mirror of
https://github.com/ClickHouse/ClickHouse.git
synced 2024-11-22 15:42:02 +00:00
Merge branch 'master' into alternative-keeper-configs
This commit is contained in:
commit
f5e97fbb66
2
.github/workflows/backport_branches.yml
vendored
2
.github/workflows/backport_branches.yml
vendored
@ -470,7 +470,7 @@ jobs:
|
||||
cd "$GITHUB_WORKSPACE/tests/ci"
|
||||
python3 docker_server.py --release-type head --no-push \
|
||||
--image-repo clickhouse/clickhouse-server --image-path docker/server
|
||||
python3 docker_server.py --release-type head --no-push --no-ubuntu \
|
||||
python3 docker_server.py --release-type head --no-push \
|
||||
--image-repo clickhouse/clickhouse-keeper --image-path docker/keeper
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
|
||||
789
.github/workflows/master.yml
vendored
789
.github/workflows/master.yml
vendored
@ -862,7 +862,7 @@ jobs:
|
||||
cd "$GITHUB_WORKSPACE/tests/ci"
|
||||
python3 docker_server.py --release-type head \
|
||||
--image-repo clickhouse/clickhouse-server --image-path docker/server
|
||||
python3 docker_server.py --release-type head --no-ubuntu \
|
||||
python3 docker_server.py --release-type head \
|
||||
--image-repo clickhouse/clickhouse-keeper --image-path docker/keeper
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
@ -1131,7 +1131,7 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_database_replicated/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=2
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1167,6 +1167,114 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_database_replicated/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestReleaseDatabaseReplicated2:
|
||||
needs: [BuilderDebRelease]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_database_replicated
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (release, DatabaseReplicated)
|
||||
REPO_COPY=${{runner.temp}}/stateless_database_replicated/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=2
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestReleaseDatabaseReplicated3:
|
||||
needs: [BuilderDebRelease]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_database_replicated
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (release, DatabaseReplicated)
|
||||
REPO_COPY=${{runner.temp}}/stateless_database_replicated/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=3
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestReleaseS3_0:
|
||||
needs: [BuilderDebRelease]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_s3_storage
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (release, s3 storage)
|
||||
REPO_COPY=${{runner.temp}}/stateless_s3_storage/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=2
|
||||
EOF
|
||||
- name: Download json reports
|
||||
@ -1190,7 +1298,7 @@ jobs:
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestReleaseS3:
|
||||
FunctionalStatelessTestReleaseS3_1:
|
||||
needs: [BuilderDebRelease]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
@ -1202,6 +1310,8 @@ jobs:
|
||||
CHECK_NAME=Stateless tests (release, s3 storage)
|
||||
REPO_COPY=${{runner.temp}}/stateless_s3_storage/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=2
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1271,7 +1381,7 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_debug/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=2
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1307,7 +1417,79 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_debug/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=2
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestAsan2:
|
||||
needs: [BuilderDebAsan]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_debug
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (asan)
|
||||
REPO_COPY=${{runner.temp}}/stateless_debug/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=2
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestAsan3:
|
||||
needs: [BuilderDebAsan]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_debug
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (asan)
|
||||
REPO_COPY=${{runner.temp}}/stateless_debug/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=3
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1343,7 +1525,7 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_tsan/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1379,7 +1561,7 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_tsan/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1415,7 +1597,7 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_tsan/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=2
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1438,7 +1620,79 @@ jobs:
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestUBsan:
|
||||
FunctionalStatelessTestTsan3:
|
||||
needs: [BuilderDebTsan]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_tsan
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (tsan)
|
||||
REPO_COPY=${{runner.temp}}/stateless_tsan/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=3
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestTsan4:
|
||||
needs: [BuilderDebTsan]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_tsan
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (tsan)
|
||||
REPO_COPY=${{runner.temp}}/stateless_tsan/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=4
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestUBsan0:
|
||||
needs: [BuilderDebUBsan]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
@ -1450,6 +1704,44 @@ jobs:
|
||||
CHECK_NAME=Stateless tests (ubsan)
|
||||
REPO_COPY=${{runner.temp}}/stateless_ubsan/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=2
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestUBsan1:
|
||||
needs: [BuilderDebUBsan]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_ubsan
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (ubsan)
|
||||
REPO_COPY=${{runner.temp}}/stateless_ubsan/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=2
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1485,7 +1777,7 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_memory/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1521,7 +1813,7 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_memory/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1557,7 +1849,115 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_memory/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=2
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestMsan3:
|
||||
needs: [BuilderDebMsan]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_memory
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (msan)
|
||||
REPO_COPY=${{runner.temp}}/stateless_memory/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=3
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestMsan4:
|
||||
needs: [BuilderDebMsan]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_memory
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (msan)
|
||||
REPO_COPY=${{runner.temp}}/stateless_memory/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=4
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestMsan5:
|
||||
needs: [BuilderDebMsan]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_memory
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (msan)
|
||||
REPO_COPY=${{runner.temp}}/stateless_memory/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=5
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1593,7 +1993,7 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_debug/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1629,7 +2029,7 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_debug/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -1665,7 +2065,79 @@ jobs:
|
||||
REPO_COPY=${{runner.temp}}/stateless_debug/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=2
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestDebug3:
|
||||
needs: [BuilderDebDebug]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_debug
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (debug)
|
||||
REPO_COPY=${{runner.temp}}/stateless_debug/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=3
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Functional test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 functional_test_check.py "$CHECK_NAME" "$KILL_TIMEOUT"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
FunctionalStatelessTestDebug4:
|
||||
needs: [BuilderDebDebug]
|
||||
runs-on: [self-hosted, func-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/stateless_debug
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Stateless tests (debug)
|
||||
REPO_COPY=${{runner.temp}}/stateless_debug/ClickHouse
|
||||
KILL_TIMEOUT=10800
|
||||
RUN_BY_HASH_NUM=4
|
||||
RUN_BY_HASH_TOTAL=5
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -2116,7 +2588,7 @@ jobs:
|
||||
CHECK_NAME=Integration tests (asan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_asan/ClickHouse
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -2151,7 +2623,7 @@ jobs:
|
||||
CHECK_NAME=Integration tests (asan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_asan/ClickHouse
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -2186,7 +2658,112 @@ jobs:
|
||||
CHECK_NAME=Integration tests (asan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_asan/ClickHouse
|
||||
RUN_BY_HASH_NUM=2
|
||||
RUN_BY_HASH_TOTAL=3
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Integration test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 integration_test_check.py "$CHECK_NAME"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
IntegrationTestsAsan3:
|
||||
needs: [BuilderDebAsan]
|
||||
runs-on: [self-hosted, stress-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/integration_tests_asan
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Integration tests (asan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_asan/ClickHouse
|
||||
RUN_BY_HASH_NUM=3
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Integration test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 integration_test_check.py "$CHECK_NAME"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
IntegrationTestsAsan4:
|
||||
needs: [BuilderDebAsan]
|
||||
runs-on: [self-hosted, stress-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/integration_tests_asan
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Integration tests (asan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_asan/ClickHouse
|
||||
RUN_BY_HASH_NUM=4
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Integration test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 integration_test_check.py "$CHECK_NAME"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
IntegrationTestsAsan5:
|
||||
needs: [BuilderDebAsan]
|
||||
runs-on: [self-hosted, stress-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/integration_tests_asan
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Integration tests (asan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_asan/ClickHouse
|
||||
RUN_BY_HASH_NUM=5
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -2221,7 +2798,7 @@ jobs:
|
||||
CHECK_NAME=Integration tests (tsan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_tsan/ClickHouse
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -2256,7 +2833,7 @@ jobs:
|
||||
CHECK_NAME=Integration tests (tsan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_tsan/ClickHouse
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -2291,7 +2868,7 @@ jobs:
|
||||
CHECK_NAME=Integration tests (tsan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_tsan/ClickHouse
|
||||
RUN_BY_HASH_NUM=2
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -2326,7 +2903,77 @@ jobs:
|
||||
CHECK_NAME=Integration tests (tsan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_tsan/ClickHouse
|
||||
RUN_BY_HASH_NUM=3
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Integration test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 integration_test_check.py "$CHECK_NAME"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
IntegrationTestsTsan4:
|
||||
needs: [BuilderDebTsan]
|
||||
runs-on: [self-hosted, stress-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/integration_tests_tsan
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Integration tests (tsan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_tsan/ClickHouse
|
||||
RUN_BY_HASH_NUM=4
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Integration test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 integration_test_check.py "$CHECK_NAME"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
IntegrationTestsTsan5:
|
||||
needs: [BuilderDebTsan]
|
||||
runs-on: [self-hosted, stress-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/integration_tests_tsan
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Integration tests (tsan)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_tsan/ClickHouse
|
||||
RUN_BY_HASH_NUM=5
|
||||
RUN_BY_HASH_TOTAL=6
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -2361,7 +3008,7 @@ jobs:
|
||||
CHECK_NAME=Integration tests (release)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_release/ClickHouse
|
||||
RUN_BY_HASH_NUM=0
|
||||
RUN_BY_HASH_TOTAL=2
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -2396,7 +3043,77 @@ jobs:
|
||||
CHECK_NAME=Integration tests (release)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_release/ClickHouse
|
||||
RUN_BY_HASH_NUM=1
|
||||
RUN_BY_HASH_TOTAL=2
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Integration test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 integration_test_check.py "$CHECK_NAME"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
IntegrationTestsRelease2:
|
||||
needs: [BuilderDebRelease]
|
||||
runs-on: [self-hosted, stress-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/integration_tests_release
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Integration tests (release)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_release/ClickHouse
|
||||
RUN_BY_HASH_NUM=2
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: ${{ env.REPORTS_PATH }}
|
||||
- name: Check out repository code
|
||||
uses: ClickHouse/checkout@v1
|
||||
with:
|
||||
clear-repository: true
|
||||
- name: Integration test
|
||||
run: |
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
mkdir -p "$TEMP_PATH"
|
||||
cp -r "$GITHUB_WORKSPACE" "$TEMP_PATH"
|
||||
cd "$REPO_COPY/tests/ci"
|
||||
python3 integration_test_check.py "$CHECK_NAME"
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
run: |
|
||||
docker ps --quiet | xargs --no-run-if-empty docker kill ||:
|
||||
docker ps --all --quiet | xargs --no-run-if-empty docker rm -f ||:
|
||||
sudo rm -fr "$TEMP_PATH"
|
||||
IntegrationTestsRelease3:
|
||||
needs: [BuilderDebRelease]
|
||||
runs-on: [self-hosted, stress-tester]
|
||||
steps:
|
||||
- name: Set envs
|
||||
run: |
|
||||
cat >> "$GITHUB_ENV" << 'EOF'
|
||||
TEMP_PATH=${{runner.temp}}/integration_tests_release
|
||||
REPORTS_PATH=${{runner.temp}}/reports_dir
|
||||
CHECK_NAME=Integration tests (release)
|
||||
REPO_COPY=${{runner.temp}}/integration_tests_release/ClickHouse
|
||||
RUN_BY_HASH_NUM=3
|
||||
RUN_BY_HASH_TOTAL=4
|
||||
EOF
|
||||
- name: Download json reports
|
||||
uses: actions/download-artifact@v3
|
||||
@ -3116,23 +3833,36 @@ jobs:
|
||||
- FunctionalStatelessTestDebug0
|
||||
- FunctionalStatelessTestDebug1
|
||||
- FunctionalStatelessTestDebug2
|
||||
- FunctionalStatelessTestDebug3
|
||||
- FunctionalStatelessTestDebug4
|
||||
- FunctionalStatelessTestRelease
|
||||
- FunctionalStatelessTestReleaseDatabaseOrdinary
|
||||
- FunctionalStatelessTestReleaseDatabaseReplicated0
|
||||
- FunctionalStatelessTestReleaseDatabaseReplicated1
|
||||
- FunctionalStatelessTestReleaseDatabaseReplicated2
|
||||
- FunctionalStatelessTestReleaseDatabaseReplicated3
|
||||
- FunctionalStatelessTestAarch64
|
||||
- FunctionalStatelessTestAsan0
|
||||
- FunctionalStatelessTestAsan1
|
||||
- FunctionalStatelessTestAsan2
|
||||
- FunctionalStatelessTestAsan3
|
||||
- FunctionalStatelessTestTsan0
|
||||
- FunctionalStatelessTestTsan1
|
||||
- FunctionalStatelessTestTsan2
|
||||
- FunctionalStatelessTestTsan3
|
||||
- FunctionalStatelessTestTsan4
|
||||
- FunctionalStatelessTestMsan0
|
||||
- FunctionalStatelessTestMsan1
|
||||
- FunctionalStatelessTestMsan2
|
||||
- FunctionalStatelessTestUBsan
|
||||
- FunctionalStatelessTestMsan3
|
||||
- FunctionalStatelessTestMsan4
|
||||
- FunctionalStatelessTestMsan5
|
||||
- FunctionalStatelessTestUBsan0
|
||||
- FunctionalStatelessTestUBsan1
|
||||
- FunctionalStatefulTestDebug
|
||||
- FunctionalStatefulTestRelease
|
||||
- FunctionalStatelessTestReleaseS3
|
||||
- FunctionalStatelessTestReleaseS3_0
|
||||
- FunctionalStatelessTestReleaseS3_1
|
||||
- FunctionalStatefulTestAarch64
|
||||
- FunctionalStatefulTestAsan
|
||||
- FunctionalStatefulTestTsan
|
||||
@ -3146,12 +3876,19 @@ jobs:
|
||||
- IntegrationTestsAsan0
|
||||
- IntegrationTestsAsan1
|
||||
- IntegrationTestsAsan2
|
||||
- IntegrationTestsAsan3
|
||||
- IntegrationTestsAsan4
|
||||
- IntegrationTestsAsan5
|
||||
- IntegrationTestsRelease0
|
||||
- IntegrationTestsRelease1
|
||||
- IntegrationTestsRelease2
|
||||
- IntegrationTestsRelease3
|
||||
- IntegrationTestsTsan0
|
||||
- IntegrationTestsTsan1
|
||||
- IntegrationTestsTsan2
|
||||
- IntegrationTestsTsan3
|
||||
- IntegrationTestsTsan4
|
||||
- IntegrationTestsTsan5
|
||||
- PerformanceComparisonX86-0
|
||||
- PerformanceComparisonX86-1
|
||||
- PerformanceComparisonX86-2
|
||||
|
||||
2
.github/workflows/pull_request.yml
vendored
2
.github/workflows/pull_request.yml
vendored
@ -918,7 +918,7 @@ jobs:
|
||||
cd "$GITHUB_WORKSPACE/tests/ci"
|
||||
python3 docker_server.py --release-type head --no-push \
|
||||
--image-repo clickhouse/clickhouse-server --image-path docker/server
|
||||
python3 docker_server.py --release-type head --no-push --no-ubuntu \
|
||||
python3 docker_server.py --release-type head --no-push \
|
||||
--image-repo clickhouse/clickhouse-keeper --image-path docker/keeper
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
|
||||
2
.github/workflows/release.yml
vendored
2
.github/workflows/release.yml
vendored
@ -55,7 +55,7 @@ jobs:
|
||||
cd "$GITHUB_WORKSPACE/tests/ci"
|
||||
python3 docker_server.py --release-type auto --version "$GITHUB_TAG" \
|
||||
--image-repo clickhouse/clickhouse-server --image-path docker/server
|
||||
python3 docker_server.py --release-type auto --version "$GITHUB_TAG" --no-ubuntu \
|
||||
python3 docker_server.py --release-type auto --version "$GITHUB_TAG" \
|
||||
--image-repo clickhouse/clickhouse-keeper --image-path docker/keeper
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
|
||||
2
.github/workflows/release_branches.yml
vendored
2
.github/workflows/release_branches.yml
vendored
@ -527,7 +527,7 @@ jobs:
|
||||
cd "$GITHUB_WORKSPACE/tests/ci"
|
||||
python3 docker_server.py --release-type head --no-push \
|
||||
--image-repo clickhouse/clickhouse-server --image-path docker/server
|
||||
python3 docker_server.py --release-type head --no-push --no-ubuntu \
|
||||
python3 docker_server.py --release-type head --no-push \
|
||||
--image-repo clickhouse/clickhouse-keeper --image-path docker/keeper
|
||||
- name: Cleanup
|
||||
if: always()
|
||||
|
||||
185
CHANGELOG.md
185
CHANGELOG.md
@ -1,10 +1,195 @@
|
||||
### Table of Contents
|
||||
**[ClickHouse release v23.3 LTS, 2023-03-30](#233)**<br/>
|
||||
**[ClickHouse release v23.2, 2023-02-23](#232)**<br/>
|
||||
**[ClickHouse release v23.1, 2023-01-25](#231)**<br/>
|
||||
**[Changelog for 2022](https://clickhouse.com/docs/en/whats-new/changelog/2022/)**<br/>
|
||||
|
||||
# 2023 Changelog
|
||||
|
||||
### <a id="233"></a> ClickHouse release 23.3 LTS, 2023-03-30
|
||||
|
||||
#### Upgrade Notes
|
||||
* Lightweight DELETEs are production ready and enabled by default. The `DELETE` query for MergeTree tables is now available by default.
|
||||
* The behavior of `*domain*RFC` and `netloc` functions is slightly changed: relaxed the set of symbols that are allowed in the URL authority for better conformance. [#46841](https://github.com/ClickHouse/ClickHouse/pull/46841) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Prohibited creating tables based on KafkaEngine with DEFAULT/EPHEMERAL/ALIAS/MATERIALIZED statements for columns. [#47138](https://github.com/ClickHouse/ClickHouse/pull/47138) ([Aleksandr Musorin](https://github.com/AVMusorin)).
|
||||
* An "asynchronous connection drain" feature is removed. Related settings and metrics are removed as well. It was an internal feature, so the removal should not affect users who had never heard about that feature. [#47486](https://github.com/ClickHouse/ClickHouse/pull/47486) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Support 256-bit Decimal data type (more than 38 digits) in `arraySum`/`Min`/`Max`/`Avg`/`Product`, `arrayCumSum`/`CumSumNonNegative`, `arrayDifference`, array construction, IN operator, query parameters, `groupArrayMovingSum`, statistical functions, `min`/`max`/`any`/`argMin`/`argMax`, PostgreSQL wire protocol, MySQL table engine and function, `sumMap`, `mapAdd`, `mapSubtract`, `arrayIntersect`. Add support for big integers in `arrayIntersect`. Statistical aggregate functions involving moments (such as `corr` or various `TTest`s) will use `Float64` as their internal representation (they were using `Decimal128` before this change, but it was pointless), and these functions can return `nan` instead of `inf` in case of infinite variance. Some functions were allowed on `Decimal256` data types but returned `Decimal128` in previous versions - now it is fixed. This closes [#47569](https://github.com/ClickHouse/ClickHouse/issues/47569). This closes [#44864](https://github.com/ClickHouse/ClickHouse/issues/44864). This closes [#28335](https://github.com/ClickHouse/ClickHouse/issues/28335). [#47594](https://github.com/ClickHouse/ClickHouse/pull/47594) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Make backup_threads/restore_threads server settings (instead of user settings). [#47881](https://github.com/ClickHouse/ClickHouse/pull/47881) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Do not allow const and non-deterministic secondary indices [#46839](https://github.com/ClickHouse/ClickHouse/pull/46839) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
|
||||
#### New Feature
|
||||
* Add a new mode for splitting the work on replicas using settings `parallel_replicas_custom_key` and `parallel_replicas_custom_key_filter_type`. If the cluster consists of a single shard with multiple replicas, up to `max_parallel_replicas` will be randomly picked and turned into shards. For each shard, a corresponding filter is added to the query on the initiator before being sent to the shard. If the cluster consists of multiple shards, it will behave the same as `sample_key` but with the possibility to define an arbitrary key. [#45108](https://github.com/ClickHouse/ClickHouse/pull/45108) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* An option to display partial result on cancel: Added query setting `partial_result_on_first_cancel` allowing the canceled query (e.g. due to Ctrl-C) to return a partial result. [#45689](https://github.com/ClickHouse/ClickHouse/pull/45689) ([Alexey Perevyshin](https://github.com/alexX512)).
|
||||
* Added support of arbitrary tables engines for temporary tables (except for Replicated and KeeperMap engines). Close [#31497](https://github.com/ClickHouse/ClickHouse/issues/31497). [#46071](https://github.com/ClickHouse/ClickHouse/pull/46071) ([Roman Vasin](https://github.com/rvasin)).
|
||||
* Add support for replication of user-defined SQL functions using centralized storage in Keeper. [#46085](https://github.com/ClickHouse/ClickHouse/pull/46085) ([Aleksei Filatov](https://github.com/aalexfvk)).
|
||||
* Implement `system.server_settings` (similar to `system.settings`), which will contain server configurations. [#46550](https://github.com/ClickHouse/ClickHouse/pull/46550) ([pufit](https://github.com/pufit)).
|
||||
* Support for `UNDROP TABLE` query. Closes [#46811](https://github.com/ClickHouse/ClickHouse/issues/46811). [#47241](https://github.com/ClickHouse/ClickHouse/pull/47241) ([chen](https://github.com/xiedeyantu)).
|
||||
* Allow separate grants for named collections (e.g. to be able to give `SHOW/CREATE/ALTER/DROP named collection` access only to certain collections, instead of all at once). Closes [#40894](https://github.com/ClickHouse/ClickHouse/issues/40894). Add new access type `NAMED_COLLECTION_CONTROL` which is not given to user default unless explicitly added to the user config (is required to be able to do `GRANT ALL`), also `show_named_collections` is no longer obligatory to be manually specified for user default to be able to have full access rights as was in 23.2. [#46241](https://github.com/ClickHouse/ClickHouse/pull/46241) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Allow nested custom disks. Previously custom disks supported only flat disk structure. [#47106](https://github.com/ClickHouse/ClickHouse/pull/47106) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Introduce a function `widthBucket` (with a `WIDTH_BUCKET` alias for compatibility). [#42974](https://github.com/ClickHouse/ClickHouse/issues/42974). [#46790](https://github.com/ClickHouse/ClickHouse/pull/46790) ([avoiderboi](https://github.com/avoiderboi)).
|
||||
* Add new function `parseDateTime`/`parseDateTimeInJodaSyntax` according to the specified format string. parseDateTime parses String to DateTime in MySQL syntax, parseDateTimeInJodaSyntax parses in Joda syntax. [#46815](https://github.com/ClickHouse/ClickHouse/pull/46815) ([李扬](https://github.com/taiyang-li)).
|
||||
* Use `dummy UInt8` for the default structure of table function `null`. Closes [#46930](https://github.com/ClickHouse/ClickHouse/issues/46930). [#47006](https://github.com/ClickHouse/ClickHouse/pull/47006) ([flynn](https://github.com/ucasfl)).
|
||||
* Support for date format with a comma, like `Dec 15, 2021` in the `parseDateTimeBestEffort` function. Closes [#46816](https://github.com/ClickHouse/ClickHouse/issues/46816). [#47071](https://github.com/ClickHouse/ClickHouse/pull/47071) ([chen](https://github.com/xiedeyantu)).
|
||||
* Add settings `http_wait_end_of_query` and `http_response_buffer_size` that corresponds to URL params `wait_end_of_query` and `buffer_size` for the HTTP interface. This allows changing these settings in the profiles. [#47108](https://github.com/ClickHouse/ClickHouse/pull/47108) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Add `system.dropped_tables` table that shows tables that were dropped from `Atomic` databases but were not completely removed yet. [#47364](https://github.com/ClickHouse/ClickHouse/pull/47364) ([chen](https://github.com/xiedeyantu)).
|
||||
* Add `INSTR` as alias of `positionCaseInsensitive` for MySQL compatibility. Closes [#47529](https://github.com/ClickHouse/ClickHouse/issues/47529). [#47535](https://github.com/ClickHouse/ClickHouse/pull/47535) ([flynn](https://github.com/ucasfl)).
|
||||
* Added `toDecimalString` function allowing to convert numbers to string with fixed precision. [#47838](https://github.com/ClickHouse/ClickHouse/pull/47838) ([Andrey Zvonov](https://github.com/zvonand)).
|
||||
* Add a merge tree setting `max_number_of_mutations_for_replica`. It limits the number of part mutations per replica to the specified amount. Zero means no limit on the number of mutations per replica (the execution can still be constrained by other settings). [#48047](https://github.com/ClickHouse/ClickHouse/pull/48047) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Add the Map-related function `mapFromArrays`, which allows the creation of a map from a pair of arrays. [#31125](https://github.com/ClickHouse/ClickHouse/pull/31125) ([李扬](https://github.com/taiyang-li)).
|
||||
* Allow control of compression in Parquet/ORC/Arrow output formats, adds support for more compression input formats. This closes [#13541](https://github.com/ClickHouse/ClickHouse/issues/13541). [#47114](https://github.com/ClickHouse/ClickHouse/pull/47114) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Add SSL User Certificate authentication to the native protocol. Closes [#47077](https://github.com/ClickHouse/ClickHouse/issues/47077). [#47596](https://github.com/ClickHouse/ClickHouse/pull/47596) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Add *OrNull() and *OrZero() variants for `parseDateTime`, add alias `str_to_date` for MySQL parity. [#48000](https://github.com/ClickHouse/ClickHouse/pull/48000) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Added operator `REGEXP` (similar to operators "LIKE", "IN", "MOD" etc.) for better compatibility with MySQL [#47869](https://github.com/ClickHouse/ClickHouse/pull/47869) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
|
||||
#### Performance Improvement
|
||||
* Marks in memory are now compressed, using 3-6x less memory. [#47290](https://github.com/ClickHouse/ClickHouse/pull/47290) ([Michael Kolupaev](https://github.com/al13n321)).
