mirror of
https://github.com/ClickHouse/ClickHouse.git
synced 2024-09-20 08:40:50 +00:00
Merge branch 'master' into count-distinct-if
This commit is contained in:
commit
e101f2011b
@ -8,6 +8,7 @@
|
||||
#include <functional>
|
||||
#include <iosfwd>
|
||||
|
||||
#include <base/defines.h>
|
||||
#include <base/types.h>
|
||||
#include <base/unaligned.h>
|
||||
|
||||
@ -274,6 +275,8 @@ struct CRC32Hash
|
||||
if (size == 0)
|
||||
return 0;
|
||||
|
||||
chassert(pos);
|
||||
|
||||
if (size < 8)
|
||||
{
|
||||
return static_cast<unsigned>(hashLessThan8(x.data, x.size));
|
||||
|
||||
@ -115,8 +115,15 @@
|
||||
/// because SIGABRT is easier to debug than SIGTRAP (the second one makes gdb crazy)
|
||||
#if !defined(chassert)
|
||||
#if defined(ABORT_ON_LOGICAL_ERROR)
|
||||
// clang-format off
|
||||
#include <base/types.h>
|
||||
namespace DB
|
||||
{
|
||||
void abortOnFailedAssertion(const String & description);
|
||||
}
|
||||
#define chassert(x) static_cast<bool>(x) ? void(0) : ::DB::abortOnFailedAssertion(#x)
|
||||
#define UNREACHABLE() abort()
|
||||
// clang-format off
|
||||
#else
|
||||
/// Here sizeof() trick is used to suppress unused warning for result,
|
||||
/// since simple "(void)x" will evaluate the expression, while
|
||||
|
||||
@ -57,7 +57,7 @@ public:
|
||||
URI();
|
||||
/// Creates an empty URI.
|
||||
|
||||
explicit URI(const std::string & uri, bool disable_url_encoding = false);
|
||||
explicit URI(const std::string & uri, bool enable_url_encoding = true);
|
||||
/// Parses an URI from the given string. Throws a
|
||||
/// SyntaxException if the uri is not valid.
|
||||
|
||||
@ -362,7 +362,7 @@ private:
|
||||
std::string _query;
|
||||
std::string _fragment;
|
||||
|
||||
bool _disable_url_encoding = false;
|
||||
bool _enable_url_encoding = true;
|
||||
};
|
||||
|
||||
|
||||
|
||||
@ -36,8 +36,8 @@ URI::URI():
|
||||
}
|
||||
|
||||
|
||||
URI::URI(const std::string& uri, bool decode_and_encode_path):
|
||||
_port(0), _disable_url_encoding(decode_and_encode_path)
|
||||
URI::URI(const std::string& uri, bool enable_url_encoding):
|
||||
_port(0), _enable_url_encoding(enable_url_encoding)
|
||||
{
|
||||
parse(uri);
|
||||
}
|
||||
@ -108,7 +108,7 @@ URI::URI(const URI& uri):
|
||||
_path(uri._path),
|
||||
_query(uri._query),
|
||||
_fragment(uri._fragment),
|
||||
_disable_url_encoding(uri._disable_url_encoding)
|
||||
_enable_url_encoding(uri._enable_url_encoding)
|
||||
{
|
||||
}
|
||||
|
||||
@ -121,7 +121,7 @@ URI::URI(const URI& baseURI, const std::string& relativeURI):
|
||||
_path(baseURI._path),
|
||||
_query(baseURI._query),
|
||||
_fragment(baseURI._fragment),
|
||||
_disable_url_encoding(baseURI._disable_url_encoding)
|
||||
_enable_url_encoding(baseURI._enable_url_encoding)
|
||||
{
|
||||
resolve(relativeURI);
|
||||
}
|
||||
@ -153,7 +153,7 @@ URI& URI::operator = (const URI& uri)
|
||||
_path = uri._path;
|
||||
_query = uri._query;
|
||||
_fragment = uri._fragment;
|
||||
_disable_url_encoding = uri._disable_url_encoding;
|
||||
_enable_url_encoding = uri._enable_url_encoding;
|
||||
}
|
||||
return *this;
|
||||
}
|
||||
@ -184,7 +184,7 @@ void URI::swap(URI& uri)
|
||||
std::swap(_path, uri._path);
|
||||
std::swap(_query, uri._query);
|
||||
std::swap(_fragment, uri._fragment);
|
||||
std::swap(_disable_url_encoding, uri._disable_url_encoding);
|
||||
std::swap(_enable_url_encoding, uri._enable_url_encoding);
|
||||
}
|
||||
|
||||
|
||||
@ -687,18 +687,18 @@ void URI::decode(const std::string& str, std::string& decodedStr, bool plusAsSpa
|
||||
|
||||
void URI::encodePath(std::string & encodedStr) const
|
||||
{
|
||||
if (_disable_url_encoding)
|
||||
encodedStr = _path;
|
||||
else
|
||||
if (_enable_url_encoding)
|
||||
encode(_path, RESERVED_PATH, encodedStr);
|
||||
else
|
||||
encodedStr = _path;
|
||||
}
|
||||
|
||||
void URI::decodePath(const std::string & encodedStr)
|
||||
{
|
||||
if (_disable_url_encoding)
|
||||
_path = encodedStr;
|
||||
else
|
||||
if (_enable_url_encoding)
|
||||
decode(encodedStr, _path);
|
||||
else
|
||||
_path = encodedStr;
|
||||
}
|
||||
|
||||
bool URI::isWellKnownPort() const
|
||||
|
||||
@ -17,7 +17,8 @@
|
||||
#ifndef METROHASH_PLATFORM_H
|
||||
#define METROHASH_PLATFORM_H
|
||||
|
||||
#include <stdint.h>
|
||||
#include <bit>
|
||||
#include <cstdint>
|
||||
#include <cstring>
|
||||
|
||||
// rotate right idiom recognized by most compilers
|
||||
@ -33,6 +34,11 @@ inline static uint64_t read_u64(const void * const ptr)
|
||||
// so we use memcpy() which is the most portable. clang & gcc usually translates `memcpy()` into a single `load` instruction
|
||||
// when hardware supports it, so using memcpy() is efficient too.
|
||||
memcpy(&result, ptr, sizeof(result));
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
result = std::byteswap(result);
|
||||
#endif
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
@ -40,6 +46,11 @@ inline static uint64_t read_u32(const void * const ptr)
|
||||
{
|
||||
uint32_t result;
|
||||
memcpy(&result, ptr, sizeof(result));
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
result = std::byteswap(result);
|
||||
#endif
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
@ -47,6 +58,11 @@ inline static uint64_t read_u16(const void * const ptr)
|
||||
{
|
||||
uint16_t result;
|
||||
memcpy(&result, ptr, sizeof(result));
|
||||
|
||||
#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
|
||||
result = std::byteswap(result);
|
||||
#endif
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
|
||||
@ -161,5 +161,9 @@
|
||||
"docker/test/sqllogic": {
|
||||
"name": "clickhouse/sqllogic-test",
|
||||
"dependent": []
|
||||
},
|
||||
"docker/test/integration/nginx_dav": {
|
||||
"name": "clickhouse/nginx-dav",
|
||||
"dependent": []
|
||||
}
|
||||
}
|
||||
|
||||
@ -6,7 +6,7 @@ Usage:
|
||||
Build deb package with `clang-14` in `debug` mode:
|
||||
```
|
||||
$ mkdir deb/test_output
|
||||
$ ./packager --output-dir deb/test_output/ --package-type deb --compiler=clang-14 --build-type=debug
|
||||
$ ./packager --output-dir deb/test_output/ --package-type deb --compiler=clang-14 --debug-build
|
||||
$ ls -l deb/test_output
|
||||
-rw-r--r-- 1 root root 3730 clickhouse-client_22.2.2+debug_all.deb
|
||||
-rw-r--r-- 1 root root 84221888 clickhouse-common-static_22.2.2+debug_amd64.deb
|
||||
|
||||
@ -112,12 +112,12 @@ def run_docker_image_with_env(
|
||||
subprocess.check_call(cmd, shell=True)
|
||||
|
||||
|
||||
def is_release_build(build_type: str, package_type: str, sanitizer: str) -> bool:
|
||||
return build_type == "" and package_type == "deb" and sanitizer == ""
|
||||
def is_release_build(debug_build: bool, package_type: str, sanitizer: str) -> bool:
|
||||
return not debug_build and package_type == "deb" and sanitizer == ""
|
||||
|
||||
|
||||
def parse_env_variables(
|
||||
build_type: str,
|
||||
debug_build: bool,
|
||||
compiler: str,
|
||||
sanitizer: str,
|
||||
package_type: str,
|
||||
@ -240,7 +240,7 @@ def parse_env_variables(
|
||||
build_target = (
|
||||
f"{build_target} clickhouse-odbc-bridge clickhouse-library-bridge"
|
||||
)
|
||||
if is_release_build(build_type, package_type, sanitizer):
|
||||
if is_release_build(debug_build, package_type, sanitizer):
|
||||
cmake_flags.append("-DSPLIT_DEBUG_SYMBOLS=ON")
|
||||
result.append("WITH_PERFORMANCE=1")
|
||||
if is_cross_arm:
|
||||
@ -255,8 +255,8 @@ def parse_env_variables(
|
||||
|
||||
if sanitizer:
|
||||
result.append(f"SANITIZER={sanitizer}")
|
||||
if build_type:
|
||||
result.append(f"BUILD_TYPE={build_type.capitalize()}")
|
||||
if debug_build:
|
||||
result.append("BUILD_TYPE=Debug")
|
||||
else:
|
||||
result.append("BUILD_TYPE=None")
|
||||
|
||||
@ -361,7 +361,7 @@ def parse_args() -> argparse.Namespace:
|
||||
help="ClickHouse git repository",
|
||||
)
|
||||
parser.add_argument("--output-dir", type=dir_name, required=True)
|
||||
parser.add_argument("--build-type", choices=("debug", ""), default="")
|
||||
parser.add_argument("--debug-build", action="store_true")
|
||||
|
||||
parser.add_argument(
|
||||
"--compiler",
|
||||
@ -467,7 +467,7 @@ def main():
|
||||
build_image(image_with_version, dockerfile)
|
||||
|
||||
env_prepared = parse_env_variables(
|
||||
args.build_type,
|
||||
args.debug_build,
|
||||
args.compiler,
|
||||
args.sanitizer,
|
||||
args.package_type,
|
||||
|
||||
@ -32,7 +32,7 @@ ENV MSAN_OPTIONS='abort_on_error=1 poison_in_dtor=1'
|
||||
RUN echo "en_US.UTF-8 UTF-8" > /etc/locale.gen && locale-gen en_US.UTF-8
|
||||
ENV LC_ALL en_US.UTF-8
|
||||
|
||||
ENV TZ=Europe/Moscow
|
||||
ENV TZ=Europe/Amsterdam
|
||||
RUN ln -snf "/usr/share/zoneinfo/$TZ" /etc/localtime && echo "$TZ" > /etc/timezone
|
||||
|
||||
CMD sleep 1
|
||||
|
||||
@ -32,7 +32,7 @@ RUN mkdir -p /tmp/clickhouse-odbc-tmp \
|
||||
&& odbcinst -i -s -l -f /tmp/clickhouse-odbc-tmp/share/doc/clickhouse-odbc/config/odbc.ini.sample \
|
||||
&& rm -rf /tmp/clickhouse-odbc-tmp
|
||||
|
||||
ENV TZ=Europe/Moscow
|
||||
ENV TZ=Europe/Amsterdam
|
||||
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
|
||||
|
||||
ENV COMMIT_SHA=''
|
||||
|
||||
@ -8,7 +8,7 @@ ARG apt_archive="http://archive.ubuntu.com"
|
||||
RUN sed -i "s|http://archive.ubuntu.com|$apt_archive|g" /etc/apt/sources.list
|
||||
|
||||
ENV LANG=C.UTF-8
|
||||
ENV TZ=Europe/Moscow
|
||||
ENV TZ=Europe/Amsterdam
|
||||
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
|
||||
|
||||
RUN apt-get update \
|
||||
|
||||
6
docker/test/integration/nginx_dav/Dockerfile
Normal file
6
docker/test/integration/nginx_dav/Dockerfile
Normal file
@ -0,0 +1,6 @@
|
||||
FROM nginx:alpine-slim
|
||||
|
||||
COPY default.conf /etc/nginx/conf.d/
|
||||
|
||||
RUN mkdir /usr/share/nginx/files/ \
|
||||
&& chown nginx: /usr/share/nginx/files/ -R
|
||||
25
docker/test/integration/nginx_dav/default.conf
Normal file
25
docker/test/integration/nginx_dav/default.conf
Normal file
@ -0,0 +1,25 @@
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
#root /usr/share/nginx/test.com;
|
||||
index index.html index.htm;
|
||||
|
||||
server_name test.com localhost;
|
||||
|
||||
location / {
|
||||
expires max;
|
||||
root /usr/share/nginx/files;
|
||||
client_max_body_size 20m;
|
||||
client_body_temp_path /usr/share/nginx/tmp;
|
||||
dav_methods PUT; # Allowed methods, only PUT is necessary
|
||||
|
||||
create_full_put_path on; # nginx automatically creates nested directories
|
||||
dav_access user:rw group:r all:r; # access permissions for files
|
||||
|
||||
limit_except GET {
|
||||
allow all;
|
||||
}
|
||||
}
|
||||
|
||||
error_page 405 =200 $uri;
|
||||
}
|
||||
@ -95,6 +95,7 @@ RUN python3 -m pip install --no-cache-dir \
|
||||
pytest-timeout \
|
||||
pytest-xdist \
|
||||
pytz \
|
||||
pyyaml==5.3.1 \
|
||||
redis \
|
||||
requests-kerberos \
|
||||
tzlocal==2.1 \
|
||||
|
||||
@ -1,16 +1,15 @@
|
||||
version: '2.3'
|
||||
services:
|
||||
meili1:
|
||||
image: getmeili/meilisearch:v0.27.0
|
||||
image: getmeili/meilisearch:v0.27.0
|
||||
restart: always
|
||||
ports:
|
||||
- ${MEILI_EXTERNAL_PORT:-7700}:${MEILI_INTERNAL_PORT:-7700}
|
||||
|
||||
meili_secure:
|
||||
image: getmeili/meilisearch:v0.27.0
|
||||
image: getmeili/meilisearch:v0.27.0
|
||||
restart: always
|
||||
ports:
|
||||
- ${MEILI_SECURE_EXTERNAL_PORT:-7700}:${MEILI_SECURE_INTERNAL_PORT:-7700}
|
||||
environment:
|
||||
MEILI_MASTER_KEY: "password"
|
||||
|
||||
|
||||
@ -9,10 +9,10 @@ services:
|
||||
DATADIR: /mysql/
|
||||
expose:
|
||||
- ${MYSQL_PORT:-3306}
|
||||
command: --server_id=100
|
||||
--log-bin='mysql-bin-1.log'
|
||||
--default-time-zone='+3:00'
|
||||
--gtid-mode="ON"
|
||||
command: --server_id=100
|
||||
--log-bin='mysql-bin-1.log'
|
||||
--default-time-zone='+3:00'
|
||||
--gtid-mode="ON"
|
||||
--enforce-gtid-consistency
|
||||
--log-error-verbosity=3
|
||||
--log-error=/mysql/error.log
|
||||
@ -21,4 +21,4 @@ services:
|
||||
volumes:
|
||||
- type: ${MYSQL_LOGS_FS:-tmpfs}
|
||||
source: ${MYSQL_LOGS:-}
|
||||
target: /mysql/
|
||||
target: /mysql/
|
||||
|
||||
@ -9,9 +9,9 @@ services:
|
||||
DATADIR: /mysql/
|
||||
expose:
|
||||
- ${MYSQL8_PORT:-3306}
|
||||
command: --server_id=100 --log-bin='mysql-bin-1.log'
|
||||
--default_authentication_plugin='mysql_native_password'
|
||||
--default-time-zone='+3:00' --gtid-mode="ON"
|
||||
command: --server_id=100 --log-bin='mysql-bin-1.log'
|
||||
--default_authentication_plugin='mysql_native_password'
|
||||
--default-time-zone='+3:00' --gtid-mode="ON"
|
||||
--enforce-gtid-consistency
|
||||
--log-error-verbosity=3
|
||||
--log-error=/mysql/error.log
|
||||
@ -20,4 +20,4 @@ services:
|
||||
volumes:
|
||||
- type: ${MYSQL8_LOGS_FS:-tmpfs}
|
||||
source: ${MYSQL8_LOGS:-}
|
||||
target: /mysql/
|
||||
target: /mysql/
|
||||
|
||||
@ -9,10 +9,10 @@ services:
|
||||
DATADIR: /mysql/
|
||||
expose:
|
||||
- ${MYSQL_CLUSTER_PORT:-3306}
|
||||
command: --server_id=100
|
||||
--log-bin='mysql-bin-2.log'
|
||||
--default-time-zone='+3:00'
|
||||
--gtid-mode="ON"
|
||||
command: --server_id=100
|
||||
--log-bin='mysql-bin-2.log'
|
||||
--default-time-zone='+3:00'
|
||||
--gtid-mode="ON"
|
||||
--enforce-gtid-consistency
|
||||
--log-error-verbosity=3
|
||||
--log-error=/mysql/2_error.log
|
||||
@ -31,10 +31,10 @@ services:
|
||||
DATADIR: /mysql/
|
||||
expose:
|
||||
- ${MYSQL_CLUSTER_PORT:-3306}
|
||||
command: --server_id=100
|
||||
--log-bin='mysql-bin-3.log'
|
||||
--default-time-zone='+3:00'
|
||||
--gtid-mode="ON"
|
||||
command: --server_id=100
|
||||
--log-bin='mysql-bin-3.log'
|
||||
--default-time-zone='+3:00'
|
||||
--gtid-mode="ON"
|
||||
--enforce-gtid-consistency
|
||||
--log-error-verbosity=3
|
||||
--log-error=/mysql/3_error.log
|
||||
@ -53,10 +53,10 @@ services:
|
||||
DATADIR: /mysql/
|
||||
expose:
|
||||
- ${MYSQL_CLUSTER_PORT:-3306}
|
||||
command: --server_id=100
|
||||
--log-bin='mysql-bin-4.log'
|
||||
--default-time-zone='+3:00'
|
||||
--gtid-mode="ON"
|
||||
command: --server_id=100
|
||||
--log-bin='mysql-bin-4.log'
|
||||
--default-time-zone='+3:00'
|
||||
--gtid-mode="ON"
|
||||
--enforce-gtid-consistency
|
||||
--log-error-verbosity=3
|
||||
--log-error=/mysql/4_error.log
|
||||
@ -65,4 +65,4 @@ services:
|
||||
volumes:
|
||||
- type: ${MYSQL_CLUSTER_LOGS_FS:-tmpfs}
|
||||
source: ${MYSQL_CLUSTER_LOGS:-}
|
||||
target: /mysql/
|
||||
target: /mysql/
|
||||
|
||||
@ -5,7 +5,7 @@ services:
