16-byte value used to identify records. For detailed information about UUIDs, see [Wikipedia](https://en.wikipedia.org/wiki/Universally_unique_identifier).
|
||||||
|
|
||||||
The example of UUID type value is represented below:
|
While different UUID variants exist (see [here](https://datatracker.ietf.org/doc/html/draft-ietf-uuidrev-rfc4122bis)), ClickHouse does not validate that inserted UUIDs conform to a particular variant. UUIDs are internally treated as a sequence of 16 random bytes with [8-4-4-4-12 representation](https://en.wikipedia.org/wiki/Universally_unique_identifier#Textual_representation) at SQL level.
|
||||||
|
|
||||||
|
Example UUID value:
|
||||||
|
|
||||||
``` text
|
``` text
|
||||||
61f0c404-5cb3-11e7-907b-a6006ad3dba0
|
61f0c404-5cb3-11e7-907b-a6006ad3dba0
|
||||||
```
|
```
|
||||||
|
|
||||||
If you do not specify the UUID column value when inserting a new record, the UUID value is filled with zero:
|
The default UUID is all-zero. It is used, for example, when a new record is inserted but no value for a UUID column is specified:
|
||||||
|
|
||||||
``` text
|
``` text
|
||||||
00000000-0000-0000-0000-000000000000
|
00000000-0000-0000-0000-000000000000
|
||||||
```
|
```
|
||||||
|
|
||||||
## How to Generate
|
## Generating UUIDs
|
||||||
|
|
||||||
To generate the UUID value, ClickHouse provides the [generateUUIDv4](../../sql-reference/functions/uuid-functions.md) function.
|
ClickHouse provides the [generateUUIDv4](../../sql-reference/functions/uuid-functions.md) function to generate random UUID version 4 values.
|
||||||
|
|
||||||
## Usage Example
|
## Usage Example
|
||||||
|
|
||||||
**Example 1**
|
**Example 1**
|
||||||
|
|
||||||
This example demonstrates creating a table with the UUID type column and inserting a value into the table.
|
This example demonstrates the creation of a table with a UUID column and the insertion of a value into the table.
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
CREATE TABLE t_uuid (x UUID, y String) ENGINE=TinyLog
|
CREATE TABLE t_uuid (x UUID, y String) ENGINE=TinyLog
|
||||||
```
|
|
||||||
|
|
||||||
``` sql
|
|
||||||
INSERT INTO t_uuid SELECT generateUUIDv4(), 'Example 1'
|
INSERT INTO t_uuid SELECT generateUUIDv4(), 'Example 1'
|
||||||
```
|
|
||||||
|
|
||||||
``` sql
|
|
||||||
SELECT * FROM t_uuid
|
SELECT * FROM t_uuid
|
||||||
```
|
```
|
||||||
|
|
||||||
|
Result:
|
||||||
|
|
||||||
``` text
|
``` text
|
||||||
┌────────────────────────────────────x─┬─y─────────┐
|
┌────────────────────────────────────x─┬─y─────────┐
|
||||||
│ 417ddc5d-e556-4d27-95dd-a34d84e46a50 │ Example 1 │
|
│ 417ddc5d-e556-4d27-95dd-a34d84e46a50 │ Example 1 │
|
||||||
@ -50,13 +50,11 @@ SELECT * FROM t_uuid
|
|||||||
|
|
||||||
**Example 2**
|
**Example 2**
|
||||||
|
|
||||||
In this example, the UUID column value is not specified when inserting a new record.
|
In this example, no UUID column value is specified when the record is inserted, i.e. the default UUID value is inserted:
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO t_uuid (y) VALUES ('Example 2')
|
INSERT INTO t_uuid (y) VALUES ('Example 2')
|
||||||
```
|
|
||||||
|
|
||||||
``` sql
|
|
||||||
SELECT * FROM t_uuid
|
SELECT * FROM t_uuid
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@ -18,7 +18,7 @@ file(path[, default])
|
|||||||
|
|
||||||
**Arguments**
|
**Arguments**
|
||||||
|
|
||||||
- `path` — The path of the file relative to [user_files_path](../../operations/server-configuration-parameters/settings.md#server_configuration_parameters-user_files_path). Supports wildcards `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` are numbers and `'abc', 'def'` are strings.
|
- `path` — The path of the file relative to [user_files_path](../../operations/server-configuration-parameters/settings.md#server_configuration_parameters-user_files_path). Supports wildcards `*`, `**`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` are numbers and `'abc', 'def'` are strings.
|
||||||
- `default` — The value returned if the file does not exist or cannot be accessed. Supported data types: [String](../../sql-reference/data-types/string.md) and [NULL](../../sql-reference/syntax.md#null-literal).
|
- `default` — The value returned if the file does not exist or cannot be accessed. Supported data types: [String](../../sql-reference/data-types/string.md) and [NULL](../../sql-reference/syntax.md#null-literal).
|
||||||
|
|
||||||
**Example**
|
**Example**
|
||||||
|
|||||||
@ -2552,3 +2552,187 @@ Result:
|
|||||||
|
|
||||||
This function can be used together with [generateRandom](../../sql-reference/table-functions/generate.md) to generate completely random tables.
|
This function can be used together with [generateRandom](../../sql-reference/table-functions/generate.md) to generate completely random tables.
|
||||||
|
|
||||||
|
## structureToCapnProtoSchema {#structure_to_capn_proto_schema}
|
||||||
|
|
||||||
|
Converts ClickHouse table structure to CapnProto schema.
|
||||||
|
|
||||||
|
**Syntax**
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
structureToCapnProtoSchema(structure)
|
||||||
|
```
|
||||||
|
|
||||||
|
**Arguments**
|
||||||
|
|
||||||
|
- `structure` — Table structure in a format `column1_name column1_type, column2_name column2_type, ...`.
|
||||||
|
- `root_struct_name` — Name for root struct in CapnProto schema. Default value - `Message`;
|
||||||
|
|
||||||
|
**Returned value**
|
||||||
|
|
||||||
|
- CapnProto schema
|
||||||
|
|
||||||
|
Type: [String](../../sql-reference/data-types/string.md).
|
||||||
|
|
||||||
|
**Examples**
|
||||||
|
|
||||||
|
Query:
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
SELECT structureToCapnProtoSchema('column1 String, column2 UInt32, column3 Array(String)') FORMAT RawBLOB
|
||||||
|
```
|
||||||
|
|
||||||
|
Result:
|
||||||
|
|
||||||
|
``` text
|
||||||
|
@0xf96402dd754d0eb7;
|
||||||
|
|
||||||
|
struct Message
|
||||||
|
{
|
||||||
|
column1 @0 : Data;
|
||||||
|
column2 @1 : UInt32;
|
||||||
|
column3 @2 : List(Data);
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Query:
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
SELECT structureToCapnProtoSchema('column1 Nullable(String), column2 Tuple(element1 UInt32, element2 Array(String)), column3 Map(String, String)') FORMAT RawBLOB
|
||||||
|
```
|
||||||
|
|
||||||
|
Result:
|
||||||
|
|
||||||
|
``` text
|
||||||
|
@0xd1c8320fecad2b7f;
|
||||||
|
|
||||||
|
struct Message
|
||||||
|
{
|
||||||
|
struct Column1
|
||||||
|
{
|
||||||
|
union
|
||||||
|
{
|
||||||
|
value @0 : Data;
|
||||||
|
null @1 : Void;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
column1 @0 : Column1;
|
||||||
|
struct Column2
|
||||||
|
{
|
||||||
|
element1 @0 : UInt32;
|
||||||
|
element2 @1 : List(Data);
|
||||||
|
}
|
||||||
|
column2 @1 : Column2;
|
||||||
|
struct Column3
|
||||||
|
{
|
||||||
|
struct Entry
|
||||||
|
{
|
||||||
|
key @0 : Data;
|
||||||
|
value @1 : Data;
|
||||||
|
}
|
||||||
|
entries @0 : List(Entry);
|
||||||
|
}
|
||||||
|
column3 @2 : Column3;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Query:
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
SELECT structureToCapnProtoSchema('column1 String, column2 UInt32', 'Root') FORMAT RawBLOB
|
||||||
|
```
|
||||||
|
|
||||||
|
Result:
|
||||||
|
|
||||||
|
``` text
|
||||||
|
@0x96ab2d4ab133c6e1;
|
||||||
|
|
||||||
|
struct Root
|
||||||
|
{
|
||||||
|
column1 @0 : Data;
|
||||||
|
column2 @1 : UInt32;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## structureToProtobufSchema {#structure_to_protobuf_schema}
|
||||||
|
|
||||||
|
Converts ClickHouse table structure to Protobuf schema.
|
||||||
|
|
||||||
|
**Syntax**
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
structureToProtobufSchema(structure)
|
||||||
|
```
|
||||||
|
|
||||||
|
**Arguments**
|
||||||
|
|
||||||
|
- `structure` — Table structure in a format `column1_name column1_type, column2_name column2_type, ...`.