|
||||
* Backups for large numbers of files were unbelievably slow in previous versions. Not anymore. Now they are unbelievably fast. [#47251](https://github.com/ClickHouse/ClickHouse/pull/47251) ([Alexey Milovidov](https://github.com/alexey-milovidov)). Introduced a separate thread pool for backup's IO operations. This will allow scaling it independently of other pools and increase performance. [#47174](https://github.com/ClickHouse/ClickHouse/pull/47174) ([Nikita Mikhaylov](https://github.com/nikitamikhaylov)). Use MultiRead request and retries for collecting metadata at the final stage of backup processing. [#47243](https://github.com/ClickHouse/ClickHouse/pull/47243) ([Nikita Mikhaylov](https://github.com/nikitamikhaylov)). If a backup and restoring data are both in S3 then server-side copy should be used from now on. [#47546](https://github.com/ClickHouse/ClickHouse/pull/47546) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Fixed excessive reading in queries with `FINAL`. [#47801](https://github.com/ClickHouse/ClickHouse/pull/47801) ([Nikita Taranov](https://github.com/nickitat)).
|
||||
* Setting `max_final_threads` would be set to the number of cores at server startup (by the same algorithm as used for `max_threads`). This improves the concurrency of `final` execution on servers with high number of CPUs. [#47915](https://github.com/ClickHouse/ClickHouse/pull/47915) ([Nikita Taranov](https://github.com/nickitat)).
|
||||
* Allow executing reading pipeline for DIRECT dictionary with CLICKHOUSE source in multiple threads. To enable set `dictionary_use_async_executor=1` in `SETTINGS` section for source in `CREATE DICTIONARY` statement. [#47986](https://github.com/ClickHouse/ClickHouse/pull/47986) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Optimize one nullable key aggregate performance. [#45772](https://github.com/ClickHouse/ClickHouse/pull/45772) ([LiuNeng](https://github.com/liuneng1994)).
|
||||
* Implemented lowercase `tokenbf_v1` index utilization for `hasTokenOrNull`, `hasTokenCaseInsensitive` and `hasTokenCaseInsensitiveOrNull`. [#46252](https://github.com/ClickHouse/ClickHouse/pull/46252) ([ltrk2](https://github.com/ltrk2)).
|
||||
* Optimize functions `position` and `LIKE` by searching the first two chars using SIMD. [#46289](https://github.com/ClickHouse/ClickHouse/pull/46289) ([Jiebin Sun](https://github.com/jiebinn)).
|
||||
* Optimize queries from the `system.detached_parts`, which could be significantly large. Added several sources with respect to the block size limitation; in each block, an IO thread pool is used to calculate the part size, i.e. to make syscalls in parallel. [#46624](https://github.com/ClickHouse/ClickHouse/pull/46624) ([Sema Checherinda](https://github.com/CheSema)).
|
||||
* Increase the default value of `max_replicated_merges_in_queue` for ReplicatedMergeTree tables from 16 to 1000. It allows faster background merge operation on clusters with a very large number of replicas, such as clusters with shared storage in ClickHouse Cloud. [#47050](https://github.com/ClickHouse/ClickHouse/pull/47050) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Updated `clickhouse-copier` to use `GROUP BY` instead of `DISTINCT` to get the list of partitions. For large tables, this reduced the select time from over 500s to under 1s. [#47386](https://github.com/ClickHouse/ClickHouse/pull/47386) ([Clayton McClure](https://github.com/cmcclure-twilio)).
|
||||
* Fix performance degradation in `ASOF JOIN`. [#47544](https://github.com/ClickHouse/ClickHouse/pull/47544) ([Ongkong](https://github.com/ongkong)).
|
||||
* Even more batching in Keeper. Improve performance by avoiding breaking batches on read requests. [#47978](https://github.com/ClickHouse/ClickHouse/pull/47978) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Allow PREWHERE for Merge with different DEFAULT expressions for columns. [#46831](https://github.com/ClickHouse/ClickHouse/pull/46831) ([Azat Khuzhin](https://github.com/azat)).
|
||||
|
||||
#### Experimental Feature
|
||||
* Parallel replicas: Improved the overall performance by better utilizing the local replica, and forbid the reading with parallel replicas from non-replicated MergeTree by default. [#47858](https://github.com/ClickHouse/ClickHouse/pull/47858) ([Nikita Mikhaylov](https://github.com/nikitamikhaylov)).
|
||||
* Support filter push down to left table for JOIN with `Join`, `Dictionary` and `EmbeddedRocksDB` tables if the experimental Analyzer is enabled. [#47280](https://github.com/ClickHouse/ClickHouse/pull/47280) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* Now ReplicatedMergeTree with zero copy replication has less load to Keeper. [#47676](https://github.com/ClickHouse/ClickHouse/pull/47676) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix create materialized view with MaterializedPostgreSQL [#40807](https://github.com/ClickHouse/ClickHouse/pull/40807) ([Maksim Buren](https://github.com/maks-buren630501)).
|
||||
|
||||
#### Improvement
|
||||
* Enable `input_format_json_ignore_unknown_keys_in_named_tuple` by default. [#46742](https://github.com/ClickHouse/ClickHouse/pull/46742) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Allow errors to be ignored while pushing to MATERIALIZED VIEW (add new setting `materialized_views_ignore_errors`, by default to `false`, but it is set to `true` for flushing logs to `system.*_log` tables unconditionally). [#46658](https://github.com/ClickHouse/ClickHouse/pull/46658) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Track the file queue of distributed sends in memory. [#45491](https://github.com/ClickHouse/ClickHouse/pull/45491) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Now `X-ClickHouse-Query-Id` and `X-ClickHouse-Timezone` headers are added to responses in all queries via HTTP protocol. Previously it was done only for `SELECT` queries. [#46364](https://github.com/ClickHouse/ClickHouse/pull/46364) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* External tables from `MongoDB`: support for connection to a replica set via a URI with a host:port enum and support for the readPreference option in MongoDB dictionaries. Example URI: mongodb://db0.example.com:27017,db1.example.com:27017,db2.example.com:27017/?replicaSet=myRepl&readPreference=primary. [#46524](https://github.com/ClickHouse/ClickHouse/pull/46524) ([artem-yadr](https://github.com/artem-yadr)).
|
||||
* This improvement should be invisible for users. Re-implement projection analysis on top of query plan. Added setting `query_plan_optimize_projection=1` to switch between old and new version. Fixes [#44963](https://github.com/ClickHouse/ClickHouse/issues/44963). [#46537](https://github.com/ClickHouse/ClickHouse/pull/46537) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Use Parquet format v2 instead of v1 in output format by default. Add setting `output_format_parquet_version` to control parquet version, possible values `1.0`, `2.4`, `2.6`, `2.latest` (default). [#46617](https://github.com/ClickHouse/ClickHouse/pull/46617) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* It is now possible to use the new configuration syntax to configure Kafka topics with periods (`.`) in their name. [#46752](https://github.com/ClickHouse/ClickHouse/pull/46752) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix heuristics that check hyperscan patterns for problematic repeats. [#46819](https://github.com/ClickHouse/ClickHouse/pull/46819) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Don't report ZK node exists to system.errors when a block was created concurrently by a different replica. [#46820](https://github.com/ClickHouse/ClickHouse/pull/46820) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Increase the limit for opened files in `clickhouse-local`. It will be able to read from `web` tables on servers with a huge number of CPU cores. Do not back off reading from the URL table engine in case of too many opened files. This closes [#46852](https://github.com/ClickHouse/ClickHouse/issues/46852). [#46853](https://github.com/ClickHouse/ClickHouse/pull/46853) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Exceptions thrown when numbers cannot be parsed now have an easier-to-read exception message. [#46917](https://github.com/ClickHouse/ClickHouse/pull/46917) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Added update `system.backups` after every processed task to track the progress of backups. [#46989](https://github.com/ClickHouse/ClickHouse/pull/46989) ([Aleksandr Musorin](https://github.com/AVMusorin)).
|
||||
* Allow types conversion in Native input format. Add settings `input_format_native_allow_types_conversion` that controls it (enabled by default). [#46990](https://github.com/ClickHouse/ClickHouse/pull/46990) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Allow IPv4 in the `range` function to generate IP ranges. [#46995](https://github.com/ClickHouse/ClickHouse/pull/46995) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Improve exception message when it's impossible to move a part from one volume/disk to another. [#47032](https://github.com/ClickHouse/ClickHouse/pull/47032) ([alesapin](https://github.com/alesapin)).
|
||||
* Support `Bool` type in `JSONType` function. Previously `Null` type was mistakenly returned for bool values. [#47046](https://github.com/ClickHouse/ClickHouse/pull/47046) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Use `_request_body` parameter to configure predefined HTTP queries. [#47086](https://github.com/ClickHouse/ClickHouse/pull/47086) ([Constantine Peresypkin](https://github.com/pkit)).
|
||||
* Automatic indentation in the built-in UI SQL editor when Enter is pressed. [#47113](https://github.com/ClickHouse/ClickHouse/pull/47113) ([Alexey Korepanov](https://github.com/alexkorep)).
|
||||
* Self-extraction with 'sudo' will attempt to set uid and gid of extracted files to running user. [#47116](https://github.com/ClickHouse/ClickHouse/pull/47116) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Previously, the `repeat` function's second argument only accepted an unsigned integer type, which meant it could not accept values such as -1. This behavior differed from that of the Spark function. In this update, the repeat function has been modified to match the behavior of the Spark function. It now accepts the same types of inputs, including negative integers. Extensive testing has been performed to verify the correctness of the updated implementation. [#47134](https://github.com/ClickHouse/ClickHouse/pull/47134) ([KevinyhZou](https://github.com/KevinyhZou)). Note: the changelog entry was rewritten by ChatGPT.
|
||||
* Remove `::__1` part from stacktraces. Display `std::basic_string<char, ...` as `String` in stacktraces. [#47171](https://github.com/ClickHouse/ClickHouse/pull/47171) ([Mike Kot](https://github.com/myrrc)).
|
||||
* Reimplement interserver mode to avoid replay attacks (note, that change is backward compatible with older servers). [#47213](https://github.com/ClickHouse/ClickHouse/pull/47213) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Improve recognition of regular expression groups and refine the regexp_tree dictionary. [#47218](https://github.com/ClickHouse/ClickHouse/pull/47218) ([Han Fei](https://github.com/hanfei1991)).
|
||||
* Keeper improvement: Add new 4LW `clrs` to clean resources used by Keeper (e.g. release unused memory). [#47256](https://github.com/ClickHouse/ClickHouse/pull/47256) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Add optional arguments to codecs `DoubleDelta(bytes_size)`, `Gorilla(bytes_size)`, `FPC(level, float_size)`, this allows using these codecs without column type in `clickhouse-compressor`. Fix possible aborts and arithmetic errors in `clickhouse-compressor` with these codecs. Fixes: https://github.com/ClickHouse/ClickHouse/discussions/47262. [#47271](https://github.com/ClickHouse/ClickHouse/pull/47271) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Add support for big int types to the `runningDifference` function. Closes [#47194](https://github.com/ClickHouse/ClickHouse/issues/47194). [#47322](https://github.com/ClickHouse/ClickHouse/pull/47322) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Add an expiration window for S3 credentials that have an expiration time to avoid `ExpiredToken` errors in some edge cases. It can be controlled with `expiration_window_seconds` config, the default is 120 seconds. [#47423](https://github.com/ClickHouse/ClickHouse/pull/47423) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Support Decimals and Date32 in `Avro` format. [#47434](https://github.com/ClickHouse/ClickHouse/pull/47434) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Do not start the server if an interrupted conversion from `Ordinary` to `Atomic` was detected, print a better error message with troubleshooting instructions. [#47487](https://github.com/ClickHouse/ClickHouse/pull/47487) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Add a new column `kind` to the `system.opentelemetry_span_log`. This column holds the value of [SpanKind](https://opentelemetry.io/docs/reference/specification/trace/api/#spankind) defined in OpenTelemtry. [#47499](https://github.com/ClickHouse/ClickHouse/pull/47499) ([Frank Chen](https://github.com/FrankChen021)).
|
||||
* Allow reading/writing nested arrays in `Protobuf` format with only the root field name as column name. Previously column name should've contained all nested field names (like `a.b.c Array(Array(Array(UInt32)))`, now you can use just `a Array(Array(Array(UInt32)))`. [#47650](https://github.com/ClickHouse/ClickHouse/pull/47650) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Added an optional `STRICT` modifier for `SYSTEM SYNC REPLICA` which makes the query wait for the replication queue to become empty (just like it worked before https://github.com/ClickHouse/ClickHouse/pull/45648). [#47659](https://github.com/ClickHouse/ClickHouse/pull/47659) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Improve the naming of some OpenTelemetry span logs. [#47667](https://github.com/ClickHouse/ClickHouse/pull/47667) ([Frank Chen](https://github.com/FrankChen021)).
|
||||
* Prevent using too long chains of aggregate function combinators (they can lead to slow queries in the analysis stage). This closes [#47715](https://github.com/ClickHouse/ClickHouse/issues/47715). [#47716](https://github.com/ClickHouse/ClickHouse/pull/47716) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Support for subquery in parameterized views; resolves [#46741](https://github.com/ClickHouse/ClickHouse/issues/46741) [#47725](https://github.com/ClickHouse/ClickHouse/pull/47725) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Fix memory leak in MySQL integration (reproduces with `connection_auto_close=1`). [#47732](https://github.com/ClickHouse/ClickHouse/pull/47732) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Improved error handling in the code related to Decimal parameters, resulting in more informative error messages. Previously, when incorrect Decimal parameters were supplied, the error message generated was unclear or unhelpful. With this update, the error message printed has been fixed to provide more detailed and useful information, making it easier to identify and correct issues related to Decimal parameters. [#47812](https://github.com/ClickHouse/ClickHouse/pull/47812) ([Yu Feng](https://github.com/Vigor-jpg)). Note: this changelog entry is rewritten by ChatGPT.
|
||||
* The parameter `exact_rows_before_limit` is used to make `rows_before_limit_at_least` is designed to accurately reflect the number of rows returned before the limit is reached. This pull request addresses issues encountered when the query involves distributed processing across multiple shards or sorting operations. Prior to this update, these scenarios were not functioning as intended. [#47874](https://github.com/ClickHouse/ClickHouse/pull/47874) ([Amos Bird](https://github.com/amosbird)).
|
||||
* ThreadPools metrics introspection. [#47880](https://github.com/ClickHouse/ClickHouse/pull/47880) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Add `WriteBufferFromS3Microseconds` and `WriteBufferFromS3RequestsErrors` profile events. [#47885](https://github.com/ClickHouse/ClickHouse/pull/47885) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Add `--link` and `--noninteractive` (`-y`) options to ClickHouse install. Closes [#47750](https://github.com/ClickHouse/ClickHouse/issues/47750). [#47887](https://github.com/ClickHouse/ClickHouse/pull/47887) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Fixed `UNKNOWN_TABLE` exception when attaching to a materialized view that has dependent tables that are not available. This might be useful when trying to restore state from a backup. [#47975](https://github.com/ClickHouse/ClickHouse/pull/47975) ([MikhailBurdukov](https://github.com/MikhailBurdukov)).
|
||||
* Fix case when the (optional) path is not added to an encrypted disk configuration. [#47981](https://github.com/ClickHouse/ClickHouse/pull/47981) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Support for CTE in parameterized views Implementation: Updated to allow query parameters while evaluating scalar subqueries. [#48065](https://github.com/ClickHouse/ClickHouse/pull/48065) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Support big integers `(U)Int128/(U)Int256`, `Map` with any key type and `DateTime64` with any precision (not only 3 and 6). [#48119](https://github.com/ClickHouse/ClickHouse/pull/48119) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Allow skipping errors related to unknown enum values in row input formats. [#48133](https://github.com/ClickHouse/ClickHouse/pull/48133) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
|
||||
#### Build/Testing/Packaging Improvement
|
||||
* ClickHouse now builds with `C++23`. [#47424](https://github.com/ClickHouse/ClickHouse/pull/47424) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fuzz `EXPLAIN` queries in the AST Fuzzer. [#47803](https://github.com/ClickHouse/ClickHouse/pull/47803) [#47852](https://github.com/ClickHouse/ClickHouse/pull/47852) ([flynn](https://github.com/ucasfl)).
|
||||
* Split stress test and the automated backward compatibility check (now Upgrade check). [#44879](https://github.com/ClickHouse/ClickHouse/pull/44879) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Updated the Ubuntu Image for Docker to calm down some bogus security reports. [#46784](https://github.com/ClickHouse/ClickHouse/pull/46784) ([Julio Jimenez](https://github.com/juliojimenez)). Please note that ClickHouse has no dependencies and does not require Docker.
|
||||
* Adds a prompt to allow the removal of an existing `clickhouse` download when using "curl | sh" download of ClickHouse. Prompt is "ClickHouse binary clickhouse already exists. Overwrite? \[y/N\]". [#46859](https://github.com/ClickHouse/ClickHouse/pull/46859) ([Dan Roscigno](https://github.com/DanRoscigno)).
|
||||
* Fix error during server startup on old distros (e.g. Amazon Linux 2) and on ARM that glibc 2.28 symbols are not found. [#47008](https://github.com/ClickHouse/ClickHouse/pull/47008) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Prepare for clang 16. [#47027](https://github.com/ClickHouse/ClickHouse/pull/47027) ([Amos Bird](https://github.com/amosbird)).
|
||||
* Added a CI check which ensures ClickHouse can run with an old glibc on ARM. [#47063](https://github.com/ClickHouse/ClickHouse/pull/47063) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Add a style check to prevent incorrect usage of the `NDEBUG` macro. [#47699](https://github.com/ClickHouse/ClickHouse/pull/47699) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Speed up the build a little. [#47714](https://github.com/ClickHouse/ClickHouse/pull/47714) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Bump `vectorscan` to 5.4.9. [#47955](https://github.com/ClickHouse/ClickHouse/pull/47955) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Add a unit test to assert Apache Arrow's fatal logging does not abort. It covers the changes in [ClickHouse/arrow#16](https://github.com/ClickHouse/arrow/pull/16). [#47958](https://github.com/ClickHouse/ClickHouse/pull/47958) ([Arthur Passos](https://github.com/arthurpassos)).
|
||||
* Restore the ability of native macOS debug server build to start. [#48050](https://github.com/ClickHouse/ClickHouse/pull/48050) ([Robert Schulze](https://github.com/rschu1ze)). Note: this change is only relevant for development, as the ClickHouse official builds are done with cross-compilation.
|
||||
|
||||
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||
* Fix formats parser resetting, test processing bad messages in `Kafka` [#45693](https://github.com/ClickHouse/ClickHouse/pull/45693) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix data size calculation in Keeper [#46086](https://github.com/ClickHouse/ClickHouse/pull/46086) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fixed a bug in automatic retries of `DROP TABLE` query with `ReplicatedMergeTree` tables and `Atomic` databases. In rare cases it could lead to `Can't get data for node /zk_path/log_pointer` and `The specified key does not exist` errors if the ZooKeeper session expired during DROP and a new replicated table with the same path in ZooKeeper was created in parallel. [#46384](https://github.com/ClickHouse/ClickHouse/pull/46384) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix incorrect alias recursion while normalizing queries that prevented some queries to run. [#46609](https://github.com/ClickHouse/ClickHouse/pull/46609) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Fix IPv4/IPv6 serialization/deserialization in binary formats [#46616](https://github.com/ClickHouse/ClickHouse/pull/46616) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* ActionsDAG: do not change result of `and` during optimization [#46653](https://github.com/ClickHouse/ClickHouse/pull/46653) ([Salvatore Mesoraca](https://github.com/aiven-sal)).
|
||||
* Improve query cancellation when a client dies [#46681](https://github.com/ClickHouse/ClickHouse/pull/46681) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix arithmetic operations in aggregate optimization [#46705](https://github.com/ClickHouse/ClickHouse/pull/46705) ([Duc Canh Le](https://github.com/canhld94)).
|
||||
* Fix possible `clickhouse-local`'s abort on JSONEachRow schema inference [#46731](https://github.com/ClickHouse/ClickHouse/pull/46731) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix changing an expired role [#46772](https://github.com/ClickHouse/ClickHouse/pull/46772) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Fix combined PREWHERE column accumulation from multiple steps [#46785](https://github.com/ClickHouse/ClickHouse/pull/46785) ([Alexander Gololobov](https://github.com/davenger)).
|
||||
* Use initial range for fetching file size in HTTP read buffer. Without this change, some remote files couldn't be processed. [#46824](https://github.com/ClickHouse/ClickHouse/pull/46824) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix the incorrect progress bar while using the URL tables [#46830](https://github.com/ClickHouse/ClickHouse/pull/46830) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix MSan report in `maxIntersections` function [#46847](https://github.com/ClickHouse/ClickHouse/pull/46847) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix a bug in `Map` data type [#46856](https://github.com/ClickHouse/ClickHouse/pull/46856) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix wrong results of some LIKE searches when the LIKE pattern contains quoted non-quotable characters [#46875](https://github.com/ClickHouse/ClickHouse/pull/46875) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix - WITH FILL would produce abort when the Filling Transform processing an empty block [#46897](https://github.com/ClickHouse/ClickHouse/pull/46897) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Fix date and int inference from string in JSON [#46972](https://github.com/ClickHouse/ClickHouse/pull/46972) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix bug in zero-copy replication disk choice during fetch [#47010](https://github.com/ClickHouse/ClickHouse/pull/47010) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix a typo in systemd service definition [#47051](https://github.com/ClickHouse/ClickHouse/pull/47051) ([Palash Goel](https://github.com/palash-goel)).
|
||||
* Fix the NOT_IMPLEMENTED error with CROSS JOIN and algorithm = auto [#47068](https://github.com/ClickHouse/ClickHouse/pull/47068) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix the problem that the 'ReplicatedMergeTree' table failed to insert two similar data when the 'part_type' is configured as 'InMemory' mode (experimental feature). [#47121](https://github.com/ClickHouse/ClickHouse/pull/47121) ([liding1992](https://github.com/liding1992)).
|
||||
* External dictionaries / library-bridge: Fix error "unknown library method 'extDict_libClone'" [#47136](https://github.com/ClickHouse/ClickHouse/pull/47136) ([alex filatov](https://github.com/phil-88)).
|
||||
* Fix race condition in a grace hash join with limit [#47153](https://github.com/ClickHouse/ClickHouse/pull/47153) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix concrete columns PREWHERE support [#47154](https://github.com/ClickHouse/ClickHouse/pull/47154) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix possible deadlock in Query Status [#47161](https://github.com/ClickHouse/ClickHouse/pull/47161) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Forbid insert select for the same `Join` table, as it leads to a deadlock [#47260](https://github.com/ClickHouse/ClickHouse/pull/47260) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Skip merged partitions for `min_age_to_force_merge_seconds` merges [#47303](https://github.com/ClickHouse/ClickHouse/pull/47303) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Modify find_first_symbols, so it works as expected for find_first_not_symbols [#47304](https://github.com/ClickHouse/ClickHouse/pull/47304) ([Arthur Passos](https://github.com/arthurpassos)).
|
||||
* Fix big numbers inference in CSV [#47410](https://github.com/ClickHouse/ClickHouse/pull/47410) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Disable logical expression optimizer for expression with aliases. [#47451](https://github.com/ClickHouse/ClickHouse/pull/47451) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Fix error in `decodeURLComponent` [#47457](https://github.com/ClickHouse/ClickHouse/pull/47457) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix explain graph with projection [#47473](https://github.com/ClickHouse/ClickHouse/pull/47473) ([flynn](https://github.com/ucasfl)).
|
||||
* Fix query parameters [#47488](https://github.com/ClickHouse/ClickHouse/pull/47488) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Parameterized view: a bug fix. [#47495](https://github.com/ClickHouse/ClickHouse/pull/47495) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Fuzzer of data formats, and the corresponding fixes. [#47519](https://github.com/ClickHouse/ClickHouse/pull/47519) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix monotonicity check for `DateTime64` [#47526](https://github.com/ClickHouse/ClickHouse/pull/47526) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix "block structure mismatch" for a Nullable LowCardinality column [#47537](https://github.com/ClickHouse/ClickHouse/pull/47537) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Proper fix for a bug in Apache Parquet [#45878](https://github.com/ClickHouse/ClickHouse/issues/45878) [#47538](https://github.com/ClickHouse/ClickHouse/pull/47538) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix `BSONEachRow` parallel parsing when document size is invalid [#47540](https://github.com/ClickHouse/ClickHouse/pull/47540) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Preserve error in `system.distribution_queue` on `SYSTEM FLUSH DISTRIBUTED` [#47541](https://github.com/ClickHouse/ClickHouse/pull/47541) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Check for duplicate column in `BSONEachRow` format [#47609](https://github.com/ClickHouse/ClickHouse/pull/47609) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix wait for zero copy lock during move [#47631](https://github.com/ClickHouse/ClickHouse/pull/47631) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix aggregation by partitions [#47634](https://github.com/ClickHouse/ClickHouse/pull/47634) ([Nikita Taranov](https://github.com/nickitat)).