|
||||
# Files will be put into /usr/share/nginx/files.
|
||||
|
||||
nginx:
|
||||
image: kssenii/nginx-test:1.1
|
||||
image: clickhouse/nginx-dav:${DOCKER_NGINX_DAV_TAG:-latest}
|
||||
restart: always
|
||||
ports:
|
||||
- 80:80
|
||||
|
||||
@ -12,9 +12,9 @@ services:
|
||||
timeout: 5s
|
||||
retries: 5
|
||||
networks:
|
||||
default:
|
||||
aliases:
|
||||
- postgre-sql.local
|
||||
default:
|
||||
aliases:
|
||||
- postgre-sql.local
|
||||
environment:
|
||||
POSTGRES_HOST_AUTH_METHOD: "trust"
|
||||
POSTGRES_PASSWORD: mysecretpassword
|
||||
|
||||
@ -12,7 +12,7 @@ services:
|
||||
command: ["zkServer.sh", "start-foreground"]
|
||||
entrypoint: /zookeeper-ssl-entrypoint.sh
|
||||
volumes:
|
||||
- type: bind
|
||||
- type: bind
|
||||
source: /misc/zookeeper-ssl-entrypoint.sh
|
||||
target: /zookeeper-ssl-entrypoint.sh
|
||||
- type: bind
|
||||
@ -37,7 +37,7 @@ services:
|
||||
command: ["zkServer.sh", "start-foreground"]
|
||||
entrypoint: /zookeeper-ssl-entrypoint.sh
|
||||
volumes:
|
||||
- type: bind
|
||||
- type: bind
|
||||
source: /misc/zookeeper-ssl-entrypoint.sh
|
||||
target: /zookeeper-ssl-entrypoint.sh
|
||||
- type: bind
|
||||
@ -61,7 +61,7 @@ services:
|
||||
command: ["zkServer.sh", "start-foreground"]
|
||||
entrypoint: /zookeeper-ssl-entrypoint.sh
|
||||
volumes:
|
||||
- type: bind
|
||||
- type: bind
|
||||
source: /misc/zookeeper-ssl-entrypoint.sh
|
||||
target: /zookeeper-ssl-entrypoint.sh
|
||||
- type: bind
|
||||
|
||||
@ -64,15 +64,16 @@ export CLICKHOUSE_ODBC_BRIDGE_BINARY_PATH=/clickhouse-odbc-bridge
|
||||
export CLICKHOUSE_LIBRARY_BRIDGE_BINARY_PATH=/clickhouse-library-bridge
|
||||
|
||||
export DOCKER_BASE_TAG=${DOCKER_BASE_TAG:=latest}
|
||||
export DOCKER_HELPER_TAG=${DOCKER_HELPER_TAG:=latest}
|
||||
export DOCKER_MYSQL_GOLANG_CLIENT_TAG=${DOCKER_MYSQL_GOLANG_CLIENT_TAG:=latest}
|
||||
export DOCKER_DOTNET_CLIENT_TAG=${DOCKER_DOTNET_CLIENT_TAG:=latest}
|
||||
export DOCKER_HELPER_TAG=${DOCKER_HELPER_TAG:=latest}
|
||||
export DOCKER_KERBERIZED_HADOOP_TAG=${DOCKER_KERBERIZED_HADOOP_TAG:=latest}
|
||||
export DOCKER_KERBEROS_KDC_TAG=${DOCKER_KERBEROS_KDC_TAG:=latest}
|
||||
export DOCKER_MYSQL_GOLANG_CLIENT_TAG=${DOCKER_MYSQL_GOLANG_CLIENT_TAG:=latest}
|
||||
export DOCKER_MYSQL_JAVA_CLIENT_TAG=${DOCKER_MYSQL_JAVA_CLIENT_TAG:=latest}
|
||||
export DOCKER_MYSQL_JS_CLIENT_TAG=${DOCKER_MYSQL_JS_CLIENT_TAG:=latest}
|
||||
export DOCKER_MYSQL_PHP_CLIENT_TAG=${DOCKER_MYSQL_PHP_CLIENT_TAG:=latest}
|
||||
export DOCKER_NGINX_DAV_TAG=${DOCKER_NGINX_DAV_TAG:=latest}
|
||||
export DOCKER_POSTGRESQL_JAVA_CLIENT_TAG=${DOCKER_POSTGRESQL_JAVA_CLIENT_TAG:=latest}
|
||||
export DOCKER_KERBEROS_KDC_TAG=${DOCKER_KERBEROS_KDC_TAG:=latest}
|
||||
export DOCKER_KERBERIZED_HADOOP_TAG=${DOCKER_KERBERIZED_HADOOP_TAG:=latest}
|
||||
|
||||
cd /ClickHouse/tests/integration
|
||||
exec "$@"
|
||||
|
||||
@ -11,7 +11,7 @@ ARG apt_archive="http://archive.ubuntu.com"
|
||||
RUN sed -i "s|http://archive.ubuntu.com|$apt_archive|g" /etc/apt/sources.list
|
||||
|
||||
ENV LANG=C.UTF-8
|
||||
ENV TZ=Europe/Moscow
|
||||
ENV TZ=Europe/Amsterdam
|
||||
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
|
||||
|
||||
RUN apt-get update \
|
||||
|
||||
@ -52,7 +52,7 @@ RUN mkdir -p /tmp/clickhouse-odbc-tmp \
|
||||
&& odbcinst -i -s -l -f /tmp/clickhouse-odbc-tmp/share/doc/clickhouse-odbc/config/odbc.ini.sample \
|
||||
&& rm -rf /tmp/clickhouse-odbc-tmp
|
||||
|
||||
ENV TZ=Europe/Moscow
|
||||
ENV TZ=Europe/Amsterdam
|
||||
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
|
||||
|
||||
ENV NUM_TRIES=1
|
||||
|
||||
@ -233,4 +233,10 @@ rowNumberInAllBlocks()
|
||||
LIMIT 1" < /test_output/test_results.tsv > /test_output/check_status.tsv || echo "failure\tCannot parse test_results.tsv" > /test_output/check_status.tsv
|
||||
[ -s /test_output/check_status.tsv ] || echo -e "success\tNo errors found" > /test_output/check_status.tsv
|
||||
|
||||
# But OOMs in stress test are allowed
|
||||
if rg 'OOM in dmesg|Signal 9' /test_output/check_status.tsv
|
||||
then
|
||||
sed -i 's/failure/success/' /test_output/check_status.tsv
|
||||
fi
|
||||
|
||||
collect_core_dumps
|
||||
|
||||
@ -231,4 +231,10 @@ rowNumberInAllBlocks()
|
||||
LIMIT 1" < /test_output/test_results.tsv > /test_output/check_status.tsv || echo "failure\tCannot parse test_results.tsv" > /test_output/check_status.tsv
|
||||
[ -s /test_output/check_status.tsv ] || echo -e "success\tNo errors found" > /test_output/check_status.tsv
|
||||
|
||||
# But OOMs in stress test are allowed
|
||||
if rg 'OOM in dmesg|Signal 9' /test_output/check_status.tsv
|
||||
then
|
||||
sed -i 's/failure/success/' /test_output/check_status.tsv
|
||||
fi
|
||||
|
||||
collect_core_dumps
|
||||
|
||||
@ -14,6 +14,20 @@ Supported platforms:
|
||||
- PowerPC 64 LE (experimental)
|
||||
- RISC-V 64 (experimental)
|
||||
|
||||
## Building in docker
|
||||
We use the docker image `clickhouse/binary-builder` for our CI builds. It contains everything necessary to build the binary and packages. There is a script `docker/packager/packager` to ease the image usage:
|
||||
|
||||
```bash
|
||||
# define a directory for the output artifacts
|
||||
output_dir="build_results"
|
||||
# a simplest build
|
||||
./docker/packager/packager --package-type=binary --output-dir "$output_dir"
|
||||
# build debian packages
|
||||
./docker/packager/packager --package-type=deb --output-dir "$output_dir"
|
||||
# by default, debian packages use thin LTO, so we can override it to speed up the build
|
||||
CMAKE_FLAGS='-DENABLE_THINLTO=' ./docker/packager/packager --package-type=deb --output-dir "./$(git rev-parse --show-cdup)/build_results"
|
||||
```
|
||||
|
||||
## Building on Ubuntu
|
||||
|
||||
The following tutorial is based on Ubuntu Linux.
|
||||
|
||||
@ -35,7 +35,7 @@ The [system.clusters](../../operations/system-tables/clusters.md) system table c
|
||||
|
||||
When creating a new replica of the database, this replica creates tables by itself. If the replica has been unavailable for a long time and has lagged behind the replication log — it checks its local metadata with the current metadata in ZooKeeper, moves the extra tables with data to a separate non-replicated database (so as not to accidentally delete anything superfluous), creates the missing tables, updates the table names if they have been renamed. The data is replicated at the `ReplicatedMergeTree` level, i.e. if the table is not replicated, the data will not be replicated (the database is responsible only for metadata).
|
||||
|
||||
[`ALTER TABLE ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
||||
[`ALTER TABLE FREEZE|ATTACH|FETCH|DROP|DROP DETACHED|DETACH PARTITION|PART`](../../sql-reference/statements/alter/partition.md) queries are allowed but not replicated. The database engine will only add/fetch/remove the partition/part to the current replica. However, if the table itself uses a Replicated table engine, then the data will be replicated after using `ATTACH`.
|
||||
|
||||
## Usage Example {#usage-example}
|
||||
|
||||
|
||||
@ -60,6 +60,7 @@ Engines in the family:
|
||||
- [EmbeddedRocksDB](../../engines/table-engines/integrations/embedded-rocksdb.md)
|
||||
- [RabbitMQ](../../engines/table-engines/integrations/rabbitmq.md)
|
||||
- [PostgreSQL](../../engines/table-engines/integrations/postgresql.md)
|
||||
- [S3Queue](../../engines/table-engines/integrations/s3queue.md)
|
||||
|
||||
### Special Engines {#special-engines}
|
||||
|
||||
|
||||
224
docs/en/engines/table-engines/integrations/s3queue.md
Normal file
224
docs/en/engines/table-engines/integrations/s3queue.md
Normal file
@ -0,0 +1,224 @@
|
||||
---
|
||||
slug: /en/engines/table-engines/integrations/s3queue
|
||||
sidebar_position: 7
|
||||
sidebar_label: S3Queue
|
||||
---
|
||||
|
||||
# S3Queue Table Engine
|
||||
This engine provides integration with [Amazon S3](https://aws.amazon.com/s3/) ecosystem and allows streaming import. This engine is similar to the [Kafka](../../../engines/table-engines/integrations/kafka.md), [RabbitMQ](../../../engines/table-engines/integrations/rabbitmq.md) engines, but provides S3-specific features.
|
||||
|
||||
## Create Table {#creating-a-table}
|
||||
|
||||
``` sql
|
||||
CREATE TABLE s3_queue_engine_table (name String, value UInt32)
|
||||
ENGINE = S3Queue(path [, NOSIGN | aws_access_key_id, aws_secret_access_key,] format, [compression])
|
||||
[SETTINGS]
|
||||
[mode = 'unordered',]
|
||||
[after_processing = 'keep',]
|
||||
[keeper_path = '',]
|
||||
[s3queue_loading_retries = 0,]
|
||||
[s3queue_polling_min_timeout_ms = 1000,]
|
||||
[s3queue_polling_max_timeout_ms = 10000,]
|
||||
[s3queue_polling_backoff_ms = 0,]
|
||||
[s3queue_tracked_files_limit = 1000,]
|
||||
[s3queue_tracked_file_ttl_sec = 0,]
|
||||
[s3queue_polling_size = 50,]
|
||||
```
|
||||
|
||||
**Engine parameters**
|
||||
|
||||
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings. For more information see [below](#wildcards-in-path).
|
||||
- `NOSIGN` - If this keyword is provided in place of credentials, all the requests will not be signed.
|
||||
- `format` — The [format](../../../interfaces/formats.md#formats) of the file.
|
||||
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file. For more information see [Using S3 for Data Storage](../mergetree-family/mergetree.md#table_engine-mergetree-s3).
|
||||
- `compression` — Compression type. Supported values: `none`, `gzip/gz`, `brotli/br`, `xz/LZMA`, `zstd/zst`. Parameter is optional. By default, it will autodetect compression by file extension.
|
||||
|
||||
**Example**
|
||||
|
||||
```sql
|
||||
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||
ENGINE=S3Queue('https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*', 'CSV', 'gzip')
|
||||
SETTINGS
|
||||
mode = 'ordred';
|
||||
```
|
||||
|
||||
Using named collections:
|
||||
|
||||
``` xml
|
||||
<clickhouse>
|
||||
<named_collections>
|
||||
<s3queue_conf>
|
||||
<url>'https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*</url>
|
||||
<access_key_id>test<access_key_id>
|
||||
<secret_access_key>test</secret_access_key>
|
||||
</s3queue_conf>
|
||||
</named_collections>
|
||||
</clickhouse>
|
||||
```
|
||||
|
||||
```sql
|
||||
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||
ENGINE=S3Queue(s3queue_conf, format = 'CSV', compression_method = 'gzip')
|
||||
SETTINGS
|
||||
mode = 'ordred';
|
||||
```
|
||||
|
||||
## Settings {#s3queue-settings}
|
||||
|
||||
### mode {#mode}
|
||||
|
||||
Possible values:
|
||||
|
||||
- unordered — With unordered mode, the set of all already processed files is tracked with persistent nodes in ZooKeeper.
|
||||
- ordered — With ordered mode, only the max name of the successfully consumed file, and the names of files that will be retried after unsuccessful loading attempt are being stored in ZooKeeper.
|
||||
|
||||
Default value: `unordered`.
|
||||
|
||||
### after_processing {#after_processing}
|
||||
|
||||
Delete or keep file after successful processing.
|
||||
Possible values:
|
||||
|
||||
- keep.
|
||||
- delete.
|
||||
|
||||
Default value: `keep`.
|
||||
|
||||
### keeper_path {#keeper_path}
|
||||
|
||||
The path in ZooKeeper can be specified as a table engine setting or default path can be formed from the global configuration-provided path and table UUID.
|
||||
Possible values:
|
||||
|
||||
- String.
|
||||
|
||||
Default value: `/`.
|
||||
|
||||
### s3queue_loading_retries {#s3queue_loading_retries}
|
||||
|
||||
Retry file loading up to specified number of times. By default, there are no retries.
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### s3queue_polling_min_timeout_ms {#s3queue_polling_min_timeout_ms}
|
||||
|
||||
Minimal timeout before next polling (in milliseconds).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `1000`.
|
||||
|
||||
### s3queue_polling_max_timeout_ms {#s3queue_polling_max_timeout_ms}
|
||||
|
||||
Maximum timeout before next polling (in milliseconds).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `10000`.
|
||||
|
||||
### s3queue_polling_backoff_ms {#s3queue_polling_backoff_ms}
|
||||
|
||||
Polling backoff (in milliseconds).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### s3queue_tracked_files_limit {#s3queue_tracked_files_limit}
|
||||
|
||||
Allows to limit the number of Zookeeper nodes if the 'unordered' mode is used, does nothing for 'ordered' mode.
|
||||
If limit reached the oldest processed files will be deleted from ZooKeeper node and processed again.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `1000`.
|
||||
|
||||
### s3queue_tracked_file_ttl_sec {#s3queue_tracked_file_ttl_sec}
|
||||
|
||||
Maximum number of seconds to store processed files in ZooKeeper node (store forever by default) for 'unordered' mode, does nothing for 'ordered' mode.
|
||||
After the specified number of seconds, the file will be re-imported.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### s3queue_polling_size {#s3queue_polling_size}
|
||||
|
||||
Maximum files to fetch from S3 with SELECT or in background task.
|
||||
Engine takes files for processing from S3 in batches.
|
||||
We limit the batch size to increase concurrency if multiple table engines with the same `keeper_path` consume files from the same path.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Positive integer.
|
||||
|
||||
Default value: `50`.
|
||||
|
||||
|
||||
## S3-related Settings {#s3-settings}
|
||||
|
||||
Engine supports all s3 related settings. For more information about S3 settings see [here](../../../engines/table-engines/integrations/s3.md).
|
||||
|
||||
|
||||
## Description {#description}
|
||||
|
||||
`SELECT` is not particularly useful for streaming import (except for debugging), because each file can be imported only once. It is more practical to create real-time threads using [materialized views](../../../sql-reference/statements/create/view.md). To do this:
|
||||
|
||||
1. Use the engine to create a table for consuming from specified path in S3 and consider it a data stream.
|
||||
2. Create a table with the desired structure.
|
||||
3. Create a materialized view that converts data from the engine and puts it into a previously created table.
|
||||
|
||||
When the `MATERIALIZED VIEW` joins the engine, it starts collecting data in the background.
|
||||
|
||||
Example:
|
||||
|
||||
``` sql
|
||||
CREATE TABLE s3queue_engine_table (name String, value UInt32)
|
||||
ENGINE=S3Queue('https://clickhouse-public-datasets.s3.amazonaws.com/my-test-bucket-768/*', 'CSV', 'gzip')
|
||||
SETTINGS
|
||||
mode = 'unordred',
|
||||
keeper_path = '/clickhouse/s3queue/';
|
||||
|
||||
CREATE TABLE stats (name String, value UInt32)
|
||||
ENGINE = MergeTree() ORDER BY name;
|
||||
|
||||
CREATE MATERIALIZED VIEW consumer TO stats
|
||||
AS SELECT name, value FROM s3queue_engine_table;
|
||||
|
||||
SELECT * FROM stats ORDER BY name;
|
||||
```
|
||||
|
||||
## Virtual columns {#virtual-columns}
|
||||
|
||||
- `_path` — Path to the file.
|
||||
- `_file` — Name of the file.
|
||||
|
||||
For more information about virtual columns see [here](../../../engines/table-engines/index.md#table_engines-virtual_columns).
|
||||
|
||||
|
||||
## Wildcards In Path {#wildcards-in-path}
|
||||
|
||||
`path` argument can specify multiple files using bash-like wildcards. For being processed file should exist and match to the whole path pattern. Listing of files is determined during `SELECT` (not at `CREATE` moment).
|
||||
|
||||
- `*` — Substitutes any number of any characters except `/` including empty string.
|
||||
- `?` — Substitutes any single character.
|
||||
- `{some_string,another_string,yet_another_one}` — Substitutes any of strings `'some_string', 'another_string', 'yet_another_one'`.
|
||||
- `{N..M}` — Substitutes any number in range from N to M including both borders. N and M can have leading zeroes e.g. `000..078`.
|
||||
|
||||
Constructions with `{}` are similar to the [remote](../../../sql-reference/table-functions/remote.md) table function.
|
||||
|
||||
:::note
|
||||
If the listing of files contains number ranges with leading zeros, use the construction with braces for each digit separately or use `?`.
|
||||
:::
|
||||
@ -193,6 +193,19 @@ index creation, `L2Distance` is used as default. Parameter `NumTrees` is the num
|
||||
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
||||
linearly) as well as larger index sizes.
|
||||
|
||||
`L2Distance` is also called Euclidean distance, the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points.
|
||||
For example: If we have point P(p1,p2), Q(q1,q2), their distance will be d(p,q)
|
||||

|
||||
|
||||
`cosineDistance` also called cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths.
|
||||
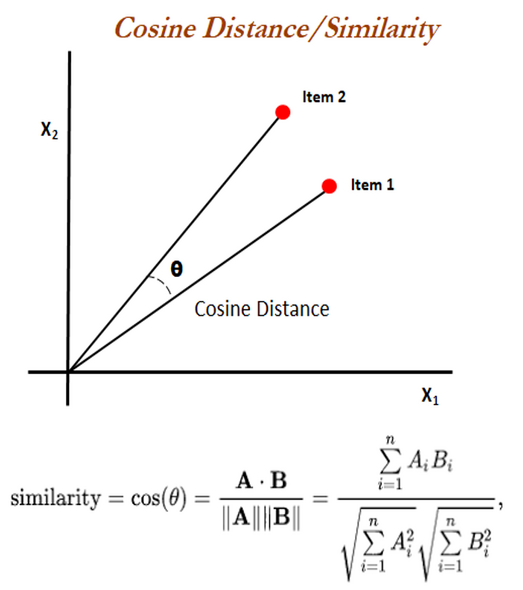
|
||||
|
||||
The Euclidean distance corresponds to the L2-norm of a difference between vectors. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
|
||||

|
||||
In one sentence: cosine similarity care only about the angle between them, but do not care about the "distance" we normally think.
|
||||
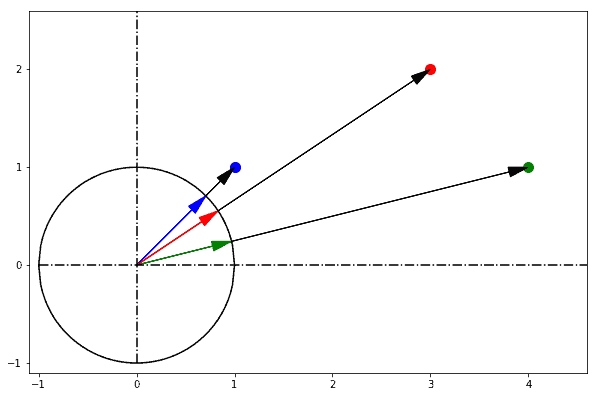
|
||||
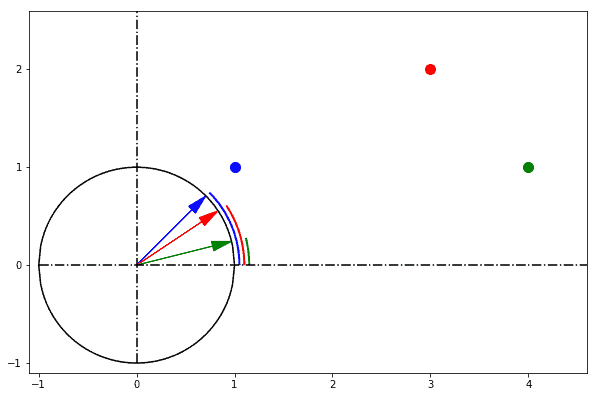
|
||||
|
||||
:::note
|
||||
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
||||
[CONSTRAINT](/docs/en/sql-reference/statements/create/table.md#constraints) to avoid errors. For example, `CONSTRAINT constraint_name_1
|
||||
|
||||
@ -106,4 +106,4 @@ For partitioning by month, use the `toYYYYMM(date_column)` expression, where `da
|
||||
## Storage Settings {#storage-settings}
|
||||
|
||||
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
||||
- [disable_url_encoding](/docs/en/operations/settings/settings.md#disable_url_encoding) -allows to disable decoding/encoding path in uri. Disabled by default.