|
||||||
|
- `root_message_name` — Name for root message in Protobuf schema. Default value - `Message`;
|
||||||
|
|
||||||
|
**Returned value**
|
||||||
|
|
||||||
|
- Protobuf schema
|
||||||
|
|
||||||
|
Type: [String](../../sql-reference/data-types/string.md).
|
||||||
|
|
||||||
|
**Examples**
|
||||||
|
|
||||||
|
Query:
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
SELECT structureToProtobufSchema('column1 String, column2 UInt32, column3 Array(String)') FORMAT RawBLOB
|
||||||
|
```
|
||||||
|
|
||||||
|
Result:
|
||||||
|
|
||||||
|
``` text
|
||||||
|
syntax = "proto3";
|
||||||
|
|
||||||
|
message Message
|
||||||
|
{
|
||||||
|
bytes column1 = 1;
|
||||||
|
uint32 column2 = 2;
|
||||||
|
repeated bytes column3 = 3;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Query:
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
SELECT structureToProtobufSchema('column1 Nullable(String), column2 Tuple(element1 UInt32, element2 Array(String)), column3 Map(String, String)') FORMAT RawBLOB
|
||||||
|
```
|
||||||
|
|
||||||
|
Result:
|
||||||
|
|
||||||
|
``` text
|
||||||
|
syntax = "proto3";
|
||||||
|
|
||||||
|
message Message
|
||||||
|
{
|
||||||
|
bytes column1 = 1;
|
||||||
|
message Column2
|
||||||
|
{
|
||||||
|
uint32 element1 = 1;
|
||||||
|
repeated bytes element2 = 2;
|
||||||
|
}
|
||||||
|
Column2 column2 = 2;
|
||||||
|
map<string, bytes> column3 = 3;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Query:
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
SELECT structureToProtobufSchema('column1 String, column2 UInt32', 'Root') FORMAT RawBLOB
|
||||||
|
```
|
||||||
|
|
||||||
|
Result:
|
||||||
|
|
||||||
|
``` text
|
||||||
|
syntax = "proto3";
|
||||||
|
|
||||||
|
message Root
|
||||||
|
{
|
||||||
|
bytes column1 = 1;
|
||||||
|
uint32 column2 = 2;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|||||||
@ -36,6 +36,8 @@ These `ALTER` statements modify entities related to role-based access control:
|
|||||||
|
|
||||||
[ALTER TABLE ... MODIFY COMMENT](/docs/en/sql-reference/statements/alter/comment.md) statement adds, modifies, or removes comments to the table, regardless if it was set before or not.
|
[ALTER TABLE ... MODIFY COMMENT](/docs/en/sql-reference/statements/alter/comment.md) statement adds, modifies, or removes comments to the table, regardless if it was set before or not.
|
||||||
|
|
||||||
|
[ALTER NAMED COLLECTION](/docs/en/sql-reference/statements/alter/named-collection.md) statement modifies [Named Collections](/docs/en/operations/named-collections.md).
|
||||||
|
|
||||||
## Mutations
|
## Mutations
|
||||||
|
|
||||||
`ALTER` queries that are intended to manipulate table data are implemented with a mechanism called “mutations”, most notably [ALTER TABLE … DELETE](/docs/en/sql-reference/statements/alter/delete.md) and [ALTER TABLE … UPDATE](/docs/en/sql-reference/statements/alter/update.md). They are asynchronous background processes similar to merges in [MergeTree](/docs/en/engines/table-engines/mergetree-family/index.md) tables that to produce new “mutated” versions of parts.
|
`ALTER` queries that are intended to manipulate table data are implemented with a mechanism called “mutations”, most notably [ALTER TABLE … DELETE](/docs/en/sql-reference/statements/alter/delete.md) and [ALTER TABLE … UPDATE](/docs/en/sql-reference/statements/alter/update.md). They are asynchronous background processes similar to merges in [MergeTree](/docs/en/engines/table-engines/mergetree-family/index.md) tables that to produce new “mutated” versions of parts.
|
||||||
|
|||||||
30
docs/en/sql-reference/statements/alter/named-collection.md
Normal file
30
docs/en/sql-reference/statements/alter/named-collection.md
Normal file
@ -0,0 +1,30 @@
|
|||||||
|
---
|
||||||
|
slug: /en/sql-reference/statements/alter/named-collection
|
||||||
|
sidebar_label: NAMED COLLECTION
|
||||||
|
---
|
||||||
|
|
||||||
|
# ALTER NAMED COLLECTION
|
||||||
|
|
||||||
|
This query intends to modify already existing named collections.
|
||||||
|
|
||||||
|
**Syntax**
|
||||||
|
|
||||||
|
```sql
|
||||||
|
ALTER NAMED COLLECTION [IF EXISTS] name [ON CLUSTER cluster]
|
||||||
|
[ SET
|
||||||
|
key_name1 = 'some value',
|
||||||
|
key_name2 = 'some value',
|
||||||
|
key_name3 = 'some value',
|
||||||
|
... ] |
|
||||||
|
[ DELETE key_name4, key_name5, ... ]
|
||||||
|
```
|
||||||
|
|
||||||
|
**Example**
|
||||||
|
|
||||||
|
```sql
|
||||||
|
CREATE NAMED COLLECTION foobar AS a = '1', b = '2';
|
||||||
|
|
||||||
|
ALTER NAMED COLLECTION foobar SET a = '2', c = '3';
|
||||||
|
|
||||||
|
ALTER NAMED COLLECTION foobar DELETE b;
|
||||||
|
```
|
||||||
@ -5,19 +5,38 @@ sidebar_label: CHECK TABLE
|
|||||||
title: "CHECK TABLE Statement"
|
title: "CHECK TABLE Statement"
|
||||||
---
|
---
|
||||||
|
|
||||||
Checks if the data in the table is corrupted.
|
The `CHECK TABLE` query in ClickHouse is used to perform a validation check on a specific table or its partitions. It ensures the integrity of the data by verifying the checksums and other internal data structures.
|
||||||
|
|
||||||
``` sql
|
Particularly it compares actual file sizes with the expected values which are stored on the server. If the file sizes do not match the stored values, it means the data is corrupted. This can be caused, for example, by a system crash during query execution.
|
||||||
CHECK TABLE [db.]name [PARTITION partition_expr]
|
|
||||||
|
:::note
|
||||||
|
The `CHECK TABLE`` query may read all the data in the table and hold some resources, making it resource-intensive.
|
||||||
|
Consider the potential impact on performance and resource utilization before executing this query.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Syntax
|
||||||
|
|
||||||
|
The basic syntax of the query is as follows:
|
||||||
|
|
||||||
|
```sql
|
||||||
|
CHECK TABLE table_name [PARTITION partition_expression] [FORMAT format] [SETTINGS check_query_single_value_result = (0|1) [, other_settings] ]
|
||||||
```
|
```
|
||||||
|
|
||||||
The `CHECK TABLE` query compares actual file sizes with the expected values which are stored on the server. If the file sizes do not match the stored values, it means the data is corrupted. This can be caused, for example, by a system crash during query execution.
|
- `table_name`: Specifies the name of the table that you want to check.
|
||||||
|
- `partition_expression`: (Optional) If you want to check a specific partition of the table, you can use this expression to specify the partition.
|
||||||
|
- `FORMAT format`: (Optional) Allows you to specify the output format of the result.
|
||||||
|
- `SETTINGS`: (Optional) Allows additional settings.
|
||||||
|
- **`check_query_single_value_result`**: (Optional) This setting allows you to toggle between a detailed result (`0`) or a summarized result (`1`).
|
||||||
|
- Other settings (e.g. `max_threads` can be applied as well).
|
||||||
|
|
||||||
The query response contains the `result` column with a single row. The row has a value of
|
|
||||||
[Boolean](../../sql-reference/data-types/boolean.md) type:
|
|
||||||
|
|
||||||
- 0 - The data in the table is corrupted.
|
The query response depends on the value of contains `check_query_single_value_result` setting.
|
||||||
- 1 - The data maintains integrity.
|
In case of `check_query_single_value_result = 1` only `result` column with a single row is returned. Value inside this row is `1` if the integrity check is passed and `0` if data is corrupted.
|
||||||
|
|
||||||
|
With `check_query_single_value_result = 0` the query returns the following columns:
|
||||||
|
- `part_path`: Indicates the path to the data part or file name.
|
||||||
|
- `is_passed`: Returns 1 if the check for this part is successful, 0 otherwise.
|
||||||
|
- `message`: Any additional messages related to the check, such as errors or success messages.