|
||||
* Fix bug in tuple as array serialization in `BSONEachRow` format [#47690](https://github.com/ClickHouse/ClickHouse/pull/47690) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix crash in `polygonsSymDifferenceCartesian` [#47702](https://github.com/ClickHouse/ClickHouse/pull/47702) ([pufit](https://github.com/pufit)).
|
||||
* Fix reading from storage `File` compressed files with `zlib` and `gzip` compression [#47796](https://github.com/ClickHouse/ClickHouse/pull/47796) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Improve empty query detection for PostgreSQL (for pgx golang driver) [#47854](https://github.com/ClickHouse/ClickHouse/pull/47854) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix DateTime monotonicity check for LowCardinality types [#47860](https://github.com/ClickHouse/ClickHouse/pull/47860) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Use restore_threads (not backup_threads) for RESTORE ASYNC [#47861](https://github.com/ClickHouse/ClickHouse/pull/47861) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix DROP COLUMN with ReplicatedMergeTree containing projections [#47883](https://github.com/ClickHouse/ClickHouse/pull/47883) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix for Replicated database recovery [#47901](https://github.com/ClickHouse/ClickHouse/pull/47901) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Hotfix for too verbose warnings in HTTP [#47903](https://github.com/ClickHouse/ClickHouse/pull/47903) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix "Field value too long" in `catboostEvaluate` [#47970](https://github.com/ClickHouse/ClickHouse/pull/47970) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix [#36971](https://github.com/ClickHouse/ClickHouse/issues/36971): Watchdog: exit with non-zero code if child process exits [#47973](https://github.com/ClickHouse/ClickHouse/pull/47973) ([Коренберг Марк](https://github.com/socketpair)).
|
||||
* Fix for "index file `cidx` is unexpectedly long" [#48010](https://github.com/ClickHouse/ClickHouse/pull/48010) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Fix MaterializedPostgreSQL query to get attributes (replica-identity) [#48015](https://github.com/ClickHouse/ClickHouse/pull/48015) ([Solomatov Sergei](https://github.com/solomatovs)).
|
||||
* parseDateTime(): Fix UB (signed integer overflow) [#48019](https://github.com/ClickHouse/ClickHouse/pull/48019) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Use unique names for Records in Avro to avoid reusing its schema [#48057](https://github.com/ClickHouse/ClickHouse/pull/48057) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Correctly set TCP/HTTP socket timeouts in Keeper [#48108](https://github.com/ClickHouse/ClickHouse/pull/48108) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix possible member call on null pointer in `Avro` format [#48184](https://github.com/ClickHouse/ClickHouse/pull/48184) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
|
||||
### <a id="232"></a> ClickHouse release 23.2, 2023-02-23
|
||||
|
||||
#### Backward Incompatible Change
|
||||
|
||||
@ -568,7 +568,7 @@ if (NATIVE_BUILD_TARGETS
|
||||
COMMAND ${CMAKE_COMMAND}
|
||||
"-DCMAKE_C_COMPILER=${CMAKE_C_COMPILER}"
|
||||
"-DCMAKE_CXX_COMPILER=${CMAKE_CXX_COMPILER}"
|
||||
"-DENABLE_CCACHE=${ENABLE_CCACHE}"
|
||||
"-DCOMPILER_CACHE=${COMPILER_CACHE}"
|
||||
# Avoid overriding .cargo/config.toml with native toolchain.
|
||||
"-DENABLE_RUST=OFF"
|
||||
"-DENABLE_CLICKHOUSE_SELF_EXTRACTING=${ENABLE_CLICKHOUSE_SELF_EXTRACTING}"
|
||||
|
||||
@ -13,9 +13,10 @@ The following versions of ClickHouse server are currently being supported with s
|
||||
|
||||
| Version | Supported |
|
||||
|:-|:-|
|
||||
| 23.3 | ✔️ |
|
||||
| 23.2 | ✔️ |
|
||||
| 23.1 | ✔️ |
|
||||
| 22.12 | ✔️ |
|
||||
| 22.12 | ❌ |
|
||||
| 22.11 | ❌ |
|
||||
| 22.10 | ❌ |
|
||||
| 22.9 | ❌ |
|
||||
@ -24,7 +25,7 @@ The following versions of ClickHouse server are currently being supported with s
|
||||
| 22.6 | ❌ |
|
||||
| 22.5 | ❌ |
|
||||
| 22.4 | ❌ |
|
||||
| 22.3 | ✔️ |
|
||||
| 22.3 | ❌ |
|
||||
| 22.2 | ❌ |
|
||||
| 22.1 | ❌ |
|
||||
| 21.* | ❌ |
|
||||
|
||||
@ -466,9 +466,8 @@ JSON::Pos JSON::searchField(const char * data, size_t size) const
|
||||
{
|
||||
if (!it->hasEscapes())
|
||||
{
|
||||
if (static_cast<int>(size) + 2 > it->dataEnd() - it->data())
|
||||
continue;
|
||||
if (!strncmp(data, it->data() + 1, size))
|
||||
const auto current_name = it->getRawName();
|
||||
if (current_name.size() == size && 0 == memcmp(current_name.data(), data, size))
|
||||
break;
|
||||
}
|
||||
else
|
||||
|
||||
@ -35,7 +35,7 @@ public:
|
||||
Self & operator=(T && rhs) { t = std::move(rhs); return *this;}
|
||||
|
||||
// NOLINTBEGIN(google-explicit-constructor)
|
||||
operator const T & () const { return t; }
|
||||
constexpr operator const T & () const { return t; }
|
||||
operator T & () { return t; }
|
||||
// NOLINTEND(google-explicit-constructor)
|
||||
|
||||
|
||||
@ -1242,7 +1242,7 @@ constexpr integer<Bits, Signed>::operator long double() const noexcept
|
||||
for (unsigned i = 0; i < _impl::item_count; ++i)
|
||||
{
|
||||
long double t = res;
|
||||
res *= std::numeric_limits<base_type>::max();
|
||||
res *= static_cast<long double>(std::numeric_limits<base_type>::max());
|
||||
res += t;
|
||||
res += tmp.items[_impl::big(i)];
|
||||
}
|
||||
|
||||
@ -2,11 +2,11 @@
|
||||
|
||||
# NOTE: has nothing common with DBMS_TCP_PROTOCOL_VERSION,
|
||||
# only DBMS_TCP_PROTOCOL_VERSION should be incremented on protocol changes.
|
||||
SET(VERSION_REVISION 54472)
|
||||
SET(VERSION_REVISION 54473)
|
||||
SET(VERSION_MAJOR 23)
|
||||
SET(VERSION_MINOR 3)
|
||||
SET(VERSION_MINOR 4)
|
||||
SET(VERSION_PATCH 1)
|
||||
SET(VERSION_GITHASH 52bf836e03a6ba7cf2d654eaaf73231701abc3a2)
|
||||
SET(VERSION_DESCRIBE v23.3.1.2537-testing)
|
||||
SET(VERSION_STRING 23.3.1.2537)
|
||||
SET(VERSION_GITHASH 46e85357ce2da2a99f56ee83a079e892d7ec3726)
|
||||
SET(VERSION_DESCRIBE v23.4.1.1-testing)
|
||||
SET(VERSION_STRING 23.4.1.1)
|
||||
# end of autochange
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
# Setup integration with ccache to speed up builds, see https://ccache.dev/
|
||||
|
||||
# Matches both ccache and sccache
|
||||
if (CMAKE_CXX_COMPILER_LAUNCHER MATCHES "ccache" OR CMAKE_C_COMPILER_LAUNCHER MATCHES "ccache")
|
||||
# custom compiler launcher already defined, most likely because cmake was invoked with like "-DCMAKE_CXX_COMPILER_LAUNCHER=ccache" or
|
||||
# via environment variable --> respect setting and trust that the launcher was specified correctly
|
||||
@ -8,45 +9,65 @@ if (CMAKE_CXX_COMPILER_LAUNCHER MATCHES "ccache" OR CMAKE_C_COMPILER_LAUNCHER MA
|
||||
return()
|
||||
endif()
|
||||
|
||||
option(ENABLE_CCACHE "Speedup re-compilations using ccache (external tool)" ON)
|
||||
|
||||
if (NOT ENABLE_CCACHE)
|
||||
message(STATUS "Using ccache: no (disabled via configuration)")
|
||||
return()
|
||||
set(ENABLE_CCACHE "default" CACHE STRING "Deprecated, use COMPILER_CACHE=(auto|ccache|sccache|disabled)")
|
||||
if (NOT ENABLE_CCACHE STREQUAL "default")
|
||||
message(WARNING "The -DENABLE_CCACHE is deprecated in favor of -DCOMPILER_CACHE")
|
||||
endif()
|
||||
|
||||
set(COMPILER_CACHE "auto" CACHE STRING "Speedup re-compilations using the caching tools; valid options are 'auto' (ccache, then sccache), 'ccache', 'sccache', or 'disabled'")
|
||||
|
||||
# It has pretty complex logic, because the ENABLE_CCACHE is deprecated, but still should
|
||||
# control the COMPILER_CACHE
|
||||
# After it will be completely removed, the following block will be much simpler
|
||||
if (COMPILER_CACHE STREQUAL "ccache" OR (ENABLE_CCACHE AND NOT ENABLE_CCACHE STREQUAL "default"))
|
||||
find_program (CCACHE_EXECUTABLE ccache)
|
||||
elseif(COMPILER_CACHE STREQUAL "disabled" OR NOT ENABLE_CCACHE STREQUAL "default")
|
||||
message(STATUS "Using *ccache: no (disabled via configuration)")
|
||||
return()
|
||||
elseif(COMPILER_CACHE STREQUAL "auto")
|
||||
find_program (CCACHE_EXECUTABLE ccache sccache)
|
||||
elseif(COMPILER_CACHE STREQUAL "sccache")
|
||||
find_program (CCACHE_EXECUTABLE sccache)
|
||||
else()
|
||||
message(${RECONFIGURE_MESSAGE_LEVEL} "The COMPILER_CACHE must be one of (auto|ccache|sccache|disabled), given '${COMPILER_CACHE}'")
|
||||
endif()
|
||||
|
||||
find_program (CCACHE_EXECUTABLE ccache)
|
||||
|
||||
if (NOT CCACHE_EXECUTABLE)
|
||||
message(${RECONFIGURE_MESSAGE_LEVEL} "Using ccache: no (Could not find find ccache. To significantly reduce compile times for the 2nd, 3rd, etc. build, it is highly recommended to install ccache. To suppress this message, run cmake with -DENABLE_CCACHE=0)")
|
||||
message(${RECONFIGURE_MESSAGE_LEVEL} "Using *ccache: no (Could not find find ccache or sccache. To significantly reduce compile times for the 2nd, 3rd, etc. build, it is highly recommended to install one of them. To suppress this message, run cmake with -DCOMPILER_CACHE=disabled)")
|
||||
return()
|
||||
endif()
|
||||
|
||||
execute_process(COMMAND ${CCACHE_EXECUTABLE} "-V" OUTPUT_VARIABLE CCACHE_VERSION)
|
||||
string(REGEX REPLACE "ccache version ([0-9\\.]+).*" "\\1" CCACHE_VERSION ${CCACHE_VERSION})
|
||||
if (CCACHE_EXECUTABLE MATCHES "/ccache$")
|
||||
execute_process(COMMAND ${CCACHE_EXECUTABLE} "-V" OUTPUT_VARIABLE CCACHE_VERSION)
|
||||
string(REGEX REPLACE "ccache version ([0-9\\.]+).*" "\\1" CCACHE_VERSION ${CCACHE_VERSION})
|
||||
|
||||
set (CCACHE_MINIMUM_VERSION 3.3)
|
||||
set (CCACHE_MINIMUM_VERSION 3.3)
|
||||
|
||||
if (CCACHE_VERSION VERSION_LESS_EQUAL ${CCACHE_MINIMUM_VERSION})
|
||||
if (CCACHE_VERSION VERSION_LESS_EQUAL ${CCACHE_MINIMUM_VERSION})
|
||||
message(${RECONFIGURE_MESSAGE_LEVEL} "Using ccache: no (found ${CCACHE_EXECUTABLE} (version ${CCACHE_VERSION}), the minimum required version is ${CCACHE_MINIMUM_VERSION}")
|
||||
return()
|
||||
endif()
|
||||
endif()
|
||||
|
||||
message(STATUS "Using ccache: ${CCACHE_EXECUTABLE} (version ${CCACHE_VERSION})")
|
||||
set(LAUNCHER ${CCACHE_EXECUTABLE})
|
||||
message(STATUS "Using ccache: ${CCACHE_EXECUTABLE} (version ${CCACHE_VERSION})")
|
||||
set(LAUNCHER ${CCACHE_EXECUTABLE})
|
||||
|
||||
# Work around a well-intended but unfortunate behavior of ccache 4.0 & 4.1 with
|
||||
# environment variable SOURCE_DATE_EPOCH. This variable provides an alternative
|
||||
# to source-code embedded timestamps (__DATE__/__TIME__) and therefore helps with
|
||||
# reproducible builds (*). SOURCE_DATE_EPOCH is set automatically by the
|
||||
# distribution, e.g. Debian. Ccache 4.0 & 4.1 incorporate SOURCE_DATE_EPOCH into
|
||||
# the hash calculation regardless they contain timestamps or not. This invalidates
|
||||
# the cache whenever SOURCE_DATE_EPOCH changes. As a fix, ignore SOURCE_DATE_EPOCH.
|
||||
#
|
||||
# (*) https://reproducible-builds.org/specs/source-date-epoch/
|
||||
if (CCACHE_VERSION VERSION_GREATER_EQUAL "4.0" AND CCACHE_VERSION VERSION_LESS "4.2")
|
||||
# Work around a well-intended but unfortunate behavior of ccache 4.0 & 4.1 with
|
||||
# environment variable SOURCE_DATE_EPOCH. This variable provides an alternative
|
||||
# to source-code embedded timestamps (__DATE__/__TIME__) and therefore helps with
|
||||
# reproducible builds (*). SOURCE_DATE_EPOCH is set automatically by the
|
||||
# distribution, e.g. Debian. Ccache 4.0 & 4.1 incorporate SOURCE_DATE_EPOCH into
|
||||
# the hash calculation regardless they contain timestamps or not. This invalidates
|
||||
# the cache whenever SOURCE_DATE_EPOCH changes. As a fix, ignore SOURCE_DATE_EPOCH.
|
||||
#
|
||||
# (*) https://reproducible-builds.org/specs/source-date-epoch/
|
||||
if (CCACHE_VERSION VERSION_GREATER_EQUAL "4.0" AND CCACHE_VERSION VERSION_LESS "4.2")
|
||||
message(STATUS "Ignore SOURCE_DATE_EPOCH for ccache 4.0 / 4.1")
|
||||
set(LAUNCHER env -u SOURCE_DATE_EPOCH ${CCACHE_EXECUTABLE})
|
||||
endif()
|
||||
elseif(CCACHE_EXECUTABLE MATCHES "/sccache$")
|
||||
message(STATUS "Using sccache: ${CCACHE_EXECUTABLE}")
|
||||
set(LAUNCHER ${CCACHE_EXECUTABLE})
|
||||
endif()
|
||||
|
||||
set (CMAKE_CXX_COMPILER_LAUNCHER ${LAUNCHER} ${CMAKE_CXX_COMPILER_LAUNCHER})
|
||||
|
||||
2
contrib/boost
vendored
2
contrib/boost
vendored
@ -1 +1 @@
|
||||
Subproject commit 03d9ec9cd159d14bd0b17c05138098451a1ea606
|
||||
Subproject commit 8fe7b3326ef482ee6ecdf5a4f698f2b8c2780f98
|
||||
2
contrib/llvm-project
vendored
2
contrib/llvm-project
vendored
@ -1 +1 @@
|
||||
Subproject commit 4bfaeb31dd0ef13f025221f93c138974a3e0a22a
|
||||
Subproject commit e0accd517933ebb44aff84bc8db448ffd8ef1929
|
||||
2
contrib/sqlite-amalgamation
vendored
2
contrib/sqlite-amalgamation
vendored
@ -1 +1 @@
|
||||
Subproject commit 400ad7152a0c7ee07756d96ab4f6a8f6d1080916
|
||||
Subproject commit 20598079891d27ef1a3ad3f66bbfa3f983c25268
|
||||
@ -1,3 +1,6 @@
|
||||
# The Dockerfile.ubuntu exists for the tests/ci/docker_server.py script
|
||||
# If the image is built from Dockerfile.alpine, then the `-alpine` suffix is added automatically,
|
||||
# so the only purpose of Dockerfile.ubuntu is to push `latest`, `head` and so on w/o suffixes
|
||||
FROM ubuntu:20.04 AS glibc-donor
|
||||
|
||||
ARG TARGETARCH
|
||||
@ -29,7 +32,7 @@ RUN arch=${TARGETARCH:-amd64} \
|
||||
esac
|
||||
|
||||
ARG REPOSITORY="https://s3.amazonaws.com/clickhouse-builds/22.4/31c367d3cd3aefd316778601ff6565119fe36682/package_release"
|
||||
ARG VERSION="23.2.4.12"
|
||||
ARG VERSION="23.3.1.2823"
|
||||
ARG PACKAGES="clickhouse-keeper"
|
||||
|
||||
# user/group precreated explicitly with fixed uid/gid on purpose.
|
||||
|
||||
1
docker/keeper/Dockerfile.ubuntu
Symbolic link
1
docker/keeper/Dockerfile.ubuntu
Symbolic link
@ -0,0 +1 @@
|
||||
Dockerfile
|
||||
@ -69,13 +69,14 @@ RUN add-apt-repository ppa:ubuntu-toolchain-r/test --yes \
|
||||
libc6 \
|
||||
libc6-dev \
|
||||
libc6-dev-arm64-cross \
|
||||
python3-boto3 \
|
||||
yasm \
|
||||
zstd \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists
|
||||
|
||||
# Download toolchain and SDK for Darwin
|
||||
RUN wget -nv https://github.com/phracker/MacOSX-SDKs/releases/download/11.3/MacOSX11.0.sdk.tar.xz
|
||||
RUN curl -sL -O https://github.com/phracker/MacOSX-SDKs/releases/download/11.3/MacOSX11.0.sdk.tar.xz
|
||||
|
||||
# Architecture of the image when BuildKit/buildx is used
|
||||
ARG TARGETARCH
|
||||
@ -97,7 +98,7 @@ ENV PATH="$PATH:/usr/local/go/bin"
|
||||
ENV GOPATH=/workdir/go
|
||||
ENV GOCACHE=/workdir/
|
||||
|
||||
ARG CLANG_TIDY_SHA1=03644275e794b0587849bfc2ec6123d5ae0bdb1c
|
||||
ARG CLANG_TIDY_SHA1=c191254ea00d47ade11d7170ef82fe038c213774
|
||||
RUN curl -Lo /usr/bin/clang-tidy-cache \
|
||||
"https://raw.githubusercontent.com/matus-chochlik/ctcache/$CLANG_TIDY_SHA1/clang-tidy-cache" \
|
||||
&& chmod +x /usr/bin/clang-tidy-cache
|
||||
|
||||
@ -6,6 +6,7 @@ exec &> >(ts)
|
||||
ccache_status () {
|
||||
ccache --show-config ||:
|
||||
ccache --show-stats ||:
|
||||
SCCACHE_NO_DAEMON=1 sccache --show-stats ||:
|
||||
}
|
||||
|
||||
[ -O /build ] || git config --global --add safe.directory /build
|
||||
|
||||
@ -5,13 +5,19 @@ import os
|
||||
import argparse
|
||||
import logging
|
||||
import sys
|
||||
from typing import List
|
||||
from pathlib import Path
|
||||
from typing import List, Optional
|
||||
|
||||
SCRIPT_PATH = os.path.realpath(__file__)
|
||||
SCRIPT_PATH = Path(__file__).absolute()
|
||||
IMAGE_TYPE = "binary"
|
||||
IMAGE_NAME = f"clickhouse/{IMAGE_TYPE}-builder"
|
||||
|
||||
|
||||
def check_image_exists_locally(image_name):
|
||||
class BuildException(Exception):
|
||||
pass
|
||||
|
||||
|
||||
def check_image_exists_locally(image_name: str) -> bool:
|
||||
try:
|
||||
output = subprocess.check_output(
|
||||
f"docker images -q {image_name} 2> /dev/null", shell=True
|
||||
@ -21,17 +27,17 @@ def check_image_exists_locally(image_name):
|
||||
return False
|
||||
|
||||
|
||||
def pull_image(image_name):
|
||||
def pull_image(image_name: str) -> bool:
|
||||
try:
|
||||
subprocess.check_call(f"docker pull {image_name}", shell=True)
|
||||
return True
|
||||
except subprocess.CalledProcessError:
|
||||
logging.info(f"Cannot pull image {image_name}".format())
|
||||
logging.info("Cannot pull image %s", image_name)
|
||||
return False
|
||||
|
||||
|
||||
def build_image(image_name, filepath):
|
||||
context = os.path.dirname(filepath)
|
||||
def build_image(image_name: str, filepath: Path) -> None:
|
||||
context = filepath.parent
|
||||
build_cmd = f"docker build --network=host -t {image_name} -f {filepath} {context}"
|
||||
logging.info("Will build image with cmd: '%s'", build_cmd)
|
||||
subprocess.check_call(
|
||||
@ -40,7 +46,7 @@ def build_image(image_name, filepath):
|
||||
)
|
||||
|
||||
|
||||
def pre_build(repo_path: str, env_variables: List[str]):
|
||||
def pre_build(repo_path: Path, env_variables: List[str]):
|
||||
if "WITH_PERFORMANCE=1" in env_variables:
|
||||
current_branch = subprocess.check_output(
|
||||
"git branch --show-current", shell=True, encoding="utf-8"
|
||||
@ -56,7 +62,9 @@ def pre_build(repo_path: str, env_variables: List[str]):
|
||||
# conclusion is: in the current state the easiest way to go is to force
|
||||
# unshallow repository for performance artifacts.
|
||||
# To change it we need to rework our performance tests docker image
|
||||
raise Exception("shallow repository is not suitable for performance builds")
|
||||
raise BuildException(
|
||||
"shallow repository is not suitable for performance builds"
|
||||
)
|
||||
if current_branch != "master":
|
||||
cmd = (
|
||||
f"git -C {repo_path} fetch --no-recurse-submodules "
|
||||
@ -67,14 +75,14 @@ def pre_build(repo_path: str, env_variables: List[str]):
|
||||
|
||||
|
||||
def run_docker_image_with_env(
|
||||
image_name,
|
||||
as_root,
|
||||
output,
|
||||
env_variables,
|
||||
ch_root,
|
||||
ccache_dir,
|
||||
docker_image_version,
|
||||
image_name: str,
|
||||
as_root: bool,
|
||||
output_dir: Path,
|
||||
env_variables: List[str],
|
||||
ch_root: Path,
|
||||
ccache_dir: Optional[Path],
|
||||
):
|
||||
output_dir.mkdir(parents=True, exist_ok=True)
|
||||
env_part = " -e ".join(env_variables)
|
||||
if env_part:
|
||||
env_part = " -e " + env_part
|
||||
@ -89,10 +97,14 @@ def run_docker_image_with_env(
|
||||
else:
|
||||
user = f"{os.geteuid()}:{os.getegid()}"
|
||||
|
||||
ccache_mount = f"--volume={ccache_dir}:/ccache"
|
||||
if ccache_dir is None:
|
||||
ccache_mount = ""
|
||||
|
||||
cmd = (
|
||||
f"docker run --network=host --user={user} --rm --volume={output}:/output "
|
||||
f"--volume={ch_root}:/build --volume={ccache_dir}:/ccache {env_part} "
|
||||
f"{interactive} {image_name}:{docker_image_version}"
|
||||
f"docker run --network=host --user={user} --rm {ccache_mount}"
|
||||
f"--volume={output_dir}:/output --volume={ch_root}:/build {env_part} "
|
||||
f"{interactive} {image_name}"
|
||||
)
|
||||
|
||||
logging.info("Will build ClickHouse pkg with cmd: '%s'", cmd)
|
||||
@ -100,24 +112,25 @@ def run_docker_image_with_env(
|
||||
subprocess.check_call(cmd, shell=True)
|
||||
|
||||
|
||||
def is_release_build(build_type, package_type, sanitizer):
|
||||
def is_release_build(build_type: str, package_type: str, sanitizer: str) -> bool:
|
||||
return build_type == "" and package_type == "deb" and sanitizer == ""
|
||||
|
||||
|
||||
def parse_env_variables(
|
||||
build_type,
|
||||
compiler,
|
||||
sanitizer,
|
||||
package_type,
|
||||
cache,
|
||||
distcc_hosts,
|
||||
clang_tidy,
|
||||
version,
|
||||
author,
|
||||
official,
|
||||
additional_pkgs,
|
||||
with_coverage,
|
||||
with_binaries,
|
||||
build_type: str,
|
||||
compiler: str,
|
||||
sanitizer: str,
|
||||
package_type: str,
|
||||
cache: str,
|
||||
s3_bucket: str,
|
||||
s3_directory: str,
|
||||
s3_rw_access: bool,
|
||||
clang_tidy: bool,
|
||||
version: str,
|
||||
official: bool,
|
||||
additional_pkgs: bool,
|
||||
with_coverage: bool,
|
||||
with_binaries: str,
|
||||
):
|
||||
DARWIN_SUFFIX = "-darwin"
|
||||
DARWIN_ARM_SUFFIX = "-darwin-aarch64"
|
||||
@ -243,32 +256,43 @@ def parse_env_variables(
|
||||
else:
|
||||
result.append("BUILD_TYPE=None")
|
||||
|
||||
if cache == "distcc":
|
||||
result.append(f"CCACHE_PREFIX={cache}")
|
||||
if not cache:
|
||||
cmake_flags.append("-DCOMPILER_CACHE=disabled")
|
||||
|
||||
if cache:
|
||||
if cache == "ccache":
|
||||
cmake_flags.append("-DCOMPILER_CACHE=ccache")
|
||||
result.append("CCACHE_DIR=/ccache")
|
||||
result.append("CCACHE_COMPRESSLEVEL=5")
|
||||
result.append("CCACHE_BASEDIR=/build")
|
||||
result.append("CCACHE_NOHASHDIR=true")
|
||||
result.append("CCACHE_COMPILERCHECK=content")
|
||||
cache_maxsize = "15G"
|
||||
if clang_tidy:
|
||||
# 15G is not enough for tidy build
|
||||
cache_maxsize = "25G"
|
||||
result.append("CCACHE_MAXSIZE=15G")
|
||||
|
||||
if cache == "sccache":
|
||||
cmake_flags.append("-DCOMPILER_CACHE=sccache")
|
||||
# see https://github.com/mozilla/sccache/blob/main/docs/S3.md
|
||||
result.append(f"SCCACHE_BUCKET={s3_bucket}")
|
||||
sccache_dir = "sccache"
|
||||
if s3_directory:
|
||||
sccache_dir = f"{s3_directory}/{sccache_dir}"
|
||||
result.append(f"SCCACHE_S3_KEY_PREFIX={sccache_dir}")
|
||||
if not s3_rw_access:
|
||||
result.append("SCCACHE_S3_NO_CREDENTIALS=true")
|
||||
|
||||
if clang_tidy:
|
||||
# `CTCACHE_DIR` has the same purpose as the `CCACHE_DIR` above.
|
||||
# It's there to have the clang-tidy cache embedded into our standard `CCACHE_DIR`
|
||||
if cache == "ccache":
|
||||
result.append("CTCACHE_DIR=/ccache/clang-tidy-cache")
|
||||
result.append(f"CCACHE_MAXSIZE={cache_maxsize}")
|
||||
|
||||
if distcc_hosts:
|
||||
hosts_with_params = [f"{host}/24,lzo" for host in distcc_hosts] + [
|
||||
"localhost/`nproc`"
|
||||
]
|
||||
result.append('DISTCC_HOSTS="' + " ".join(hosts_with_params) + '"')
|
||||
elif cache == "distcc":
|
||||
result.append('DISTCC_HOSTS="localhost/`nproc`"')
|
||||
if s3_bucket:
|
||||
# see https://github.com/matus-chochlik/ctcache#environment-variables
|
||||
ctcache_dir = "clang-tidy-cache"
|
||||
if s3_directory:
|
||||
ctcache_dir = f"{s3_directory}/{ctcache_dir}"
|
||||
result.append(f"CTCACHE_S3_BUCKET={s3_bucket}")
|
||||
result.append(f"CTCACHE_S3_FOLDER={ctcache_dir}")
|
||||
if not s3_rw_access:
|
||||
result.append("CTCACHE_S3_NO_CREDENTIALS=true")
|
||||
|
||||
if additional_pkgs:
|
||||
# NOTE: This are the env for packages/build script
|
||||
@ -300,9 +324,6 @@ def parse_env_variables(
|
||||
if version:
|
||||
result.append(f"VERSION_STRING='{version}'")
|
||||
|
||||
if author:
|
||||
result.append(f"AUTHOR='{author}'")
|
||||
|
||||
if official:
|
||||
cmake_flags.append("-DCLICKHOUSE_OFFICIAL_BUILD=1")
|
||||
|
||||
@ -312,14 +333,14 @@ def parse_env_variables(
|
||||
return result
|
||||
|
||||
|
||||
def dir_name(name: str) -> str:
|
||||
if not os.path.isabs(name):
|
||||
name = os.path.abspath(os.path.join(os.getcwd(), name))
|
||||
return name
|
||||
def dir_name(name: str) -> Path:
|
||||
path = Path(name)
|
||||
if not path.is_absolute():
|
||||
path = Path.cwd() / name
|
||||
return path
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(message)s")
|
||||
def parse_args() -> argparse.Namespace:
|
||||
parser = argparse.ArgumentParser(
|
||||
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
|
||||
description="ClickHouse building script using prebuilt Docker image",
|
||||
@ -331,7 +352,7 @@ if __name__ == "__main__":
|
||||
)
|
||||
parser.add_argument(
|
||||
"--clickhouse-repo-path",
|
||||
default=os.path.join(os.path.dirname(SCRIPT_PATH), os.pardir, os.pardir),
|
||||
default=SCRIPT_PATH.parents[2],
|
||||
type=dir_name,
|
||||
help="ClickHouse git repository",
|
||||
)
|
||||
@ -361,17 +382,34 @@ if __name__ == "__main__":
|
||||
)
|
||||
|
||||
parser.add_argument("--clang-tidy", action="store_true")
|
||||
parser.add_argument("--cache", choices=("ccache", "distcc", ""), default="")
|
||||
parser.add_argument(
|
||||
"--ccache_dir",
|
||||
default=os.getenv("HOME", "") + "/.ccache",
|
||||
"--cache",
|
||||
choices=("ccache", "sccache", ""),
|
||||
default="",
|
||||
help="ccache or sccache for objects caching; sccache uses only S3 buckets",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--ccache-dir",
|
||||
default=Path.home() / ".ccache",
|
||||
type=dir_name,
|
||||
help="a directory with ccache",
|
||||
)
|
||||
parser.add_argument("--distcc-hosts", nargs="+")
|
||||
parser.add_argument(
|
||||
"--s3-bucket",
|
||||
help="an S3 bucket used for sscache and clang-tidy-cache",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--s3-directory",
|
||||
default="ccache",
|
||||
help="an S3 directory prefix used for sscache and clang-tidy-cache",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--s3-rw-access",
|
||||
action="store_true",
|
||||
help="if set, the build fails on errors writing cache to S3",
|
||||
)
|
||||
parser.add_argument("--force-build-image", action="store_true")
|
||||
parser.add_argument("--version")
|
||||
parser.add_argument("--author", default="clickhouse", help="a package author")
|
||||
parser.add_argument("--official", action="store_true")
|
||||
parser.add_argument("--additional-pkgs", action="store_true")
|
||||
parser.add_argument("--with-coverage", action="store_true")
|
||||
@ -387,34 +425,54 @@ if __name__ == "__main__":
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
image_name = f"clickhouse/{IMAGE_TYPE}-builder"
|
||||
if args.additional_pkgs and args.package_type != "deb":
|
||||
raise argparse.ArgumentTypeError(
|
||||
"Can build additional packages only in deb build"
|
||||
)
|
||||
|
||||
if args.cache != "ccache":
|
||||
args.ccache_dir = None
|
||||
|
||||
if args.with_binaries != "":
|
||||
if args.package_type != "deb":
|
||||
raise argparse.ArgumentTypeError(
|
||||
"Can add additional binaries only in deb build"
|
||||
)
|
||||
logging.info("Should place %s to output", args.with_binaries)
|
||||
|
||||
if args.cache == "sccache":
|
||||
if not args.s3_bucket:
|
||||
raise argparse.ArgumentTypeError("sccache must have --s3-bucket set")
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def main():
|
||||
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(message)s")
|
||||
args = parse_args()
|
||||
|
||||
ch_root = args.clickhouse_repo_path
|
||||
|
||||
if args.additional_pkgs and args.package_type != "deb":
|
||||
raise Exception("Can build additional packages only in deb build")
|
||||
|
||||
if args.with_binaries != "" and args.package_type != "deb":
|
||||
raise Exception("Can add additional binaries only in deb build")
|
||||
|
||||
if args.with_binaries != "" and args.package_type == "deb":
|
||||
logging.info("Should place %s to output", args.with_binaries)
|
||||
|
||||
dockerfile = os.path.join(ch_root, "docker/packager", IMAGE_TYPE, "Dockerfile")
|
||||
image_with_version = image_name + ":" + args.docker_image_version
|
||||
if not check_image_exists_locally(image_name) or args.force_build_image:
|
||||
if not pull_image(image_with_version) or args.force_build_image:
|
||||
dockerfile = ch_root / "docker/packager" / IMAGE_TYPE / "Dockerfile"
|
||||
image_with_version = IMAGE_NAME + ":" + args.docker_image_version
|
||||
if args.force_build_image:
|
||||
build_image(image_with_version, dockerfile)
|
||||
elif not (
|
||||
check_image_exists_locally(image_with_version) or pull_image(image_with_version)
|
||||
):
|
||||
build_image(image_with_version, dockerfile)
|
||||
|
||||
env_prepared = parse_env_variables(
|
||||
args.build_type,
|
||||
args.compiler,
|
||||
args.sanitizer,
|
||||
args.package_type,
|
||||
args.cache,
|
||||
args.distcc_hosts,
|
||||
args.s3_bucket,
|
||||
args.s3_directory,
|
||||
args.s3_rw_access,
|
||||
args.clang_tidy,
|
||||
args.version,
|
||||
args.author,
|
||||
args.official,
|
||||
args.additional_pkgs,
|
||||
args.with_coverage,
|
||||
@ -423,12 +481,15 @@ if __name__ == "__main__":
|
||||
|
||||
pre_build(args.clickhouse_repo_path, env_prepared)
|
||||
run_docker_image_with_env(
|
||||
image_name,
|
||||
image_with_version,
|
||||
args.as_root,
|
||||
args.output_dir,
|
||||
env_prepared,
|
||||
ch_root,
|
||||
args.ccache_dir,
|
||||
args.docker_image_version,
|
||||
)
|
||||
logging.info("Output placed into %s", args.output_dir)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
||||
@ -33,7 +33,7 @@ RUN arch=${TARGETARCH:-amd64} \
|
||||
# lts / testing / prestable / etc
|
||||
ARG REPO_CHANNEL="stable"
|
||||
ARG REPOSITORY="https://packages.clickhouse.com/tgz/${REPO_CHANNEL}"
|
||||
ARG VERSION="23.2.4.12"
|
||||
ARG VERSION="23.3.1.2823"
|
||||
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
||||
|
||||
# user/group precreated explicitly with fixed uid/gid on purpose.
|
||||
|
||||
@ -22,7 +22,7 @@ RUN sed -i "s|http://archive.ubuntu.com|${apt_archive}|g" /etc/apt/sources.list
|
||||
|
||||
ARG REPO_CHANNEL="stable"
|
||||
ARG REPOSITORY="deb https://packages.clickhouse.com/deb ${REPO_CHANNEL} main"
|
||||
ARG VERSION="23.2.4.12"
|
||||
ARG VERSION="23.3.1.2823"
|
||||
ARG PACKAGES="clickhouse-client clickhouse-server clickhouse-common-static"
|
||||
|
||||
# set non-empty deb_location_url url to create a docker image
|
||||
|
||||
@ -20,12 +20,6 @@ RUN apt-get update \
|
||||
zstd \
|
||||
--yes --no-install-recommends
|
||||
|
||||
# Install CMake 3.20+ for Rust compilation
|
||||
RUN apt purge cmake --yes
|
||||
RUN wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | gpg --dearmor - | tee /etc/apt/trusted.gpg.d/kitware.gpg >/dev/null
|
||||
RUN apt-add-repository 'deb https://apt.kitware.com/ubuntu/ focal main'
|
||||
RUN apt update && apt install cmake --yes
|
||||
|
||||
RUN pip3 install numpy scipy pandas Jinja2
|
||||
|
||||
ARG odbc_driver_url="https://github.com/ClickHouse/clickhouse-odbc/releases/download/v1.1.4.20200302/clickhouse-odbc-1.1.4-Linux.tar.gz"
|
||||
|
||||
@ -16,7 +16,8 @@ export LLVM_VERSION=${LLVM_VERSION:-13}
|
||||
# it being undefined. Also read it as array so that we can pass an empty list
|
||||
# of additional variable to cmake properly, and it doesn't generate an extra
|
||||
# empty parameter.
|
||||
read -ra FASTTEST_CMAKE_FLAGS <<< "${FASTTEST_CMAKE_FLAGS:-}"
|
||||
# Read it as CMAKE_FLAGS to not lose exported FASTTEST_CMAKE_FLAGS on subsequential launch
|
||||
read -ra CMAKE_FLAGS <<< "${FASTTEST_CMAKE_FLAGS:-}"
|
||||
|
||||
# Run only matching tests.
|
||||
FASTTEST_FOCUS=${FASTTEST_FOCUS:-""}
|
||||
@ -37,6 +38,13 @@ export FASTTEST_DATA
|
||||
export FASTTEST_OUT
|
||||
export PATH
|
||||
|
||||
function ccache_status
|
||||
{
|
||||
ccache --show-config ||:
|
||||
ccache --show-stats ||:
|
||||
SCCACHE_NO_DAEMON=1 sccache --show-stats ||:
|
||||
}
|
||||
|
||||
function start_server
|
||||
{
|
||||
set -m # Spawn server in its own process groups
|
||||
@ -171,14 +179,14 @@ function run_cmake
|
||||
export CCACHE_COMPILERCHECK=content
|
||||
export CCACHE_MAXSIZE=15G
|
||||
|
||||
ccache --show-stats ||:
|
||||
ccache_status
|
||||
ccache --zero-stats ||:
|
||||
|
||||
mkdir "$FASTTEST_BUILD" ||:
|
||||
|
||||
(
|
||||
cd "$FASTTEST_BUILD"
|
||||
cmake "$FASTTEST_SOURCE" -DCMAKE_CXX_COMPILER="clang++-${LLVM_VERSION}" -DCMAKE_C_COMPILER="clang-${LLVM_VERSION}" "${CMAKE_LIBS_CONFIG[@]}" "${FASTTEST_CMAKE_FLAGS[@]}" 2>&1 | ts '%Y-%m-%d %H:%M:%S' | tee "$FASTTEST_OUTPUT/cmake_log.txt"
|
||||
cmake "$FASTTEST_SOURCE" -DCMAKE_CXX_COMPILER="clang++-${LLVM_VERSION}" -DCMAKE_C_COMPILER="clang-${LLVM_VERSION}" "${CMAKE_LIBS_CONFIG[@]}" "${CMAKE_FLAGS[@]}" 2>&1 | ts '%Y-%m-%d %H:%M:%S' | tee "$FASTTEST_OUTPUT/cmake_log.txt"
|
||||
)
|
||||
}
|
||||
|
||||
@ -193,7 +201,7 @@ function build
|
||||
strip programs/clickhouse -o "$FASTTEST_OUTPUT/clickhouse-stripped"
|
||||
zstd --threads=0 "$FASTTEST_OUTPUT/clickhouse-stripped"
|
||||
fi
|
||||
ccache --show-stats ||:
|
||||
ccache_status
|
||||
ccache --evict-older-than 1d ||:
|
||||
)
|
||||
}
|
||||
|
||||
@ -109,8 +109,7 @@ mv /var/log/clickhouse-server/clickhouse-server.log /var/log/clickhouse-server/c
|
||||
|
||||
# Install and start new server
|
||||
install_packages package_folder
|
||||
# Disable fault injections on start (we don't test them here, and it can lead to tons of requests in case of huge number of tables).
|
||||
export ZOOKEEPER_FAULT_INJECTION=0
|
||||
export ZOOKEEPER_FAULT_INJECTION=1
|
||||
configure
|
||||
start 500
|
||||
clickhouse-client --query "SELECT 'Server successfully started', 'OK', NULL, ''" >> /test_output/test_results.tsv \
|
||||
|
||||
@ -92,4 +92,17 @@ RUN mkdir /tmp/ccache \
|
||||
&& cd / \
|
||||
&& rm -rf /tmp/ccache
|
||||
|
||||
ARG TARGETARCH
|
||||
ARG SCCACHE_VERSION=v0.4.1
|
||||
RUN arch=${TARGETARCH:-amd64} \
|
||||
&& case $arch in \
|
||||
amd64) rarch=x86_64 ;; \
|
||||
arm64) rarch=aarch64 ;; \
|
||||
esac \
|
||||
&& curl -Ls "https://github.com/mozilla/sccache/releases/download/$SCCACHE_VERSION/sccache-$SCCACHE_VERSION-$rarch-unknown-linux-musl.tar.gz" | \
|
||||
tar xz -C /tmp \
|
||||
&& mv "/tmp/sccache-$SCCACHE_VERSION-$rarch-unknown-linux-musl/sccache" /usr/bin \
|
||||
&& rm "/tmp/sccache-$SCCACHE_VERSION-$rarch-unknown-linux-musl" -r
|
||||
|
||||
|
||||
COPY process_functional_tests_result.py /
|
||||
|
||||
1
docs/.gitignore
vendored
1
docs/.gitignore
vendored
@ -1 +1,2 @@
|
||||
build
|
||||
clickhouse-docs
|
||||
|
||||
@ -40,6 +40,8 @@ The documentation contains information about all the aspects of the ClickHouse l
|
||||
|
||||
At the moment, [documentation](https://clickhouse.com/docs) exists in English, Russian, and Chinese. We store the reference documentation besides the ClickHouse source code in the [GitHub repository](https://github.com/ClickHouse/ClickHouse/tree/master/docs), and user guides in a separate repo [Clickhouse/clickhouse-docs](https://github.com/ClickHouse/clickhouse-docs).
|
||||
|
||||
To get the latter launch the `get-clickhouse-docs.sh` script.
|
||||
|
||||
Each language lies in the corresponding folder. Files that are not translated from English are symbolic links to the English ones.
|
||||
|
||||
<a name="how-to-contribute"/>
|
||||
|
||||
26
docs/changelogs/v22.12.6.22-stable.md
Normal file
26
docs/changelogs/v22.12.6.22-stable.md
Normal file
@ -0,0 +1,26 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_label: 2023
|
||||
---
|
||||
|
||||
# 2023 Changelog
|
||||
|
||||
### ClickHouse release v22.12.6.22-stable (10d87f90261) FIXME as compared to v22.12.5.34-stable (b82d6401ca1)
|
||||
|
||||
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||
|
||||
* Fix changing an expired role [#46772](https://github.com/ClickHouse/ClickHouse/pull/46772) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Fix bug in zero-copy replication disk choice during fetch [#47010](https://github.com/ClickHouse/ClickHouse/pull/47010) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix NOT_IMPLEMENTED error with CROSS JOIN and algorithm = auto [#47068](https://github.com/ClickHouse/ClickHouse/pull/47068) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix query parameters [#47488](https://github.com/ClickHouse/ClickHouse/pull/47488) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Hotfix for too verbose warnings in HTTP [#47903](https://github.com/ClickHouse/ClickHouse/pull/47903) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
|
||||
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||
|
||||
* Better error messages in ReplicatedMergeTreeAttachThread [#47454](https://github.com/ClickHouse/ClickHouse/pull/47454) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Add a fuse for backport branches w/o a created PR [#47760](https://github.com/ClickHouse/ClickHouse/pull/47760) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Only valid Reviews.STATES overwrite existing reviews [#47789](https://github.com/ClickHouse/ClickHouse/pull/47789) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Place short return before big block, improve logging [#47822](https://github.com/ClickHouse/ClickHouse/pull/47822) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Artifacts s3 prefix [#47945](https://github.com/ClickHouse/ClickHouse/pull/47945) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix tsan error lock-order-inversion [#47953](https://github.com/ClickHouse/ClickHouse/pull/47953) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
|
||||
29
docs/changelogs/v22.3.20.29-lts.md
Normal file
29
docs/changelogs/v22.3.20.29-lts.md
Normal file
@ -0,0 +1,29 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_label: 2023
|
||||
---
|
||||
|
||||
# 2023 Changelog
|
||||
|
||||
### ClickHouse release v22.3.20.29-lts (297b4dd5e55) FIXME as compared to v22.3.19.6-lts (467e0a7bd77)
|
||||
|
||||
#### Improvement
|
||||
* Backported in [#46979](https://github.com/ClickHouse/ClickHouse/issues/46979): Apply `ALTER TABLE table_name ON CLUSTER cluster MOVE PARTITION|PART partition_expr TO DISK|VOLUME 'disk_name'` to all replicas. Because `ALTER TABLE t MOVE` is not replicated. [#46402](https://github.com/ClickHouse/ClickHouse/pull/46402) ([lizhuoyu5](https://github.com/lzydmxy)).
|
||||
|
||||
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||
|
||||
* Fix incorrect alias recursion in QueryNormalizer [#46609](https://github.com/ClickHouse/ClickHouse/pull/46609) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Fix arithmetic operations in aggregate optimization [#46705](https://github.com/ClickHouse/ClickHouse/pull/46705) ([Duc Canh Le](https://github.com/canhld94)).
|
||||
* Fix MSan report in `maxIntersections` function [#46847](https://github.com/ClickHouse/ClickHouse/pull/46847) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix wrong results of some LIKE searches when the LIKE pattern contains quoted non-quotable characters [#46875](https://github.com/ClickHouse/ClickHouse/pull/46875) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix possible deadlock in QueryStatus [#47161](https://github.com/ClickHouse/ClickHouse/pull/47161) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
|
||||
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||
|
||||
* Update typing for a new PyGithub version [#47123](https://github.com/ClickHouse/ClickHouse/pull/47123) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Add a manual trigger for release workflow [#47302](https://github.com/ClickHouse/ClickHouse/pull/47302) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Add a fuse for backport branches w/o a created PR [#47760](https://github.com/ClickHouse/ClickHouse/pull/47760) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Only valid Reviews.STATES overwrite existing reviews [#47789](https://github.com/ClickHouse/ClickHouse/pull/47789) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Place short return before big block, improve logging [#47822](https://github.com/ClickHouse/ClickHouse/pull/47822) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix tsan error lock-order-inversion [#47953](https://github.com/ClickHouse/ClickHouse/pull/47953) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
|
||||
@ -9,7 +9,7 @@ sidebar_label: 2022
|
||||
|
||||
#### Backward Incompatible Change
|
||||
* Function `yandexConsistentHash` (consistent hashing algorithm by Konstantin "kostik" Oblakov) is renamed to `kostikConsistentHash`. The old name is left as an alias for compatibility. Although this change is backward compatible, we may remove the alias in subsequent releases, that's why it's recommended to update the usages of this function in your apps. [#35553](https://github.com/ClickHouse/ClickHouse/pull/35553) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Do not allow SETTINGS after FORMAT for INSERT queries (there is compatibility setting `parser_settings_after_format_compact` to accept such queries, but it is turned OFF by default). [#35883](https://github.com/ClickHouse/ClickHouse/pull/35883) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Do not allow SETTINGS after FORMAT for INSERT queries (there is compatibility setting `allow_settings_after_format_in_insert` to accept such queries, but it is turned OFF by default). [#35883](https://github.com/ClickHouse/ClickHouse/pull/35883) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Changed hashed path for cache files. [#36079](https://github.com/ClickHouse/ClickHouse/pull/36079) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
|
||||
#### New Feature
|
||||
|
||||
34
docs/changelogs/v23.1.6.42-stable.md
Normal file
34
docs/changelogs/v23.1.6.42-stable.md
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_label: 2023
|
||||
---
|
||||
|
||||
# 2023 Changelog
|
||||
|
||||
### ClickHouse release v23.1.6.42-stable (783ddf67991) FIXME as compared to v23.1.5.24-stable (0e51b53ba99)
|
||||
|
||||
#### Build/Testing/Packaging Improvement
|
||||
* Backported in [#48215](https://github.com/ClickHouse/ClickHouse/issues/48215): Use sccache as a replacement for ccache and using S3 as cache backend. [#46240](https://github.com/ClickHouse/ClickHouse/pull/46240) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Backported in [#48254](https://github.com/ClickHouse/ClickHouse/issues/48254): The `clickhouse/clickhouse-keeper` image used to be pushed only with tags `-alpine`, e.g. `latest-alpine`. As it was suggested in https://github.com/ClickHouse/examples/pull/2, now it will be pushed as suffixless too. [#48236](https://github.com/ClickHouse/ClickHouse/pull/48236) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
|
||||
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||
|
||||
* Fix changing an expired role [#46772](https://github.com/ClickHouse/ClickHouse/pull/46772) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Fix bug in zero-copy replication disk choice during fetch [#47010](https://github.com/ClickHouse/ClickHouse/pull/47010) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix NOT_IMPLEMENTED error with CROSS JOIN and algorithm = auto [#47068](https://github.com/ClickHouse/ClickHouse/pull/47068) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Disable logical expression optimizer for expression with aliases. [#47451](https://github.com/ClickHouse/ClickHouse/pull/47451) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Fix query parameters [#47488](https://github.com/ClickHouse/ClickHouse/pull/47488) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Parameterized view bug fix 47287 47247 [#47495](https://github.com/ClickHouse/ClickHouse/pull/47495) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Fix wait for zero copy lock during move [#47631](https://github.com/ClickHouse/ClickHouse/pull/47631) ([alesapin](https://github.com/alesapin)).