|
||||
- [enable_url_encoding](/docs/en/operations/settings/settings.md#enable_url_encoding) - allows to enable/disable decoding/encoding path in uri. Enabled by default.
|
||||
|
||||
@ -1723,6 +1723,34 @@ You can select data from a ClickHouse table and save them into some file in the
|
||||
``` bash
|
||||
$ clickhouse-client --query = "SELECT * FROM test.hits FORMAT CapnProto SETTINGS format_schema = 'schema:Message'"
|
||||
```
|
||||
|
||||
### Using autogenerated schema {#using-autogenerated-capn-proto-schema}
|
||||
|
||||
If you don't have an external CapnProto schema for your data, you can still output/input data in CapnProto format using autogenerated schema.
|
||||
For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format CapnProto SETTINGS format_capn_proto_use_autogenerated_schema=1
|
||||
```
|
||||
|
||||
In this case ClickHouse will autogenerate CapnProto schema according to the table structure using function [structureToCapnProtoSchema](../sql-reference/functions/other-functions.md#structure_to_capn_proto_schema) and will use this schema to serialize data in CapnProto format.
|
||||
|
||||
You can also read CapnProto file with autogenerated schema (in this case the file must be created using the same schema):
|
||||
|
||||
```bash
|
||||
$ cat hits.bin | clickhouse-client --query "INSERT INTO test.hits SETTINGS format_capn_proto_use_autogenerated_schema=1 FORMAT CapnProto"
|
||||
```
|
||||
|
||||
The setting [format_capn_proto_use_autogenerated_schema](../operations/settings/settings-formats.md#format_capn_proto_use_autogenerated_schema) is enabled by default and applies if [format_schema](../operations/settings/settings-formats.md#formatschema-format-schema) is not set.
|
||||
|
||||
You can also save autogenerated schema in the file during input/output using setting [output_format_schema](../operations/settings/settings-formats.md#outputformatschema-output-format-schema). For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format CapnProto SETTINGS format_capn_proto_use_autogenerated_schema=1, output_format_schema='path/to/schema/schema.capnp'
|
||||
```
|
||||
|
||||
In this case autogenerated CapnProto schema will be saved in file `path/to/schema/schema.capnp`.
|
||||
|
||||
## Prometheus {#prometheus}
|
||||
|
||||
Expose metrics in [Prometheus text-based exposition format](https://prometheus.io/docs/instrumenting/exposition_formats/#text-based-format).
|
||||
@ -1861,6 +1889,33 @@ ClickHouse inputs and outputs protobuf messages in the `length-delimited` format
|
||||
It means before every message should be written its length as a [varint](https://developers.google.com/protocol-buffers/docs/encoding#varints).
|
||||
See also [how to read/write length-delimited protobuf messages in popular languages](https://cwiki.apache.org/confluence/display/GEODE/Delimiting+Protobuf+Messages).
|
||||
|
||||
### Using autogenerated schema {#using-autogenerated-protobuf-schema}
|
||||
|
||||
If you don't have an external Protobuf schema for your data, you can still output/input data in Protobuf format using autogenerated schema.
|
||||
For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format Protobuf SETTINGS format_protobuf_use_autogenerated_schema=1
|
||||
```
|
||||
|
||||
In this case ClickHouse will autogenerate Protobuf schema according to the table structure using function [structureToProtobufSchema](../sql-reference/functions/other-functions.md#structure_to_protobuf_schema) and will use this schema to serialize data in Protobuf format.
|
||||
|
||||
You can also read Protobuf file with autogenerated schema (in this case the file must be created using the same schema):
|
||||
|
||||
```bash
|
||||
$ cat hits.bin | clickhouse-client --query "INSERT INTO test.hits SETTINGS format_protobuf_use_autogenerated_schema=1 FORMAT Protobuf"
|
||||
```
|
||||
|
||||
The setting [format_protobuf_use_autogenerated_schema](../operations/settings/settings-formats.md#format_protobuf_use_autogenerated_schema) is enabled by default and applies if [format_schema](../operations/settings/settings-formats.md#formatschema-format-schema) is not set.
|
||||
|
||||
You can also save autogenerated schema in the file during input/output using setting [output_format_schema](../operations/settings/settings-formats.md#outputformatschema-output-format-schema). For example:
|
||||
|
||||
```sql
|
||||
SELECT * FROM test.hits format Protobuf SETTINGS format_protobuf_use_autogenerated_schema=1, output_format_schema='path/to/schema/schema.proto'
|
||||
```
|
||||
|
||||
In this case autogenerated Protobuf schema will be saved in file `path/to/schema/schema.capnp`.
|
||||
|
||||
## ProtobufSingle {#protobufsingle}
|
||||
|
||||
Same as [Protobuf](#protobuf) but for storing/parsing single Protobuf message without length delimiters.
|
||||
|
||||
@ -84,6 +84,7 @@ The BACKUP and RESTORE statements take a list of DATABASE and TABLE names, a des
|
||||
- `password` for the file on disk
|
||||
- `base_backup`: the destination of the previous backup of this source. For example, `Disk('backups', '1.zip')`
|
||||
- `structure_only`: if enabled, allows to only backup or restore the CREATE statements without the data of tables
|
||||
- `s3_storage_class`: the storage class used for S3 backup. For example, `STANDARD`
|
||||
|
||||
### Usage examples
|
||||
|
||||
|
||||
@ -0,0 +1,26 @@
|
||||
---
|
||||
slug: /en/operations/optimizing-performance/profile-guided-optimization
|
||||
sidebar_position: 54
|
||||
sidebar_label: Profile Guided Optimization (PGO)
|
||||
---
|
||||
import SelfManaged from '@site/docs/en/_snippets/_self_managed_only_no_roadmap.md';
|
||||
|
||||
# Profile Guided Optimization
|
||||
|
||||
Profile-Guided Optimization (PGO) is a compiler optimization technique where a program is optimized based on the runtime profile.
|
||||
|
||||
According to the tests, PGO helps with achieving better performance for ClickHouse. According to the tests, we see improvements up to 15% in QPS on the ClickBench test suite. The more detailed results are available [here](https://pastebin.com/xbue3HMU). The performance benefits depend on your typical workload - you can get better or worse results.
|
||||
|
||||
More information about PGO in ClickHouse you can read in the corresponding GitHub [issue](https://github.com/ClickHouse/ClickHouse/issues/44567).
|
||||
|
||||
## How to build ClickHouse with PGO?
|
||||
|
||||
There are two major kinds of PGO: [Instrumentation](https://clang.llvm.org/docs/UsersManual.html#using-sampling-profilers) and [Sampling](https://clang.llvm.org/docs/UsersManual.html#using-sampling-profilers) (also known as AutoFDO). In this guide is described the Instrumentation PGO with ClickHouse.
|
||||
|
||||
1. Build ClickHouse in Instrumented mode. In Clang it can be done via passing `-fprofile-instr-generate` option to `CXXFLAGS`.
|
||||
2. Run instrumented ClickHouse on a sample workload. Here you need to use your usual workload. One of the approaches could be using [ClickBench](https://github.com/ClickHouse/ClickBench) as a sample workload. ClickHouse in the instrumentation mode could work slowly so be ready for that and do not run instrumented ClickHouse in performance-critical environments.
|
||||
3. Recompile ClickHouse once again with `-fprofile-instr-use` compiler flags and profiles that are collected from the previous step.
|
||||
|
||||
A more detailed guide on how to apply PGO is in the Clang [documentation](https://clang.llvm.org/docs/UsersManual.html#profile-guided-optimization).
|
||||
|
||||
If you are going to collect a sample workload directly from a production environment, we recommend trying to use Sampling PGO.
|
||||
@ -2288,6 +2288,8 @@ This section contains the following parameters:
|
||||
- `session_timeout_ms` — Maximum timeout for the client session in milliseconds.
|
||||
- `operation_timeout_ms` — Maximum timeout for one operation in milliseconds.
|
||||
- `root` — The [znode](http://zookeeper.apache.org/doc/r3.5.5/zookeeperOver.html#Nodes+and+ephemeral+nodes) that is used as the root for znodes used by the ClickHouse server. Optional.
|
||||
- `fallback_session_lifetime.min` - If the first zookeeper host resolved by zookeeper_load_balancing strategy is unavailable, limit the lifetime of a zookeeper session to the fallback node. This is done for load-balancing purposes to avoid excessive load on one of zookeeper hosts. This setting sets the minimal duration of the fallback session. Set in seconds. Optional. Default is 3 hours.
|
||||
- `fallback_session_lifetime.max` - If the first zookeeper host resolved by zookeeper_load_balancing strategy is unavailable, limit the lifetime of a zookeeper session to the fallback node. This is done for load-balancing purposes to avoid excessive load on one of zookeeper hosts. This setting sets the maximum duration of the fallback session. Set in seconds. Optional. Default is 6 hours.
|
||||
- `identity` — User and password, that can be required by ZooKeeper to give access to requested znodes. Optional.
|
||||
- zookeeper_load_balancing - Specifies the algorithm of ZooKeeper node selection.
|
||||
* random - randomly selects one of ZooKeeper nodes.
|
||||
|
||||
@ -327,3 +327,39 @@ The maximum amount of data consumed by temporary files on disk in bytes for all
|
||||
Zero means unlimited.
|
||||
|
||||
Default value: 0.
|
||||
|
||||
## max_sessions_for_user {#max-sessions-per-user}
|
||||
|
||||
Maximum number of simultaneous sessions per authenticated user to the ClickHouse server.
|
||||
|
||||
Example:
|
||||
|
||||
``` xml
|
||||
<profiles>
|
||||
<single_session_profile>
|
||||
<max_sessions_for_user>1</max_sessions_for_user>
|
||||
</single_session_profile>
|
||||
<two_sessions_profile>
|
||||
<max_sessions_for_user>2</max_sessions_for_user>
|
||||
</two_sessions_profile>
|
||||
<unlimited_sessions_profile>
|
||||
<max_sessions_for_user>0</max_sessions_for_user>
|
||||
</unlimited_sessions_profile>
|
||||
</profiles>
|
||||
<users>
|
||||
<!-- User Alice can connect to a ClickHouse server no more than once at a time. -->
|
||||
<Alice>
|
||||
<profile>single_session_user</profile>
|
||||
</Alice>
|
||||
<!-- User Bob can use 2 simultaneous sessions. -->
|
||||
<Bob>
|
||||
<profile>two_sessions_profile</profile>
|
||||
</Bob>
|
||||
<!-- User Charles can use arbitrarily many of simultaneous sessions. -->
|
||||
<Charles>
|
||||
<profile>unlimited_sessions_profile</profile>
|
||||
</Charles>
|
||||
</users>
|
||||
```
|
||||
|
||||
Default value: 0 (Infinite count of simultaneous sessions).
|
||||
|
||||
@ -321,6 +321,10 @@ If both `input_format_allow_errors_num` and `input_format_allow_errors_ratio` ar
|
||||
|
||||
This parameter is useful when you are using formats that require a schema definition, such as [Cap’n Proto](https://capnproto.org/) or [Protobuf](https://developers.google.com/protocol-buffers/). The value depends on the format.
|
||||
|
||||
## output_format_schema {#output-format-schema}
|
||||
|
||||
The path to the file where the automatically generated schema will be saved in [Cap’n Proto](../../interfaces/formats.md#capnproto-capnproto) or [Protobuf](../../interfaces/formats.md#protobuf-protobuf) formats.
|
||||
|
||||
## output_format_enable_streaming {#output_format_enable_streaming}
|
||||
|
||||
Enable streaming in output formats that support it.
|
||||
@ -1330,6 +1334,11 @@ When serializing Nullable columns with Google wrappers, serialize default values
|
||||
|
||||
Disabled by default.
|
||||
|
||||
### format_protobuf_use_autogenerated_schema {#format_capn_proto_use_autogenerated_schema}
|
||||
|
||||
Use autogenerated Protobuf schema when [format_schema](#formatschema-format-schema) is not set.
|
||||
The schema is generated from ClickHouse table structure using function [structureToProtobufSchema](../../sql-reference/functions/other-functions.md#structure_to_protobuf_schema)
|
||||
|
||||
## Avro format settings {#avro-format-settings}
|
||||
|
||||
### input_format_avro_allow_missing_fields {#input_format_avro_allow_missing_fields}
|
||||
@ -1626,6 +1635,11 @@ Possible values:
|
||||
|
||||
Default value: `'by_values'`.
|
||||
|
||||
### format_capn_proto_use_autogenerated_schema {#format_capn_proto_use_autogenerated_schema}
|
||||
|
||||
Use autogenerated CapnProto schema when [format_schema](#formatschema-format-schema) is not set.
|
||||
The schema is generated from ClickHouse table structure using function [structureToCapnProtoSchema](../../sql-reference/functions/other-functions.md#structure_to_capnproto_schema)
|
||||
|
||||
## MySQLDump format settings {#musqldump-format-settings}
|
||||
|
||||
### input_format_mysql_dump_table_name (#input_format_mysql_dump_table_name)
|
||||
|
||||
@ -39,7 +39,7 @@ Example:
|
||||
<max_threads>8</max_threads>
|
||||
</default>
|
||||
|
||||
<!-- Settings for quries from the user interface -->
|
||||
<!-- Settings for queries from the user interface -->
|
||||
<web>
|
||||
<max_rows_to_read>1000000000</max_rows_to_read>
|
||||
<max_bytes_to_read>100000000000</max_bytes_to_read>
|
||||
@ -67,6 +67,8 @@ Example:
|
||||
<max_ast_depth>50</max_ast_depth>
|
||||
<max_ast_elements>100</max_ast_elements>
|
||||
|
||||
<max_sessions_for_user>4</max_sessions_for_user>
|
||||
|
||||
<readonly>1</readonly>
|
||||
</web>
|
||||
</profiles>
|
||||
|
||||
@ -3468,11 +3468,11 @@ Possible values:
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
## disable_url_encoding {#disable_url_encoding}
|
||||
## enable_url_encoding {#enable_url_encoding}
|
||||
|
||||
Allows to disable decoding/encoding path in uri in [URL](../../engines/table-engines/special/url.md) engine tables.
|
||||
Allows to enable/disable decoding/encoding path in uri in [URL](../../engines/table-engines/special/url.md) engine tables.
|
||||
|
||||
Disabled by default.
|
||||
Enabled by default.
|
||||
|
||||
## database_atomic_wait_for_drop_and_detach_synchronously {#database_atomic_wait_for_drop_and_detach_synchronously}
|
||||
|
||||
@ -4588,3 +4588,29 @@ Possible values:
|
||||
- false — Disallow.
|
||||
|
||||
Default value: `false`.
|
||||
|
||||
## precise_float_parsing {#precise_float_parsing}
|
||||
|
||||
Switches [Float32/Float64](../../sql-reference/data-types/float.md) parsing algorithms:
|
||||
* If the value is `1`, then precise method is used. It is slower than fast method, but it always returns a number that is the closest machine representable number to the input.
|
||||
* Otherwise, fast method is used (default). It usually returns the same value as precise, but in rare cases result may differ by one or two least significant digits.
|
||||
|
||||
Possible values: `0`, `1`.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
Example:
|
||||
|
||||
```sql
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 0;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7090999999999998 │ 15008753.000000002 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 1;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7091 │ 15008753 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
```
|
||||
|
||||
@ -48,7 +48,7 @@ Columns:
|
||||
- `read_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of rows read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_rows` includes the total number of rows read at all replicas. Each replica sends it’s `read_rows` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
||||
- `read_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Total number of bytes read from all tables and table functions participated in query. It includes usual subqueries, subqueries for `IN` and `JOIN`. For distributed queries `read_bytes` includes the total number of rows read at all replicas. Each replica sends it’s `read_bytes` value, and the server-initiator of the query summarizes all received and local values. The cache volumes do not affect this value.
|
||||
- `written_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written rows. For other queries, the column value is 0.
|
||||
- `written_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written bytes. For other queries, the column value is 0.
|
||||
- `written_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — For `INSERT` queries, the number of written bytes (uncompressed). For other queries, the column value is 0.
|
||||
- `result_rows` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Number of rows in a result of the `SELECT` query, or a number of rows in the `INSERT` query.
|
||||
- `result_bytes` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — RAM volume in bytes used to store a query result.
|
||||
- `memory_usage` ([UInt64](../../sql-reference/data-types/int-uint.md#uint-ranges)) — Memory consumption by the query.
|
||||
|
||||
@ -51,3 +51,7 @@ keeper foo bar
|
||||
- `rmr <path>` -- Recursively deletes path. Confirmation required
|
||||
- `flwc <command>` -- Executes four-letter-word command
|
||||
- `help` -- Prints this message
|
||||
- `get_stat [path]` -- Returns the node's stat (default `.`)
|
||||
- `find_super_nodes <threshold> [path]` -- Finds nodes with number of children larger than some threshold for the given path (default `.`)
|
||||
- `delete_stable_backups` -- Deletes ClickHouse nodes used for backups that are now inactive
|
||||
- `find_big_family [path] [n]` -- Returns the top n nodes with the biggest family in the subtree (default path = `.` and n = 10)
|
||||
|
||||
@ -140,8 +140,8 @@ Time shifts for multiple days. Some pacific islands changed their timezone offse
|
||||
- [Type conversion functions](../../sql-reference/functions/type-conversion-functions.md)
|
||||
- [Functions for working with dates and times](../../sql-reference/functions/date-time-functions.md)
|
||||
- [Functions for working with arrays](../../sql-reference/functions/array-functions.md)
|
||||
- [The `date_time_input_format` setting](../../operations/settings/settings.md#settings-date_time_input_format)
|
||||
- [The `date_time_output_format` setting](../../operations/settings/settings.md#settings-date_time_output_format)
|
||||
- [The `date_time_input_format` setting](../../operations/settings/settings-formats.md#settings-date_time_input_format)
|
||||
- [The `date_time_output_format` setting](../../operations/settings/settings-formats.md#settings-date_time_output_format)
|
||||
- [The `timezone` server configuration parameter](../../operations/server-configuration-parameters/settings.md#server_configuration_parameters-timezone)
|
||||
- [The `session_timezone` setting](../../operations/settings/settings.md#session_timezone)
|
||||
- [Operators for working with dates and times](../../sql-reference/operators/index.md#operators-datetime)
|
||||
|
||||
@ -2552,3 +2552,187 @@ Result:
|
||||
|
||||
This function can be used together with [generateRandom](../../sql-reference/table-functions/generate.md) to generate completely random tables.
|
||||
|
||||
## structureToCapnProtoSchema {#structure_to_capn_proto_schema}
|
||||
|
||||
Converts ClickHouse table structure to CapnProto schema.
|
||||
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
structureToCapnProtoSchema(structure)
|
||||
```
|
||||
|
||||
**Arguments**
|
||||
|
||||
- `structure` — Table structure in a format `column1_name column1_type, column2_name column2_type, ...`.
|
||||
- `root_struct_name` — Name for root struct in CapnProto schema. Default value - `Message`;
|
||||
|
||||
**Returned value**
|
||||
|
||||
- CapnProto schema
|
||||
|
||||
Type: [String](../../sql-reference/data-types/string.md).
|
||||
|
||||
**Examples**
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToCapnProtoSchema('column1 String, column2 UInt32, column3 Array(String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
@0xf96402dd754d0eb7;
|
||||
|
||||
struct Message
|
||||
{
|
||||
column1 @0 : Data;
|
||||
column2 @1 : UInt32;
|
||||
column3 @2 : List(Data);
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToCapnProtoSchema('column1 Nullable(String), column2 Tuple(element1 UInt32, element2 Array(String)), column3 Map(String, String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
@0xd1c8320fecad2b7f;
|
||||
|
||||
struct Message
|
||||
{
|
||||
struct Column1
|
||||
{
|
||||
union
|
||||
{
|
||||
value @0 : Data;
|
||||
null @1 : Void;
|
||||
}
|
||||
}
|
||||
column1 @0 : Column1;
|
||||
struct Column2
|
||||
{
|
||||
element1 @0 : UInt32;
|
||||
element2 @1 : List(Data);
|
||||
}
|
||||
column2 @1 : Column2;
|
||||
struct Column3
|
||||
{
|
||||
struct Entry
|
||||
{
|
||||
key @0 : Data;
|
||||
value @1 : Data;
|
||||
}
|
||||
entries @0 : List(Entry);
|
||||
}
|
||||
column3 @2 : Column3;
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToCapnProtoSchema('column1 String, column2 UInt32', 'Root') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
@0x96ab2d4ab133c6e1;
|
||||
|
||||
struct Root
|
||||
{
|
||||
column1 @0 : Data;
|
||||
column2 @1 : UInt32;
|
||||
}
|
||||
```
|
||||
|
||||
## structureToProtobufSchema {#structure_to_protobuf_schema}
|
||||
|
||||
Converts ClickHouse table structure to Protobuf schema.