|
||||||
|
|
||||||
The `CHECK TABLE` query supports the following table engines:
|
The `CHECK TABLE` query supports the following table engines:
|
||||||
|
|
||||||
@ -26,30 +45,15 @@ The `CHECK TABLE` query supports the following table engines:
|
|||||||
- [StripeLog](../../engines/table-engines/log-family/stripelog.md)
|
- [StripeLog](../../engines/table-engines/log-family/stripelog.md)
|
||||||
- [MergeTree family](../../engines/table-engines/mergetree-family/mergetree.md)
|
- [MergeTree family](../../engines/table-engines/mergetree-family/mergetree.md)
|
||||||
|
|
||||||
Performed over the tables with another table engines causes an exception.
|
Performed over the tables with another table engines causes an `NOT_IMPLEMETED` exception.
|
||||||
|
|
||||||
Engines from the `*Log` family do not provide automatic data recovery on failure. Use the `CHECK TABLE` query to track data loss in a timely manner.
|
Engines from the `*Log` family do not provide automatic data recovery on failure. Use the `CHECK TABLE` query to track data loss in a timely manner.
|
||||||
|
|
||||||
## Checking the MergeTree Family Tables
|
## Examples
|
||||||
|
|
||||||
For `MergeTree` family engines, if [check_query_single_value_result](../../operations/settings/settings.md#check_query_single_value_result) = 0, the `CHECK TABLE` query shows a check status for every individual data part of a table on the local server.
|
By default `CHECK TABLE` query shows the general table check status:
|
||||||
|
|
||||||
```sql
|
```sql
|
||||||
SET check_query_single_value_result = 0;
|
|
||||||
CHECK TABLE test_table;
|
|
||||||
```
|
|
||||||
|
|
||||||
```text
|
|
||||||
┌─part_path─┬─is_passed─┬─message─┐
|
|
||||||
│ all_1_4_1 │ 1 │ │
|
|
||||||
│ all_1_4_2 │ 1 │ │
|
|
||||||
└───────────┴───────────┴─────────┘
|
|
||||||
```
|
|
||||||
|
|
||||||
If `check_query_single_value_result` = 1, the `CHECK TABLE` query shows the general table check status.
|
|
||||||
|
|
||||||
```sql
|
|
||||||
SET check_query_single_value_result = 1;
|
|
||||||
CHECK TABLE test_table;
|
CHECK TABLE test_table;
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -59,11 +63,60 @@ CHECK TABLE test_table;
|
|||||||
└────────┘
|
└────────┘
|
||||||
```
|
```
|
||||||
|
|
||||||
|
If you want to see the check status for every individual data part you may use `check_query_single_value_result` setting.
|
||||||
|
|
||||||
|
Also, to check a specific partition of the table, you can use the `PARTITION` keyword.
|
||||||
|
|
||||||
|
```sql
|
||||||
|
CHECK TABLE t0 PARTITION ID '201003'
|
||||||
|
FORMAT PrettyCompactMonoBlock
|
||||||
|
SETTINGS check_query_single_value_result = 0
|
||||||
|
```
|
||||||
|
|
||||||
|
Output:
|
||||||
|
|
||||||
|
```text
|
||||||
|
┌─part_path────┬─is_passed─┬─message─┐
|
||||||
|
│ 201003_7_7_0 │ 1 │ │
|
||||||
|
│ 201003_3_3_0 │ 1 │ │
|
||||||
|
└──────────────┴───────────┴─────────┘
|
||||||
|
```
|
||||||
|
|
||||||
|
### Receiving a 'Corrupted' Result
|
||||||
|
|
||||||
|
:::warning
|
||||||
|
Disclaimer: The procedure described here, including the manual manipulating or removing files directly from the data directory, is for experimental or development environments only. Do **not** attempt this on a production server, as it may lead to data loss or other unintended consequences.
|
||||||
|
:::
|
||||||
|
|
||||||
|
Remove the existing checksum file:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
rm /var/lib/clickhouse-server/data/default/t0/201003_3_3_0/checksums.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
```sql
|
||||||
|
CHECK TABLE t0 PARTITION ID '201003'
|
||||||
|
FORMAT PrettyCompactMonoBlock
|
||||||
|
SETTINGS check_query_single_value_result = 0
|
||||||
|
|
||||||
|
|
||||||
|
Output:
|
||||||
|
|
||||||
|
```text
|
||||||
|
┌─part_path────┬─is_passed─┬─message──────────────────────────────────┐
|
||||||
|
│ 201003_7_7_0 │ 1 │ │
|
||||||
|
│ 201003_3_3_0 │ 1 │ Checksums recounted and written to disk. │
|
||||||
|
└──────────────┴───────────┴──────────────────────────────────────────┘
|
||||||
|
```
|
||||||
|
|
||||||
|
If the checksums.txt file is missing, it can be restored. It will be recalculated and rewritten during the execution of the CHECK TABLE command for the specific partition, and the status will still be reported as 'success.'"
|
||||||
|
|
||||||
|
|
||||||
## If the Data Is Corrupted
|
## If the Data Is Corrupted
|
||||||
|
|
||||||
If the table is corrupted, you can copy the non-corrupted data to another table. To do this:
|
If the table is corrupted, you can copy the non-corrupted data to another table. To do this:
|
||||||
|
|
||||||
1. Create a new table with the same structure as damaged table. To do this execute the query `CREATE TABLE <new_table_name> AS <damaged_table_name>`.
|
1. Create a new table with the same structure as damaged table. To do this execute the query `CREATE TABLE <new_table_name> AS <damaged_table_name>`.
|
||||||
2. Set the [max_threads](../../operations/settings/settings.md#settings-max_threads) value to 1 to process the next query in a single thread. To do this run the query `SET max_threads = 1`.
|
2. Set the `max_threads` value to 1 to process the next query in a single thread. To do this run the query `SET max_threads = 1`.
|
||||||
3. Execute the query `INSERT INTO <new_table_name> SELECT * FROM <damaged_table_name>`. This request copies the non-corrupted data from the damaged table to another table. Only the data before the corrupted part will be copied.
|
3. Execute the query `INSERT INTO <new_table_name> SELECT * FROM <damaged_table_name>`. This request copies the non-corrupted data from the damaged table to another table. Only the data before the corrupted part will be copied.
|
||||||
4. Restart the `clickhouse-client` to reset the `max_threads` value.
|
4. Restart the `clickhouse-client` to reset the `max_threads` value.
|
||||||
|
|||||||
@ -8,13 +8,14 @@ sidebar_label: CREATE
|
|||||||
|
|
||||||
Create queries make a new entity of one of the following kinds:
|
Create queries make a new entity of one of the following kinds:
|
||||||
|
|
||||||
- [DATABASE](../../../sql-reference/statements/create/database.md)
|
- [DATABASE](/docs/en/sql-reference/statements/create/database.md)
|
||||||
- [TABLE](../../../sql-reference/statements/create/table.md)
|
- [TABLE](/docs/en/sql-reference/statements/create/table.md)
|
||||||
- [VIEW](../../../sql-reference/statements/create/view.md)
|
- [VIEW](/docs/en/sql-reference/statements/create/view.md)
|
||||||
- [DICTIONARY](../../../sql-reference/statements/create/dictionary.md)
|
- [DICTIONARY](/docs/en/sql-reference/statements/create/dictionary.md)
|
||||||
- [FUNCTION](../../../sql-reference/statements/create/function.md)
|
- [FUNCTION](/docs/en/sql-reference/statements/create/function.md)
|
||||||
- [USER](../../../sql-reference/statements/create/user.md)
|
- [USER](/docs/en/sql-reference/statements/create/user.md)
|
||||||
- [ROLE](../../../sql-reference/statements/create/role.md)
|
- [ROLE](/docs/en/sql-reference/statements/create/role.md)
|
||||||
- [ROW POLICY](../../../sql-reference/statements/create/row-policy.md)
|
- [ROW POLICY](/docs/en/sql-reference/statements/create/row-policy.md)
|
||||||
- [QUOTA](../../../sql-reference/statements/create/quota.md)
|
- [QUOTA](/docs/en/sql-reference/statements/create/quota.md)
|
||||||
- [SETTINGS PROFILE](../../../sql-reference/statements/create/settings-profile.md)
|
- [SETTINGS PROFILE](/docs/en/sql-reference/statements/create/settings-profile.md)
|
||||||
|
- [NAMED COLLECTION](/docs/en/sql-reference/statements/create/named-collection.md)
|
||||||
|
|||||||
34
docs/en/sql-reference/statements/create/named-collection.md
Normal file
34
docs/en/sql-reference/statements/create/named-collection.md
Normal file
@ -0,0 +1,34 @@
|
|||||||
|
---
|
||||||
|
slug: /en/sql-reference/statements/create/named-collection
|
||||||
|
sidebar_label: NAMED COLLECTION
|
||||||
|
---
|
||||||
|
|
||||||
|
# CREATE NAMED COLLECTION
|
||||||
|
|
||||||
|
Creates a new named collection.