|
||||
* Hotfix for too verbose warnings in HTTP [#47903](https://github.com/ClickHouse/ClickHouse/pull/47903) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
|
||||
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||
|
||||
* Better error messages in ReplicatedMergeTreeAttachThread [#47454](https://github.com/ClickHouse/ClickHouse/pull/47454) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix `00933_test_fix_extra_seek_on_compressed_cache` in releases. [#47490](https://github.com/ClickHouse/ClickHouse/pull/47490) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Add a fuse for backport branches w/o a created PR [#47760](https://github.com/ClickHouse/ClickHouse/pull/47760) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Only valid Reviews.STATES overwrite existing reviews [#47789](https://github.com/ClickHouse/ClickHouse/pull/47789) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Place short return before big block, improve logging [#47822](https://github.com/ClickHouse/ClickHouse/pull/47822) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Artifacts s3 prefix [#47945](https://github.com/ClickHouse/ClickHouse/pull/47945) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix tsan error lock-order-inversion [#47953](https://github.com/ClickHouse/ClickHouse/pull/47953) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
|
||||
40
docs/changelogs/v23.2.5.46-stable.md
Normal file
40
docs/changelogs/v23.2.5.46-stable.md
Normal file
@ -0,0 +1,40 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_label: 2023
|
||||
---
|
||||
|
||||
# 2023 Changelog
|
||||
|
||||
### ClickHouse release v23.2.5.46-stable (b50faecbb12) FIXME as compared to v23.2.4.12-stable (8fe866cb035)
|
||||
|
||||
#### Improvement
|
||||
* Backported in [#48164](https://github.com/ClickHouse/ClickHouse/issues/48164): Fixed `UNKNOWN_TABLE` exception when attaching to a materialized view that has dependent tables that are not available. This might be useful when trying to restore state from a backup. [#47975](https://github.com/ClickHouse/ClickHouse/pull/47975) ([MikhailBurdukov](https://github.com/MikhailBurdukov)).
|
||||
|
||||
#### Build/Testing/Packaging Improvement
|
||||
* Backported in [#48216](https://github.com/ClickHouse/ClickHouse/issues/48216): Use sccache as a replacement for ccache and using S3 as cache backend. [#46240](https://github.com/ClickHouse/ClickHouse/pull/46240) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Backported in [#48256](https://github.com/ClickHouse/ClickHouse/issues/48256): The `clickhouse/clickhouse-keeper` image used to be pushed only with tags `-alpine`, e.g. `latest-alpine`. As it was suggested in https://github.com/ClickHouse/examples/pull/2, now it will be pushed as suffixless too. [#48236](https://github.com/ClickHouse/ClickHouse/pull/48236) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
|
||||
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||
|
||||
* Fix changing an expired role [#46772](https://github.com/ClickHouse/ClickHouse/pull/46772) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Fix bug in zero-copy replication disk choice during fetch [#47010](https://github.com/ClickHouse/ClickHouse/pull/47010) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix NOT_IMPLEMENTED error with CROSS JOIN and algorithm = auto [#47068](https://github.com/ClickHouse/ClickHouse/pull/47068) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Disable logical expression optimizer for expression with aliases. [#47451](https://github.com/ClickHouse/ClickHouse/pull/47451) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Fix query parameters [#47488](https://github.com/ClickHouse/ClickHouse/pull/47488) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Parameterized view bug fix 47287 47247 [#47495](https://github.com/ClickHouse/ClickHouse/pull/47495) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Proper fix for bug in parquet, revert reverted [#45878](https://github.com/ClickHouse/ClickHouse/issues/45878) [#47538](https://github.com/ClickHouse/ClickHouse/pull/47538) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix wait for zero copy lock during move [#47631](https://github.com/ClickHouse/ClickHouse/pull/47631) ([alesapin](https://github.com/alesapin)).
|
||||
* Hotfix for too verbose warnings in HTTP [#47903](https://github.com/ClickHouse/ClickHouse/pull/47903) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
|
||||
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||
|
||||
* fix: keeper systemd service file include invalid inline comment [#47105](https://github.com/ClickHouse/ClickHouse/pull/47105) ([SuperDJY](https://github.com/cmsxbc)).
|
||||
* Better error messages in ReplicatedMergeTreeAttachThread [#47454](https://github.com/ClickHouse/ClickHouse/pull/47454) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix `00933_test_fix_extra_seek_on_compressed_cache` in releases. [#47490](https://github.com/ClickHouse/ClickHouse/pull/47490) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix startup on older systemd versions [#47689](https://github.com/ClickHouse/ClickHouse/pull/47689) ([Thomas Casteleyn](https://github.com/Hipska)).
|
||||
* Add a fuse for backport branches w/o a created PR [#47760](https://github.com/ClickHouse/ClickHouse/pull/47760) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Only valid Reviews.STATES overwrite existing reviews [#47789](https://github.com/ClickHouse/ClickHouse/pull/47789) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Place short return before big block, improve logging [#47822](https://github.com/ClickHouse/ClickHouse/pull/47822) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Artifacts s3 prefix [#47945](https://github.com/ClickHouse/ClickHouse/pull/47945) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix tsan error lock-order-inversion [#47953](https://github.com/ClickHouse/ClickHouse/pull/47953) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
|
||||
545
docs/changelogs/v23.3.1.2823-lts.md
Normal file
545
docs/changelogs/v23.3.1.2823-lts.md
Normal file
@ -0,0 +1,545 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_label: 2023
|
||||
---
|
||||
|
||||
# 2023 Changelog
|
||||
|
||||
### ClickHouse release v23.3.1.2823-lts (46e85357ce2) FIXME as compared to v23.2.1.2537-stable (52bf836e03a)
|
||||
|
||||
#### Backward Incompatible Change
|
||||
* Relax symbols that are allowed in URL authority in *domain*RFC()/netloc(). [#46841](https://github.com/ClickHouse/ClickHouse/pull/46841) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Prohibit create tables based on KafkaEngine with DEFAULT/EPHEMERAL/ALIAS/MATERIALIZED statements for columns. [#47138](https://github.com/ClickHouse/ClickHouse/pull/47138) ([Aleksandr Musorin](https://github.com/AVMusorin)).
|
||||
* An "asynchronous connection drain" feature is removed. Related settings and metrics are removed as well. It was an internal feature, so the removal should not affect users who had never heard about that feature. [#47486](https://github.com/ClickHouse/ClickHouse/pull/47486) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Support 256-bit Decimal data type (more than 38 digits) in `arraySum`/`Min`/`Max`/`Avg`/`Product`, `arrayCumSum`/`CumSumNonNegative`, `arrayDifference`, array construction, IN operator, query parameters, `groupArrayMovingSum`, statistical functions, `min`/`max`/`any`/`argMin`/`argMax`, PostgreSQL wire protocol, MySQL table engine and function, `sumMap`, `mapAdd`, `mapSubtract`, `arrayIntersect`. Add support for big integers in `arrayIntersect`. Statistical aggregate functions involving moments (such as `corr` or various `TTest`s) will use `Float64` as their internal representation (they were using `Decimal128` before this change, but it was pointless), and these functions can return `nan` instead of `inf` in case of infinite variance. Some functions were allowed on `Decimal256` data types but returned `Decimal128` in previous versions - now it is fixed. This closes [#47569](https://github.com/ClickHouse/ClickHouse/issues/47569). This closes [#44864](https://github.com/ClickHouse/ClickHouse/issues/44864). This closes [#28335](https://github.com/ClickHouse/ClickHouse/issues/28335). [#47594](https://github.com/ClickHouse/ClickHouse/pull/47594) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Make backup_threads/restore_threads server settings. [#47881](https://github.com/ClickHouse/ClickHouse/pull/47881) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix the isIPv6String function which could have outputted a false positive result in the case of an incorrect IPv6 address. For example `1234::1234:` was considered a valid IPv6 address. [#47895](https://github.com/ClickHouse/ClickHouse/pull/47895) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
|
||||
#### New Feature
|
||||
* Add new mode for splitting the work on replicas using settings `parallel_replicas_custom_key` and `parallel_replicas_custom_key_filter_type`. If the cluster consists of a single shard with multiple replicas, up to `max_parallel_replicas` will be randomly picked and turned into shards. For each shard, a corresponding filter is added to the query on the initiator before being sent to the shard. If the cluster consists of multiple shards, it will behave the same as `sample_key` but with the possibility to define an arbitrary key. [#45108](https://github.com/ClickHouse/ClickHouse/pull/45108) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Added query setting `partial_result_on_first_cancel` allowing the canceled query (e.g. due to Ctrl-C) to return a partial result. [#45689](https://github.com/ClickHouse/ClickHouse/pull/45689) ([Alexey Perevyshin](https://github.com/alexX512)).
|
||||
* Added support of arbitrary tables engines for temporary tables except for Replicated and KeeperMap engines. Partially close [#31497](https://github.com/ClickHouse/ClickHouse/issues/31497). [#46071](https://github.com/ClickHouse/ClickHouse/pull/46071) ([Roman Vasin](https://github.com/rvasin)).
|
||||
* Add replication of user-defined SQL functions using ZooKeeper. [#46085](https://github.com/ClickHouse/ClickHouse/pull/46085) ([Aleksei Filatov](https://github.com/aalexfvk)).
|
||||
* Implement `system.server_settings` (similar to `system.settings`), which will contain server configurations. [#46550](https://github.com/ClickHouse/ClickHouse/pull/46550) ([pufit](https://github.com/pufit)).
|
||||
* Intruduce a function `WIDTH_BUCKET`. [#42974](https://github.com/ClickHouse/ClickHouse/issues/42974). [#46790](https://github.com/ClickHouse/ClickHouse/pull/46790) ([avoiderboi](https://github.com/avoiderboi)).
|
||||
* Add new function parseDateTime/parseDateTimeInJodaSyntax according to specified format string. parseDateTime parses string to datetime in MySQL syntax, parseDateTimeInJodaSyntax parses in Joda syntax. [#46815](https://github.com/ClickHouse/ClickHouse/pull/46815) ([李扬](https://github.com/taiyang-li)).
|
||||
* Use `dummy UInt8` for default structure of table function `null`. Closes [#46930](https://github.com/ClickHouse/ClickHouse/issues/46930). [#47006](https://github.com/ClickHouse/ClickHouse/pull/47006) ([flynn](https://github.com/ucasfl)).
|
||||
* Dec 15, 2021 support for parseDateTimeBestEffort function. closes [#46816](https://github.com/ClickHouse/ClickHouse/issues/46816). [#47071](https://github.com/ClickHouse/ClickHouse/pull/47071) ([chen](https://github.com/xiedeyantu)).
|
||||
* Add function ULIDStringToDateTime(). Closes [#46945](https://github.com/ClickHouse/ClickHouse/issues/46945). [#47087](https://github.com/ClickHouse/ClickHouse/pull/47087) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Add settings `http_wait_end_of_query` and `http_response_buffer_size` that corresponds to URL params `wait_end_of_query` and `buffer_size` for HTTP interface. [#47108](https://github.com/ClickHouse/ClickHouse/pull/47108) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Support for `UNDROP TABLE` query. Closes [#46811](https://github.com/ClickHouse/ClickHouse/issues/46811). [#47241](https://github.com/ClickHouse/ClickHouse/pull/47241) ([chen](https://github.com/xiedeyantu)).
|
||||
* Add `system.marked_dropped_tables` table that shows tables that were dropped from `Atomic` databases but were not completely removed yet. [#47364](https://github.com/ClickHouse/ClickHouse/pull/47364) ([chen](https://github.com/xiedeyantu)).
|
||||
* Add `INSTR` as alias of `positionCaseInsensitive` for MySQL compatibility. Closes [#47529](https://github.com/ClickHouse/ClickHouse/issues/47529). [#47535](https://github.com/ClickHouse/ClickHouse/pull/47535) ([flynn](https://github.com/ucasfl)).
|
||||
* Added `toDecimalString` function allowing to convert numbers to string with fixed precision. [#47838](https://github.com/ClickHouse/ClickHouse/pull/47838) ([Andrey Zvonov](https://github.com/zvonand)).
|
||||
* Added operator "REGEXP" (similar to operators "LIKE", "IN", "MOD" etc.) for better compatibility with MySQL. [#47869](https://github.com/ClickHouse/ClickHouse/pull/47869) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Allow executing reading pipeline for DIRECT dictionary with CLICKHOUSE source in multiple threads. To enable set `dictionary_use_async_executor=1` in `SETTINGS` section for source in `CREATE DICTIONARY` statement. [#47986](https://github.com/ClickHouse/ClickHouse/pull/47986) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Add merge tree setting `max_number_of_mutatuins_for_replica`. It limit the number of part mutations per replica to the specified amount. Zero means no limit on the number of mutations per replica (the execution can still be constrained by other settings). [#48047](https://github.com/ClickHouse/ClickHouse/pull/48047) ([Vladimir C](https://github.com/vdimir)).
|
||||
|
||||
#### Performance Improvement
|
||||
* Optimize one nullable key aggregate performance. [#45772](https://github.com/ClickHouse/ClickHouse/pull/45772) ([LiuNeng](https://github.com/liuneng1994)).
|
||||
* Implemented lowercase tokenbf_v1 index utilization for hasTokenOrNull, hasTokenCaseInsensitive and hasTokenCaseInsensitiveOrNull. [#46252](https://github.com/ClickHouse/ClickHouse/pull/46252) ([ltrk2](https://github.com/ltrk2)).
|
||||
* Optimize the generic SIMD StringSearcher by searching first two chars. [#46289](https://github.com/ClickHouse/ClickHouse/pull/46289) ([Jiebin Sun](https://github.com/jiebinn)).
|
||||
* System.detached_parts could be significant large. - added several sources with respects block size limitation - in each block iothread pool is used to calculate part size, ie to make syscalls in parallel. [#46624](https://github.com/ClickHouse/ClickHouse/pull/46624) ([Sema Checherinda](https://github.com/CheSema)).
|
||||
* Increase the default value of `max_replicated_merges_in_queue` for ReplicatedMergeTree tables from 16 to 1000. It allows faster background merge operation on clusters with a very large number of replicas, such as clusters with shared storage in ClickHouse Cloud. [#47050](https://github.com/ClickHouse/ClickHouse/pull/47050) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Backups for large numbers of files were unbelievably slow in previous versions. [#47251](https://github.com/ClickHouse/ClickHouse/pull/47251) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Support filter push down to left table for JOIN with StorageJoin, StorageDictionary, StorageEmbeddedRocksDB. [#47280](https://github.com/ClickHouse/ClickHouse/pull/47280) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* Marks in memory are now compressed, using 3-6x less memory. [#47290](https://github.com/ClickHouse/ClickHouse/pull/47290) ([Michael Kolupaev](https://github.com/al13n321)).
|
||||
* Updated copier to use group by instead of distinct to get list of partitions. For large tables this reduced the select time from over 500s to under 1s. [#47386](https://github.com/ClickHouse/ClickHouse/pull/47386) ([Clayton McClure](https://github.com/cmcclure-twilio)).
|
||||
* Address https://github.com/clickhouse/clickhouse/issues/46453. bisect marked https://github.com/clickhouse/clickhouse/pull/35525 as the bad changed. this pr looks to reverse the changes in that pr. [#47544](https://github.com/ClickHouse/ClickHouse/pull/47544) ([Ongkong](https://github.com/ongkong)).
|
||||
* Fixed excessive reading in queries with `FINAL`. [#47801](https://github.com/ClickHouse/ClickHouse/pull/47801) ([Nikita Taranov](https://github.com/nickitat)).
|
||||
* Setting `max_final_threads` would be set to number of cores at server startup (by the same algorithm as we use for `max_threads`). This improves concurrency of `final` execution on servers with high number of CPUs. [#47915](https://github.com/ClickHouse/ClickHouse/pull/47915) ([Nikita Taranov](https://github.com/nickitat)).
|
||||
* Avoid breaking batches on read requests to improve performance. [#47978](https://github.com/ClickHouse/ClickHouse/pull/47978) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
|
||||
#### Improvement
|
||||
* Add map related functions: mapFromArrays, which allows us to create map from a pair of arrays. [#31125](https://github.com/ClickHouse/ClickHouse/pull/31125) ([李扬](https://github.com/taiyang-li)).
|
||||
* Rewrite distributed sends to avoid using filesystem as a queue, use in-memory queue instead. [#45491](https://github.com/ClickHouse/ClickHouse/pull/45491) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Allow separate grants for named collections (e.g. to be able to give `SHOW/CREATE/ALTER/DROP named collection` access only to certain collections, instead of all at once). Closes [#40894](https://github.com/ClickHouse/ClickHouse/issues/40894). Add new access type `NAMED_COLLECTION_CONTROL` which is not given to default user unless explicitly added to user config (is required to be able to do `GRANT ALL`), also `show_named_collections` is no longer obligatory to be manually specified for default user to be able to have full access rights as was in 23.2. [#46241](https://github.com/ClickHouse/ClickHouse/pull/46241) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Now `X-ClickHouse-Query-Id` and `X-ClickHouse-Timezone` headers are added to response in all queries via http protocol. Previously it was done only for `SELECT` queries. [#46364](https://github.com/ClickHouse/ClickHouse/pull/46364) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Support for connection to a replica set via a URI with a host:port enum and support for the readPreference option in MongoDB dictionaries. Example URI: mongodb://db0.example.com:27017,db1.example.com:27017,db2.example.com:27017/?replicaSet=myRepl&readPreference=primary. [#46524](https://github.com/ClickHouse/ClickHouse/pull/46524) ([artem-yadr](https://github.com/artem-yadr)).
|
||||
* Re-implement projection analysis on top of query plan. Added setting `query_plan_optimize_projection=1` to switch between old and new version. Fixes [#44963](https://github.com/ClickHouse/ClickHouse/issues/44963). [#46537](https://github.com/ClickHouse/ClickHouse/pull/46537) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Use parquet format v2 instead of v1 in output format by default. Add setting `output_format_parquet_version` to control parquet version, possible values `v1_0`, `v2_4`, `v2_6`, `v2_latest` (default). [#46617](https://github.com/ClickHouse/ClickHouse/pull/46617) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Not for changelog - part of [#42648](https://github.com/ClickHouse/ClickHouse/issues/42648). [#46632](https://github.com/ClickHouse/ClickHouse/pull/46632) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Allow to ignore errors while pushing to MATERILIZED VIEW (add new setting `materialized_views_ignore_errors`, by default to `false`, but it is set to `true` for flushing logs to `system.*_log` tables unconditionally). [#46658](https://github.com/ClickHouse/ClickHouse/pull/46658) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Enable input_format_json_ignore_unknown_keys_in_named_tuple by default. [#46742](https://github.com/ClickHouse/ClickHouse/pull/46742) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* It is now possible using new configuration syntax to configure Kafka topics with periods in their name. [#46752](https://github.com/ClickHouse/ClickHouse/pull/46752) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix heuristics that check hyperscan patterns for problematic repeats. [#46819](https://github.com/ClickHouse/ClickHouse/pull/46819) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Don't report ZK node exists to system.errors when a block was created concurrently by a different replica. [#46820](https://github.com/ClickHouse/ClickHouse/pull/46820) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Allow PREWHERE for Merge with different DEFAULT expression for column. [#46831](https://github.com/ClickHouse/ClickHouse/pull/46831) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Increase the limit for opened files in `clickhouse-local`. It will be able to read from `web` tables on servers with a huge number of CPU cores. Do not back off reading from the URL table engine in case of too many opened files. This closes [#46852](https://github.com/ClickHouse/ClickHouse/issues/46852). [#46853](https://github.com/ClickHouse/ClickHouse/pull/46853) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Exceptions thrown when numbers cannot be parsed now have an easier-to-read exception message. [#46917](https://github.com/ClickHouse/ClickHouse/pull/46917) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Added update `system.backups` after every processed task. [#46989](https://github.com/ClickHouse/ClickHouse/pull/46989) ([Aleksandr Musorin](https://github.com/AVMusorin)).
|
||||
* Allow types conversion in Native input format. Add settings `input_format_native_allow_types_conversion` that controls it (enabled by default). [#46990](https://github.com/ClickHouse/ClickHouse/pull/46990) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Allow IPv4 in the `range` function to generate IP ranges. [#46995](https://github.com/ClickHouse/ClickHouse/pull/46995) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Role change was not promoted sometimes before https://github.com/ClickHouse/ClickHouse/pull/46772 This PR just adds tests. [#47002](https://github.com/ClickHouse/ClickHouse/pull/47002) ([Ilya Golshtein](https://github.com/ilejn)).
|
||||
* Improve exception message when it's impossible to make part move from one volume/disk to another. [#47032](https://github.com/ClickHouse/ClickHouse/pull/47032) ([alesapin](https://github.com/alesapin)).
|
||||
* Support `Bool` type in `JSONType` function. Previously `Null` type was mistakenly returned for bool values. [#47046](https://github.com/ClickHouse/ClickHouse/pull/47046) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Use _request_body parameter to configure predefined http queries. [#47086](https://github.com/ClickHouse/ClickHouse/pull/47086) ([Constantine Peresypkin](https://github.com/pkit)).
|
||||
* Removing logging of custom disk structure. [#47103](https://github.com/ClickHouse/ClickHouse/pull/47103) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Allow nested custom disks. Previously custom disks supported only flat disk structure. [#47106](https://github.com/ClickHouse/ClickHouse/pull/47106) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Automatic indentation in the built-in UI SQL editor when Enter is pressed. [#47113](https://github.com/ClickHouse/ClickHouse/pull/47113) ([Alexey Korepanov](https://github.com/alexkorep)).
|
||||
* Allow control compression in Parquet/ORC/Arrow output formats, support more compression for input formats. This closes [#13541](https://github.com/ClickHouse/ClickHouse/issues/13541). [#47114](https://github.com/ClickHouse/ClickHouse/pull/47114) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Self-extraction with 'sudo' will attempt to set uid and gid of extracted files to running user. [#47116](https://github.com/ClickHouse/ClickHouse/pull/47116) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Currently the funtion repeat's second argument must be unsigned integer type, which can not accept a integer value like -1. And this is different from the spark function, so I fix this here to make it same as spark. And it tested as below. [#47134](https://github.com/ClickHouse/ClickHouse/pull/47134) ([KevinyhZou](https://github.com/KevinyhZou)).
|
||||
* Remove `::__1` part from stacktraces. Display `std::basic_string<char, ...` as `String` in stacktraces. [#47171](https://github.com/ClickHouse/ClickHouse/pull/47171) ([Mike Kot](https://github.com/myrrc)).
|
||||
* Introduced a separate thread pool for backup IO operations. This will allow to scale it independently from other pool and increase performance. [#47174](https://github.com/ClickHouse/ClickHouse/pull/47174) ([Nikita Mikhaylov](https://github.com/nikitamikhaylov)).
|
||||
* Reimplement interserver mode to avoid replay attacks (note, that change is backward compatible with older servers). [#47213](https://github.com/ClickHouse/ClickHouse/pull/47213) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Make function `optimizeregularexpression` recognize re groups and refine regexp tree dictionary. [#47218](https://github.com/ClickHouse/ClickHouse/pull/47218) ([Han Fei](https://github.com/hanfei1991)).
|
||||
* Use MultiRead request and retries for collecting metadata at final stage of backup processing. [#47243](https://github.com/ClickHouse/ClickHouse/pull/47243) ([Nikita Mikhaylov](https://github.com/nikitamikhaylov)).
|
||||
* Keeper improvement: Add new 4LW `clrs` to clean resources used by Keeper (e.g. release unused memory). [#47256](https://github.com/ClickHouse/ClickHouse/pull/47256) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Add optional arguments to codecs `DoubleDelta(bytes_size)`, `Gorilla(bytes_size)`, `FPC(level, float_size)`, it will allow using this codecs without column type in `clickhouse-compressor`. Fix possible abrots and arithmetic errors in `clickhouse-compressor` with these codecs. Fixes: https://github.com/ClickHouse/ClickHouse/discussions/47262. [#47271](https://github.com/ClickHouse/ClickHouse/pull/47271) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Add support for big int types to runningDifference() function. Closes [#47194](https://github.com/ClickHouse/ClickHouse/issues/47194). [#47322](https://github.com/ClickHouse/ClickHouse/pull/47322) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* PostgreSQL replication has been adjusted to use "FROM ONLY" clause while performing initial synchronization. This prevents double-fetching the same data in case the target PostgreSQL database uses table inheritance. [#47387](https://github.com/ClickHouse/ClickHouse/pull/47387) ([Maksym Sobolyev](https://github.com/sobomax)).
|
||||
* Add an expiration window for S3 credentials that have an expiration time to avoid `ExpiredToken` errors in some edge cases. It can be controlled with `expiration_window_seconds` config, the default is 120 seconds. [#47423](https://github.com/ClickHouse/ClickHouse/pull/47423) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Support Decimals and Date32 in Avro format. [#47434](https://github.com/ClickHouse/ClickHouse/pull/47434) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Do not start the server if an interrupted conversion from `Ordinary` to `Atomic` was detected, print a better error message with troubleshooting instructions. [#47487](https://github.com/ClickHouse/ClickHouse/pull/47487) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Add a new column `kind` to system.opentelemetry_span_log. This column holds the value of [SpanKind](https://opentelemetry.io/docs/reference/specification/trace/api/#spankind) defined in OpenTelemtry. [#47499](https://github.com/ClickHouse/ClickHouse/pull/47499) ([Frank Chen](https://github.com/FrankChen021)).