|
||||
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
structureToProtobufSchema(structure)
|
||||
```
|
||||
|
||||
**Arguments**
|
||||
|
||||
- `structure` — Table structure in a format `column1_name column1_type, column2_name column2_type, ...`.
|
||||
- `root_message_name` — Name for root message in Protobuf schema. Default value - `Message`;
|
||||
|
||||
**Returned value**
|
||||
|
||||
- Protobuf schema
|
||||
|
||||
Type: [String](../../sql-reference/data-types/string.md).
|
||||
|
||||
**Examples**
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToProtobufSchema('column1 String, column2 UInt32, column3 Array(String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
syntax = "proto3";
|
||||
|
||||
message Message
|
||||
{
|
||||
bytes column1 = 1;
|
||||
uint32 column2 = 2;
|
||||
repeated bytes column3 = 3;
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToProtobufSchema('column1 Nullable(String), column2 Tuple(element1 UInt32, element2 Array(String)), column3 Map(String, String)') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
syntax = "proto3";
|
||||
|
||||
message Message
|
||||
{
|
||||
bytes column1 = 1;
|
||||
message Column2
|
||||
{
|
||||
uint32 element1 = 1;
|
||||
repeated bytes element2 = 2;
|
||||
}
|
||||
Column2 column2 = 2;
|
||||
map<string, bytes> column3 = 3;
|
||||
}
|
||||
```
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT structureToProtobufSchema('column1 String, column2 UInt32', 'Root') FORMAT RawBLOB
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
syntax = "proto3";
|
||||
|
||||
message Root
|
||||
{
|
||||
bytes column1 = 1;
|
||||
uint32 column2 = 2;
|
||||
}
|
||||
```
|
||||
|
||||
@ -56,7 +56,7 @@ Character `|` inside patterns is used to specify failover addresses. They are it
|
||||
## Storage Settings {#storage-settings}
|
||||
|
||||
- [engine_url_skip_empty_files](/docs/en/operations/settings/settings.md#engine_url_skip_empty_files) - allows to skip empty files while reading. Disabled by default.
|
||||
- [disable_url_encoding](/docs/en/operations/settings/settings.md#disable_url_encoding) - allows to disable decoding/encoding path in uri. Disabled by default.
|
||||
- [enable_url_encoding](/docs/en/operations/settings/settings.md#enable_url_encoding) - allows to enable/disable decoding/encoding path in uri. Enabled by default.
|
||||
|
||||
**See Also**
|
||||
|
||||
|
||||
@ -314,3 +314,40 @@ FORMAT Null;
|
||||
При вставке данных, ClickHouse вычисляет количество партиций во вставленном блоке. Если число партиций больше, чем `max_partitions_per_insert_block`, ClickHouse генерирует исключение со следующим текстом:
|
||||
|
||||
> «Too many partitions for single INSERT block (more than» + toString(max_parts) + «). The limit is controlled by ‘max_partitions_per_insert_block’ setting. Large number of partitions is a common misconception. It will lead to severe negative performance impact, including slow server startup, slow INSERT queries and slow SELECT queries. Recommended total number of partitions for a table is under 1000..10000. Please note, that partitioning is not intended to speed up SELECT queries (ORDER BY key is sufficient to make range queries fast). Partitions are intended for data manipulation (DROP PARTITION, etc).»
|
||||
|
||||
## max_sessions_for_user {#max-sessions-per-user}
|
||||
|
||||
Максимальное количество одновременных сессий на одного аутентифицированного пользователя.
|
||||
|
||||
Пример:
|
||||
|
||||
``` xml
|
||||
<profiles>
|
||||
<single_session_profile>
|
||||
<max_sessions_for_user>1</max_sessions_for_user>
|
||||
</single_session_profile>
|
||||
<two_sessions_profile>
|
||||
<max_sessions_for_user>2</max_sessions_for_user>
|
||||
</two_sessions_profile>
|
||||
<unlimited_sessions_profile>
|
||||
<max_sessions_for_user>0</max_sessions_for_user>
|
||||
</unlimited_sessions_profile>
|
||||
</profiles>
|
||||
<users>
|
||||
<!-- Пользователь Alice может одновременно подключаться не
|
||||
более одного раза к серверу ClickHouse. -->
|
||||
<Alice>
|
||||
<profile>single_session_profile</profile>
|
||||
</Alice>
|
||||
<!-- Пользователь Bob может использовать 2 одновременных сессии. -->
|
||||
<Bob>
|
||||
<profile>two_sessions_profile</profile>
|
||||
</Bob>
|
||||
<!-- Пользователь Charles может иметь любое количество одновременных сессий. -->
|
||||
<Charles>
|
||||
<profile>unlimited_sessions_profile</profile>
|
||||
</Charles>
|
||||
</users>
|
||||
```
|
||||
|
||||
Значение по умолчанию: 0 (неограниченное количество сессий).
|
||||
|
||||
@ -39,7 +39,7 @@ SET profile = 'web'
|
||||
<max_threads>8</max_threads>
|
||||
</default>
|
||||
|
||||
<!-- Settings for quries from the user interface -->
|
||||
<!-- Settings for queries from the user interface -->
|
||||
<web>
|
||||
<max_rows_to_read>1000000000</max_rows_to_read>
|
||||
<max_bytes_to_read>100000000000</max_bytes_to_read>
|
||||
@ -67,6 +67,7 @@ SET profile = 'web'
|
||||
<max_ast_depth>50</max_ast_depth>
|
||||
<max_ast_elements>100</max_ast_elements>
|
||||
|
||||
<max_sessions_for_user>4</max_sessions_for_user>
|
||||
<readonly>1</readonly>
|
||||
</web>
|
||||
</profiles>
|
||||
|
||||
@ -4213,3 +4213,29 @@ SELECT *, timezone() FROM test_tz WHERE d = '2000-01-01 00:00:00' SETTINGS sessi
|
||||
- Запрос: `SELECT * FROM file('sample.csv')`
|
||||
|
||||
Если чтение и обработка `sample.csv` прошли успешно, файл будет переименован в `processed_sample_1683473210851438.csv`.
|
||||
|
||||
## precise_float_parsing {#precise_float_parsing}
|
||||
|
||||
Позволяет выбрать алгоритм, используемый при парсинге [Float32/Float64](../../sql-reference/data-types/float.md):
|
||||
* Если установлено значение `1`, то используется точный метод. Он более медленный, но всегда возвращает число, наиболее близкое к входному значению.
|
||||
* В противном случае используется быстрый метод (поведение по умолчанию). Обычно результат его работы совпадает с результатом, полученным точным методом, однако в редких случаях он может отличаться на 1 или 2 наименее значимых цифры.
|
||||
|
||||
Возможные значения: `0`, `1`.
|
||||
|
||||
Значение по умолчанию: `0`.
|
||||
|
||||
Пример:
|
||||
|
||||
```sql
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 0;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7090999999999998 │ 15008753.000000002 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
|
||||
SELECT toFloat64('1.7091'), toFloat64('1.5008753E7') SETTINGS precise_float_parsing = 1;
|
||||
|
||||
┌─toFloat64('1.7091')─┬─toFloat64('1.5008753E7')─┐
|
||||
│ 1.7091 │ 15008753 │
|
||||
└─────────────────────┴──────────────────────────┘
|
||||
```
|
||||
|
||||
@ -55,6 +55,9 @@ contents:
|
||||
- src: clickhouse
|
||||
dst: /usr/bin/clickhouse-keeper
|
||||
type: symlink
|
||||
- src: clickhouse
|
||||
dst: /usr/bin/clickhouse-keeper-client
|
||||
type: symlink
|
||||
- src: root/usr/bin/clickhouse-report
|
||||
dst: /usr/bin/clickhouse-report
|
||||
- src: root/usr/bin/clickhouse-server
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
|
||||
#include "Commands.h"
|
||||
#include <queue>
|
||||
#include "KeeperClient.h"
|
||||
|
||||
|
||||
@ -24,8 +25,18 @@ void LSCommand::execute(const ASTKeeperQuery * query, KeeperClient * client) con
|
||||
else
|
||||
path = client->cwd;
|
||||
|
||||
for (const auto & child : client->zookeeper->getChildren(path))
|
||||
std::cout << child << " ";
|
||||
auto children = client->zookeeper->getChildren(path);
|
||||
std::sort(children.begin(), children.end());
|
||||
|
||||
bool need_space = false;
|
||||
for (const auto & child : children)
|
||||
{
|
||||
if (std::exchange(need_space, true))
|
||||
std::cout << " ";
|
||||
|
||||
std::cout << child;
|
||||
}
|
||||
|
||||
std::cout << "\n";
|
||||
}
|
||||
|
||||
@ -130,6 +141,173 @@ void GetCommand::execute(const ASTKeeperQuery * query, KeeperClient * client) co
|
||||
std::cout << client->zookeeper->get(client->getAbsolutePath(query->args[0].safeGet<String>())) << "\n";
|
||||
}
|
||||
|
||||
bool GetStatCommand::parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const
|
||||
{
|
||||
String arg;
|
||||
if (!parseKeeperPath(pos, expected, arg))
|
||||
return true;
|
||||
|
||||
node->args.push_back(std::move(arg));
|
||||
return true;
|
||||
}
|
||||
|
||||
void GetStatCommand::execute(const ASTKeeperQuery * query, KeeperClient * client) const
|
||||
{
|
||||
Coordination::Stat stat;
|
||||
String path;
|
||||
if (!query->args.empty())
|
||||
path = client->getAbsolutePath(query->args[0].safeGet<String>());
|
||||
else
|
||||
path = client->cwd;
|
||||
|
||||
client->zookeeper->get(path, &stat);
|
||||
|
||||
std::cout << "cZxid = " << stat.czxid << "\n";
|
||||
std::cout << "mZxid = " << stat.mzxid << "\n";
|
||||
std::cout << "pZxid = " << stat.pzxid << "\n";
|
||||
std::cout << "ctime = " << stat.ctime << "\n";
|
||||
std::cout << "mtime = " << stat.mtime << "\n";
|
||||
std::cout << "version = " << stat.version << "\n";
|
||||
std::cout << "cversion = " << stat.cversion << "\n";
|
||||
std::cout << "aversion = " << stat.aversion << "\n";
|
||||
std::cout << "ephemeralOwner = " << stat.ephemeralOwner << "\n";
|
||||
std::cout << "dataLength = " << stat.dataLength << "\n";
|
||||
std::cout << "numChildren = " << stat.numChildren << "\n";
|
||||
}
|
||||
|
||||
bool FindSuperNodes::parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const
|
||||
{
|
||||
ASTPtr threshold;
|
||||
if (!ParserUnsignedInteger{}.parse(pos, threshold, expected))
|
||||
return false;
|
||||
|
||||
node->args.push_back(threshold->as<ASTLiteral &>().value);
|
||||
|
||||
String path;
|
||||
if (!parseKeeperPath(pos, expected, path))
|
||||
path = ".";
|
||||
|
||||
node->args.push_back(std::move(path));
|
||||
return true;
|
||||
}
|
||||
|
||||
void FindSuperNodes::execute(const ASTKeeperQuery * query, KeeperClient * client) const
|
||||
{
|
||||
auto threshold = query->args[0].safeGet<UInt64>();
|
||||
auto path = client->getAbsolutePath(query->args[1].safeGet<String>());
|
||||
|
||||
Coordination::Stat stat;
|
||||
client->zookeeper->get(path, &stat);
|
||||
|
||||
if (stat.numChildren >= static_cast<Int32>(threshold))
|
||||
{
|
||||
std::cout << static_cast<String>(path) << "\t" << stat.numChildren << "\n";
|
||||
return;
|
||||
}
|
||||
|
||||
auto children = client->zookeeper->getChildren(path);
|
||||
std::sort(children.begin(), children.end());
|
||||
for (const auto & child : children)
|
||||
{
|
||||
auto next_query = *query;
|
||||
next_query.args[1] = DB::Field(path / child);
|
||||
execute(&next_query, client);
|
||||
}
|
||||
}
|
||||
|
||||
bool DeleteStableBackups::parse(IParser::Pos & /* pos */, std::shared_ptr<ASTKeeperQuery> & /* node */, Expected & /* expected */) const
|
||||
{
|
||||
return true;
|
||||
}
|
||||
|
||||
void DeleteStableBackups::execute(const ASTKeeperQuery * /* query */, KeeperClient * client) const
|
||||
{
|
||||
client->askConfirmation(
|
||||
"You are going to delete all inactive backups in /clickhouse/backups.",
|
||||
[client]
|
||||
{
|
||||
fs::path backup_root = "/clickhouse/backups";
|
||||
auto backups = client->zookeeper->getChildren(backup_root);
|
||||
std::sort(backups.begin(), backups.end());
|
||||
|
||||
for (const auto & child : backups)
|
||||
{
|
||||
auto backup_path = backup_root / child;
|
||||
std::cout << "Found backup " << backup_path << ", checking if it's active\n";
|
||||
|
||||
String stage_path = backup_path / "stage";
|
||||
auto stages = client->zookeeper->getChildren(stage_path);
|
||||
|
||||
bool is_active = false;
|
||||
for (const auto & stage : stages)
|
||||
{
|
||||
if (startsWith(stage, "alive"))
|
||||
{
|
||||
is_active = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (is_active)
|
||||
{
|
||||
std::cout << "Backup " << backup_path << " is active, not going to delete\n";
|
||||
continue;
|
||||
}
|
||||
|
||||
std::cout << "Backup " << backup_path << " is not active, deleting it\n";
|
||||
client->zookeeper->removeRecursive(backup_path);
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
bool FindBigFamily::parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const
|
||||
{
|
||||
String path;
|
||||
if (!parseKeeperPath(pos, expected, path))
|
||||
path = ".";
|
||||
|
||||
node->args.push_back(std::move(path));
|
||||
|
||||
ASTPtr count;
|
||||
if (ParserUnsignedInteger{}.parse(pos, count, expected))
|
||||
node->args.push_back(count->as<ASTLiteral &>().value);
|
||||
else
|
||||
node->args.push_back(UInt64(10));
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
void FindBigFamily::execute(const ASTKeeperQuery * query, KeeperClient * client) const
|
||||
{
|
||||
auto path = client->getAbsolutePath(query->args[0].safeGet<String>());
|
||||
auto n = query->args[1].safeGet<UInt64>();
|
||||
|
||||
std::vector<std::tuple<Int32, String>> result;
|
||||
|
||||
std::queue<fs::path> queue;
|
||||
queue.push(path);
|
||||
while (!queue.empty())
|
||||
{
|
||||
auto next_path = queue.front();
|
||||
queue.pop();
|
||||
|
||||
auto children = client->zookeeper->getChildren(next_path);
|
||||
std::transform(children.cbegin(), children.cend(), children.begin(), [&](const String & child) { return next_path / child; });
|
||||
|
||||
auto response = client->zookeeper->get(children);
|
||||
|
||||
for (size_t i = 0; i < response.size(); ++i)
|
||||
{
|
||||
result.emplace_back(response[i].stat.numChildren, children[i]);
|
||||
queue.push(children[i]);
|
||||
}
|
||||
}
|
||||
|
||||
std::sort(result.begin(), result.end(), std::greater());
|
||||
for (UInt64 i = 0; i < std::min(result.size(), static_cast<size_t>(n)); ++i)
|
||||
std::cout << std::get<1>(result[i]) << "\t" << std::get<0>(result[i]) << "\n";
|
||||
}
|
||||
|
||||
bool RMCommand::parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const
|
||||
{
|
||||
String arg;
|
||||
@ -170,7 +348,7 @@ bool HelpCommand::parse(IParser::Pos & /* pos */, std::shared_ptr<ASTKeeperQuery
|
||||
void HelpCommand::execute(const ASTKeeperQuery * /* query */, KeeperClient * /* client */) const
|
||||
{
|
||||
for (const auto & pair : KeeperClient::commands)
|
||||
std::cout << pair.second->getHelpMessage() << "\n";
|
||||
std::cout << pair.second->generateHelpString() << "\n";
|
||||
}
|
||||
|
||||
bool FourLetterWordCommand::parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const
|
||||
|
||||
@ -21,6 +21,12 @@ public:
|
||||
virtual String getName() const = 0;
|
||||
|
||||
virtual ~IKeeperClientCommand() = default;
|
||||
|
||||
String generateHelpString() const
|
||||
{
|
||||
return fmt::vformat(getHelpMessage(), fmt::make_format_args(getName()));
|
||||
}
|
||||
|
||||
};
|
||||
|
||||
using Command = std::shared_ptr<IKeeperClientCommand>;
|
||||
@ -34,7 +40,7 @@ class LSCommand : public IKeeperClientCommand
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override { return "ls [path] -- Lists the nodes for the given path (default: cwd)"; }
|
||||
String getHelpMessage() const override { return "{} [path] -- Lists the nodes for the given path (default: cwd)"; }
|
||||
};
|
||||
|
||||
class CDCommand : public IKeeperClientCommand
|
||||
@ -45,7 +51,7 @@ class CDCommand : public IKeeperClientCommand
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override { return "cd [path] -- Change the working path (default `.`)"; }
|
||||
String getHelpMessage() const override { return "{} [path] -- Change the working path (default `.`)"; }
|
||||
};
|
||||
|
||||
class SetCommand : public IKeeperClientCommand
|
||||
@ -58,7 +64,7 @@ class SetCommand : public IKeeperClientCommand
|
||||
|
||||
String getHelpMessage() const override
|
||||
{
|
||||
return "set <path> <value> [version] -- Updates the node's value. Only update if version matches (default: -1)";
|
||||
return "{} <path> <value> [version] -- Updates the node's value. Only update if version matches (default: -1)";
|
||||
}
|
||||
};
|
||||
|
||||
@ -70,7 +76,7 @@ class CreateCommand : public IKeeperClientCommand
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override { return "create <path> <value> -- Creates new node"; }
|
||||
String getHelpMessage() const override { return "{} <path> <value> -- Creates new node"; }
|
||||
};
|
||||
|
||||
class GetCommand : public IKeeperClientCommand
|
||||
@ -81,9 +87,63 @@ class GetCommand : public IKeeperClientCommand
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override { return "get <path> -- Returns the node's value"; }
|
||||
String getHelpMessage() const override { return "{} <path> -- Returns the node's value"; }
|
||||
};
|
||||
|
||||
class GetStatCommand : public IKeeperClientCommand
|
||||
{
|
||||
String getName() const override { return "get_stat"; }
|
||||
|
||||
bool parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const override;
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override { return "{} [path] -- Returns the node's stat (default `.`)"; }
|
||||
};
|
||||
|
||||
class FindSuperNodes : public IKeeperClientCommand
|
||||
{
|
||||
String getName() const override { return "find_super_nodes"; }
|
||||
|
||||
bool parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const override;
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override
|
||||
{
|
||||
return "{} <threshold> [path] -- Finds nodes with number of children larger than some threshold for the given path (default `.`)";
|
||||
}
|
||||
};
|
||||
|
||||
class DeleteStableBackups : public IKeeperClientCommand
|
||||
{
|
||||
String getName() const override { return "delete_stable_backups"; }
|
||||
|
||||
bool parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const override;
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override
|
||||
{
|
||||
return "{} -- Deletes ClickHouse nodes used for backups that are now inactive";
|
||||
}
|
||||
};
|
||||
|
||||
class FindBigFamily : public IKeeperClientCommand
|
||||
{
|
||||
String getName() const override { return "find_big_family"; }
|
||||
|
||||
bool parse(IParser::Pos & pos, std::shared_ptr<ASTKeeperQuery> & node, Expected & expected) const override;
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override
|
||||
{
|
||||
return "{} [path] [n] -- Returns the top n nodes with the biggest family in the subtree (default path = `.` and n = 10)";
|
||||
}
|
||||
};
|
||||
|
||||
|
||||
class RMCommand : public IKeeperClientCommand
|
||||
{
|
||||
String getName() const override { return "rm"; }
|
||||
@ -92,7 +152,7 @@ class RMCommand : public IKeeperClientCommand