|
||||||
|
|
||||||
|
**Syntax**
|
||||||
|
|
||||||
|
```sql
|
||||||
|
CREATE NAMED COLLECTION [IF NOT EXISTS] name [ON CLUSTER cluster] AS
|
||||||
|
key_name1 = 'some value',
|
||||||
|
key_name2 = 'some value',
|
||||||
|
key_name3 = 'some value',
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
**Example**
|
||||||
|
|
||||||
|
```sql
|
||||||
|
CREATE NAMED COLLECTION foobar AS a = '1', b = '2';
|
||||||
|
```
|
||||||
|
|
||||||
|
**Related statements**
|
||||||
|
|
||||||
|
- [CREATE NAMED COLLECTION](https://clickhouse.com/docs/en/sql-reference/statements/alter/named-collection)
|
||||||
|
- [DROP NAMED COLLECTION](https://clickhouse.com/docs/en/sql-reference/statements/drop#drop-function)
|
||||||
|
|
||||||
|
|
||||||
|
**See Also**
|
||||||
|
|
||||||
|
- [Named collections guide](/docs/en/operations/named-collections.md)
|
||||||
@ -119,3 +119,20 @@ DROP FUNCTION [IF EXISTS] function_name [on CLUSTER cluster]
|
|||||||
CREATE FUNCTION linear_equation AS (x, k, b) -> k*x + b;
|
CREATE FUNCTION linear_equation AS (x, k, b) -> k*x + b;
|
||||||
DROP FUNCTION linear_equation;
|
DROP FUNCTION linear_equation;
|
||||||
```
|
```
|
||||||
|
|
||||||
|
## DROP NAMED COLLECTION
|
||||||
|
|
||||||
|
Deletes a named collection.
|
||||||
|
|
||||||
|
**Syntax**
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
DROP NAMED COLLECTION [IF EXISTS] name [on CLUSTER cluster]
|
||||||
|
```
|
||||||
|
|
||||||
|
**Example**
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
CREATE NAMED COLLECTION foobar AS a = '1', b = '2';
|
||||||
|
DROP NAMED COLLECTION foobar;
|
||||||
|
```
|
||||||
|
|||||||
@ -314,6 +314,22 @@ Provides possibility to start background fetch tasks from replication queues whi
|
|||||||
SYSTEM START REPLICATION QUEUES [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
SYSTEM START REPLICATION QUEUES [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
||||||
```
|
```
|
||||||
|
|
||||||
|
### STOP PULLING REPLICATION LOG
|
||||||
|
|
||||||
|
Stops loading new entries from replication log to replication queue in a `ReplicatedMergeTree` table.
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
SYSTEM STOP PULLING REPLICATION LOG [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
||||||
|
```
|
||||||
|
|
||||||
|
### START PULLING REPLICATION LOG
|
||||||
|
|
||||||
|
Cancels `SYSTEM STOP PULLING REPLICATION LOG`.
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
SYSTEM START PULLING REPLICATION LOG [ON CLUSTER cluster_name] [[db.]replicated_merge_tree_family_table_name]
|
||||||
|
```
|
||||||
|
|
||||||
### SYNC REPLICA
|
### SYNC REPLICA
|
||||||
|
|
||||||
Wait until a `ReplicatedMergeTree` table will be synced with other replicas in a cluster, but no more than `receive_timeout` seconds.
|
Wait until a `ReplicatedMergeTree` table will be synced with other replicas in a cluster, but no more than `receive_timeout` seconds.
|
||||||
|
|||||||
@ -19,7 +19,7 @@ azureBlobStorage(- connection_string|storage_account_url, container_name, blobpa
|
|||||||
|
|
||||||
- `connection_string|storage_account_url` — connection_string includes account name & key ([Create connection string](https://learn.microsoft.com/en-us/azure/storage/common/storage-configure-connection-string?toc=%2Fazure%2Fstorage%2Fblobs%2Ftoc.json&bc=%2Fazure%2Fstorage%2Fblobs%2Fbreadcrumb%2Ftoc.json#configure-a-connection-string-for-an-azure-storage-account)) or you could also provide the storage account url here and account name & account key as separate parameters (see parameters account_name & account_key)
|
- `connection_string|storage_account_url` — connection_string includes account name & key ([Create connection string](https://learn.microsoft.com/en-us/azure/storage/common/storage-configure-connection-string?toc=%2Fazure%2Fstorage%2Fblobs%2Ftoc.json&bc=%2Fazure%2Fstorage%2Fblobs%2Fbreadcrumb%2Ftoc.json#configure-a-connection-string-for-an-azure-storage-account)) or you could also provide the storage account url here and account name & account key as separate parameters (see parameters account_name & account_key)
|
||||||
- `container_name` - Container name
|
- `container_name` - Container name
|
||||||
- `blobpath` - file path. Supports following wildcards in readonly mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings.
|
- `blobpath` - file path. Supports following wildcards in readonly mode: `*`, `**`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings.
|
||||||
- `account_name` - if storage_account_url is used, then account name can be specified here
|
- `account_name` - if storage_account_url is used, then account name can be specified here
|
||||||
- `account_key` - if storage_account_url is used, then account key can be specified here
|
- `account_key` - if storage_account_url is used, then account key can be specified here
|
||||||
- `format` — The [format](../../interfaces/formats.md#formats) of the file.
|
- `format` — The [format](../../interfaces/formats.md#formats) of the file.
|
||||||
|
|||||||
@ -0,0 +1,47 @@
|
|||||||
|
---
|
||||||
|
slug: /en/sql-reference/table-functions/azureBlobStorageCluster
|
||||||
|
sidebar_position: 55
|
||||||
|
sidebar_label: azureBlobStorageCluster
|
||||||
|
title: "azureBlobStorageCluster Table Function"
|
||||||
|
---
|
||||||
|
|
||||||
|
Allows processing files from [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs) in parallel from many nodes in a specified cluster. On initiator it creates a connection to all nodes in the cluster, discloses asterisks in S3 file path, and dispatches each file dynamically. On the worker node it asks the initiator about the next task to process and processes it. This is repeated until all tasks are finished.
|
||||||
|
This table function is similar to the [s3Cluster function](../../sql-reference/table-functions/s3Cluster.md).
|
||||||
|
|
||||||
|
**Syntax**
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
azureBlobStorageCluster(cluster_name, connection_string|storage_account_url, container_name, blobpath, [account_name, account_key, format, compression, structure])
|
||||||
|
```
|
||||||
|
|
||||||
|
**Arguments**
|
||||||
|
|
||||||
|
- `cluster_name` — Name of a cluster that is used to build a set of addresses and connection parameters to remote and local servers.
|
||||||
|
- `connection_string|storage_account_url` — connection_string includes account name & key ([Create connection string](https://learn.microsoft.com/en-us/azure/storage/common/storage-configure-connection-string?toc=%2Fazure%2Fstorage%2Fblobs%2Ftoc.json&bc=%2Fazure%2Fstorage%2Fblobs%2Fbreadcrumb%2Ftoc.json#configure-a-connection-string-for-an-azure-storage-account)) or you could also provide the storage account url here and account name & account key as separate parameters (see parameters account_name & account_key)
|
||||||
|
- `container_name` - Container name
|
||||||
|
- `blobpath` - file path. Supports following wildcards in readonly mode: `*`, `**`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings.
|
||||||
|
- `account_name` - if storage_account_url is used, then account name can be specified here
|
||||||
|
- `account_key` - if storage_account_url is used, then account key can be specified here
|
||||||
|
- `format` — The [format](../../interfaces/formats.md#formats) of the file.
|
||||||
|
- `compression` — Supported values: `none`, `gzip/gz`, `brotli/br`, `xz/LZMA`, `zstd/zst`. By default, it will autodetect compression by file extension. (same as setting to `auto`).
|
||||||
|
- `structure` — Structure of the table. Format `'column1_name column1_type, column2_name column2_type, ...'`.
|
||||||
|
|
||||||
|
**Returned value**
|
||||||
|
|
||||||
|
A table with the specified structure for reading or writing data in the specified file.