|
||||
* If a backup and restoring data are both in S3 then server-side copy should be used from now on. [#47546](https://github.com/ClickHouse/ClickHouse/pull/47546) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Add SSL User Certificate authentication to the native protocol. Closes [#47077](https://github.com/ClickHouse/ClickHouse/issues/47077). [#47596](https://github.com/ClickHouse/ClickHouse/pull/47596) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Allow reading/writing nested arrays in Protobuf with only root field name as column name. Previously column name should've contain all nested field names (like `a.b.c Array(Array(Array(UInt32)))`, now you can use just `a Array(Array(Array(UInt32)))`. [#47650](https://github.com/ClickHouse/ClickHouse/pull/47650) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Added an optional `STRICT` modifier for `SYSTEM SYNC REPLICA` which makes the query wait for replication queue to become empty (just like it worked before https://github.com/ClickHouse/ClickHouse/pull/45648). [#47659](https://github.com/ClickHouse/ClickHouse/pull/47659) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Improvement name of some span logs. [#47667](https://github.com/ClickHouse/ClickHouse/pull/47667) ([Frank Chen](https://github.com/FrankChen021)).
|
||||
* Now ReplicatedMergeTree with zero copy replication has less load to ZooKeeper. [#47676](https://github.com/ClickHouse/ClickHouse/pull/47676) ([alesapin](https://github.com/alesapin)).
|
||||
* Prevent using too long chains of aggregate function combinators (they can lead to slow queries in the analysis stage). This closes [#47715](https://github.com/ClickHouse/ClickHouse/issues/47715). [#47716](https://github.com/ClickHouse/ClickHouse/pull/47716) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Support for subquery in parameterized views resolves [#46741](https://github.com/ClickHouse/ClickHouse/issues/46741) Implementation: * Updated to pass the parameter is_create_parameterized_view to subquery processing. Testing: * Added test case with subquery for parameterized view. [#47725](https://github.com/ClickHouse/ClickHouse/pull/47725) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Fix memory leak in MySQL integration (reproduces with `connection_auto_close=1`). [#47732](https://github.com/ClickHouse/ClickHouse/pull/47732) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* AST Fuzzer support fuzz `EXPLAIN` query. [#47803](https://github.com/ClickHouse/ClickHouse/pull/47803) ([flynn](https://github.com/ucasfl)).
|
||||
* Fixed error print message while Decimal parameters is incorrect. [#47812](https://github.com/ClickHouse/ClickHouse/pull/47812) ([Yu Feng](https://github.com/Vigor-jpg)).
|
||||
* Add `X-ClickHouse-Query-Id` to HTTP response when queries fails to execute. [#47813](https://github.com/ClickHouse/ClickHouse/pull/47813) ([Frank Chen](https://github.com/FrankChen021)).
|
||||
* AST fuzzer support fuzzing `SELECT` query to `EXPLAIN` query randomly. [#47852](https://github.com/ClickHouse/ClickHouse/pull/47852) ([flynn](https://github.com/ucasfl)).
|
||||
* Improved the overall performance by better utilizing local replica. And forbid reading with parallel replicas from non-replicated MergeTree by default. [#47858](https://github.com/ClickHouse/ClickHouse/pull/47858) ([Nikita Mikhaylov](https://github.com/nikitamikhaylov)).
|
||||
* More accurate CPU usage indication for client: account for usage in some long-living server threads (Segmentator) and do regular CPU accounting for every thread. [#47870](https://github.com/ClickHouse/ClickHouse/pull/47870) ([Sergei Trifonov](https://github.com/serxa)).
|
||||
* The parameter `exact_rows_before_limit` is used to make `rows_before_limit_at_least` is designed to accurately reflect the number of rows returned before the limit is reached. This pull request addresses issues encountered when the query involves distributed processing across multiple shards or sorting operations. Prior to this update, these scenarios were not functioning as intended. [#47874](https://github.com/ClickHouse/ClickHouse/pull/47874) ([Amos Bird](https://github.com/amosbird)).
|
||||
* ThreadPool metrics introspection. [#47880](https://github.com/ClickHouse/ClickHouse/pull/47880) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Add `WriteBufferFromS3Microseconds` and `WriteBufferFromS3RequestsErrors` profile events. [#47885](https://github.com/ClickHouse/ClickHouse/pull/47885) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Add `--link` and `--noninteractive` (`-y`) options to clickhouse install. Closes [#47750](https://github.com/ClickHouse/ClickHouse/issues/47750). [#47887](https://github.com/ClickHouse/ClickHouse/pull/47887) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Fix decimal-256 text output issue on s390x. [#47932](https://github.com/ClickHouse/ClickHouse/pull/47932) ([MeenaRenganathan22](https://github.com/MeenaRenganathan22)).
|
||||
* Fixed `UNKNOWN_TABLE` exception when attaching to a materialized view that has dependent tables that are not available. This might be useful when trying to restore state from a backup. [#47975](https://github.com/ClickHouse/ClickHouse/pull/47975) ([MikhailBurdukov](https://github.com/MikhailBurdukov)).
|
||||
* Fix case when (optional) path is not added to encrypted disk configuration. [#47981](https://github.com/ClickHouse/ClickHouse/pull/47981) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Add *OrNull() and *OrZero() variants for parseDateTime(), add alias "str_to_date" for MySQL parity. [#48000](https://github.com/ClickHouse/ClickHouse/pull/48000) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Improve the code around `background_..._pool_size` settings reading. It should be configured via the main server configuration file. [#48055](https://github.com/ClickHouse/ClickHouse/pull/48055) ([filimonov](https://github.com/filimonov)).
|
||||
* Support for cte in parameterized views Implementation: * Updated to allow query parameters while evaluating scalar subqueries. Testing: * Added test case with cte for parameterized view. [#48065](https://github.com/ClickHouse/ClickHouse/pull/48065) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Add `NOSIGN` keyword for S3 table function and storage engine to avoid signing requests with provided credentials. Add `no_sign_request` config for all functionalities using S3. [#48092](https://github.com/ClickHouse/ClickHouse/pull/48092) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Support bin integers `(U)Int128/(U)Int256`, `Map` with any key type and `DateTime64` with any precision (not only 3 and 6). [#48119](https://github.com/ClickHouse/ClickHouse/pull/48119) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Support more ClickHouse types in MsgPack format: (U)Int128/(U)Int256, Enum8(16), Date32, Decimal(32|64|128|256), Tuples. [#48124](https://github.com/ClickHouse/ClickHouse/pull/48124) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* The output of some SHOW ... statements is now sorted. [#48127](https://github.com/ClickHouse/ClickHouse/pull/48127) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Allow skipping errors related to unknown enum values in row input formats. [#48133](https://github.com/ClickHouse/ClickHouse/pull/48133) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Add `allow_distributed_ddl_queries` option to disallow distributed DDL queries for the cluster in the config. [#48171](https://github.com/ClickHouse/ClickHouse/pull/48171) ([Aleksei Filatov](https://github.com/aalexfvk)).
|
||||
* Determine the hosts' order in `SHOW CLUSTER` query, a followup for [#48127](https://github.com/ClickHouse/ClickHouse/issues/48127) and [#46240](https://github.com/ClickHouse/ClickHouse/issues/46240). [#48235](https://github.com/ClickHouse/ClickHouse/pull/48235) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
|
||||
#### Build/Testing/Packaging Improvement
|
||||
* Split stress test and backward compatibility check (now Upgrade check). [#44879](https://github.com/ClickHouse/ClickHouse/pull/44879) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Use sccache as a replacement for ccache and using S3 as cache backend. [#46240](https://github.com/ClickHouse/ClickHouse/pull/46240) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Updated Ubuntu Image. [#46784](https://github.com/ClickHouse/ClickHouse/pull/46784) ([Julio Jimenez](https://github.com/juliojimenez)).
|
||||
* Adds a prompt to allow the removal of an existing `cickhouse` download when using "curl | sh" download of ClickHouse. Prompt is "ClickHouse binary clickhouse already exists. Overwrite? [y/N] ". [#46859](https://github.com/ClickHouse/ClickHouse/pull/46859) ([Dan Roscigno](https://github.com/DanRoscigno)).
|
||||
* Fix error during server startup on old distros (e.g. Amazon Linux 2) and on ARM that glibc 2.28 symbols are not found. [#47008](https://github.com/ClickHouse/ClickHouse/pull/47008) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Clang 16 is set to release in the next few days, making it an opportune time to update. [#47027](https://github.com/ClickHouse/ClickHouse/pull/47027) ([Amos Bird](https://github.com/amosbird)).
|
||||
* Added a CI check which ensures ClickHouse can run with an old glibc on ARM. [#47063](https://github.com/ClickHouse/ClickHouse/pull/47063) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* ClickHouse now builds with C++23. [#47424](https://github.com/ClickHouse/ClickHouse/pull/47424) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fixed issue with starting `clickhouse-test` against custom clickhouse binary with `-b`. ... [#47578](https://github.com/ClickHouse/ClickHouse/pull/47578) ([Vasily Nemkov](https://github.com/Enmk)).
|
||||
* Add a style check to prevent incorrect usage of the `NDEBUG` macro. [#47699](https://github.com/ClickHouse/ClickHouse/pull/47699) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Speed up the build a little. [#47714](https://github.com/ClickHouse/ClickHouse/pull/47714) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Bump vectorscan to 5.4.9. [#47955](https://github.com/ClickHouse/ClickHouse/pull/47955) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Add a unit test to assert arrow fatal logging does not abort. It covers the changes in https://github.com/ClickHouse/arrow/pull/16. [#47958](https://github.com/ClickHouse/ClickHouse/pull/47958) ([Arthur Passos](https://github.com/arthurpassos)).
|
||||
* Restore ability of native macos debug server build to start (this time for real). [#48050](https://github.com/ClickHouse/ClickHouse/pull/48050) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Functional tests will trigger JIT compilation more frequently, in a randomized fashion. See [#48120](https://github.com/ClickHouse/ClickHouse/issues/48120). [#48196](https://github.com/ClickHouse/ClickHouse/pull/48196) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* The `clickhouse/clickhouse-keeper` image used to be pushed only with tags `-alpine`, e.g. `latest-alpine`. As it was suggested in https://github.com/ClickHouse/examples/pull/2, now it will be pushed as suffixless too. [#48236](https://github.com/ClickHouse/ClickHouse/pull/48236) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
|
||||
#### Bug Fix (user-visible misbehavior in an official stable release)
|
||||
|
||||
* Fix create materialized view with MaterializedPostgreSQL [#40807](https://github.com/ClickHouse/ClickHouse/pull/40807) ([Maksim Buren](https://github.com/maks-buren630501)).
|
||||
* Fix formats parser resetting, test processing bad messages in kafka [#45693](https://github.com/ClickHouse/ClickHouse/pull/45693) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix several `RENAME COLUMN` bugs. [#45911](https://github.com/ClickHouse/ClickHouse/pull/45911) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix data size calculation in Keeper [#46086](https://github.com/ClickHouse/ClickHouse/pull/46086) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fixes for 993 [#46384](https://github.com/ClickHouse/ClickHouse/pull/46384) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix incorrect alias recursion in QueryNormalizer [#46609](https://github.com/ClickHouse/ClickHouse/pull/46609) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Fix IPv4/IPv6 serialization/deserialization in binary formats [#46616](https://github.com/ClickHouse/ClickHouse/pull/46616) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* ActionsDAG: do not change result of and() during optimization [#46653](https://github.com/ClickHouse/ClickHouse/pull/46653) ([Salvatore Mesoraca](https://github.com/aiven-sal)).
|
||||
* Fix queries cancellation when a client dies [#46681](https://github.com/ClickHouse/ClickHouse/pull/46681) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix arithmetic operations in aggregate optimization [#46705](https://github.com/ClickHouse/ClickHouse/pull/46705) ([Duc Canh Le](https://github.com/canhld94)).
|
||||
* Fix possible clickhouse-local abort on JSONEachRow schema inference [#46731](https://github.com/ClickHouse/ClickHouse/pull/46731) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix changing an expired role [#46772](https://github.com/ClickHouse/ClickHouse/pull/46772) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Fix combined PREWHERE column accumulated from multiple steps [#46785](https://github.com/ClickHouse/ClickHouse/pull/46785) ([Alexander Gololobov](https://github.com/davenger)).
|
||||
* Use initial range for fetching file size in HTTP read buffer [#46824](https://github.com/ClickHouse/ClickHouse/pull/46824) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix progress bar with URL [#46830](https://github.com/ClickHouse/ClickHouse/pull/46830) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Do not allow const and non-deterministic secondary indexes [#46839](https://github.com/ClickHouse/ClickHouse/pull/46839) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Fix MSan report in `maxIntersections` function [#46847](https://github.com/ClickHouse/ClickHouse/pull/46847) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix a bug in `Map` data type [#46856](https://github.com/ClickHouse/ClickHouse/pull/46856) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix wrong results of some LIKE searches when the LIKE pattern contains quoted non-quotable characters [#46875](https://github.com/ClickHouse/ClickHouse/pull/46875) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix - WITH FILL would produce abort when FillingTransform processing empty block [#46897](https://github.com/ClickHouse/ClickHouse/pull/46897) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Fix date and int inference from string in JSON [#46972](https://github.com/ClickHouse/ClickHouse/pull/46972) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix bug in zero-copy replication disk choice during fetch [#47010](https://github.com/ClickHouse/ClickHouse/pull/47010) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix typo in systemd service definition [#47051](https://github.com/ClickHouse/ClickHouse/pull/47051) ([Palash Goel](https://github.com/palash-goel)).
|
||||
* Fix NOT_IMPLEMENTED error with CROSS JOIN and algorithm = auto [#47068](https://github.com/ClickHouse/ClickHouse/pull/47068) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix the problem that the 'ReplicatedMergeTree' table failed to insert two similar data when the 'part_type' is configured as 'InMemory' mode. [#47121](https://github.com/ClickHouse/ClickHouse/pull/47121) ([liding1992](https://github.com/liding1992)).
|
||||
* External dictionaries / library-bridge: Fix error "unknown library method 'extDict_libClone'" [#47136](https://github.com/ClickHouse/ClickHouse/pull/47136) ([alex filatov](https://github.com/phil-88)).
|
||||
* Fix race in grace hash join with limit [#47153](https://github.com/ClickHouse/ClickHouse/pull/47153) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix concrete columns PREWHERE support [#47154](https://github.com/ClickHouse/ClickHouse/pull/47154) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix possible deadlock in QueryStatus [#47161](https://github.com/ClickHouse/ClickHouse/pull/47161) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Backup_Restore_concurrency_check_node [#47216](https://github.com/ClickHouse/ClickHouse/pull/47216) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Forbid insert select for the same StorageJoin [#47260](https://github.com/ClickHouse/ClickHouse/pull/47260) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Skip merged partitions for `min_age_to_force_merge_seconds` merges [#47303](https://github.com/ClickHouse/ClickHouse/pull/47303) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Modify find_first_symbols so it works as expected for find_first_not_symbols [#47304](https://github.com/ClickHouse/ClickHouse/pull/47304) ([Arthur Passos](https://github.com/arthurpassos)).
|
||||
* Fix big numbers inference in CSV [#47410](https://github.com/ClickHouse/ClickHouse/pull/47410) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Disable logical expression optimizer for expression with aliases. [#47451](https://github.com/ClickHouse/ClickHouse/pull/47451) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Remove a feature [#47456](https://github.com/ClickHouse/ClickHouse/pull/47456) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix error in `decodeURLComponent` [#47457](https://github.com/ClickHouse/ClickHouse/pull/47457) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix explain graph with projection [#47473](https://github.com/ClickHouse/ClickHouse/pull/47473) ([flynn](https://github.com/ucasfl)).
|
||||
* Fix query parameters [#47488](https://github.com/ClickHouse/ClickHouse/pull/47488) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Parameterized view bug fix 47287 47247 [#47495](https://github.com/ClickHouse/ClickHouse/pull/47495) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Fuzzer of data formats [#47519](https://github.com/ClickHouse/ClickHouse/pull/47519) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix monotonicity check for DateTime64 [#47526](https://github.com/ClickHouse/ClickHouse/pull/47526) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix block structure mismatch for nullable LowCardinality column [#47537](https://github.com/ClickHouse/ClickHouse/pull/47537) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Proper fix for bug in parquet, revert reverted [#45878](https://github.com/ClickHouse/ClickHouse/issues/45878) [#47538](https://github.com/ClickHouse/ClickHouse/pull/47538) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix BSONEachRow parallel parsing when document size is invalid [#47540](https://github.com/ClickHouse/ClickHouse/pull/47540) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Preserve error in system.distribution_queue on SYSTEM FLUSH DISTRIBUTED [#47541](https://github.com/ClickHouse/ClickHouse/pull/47541) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Revert "Revert "Backup_Restore_concurrency_check_node"" [#47586](https://github.com/ClickHouse/ClickHouse/pull/47586) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Check for duplicate column in BSONEachRow format [#47609](https://github.com/ClickHouse/ClickHouse/pull/47609) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix wait for zero copy lock during move [#47631](https://github.com/ClickHouse/ClickHouse/pull/47631) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix aggregation by partitions [#47634](https://github.com/ClickHouse/ClickHouse/pull/47634) ([Nikita Taranov](https://github.com/nickitat)).
|
||||
* Fix bug in tuple as array serialization in BSONEachRow format [#47690](https://github.com/ClickHouse/ClickHouse/pull/47690) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix crash in polygonsSymDifferenceCartesian [#47702](https://github.com/ClickHouse/ClickHouse/pull/47702) ([pufit](https://github.com/pufit)).
|
||||
* Fix reading from storage `File` compressed files with `zlib` and `gzip` compression [#47796](https://github.com/ClickHouse/ClickHouse/pull/47796) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Improve empty query detection for PostgreSQL (for pgx golang driver) [#47854](https://github.com/ClickHouse/ClickHouse/pull/47854) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix DateTime monotonicity check for LowCardinality [#47860](https://github.com/ClickHouse/ClickHouse/pull/47860) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Use restore_threads (not backup_threads) for RESTORE ASYNC [#47861](https://github.com/ClickHouse/ClickHouse/pull/47861) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix DROP COLUMN with ReplicatedMergeTree containing projections [#47883](https://github.com/ClickHouse/ClickHouse/pull/47883) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix for Replicated database recovery [#47901](https://github.com/ClickHouse/ClickHouse/pull/47901) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Hotfix for too verbose warnings in HTTP [#47903](https://github.com/ClickHouse/ClickHouse/pull/47903) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix "Field value too long" in catboostEvaluate() [#47970](https://github.com/ClickHouse/ClickHouse/pull/47970) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix [#36971](https://github.com/ClickHouse/ClickHouse/issues/36971): Watchdog: exit with non-zero code if child process exits [#47973](https://github.com/ClickHouse/ClickHouse/pull/47973) ([Коренберг Марк](https://github.com/socketpair)).
|
||||
* Fix for index file cidx is unexpectedly long [#48010](https://github.com/ClickHouse/ClickHouse/pull/48010) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* fix MaterializedPostgreSQL query to get attributes (replica-identity) [#48015](https://github.com/ClickHouse/ClickHouse/pull/48015) ([Solomatov Sergei](https://github.com/solomatovs)).
|
||||
* parseDateTime(): Fix UB (signed integer overflow) [#48019](https://github.com/ClickHouse/ClickHouse/pull/48019) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Use uniq names for Records in Avro to avoid reusing its schema [#48057](https://github.com/ClickHouse/ClickHouse/pull/48057) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Fix crash in explain graph with StorageMerge [#48102](https://github.com/ClickHouse/ClickHouse/pull/48102) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Correctly set TCP/HTTP socket timeouts in Keeper [#48108](https://github.com/ClickHouse/ClickHouse/pull/48108) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix possible member call on null pointer in Avro format [#48184](https://github.com/ClickHouse/ClickHouse/pull/48184) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
|
||||
#### Build Improvement
|
||||
|
||||
* Update krb5 to 1.20.1-final to mitigate CVE-2022-42898. [#46485](https://github.com/ClickHouse/ClickHouse/pull/46485) ([MeenaRenganathan22](https://github.com/MeenaRenganathan22)).
|
||||
* Fixed random crash issues caused by bad pointers in libunwind for s390x. [#46755](https://github.com/ClickHouse/ClickHouse/pull/46755) ([Harry Lee](https://github.com/HarryLeeIBM)).
|
||||
* Fixed http xz compression issue for s390x. [#46832](https://github.com/ClickHouse/ClickHouse/pull/46832) ([Harry Lee](https://github.com/HarryLeeIBM)).
|
||||
* Fixed murmurhash function for s390x. [#47036](https://github.com/ClickHouse/ClickHouse/pull/47036) ([Harry Lee](https://github.com/HarryLeeIBM)).
|
||||
* Fixed halfMD5 and broken cityHash function for s390x. [#47115](https://github.com/ClickHouse/ClickHouse/pull/47115) ([Harry Lee](https://github.com/HarryLeeIBM)).
|
||||
* Fixed farmhash functions for s390x. [#47223](https://github.com/ClickHouse/ClickHouse/pull/47223) ([Harry Lee](https://github.com/HarryLeeIBM)).
|
||||
* Fixed endian issue in hashing tuples for s390x. [#47371](https://github.com/ClickHouse/ClickHouse/pull/47371) ([Harry Lee](https://github.com/HarryLeeIBM)).
|
||||
* Fixed SipHash integer hashing issue and byte order issue in random integer data from GenerateRandom storage engine for s390x. [#47576](https://github.com/ClickHouse/ClickHouse/pull/47576) ([Harry Lee](https://github.com/HarryLeeIBM)).
|
||||
|
||||
#### NO CL ENTRY
|
||||
|
||||
* NO CL ENTRY: 'Revert "Fix several `RENAME COLUMN` bugs."'. [#46909](https://github.com/ClickHouse/ClickHouse/pull/46909) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* NO CL ENTRY: 'Revert "Add join_algorithm='grace_hash' to stress tests"'. [#46988](https://github.com/ClickHouse/ClickHouse/pull/46988) ([Pradeep Chhetri](https://github.com/chhetripradeep)).
|
||||
* NO CL ENTRY: 'Revert "Give users option of overwriting"'. [#47169](https://github.com/ClickHouse/ClickHouse/pull/47169) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* NO CL ENTRY: 'Revert "standardize admonitions"'. [#47413](https://github.com/ClickHouse/ClickHouse/pull/47413) ([Rich Raposa](https://github.com/rfraposa)).
|
||||
* NO CL ENTRY: 'Revert "Backup_Restore_concurrency_check_node"'. [#47581](https://github.com/ClickHouse/ClickHouse/pull/47581) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* NO CL ENTRY: 'Update storing-data.md'. [#47598](https://github.com/ClickHouse/ClickHouse/pull/47598) ([San](https://github.com/santrancisco)).
|
||||
* NO CL ENTRY: 'Revert "Fix BSONEachRow parallel parsing when document size is invalid"'. [#47672](https://github.com/ClickHouse/ClickHouse/pull/47672) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* NO CL ENTRY: 'Revert "New navigation"'. [#47694](https://github.com/ClickHouse/ClickHouse/pull/47694) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* NO CL ENTRY: 'Revert "Analyzer planner fixes before enable by default"'. [#47721](https://github.com/ClickHouse/ClickHouse/pull/47721) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* NO CL ENTRY: 'Revert "Revert "Analyzer planner fixes before enable by default""'. [#47748](https://github.com/ClickHouse/ClickHouse/pull/47748) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* NO CL ENTRY: 'Revert "Add sanity checks for writing number in variable length format"'. [#47850](https://github.com/ClickHouse/ClickHouse/pull/47850) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* NO CL ENTRY: 'Revert "Revert "Revert "Backup_Restore_concurrency_check_node"""'. [#47963](https://github.com/ClickHouse/ClickHouse/pull/47963) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
|
||||
#### NOT FOR CHANGELOG / INSIGNIFICANT
|
||||
|
||||
* Test differences between using materialize_ttl_recalculate_only=1/0 [#45304](https://github.com/ClickHouse/ClickHouse/pull/45304) ([Jordi Villar](https://github.com/jrdi)).
|
||||
* Fix query in stress script [#45480](https://github.com/ClickHouse/ClickHouse/pull/45480) ([Pradeep Chhetri](https://github.com/chhetripradeep)).
|
||||
* Add join_algorithm='grace_hash' to stress tests [#45607](https://github.com/ClickHouse/ClickHouse/pull/45607) ([Pradeep Chhetri](https://github.com/chhetripradeep)).
|
||||
* Support `group_by_use_nulls` setting in new analyzer [#45910](https://github.com/ClickHouse/ClickHouse/pull/45910) ([Dmitry Novik](https://github.com/novikd)).
|
||||
* Randomize setting `ratio_of_defaults_for_sparse_serialization` [#46118](https://github.com/ClickHouse/ClickHouse/pull/46118) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Add CrossToInnerJoinPass [#46408](https://github.com/ClickHouse/ClickHouse/pull/46408) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix flakiness of test_backup_restore_on_cluster/test_disallow_concurrency [#46517](https://github.com/ClickHouse/ClickHouse/pull/46517) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Map field to string fix [#46618](https://github.com/ClickHouse/ClickHouse/pull/46618) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* Enable perf tests added in [#45364](https://github.com/ClickHouse/ClickHouse/issues/45364) [#46623](https://github.com/ClickHouse/ClickHouse/pull/46623) ([Nikita Taranov](https://github.com/nickitat)).