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override { return "remove <path> -- Remove the node"; }
|
||||
String getHelpMessage() const override { return "{} <path> -- Remove the node"; }
|
||||
};
|
||||
|
||||
class RMRCommand : public IKeeperClientCommand
|
||||
@ -103,7 +163,7 @@ class RMRCommand : public IKeeperClientCommand
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override { return "rmr <path> -- Recursively deletes path. Confirmation required"; }
|
||||
String getHelpMessage() const override { return "{} <path> -- Recursively deletes path. Confirmation required"; }
|
||||
};
|
||||
|
||||
class HelpCommand : public IKeeperClientCommand
|
||||
@ -114,7 +174,7 @@ class HelpCommand : public IKeeperClientCommand
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override { return "help -- Prints this message"; }
|
||||
String getHelpMessage() const override { return "{} -- Prints this message"; }
|
||||
};
|
||||
|
||||
class FourLetterWordCommand : public IKeeperClientCommand
|
||||
@ -125,7 +185,7 @@ class FourLetterWordCommand : public IKeeperClientCommand
|
||||
|
||||
void execute(const ASTKeeperQuery * query, KeeperClient * client) const override;
|
||||
|
||||
String getHelpMessage() const override { return "flwc <command> -- Executes four-letter-word command"; }
|
||||
String getHelpMessage() const override { return "{} <command> -- Executes four-letter-word command"; }
|
||||
};
|
||||
|
||||
}
|
||||
|
||||
@ -177,6 +177,10 @@ void KeeperClient::initialize(Poco::Util::Application & /* self */)
|
||||
std::make_shared<SetCommand>(),
|
||||
std::make_shared<CreateCommand>(),
|
||||
std::make_shared<GetCommand>(),
|
||||
std::make_shared<GetStatCommand>(),
|
||||
std::make_shared<FindSuperNodes>(),
|
||||
std::make_shared<DeleteStableBackups>(),
|
||||
std::make_shared<FindBigFamily>(),
|
||||
std::make_shared<RMCommand>(),
|
||||
std::make_shared<RMRCommand>(),
|
||||
std::make_shared<HelpCommand>(),
|
||||
|
||||
@ -58,6 +58,7 @@ bool KeeperParser::parseImpl(Pos & pos, ASTPtr & node, Expected & expected)
|
||||
return false;
|
||||
|
||||
String command_name(pos->begin, pos->end);
|
||||
std::transform(command_name.begin(), command_name.end(), command_name.begin(), [](unsigned char c) { return std::tolower(c); });
|
||||
Command command;
|
||||
|
||||
auto iter = KeeperClient::commands.find(command_name);
|
||||
|
||||
@ -328,9 +328,6 @@ void ContextAccess::setRolesInfo(const std::shared_ptr<const EnabledRolesInfo> &
|
||||
|
||||
enabled_row_policies = access_control->getEnabledRowPolicies(*params.user_id, roles_info->enabled_roles);
|
||||
|
||||
enabled_quota = access_control->getEnabledQuota(
|
||||
*params.user_id, user_name, roles_info->enabled_roles, params.address, params.forwarded_address, params.quota_key);
|
||||
|
||||
enabled_settings = access_control->getEnabledSettings(
|
||||
*params.user_id, user->settings, roles_info->enabled_roles, roles_info->settings_from_enabled_roles);
|
||||
|
||||
@ -416,19 +413,32 @@ RowPolicyFilterPtr ContextAccess::getRowPolicyFilter(const String & database, co
|
||||
std::shared_ptr<const EnabledQuota> ContextAccess::getQuota() const
|
||||
{
|
||||
std::lock_guard lock{mutex};
|
||||
if (enabled_quota)
|
||||
return enabled_quota;
|
||||
static const auto unlimited_quota = EnabledQuota::getUnlimitedQuota();
|
||||
return unlimited_quota;
|
||||
|
||||
if (!enabled_quota)
|
||||
{
|
||||
if (roles_info)
|
||||
{
|
||||
enabled_quota = access_control->getEnabledQuota(*params.user_id,
|
||||
user_name,
|
||||
roles_info->enabled_roles,
|
||||
params.address,
|
||||
params.forwarded_address,
|
||||
params.quota_key);
|
||||
}
|
||||
else
|
||||
{
|
||||
static const auto unlimited_quota = EnabledQuota::getUnlimitedQuota();
|
||||
return unlimited_quota;
|
||||
}
|
||||
}
|
||||
|
||||
return enabled_quota;
|
||||
}
|
||||
|
||||
|
||||
std::optional<QuotaUsage> ContextAccess::getQuotaUsage() const
|
||||
{
|
||||
std::lock_guard lock{mutex};
|
||||
if (enabled_quota)
|
||||
return enabled_quota->getUsage();
|
||||
return {};
|
||||
return getQuota()->getUsage();
|
||||
}
|
||||
|
||||
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
#include <string_view>
|
||||
#include <unordered_map>
|
||||
#include <Access/SettingsConstraints.h>
|
||||
#include <Access/resolveSetting.h>
|
||||
#include <Access/AccessControl.h>
|
||||
@ -6,6 +7,7 @@
|
||||
#include <Storages/MergeTree/MergeTreeSettings.h>
|
||||
#include <Common/FieldVisitorToString.h>
|
||||
#include <Common/FieldVisitorsAccurateComparison.h>
|
||||
#include <Common/SettingSource.h>
|
||||
#include <IO/WriteHelpers.h>
|
||||
#include <Poco/Util/AbstractConfiguration.h>
|
||||
#include <boost/range/algorithm_ext/erase.hpp>
|
||||
@ -20,6 +22,39 @@ namespace ErrorCodes
|
||||
extern const int UNKNOWN_SETTING;
|
||||
}
|
||||
|
||||
namespace
|
||||
{
|
||||
struct SettingSourceRestrictions
|
||||
{
|
||||
constexpr SettingSourceRestrictions() { allowed_sources.set(); }
|
||||
|
||||
constexpr SettingSourceRestrictions(std::initializer_list<SettingSource> allowed_sources_)
|
||||
{
|
||||
for (auto allowed_source : allowed_sources_)
|
||||
setSourceAllowed(allowed_source, true);
|
||||
}
|
||||
|
||||
constexpr bool isSourceAllowed(SettingSource source) { return allowed_sources[source]; }
|
||||
constexpr void setSourceAllowed(SettingSource source, bool allowed) { allowed_sources[source] = allowed; }
|
||||
|
||||
std::bitset<SettingSource::COUNT> allowed_sources;
|
||||
};
|
||||
|
||||
const std::unordered_map<std::string_view, SettingSourceRestrictions> SETTINGS_SOURCE_RESTRICTIONS = {
|
||||
{"max_sessions_for_user", {SettingSource::PROFILE}},
|
||||
};
|
||||
|
||||
SettingSourceRestrictions getSettingSourceRestrictions(std::string_view name)
|
||||
{
|
||||
auto settingConstraintIter = SETTINGS_SOURCE_RESTRICTIONS.find(name);
|
||||
if (settingConstraintIter != SETTINGS_SOURCE_RESTRICTIONS.end())
|
||||
return settingConstraintIter->second;
|
||||
else
|
||||
return SettingSourceRestrictions(); // allows everything
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
SettingsConstraints::SettingsConstraints(const AccessControl & access_control_) : access_control(&access_control_)
|
||||
{
|
||||
}
|
||||
@ -98,7 +133,7 @@ void SettingsConstraints::merge(const SettingsConstraints & other)
|
||||
}
|
||||
|
||||
|
||||
void SettingsConstraints::check(const Settings & current_settings, const SettingsProfileElements & profile_elements) const
|
||||
void SettingsConstraints::check(const Settings & current_settings, const SettingsProfileElements & profile_elements, SettingSource source) const
|
||||
{
|
||||
for (const auto & element : profile_elements)
|
||||
{
|
||||
@ -108,19 +143,19 @@ void SettingsConstraints::check(const Settings & current_settings, const Setting
|
||||
if (element.value)
|
||||
{
|
||||
SettingChange value(element.setting_name, *element.value);
|
||||
check(current_settings, value);
|
||||
check(current_settings, value, source);
|
||||
}
|
||||
|
||||
if (element.min_value)
|
||||
{
|
||||
SettingChange value(element.setting_name, *element.min_value);
|
||||
check(current_settings, value);
|
||||
check(current_settings, value, source);
|
||||
}
|
||||
|
||||
if (element.max_value)
|
||||
{
|
||||
SettingChange value(element.setting_name, *element.max_value);
|
||||
check(current_settings, value);
|
||||
check(current_settings, value, source);
|
||||
}
|
||||
|
||||
SettingConstraintWritability new_value = SettingConstraintWritability::WRITABLE;
|
||||
@ -142,24 +177,24 @@ void SettingsConstraints::check(const Settings & current_settings, const Setting
|
||||
}
|
||||
}
|
||||
|
||||
void SettingsConstraints::check(const Settings & current_settings, const SettingChange & change) const
|
||||
void SettingsConstraints::check(const Settings & current_settings, const SettingChange & change, SettingSource source) const
|
||||
{
|
||||
checkImpl(current_settings, const_cast<SettingChange &>(change), THROW_ON_VIOLATION);
|
||||
checkImpl(current_settings, const_cast<SettingChange &>(change), THROW_ON_VIOLATION, source);
|
||||
}
|
||||
|
||||
void SettingsConstraints::check(const Settings & current_settings, const SettingsChanges & changes) const
|
||||
void SettingsConstraints::check(const Settings & current_settings, const SettingsChanges & changes, SettingSource source) const
|
||||
{
|
||||
for (const auto & change : changes)
|
||||
check(current_settings, change);
|
||||
check(current_settings, change, source);
|
||||
}
|
||||
|
||||
void SettingsConstraints::check(const Settings & current_settings, SettingsChanges & changes) const
|
||||
void SettingsConstraints::check(const Settings & current_settings, SettingsChanges & changes, SettingSource source) const
|
||||
{
|
||||
boost::range::remove_erase_if(
|
||||
changes,
|
||||
[&](SettingChange & change) -> bool
|
||||
{
|
||||
return !checkImpl(current_settings, const_cast<SettingChange &>(change), THROW_ON_VIOLATION);
|
||||
return !checkImpl(current_settings, const_cast<SettingChange &>(change), THROW_ON_VIOLATION, source);
|
||||
});
|
||||
}
|
||||
|
||||
@ -174,13 +209,13 @@ void SettingsConstraints::check(const MergeTreeSettings & current_settings, cons
|
||||
check(current_settings, change);
|
||||
}
|
||||
|
||||
void SettingsConstraints::clamp(const Settings & current_settings, SettingsChanges & changes) const
|
||||
void SettingsConstraints::clamp(const Settings & current_settings, SettingsChanges & changes, SettingSource source) const
|
||||
{
|
||||
boost::range::remove_erase_if(
|
||||
changes,
|
||||
[&](SettingChange & change) -> bool
|
||||
{
|
||||
return !checkImpl(current_settings, change, CLAMP_ON_VIOLATION);
|
||||
return !checkImpl(current_settings, change, CLAMP_ON_VIOLATION, source);
|
||||
});
|
||||
}
|
||||
|
||||
@ -215,7 +250,10 @@ bool getNewValueToCheck(const T & current_settings, SettingChange & change, Fiel
|
||||
return true;
|
||||
}
|
||||
|
||||
bool SettingsConstraints::checkImpl(const Settings & current_settings, SettingChange & change, ReactionOnViolation reaction) const
|
||||
bool SettingsConstraints::checkImpl(const Settings & current_settings,
|
||||
SettingChange & change,
|
||||
ReactionOnViolation reaction,
|
||||
SettingSource source) const
|
||||
{
|
||||
std::string_view setting_name = Settings::Traits::resolveName(change.name);
|
||||
|
||||
@ -247,7 +285,7 @@ bool SettingsConstraints::checkImpl(const Settings & current_settings, SettingCh
|
||||
if (!getNewValueToCheck(current_settings, change, new_value, reaction == THROW_ON_VIOLATION))
|
||||
return false;
|
||||
|
||||
return getChecker(current_settings, setting_name).check(change, new_value, reaction);
|
||||
return getChecker(current_settings, setting_name).check(change, new_value, reaction, source);
|
||||
}
|
||||
|
||||
bool SettingsConstraints::checkImpl(const MergeTreeSettings & current_settings, SettingChange & change, ReactionOnViolation reaction) const
|
||||
@ -255,10 +293,13 @@ bool SettingsConstraints::checkImpl(const MergeTreeSettings & current_settings,
|
||||
Field new_value;
|
||||
if (!getNewValueToCheck(current_settings, change, new_value, reaction == THROW_ON_VIOLATION))
|
||||
return false;
|
||||
return getMergeTreeChecker(change.name).check(change, new_value, reaction);
|
||||
return getMergeTreeChecker(change.name).check(change, new_value, reaction, SettingSource::QUERY);
|
||||
}
|
||||
|
||||
bool SettingsConstraints::Checker::check(SettingChange & change, const Field & new_value, ReactionOnViolation reaction) const
|
||||
bool SettingsConstraints::Checker::check(SettingChange & change,
|
||||
const Field & new_value,
|
||||
ReactionOnViolation reaction,
|
||||
SettingSource source) const
|
||||
{
|
||||
if (!explain.empty())
|
||||
{
|
||||
@ -326,6 +367,14 @@ bool SettingsConstraints::Checker::check(SettingChange & change, const Field & n
|
||||
change.value = max_value;
|
||||
}
|
||||
|
||||
if (!getSettingSourceRestrictions(setting_name).isSourceAllowed(source))
|
||||
{
|
||||
if (reaction == THROW_ON_VIOLATION)
|
||||
throw Exception(ErrorCodes::READONLY, "Setting {} is not allowed to be set by {}", setting_name, toString(source));
|
||||
else
|
||||
return false;
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
@ -2,6 +2,7 @@
|
||||
|
||||
#include <Access/SettingsProfileElement.h>
|
||||
#include <Common/SettingsChanges.h>
|
||||
#include <Common/SettingSource.h>
|
||||
#include <unordered_map>
|
||||
|
||||
namespace Poco::Util
|
||||
@ -73,17 +74,18 @@ public:
|
||||
void merge(const SettingsConstraints & other);
|
||||
|
||||
/// Checks whether `change` violates these constraints and throws an exception if so.
|
||||
void check(const Settings & current_settings, const SettingsProfileElements & profile_elements) const;
|
||||
void check(const Settings & current_settings, const SettingChange & change) const;
|
||||
void check(const Settings & current_settings, const SettingsChanges & changes) const;
|
||||
void check(const Settings & current_settings, SettingsChanges & changes) const;
|
||||
void check(const Settings & current_settings, const SettingsProfileElements & profile_elements, SettingSource source) const;
|
||||
void check(const Settings & current_settings, const SettingChange & change, SettingSource source) const;
|
||||
void check(const Settings & current_settings, const SettingsChanges & changes, SettingSource source) const;
|
||||
void check(const Settings & current_settings, SettingsChanges & changes, SettingSource source) const;
|
||||
|
||||
/// Checks whether `change` violates these constraints and throws an exception if so. (setting short name is expected inside `changes`)
|
||||
void check(const MergeTreeSettings & current_settings, const SettingChange & change) const;
|
||||
void check(const MergeTreeSettings & current_settings, const SettingsChanges & changes) const;
|
||||
|
||||
/// Checks whether `change` violates these and clamps the `change` if so.
|
||||
void clamp(const Settings & current_settings, SettingsChanges & changes) const;
|
||||
void clamp(const Settings & current_settings, SettingsChanges & changes, SettingSource source) const;
|
||||
|
||||
|
||||
friend bool operator ==(const SettingsConstraints & left, const SettingsConstraints & right);
|
||||
friend bool operator !=(const SettingsConstraints & left, const SettingsConstraints & right) { return !(left == right); }
|
||||
@ -133,7 +135,10 @@ private:
|
||||
{}
|
||||
|
||||
// Perform checking
|
||||
bool check(SettingChange & change, const Field & new_value, ReactionOnViolation reaction) const;
|
||||
bool check(SettingChange & change,
|
||||
const Field & new_value,
|
||||
ReactionOnViolation reaction,
|
||||
SettingSource source) const;
|
||||
};
|
||||
|
||||
struct StringHash
|
||||
@ -145,7 +150,11 @@ private:
|
||||
}
|
||||
};
|
||||
|
||||
bool checkImpl(const Settings & current_settings, SettingChange & change, ReactionOnViolation reaction) const;
|
||||
bool checkImpl(const Settings & current_settings,
|
||||
SettingChange & change,
|
||||
ReactionOnViolation reaction,
|
||||
SettingSource source) const;
|
||||
|
||||
bool checkImpl(const MergeTreeSettings & current_settings, SettingChange & change, ReactionOnViolation reaction) const;
|
||||
|
||||
Checker getChecker(const Settings & current_settings, std::string_view setting_name) const;
|
||||
|
||||
@ -0,0 +1,221 @@
|
||||
#include <Analyzer/Passes/OptimizeDateOrDateTimeConverterWithPreimagePass.h>
|
||||
|
||||
#include <Functions/FunctionFactory.h>
|
||||
|
||||
#include <Analyzer/InDepthQueryTreeVisitor.h>
|
||||
#include <Analyzer/ColumnNode.h>
|
||||
#include <Analyzer/ConstantNode.h>
|
||||
#include <Analyzer/FunctionNode.h>
|
||||
#include <Common/DateLUT.h>
|
||||
#include <Common/DateLUTImpl.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
namespace ErrorCodes
|
||||
{
|
||||
extern const int LOGICAL_ERROR;
|
||||
}
|
||||
|
||||
namespace
|
||||
{
|
||||
|
||||
class OptimizeDateOrDateTimeConverterWithPreimageVisitor : public InDepthQueryTreeVisitorWithContext<OptimizeDateOrDateTimeConverterWithPreimageVisitor>
|
||||
{
|
||||
public:
|
||||
using Base = InDepthQueryTreeVisitorWithContext<OptimizeDateOrDateTimeConverterWithPreimageVisitor>;
|
||||
|
||||
explicit OptimizeDateOrDateTimeConverterWithPreimageVisitor(ContextPtr context)
|
||||
: Base(std::move(context))
|
||||
{}
|
||||
|
||||
static bool needChildVisit(QueryTreeNodePtr & node, QueryTreeNodePtr & /*child*/)
|
||||
{
|
||||
const static std::unordered_set<String> relations = {
|
||||
"equals",
|
||||
"notEquals",
|
||||
"less",
|
||||
"greater",
|
||||
"lessOrEquals",
|
||||
"greaterOrEquals",
|
||||
};
|
||||
|
||||
if (const auto * function = node->as<FunctionNode>())
|
||||
{
|
||||
return !relations.contains(function->getFunctionName());
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
void enterImpl(QueryTreeNodePtr & node) const
|
||||
{
|
||||
const static std::unordered_map<String, String> swap_relations = {
|
||||
{"equals", "equals"},
|
||||
{"notEquals", "notEquals"},
|
||||
{"less", "greater"},
|
||||
{"greater", "less"},
|
||||
{"lessOrEquals", "greaterOrEquals"},
|
||||
{"greaterOrEquals", "lessOrEquals"},
|
||||
};
|
||||
|
||||
const auto * function = node->as<FunctionNode>();
|
||||
|
||||
if (!function || !swap_relations.contains(function->getFunctionName())) return;
|
||||
|
||||
if (function->getArguments().getNodes().size() != 2) return;
|
||||
|
||||
size_t func_id = function->getArguments().getNodes().size();
|
||||
|
||||
for (size_t i = 0; i < function->getArguments().getNodes().size(); i++)
|
||||
{
|
||||
if (const auto * func = function->getArguments().getNodes()[i]->as<FunctionNode>())
|
||||
{
|
||||
func_id = i;
|
||||
}
|
||||
}
|
||||
|
||||
if (func_id == function->getArguments().getNodes().size()) return;
|
||||
|
||||
size_t literal_id = 1 - func_id;
|
||||
const auto * literal = function->getArguments().getNodes()[literal_id]->as<ConstantNode>();
|
||||
|
||||
if (!literal || literal->getValue().getType() != Field::Types::UInt64) return;
|
||||
|
||||
String comparator = literal_id > func_id ? function->getFunctionName(): swap_relations.at(function->getFunctionName());
|
||||
|
||||
const auto * func_node = function->getArguments().getNodes()[func_id]->as<FunctionNode>();
|
||||
/// Currently we only handle single-argument functions.