|
||||||
|
|
||||||
|
**Examples**
|
||||||
|
|
||||||
|
Select the count for the file `test_cluster_*.csv`, using all the nodes in the `cluster_simple` cluster:
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
SELECT count(*) from azureBlobStorageCluster(
|
||||||
|
'cluster_simple', 'http://azurite1:10000/devstoreaccount1', 'test_container', 'test_cluster_count.csv', 'devstoreaccount1',
|
||||||
|
'Eby8vdM02xNOcqFlqUwJPLlmEtlCDXJ1OUzFT50uSRZ6IFsuFq2UVErCz4I6tq/K1SZFPTOtr/KBHBeksoGMGw==', 'CSV',
|
||||||
|
'auto', 'key UInt64')
|
||||||
|
```
|
||||||
|
|
||||||
|
**See Also**
|
||||||
|
|
||||||
|
- [AzureBlobStorage engine](../../engines/table-engines/integrations/azureBlobStorage.md)
|
||||||
|
- [azureBlobStorage table function](../../sql-reference/table-functions/azureBlobStorage.md)
|
||||||
@ -16,14 +16,14 @@ All available clusters are listed in the [system.clusters](../../operations/syst
|
|||||||
**Syntax**
|
**Syntax**
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
cluster('cluster_name', db.table[, sharding_key])
|
cluster(['cluster_name', db.table, sharding_key])
|
||||||
cluster('cluster_name', db, table[, sharding_key])
|
cluster(['cluster_name', db, table, sharding_key])
|
||||||
clusterAllReplicas('cluster_name', db.table[, sharding_key])
|
clusterAllReplicas(['cluster_name', db.table, sharding_key])
|
||||||
clusterAllReplicas('cluster_name', db, table[, sharding_key])
|
clusterAllReplicas(['cluster_name', db, table, sharding_key])
|
||||||
```
|
```
|
||||||
**Arguments**
|
**Arguments**
|
||||||
|
|
||||||
- `cluster_name` – Name of a cluster that is used to build a set of addresses and connection parameters to remote and local servers.
|
- `cluster_name` – Name of a cluster that is used to build a set of addresses and connection parameters to remote and local servers, set `default` if not specified.
|
||||||
- `db.table` or `db`, `table` - Name of a database and a table.
|
- `db.table` or `db`, `table` - Name of a database and a table.
|
||||||
- `sharding_key` - A sharding key. Optional. Needs to be specified if the cluster has more than one shard.
|
- `sharding_key` - A sharding key. Optional. Needs to be specified if the cluster has more than one shard.
|
||||||
|
|
||||||
|
|||||||
@ -13,16 +13,18 @@ The `file` function can be used in `SELECT` and `INSERT` queries to read from or
|
|||||||
**Syntax**
|
**Syntax**
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
file(path [,format] [,structure] [,compression])
|
file([path_to_archive ::] path [,format] [,structure] [,compression])
|
||||||
```
|
```
|
||||||
|
|
||||||
**Parameters**
|
**Parameters**
|
||||||
|
|
||||||
- `path` — The relative path to the file from [user_files_path](/docs/en/operations/server-configuration-parameters/settings.md#server_configuration_parameters-user_files_path). Path to file support following globs in read-only mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc', 'def'` — strings.
|
- `path` — The relative path to the file from [user_files_path](/docs/en/operations/server-configuration-parameters/settings.md#server_configuration_parameters-user_files_path). Path to file support following globs in read-only mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc', 'def'` — strings.
|
||||||
|
- `path_to_archive` - The relative path to zip/tar/7z archive. Path to archive support the same globs as `path`.
|
||||||
- `format` — The [format](/docs/en/interfaces/formats.md#formats) of the file.
|
- `format` — The [format](/docs/en/interfaces/formats.md#formats) of the file.
|
||||||
- `structure` — Structure of the table. Format: `'column1_name column1_type, column2_name column2_type, ...'`.
|
- `structure` — Structure of the table. Format: `'column1_name column1_type, column2_name column2_type, ...'`.
|
||||||
- `compression` — The existing compression type when used in a `SELECT` query, or the desired compression type when used in an `INSERT` query. The supported compression types are `gz`, `br`, `xz`, `zst`, `lz4`, and `bz2`.
|
- `compression` — The existing compression type when used in a `SELECT` query, or the desired compression type when used in an `INSERT` query. The supported compression types are `gz`, `br`, `xz`, `zst`, `lz4`, and `bz2`.
|
||||||
|
|
||||||
|
|
||||||
**Returned value**
|
**Returned value**
|
||||||
|
|
||||||
A table with the specified structure for reading or writing data in the specified file.
|
A table with the specified structure for reading or writing data in the specified file.
|
||||||
@ -128,6 +130,11 @@ file('test.csv', 'CSV', 'column1 UInt32, column2 UInt32, column3 UInt32');
|
|||||||
└─────────┴─────────┴─────────┘
|
└─────────┴─────────┴─────────┘
|
||||||
```
|
```
|
||||||
|
|
||||||
|
Getting data from table in table.csv, located in archive1.zip or/and archive2.zip
|
||||||
|
``` sql
|
||||||
|
SELECT * FROM file('user_files/archives/archive{1..2}.zip :: table.csv');
|
||||||
|
```
|
||||||
|
|
||||||
## Globs in Path
|
## Globs in Path
|
||||||
|
|
||||||
Multiple path components can have globs. For being processed file must exist and match to the whole path pattern (not only suffix or prefix).
|
Multiple path components can have globs. For being processed file must exist and match to the whole path pattern (not only suffix or prefix).
|
||||||
|
|||||||
@ -22,7 +22,7 @@ The GCS Table Function integrates with Google Cloud Storage by using the GCS XML
|
|||||||
|
|
||||||
**Arguments**
|
**Arguments**
|
||||||
|
|
||||||
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings.
|
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `**`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings.
|
||||||
|
|
||||||
:::note GCS
|
:::note GCS
|
||||||
The GCS path is in this format as the endpoint for the Google XML API is different than the JSON API:
|
The GCS path is in this format as the endpoint for the Google XML API is different than the JSON API:
|
||||||
|
|||||||
@ -17,7 +17,7 @@ hdfsCluster(cluster_name, URI, format, structure)
|
|||||||
**Arguments**
|
**Arguments**
|
||||||
|
|
||||||
- `cluster_name` — Name of a cluster that is used to build a set of addresses and connection parameters to remote and local servers.
|
- `cluster_name` — Name of a cluster that is used to build a set of addresses and connection parameters to remote and local servers.
|
||||||
- `URI` — URI to a file or a bunch of files. Supports following wildcards in readonly mode: `*`, `?`, `{'abc','def'}` and `{N..M}` where `N`, `M` — numbers, `abc`, `def` — strings. For more information see [Wildcards In Path](../../engines/table-engines/integrations/s3.md#wildcards-in-path).
|
- `URI` — URI to a file or a bunch of files. Supports following wildcards in readonly mode: `*`, `**`, `?`, `{'abc','def'}` and `{N..M}` where `N`, `M` — numbers, `abc`, `def` — strings. For more information see [Wildcards In Path](../../engines/table-engines/integrations/s3.md#wildcards-in-path).
|
||||||
- `format` — The [format](../../interfaces/formats.md#formats) of the file.
|
- `format` — The [format](../../interfaces/formats.md#formats) of the file.
|
||||||
- `structure` — Structure of the table. Format `'column1_name column1_type, column2_name column2_type, ...'`.
|
- `structure` — Structure of the table. Format `'column1_name column1_type, column2_name column2_type, ...'`.
|
||||||
|
|
||||||
|
|||||||
@ -21,7 +21,7 @@ iceberg(url [,aws_access_key_id, aws_secret_access_key] [,format] [,structure])
|
|||||||
- `format` — The [format](/docs/en/interfaces/formats.md/#formats) of the file. By default `Parquet` is used.
|
- `format` — The [format](/docs/en/interfaces/formats.md/#formats) of the file. By default `Parquet` is used.
|
||||||
- `structure` — Structure of the table. Format `'column1_name column1_type, column2_name column2_type, ...'`.
|
- `structure` — Structure of the table. Format `'column1_name column1_type, column2_name column2_type, ...'`.
|
||||||
|
|
||||||
Engine parameters can be specified using [Named Collections](../../operations/named-collections.md)
|
Engine parameters can be specified using [Named Collections](/docs/en/operations/named-collections.md).
|
||||||
|
|
||||||
**Returned value**
|
**Returned value**
|
||||||
|
|
||||||
|
|||||||
@ -13,10 +13,10 @@ Both functions can be used in `SELECT` and `INSERT` queries.
|
|||||||
## Syntax
|
## Syntax
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
remote('addresses_expr', db, table[, 'user'[, 'password'], sharding_key])
|
remote('addresses_expr', [db, table, 'user'[, 'password'], sharding_key])
|
||||||
remote('addresses_expr', db.table[, 'user'[, 'password'], sharding_key])
|
remote('addresses_expr', [db.table, 'user'[, 'password'], sharding_key])
|
||||||
remoteSecure('addresses_expr', db, table[, 'user'[, 'password'], sharding_key])
|
remoteSecure('addresses_expr', [db, table, 'user'[, 'password'], sharding_key])
|
||||||
remoteSecure('addresses_expr', db.table[, 'user'[, 'password'], sharding_key])
|
remoteSecure('addresses_expr', [db.table, 'user'[, 'password'], sharding_key])
|
||||||
```
|
```
|
||||||
|
|
||||||
## Parameters
|
## Parameters
|
||||||
@ -29,6 +29,8 @@ remoteSecure('addresses_expr', db.table[, 'user'[, 'password'], sharding_key])
|
|||||||
|
|
||||||
The port is required for an IPv6 address.
|
The port is required for an IPv6 address.