|
||||
* Logical expression optimizer in new analyzer [#46644](https://github.com/ClickHouse/ClickHouse/pull/46644) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Named collections: finish replacing old code for storages [#46647](https://github.com/ClickHouse/ClickHouse/pull/46647) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Make tiny improvements [#46659](https://github.com/ClickHouse/ClickHouse/pull/46659) ([ltrk2](https://github.com/ltrk2)).
|
||||
* Fix openssl/s390x build (setenv + link order) [#46684](https://github.com/ClickHouse/ClickHouse/pull/46684) ([Boris Kuschel](https://github.com/bkuschel)).
|
||||
* Analyzer AutoFinalOnQueryPass fix [#46729](https://github.com/ClickHouse/ClickHouse/pull/46729) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* Mark failed build reports as pending on reruns [#46736](https://github.com/ClickHouse/ClickHouse/pull/46736) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Do not reanalyze expressions from aggregation in projection [#46738](https://github.com/ClickHouse/ClickHouse/pull/46738) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Update CHANGELOG.md [#46766](https://github.com/ClickHouse/ClickHouse/pull/46766) ([Ilya Yatsishin](https://github.com/qoega)).
|
||||
* Poco: Remove some dead code [#46768](https://github.com/ClickHouse/ClickHouse/pull/46768) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* More concise logging at trace level for PREWHERE steps [#46771](https://github.com/ClickHouse/ClickHouse/pull/46771) ([Alexander Gololobov](https://github.com/davenger)).
|
||||
* Follow-up to [#41534](https://github.com/ClickHouse/ClickHouse/issues/41534) [#46775](https://github.com/ClickHouse/ClickHouse/pull/46775) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix timeout for all expect tests (wrong usage of expect_after timeout) [#46779](https://github.com/ClickHouse/ClickHouse/pull/46779) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Reduce updates of Mergeable Check [#46781](https://github.com/ClickHouse/ClickHouse/pull/46781) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Updated Slack invite link [#46783](https://github.com/ClickHouse/ClickHouse/pull/46783) ([clickhouse-adrianfraguela](https://github.com/clickhouse-adrianfraguela)).
|
||||
* Print all stacktraces in hung check [#46787](https://github.com/ClickHouse/ClickHouse/pull/46787) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Quick temporary fix for stress tests [#46789](https://github.com/ClickHouse/ClickHouse/pull/46789) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Update version after release [#46792](https://github.com/ClickHouse/ClickHouse/pull/46792) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Update version_date.tsv and changelogs after v23.2.1.2537-stable [#46794](https://github.com/ClickHouse/ClickHouse/pull/46794) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Remove ZSTD version from CMake output [#46796](https://github.com/ClickHouse/ClickHouse/pull/46796) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Update version_date.tsv and changelogs after v22.11.6.44-stable [#46801](https://github.com/ClickHouse/ClickHouse/pull/46801) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* CMake: Add best effort checks that the build machine isn't too old [#46803](https://github.com/ClickHouse/ClickHouse/pull/46803) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix async reading pipeline when small limit is present [#46804](https://github.com/ClickHouse/ClickHouse/pull/46804) ([Nikita Taranov](https://github.com/nickitat)).
|
||||
* Cleanup string search code [#46814](https://github.com/ClickHouse/ClickHouse/pull/46814) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Stateless cmake version [#46821](https://github.com/ClickHouse/ClickHouse/pull/46821) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* refine regexp tree dictionary [#46822](https://github.com/ClickHouse/ClickHouse/pull/46822) ([Han Fei](https://github.com/hanfei1991)).
|
||||
* Non-significant change [#46844](https://github.com/ClickHouse/ClickHouse/pull/46844) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Add a trap [#46845](https://github.com/ClickHouse/ClickHouse/pull/46845) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Better handling of fatal errors [#46846](https://github.com/ClickHouse/ClickHouse/pull/46846) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Add a test for [#43184](https://github.com/ClickHouse/ClickHouse/issues/43184) [#46848](https://github.com/ClickHouse/ClickHouse/pull/46848) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix wrong function name [#46849](https://github.com/ClickHouse/ClickHouse/pull/46849) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Add a test for [#45214](https://github.com/ClickHouse/ClickHouse/issues/45214) [#46850](https://github.com/ClickHouse/ClickHouse/pull/46850) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Final fixes for expect tests [#46857](https://github.com/ClickHouse/ClickHouse/pull/46857) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Small optimization of LIKE patterns with > 1 trailing % [#46869](https://github.com/ClickHouse/ClickHouse/pull/46869) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Add new metrics to system.asynchronous_metrics [#46886](https://github.com/ClickHouse/ClickHouse/pull/46886) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix flaky `test_concurrent_queries_restriction_by_query_kind` [#46887](https://github.com/ClickHouse/ClickHouse/pull/46887) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix test test_async_backups_to_same_destination. [#46888](https://github.com/ClickHouse/ClickHouse/pull/46888) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Make ASTSelectQuery::formatImpl() more robust [#46889](https://github.com/ClickHouse/ClickHouse/pull/46889) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* tests: fix 02116_interactive_hello for "official build" [#46911](https://github.com/ClickHouse/ClickHouse/pull/46911) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix some expect tests leftovers and enable them in fasttest [#46915](https://github.com/ClickHouse/ClickHouse/pull/46915) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Increase ddl timeout for DROP statement in backup restore tests [#46920](https://github.com/ClickHouse/ClickHouse/pull/46920) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* A better alternative to [#46344](https://github.com/ClickHouse/ClickHouse/issues/46344) [#46921](https://github.com/ClickHouse/ClickHouse/pull/46921) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Code review from @tavplubix [#46922](https://github.com/ClickHouse/ClickHouse/pull/46922) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Planner: trivial count optimization [#46923](https://github.com/ClickHouse/ClickHouse/pull/46923) ([Igor Nikonov](https://github.com/devcrafter)).
|
||||
* Typo: SIZES_OF_ARRAYS_DOESNT_MATCH --> SIZES_OF_ARRAYS_DONT_MATCH [#46940](https://github.com/ClickHouse/ClickHouse/pull/46940) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Another fix for clone() for ASTColumnMatchers [#46947](https://github.com/ClickHouse/ClickHouse/pull/46947) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Un-inline likePatternToRegexp() [#46950](https://github.com/ClickHouse/ClickHouse/pull/46950) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix missing format_description [#46959](https://github.com/ClickHouse/ClickHouse/pull/46959) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* ARM: Activate LDAPR with -march flag instead via -XClang [#46960](https://github.com/ClickHouse/ClickHouse/pull/46960) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Preset description on the tweak reset [#46963](https://github.com/ClickHouse/ClickHouse/pull/46963) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Update version_date.tsv and changelogs after v22.3.19.6-lts [#46964](https://github.com/ClickHouse/ClickHouse/pull/46964) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Update version_date.tsv and changelogs after v22.8.14.53-lts [#46969](https://github.com/ClickHouse/ClickHouse/pull/46969) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Better exception messages when schema_inference_hints is ill-formatted [#46971](https://github.com/ClickHouse/ClickHouse/pull/46971) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Decrease log level in "disks" [#46976](https://github.com/ClickHouse/ClickHouse/pull/46976) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Change the cherry-pick PR body [#46977](https://github.com/ClickHouse/ClickHouse/pull/46977) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Rename recent stateless tests to fix order [#46991](https://github.com/ClickHouse/ClickHouse/pull/46991) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Pass headers from StorageURL to WriteBufferFromHTTP [#46996](https://github.com/ClickHouse/ClickHouse/pull/46996) ([Konstantin Bogdanov](https://github.com/thevar1able)).
|
||||
* Change level log in executeQuery [#46997](https://github.com/ClickHouse/ClickHouse/pull/46997) ([Andrey Bystrov](https://github.com/AndyBys)).
|
||||
* Add thevar1able to trusted contributors [#46998](https://github.com/ClickHouse/ClickHouse/pull/46998) ([Konstantin Bogdanov](https://github.com/thevar1able)).
|
||||
* Use /etc/default/clickhouse in systemd too [#47003](https://github.com/ClickHouse/ClickHouse/pull/47003) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix tmp_path_template in HTTPHandler::processQuery [#47007](https://github.com/ClickHouse/ClickHouse/pull/47007) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix flaky azure test [#47011](https://github.com/ClickHouse/ClickHouse/pull/47011) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Temporary enable force_sync for keeper in CI [#47024](https://github.com/ClickHouse/ClickHouse/pull/47024) ([alesapin](https://github.com/alesapin)).
|
||||
* ActionsDAG: do not change result of and() during optimization - part 2 [#47028](https://github.com/ClickHouse/ClickHouse/pull/47028) ([Salvatore Mesoraca](https://github.com/aiven-sal)).
|
||||
* Add upgrade check to stateful dependent field [#47031](https://github.com/ClickHouse/ClickHouse/pull/47031) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Disable path check in SQLite storage for clickhouse-local [#47052](https://github.com/ClickHouse/ClickHouse/pull/47052) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Terminate long-running offline non-busy runners in EC2 [#47064](https://github.com/ClickHouse/ClickHouse/pull/47064) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix Keeper with `force_sync = false` [#47065](https://github.com/ClickHouse/ClickHouse/pull/47065) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Update version_date.tsv and changelogs after v23.2.2.20-stable [#47069](https://github.com/ClickHouse/ClickHouse/pull/47069) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Update version_date.tsv and changelogs after v23.1.4.58-stable [#47070](https://github.com/ClickHouse/ClickHouse/pull/47070) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Update version_date.tsv and changelogs after v22.12.4.76-stable [#47074](https://github.com/ClickHouse/ClickHouse/pull/47074) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Fix empty result when selection from only one side of join in analyzer [#47093](https://github.com/ClickHouse/ClickHouse/pull/47093) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Suppress "Cannot flush" for Distributed tables in upgrade check [#47095](https://github.com/ClickHouse/ClickHouse/pull/47095) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Make stacktraces in hung check more readable [#47096](https://github.com/ClickHouse/ClickHouse/pull/47096) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* release lambda resources before detaching thread group [#47098](https://github.com/ClickHouse/ClickHouse/pull/47098) ([Sema Checherinda](https://github.com/CheSema)).
|
||||
* Analyzer Planner fixes before enable by default [#47101](https://github.com/ClickHouse/ClickHouse/pull/47101) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* do flushUntrackedMemory when context switches [#47102](https://github.com/ClickHouse/ClickHouse/pull/47102) ([Sema Checherinda](https://github.com/CheSema)).
|
||||
* fix: keeper systemd service file include invalid inline comment [#47105](https://github.com/ClickHouse/ClickHouse/pull/47105) ([SuperDJY](https://github.com/cmsxbc)).
|
||||
* Add code for autoscaling lambda [#47107](https://github.com/ClickHouse/ClickHouse/pull/47107) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Enable lightweight delete support by default [#47109](https://github.com/ClickHouse/ClickHouse/pull/47109) ([Alexander Gololobov](https://github.com/davenger)).
|
||||
* Update typing for a new PyGithub version [#47123](https://github.com/ClickHouse/ClickHouse/pull/47123) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Shorten some code with CTAD [#47139](https://github.com/ClickHouse/ClickHouse/pull/47139) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Make 01710_projections more stable. [#47145](https://github.com/ClickHouse/ClickHouse/pull/47145) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* fix_JSON_searchField [#47147](https://github.com/ClickHouse/ClickHouse/pull/47147) ([Aleksei Tikhomirov](https://github.com/aletik256)).
|
||||
* Mark 01771_bloom_filter_not_has as no-parallel and long [#47148](https://github.com/ClickHouse/ClickHouse/pull/47148) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Use unique names and paths in `test_replicated_database` [#47152](https://github.com/ClickHouse/ClickHouse/pull/47152) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Add stupid retries in clickhouse-test health check. [#47158](https://github.com/ClickHouse/ClickHouse/pull/47158) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* 02346_full_text_search.sql: Add result separators to simplify analysis [#47166](https://github.com/ClickHouse/ClickHouse/pull/47166) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* More correct handling of fatal errors [#47175](https://github.com/ClickHouse/ClickHouse/pull/47175) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Update read in StorageMemory [#47180](https://github.com/ClickHouse/ClickHouse/pull/47180) ([Konstantin Morozov](https://github.com/k-morozov)).
|
||||
* Doc update for mapFromArrays() [#47183](https://github.com/ClickHouse/ClickHouse/pull/47183) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix failure context for Upgrade check [#47191](https://github.com/ClickHouse/ClickHouse/pull/47191) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Add support for different expected errors [#47196](https://github.com/ClickHouse/ClickHouse/pull/47196) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Fix ip coding on s390x [#47208](https://github.com/ClickHouse/ClickHouse/pull/47208) ([Suzy Wang](https://github.com/SuzyWangIBMer)).
|
||||
* Add real client (initiator server) address into the logs for interserver mode [#47214](https://github.com/ClickHouse/ClickHouse/pull/47214) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix 01019_alter_materialized_view_consistent [#47215](https://github.com/ClickHouse/ClickHouse/pull/47215) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix RewriteArrayExistsToHasPass [#47225](https://github.com/ClickHouse/ClickHouse/pull/47225) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* Release shared ptrs after finishing a transaction [#47245](https://github.com/ClickHouse/ClickHouse/pull/47245) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Add default constructor for `MultiReadResponse` [#47254](https://github.com/ClickHouse/ClickHouse/pull/47254) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Join threads if exception happened in `ZooKeeperImpl` constructor [#47261](https://github.com/ClickHouse/ClickHouse/pull/47261) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* use std::lerp, constexpr hex.h [#47268](https://github.com/ClickHouse/ClickHouse/pull/47268) ([Mike Kot](https://github.com/myrrc)).
|
||||
* Update version_date.tsv and changelogs after v23.2.3.17-stable [#47269](https://github.com/ClickHouse/ClickHouse/pull/47269) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Fix bug in zero copy replica which can lead to dataloss [#47274](https://github.com/ClickHouse/ClickHouse/pull/47274) ([alesapin](https://github.com/alesapin)).
|
||||
* Fix typo [#47282](https://github.com/ClickHouse/ClickHouse/pull/47282) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Follow-up to [#46681](https://github.com/ClickHouse/ClickHouse/issues/46681) [#47284](https://github.com/ClickHouse/ClickHouse/pull/47284) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix test 02566_ipv4_ipv6_binary_formats [#47295](https://github.com/ClickHouse/ClickHouse/pull/47295) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Set fixed index_granularity for test 00636 [#47298](https://github.com/ClickHouse/ClickHouse/pull/47298) ([Sema Checherinda](https://github.com/CheSema)).
|
||||
* Add a manual trigger for release workflow [#47302](https://github.com/ClickHouse/ClickHouse/pull/47302) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix 02570_fallback_from_async_insert [#47308](https://github.com/ClickHouse/ClickHouse/pull/47308) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Catch exceptions in LiveViewPeriodicRefreshTask [#47309](https://github.com/ClickHouse/ClickHouse/pull/47309) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix MergeTreeTransaction::isReadOnly [#47310](https://github.com/ClickHouse/ClickHouse/pull/47310) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix an assertion with implicit transactions in interserver mode [#47312](https://github.com/ClickHouse/ClickHouse/pull/47312) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix `File exists` error in Upgrade check [#47314](https://github.com/ClickHouse/ClickHouse/pull/47314) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Support transformQueryForExternalDatabase for analyzer [#47316](https://github.com/ClickHouse/ClickHouse/pull/47316) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Disable parallel format in health check [#47318](https://github.com/ClickHouse/ClickHouse/pull/47318) ([Ilya Yatsishin](https://github.com/qoega)).
|
||||
* Analyzer - fix combine logic for limit expression and limit setting [#47324](https://github.com/ClickHouse/ClickHouse/pull/47324) ([Yakov Olkhovskiy](https://github.com/yakov-olkhovskiy)).
|
||||
* Suppress expected errors from test 01111 in Upgrade check [#47365](https://github.com/ClickHouse/ClickHouse/pull/47365) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix GROUPING function initialization for grouping sets [#47370](https://github.com/ClickHouse/ClickHouse/pull/47370) ([Dmitry Novik](https://github.com/novikd)).
|
||||
* Add join_algorithm='grace_hash' to stress tests [#47372](https://github.com/ClickHouse/ClickHouse/pull/47372) ([Pradeep Chhetri](https://github.com/chhetripradeep)).
|
||||
* Fix 02343_group_by_use_nulls test in new analyzer [#47373](https://github.com/ClickHouse/ClickHouse/pull/47373) ([Dmitry Novik](https://github.com/novikd)).
|
||||
* Disable 02368_cancel_write_into_hdfs in stress tests [#47382](https://github.com/ClickHouse/ClickHouse/pull/47382) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Analyzer planner fixes before enable by default [#47383](https://github.com/ClickHouse/ClickHouse/pull/47383) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* Fix `ALTER CLEAR COLUMN` with sparse columns [#47384](https://github.com/ClickHouse/ClickHouse/pull/47384) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Fix: apply reading in order for distinct [#47385](https://github.com/ClickHouse/ClickHouse/pull/47385) ([Igor Nikonov](https://github.com/devcrafter)).
|
||||
* add checks for ptr [#47398](https://github.com/ClickHouse/ClickHouse/pull/47398) ([Sema Checherinda](https://github.com/CheSema)).
|
||||
* Remove distinct on top of MergingAggregatedStep [#47399](https://github.com/ClickHouse/ClickHouse/pull/47399) ([Igor Nikonov](https://github.com/devcrafter)).
|
||||
* Update LRUFileCachePriority.cpp [#47411](https://github.com/ClickHouse/ClickHouse/pull/47411) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Make test 02473_optimize_old_parts less flaky [#47416](https://github.com/ClickHouse/ClickHouse/pull/47416) ([Michael Kolupaev](https://github.com/al13n321)).
|
||||
* Add test to prevent regressions when using bitmapHasAny [#47419](https://github.com/ClickHouse/ClickHouse/pull/47419) ([Jordi Villar](https://github.com/jrdi)).
|
||||
* Update README.md [#47421](https://github.com/ClickHouse/ClickHouse/pull/47421) ([Tyler Hannan](https://github.com/tylerhannan)).
|
||||
* Refactor query cache (make use of CacheBase) [#47428](https://github.com/ClickHouse/ClickHouse/pull/47428) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Suppress Hung Check with UBsan [#47429](https://github.com/ClickHouse/ClickHouse/pull/47429) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* [docs] Document add async_insert_max_query_number [#47431](https://github.com/ClickHouse/ClickHouse/pull/47431) ([Antonio Bonuccelli](https://github.com/nellicus)).
|
||||
* Apply settings for EXPLAIN earlier (in the same way we do for SELECT). [#47433](https://github.com/ClickHouse/ClickHouse/pull/47433) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Update version_date.tsv and changelogs after v23.2.4.12-stable [#47448](https://github.com/ClickHouse/ClickHouse/pull/47448) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Fix aggregation-in-order with aliases. [#47449](https://github.com/ClickHouse/ClickHouse/pull/47449) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Fix 01429_join_on_error_messages [#47450](https://github.com/ClickHouse/ClickHouse/pull/47450) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Update version_date.tsv and changelogs after v23.1.5.24-stable [#47452](https://github.com/ClickHouse/ClickHouse/pull/47452) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Update version_date.tsv and changelogs after v22.12.5.34-stable [#47453](https://github.com/ClickHouse/ClickHouse/pull/47453) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Better error messages in ReplicatedMergeTreeAttachThread [#47454](https://github.com/ClickHouse/ClickHouse/pull/47454) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Update version_date.tsv and changelogs after v22.8.15.23-lts [#47455](https://github.com/ClickHouse/ClickHouse/pull/47455) ([robot-clickhouse](https://github.com/robot-clickhouse)).
|
||||
* Disable grace hash join in upgrade check [#47474](https://github.com/ClickHouse/ClickHouse/pull/47474) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Revert [#46622](https://github.com/ClickHouse/ClickHouse/issues/46622) (test_async_insert_memory) [#47476](https://github.com/ClickHouse/ClickHouse/pull/47476) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix `00933_test_fix_extra_seek_on_compressed_cache` in releases. [#47490](https://github.com/ClickHouse/ClickHouse/pull/47490) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix long test `02371_select_projection_normal_agg.sql` [#47491](https://github.com/ClickHouse/ClickHouse/pull/47491) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Revert [#45878](https://github.com/ClickHouse/ClickHouse/issues/45878) and add a test [#47492](https://github.com/ClickHouse/ClickHouse/pull/47492) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Planner JOIN TREE build fix [#47498](https://github.com/ClickHouse/ClickHouse/pull/47498) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* Better support of identifiers from compound expressions in analyzer [#47506](https://github.com/ClickHouse/ClickHouse/pull/47506) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Adapt some tests to pass with and without the analyzer [#47525](https://github.com/ClickHouse/ClickHouse/pull/47525) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Small enhancements [#47534](https://github.com/ClickHouse/ClickHouse/pull/47534) ([Nikita Mikhaylov](https://github.com/nikitamikhaylov)).
|
||||
* Support constants in INTERPOLATE clause (new analyzer) [#47539](https://github.com/ClickHouse/ClickHouse/pull/47539) ([Dmitry Novik](https://github.com/novikd)).
|
||||
* Remove TOTALS handling in FillingTransform [#47542](https://github.com/ClickHouse/ClickHouse/pull/47542) ([Igor Nikonov](https://github.com/devcrafter)).
|
||||
* Hide too noisy log messages, fix some tests [#47547](https://github.com/ClickHouse/ClickHouse/pull/47547) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix some flaky tests [#47553](https://github.com/ClickHouse/ClickHouse/pull/47553) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* remove counters for threads, fix negative counters [#47564](https://github.com/ClickHouse/ClickHouse/pull/47564) ([Sema Checherinda](https://github.com/CheSema)).
|
||||
* Fix typo [#47565](https://github.com/ClickHouse/ClickHouse/pull/47565) ([hq1](https://github.com/aerosol)).
|
||||
* Fixes for upgrade check [#47570](https://github.com/ClickHouse/ClickHouse/pull/47570) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Change error code in case of columns definitions was empty in ODBC [#47573](https://github.com/ClickHouse/ClickHouse/pull/47573) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Add missing SYSTEM FLUSH LOGS for log messages statistics [#47575](https://github.com/ClickHouse/ClickHouse/pull/47575) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Fix performance regression in aggregation [#47582](https://github.com/ClickHouse/ClickHouse/pull/47582) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* ReadFromMergeTree explain prewhere and row policy actions [#47583](https://github.com/ClickHouse/ClickHouse/pull/47583) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* Fix possible failures of 01300_client_save_history_when_terminated_long [#47606](https://github.com/ClickHouse/ClickHouse/pull/47606) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* checksum: do not check inverted index files [#47607](https://github.com/ClickHouse/ClickHouse/pull/47607) ([save-my-heart](https://github.com/save-my-heart)).
|
||||
* Add sanity checks for writing number in variable length format [#47608](https://github.com/ClickHouse/ClickHouse/pull/47608) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Analyzer planner fixes before enable by default [#47622](https://github.com/ClickHouse/ClickHouse/pull/47622) ([Maksim Kita](https://github.com/kitaisreal)).
|
||||
* Fix exception message in clickhouse-test [#47625](https://github.com/ClickHouse/ClickHouse/pull/47625) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* FillingTransform: remove unnecessary indirection when accessing columns [#47632](https://github.com/ClickHouse/ClickHouse/pull/47632) ([Igor Nikonov](https://github.com/devcrafter)).
|
||||
* fix typo in HashJoin insertion that enables debug code in release build [#46726](https://github.com/ClickHouse/ClickHouse/issues/46726) [#47647](https://github.com/ClickHouse/ClickHouse/pull/47647) ([jorisgio](https://github.com/jorisgio)).
|
||||
* clang-tidy >= 15: write CheckOptions in dictionary format [#47648](https://github.com/ClickHouse/ClickHouse/pull/47648) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* CMake: Build ClickHouse w/o GNU extensions [#47651](https://github.com/ClickHouse/ClickHouse/pull/47651) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Faster fasttest [#47654](https://github.com/ClickHouse/ClickHouse/pull/47654) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Add background pools size metrics [#47656](https://github.com/ClickHouse/ClickHouse/pull/47656) ([Sergei Trifonov](https://github.com/serxa)).
|
||||
* Improve ThreadPool [#47657](https://github.com/ClickHouse/ClickHouse/pull/47657) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* cmake: remove support for gold linker [#47660](https://github.com/ClickHouse/ClickHouse/pull/47660) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Updated events and recordings [#47668](https://github.com/ClickHouse/ClickHouse/pull/47668) ([clickhouse-adrianfraguela](https://github.com/clickhouse-adrianfraguela)).
|
||||
* Follow-up to [#47660](https://github.com/ClickHouse/ClickHouse/issues/47660): Further removal of gold linker support [#47669](https://github.com/ClickHouse/ClickHouse/pull/47669) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Enable parallel execution for two tests [#47670](https://github.com/ClickHouse/ClickHouse/pull/47670) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Restore native macos build [#47673](https://github.com/ClickHouse/ClickHouse/pull/47673) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* CMake: Remove further cruft from build [#47680](https://github.com/ClickHouse/ClickHouse/pull/47680) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* fix test / remove hardcoded database [#47682](https://github.com/ClickHouse/ClickHouse/pull/47682) ([Denny Crane](https://github.com/den-crane)).