|
||||
if (!func_node || func_node->getArguments().getNodes().size() != 1) return;
|
||||
|
||||
const auto * column_id = func_node->getArguments().getNodes()[0]->as<ColumnNode>();
|
||||
if (!column_id) return;
|
||||
|
||||
const auto * column_type = column_id->getColumnType().get();
|
||||
if (!isDateOrDate32(column_type) && !isDateTime(column_type) && !isDateTime64(column_type)) return;
|
||||
|
||||
const auto & converter = FunctionFactory::instance().tryGet(func_node->getFunctionName(), getContext());
|
||||
if (!converter) return;
|
||||
|
||||
ColumnsWithTypeAndName args;
|
||||
args.emplace_back(column_id->getColumnType(), "tmp");
|
||||
auto converter_base = converter->build(args);
|
||||
if (!converter_base || !converter_base->hasInformationAboutPreimage()) return;
|
||||
|
||||
auto preimage_range = converter_base->getPreimage(*(column_id->getColumnType()), literal->getValue());
|
||||
if (!preimage_range) return;
|
||||
|
||||
const auto new_node = generateOptimizedDateFilter(comparator, *column_id, *preimage_range);
|
||||
|
||||
if (!new_node) return;
|
||||
|
||||
node = new_node;
|
||||
}
|
||||
|
||||
private:
|
||||
QueryTreeNodePtr generateOptimizedDateFilter(const String & comparator, const ColumnNode & column_node, const std::pair<Field, Field>& range) const
|
||||
{
|
||||
const DateLUTImpl & date_lut = DateLUT::instance("UTC");
|
||||
|
||||
String start_date_or_date_time;
|
||||
String end_date_or_date_time;
|
||||
|
||||
if (isDateOrDate32(column_node.getColumnType().get()))
|
||||
{
|
||||
start_date_or_date_time = date_lut.dateToString(range.first.get<DateLUTImpl::Time>());
|
||||
end_date_or_date_time = date_lut.dateToString(range.second.get<DateLUTImpl::Time>());
|
||||
}
|
||||
else if (isDateTime(column_node.getColumnType().get()) || isDateTime64(column_node.getColumnType().get()))
|
||||
{
|
||||
start_date_or_date_time = date_lut.timeToString(range.first.get<DateLUTImpl::Time>());
|
||||
end_date_or_date_time = date_lut.timeToString(range.second.get<DateLUTImpl::Time>());
|
||||
}
|
||||
else [[unlikely]] return {};
|
||||
|
||||
if (comparator == "equals")
|
||||
{
|
||||
const auto lhs = std::make_shared<FunctionNode>("greaterOrEquals");
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(start_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*lhs, lhs->getFunctionName());
|
||||
|
||||
const auto rhs = std::make_shared<FunctionNode>("less");
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*rhs, rhs->getFunctionName());
|
||||
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("and");
|
||||
new_date_filter->getArguments().getNodes() = {lhs, rhs};
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "notEquals")
|
||||
{
|
||||
const auto lhs = std::make_shared<FunctionNode>("less");
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
lhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(start_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*lhs, lhs->getFunctionName());
|
||||
|
||||
const auto rhs = std::make_shared<FunctionNode>("greaterOrEquals");
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
rhs->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*rhs, rhs->getFunctionName());
|
||||
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("or");
|
||||
new_date_filter->getArguments().getNodes() = {lhs, rhs};
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "greater")
|
||||
{
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("greaterOrEquals");
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "lessOrEquals")
|
||||
{
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>("less");
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(end_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else if (comparator == "less" || comparator == "greaterOrEquals")
|
||||
{
|
||||
const auto new_date_filter = std::make_shared<FunctionNode>(comparator);
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ColumnNode>(column_node.getColumn(), column_node.getColumnSource()));
|
||||
new_date_filter->getArguments().getNodes().push_back(std::make_shared<ConstantNode>(start_date_or_date_time));
|
||||
resolveOrdinaryFunctionNode(*new_date_filter, new_date_filter->getFunctionName());
|
||||
|
||||
return new_date_filter;
|
||||
}
|
||||
else [[unlikely]]
|
||||
{
|
||||
throw Exception(ErrorCodes::LOGICAL_ERROR,
|
||||
"Expected equals, notEquals, less, lessOrEquals, greater, greaterOrEquals. Actual {}",
|
||||
comparator);
|
||||
}
|
||||
}
|
||||
|
||||
void resolveOrdinaryFunctionNode(FunctionNode & function_node, const String & function_name) const
|
||||
{
|
||||
auto function = FunctionFactory::instance().get(function_name, getContext());
|
||||
function_node.resolveAsFunction(function->build(function_node.getArgumentColumns()));
|
||||
}
|
||||
};
|
||||
|
||||
}
|
||||
|
||||
void OptimizeDateOrDateTimeConverterWithPreimagePass::run(QueryTreeNodePtr query_tree_node, ContextPtr context)
|
||||
{
|
||||
OptimizeDateOrDateTimeConverterWithPreimageVisitor visitor(std::move(context));
|
||||
visitor.visit(query_tree_node);
|
||||
}
|
||||
|
||||
}
|
||||
@ -0,0 +1,24 @@
|
||||
#pragma once
|
||||
|
||||
#include <Analyzer/IQueryTreePass.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
/** Replace predicate having Date/DateTime converters with their preimages to improve performance.
|
||||
* Given a Date column c, toYear(c) = 2023 -> c >= '2023-01-01' AND c < '2024-01-01'
|
||||
* Or if c is a DateTime column, toYear(c) = 2023 -> c >= '2023-01-01 00:00:00' AND c < '2024-01-01 00:00:00'.
|
||||
* The similar optimization also applies to other converters.
|
||||
*/
|
||||
class OptimizeDateOrDateTimeConverterWithPreimagePass final : public IQueryTreePass
|
||||
{
|
||||
public:
|
||||
String getName() override { return "OptimizeDateOrDateTimeConverterWithPreimagePass"; }
|
||||
|
||||
String getDescription() override { return "Replace predicate having Date/DateTime converters with their preimages"; }
|
||||
|
||||
void run(QueryTreeNodePtr query_tree_node, ContextPtr context) override;
|
||||
|
||||
};
|
||||
|
||||
}
|
||||
@ -6494,55 +6494,69 @@ void QueryAnalyzer::resolveArrayJoin(QueryTreeNodePtr & array_join_node, Identif
|
||||
|
||||
resolveExpressionNode(array_join_expression, scope, false /*allow_lambda_expression*/, false /*allow_table_expression*/);
|
||||
|
||||
auto result_type = array_join_expression->getResultType();
|
||||
bool is_array_type = isArray(result_type);
|
||||
bool is_map_type = isMap(result_type);
|
||||
|
||||
if (!is_array_type && !is_map_type)
|
||||
throw Exception(ErrorCodes::TYPE_MISMATCH,
|
||||
"ARRAY JOIN {} requires expression {} with Array or Map type. Actual {}. In scope {}",
|
||||
array_join_node_typed.formatASTForErrorMessage(),
|
||||
array_join_expression->formatASTForErrorMessage(),
|
||||
result_type->getName(),
|
||||
scope.scope_node->formatASTForErrorMessage());
|
||||
|
||||
if (is_map_type)
|
||||
result_type = assert_cast<const DataTypeMap &>(*result_type).getNestedType();
|
||||
|
||||
result_type = assert_cast<const DataTypeArray &>(*result_type).getNestedType();
|
||||
|
||||
String array_join_column_name;
|
||||
|
||||
if (!array_join_expression_alias.empty())
|
||||
auto process_array_join_expression = [&](QueryTreeNodePtr & expression)
|
||||
{
|
||||
array_join_column_name = array_join_expression_alias;
|
||||
}
|
||||
else if (auto * array_join_expression_inner_column = array_join_expression->as<ColumnNode>())
|
||||
auto result_type = expression->getResultType();
|
||||
bool is_array_type = isArray(result_type);
|
||||
bool is_map_type = isMap(result_type);
|
||||
|
||||
if (!is_array_type && !is_map_type)
|
||||
throw Exception(ErrorCodes::TYPE_MISMATCH,
|
||||
"ARRAY JOIN {} requires expression {} with Array or Map type. Actual {}. In scope {}",
|
||||
array_join_node_typed.formatASTForErrorMessage(),
|
||||
expression->formatASTForErrorMessage(),
|
||||
result_type->getName(),
|
||||
scope.scope_node->formatASTForErrorMessage());
|
||||
|
||||
if (is_map_type)
|
||||
result_type = assert_cast<const DataTypeMap &>(*result_type).getNestedType();
|
||||
|
||||
result_type = assert_cast<const DataTypeArray &>(*result_type).getNestedType();
|
||||
|
||||
String array_join_column_name;
|
||||
|
||||
if (!array_join_expression_alias.empty())
|
||||
{
|
||||
array_join_column_name = array_join_expression_alias;
|
||||
}
|
||||
else if (auto * array_join_expression_inner_column = array_join_expression->as<ColumnNode>())
|
||||
{
|
||||
array_join_column_name = array_join_expression_inner_column->getColumnName();
|
||||
}
|
||||
else if (!identifier_full_name.empty())
|
||||
{
|
||||
array_join_column_name = identifier_full_name;
|
||||
}
|
||||
else
|
||||
{
|
||||
array_join_column_name = "__array_join_expression_" + std::to_string(array_join_expressions_counter);
|
||||
++array_join_expressions_counter;
|
||||
}
|
||||
|
||||
if (array_join_column_names.contains(array_join_column_name))
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS,
|
||||
"ARRAY JOIN {} multiple columns with name {}. In scope {}",
|
||||
array_join_node_typed.formatASTForErrorMessage(),
|
||||
array_join_column_name,
|
||||
scope.scope_node->formatASTForErrorMessage());
|
||||
array_join_column_names.emplace(array_join_column_name);
|
||||
|
||||
NameAndTypePair array_join_column(array_join_column_name, result_type);
|
||||
auto array_join_column_node = std::make_shared<ColumnNode>(std::move(array_join_column), expression, array_join_node);
|
||||
array_join_column_node->setAlias(array_join_expression_alias);
|
||||
array_join_column_expressions.push_back(std::move(array_join_column_node));
|
||||
};
|
||||
|
||||
// Support ARRAY JOIN COLUMNS(...). COLUMNS transformer is resolved to list of columns.
|
||||
if (auto * columns_list = array_join_expression->as<ListNode>())
|
||||
{
|
||||
array_join_column_name = array_join_expression_inner_column->getColumnName();
|
||||
}
|
||||
else if (!identifier_full_name.empty())
|
||||
{
|
||||
array_join_column_name = identifier_full_name;
|
||||
for (auto & array_join_subexpression : columns_list->getNodes())
|
||||
process_array_join_expression(array_join_subexpression);
|
||||
}
|
||||
else
|
||||
{
|
||||
array_join_column_name = "__array_join_expression_" + std::to_string(array_join_expressions_counter);
|
||||
++array_join_expressions_counter;
|
||||
process_array_join_expression(array_join_expression);
|
||||
}
|
||||
|
||||
if (array_join_column_names.contains(array_join_column_name))
|
||||
throw Exception(ErrorCodes::BAD_ARGUMENTS,
|
||||
"ARRAY JOIN {} multiple columns with name {}. In scope {}",
|
||||
array_join_node_typed.formatASTForErrorMessage(),
|
||||
array_join_column_name,
|
||||
scope.scope_node->formatASTForErrorMessage());
|
||||
array_join_column_names.emplace(array_join_column_name);
|
||||
|
||||
NameAndTypePair array_join_column(array_join_column_name, result_type);
|
||||
auto array_join_column_node = std::make_shared<ColumnNode>(std::move(array_join_column), array_join_expression, array_join_node);
|
||||
array_join_column_node->setAlias(array_join_expression_alias);
|
||||
array_join_column_expressions.push_back(std::move(array_join_column_node));
|
||||
}
|
||||
|
||||
/** Allow to resolve ARRAY JOIN columns from aliases with types after ARRAY JOIN only after ARRAY JOIN expression list is resolved, because
|
||||
@ -6554,11 +6568,9 @@ void QueryAnalyzer::resolveArrayJoin(QueryTreeNodePtr & array_join_node, Identif
|
||||
* And it is expected that `value_element` inside projection expression list will be resolved as `value_element` expression
|
||||
* with type after ARRAY JOIN.
|
||||
*/
|
||||
for (size_t i = 0; i < array_join_nodes_size; ++i)
|
||||
array_join_nodes = std::move(array_join_column_expressions);
|
||||
for (auto & array_join_column_expression : array_join_nodes)
|
||||
{
|
||||
auto & array_join_column_expression = array_join_nodes[i];
|
||||
array_join_column_expression = std::move(array_join_column_expressions[i]);
|
||||
|
||||
auto it = scope.alias_name_to_expression_node.find(array_join_column_expression->getAlias());
|
||||
if (it != scope.alias_name_to_expression_node.end())
|
||||
{
|
||||
|
||||
@ -42,6 +42,7 @@
|
||||
#include <Analyzer/Passes/CrossToInnerJoinPass.h>
|
||||
#include <Analyzer/Passes/ShardNumColumnToFunctionPass.h>
|
||||
#include <Analyzer/Passes/ConvertQueryToCNFPass.h>
|
||||
#include <Analyzer/Passes/OptimizeDateOrDateTimeConverterWithPreimagePass.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
@ -278,6 +279,7 @@ void addQueryTreePasses(QueryTreePassManager & manager)
|
||||
manager.addPass(std::make_unique<AutoFinalOnQueryPass>());
|
||||
manager.addPass(std::make_unique<CrossToInnerJoinPass>());
|
||||
manager.addPass(std::make_unique<ShardNumColumnToFunctionPass>());
|
||||
manager.addPass(std::make_unique<OptimizeDateOrDateTimeConverterWithPreimagePass>());
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@ -30,6 +30,7 @@ public:
|
||||
String compression_method;
|
||||
int compression_level = -1;
|
||||
String password;
|
||||
String s3_storage_class;
|
||||
ContextPtr context;
|
||||
bool is_internal_backup = false;
|
||||
std::shared_ptr<IBackupCoordination> backup_coordination;
|
||||
|
||||
@ -88,7 +88,7 @@ namespace
|
||||
request.SetMaxKeys(1);
|
||||
auto outcome = client.ListObjects(request);
|
||||
if (!outcome.IsSuccess())
|
||||
throw Exception::createDeprecated(outcome.GetError().GetMessage(), ErrorCodes::S3_ERROR);
|
||||
throw S3Exception(outcome.GetError().GetMessage(), outcome.GetError().GetErrorType());
|
||||
return outcome.GetResult().GetContents();
|
||||
}
|
||||
|
||||
@ -178,7 +178,7 @@ void BackupReaderS3::copyFileToDisk(const String & path_in_backup, size_t file_s
|
||||
|
||||
|
||||
BackupWriterS3::BackupWriterS3(
|
||||
const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const ContextPtr & context_)
|
||||
const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const String & storage_class_name, const ContextPtr & context_)
|
||||
: BackupWriterDefault(&Poco::Logger::get("BackupWriterS3"), context_)
|
||||
, s3_uri(s3_uri_)
|
||||
, client(makeS3Client(s3_uri_, access_key_id_, secret_access_key_, context_))
|
||||
@ -188,6 +188,7 @@ BackupWriterS3::BackupWriterS3(
|
||||
request_settings.updateFromSettings(context_->getSettingsRef());
|
||||
request_settings.max_single_read_retries = context_->getSettingsRef().s3_max_single_read_retries; // FIXME: Avoid taking value for endpoint
|
||||
request_settings.allow_native_copy = allow_s3_native_copy;
|
||||
request_settings.setStorageClassName(storage_class_name);
|
||||
}
|
||||
|
||||
void BackupWriterS3::copyFileFromDisk(const String & path_in_backup, DiskPtr src_disk, const String & src_path,
|
||||
@ -271,7 +272,7 @@ void BackupWriterS3::removeFile(const String & file_name)
|
||||
request.SetKey(fs::path(s3_uri.key) / file_name);
|
||||
auto outcome = client->DeleteObject(request);
|
||||
if (!outcome.IsSuccess() && !isNotFoundError(outcome.GetError().GetErrorType()))
|
||||
throw Exception::createDeprecated(outcome.GetError().GetMessage(), ErrorCodes::S3_ERROR);
|
||||
throw S3Exception(outcome.GetError().GetMessage(), outcome.GetError().GetErrorType());
|
||||
}
|
||||
|
||||
void BackupWriterS3::removeFiles(const Strings & file_names)
|
||||
@ -329,7 +330,7 @@ void BackupWriterS3::removeFilesBatch(const Strings & file_names)
|
||||
|
||||
auto outcome = client->DeleteObjects(request);
|
||||
if (!outcome.IsSuccess() && !isNotFoundError(outcome.GetError().GetErrorType()))
|
||||
throw Exception::createDeprecated(outcome.GetError().GetMessage(), ErrorCodes::S3_ERROR);
|
||||
throw S3Exception(outcome.GetError().GetMessage(), outcome.GetError().GetErrorType());
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@ -38,7 +38,7 @@ private:
|
||||
class BackupWriterS3 : public BackupWriterDefault
|
||||
{
|
||||
public:
|
||||
BackupWriterS3(const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const ContextPtr & context_);
|
||||
BackupWriterS3(const S3::URI & s3_uri_, const String & access_key_id_, const String & secret_access_key_, bool allow_s3_native_copy, const String & storage_class_name, const ContextPtr & context_);
|
||||
~BackupWriterS3() override;
|
||||
|
||||
bool fileExists(const String & file_name) override;
|
||||
|
||||
@ -21,6 +21,7 @@ namespace ErrorCodes
|
||||
M(String, id) \
|
||||
M(String, compression_method) \
|
||||
M(String, password) \
|
||||
M(String, s3_storage_class) \
|
||||
M(Bool, structure_only) \
|
||||
M(Bool, async) \
|
||||
M(Bool, decrypt_files_from_encrypted_disks) \
|
||||
|
||||
@ -25,6 +25,9 @@ struct BackupSettings
|
||||
/// Password used to encrypt the backup.
|
||||
String password;
|
||||
|
||||
/// S3 storage class.
|
||||
String s3_storage_class = "";
|
||||
|
||||
/// If this is set to true then only create queries will be written to backup,
|
||||
/// without the data of tables.
|
||||
bool structure_only = false;
|
||||
|
||||
@ -344,6 +344,7 @@ void BackupsWorker::doBackup(
|
||||
backup_create_params.compression_method = backup_settings.compression_method;
|
||||
backup_create_params.compression_level = backup_settings.compression_level;
|
||||
backup_create_params.password = backup_settings.password;
|
||||
backup_create_params.s3_storage_class = backup_settings.s3_storage_class;
|
||||
backup_create_params.is_internal_backup = backup_settings.internal;
|
||||
backup_create_params.backup_coordination = backup_coordination;
|
||||
backup_create_params.backup_uuid = backup_settings.backup_uuid;
|
||||
|
||||
@ -112,7 +112,7 @@ void registerBackupEngineS3(BackupFactory & factory)
|
||||
}
|
||||
else
|
||||
{
|
||||
auto writer = std::make_shared<BackupWriterS3>(S3::URI{s3_uri}, access_key_id, secret_access_key, params.allow_s3_native_copy, params.context);
|
||||
auto writer = std::make_shared<BackupWriterS3>(S3::URI{s3_uri}, access_key_id, secret_access_key, params.allow_s3_native_copy, params.s3_storage_class, params.context);
|
||||
return std::make_unique<BackupImpl>(
|
||||
backup_name_for_logging,
|
||||
archive_params,
|
||||
|
||||
@ -248,6 +248,7 @@ add_object_library(clickhouse_storages_distributed Storages/Distributed)
|
||||
add_object_library(clickhouse_storages_mergetree Storages/MergeTree)
|
||||
add_object_library(clickhouse_storages_liveview Storages/LiveView)
|
||||
add_object_library(clickhouse_storages_windowview Storages/WindowView)
|
||||
add_object_library(clickhouse_storages_s3queue Storages/S3Queue)
|
||||
add_object_library(clickhouse_client Client)
|
||||
add_object_library(clickhouse_bridge BridgeHelper)
|
||||
add_object_library(clickhouse_server Server)
|
||||
|
||||
@ -124,6 +124,9 @@ void Suggest::load(ContextPtr context, const ConnectionParameters & connection_p
|
||||
if (e.code() == ErrorCodes::DEADLOCK_AVOIDED)
|
||||
continue;
|
||||
|
||||
/// Client can successfully connect to the server and
|
||||
/// get ErrorCodes::USER_SESSION_LIMIT_EXCEEDED for suggestion connection.
|
||||
|
||||
/// We should not use std::cerr here, because this method works concurrently with the main thread.
|
||||
/// WriteBufferFromFileDescriptor will write directly to the file descriptor, avoiding data race on std::cerr.
|
||||
|
||||
|
||||
@ -564,15 +564,22 @@ void ColumnNullable::updatePermutationImpl(IColumn::PermutationSortDirection dir
|
||||
else
|
||||
getNestedColumn().updatePermutation(direction, stability, limit, null_direction_hint, res, new_ranges);
|
||||
|
||||
equal_ranges = std::move(new_ranges);
|
||||
|
||||
if (unlikely(stability == PermutationSortStability::Stable))
|
||||
{
|
||||
for (auto & null_range : null_ranges)
|
||||
::sort(res.begin() + null_range.first, res.begin() + null_range.second);
|
||||
}
|
||||
|
||||
std::move(null_ranges.begin(), null_ranges.end(), std::back_inserter(equal_ranges));
|
||||
if (is_nulls_last || null_ranges.empty())
|
||||
{
|
||||
equal_ranges = std::move(new_ranges);
|
||||
std::move(null_ranges.begin(), null_ranges.end(), std::back_inserter(equal_ranges));
|
||||
}
|
||||
else
|
||||
{
|
||||
equal_ranges = std::move(null_ranges);
|
||||
std::move(new_ranges.begin(), new_ranges.end(), std::back_inserter(equal_ranges));
|
||||
}
|
||||
}
|
||||
|
||||
void ColumnNullable::getPermutation(IColumn::PermutationSortDirection direction, IColumn::PermutationSortStability stability,
|
||||
|
||||
@ -439,7 +439,7 @@ void ColumnSparse::compareColumn(const IColumn & rhs, size_t rhs_row_num,
|
||||
PaddedPODArray<UInt64> * row_indexes, PaddedPODArray<Int8> & compare_results,
|
||||
int direction, int nan_direction_hint) const
|
||||
{
|
||||
if (row_indexes)
|
||||
if (row_indexes || !typeid_cast<const ColumnSparse *>(&rhs))
|
||||
{
|
||||
/// TODO: implement without conversion to full column.