|
||||||
|
|
||||||
|
If only specify this parameter, `db` and `table` will use `system.one` by default.
|
||||||
|
|
||||||
Type: [String](../../sql-reference/data-types/string.md).
|
Type: [String](../../sql-reference/data-types/string.md).
|
||||||
|
|
||||||
- `db` — Database name. Type: [String](../../sql-reference/data-types/string.md).
|
- `db` — Database name. Type: [String](../../sql-reference/data-types/string.md).
|
||||||
|
|||||||
@ -23,7 +23,7 @@ For GCS, substitute your HMAC key and HMAC secret where you see `aws_access_key_
|
|||||||
|
|
||||||
**Arguments**
|
**Arguments**
|
||||||
|
|
||||||
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings. For more information see [here](../../engines/table-engines/integrations/s3.md#wildcards-in-path).
|
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `**`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings. For more information see [here](../../engines/table-engines/integrations/s3.md#wildcards-in-path).
|
||||||
|
|
||||||
:::note GCS
|
:::note GCS
|
||||||
The GCS path is in this format as the endpoint for the Google XML API is different than the JSON API:
|
The GCS path is in this format as the endpoint for the Google XML API is different than the JSON API:
|
||||||
|
|||||||
@ -16,7 +16,7 @@ s3Cluster(cluster_name, source, [,access_key_id, secret_access_key] [,format] [,
|
|||||||
**Arguments**
|
**Arguments**
|
||||||
|
|
||||||
- `cluster_name` — Name of a cluster that is used to build a set of addresses and connection parameters to remote and local servers.
|
- `cluster_name` — Name of a cluster that is used to build a set of addresses and connection parameters to remote and local servers.
|
||||||
- `source` — URL to a file or a bunch of files. Supports following wildcards in readonly mode: `*`, `?`, `{'abc','def'}` and `{N..M}` where `N`, `M` — numbers, `abc`, `def` — strings. For more information see [Wildcards In Path](../../engines/table-engines/integrations/s3.md#wildcards-in-path).
|
- `source` — URL to a file or a bunch of files. Supports following wildcards in readonly mode: `*`, `**`, `?`, `{'abc','def'}` and `{N..M}` where `N`, `M` — numbers, `abc`, `def` — strings. For more information see [Wildcards In Path](../../engines/table-engines/integrations/s3.md#wildcards-in-path).
|
||||||
- `access_key_id` and `secret_access_key` — Keys that specify credentials to use with given endpoint. Optional.
|
- `access_key_id` and `secret_access_key` — Keys that specify credentials to use with given endpoint. Optional.
|
||||||
- `format` — The [format](../../interfaces/formats.md#formats) of the file.
|
- `format` — The [format](../../interfaces/formats.md#formats) of the file.
|
||||||
- `structure` — Structure of the table. Format `'column1_name column1_type, column2_name column2_type, ...'`.
|
- `structure` — Structure of the table. Format `'column1_name column1_type, column2_name column2_type, ...'`.
|
||||||
|
|||||||
@ -56,7 +56,7 @@ Character `|` inside patterns is used to specify failover addresses. They are it
|
|||||||
## Storage Settings {#storage-settings}
|
## Storage Settings {#storage-settings}
|
||||||
|
|
||||||
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
||||||
- [disable_url_encoding](/docs/en/operations/settings/settings.md#disable_url_encoding) - allows to disable decoding/encoding path in uri. Disabled by default.
|
- [enable_url_encoding](/docs/en/operations/settings/settings.md#enable_url_encoding) - allows to enable/disable decoding/encoding path in uri. Enabled by default.
|
||||||
|
|
||||||
**See Also**
|
**See Also**
|
||||||
|
|
||||||
|
|||||||
@ -9,7 +9,7 @@ sidebar_label: Buffer
|
|||||||
Буферизует записываемые данные в оперативке, периодически сбрасывая их в другую таблицу. При чтении, производится чтение данных одновременно из буфера и из другой таблицы.
|
Буферизует записываемые данные в оперативке, периодически сбрасывая их в другую таблицу. При чтении, производится чтение данных одновременно из буфера и из другой таблицы.
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes)
|
Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes [,flush_time [,flush_rows [,flush_bytes]]])
|
||||||
```
|
```
|
||||||
|
|
||||||
Параметры движка:
|
Параметры движка:
|
||||||
|
|||||||
@ -1353,8 +1353,6 @@ ClickHouse поддерживает настраиваемую точность
|
|||||||
$ cat {filename} | clickhouse-client --query="INSERT INTO {some_table} FORMAT Parquet"
|
$ cat {filename} | clickhouse-client --query="INSERT INTO {some_table} FORMAT Parquet"
|
||||||
```
|
```
|
||||||
|
|
||||||
Чтобы вставить данные в колонки типа [Nested](../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур, нужно включить настройку [input_format_parquet_import_nested](../operations/settings/settings.md#input_format_parquet_import_nested).
|
|
||||||
|
|
||||||
Чтобы получить данные из таблицы ClickHouse и сохранить их в файл формата Parquet, используйте команду следующего вида:
|
Чтобы получить данные из таблицы ClickHouse и сохранить их в файл формата Parquet, используйте команду следующего вида:
|
||||||
|
|
||||||
``` bash
|
``` bash
|
||||||
@ -1413,8 +1411,6 @@ ClickHouse поддерживает настраиваемую точность
|
|||||||
$ cat filename.arrow | clickhouse-client --query="INSERT INTO some_table FORMAT Arrow"
|
$ cat filename.arrow | clickhouse-client --query="INSERT INTO some_table FORMAT Arrow"
|
||||||
```
|
```
|
||||||
|
|
||||||
Чтобы вставить данные в колонки типа [Nested](../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур, нужно включить настройку [input_format_arrow_import_nested](../operations/settings/settings.md#input_format_arrow_import_nested).
|
|
||||||
|
|
||||||
### Вывод данных {#selecting-data-arrow}
|
### Вывод данных {#selecting-data-arrow}
|
||||||
|
|
||||||
Чтобы получить данные из таблицы ClickHouse и сохранить их в файл формата Arrow, используйте команду следующего вида:
|
Чтобы получить данные из таблицы ClickHouse и сохранить их в файл формата Arrow, используйте команду следующего вида:
|
||||||
@ -1471,8 +1467,6 @@ ClickHouse поддерживает настраиваемую точность
|
|||||||
$ cat filename.orc | clickhouse-client --query="INSERT INTO some_table FORMAT ORC"
|
$ cat filename.orc | clickhouse-client --query="INSERT INTO some_table FORMAT ORC"
|
||||||
```
|
```
|
||||||
|
|
||||||
Чтобы вставить данные в колонки типа [Nested](../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур, нужно включить настройку [input_format_orc_import_nested](../operations/settings/settings.md#input_format_orc_import_nested).
|
|
||||||
|
|
||||||
### Вывод данных {#selecting-data-2}
|
### Вывод данных {#selecting-data-2}
|
||||||
|
|
||||||
Чтобы получить данные из таблицы ClickHouse и сохранить их в файл формата ORC, используйте команду следующего вида:
|
Чтобы получить данные из таблицы ClickHouse и сохранить их в файл формата ORC, используйте команду следующего вида:
|
||||||
|
|||||||
@ -0,0 +1 @@
|
|||||||
|
../../../en/operations/optimizing-performance/profile-guided-optimization.md
|
||||||
@ -311,9 +311,18 @@ FORMAT Null;
|
|||||||
|
|
||||||
**Подробности**
|
**Подробности**
|
||||||
|
|
||||||
При вставке данных, ClickHouse вычисляет количество партиций во вставленном блоке. Если число партиций больше, чем `max_partitions_per_insert_block`, ClickHouse генерирует исключение со следующим текстом:
|
При вставке данных ClickHouse проверяет количество партиций во вставляемом блоке. Если количество разделов превышает число `max_partitions_per_insert_block`, ClickHouse либо логирует предупреждение, либо выбрасывает исключение в зависимости от значения `throw_on_max_partitions_per_insert_block`. Исключения имеют следующий текст:
|
||||||
|
|
||||||
> «Too many partitions for single INSERT block (more than» + toString(max_parts) + «). The limit is controlled by ‘max_partitions_per_insert_block’ setting. Large number of partitions is a common misconception. It will lead to severe negative performance impact, including slow server startup, slow INSERT queries and slow SELECT queries. Recommended total number of partitions for a table is under 1000..10000. Please note, that partitioning is not intended to speed up SELECT queries (ORDER BY key is sufficient to make range queries fast). Partitions are intended for data manipulation (DROP PARTITION, etc).»