|
||||
auto this_full = convertToFullColumnIfSparse();
|
||||
|
||||
@ -582,6 +582,7 @@
|
||||
M(697, CANNOT_RESTORE_TO_NONENCRYPTED_DISK) \
|
||||
M(698, INVALID_REDIS_STORAGE_TYPE) \
|
||||
M(699, INVALID_REDIS_TABLE_STRUCTURE) \
|
||||
M(700, USER_SESSION_LIMIT_EXCEEDED) \
|
||||
\
|
||||
M(999, KEEPER_EXCEPTION) \
|
||||
M(1000, POCO_EXCEPTION) \
|
||||
|
||||
@ -208,10 +208,10 @@ void MemoryTracker::allocImpl(Int64 size, bool throw_if_memory_exceeded, MemoryT
|
||||
* we allow exception about memory limit exceeded to be thrown only on next allocation.
|
||||
* So, we allow over-allocations.
|
||||
*/
|
||||
Int64 will_be = size + amount.fetch_add(size, std::memory_order_relaxed);
|
||||
Int64 will_be = size ? size + amount.fetch_add(size, std::memory_order_relaxed) : amount.load(std::memory_order_relaxed);
|
||||
|
||||
auto metric_loaded = metric.load(std::memory_order_relaxed);
|
||||
if (metric_loaded != CurrentMetrics::end())
|
||||
if (metric_loaded != CurrentMetrics::end() && size)
|
||||
CurrentMetrics::add(metric_loaded, size);
|
||||
|
||||
Int64 current_hard_limit = hard_limit.load(std::memory_order_relaxed);
|
||||
|
||||
@ -45,6 +45,25 @@ size_t shortest_literal_length(const Literals & literals)
|
||||
return shortest;
|
||||
}
|
||||
|
||||
const char * skipNameCapturingGroup(const char * pos, size_t offset, const char * end)
|
||||
{
|
||||
const char special = *(pos + offset) == '<' ? '>' : '\'';
|
||||
offset ++;
|
||||
while (pos + offset < end)
|
||||
{
|
||||
const char cur = *(pos + offset);
|
||||
if (cur == special)
|
||||
{
|
||||
return pos + offset;
|
||||
}
|
||||
if (('0' <= cur && cur <= '9') || ('a' <= cur && cur <= 'z') || ('A' <= cur && cur <= 'Z'))
|
||||
offset ++;
|
||||
else
|
||||
return pos;
|
||||
}
|
||||
return pos;
|
||||
}
|
||||
|
||||
const char * analyzeImpl(
|
||||
std::string_view regexp,
|
||||
const char * pos,
|
||||
@ -247,10 +266,15 @@ const char * analyzeImpl(
|
||||
break;
|
||||
}
|
||||
}
|
||||
/// (?:regex) means non-capturing parentheses group
|
||||
if (pos + 2 < end && pos[1] == '?' && pos[2] == ':')
|
||||
{
|
||||
pos += 2;
|
||||
}
|
||||
if (pos + 3 < end && pos[1] == '?' && (pos[2] == '<' || pos[2] == '\'' || (pos[2] == 'P' && pos[3] == '<')))
|
||||
{
|
||||
pos = skipNameCapturingGroup(pos, pos[2] == 'P' ? 3: 2, end);
|
||||
}
|
||||
Literal group_required_substr;
|
||||
bool group_is_trival = true;
|
||||
Literals group_alters;
|
||||
|
||||
43
src/Common/SettingSource.h
Normal file
43
src/Common/SettingSource.h
Normal file
@ -0,0 +1,43 @@
|
||||
#pragma once
|
||||
|
||||
#include <string_view>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
enum SettingSource
|
||||
{
|
||||
/// Query or session change:
|
||||
/// SET <setting> = <value>
|
||||
/// SELECT ... SETTINGS [<setting> = <value]
|
||||
QUERY,
|
||||
|
||||
/// Profile creation or altering:
|
||||
/// CREATE SETTINGS PROFILE ... SETTINGS [<setting> = <value]
|
||||
/// ALTER SETTINGS PROFILE ... SETTINGS [<setting> = <value]
|
||||
PROFILE,
|
||||
|
||||
/// Role creation or altering:
|
||||
/// CREATE ROLE ... SETTINGS [<setting> = <value>]
|
||||
/// ALTER ROLE ... SETTINGS [<setting> = <value]
|
||||
ROLE,
|
||||
|
||||
/// User creation or altering:
|
||||
/// CREATE USER ... SETTINGS [<setting> = <value>]
|
||||
/// ALTER USER ... SETTINGS [<setting> = <value]
|
||||
USER,
|
||||
|
||||
COUNT,
|
||||
};
|
||||
|
||||
constexpr std::string_view toString(SettingSource source)
|
||||
{
|
||||
switch (source)
|
||||
{
|
||||
case SettingSource::QUERY: return "query";
|
||||
case SettingSource::PROFILE: return "profile";
|
||||
case SettingSource::USER: return "user";
|
||||
case SettingSource::ROLE: return "role";
|
||||
default: return "unknown";
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -492,8 +492,6 @@ public:
|
||||
/// Useful to check owner of ephemeral node.
|
||||
virtual int64_t getSessionID() const = 0;
|
||||
|
||||
virtual Poco::Net::SocketAddress getConnectedAddress() const = 0;
|
||||
|
||||
/// If the method will throw an exception, callbacks won't be called.
|
||||
///
|
||||
/// After the method is executed successfully, you must wait for callbacks
|
||||
@ -566,6 +564,10 @@ public:
|
||||
|
||||
virtual const DB::KeeperFeatureFlags * getKeeperFeatureFlags() const { return nullptr; }
|
||||
|
||||
/// A ZooKeeper session can have an optional deadline set on it.
|
||||
/// After it has been reached, the session needs to be finalized.
|
||||
virtual bool hasReachedDeadline() const = 0;
|
||||
|
||||
/// Expire session and finish all pending requests
|
||||
virtual void finalize(const String & reason) = 0;
|
||||
};
|
||||
|
||||
@ -39,8 +39,8 @@ public:
|
||||
~TestKeeper() override;
|
||||
|
||||
bool isExpired() const override { return expired; }
|
||||
bool hasReachedDeadline() const override { return false; }
|
||||
int64_t getSessionID() const override { return 0; }
|
||||
Poco::Net::SocketAddress getConnectedAddress() const override { return connected_zk_address; }
|
||||
|
||||
|
||||
void create(
|
||||
@ -135,8 +135,6 @@ private:
|
||||
|
||||
zkutil::ZooKeeperArgs args;
|
||||
|
||||
Poco::Net::SocketAddress connected_zk_address;
|
||||
|
||||
std::mutex push_request_mutex;
|
||||
std::atomic<bool> expired{false};
|
||||
|
||||
|
||||
@ -112,31 +112,17 @@ void ZooKeeper::init(ZooKeeperArgs args_)
|
||||
throw KeeperException("Cannot use any of provided ZooKeeper nodes", Coordination::Error::ZCONNECTIONLOSS);
|
||||
}
|
||||
|
||||
impl = std::make_unique<Coordination::ZooKeeper>(nodes, args, zk_log);
|
||||
impl = std::make_unique<Coordination::ZooKeeper>(nodes, args, zk_log, [this](size_t node_idx, const Coordination::ZooKeeper::Node & node)
|
||||
{
|
||||
connected_zk_host = node.address.host().toString();
|
||||
connected_zk_port = node.address.port();
|
||||
connected_zk_index = node_idx;
|
||||
});
|
||||
|
||||
if (args.chroot.empty())
|
||||
LOG_TRACE(log, "Initialized, hosts: {}", fmt::join(args.hosts, ","));
|
||||
else
|
||||
LOG_TRACE(log, "Initialized, hosts: {}, chroot: {}", fmt::join(args.hosts, ","), args.chroot);
|
||||
|
||||
Poco::Net::SocketAddress address = impl->getConnectedAddress();
|
||||
|
||||
connected_zk_host = address.host().toString();
|
||||
connected_zk_port = address.port();
|
||||
|
||||
connected_zk_index = 0;
|
||||
|
||||
if (args.hosts.size() > 1)
|
||||
{
|
||||
for (size_t i = 0; i < args.hosts.size(); i++)
|
||||
{
|
||||
if (args.hosts[i] == address.toString())
|
||||
{
|
||||
connected_zk_index = i;
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
else if (args.implementation == "testkeeper")
|
||||
{
|
||||
|
||||
@ -521,6 +521,7 @@ public:
|
||||
void setZooKeeperLog(std::shared_ptr<DB::ZooKeeperLog> zk_log_);
|
||||
|
||||
UInt32 getSessionUptime() const { return static_cast<UInt32>(session_uptime.elapsedSeconds()); }
|
||||
bool hasReachedDeadline() const { return impl->hasReachedDeadline(); }
|
||||
|
||||
void setServerCompletelyStarted();
|
||||
|
||||
|
||||
@ -204,6 +204,14 @@ void ZooKeeperArgs::initFromKeeperSection(const Poco::Util::AbstractConfiguratio
|
||||
throw DB::Exception(DB::ErrorCodes::BAD_ARGUMENTS, "Unknown load balancing: {}", load_balancing_str);
|
||||
get_priority_load_balancing.load_balancing = *load_balancing;
|
||||
}
|
||||
else if (key == "fallback_session_lifetime")
|
||||
{
|
||||
fallback_session_lifetime = SessionLifetimeConfiguration
|
||||
{
|
||||
.min_sec = config.getUInt(config_name + "." + key + ".min"),
|
||||
.max_sec = config.getUInt(config_name + "." + key + ".max"),
|
||||
};
|
||||
}
|
||||
else
|
||||
throw KeeperException(std::string("Unknown key ") + key + " in config file", Coordination::Error::ZBADARGUMENTS);
|
||||
}
|
||||
|
||||
@ -11,8 +11,17 @@ namespace Poco::Util
|
||||
namespace zkutil
|
||||
{
|
||||
|
||||
constexpr UInt32 ZK_MIN_FALLBACK_SESSION_DEADLINE_SEC = 3 * 60 * 60;
|
||||
constexpr UInt32 ZK_MAX_FALLBACK_SESSION_DEADLINE_SEC = 6 * 60 * 60;
|
||||
|
||||
struct ZooKeeperArgs
|
||||
{
|
||||
struct SessionLifetimeConfiguration
|
||||
{
|
||||
UInt32 min_sec = ZK_MIN_FALLBACK_SESSION_DEADLINE_SEC;
|
||||
UInt32 max_sec = ZK_MAX_FALLBACK_SESSION_DEADLINE_SEC;
|
||||
bool operator == (const SessionLifetimeConfiguration &) const = default;
|
||||
};
|
||||
ZooKeeperArgs(const Poco::Util::AbstractConfiguration & config, const String & config_name);
|
||||
|
||||
/// hosts_string -- comma separated [secure://]host:port list
|
||||
@ -36,6 +45,7 @@ struct ZooKeeperArgs
|
||||
UInt64 send_sleep_ms = 0;
|
||||
UInt64 recv_sleep_ms = 0;
|
||||
|
||||
SessionLifetimeConfiguration fallback_session_lifetime = {};
|
||||
DB::GetPriorityForLoadBalancing get_priority_load_balancing;
|
||||
|
||||
private:
|
||||
|
||||
@ -313,8 +313,8 @@ ZooKeeper::~ZooKeeper()
|
||||
ZooKeeper::ZooKeeper(
|
||||
const Nodes & nodes,
|
||||
const zkutil::ZooKeeperArgs & args_,
|
||||
std::shared_ptr<ZooKeeperLog> zk_log_)
|
||||
: args(args_)
|
||||
std::shared_ptr<ZooKeeperLog> zk_log_, std::optional<ConnectedCallback> && connected_callback_)
|
||||
: args(args_), connected_callback(std::move(connected_callback_))
|
||||
{
|
||||
log = &Poco::Logger::get("ZooKeeperClient");
|
||||
std::atomic_store(&zk_log, std::move(zk_log_));
|
||||
@ -395,8 +395,9 @@ void ZooKeeper::connect(
|
||||
WriteBufferFromOwnString fail_reasons;
|
||||
for (size_t try_no = 0; try_no < num_tries; ++try_no)
|
||||
{
|
||||
for (const auto & node : nodes)
|
||||
for (size_t i = 0; i < nodes.size(); ++i)
|
||||
{
|
||||
const auto & node = nodes[i];
|
||||
try
|
||||
{
|
||||
/// Reset the state of previous attempt.
|
||||
@ -443,9 +444,25 @@ void ZooKeeper::connect(
|
||||
e.addMessage("while receiving handshake from ZooKeeper");
|
||||
throw;
|
||||
}
|
||||
|
||||
connected = true;
|
||||
connected_zk_address = node.address;
|
||||
|
||||
if (connected_callback.has_value())
|
||||
(*connected_callback)(i, node);
|
||||
|
||||
if (i != 0)
|
||||
{
|
||||
std::uniform_int_distribution<UInt32> fallback_session_lifetime_distribution
|
||||
{
|
||||
args.fallback_session_lifetime.min_sec,
|
||||
args.fallback_session_lifetime.max_sec,
|
||||
};
|
||||
UInt32 session_lifetime_seconds = fallback_session_lifetime_distribution(thread_local_rng);
|
||||
client_session_deadline = clock::now() + std::chrono::seconds(session_lifetime_seconds);
|
||||
|
||||
LOG_DEBUG(log, "Connected to a suboptimal ZooKeeper host ({}, index {})."
|
||||
" To preserve balance in ZooKeeper usage, this ZooKeeper session will expire in {} seconds",
|
||||
node.address.toString(), i, session_lifetime_seconds);
|
||||
}
|
||||
|
||||
break;
|
||||
}
|
||||
@ -462,7 +479,6 @@ void ZooKeeper::connect(
|
||||
if (!connected)
|
||||
{
|
||||
WriteBufferFromOwnString message;
|
||||
connected_zk_address = Poco::Net::SocketAddress();
|
||||
|
||||
message << "All connection tries failed while connecting to ZooKeeper. nodes: ";
|
||||
bool first = true;
|
||||
@ -1060,6 +1076,7 @@ void ZooKeeper::pushRequest(RequestInfo && info)
|
||||
{
|
||||
try
|
||||
{
|
||||
checkSessionDeadline();
|
||||
info.time = clock::now();
|
||||
if (zk_log)
|
||||
{
|
||||
@ -1482,6 +1499,17 @@ void ZooKeeper::setupFaultDistributions()
|
||||
inject_setup.test_and_set();
|
||||
}
|
||||
|
||||
void ZooKeeper::checkSessionDeadline() const
|
||||
{
|
||||
if (unlikely(hasReachedDeadline()))
|
||||
throw Exception(Error::ZSESSIONEXPIRED, "Session expired (force expiry client-side)");
|
||||
}
|
||||
|
||||
bool ZooKeeper::hasReachedDeadline() const
|
||||
{
|
||||
return client_session_deadline.has_value() && clock::now() >= client_session_deadline.value();
|
||||
}
|
||||
|
||||
void ZooKeeper::maybeInjectSendFault()
|
||||
{
|
||||
if (unlikely(inject_setup.test() && send_inject_fault && send_inject_fault.value()(thread_local_rng)))
|
||||
|
||||
@ -107,6 +107,7 @@ public:
|
||||
};
|
||||
|
||||
using Nodes = std::vector<Node>;
|
||||
using ConnectedCallback = std::function<void(size_t, const Node&)>;
|
||||
|
||||
/** Connection to nodes is performed in order. If you want, shuffle them manually.
|
||||
* Operation timeout couldn't be greater than session timeout.
|
||||
@ -115,7 +116,8 @@ public:
|
||||
ZooKeeper(
|
||||
const Nodes & nodes,
|
||||
const zkutil::ZooKeeperArgs & args_,
|
||||
std::shared_ptr<ZooKeeperLog> zk_log_);
|
||||
std::shared_ptr<ZooKeeperLog> zk_log_,
|
||||
std::optional<ConnectedCallback> && connected_callback_ = {});
|
||||
|
||||
~ZooKeeper() override;
|
||||
|
||||
@ -123,11 +125,13 @@ public:
|
||||
/// If expired, you can only destroy the object. All other methods will throw exception.
|
||||
bool isExpired() const override { return requests_queue.isFinished(); }
|
||||
|
||||
/// A ZooKeeper session can have an optional deadline set on it.
|
||||
/// After it has been reached, the session needs to be finalized.
|
||||
bool hasReachedDeadline() const override;
|
||||
|
||||
/// Useful to check owner of ephemeral node.
|
||||
int64_t getSessionID() const override { return session_id; }
|
||||
|
||||
Poco::Net::SocketAddress getConnectedAddress() const override { return connected_zk_address; }
|
||||
|
||||
void executeGenericRequest(
|
||||
const ZooKeeperRequestPtr & request,
|
||||
ResponseCallback callback);
|
||||
@ -213,9 +217,9 @@ public:
|
||||
|
||||
private:
|
||||
ACLs default_acls;
|
||||
Poco::Net::SocketAddress connected_zk_address;
|
||||
|
||||
zkutil::ZooKeeperArgs args;
|
||||
std::optional<ConnectedCallback> connected_callback = {};
|
||||
|
||||
/// Fault injection
|
||||
void maybeInjectSendFault();
|
||||
@ -252,6 +256,7 @@ private:
|
||||
clock::time_point time;
|
||||
};
|
||||
|
||||
std::optional<clock::time_point> client_session_deadline {};
|
||||
using RequestsQueue = ConcurrentBoundedQueue<RequestInfo>;
|
||||
|
||||
RequestsQueue requests_queue{1024};
|
||||
@ -324,6 +329,8 @@ private:
|
||||
|
||||
void initFeatureFlags();
|
||||
|
||||
void checkSessionDeadline() const;
|
||||
|
||||
CurrentMetrics::Increment active_session_metric_increment{CurrentMetrics::ZooKeeperSession};
|
||||
std::shared_ptr<ZooKeeperLog> zk_log;
|
||||
|
||||
|
||||
@ -153,7 +153,10 @@ Pool::Entry Pool::get(uint64_t wait_timeout)
|
||||
for (auto & connection : connections)
|
||||
{
|
||||
if (connection->ref_count == 0)
|
||||
{
|
||||
logger.test("Found free connection in pool, returning it to the caller");
|
||||
return Entry(connection, this);
|
||||
}
|
||||
}
|
||||
|
||||
logger.trace("(%s): Trying to allocate a new connection.", getDescription());
|
||||
|
||||
@ -26,7 +26,7 @@ namespace mysqlxx
|
||||
*
|
||||
* void thread()
|
||||
* {
|
||||
* mysqlxx::Pool::Entry connection = pool.Get();
|
||||
* mysqlxx::Pool::Entry connection = pool.Get();
|
||||
* std::string s = connection->query("SELECT 'Hello, world!' AS world").use().fetch()["world"].getString();
|
||||
* }
|
||||
* TODO: simplify with PoolBase.
|
||||
|
||||
@ -47,4 +47,8 @@ TEST(OptimizeRE, analyze)
|
||||
test_f("abc|(:?xx|yy|zz|x?)def", "", {"abc", "def"});
|
||||
test_f("abc|(:?xx|yy|zz|x?){1,2}def", "", {"abc", "def"});
|
||||
test_f(R"(\\A(?:(?:[-0-9_a-z]+(?:\\.[-0-9_a-z]+)*)/k8s1)\\z)", "/k8s1");
|
||||
test_f("[a-zA-Z]+(?P<num>\\d+)", "");
|
||||
test_f("[a-zA-Z]+(?<num>\\d+)", "");
|
||||
test_f("[a-zA-Z]+(?'num'\\d+)", "");
|
||||
test_f("[a-zA-Z]+(?x<num>\\d+)", "x<num>");
|
||||
}
|
||||
|
||||
@ -320,8 +320,6 @@ bool KeeperDispatcher::putRequest(const Coordination::ZooKeeperRequestPtr & requ
|
||||
request_info.time = duration_cast<milliseconds>(system_clock::now().time_since_epoch()).count();
|
||||
request_info.session_id = session_id;
|
||||
|
||||
std::lock_guard lock(push_request_mutex);
|
||||
|
||||
if (shutdown_called)
|
||||
return false;
|
||||
|
||||
@ -423,13 +421,10 @@ void KeeperDispatcher::shutdown()
|
||||
try
|
||||
{
|
||||
{
|
||||
std::lock_guard lock(push_request_mutex);
|
||||
|
||||
if (shutdown_called)
|
||||
if (shutdown_called.exchange(true))
|
||||
return;
|
||||
|
||||
LOG_DEBUG(log, "Shutting down storage dispatcher");
|
||||
shutdown_called = true;
|
||||
|
||||
if (session_cleaner_thread.joinable())
|
||||
session_cleaner_thread.join();
|
||||
@ -582,12 +577,9 @@ void KeeperDispatcher::sessionCleanerTask()
|
||||
.time = duration_cast<milliseconds>(system_clock::now().time_since_epoch()).count(),
|
||||
.request = std::move(request),
|
||||
};
|
||||
{
|
||||
std::lock_guard lock(push_request_mutex);
|
||||
if (!requests_queue->push(std::move(request_info)))
|
||||
LOG_INFO(log, "Cannot push close request to queue while cleaning outdated sessions");
|
||||
CurrentMetrics::add(CurrentMetrics::KeeperOutstandingRequets);
|
||||
}
|
||||
if (!requests_queue->push(std::move(request_info)))
|
||||
LOG_INFO(log, "Cannot push close request to queue while cleaning outdated sessions");
|
||||
CurrentMetrics::add(CurrentMetrics::KeeperOutstandingRequets);
|
||||
|
||||
/// Remove session from registered sessions
|
||||
finishSession(dead_session);
|
||||
@ -607,6 +599,10 @@ void KeeperDispatcher::sessionCleanerTask()
|
||||
|
||||
void KeeperDispatcher::finishSession(int64_t session_id)
|
||||
{
|
||||
/// shutdown() method will cleanup sessions if needed
|
||||
if (shutdown_called)
|
||||
return;
|
||||
|
||||
{
|
||||
std::lock_guard lock(session_to_response_callback_mutex);
|
||||
auto session_it = session_to_response_callback.find(session_id);
|
||||
@ -698,12 +694,9 @@ int64_t KeeperDispatcher::getSessionID(int64_t session_timeout_ms)
|
||||
}
|
||||
|
||||
/// Push new session request to queue
|
||||
{
|
||||
std::lock_guard lock(push_request_mutex);
|
||||
if (!requests_queue->tryPush(std::move(request_info), session_timeout_ms))
|
||||
throw Exception(ErrorCodes::TIMEOUT_EXCEEDED, "Cannot push session id request to queue within session timeout");
|
||||
CurrentMetrics::add(CurrentMetrics::KeeperOutstandingRequets);
|
||||
}
|
||||
if (!requests_queue->tryPush(std::move(request_info), session_timeout_ms))
|
||||
throw Exception(ErrorCodes::TIMEOUT_EXCEEDED, "Cannot push session id request to queue within session timeout");
|
||||
CurrentMetrics::add(CurrentMetrics::KeeperOutstandingRequets);
|
||||
|
||||
if (future.wait_for(std::chrono::milliseconds(session_timeout_ms)) != std::future_status::ready)
|
||||
throw Exception(ErrorCodes::TIMEOUT_EXCEEDED, "Cannot receive session id within session timeout");
|
||||
@ -871,10 +864,7 @@ uint64_t KeeperDispatcher::getSnapDirSize() const
|
||||
Keeper4LWInfo KeeperDispatcher::getKeeper4LWInfo() const
|
||||
{
|
||||
Keeper4LWInfo result = server->getPartiallyFilled4LWInfo();
|
||||
{
|
||||
std::lock_guard lock(push_request_mutex);
|
||||
result.outstanding_requests_count = requests_queue->size();
|
||||
}
|
||||
result.outstanding_requests_count = requests_queue->size();
|
||||
{
|
||||
std::lock_guard lock(session_to_response_callback_mutex);
|
||||
result.alive_connections_count = session_to_response_callback.size();
|
||||
|
||||
@ -27,8 +27,6 @@ using ZooKeeperResponseCallback = std::function<void(const Coordination::ZooKeep
|
||||
class KeeperDispatcher
|
||||
{
|
||||
private:
|
||||
mutable std::mutex push_request_mutex;
|
||||
|
||||
using RequestsQueue = ConcurrentBoundedQueue<KeeperStorage::RequestForSession>;
|
||||
using SessionToResponseCallback = std::unordered_map<int64_t, ZooKeeperResponseCallback>;
|
||||
using ClusterUpdateQueue = ConcurrentBoundedQueue<ClusterUpdateAction>;
|
||||
|
||||
@ -794,8 +794,14 @@ bool KeeperServer::applyConfigUpdate(const ClusterUpdateAction & action)
|
||||
std::lock_guard _{server_write_mutex};
|
||||
|
||||
if (const auto * add = std::get_if<AddRaftServer>(&action))
|
||||
return raft_instance->get_srv_config(add->id) != nullptr
|
||||
|| raft_instance->add_srv(static_cast<nuraft::srv_config>(*add))->get_accepted();
|
||||
{
|
||||
if (raft_instance->get_srv_config(add->id) != nullptr)
|
||||
return true;
|
||||
|
||||
auto resp = raft_instance->add_srv(static_cast<nuraft::srv_config>(*add));
|
||||
resp->get();
|
||||
return resp->get_accepted();
|
||||
}
|
||||
else if (const auto * remove = std::get_if<RemoveRaftServer>(&action))
|
||||
{
|
||||
if (remove->id == raft_instance->get_leader())
|
||||
@ -807,8 +813,12 @@ bool KeeperServer::applyConfigUpdate(const ClusterUpdateAction & action)
|
||||
return false;
|
||||
}
|
||||
|
||||
return raft_instance->get_srv_config(remove->id) == nullptr
|
||||
|| raft_instance->remove_srv(remove->id)->get_accepted();
|
||||
if (raft_instance->get_srv_config(remove->id) == nullptr)
|
||||
return true;
|
||||
|
||||
auto resp = raft_instance->remove_srv(remove->id);
|
||||
resp->get();
|
||||
return resp->get_accepted();
|
||||
}
|
||||
else if (const auto * update = std::get_if<UpdateRaftServerPriority>(&action))
|
||||
{
|
||||
|
||||
@ -46,15 +46,6 @@
|
||||
|
||||
#define DBMS_MIN_REVISION_WITH_CUSTOM_SERIALIZATION 54454
|
||||
|
||||
/// Version of ClickHouse TCP protocol.
|
||||
///
|
||||
/// Should be incremented manually on protocol changes.
|
||||
///
|
||||
/// NOTE: DBMS_TCP_PROTOCOL_VERSION has nothing common with VERSION_REVISION,
|
||||
/// later is just a number for server version (one number instead of commit SHA)
|
||||
/// for simplicity (sometimes it may be more convenient in some use cases).
|
||||
#define DBMS_TCP_PROTOCOL_VERSION 54464
|
||||
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_INITIAL_QUERY_START_TIME 54449
|
||||
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_PROFILE_EVENTS_IN_INSERT 54456
|
||||
@ -77,3 +68,14 @@
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TOTAL_BYTES_IN_PROGRESS 54463
|
||||
|
||||
#define DBMS_MIN_PROTOCOL_VERSION_WITH_TIMEZONE_UPDATES 54464
|
||||
|
||||
#define DBMS_MIN_REVISION_WITH_SPARSE_SERIALIZATION 54465
|
||||
|
||||
/// Version of ClickHouse TCP protocol.
|
||||
///
|
||||
/// Should be incremented manually on protocol changes.
|
||||
///
|
||||
/// NOTE: DBMS_TCP_PROTOCOL_VERSION has nothing common with VERSION_REVISION,
|
||||
/// later is just a number for server version (one number instead of commit SHA)
|
||||
/// for simplicity (sometimes it may be more convenient in some use cases).
|
||||
#define DBMS_TCP_PROTOCOL_VERSION 54465
|
||||
|
||||
@ -104,6 +104,7 @@ class IColumn;
|
||||
M(UInt64, s3_retry_attempts, 10, "Setting for Aws::Client::RetryStrategy, Aws::Client does retries itself, 0 means no retries", 0) \
|
||||
M(UInt64, s3_request_timeout_ms, 3000, "Idleness timeout for sending and receiving data to/from S3. Fail if a single TCP read or write call blocks for this long.", 0) \
|
||||
M(Bool, enable_s3_requests_logging, false, "Enable very explicit logging of S3 requests. Makes sense for debug only.", 0) \
|
||||
M(String, s3queue_default_zookeeper_path, "/s3queue/", "Default zookeeper path prefix for S3Queue engine", 0) \
|
||||
M(UInt64, hdfs_replication, 0, "The actual number of replications can be specified when the hdfs file is created.", 0) \
|
||||
M(Bool, hdfs_truncate_on_insert, false, "Enables or disables truncate before insert in s3 engine tables", 0) \
|
||||
M(Bool, hdfs_create_new_file_on_insert, false, "Enables or disables creating a new file on each insert in hdfs engine tables", 0) \
|
||||
@ -386,6 +387,8 @@ class IColumn;
|
||||
M(UInt64, max_temporary_columns, 0, "If a query generates more than the specified number of temporary columns in memory as a result of intermediate calculation, exception is thrown. Zero value means unlimited. This setting is useful to prevent too complex queries.", 0) \
|
||||
M(UInt64, max_temporary_non_const_columns, 0, "Similar to the 'max_temporary_columns' setting but applies only to non-constant columns. This makes sense, because constant columns are cheap and it is reasonable to allow more of them.", 0) \
|
||||
\
|
||||
M(UInt64, max_sessions_for_user, 0, "Maximum number of simultaneous sessions for a user.", 0) \
|
||||
\
|
||||
M(UInt64, max_subquery_depth, 100, "If a query has more than specified number of nested subqueries, throw an exception. This allows you to have a sanity check to protect the users of your cluster from going insane with their queries.", 0) \
|
||||
M(UInt64, max_analyze_depth, 5000, "Maximum number of analyses performed by interpreter.", 0) \
|
||||
M(UInt64, max_ast_depth, 1000, "Maximum depth of query syntax tree. Checked after parsing.", 0) \
|
||||
@ -625,7 +628,7 @@ class IColumn;
|
||||
M(Bool, engine_file_allow_create_multiple_files, false, "Enables or disables creating a new file on each insert in file engine tables if format has suffix.", 0) \
|
||||
M(Bool, engine_file_skip_empty_files, false, "Allows to skip empty files in file table engine", 0) \
|
||||
M(Bool, engine_url_skip_empty_files, false, "Allows to skip empty files in url table engine", 0) \
|
||||
M(Bool, disable_url_encoding, false, " Allows to disable decoding/encoding path in uri in URL table engine", 0) \
|
||||
M(Bool, enable_url_encoding, true, " Allows to enable/disable decoding/encoding path in uri in URL table engine", 0) \
|
||||
M(Bool, allow_experimental_database_replicated, false, "Allow to create databases with Replicated engine", 0) \
|
||||
M(UInt64, database_replicated_initial_query_timeout_sec, 300, "How long initial DDL query should wait for Replicated database to precess previous DDL queue entries", 0) \
|
||||
M(Bool, database_replicated_enforce_synchronous_settings, false, "Enforces synchronous waiting for some queries (see also database_atomic_wait_for_drop_and_detach_synchronously, mutation_sync, alter_sync). Not recommended to enable these settings.", 0) \
|
||||
@ -1010,6 +1013,10 @@ class IColumn;
|
||||
\
|
||||
M(CapnProtoEnumComparingMode, format_capn_proto_enum_comparising_mode, FormatSettings::CapnProtoEnumComparingMode::BY_VALUES, "How to map ClickHouse Enum and CapnProto Enum", 0) \
|
||||
\
|
||||
M(Bool, format_capn_proto_use_autogenerated_schema, true, "Use autogenerated CapnProto schema when format_schema is not set", 0) \
|
||||
M(Bool, format_protobuf_use_autogenerated_schema, true, "Use autogenerated Protobuf when format_schema is not set", 0) \
|
||||
M(String, output_format_schema, "", "The path to the file where the automatically generated schema will be saved", 0) \
|
||||
\
|
||||
M(String, input_format_mysql_dump_table_name, "", "Name of the table in MySQL dump from which to read data", 0) \
|
||||
M(Bool, input_format_mysql_dump_map_column_names, true, "Match columns from table in MySQL dump and columns from ClickHouse table by names", 0) \
|
||||
\
|
||||
@ -1026,7 +1033,8 @@ class IColumn;
|
||||
M(Bool, regexp_dict_allow_hyperscan, true, "Allow regexp_tree dictionary using Hyperscan library.", 0) \
|
||||
\
|
||||
M(Bool, dictionary_use_async_executor, false, "Execute a pipeline for reading from a dictionary with several threads. It's supported only by DIRECT dictionary with CLICKHOUSE source.", 0) \
|
||||
M(Bool, input_format_csv_allow_variable_number_of_columns, false, "Ignore extra columns in CSV input (if file has more columns than expected) and treat missing fields in CSV input as default values", 0) \
|
||||
M(Bool, input_format_csv_allow_variable_number_of_columns, false, "Ignore extra columns in CSV input (if file has more columns than expected) and treat missing fields in CSV input as default values", 0) \
|
||||
M(Bool, precise_float_parsing, false, "Prefer more precise (but slower) float parsing algorithm", 0) \
|
||||
|
||||
// End of FORMAT_FACTORY_SETTINGS
|
||||
// Please add settings non-related to formats into the COMMON_SETTINGS above.
|
||||
|
||||
@ -175,4 +175,11 @@ IMPLEMENT_SETTING_ENUM(ORCCompression, ErrorCodes::BAD_ARGUMENTS,
|
||||
{"zlib", FormatSettings::ORCCompression::ZLIB},
|
||||
{"lz4", FormatSettings::ORCCompression::LZ4}})
|
||||
|
||||
IMPLEMENT_SETTING_ENUM(S3QueueMode, ErrorCodes::BAD_ARGUMENTS,
|
||||
{{"ordered", S3QueueMode::ORDERED},
|
||||
{"unordered", S3QueueMode::UNORDERED}})
|
||||
|
||||
IMPLEMENT_SETTING_ENUM(S3QueueAction, ErrorCodes::BAD_ARGUMENTS,
|
||||
{{"keep", S3QueueAction::KEEP},
|
||||
{"delete", S3QueueAction::DELETE}})
|
||||
}
|
||||
|
||||
@ -221,4 +221,21 @@ enum class ParallelReplicasCustomKeyFilterType : uint8_t
|
||||
DECLARE_SETTING_ENUM(ParallelReplicasCustomKeyFilterType)
|
||||
|
||||
DECLARE_SETTING_ENUM(LocalFSReadMethod)
|
||||
|
||||
enum class S3QueueMode
|
||||
{
|
||||
ORDERED,
|
||||
UNORDERED,
|
||||
};
|
||||
|
||||
DECLARE_SETTING_ENUM(S3QueueMode)
|
||||
|
||||
enum class S3QueueAction
|
||||
{
|
||||
KEEP,
|
||||
DELETE,
|
||||
};
|
||||
|
||||
DECLARE_SETTING_ENUM(S3QueueAction)
|
||||
|
||||
}
|
||||
|
||||
@ -666,7 +666,7 @@ void DatabaseReplicated::checkQueryValid(const ASTPtr & query, ContextPtr query_
|
||||
{
|
||||
for (const auto & command : query_alter->command_list->children)
|
||||
{
|
||||
if (!isSupportedAlterType(command->as<ASTAlterCommand&>().type))
|
||||
if (!isSupportedAlterTypeForOnClusterDDLQuery(command->as<ASTAlterCommand&>().type))
|
||||
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Unsupported type of ALTER query");
|
||||
}
|
||||
}
|
||||
@ -1474,7 +1474,7 @@ bool DatabaseReplicated::shouldReplicateQuery(const ContextPtr & query_context,
|
||||
/// Some ALTERs are not replicated on database level
|
||||
if (const auto * alter = query_ptr->as<const ASTAlterQuery>())
|
||||
{
|
||||
if (alter->isAttachAlter() || alter->isFetchAlter() || alter->isDropPartitionAlter() || is_keeper_map_table(query_ptr))
|
||||
if (alter->isAttachAlter() || alter->isFetchAlter() || alter->isDropPartitionAlter() || is_keeper_map_table(query_ptr) || alter->isFreezeAlter())
|
||||
return false;
|
||||
|
||||
if (has_many_shards() || !is_replicated_table(query_ptr))
|
||||
|
||||
@ -65,6 +65,7 @@ void DatabaseMaterializedMySQL::setException(const std::exception_ptr & exceptio
|
||||
|
||||
void DatabaseMaterializedMySQL::startupTables(ThreadPool & thread_pool, LoadingStrictnessLevel mode)
|
||||
{
|
||||
LOG_TRACE(log, "Starting MaterializeMySQL tables");
|
||||
DatabaseAtomic::startupTables(thread_pool, mode);
|
||||
|
||||
if (mode < LoadingStrictnessLevel::FORCE_ATTACH)
|
||||
@ -122,6 +123,7 @@ void DatabaseMaterializedMySQL::alterTable(ContextPtr context_, const StorageID
|
||||
|
||||
void DatabaseMaterializedMySQL::drop(ContextPtr context_)
|
||||
{
|
||||
LOG_TRACE(log, "Dropping MaterializeMySQL database");
|
||||
/// Remove metadata info
|
||||
fs::path metadata(getMetadataPath() + "/.metadata");
|
||||
|
||||
|
||||
@ -11,6 +11,7 @@
|
||||
#include <Databases/DatabaseAtomic.h>
|
||||
#include <Databases/MySQL/MaterializedMySQLSettings.h>
|
||||
#include <Databases/MySQL/MaterializedMySQLSyncThread.h>
|
||||
#include <Common/logger_useful.h>
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
#include "Common/logger_useful.h"
|
||||
#include "config.h"
|
||||
|
||||
#if USE_MYSQL
|
||||
@ -499,7 +500,10 @@ bool MaterializedMySQLSyncThread::prepareSynchronized(MaterializeMetadata & meta
|
||||
{
|
||||
throw;
|
||||
}
|
||||
catch (const mysqlxx::ConnectionFailed &) {}
|
||||
catch (const mysqlxx::ConnectionFailed & ex)
|
||||
{
|
||||
LOG_TRACE(log, "Connection to MySQL failed {}", ex.displayText());
|
||||
}
|
||||
catch (const mysqlxx::BadQuery & e)
|
||||
{
|
||||
// Lost connection to MySQL server during query
|
||||
|
||||
@ -14,7 +14,7 @@ namespace ErrorCodes
|
||||
}
|
||||
|
||||
WriteBufferFromTemporaryFile::WriteBufferFromTemporaryFile(TemporaryFileOnDiskHolder && tmp_file_)
|
||||
: WriteBufferFromFile(tmp_file_->getPath(), DBMS_DEFAULT_BUFFER_SIZE, O_RDWR | O_TRUNC | O_CREAT, /* throttler= */ {}, 0600)
|
||||
: WriteBufferFromFile(tmp_file_->getAbsolutePath(), DBMS_DEFAULT_BUFFER_SIZE, O_RDWR | O_TRUNC | O_CREAT, /* throttler= */ {}, 0600)
|
||||
, tmp_file(std::move(tmp_file_))
|
||||
{
|
||||
}
|
||||
|
||||
@ -135,7 +135,7 @@ private:
|
||||
return result;
|
||||
}
|
||||
|
||||
throw Exception(ErrorCodes::S3_ERROR, "Could not list objects in bucket {} with prefix {}, S3 exception: {}, message: {}",
|
||||
throw S3Exception(outcome.GetError().GetErrorType(), "Could not list objects in bucket {} with prefix {}, S3 exception: {}, message: {}",
|
||||
quoteString(request.GetBucket()), quoteString(request.GetPrefix()),
|
||||
backQuote(outcome.GetError().GetExceptionName()), quoteString(outcome.GetError().GetMessage()));
|
||||
}
|
||||
|
||||
@ -54,7 +54,7 @@ TemporaryFileOnDisk::TemporaryFileOnDisk(const DiskPtr & disk_, const String & p
|
||||
throw Exception(ErrorCodes::LOGICAL_ERROR, "Temporary file name is empty");
|
||||
}
|
||||
|
||||
String TemporaryFileOnDisk::getPath() const
|
||||
String TemporaryFileOnDisk::getAbsolutePath() const
|
||||
{
|
||||
return std::filesystem::path(disk->getPath()) / relative_path;
|
||||
}
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user