|
> “Too many partitions for a single INSERT block (`partitions_count` partitions, limit is ” + toString(max_partitions) + “). The limit is controlled by the ‘max_partitions_per_insert_block’ setting. A large number of partitions is a common misconception. It will lead to severe negative performance impact, including slow server startup, slow INSERT queries and slow SELECT queries. Recommended total number of partitions for a table is under 1000..10000. Please note, that partitioning is not intended to speed up SELECT queries (ORDER BY key is sufficient to make range queries fast). Partitions are intended for data manipulation (DROP PARTITION, etc).”
|
||||||
|
|
||||||
|
## throw_on_max_partitions_per_insert_block {#settings-throw_on_max_partition_per_insert_block}
|
||||||
|
|
||||||
|
Позволяет контролировать поведение при достижении `max_partitions_per_insert_block`
|
||||||
|
|
||||||
|
- `true` - Когда вставляемый блок достигает `max_partitions_per_insert_block`, возникает исключение.
|
||||||
|
- `false` - Записывает предупреждение при достижении `max_partitions_per_insert_block`.
|
||||||
|
|
||||||
|
Значение по умолчанию: `true`
|
||||||
|
|
||||||
## max_sessions_for_user {#max-sessions-per-user}
|
## max_sessions_for_user {#max-sessions-per-user}
|
||||||
|
|
||||||
|
|||||||
@ -238,39 +238,6 @@ ClickHouse применяет настройку в тех случаях, ко
|
|||||||
|
|
||||||
В случае превышения `input_format_allow_errors_ratio` ClickHouse генерирует исключение.
|
В случае превышения `input_format_allow_errors_ratio` ClickHouse генерирует исключение.
|
||||||
|
|
||||||
## input_format_parquet_import_nested {#input_format_parquet_import_nested}
|
|
||||||
|
|
||||||
Включает или отключает возможность вставки данных в колонки типа [Nested](../../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур в формате ввода [Parquet](../../interfaces/formats.md#data-format-parquet).
|
|
||||||
|
|
||||||
Возможные значения:
|
|
||||||
|
|
||||||
- 0 — данные не могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
|
||||||
- 0 — данные могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
|
||||||
|
|
||||||
Значение по умолчанию: `0`.
|
|
||||||
|
|
||||||
## input_format_arrow_import_nested {#input_format_arrow_import_nested}
|
|
||||||
|
|
||||||
Включает или отключает возможность вставки данных в колонки типа [Nested](../../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур в формате ввода [Arrow](../../interfaces/formats.md#data_types-matching-arrow).
|
|
||||||
|
|
||||||
Возможные значения:
|
|
||||||
|
|
||||||
- 0 — данные не могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
|
||||||
- 0 — данные могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
|
||||||
|
|
||||||
Значение по умолчанию: `0`.
|
|
||||||
|
|
||||||
## input_format_orc_import_nested {#input_format_orc_import_nested}
|
|
||||||
|
|
||||||
Включает или отключает возможность вставки данных в колонки типа [Nested](../../sql-reference/data-types/nested-data-structures/nested.md) в виде массива структур в формате ввода [ORC](../../interfaces/formats.md#data-format-orc).
|
|
||||||
|
|
||||||
Возможные значения:
|
|
||||||
|
|
||||||
- 0 — данные не могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
|
||||||
- 0 — данные могут быть вставлены в колонки типа `Nested` в виде массива структур.
|
|
||||||
|
|
||||||
Значение по умолчанию: `0`.
|
|
||||||
|
|
||||||
## input_format_values_interpret_expressions {#settings-input_format_values_interpret_expressions}
|
## input_format_values_interpret_expressions {#settings-input_format_values_interpret_expressions}
|
||||||
|
|
||||||
Включает или отключает парсер SQL, если потоковый парсер не может проанализировать данные. Этот параметр используется только для формата [Values](../../interfaces/formats.md#data-format-values) при вставке данных. Дополнительные сведения о парсерах читайте в разделе [Синтаксис](../../sql-reference/syntax.md).
|
Включает или отключает парсер SQL, если потоковый парсер не может проанализировать данные. Этот параметр используется только для формата [Values](../../interfaces/formats.md#data-format-values) при вставке данных. Дополнительные сведения о парсерах читайте в разделе [Синтаксис](../../sql-reference/syntax.md).
|
||||||
@ -4213,3 +4180,29 @@ SELECT *, timezone() FROM test_tz WHERE d = '2000-01-01 00:00:00' SETTINGS sessi
|
|||||||
- Запрос: `SELECT * FROM file('sample.csv')`
|
- Запрос: `SELECT * FROM file('sample.csv')`
|
||||||
|
|
||||||
Если чтение и обработка `sample.csv` прошли успешно, файл будет переименован в `processed_sample_1683473210851438.csv`.
|
Если чтение и обработка `sample.csv` прошли успешно, файл будет переименован в `processed_sample_1683473210851438.csv`.
|
||||||
|
|
||||||
|
## precise_float_parsing {#precise_float_parsing}
|
||||||
|
|
||||||
|
Позволяет выбрать алгоритм, используемый при парсинге [Float32/Float64](../../sql-reference/data-types/float.md):
|
||||||
|
* Если установлено значение `1`, то используется точный метод. Он более медленный, но всегда возвращает число, наиболее близкое к входному значению.
|
||||||
|
* В противном случае используется быстрый метод (поведение по умолчанию). Обычно результат его работы совпадает с результатом, полученным точным методом, однако в редких случаях он может отличаться на 1 или 2 наименее значимых цифры.
|
||||||
|
|
||||||
|
Возможные значения: `0`, `1`.
|
||||||
|
|
||||||
|
Значение по умолчанию: `0`.
|
||||||
|
|
||||||
|
Пример:
|
||||||
|
|
||||||
|
```sql
|
||||||
|
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 0;
|
||||||
|
|
||||||
|
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||||
|
│ 1.7090999999999998 │ 15008753.000000002 │
|
||||||
|
└─────────────────────┴──────────────────────────┘
|
||||||
|
|
||||||
|
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 1;
|
||||||
|
|
||||||
|
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||||
|
│ 1.7091 │ 15008753 │
|
||||||
|
└─────────────────────┴──────────────────────────┘
|
||||||
|
```
|
||||||
|
|||||||
@ -5,7 +5,7 @@ slug: /zh/engines/table-engines/special/buffer
|
|||||||
|
|
||||||
缓冲数据写入 RAM 中,周期性地将数据刷新到另一个表。在读取操作时,同时从缓冲区和另一个表读取数据。
|
缓冲数据写入 RAM 中,周期性地将数据刷新到另一个表。在读取操作时,同时从缓冲区和另一个表读取数据。
|
||||||
|
|
||||||
Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes)
|
Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes [,flush_time [,flush_rows [,flush_bytes]]])
|
||||||
|
|
||||||
引擎的参数:database,table - 要刷新数据的表。可以使用返回字符串的常量表达式而不是数据库名称。 num_layers - 并行层数。在物理上,该表将表示为 num_layers 个独立缓冲区。建议值为16。min_time,max_time,min_rows,max_rows,min_bytes,max_bytes - 从缓冲区刷新数据的条件。
|
引擎的参数:database,table - 要刷新数据的表。可以使用返回字符串的常量表达式而不是数据库名称。 num_layers - 并行层数。在物理上,该表将表示为 num_layers 个独立缓冲区。建议值为16。min_time,max_time,min_rows,max_rows,min_bytes,max_bytes - 从缓冲区刷新数据的条件。
|
||||||
|
|
||||||
|
|||||||
@ -0,0 +1 @@
|
|||||||
|
../../../en/operations/optimizing-performance/profile-guided-optimization.md
|
||||||
@ -55,6 +55,9 @@ contents:
|
|||||||
- src: clickhouse
|
- src: clickhouse
|
||||||
dst: /usr/bin/clickhouse-keeper
|
dst: /usr/bin/clickhouse-keeper
|
||||||
type: symlink
|
type: symlink
|
||||||
|
- src: clickhouse
|
||||||
|
dst: /usr/bin/clickhouse-keeper-client
|
||||||
|
type: symlink
|
||||||
- src: root/usr/bin/clickhouse-report
|
- src: root/usr/bin/clickhouse-report
|
||||||
dst: /usr/bin/clickhouse-report
|
dst: /usr/bin/clickhouse-report
|
||||||
- src: root/usr/bin/clickhouse-server
|
- src: root/usr/bin/clickhouse-server
|
||||||
|
|||||||
@ -77,7 +77,7 @@ void SetCommand::execute(const ASTKeeperQuery * query, KeeperClient * client) co
|
|||||||
client->zookeeper->set(
|
client->zookeeper->set(
|
||||||
client->getAbsolutePath(query->args[0].safeGet<String>()),
|
client->getAbsolutePath(query->args[0].safeGet<String>()),
|
||||||
query->args[1].safeGet<String>(),
|
query->args[1].safeGet<String>(),
|
||||||
static_cast<Int32>(query->args[2].safeGet<Int64>()));
|
static_cast<Int32>(query->args[2].get<Int32>()));
|
||||||
}
|
}
|
||||||
|
|
||||||
bool CreateCommand::parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const
|
bool CreateCommand::parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const
|
||||||
|
|||||||
@ -131,7 +131,7 @@ void KeeperClient::defineOptions(Poco::Util::OptionSet & options)
|
|||||||
.binding("host"));
|
.binding("host"));
|
||||||
|
|
||||||
options.addOption(
|
options.addOption(
|
||||||
Poco::Util::Option("port", "p", "server port. default `2181`")
|
Poco::Util::Option("port", "p", "server port. default `9181`")
|
||||||
.argument("<port>")
|
.argument("<port>")
|
||||||
.binding("port"));
|
.binding("port"));
|
||||||
|
|
||||||
@ -266,8 +266,16 @@ void KeeperClient::runInteractive()
|
|||||||
|
|
||||||
LineReader::Patterns query_extenders = {"\\"};
|
LineReader::Patterns query_extenders = {"\\"};
|
||||||
LineReader::Patterns query_delimiters = {};
|
LineReader::Patterns query_delimiters = {};
|
||||||
|
char word_break_characters[] = " \t\v\f\a\b\r\n/";
|
||||||
|
|
||||||
ReplxxLineReader lr(suggest, history_file, false, query_extenders, query_delimiters, {});
|
ReplxxLineReader lr(
|
||||||
|
suggest,
|
||||||
|
history_file,
|
||||||
|
/* multiline= */ false,
|
||||||
|
query_extenders,
|
||||||
|
query_delimiters,
|
||||||
|
word_break_characters,
|
||||||
|
/* highlighter_= */ {});
|
||||||
lr.enableBracketedPaste();
|
lr.enableBracketedPaste();
|
||||||
|
|
||||||
while (true)
|
while (true)
|
||||||
@ -299,7 +307,7 @@ int KeeperClient::main(const std::vector<String> & /* args */)
|
|||||||
}
|
}
|
||||||
|
|
||||||
auto host = config().getString("host", "localhost");
|
auto host = config().getString("host", "localhost");
|
||||||
auto port = config().getString("port", "2181");
|
auto port = config().getString("port", "9181");
|
||||||
zk_args.hosts = {host + ":" + port};
|
zk_args.hosts = {host + ":" + port};
|
||||||
zk_args.connection_timeout_ms = config().getInt("connection-timeout", 10) * 1000;
|
zk_args.connection_timeout_ms = config().getInt("connection-timeout", 10) * 1000;
|
||||||
zk_args.session_timeout_ms = config().getInt("session-timeout", 10) * 1000;
|
zk_args.session_timeout_ms = config().getInt("session-timeout", 10) * 1000;
|
||||||
|
|||||||
@ -288,13 +288,27 @@ try
|
|||||||
std::string path;
|
std::string path;
|
||||||
|
|
||||||
if (config().has("keeper_server.storage_path"))
|
if (config().has("keeper_server.storage_path"))
|
||||||
|
{
|
||||||
path = config().getString("keeper_server.storage_path");
|
path = config().getString("keeper_server.storage_path");
|
||||||
|
}
|
||||||
|
else if (std::filesystem::is_directory(std::filesystem::path{config().getString("path", DBMS_DEFAULT_PATH)} / "coordination"))
|
||||||
|
{
|
||||||
|
throw Exception(ErrorCodes::NO_ELEMENTS_IN_CONFIG,
|
||||||
|
"By default 'keeper.storage_path' could be assigned to {}, but the directory {} already exists. Please specify 'keeper.storage_path' in the keeper configuration explicitly",
|
||||||
|
KEEPER_DEFAULT_PATH, String{std::filesystem::path{config().getString("path", DBMS_DEFAULT_PATH)} / "coordination"});
|
||||||
|
}
|
||||||
else if (config().has("keeper_server.log_storage_path"))
|
else if (config().has("keeper_server.log_storage_path"))
|
||||||
|
{
|
||||||
path = std::filesystem::path(config().getString("keeper_server.log_storage_path")).parent_path();
|
path = std::filesystem::path(config().getString("keeper_server.log_storage_path")).parent_path();
|
||||||
|
}
|
||||||
else if (config().has("keeper_server.snapshot_storage_path"))
|
else if (config().has("keeper_server.snapshot_storage_path"))
|
||||||
|
{
|
||||||
path = std::filesystem::path(config().getString("keeper_server.snapshot_storage_path")).parent_path();
|
path = std::filesystem::path(config().getString("keeper_server.snapshot_storage_path")).parent_path();
|
||||||
|
}
|
||||||
else
|
else
|
||||||
path = std::filesystem::path{KEEPER_DEFAULT_PATH};
|
{
|
||||||
|
path = KEEPER_DEFAULT_PATH;
|
||||||
|
}
|
||||||
|
|
||||||
std::filesystem::create_directories(path);
|
std::filesystem::create_directories(path);
|
||||||
|
|
||||||
@ -330,6 +344,7 @@ try
|
|||||||
auto global_context = Context::createGlobal(shared_context.get());
|
auto global_context = Context::createGlobal(shared_context.get());
|
||||||
|
|
||||||
global_context->makeGlobalContext();
|
global_context->makeGlobalContext();
|
||||||
|
global_context->setApplicationType(Context::ApplicationType::KEEPER);
|
||||||
global_context->setPath(path);
|
global_context->setPath(path);
|
||||||
global_context->setRemoteHostFilter(config());
|
global_context->setRemoteHostFilter(config());
|
||||||
|
|
||||||
@ -365,7 +380,7 @@ try
|
|||||||
}
|
}
|
||||||
|
|
||||||
/// Initialize keeper RAFT. Do nothing if no keeper_server in config.
|
/// Initialize keeper RAFT. Do nothing if no keeper_server in config.
|
||||||
global_context->initializeKeeperDispatcher(/* start_async = */ true);
|
global_context->initializeKeeperDispatcher(/* start_async = */ false);
|
||||||
FourLetterCommandFactory::registerCommands(*global_context->getKeeperDispatcher());
|
FourLetterCommandFactory::registerCommands(*global_context->getKeeperDispatcher());
|
||||||
|
|
||||||
auto config_getter = [&] () -> const Poco::Util::AbstractConfiguration &
|
auto config_getter = [&] () -> const Poco::Util::AbstractConfiguration &
|
||||||
|
|||||||
@ -466,6 +466,11 @@ int main(int argc_, char ** argv_)
|
|||||||
checkHarmfulEnvironmentVariables(argv_);
|
checkHarmfulEnvironmentVariables(argv_);
|
||||||
#endif
|
#endif
|
||||||
|
|
||||||
|
/// This is used for testing. For example,
|
||||||
|
/// clickhouse-local should be able to run a simple query without throw/catch.
|
||||||
|
if (getenv("CLICKHOUSE_TERMINATE_ON_ANY_EXCEPTION")) // NOLINT(concurrency-mt-unsafe)
|
||||||
|
DB::terminate_on_any_exception = true;
|
||||||
|
|
||||||
/// Reset new handler to default (that throws std::bad_alloc)
|
/// Reset new handler to default (that throws std::bad_alloc)
|
||||||
/// It is needed because LLVM library clobbers it.
|
/// It is needed because LLVM library clobbers it.
|
||||||
std::set_new_handler(nullptr);
|
std::set_new_handler(nullptr);
|
||||||
|
|||||||
@ -1650,6 +1650,7 @@ try
|
|||||||
database_catalog.initializeAndLoadTemporaryDatabase();
|
database_catalog.initializeAndLoadTemporaryDatabase();
|
||||||
loadMetadataSystem(global_context);
|
loadMetadataSystem(global_context);
|
||||||
maybeConvertSystemDatabase(global_context);
|
maybeConvertSystemDatabase(global_context);
|
||||||
|
startupSystemTables();
|
||||||
/// After attaching system databases we can initialize system log.
|
/// After attaching system databases we can initialize system log.
|
||||||
global_context->initializeSystemLogs();
|
global_context->initializeSystemLogs();
|
||||||
global_context->setSystemZooKeeperLogAfterInitializationIfNeeded();
|
global_context->setSystemZooKeeperLogAfterInitializationIfNeeded();
|
||||||
@ -1668,7 +1669,6 @@ try
|
|||||||
/// Then, load remaining databases
|
/// Then, load remaining databases
|
||||||
loadMetadata(global_context, default_database);
|
loadMetadata(global_context, default_database);
|
||||||
convertDatabasesEnginesIfNeed(global_context);
|
convertDatabasesEnginesIfNeed(global_context);
|
||||||
startupSystemTables();
|
|
||||||
database_catalog.startupBackgroundCleanup();
|
database_catalog.startupBackgroundCleanup();
|
||||||
/// After loading validate that default database exists
|
/// After loading validate that default database exists
|
||||||
database_catalog.assertDatabaseExists(default_database);
|
database_catalog.assertDatabaseExists(default_database);
|
||||||
|
|||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user