|
||||
* Apply log_queries_cut_to_length in MergeTreeWhereOptimizer [#47684](https://github.com/ClickHouse/ClickHouse/pull/47684) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Fix logical error in evaluate constant expression [#47685](https://github.com/ClickHouse/ClickHouse/pull/47685) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Try making `test_keeper_mntr_data_size` less flaky [#47687](https://github.com/ClickHouse/ClickHouse/pull/47687) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Fix limit offset [#47688](https://github.com/ClickHouse/ClickHouse/pull/47688) ([flynn](https://github.com/ucasfl)).
|
||||
* Fix startup on older systemd versions [#47689](https://github.com/ClickHouse/ClickHouse/pull/47689) ([Thomas Casteleyn](https://github.com/Hipska)).
|
||||
* More random query id in tests [#47700](https://github.com/ClickHouse/ClickHouse/pull/47700) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Add a style check for unsafe code [#47703](https://github.com/ClickHouse/ClickHouse/pull/47703) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Make the code in Join less disgusting [#47712](https://github.com/ClickHouse/ClickHouse/pull/47712) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fixup git reference to LLVM [#47719](https://github.com/ClickHouse/ClickHouse/pull/47719) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Preparation for libcxx(abi), llvm, clang-tidy 16 [#47722](https://github.com/ClickHouse/ClickHouse/pull/47722) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Rename cfg parameter query_cache.size to query_cache.max_size [#47724](https://github.com/ClickHouse/ClickHouse/pull/47724) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Add optimization for MemoryStorageStep [#47726](https://github.com/ClickHouse/ClickHouse/pull/47726) ([Konstantin Morozov](https://github.com/k-morozov)).
|
||||
* Fix aggregation with constant key in planner [#47727](https://github.com/ClickHouse/ClickHouse/pull/47727) ([Dmitry Novik](https://github.com/novikd)).
|
||||
* Disable setting in 02343_group_by_use_nulls_distributed (for new analyzer) [#47728](https://github.com/ClickHouse/ClickHouse/pull/47728) ([Dmitry Novik](https://github.com/novikd)).
|
||||
* Add a test for [#21469](https://github.com/ClickHouse/ClickHouse/issues/21469) [#47736](https://github.com/ClickHouse/ClickHouse/pull/47736) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Add a test for [#23804](https://github.com/ClickHouse/ClickHouse/issues/23804) [#47737](https://github.com/ClickHouse/ClickHouse/pull/47737) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Add a test for [#18937](https://github.com/ClickHouse/ClickHouse/issues/18937) [#47738](https://github.com/ClickHouse/ClickHouse/pull/47738) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Add a test for [#17756](https://github.com/ClickHouse/ClickHouse/issues/17756) [#47739](https://github.com/ClickHouse/ClickHouse/pull/47739) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Add a test for [#23162](https://github.com/ClickHouse/ClickHouse/issues/23162) [#47740](https://github.com/ClickHouse/ClickHouse/pull/47740) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* remove unused code [#47743](https://github.com/ClickHouse/ClickHouse/pull/47743) ([flynn](https://github.com/ucasfl)).
|
||||
* Fix broken cross-compiled macos builds [#47744](https://github.com/ClickHouse/ClickHouse/pull/47744) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Randomize query cache settings [#47749](https://github.com/ClickHouse/ClickHouse/pull/47749) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Clarify steps for reopened cherry-pick PRs [#47755](https://github.com/ClickHouse/ClickHouse/pull/47755) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix ZK exception error message [#47757](https://github.com/ClickHouse/ClickHouse/pull/47757) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Add ComparisonTupleEliminationVisitor [#47758](https://github.com/ClickHouse/ClickHouse/pull/47758) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Add a fuse for backport branches w/o a created PR [#47760](https://github.com/ClickHouse/ClickHouse/pull/47760) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix partition ID byte order for s390x [#47769](https://github.com/ClickHouse/ClickHouse/pull/47769) ([Harry Lee](https://github.com/HarryLeeIBM)).
|
||||
* Stop `wait for quorum` retries on shutdown [#47770](https://github.com/ClickHouse/ClickHouse/pull/47770) ([Igor Nikonov](https://github.com/devcrafter)).
|
||||
* More preparation for upgrade to libcxx(abi), llvm, clang-tidy 16 [#47771](https://github.com/ClickHouse/ClickHouse/pull/47771) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Only valid Reviews.STATES overwrite existing reviews [#47789](https://github.com/ClickHouse/ClickHouse/pull/47789) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Apply black formatter to all python scripts [#47790](https://github.com/ClickHouse/ClickHouse/pull/47790) ([Anton Popov](https://github.com/CurtizJ)).
|
||||
* Try fix window view test [#47791](https://github.com/ClickHouse/ClickHouse/pull/47791) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Update test for nested lambdas [#47795](https://github.com/ClickHouse/ClickHouse/pull/47795) ([Dmitry Novik](https://github.com/novikd)).
|
||||
* Decrease scale_down ratio for faster deflation [#47798](https://github.com/ClickHouse/ClickHouse/pull/47798) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Fix 993 and two other tests [#47802](https://github.com/ClickHouse/ClickHouse/pull/47802) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix flaky test 02417_opentelemetry_insert_on_distributed_table [#47811](https://github.com/ClickHouse/ClickHouse/pull/47811) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* Make 01086_odbc_roundtrip less flaky [#47820](https://github.com/ClickHouse/ClickHouse/pull/47820) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Place short return before big block, improve logging [#47822](https://github.com/ClickHouse/ClickHouse/pull/47822) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* [FixTests] Remove wrong chassert() in UserDefinedSQLObjectsLoaderFromZooKeeper.cpp [#47839](https://github.com/ClickHouse/ClickHouse/pull/47839) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Fix test test_replicated_merge_tree_encryption_codec [#47851](https://github.com/ClickHouse/ClickHouse/pull/47851) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Allow injecting timeout errors on Keeper [#47856](https://github.com/ClickHouse/ClickHouse/pull/47856) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Comment stale cherry-pick PRs once a day to remind for resolving conflicts [#47857](https://github.com/ClickHouse/ClickHouse/pull/47857) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Followup to [#47802](https://github.com/ClickHouse/ClickHouse/issues/47802) [#47864](https://github.com/ClickHouse/ClickHouse/pull/47864) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Slightly better error message [#47868](https://github.com/ClickHouse/ClickHouse/pull/47868) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Make test_server_reload non-parallel [#47871](https://github.com/ClickHouse/ClickHouse/pull/47871) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* aspell-dict.txt: keep sorted things sorted [#47878](https://github.com/ClickHouse/ClickHouse/pull/47878) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* throw exception when all retries exhausted [#47902](https://github.com/ClickHouse/ClickHouse/pull/47902) ([Sema Checherinda](https://github.com/CheSema)).
|
||||
* Fix GRANT query formatting [#47908](https://github.com/ClickHouse/ClickHouse/pull/47908) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Fix exception type in arrayElement function [#47909](https://github.com/ClickHouse/ClickHouse/pull/47909) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Fix logical error in DistributedSink [#47916](https://github.com/ClickHouse/ClickHouse/pull/47916) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix terminate in parts check thread [#47917](https://github.com/ClickHouse/ClickHouse/pull/47917) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Limit keeper request batching by size in bytes [#47918](https://github.com/ClickHouse/ClickHouse/pull/47918) ([Alexander Gololobov](https://github.com/davenger)).
|
||||
* Improve replicated user defined functions [#47919](https://github.com/ClickHouse/ClickHouse/pull/47919) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Update 01072_window_view_multiple_columns_groupby.sh [#47928](https://github.com/ClickHouse/ClickHouse/pull/47928) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Added test. Closes [#12264](https://github.com/ClickHouse/ClickHouse/issues/12264) [#47931](https://github.com/ClickHouse/ClickHouse/pull/47931) ([Ilya Yatsishin](https://github.com/qoega)).
|
||||
* Disallow concurrent backup restore test - removed SYSTEM SYNC [#47944](https://github.com/ClickHouse/ClickHouse/pull/47944) ([SmitaRKulkarni](https://github.com/SmitaRKulkarni)).
|
||||
* Artifacts s3 prefix [#47945](https://github.com/ClickHouse/ClickHouse/pull/47945) ([Mikhail f. Shiryaev](https://github.com/Felixoid)).
|
||||
* Set content-length for empty POST requests [#47950](https://github.com/ClickHouse/ClickHouse/pull/47950) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix test `02050_client_profile_events` [#47951](https://github.com/ClickHouse/ClickHouse/pull/47951) ([Nikita Mikhaylov](https://github.com/nikitamikhaylov)).
|
||||
* Fix tsan error lock-order-inversion [#47953](https://github.com/ClickHouse/ClickHouse/pull/47953) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Update docs for parseDateTime() (follow-up to [#46815](https://github.com/ClickHouse/ClickHouse/issues/46815)) [#47959](https://github.com/ClickHouse/ClickHouse/pull/47959) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Docs: Update secondary index example [#47961](https://github.com/ClickHouse/ClickHouse/pull/47961) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix compilation on MacOS [#47967](https://github.com/ClickHouse/ClickHouse/pull/47967) ([Jordi Villar](https://github.com/jrdi)).
|
||||
* [Refactoring] Move information about current hosts and list of all hosts to BackupCoordination [#47971](https://github.com/ClickHouse/ClickHouse/pull/47971) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Stabilize tests for new function parseDateTimeInJodaSyntax [#47974](https://github.com/ClickHouse/ClickHouse/pull/47974) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Docs: Fix links [#47976](https://github.com/ClickHouse/ClickHouse/pull/47976) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Try fix rabbitmq test [#47987](https://github.com/ClickHouse/ClickHouse/pull/47987) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Better type check in arrayElement function [#47989](https://github.com/ClickHouse/ClickHouse/pull/47989) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Fix incorrect code indentation [#48011](https://github.com/ClickHouse/ClickHouse/pull/48011) ([exmy](https://github.com/exmy)).
|
||||
* CMake: Remove configuration of CMAKE_SHARED_LINKER_FLAGS [#48018](https://github.com/ClickHouse/ClickHouse/pull/48018) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Remove the old changelog script [#48042](https://github.com/ClickHouse/ClickHouse/pull/48042) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Fix automatic indentation in the built-in UI SQL editor [#48045](https://github.com/ClickHouse/ClickHouse/pull/48045) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Rename `system.marked_dropped_tables` to `dropped_tables` [#48048](https://github.com/ClickHouse/ClickHouse/pull/48048) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Automatically correct some mistakes in the changelog [#48052](https://github.com/ClickHouse/ClickHouse/pull/48052) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Docs: Document [FULL] keyword in SHOW TABLES [#48061](https://github.com/ClickHouse/ClickHouse/pull/48061) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix stateless tests numbers [#48063](https://github.com/ClickHouse/ClickHouse/pull/48063) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* Docs: Update syntax of some SHOW queries [#48064](https://github.com/ClickHouse/ClickHouse/pull/48064) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Simplify backup coordination for file infos [#48095](https://github.com/ClickHouse/ClickHouse/pull/48095) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* materialized pg small fix [#48098](https://github.com/ClickHouse/ClickHouse/pull/48098) ([Kseniia Sumarokova](https://github.com/kssenii)).
|
||||
* Update SQLite to 3.41.2 [#48101](https://github.com/ClickHouse/ClickHouse/pull/48101) ([Nikolay Degterinsky](https://github.com/evillique)).
|
||||
* Fix test numbers again and enforce it with style [#48106](https://github.com/ClickHouse/ClickHouse/pull/48106) ([Raúl Marín](https://github.com/Algunenano)).
|
||||
* s390x reinterpret as float64 [#48112](https://github.com/ClickHouse/ClickHouse/pull/48112) ([Suzy Wang](https://github.com/SuzyWangIBMer)).
|
||||
* Remove slow outdated test [#48114](https://github.com/ClickHouse/ClickHouse/pull/48114) ([alesapin](https://github.com/alesapin)).
|
||||
* Cosmetic follow-up to [#46252](https://github.com/ClickHouse/ClickHouse/issues/46252) [#48128](https://github.com/ClickHouse/ClickHouse/pull/48128) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Merging "Support undrop table" [#48130](https://github.com/ClickHouse/ClickHouse/pull/48130) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix double whitespace in exception message [#48132](https://github.com/ClickHouse/ClickHouse/pull/48132) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Improve script for updating clickhouse-docs [#48135](https://github.com/ClickHouse/ClickHouse/pull/48135) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
* Fix stdlib compatibility issues [#48150](https://github.com/ClickHouse/ClickHouse/pull/48150) ([DimasKovas](https://github.com/DimasKovas)).
|
||||
* Make test test_disallow_concurrency less flaky [#48152](https://github.com/ClickHouse/ClickHouse/pull/48152) ([Vitaly Baranov](https://github.com/vitlibar)).
|
||||
* Remove unused mockSystemDatabase from gtest_transform_query_for_exter… [#48162](https://github.com/ClickHouse/ClickHouse/pull/48162) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Update environmental-sensors.md [#48166](https://github.com/ClickHouse/ClickHouse/pull/48166) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Correctly handle NULL constants in logical optimizer for new analyzer [#48168](https://github.com/ClickHouse/ClickHouse/pull/48168) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Try making KeeperMap test more stable [#48170](https://github.com/ClickHouse/ClickHouse/pull/48170) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* Deprecate EXPLAIN QUERY TREE with disabled analyzer. [#48177](https://github.com/ClickHouse/ClickHouse/pull/48177) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Use uniq file names in 02149_* tests to avoid SIGBUS in stress tests [#48187](https://github.com/ClickHouse/ClickHouse/pull/48187) ([Kruglov Pavel](https://github.com/Avogar)).
|
||||
* Update style in ParserKQLSort.cpp [#48199](https://github.com/ClickHouse/ClickHouse/pull/48199) ([Ilya Yatsishin](https://github.com/qoega)).
|
||||
* Remove support for std::unary/binary_function (removed in C++17) [#48204](https://github.com/ClickHouse/ClickHouse/pull/48204) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Remove unused setting [#48208](https://github.com/ClickHouse/ClickHouse/pull/48208) ([Alexey Milovidov](https://github.com/alexey-milovidov)).
|
||||
* Remove wrong assert from LogicalExpressionOptimizerPass [#48214](https://github.com/ClickHouse/ClickHouse/pull/48214) ([Antonio Andelic](https://github.com/antonio2368)).
|
||||
* MySQL compatibility: Make str_to_date alias case-insensitive [#48220](https://github.com/ClickHouse/ClickHouse/pull/48220) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Disable AST optimizations for projection analysis. [#48221](https://github.com/ClickHouse/ClickHouse/pull/48221) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Fix Too big of a difference between test numbers [#48224](https://github.com/ClickHouse/ClickHouse/pull/48224) ([Vladimir C](https://github.com/vdimir)).
|
||||
* Stabilize 02477_age [#48225](https://github.com/ClickHouse/ClickHouse/pull/48225) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Rename setting stop_reading_on_first_cancel [#48226](https://github.com/ClickHouse/ClickHouse/pull/48226) ([Nikolai Kochetov](https://github.com/KochetovNicolai)).
|
||||
* Address flaky 02346_full_text_search [#48227](https://github.com/ClickHouse/ClickHouse/pull/48227) ([Robert Schulze](https://github.com/rschu1ze)).
|
||||
* Fix incorrect ThreadPool usage after ThreadPool introspection [#48244](https://github.com/ClickHouse/ClickHouse/pull/48244) ([Azat Khuzhin](https://github.com/azat)).
|
||||
* fix test numbers again [#48264](https://github.com/ClickHouse/ClickHouse/pull/48264) ([Alexander Tokmakov](https://github.com/tavplubix)).
|
||||
|
||||
#### Testing Improvement
|
||||
|
||||
* Fixed functional test 02534_keyed_siphash and 02552_siphash128_reference for s390x. [#47615](https://github.com/ClickHouse/ClickHouse/pull/47615) ([Harry Lee](https://github.com/HarryLeeIBM)).
|
||||
|
||||
@ -11,14 +11,14 @@ This is intended for continuous integration checks that run on Linux servers. If
|
||||
|
||||
The cross-build for macOS is based on the [Build instructions](../development/build.md), follow them first.
|
||||
|
||||
## Install Clang-14
|
||||
## Install Clang-15
|
||||
|
||||
Follow the instructions from https://apt.llvm.org/ for your Ubuntu or Debian setup.
|
||||
For example the commands for Bionic are like:
|
||||
|
||||
``` bash
|
||||
sudo echo "deb [trusted=yes] http://apt.llvm.org/bionic/ llvm-toolchain-bionic-14 main" >> /etc/apt/sources.list
|
||||
sudo apt-get install clang-14
|
||||
sudo echo "deb [trusted=yes] http://apt.llvm.org/bionic/ llvm-toolchain-bionic-15 main" >> /etc/apt/sources.list
|
||||
sudo apt-get install clang-15
|
||||
```
|
||||
|
||||
## Install Cross-Compilation Toolset {#install-cross-compilation-toolset}
|
||||
@ -55,7 +55,7 @@ curl -L 'https://github.com/phracker/MacOSX-SDKs/releases/download/10.15/MacOSX1
|
||||
cd ClickHouse
|
||||
mkdir build-darwin
|
||||
cd build-darwin
|
||||
CC=clang-14 CXX=clang++-14 cmake -DCMAKE_AR:FILEPATH=${CCTOOLS}/bin/x86_64-apple-darwin-ar -DCMAKE_INSTALL_NAME_TOOL=${CCTOOLS}/bin/x86_64-apple-darwin-install_name_tool -DCMAKE_RANLIB:FILEPATH=${CCTOOLS}/bin/x86_64-apple-darwin-ranlib -DLINKER_NAME=${CCTOOLS}/bin/x86_64-apple-darwin-ld -DCMAKE_TOOLCHAIN_FILE=cmake/darwin/toolchain-x86_64.cmake ..
|
||||
CC=clang-15 CXX=clang++-15 cmake -DCMAKE_AR:FILEPATH=${CCTOOLS}/bin/x86_64-apple-darwin-ar -DCMAKE_INSTALL_NAME_TOOL=${CCTOOLS}/bin/x86_64-apple-darwin-install_name_tool -DCMAKE_RANLIB:FILEPATH=${CCTOOLS}/bin/x86_64-apple-darwin-ranlib -DLINKER_NAME=${CCTOOLS}/bin/x86_64-apple-darwin-ld -DCMAKE_TOOLCHAIN_FILE=cmake/darwin/toolchain-x86_64.cmake ..
|
||||
ninja
|
||||
```
|
||||
|
||||
|
||||
@ -85,7 +85,7 @@ The build requires the following components:
|
||||
- Git (is used only to checkout the sources, it’s not needed for the build)
|
||||
- CMake 3.15 or newer
|
||||
- Ninja
|
||||
- C++ compiler: clang-14 or newer
|
||||
- C++ compiler: clang-15 or newer
|
||||
- Linker: lld
|
||||
- Yasm
|
||||
- Gawk
|
||||
|
||||
@ -259,4 +259,4 @@ The number of rows in one Kafka message depends on whether the format is row-bas
|
||||
**See Also**
|
||||
|
||||
- [Virtual columns](../../../engines/table-engines/index.md#table_engines-virtual_columns)
|
||||
- [background_message_broker_schedule_pool_size](../../../operations/settings/settings.md#background_message_broker_schedule_pool_size)
|
||||
- [background_message_broker_schedule_pool_size](../../../operations/server-configuration-parameters/settings.md#background_message_broker_schedule_pool_size)
|
||||
|
||||
@ -12,7 +12,7 @@ This engine provides integration with [Amazon S3](https://aws.amazon.com/s3/) ec
|
||||
|
||||
``` sql
|
||||
CREATE TABLE s3_engine_table (name String, value UInt32)
|
||||
ENGINE = S3(path, [aws_access_key_id, aws_secret_access_key,] format, [compression])
|
||||
ENGINE = S3(path [, NOSIGN | aws_access_key_id, aws_secret_access_key,] format, [compression])
|
||||
[PARTITION BY expr]
|
||||
[SETTINGS ...]
|
||||
```
|
||||
@ -20,6 +20,7 @@ CREATE TABLE s3_engine_table (name String, value UInt32)
|
||||
**Engine parameters**
|
||||
|
||||
- `path` — Bucket url with path to file. Supports following wildcards in readonly mode: `*`, `?`, `{abc,def}` and `{N..M}` where `N`, `M` — numbers, `'abc'`, `'def'` — strings. For more information see [below](#wildcards-in-path).
|
||||
- `NOSIGN` - If this keyword is provided in place of credentials, all the requests will not be signed.
|
||||
- `format` — The [format](../../../interfaces/formats.md#formats) of the file.
|
||||
- `aws_access_key_id`, `aws_secret_access_key` - Long-term credentials for the [AWS](https://aws.amazon.com/) account user. You can use these to authenticate your requests. Parameter is optional. If credentials are not specified, they are used from the configuration file. For more information see [Using S3 for Data Storage](../mergetree-family/mergetree.md#table_engine-mergetree-s3).
|
||||
- `compression` — Compression type. Supported values: `none`, `gzip/gz`, `brotli/br`, `xz/LZMA`, `zstd/zst`. Parameter is optional. By default, it will autodetect compression by file extension.
|
||||
@ -151,6 +152,7 @@ The following settings can be specified in configuration file for given endpoint
|
||||
- `region` — Specifies S3 region name. Optional.
|
||||
- `use_insecure_imds_request` — If set to `true`, S3 client will use insecure IMDS request while obtaining credentials from Amazon EC2 metadata. Optional, default value is `false`.
|
||||
- `expiration_window_seconds` — Grace period for checking if expiration-based credentials have expired. Optional, default value is `120`.
|
||||
- `no_sign_request` - Ignore all the credentials so requests are not signed. Useful for accessing public buckets.
|
||||
- `header` — Adds specified HTTP header to a request to given endpoint. Optional, can be specified multiple times.
|
||||
- `server_side_encryption_customer_key_base64` — If specified, required headers for accessing S3 objects with SSE-C encryption will be set. Optional.
|
||||
- `max_single_read_retries` — The maximum number of attempts during single read. Default value is `4`. Optional.
|
||||
@ -168,6 +170,7 @@ The following settings can be specified in configuration file for given endpoint
|
||||
<!-- <use_environment_credentials>false</use_environment_credentials> -->
|
||||
<!-- <use_insecure_imds_request>false</use_insecure_imds_request> -->
|
||||
<!-- <expiration_window_seconds>120</expiration_window_seconds> -->
|
||||
<!-- <no_sign_request>false</no_sign_request> -->
|
||||
<!-- <header>Authorization: Bearer SOME-TOKEN</header> -->
|
||||
<!-- <server_side_encryption_customer_key_base64>BASE64-ENCODED-KEY</server_side_encryption_customer_key_base64> -->
|
||||
<!-- <max_single_read_retries>4</max_single_read_retries> -->
|
||||
@ -175,6 +178,17 @@ The following settings can be specified in configuration file for given endpoint
|
||||
</s3>
|
||||
```
|
||||
|
||||
## Accessing public buckets
|
||||
|
||||
ClickHouse tries to fetch credentials from many different types of sources.
|
||||
Sometimes, it can produce problems when accessing some buckets that are public causing the client to return `403` error code.
|
||||
This issue can be avoided by using `NOSIGN` keyword, forcing the client to ignore all the credentials, and not sign the requests.
|
||||
|
||||
``` sql
|
||||
CREATE TABLE big_table (name String, value UInt32)
|
||||
ENGINE = S3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/aapl_stock.csv', NOSIGN, 'CSVWithNames');
|
||||
```
|
||||
|
||||
## See also
|
||||
|
||||
- [s3 table function](../../../sql-reference/table-functions/s3.md)
|
||||
|
||||
@ -456,33 +456,35 @@ Conditions in the `WHERE` clause contains calls of the functions that operate wi
|
||||
|
||||
Indexes of type `set` can be utilized by all functions. The other index types are supported as follows:
|
||||
|
||||
| Function (operator) / Index | primary key | minmax | ngrambf_v1 | tokenbf_v1 | bloom_filter |
|
||||
|------------------------------------------------------------------------------------------------------------|-------------|--------|------------|------------|--------------|
|
||||
| [equals (=, ==)](/docs/en/sql-reference/functions/comparison-functions.md/#function-equals) | ✔ | ✔ | ✔ | ✔ | ✔ |
|
||||
| [notEquals(!=, <>)](/docs/en/sql-reference/functions/comparison-functions.md/#function-notequals) | ✔ | ✔ | ✔ | ✔ | ✔ |
|
||||
| [like](/docs/en/sql-reference/functions/string-search-functions.md/#function-like) | ✔ | ✔ | ✔ | ✔ | ✗ |
|
||||
| [notLike](/docs/en/sql-reference/functions/string-search-functions.md/#function-notlike) | ✔ | ✔ | ✔ | ✔ | ✗ |
|
||||
| [startsWith](/docs/en/sql-reference/functions/string-functions.md/#startswith) | ✔ | ✔ | ✔ | ✔ | ✗ |
|
||||
| [endsWith](/docs/en/sql-reference/functions/string-functions.md/#endswith) | ✗ | ✗ | ✔ | ✔ | ✗ |
|
||||
| [multiSearchAny](/docs/en/sql-reference/functions/string-search-functions.md/#function-multisearchany) | ✗ | ✗ | ✔ | ✗ | ✗ |
|
||||
| [in](/docs/en/sql-reference/functions/in-functions#in-functions) | ✔ | ✔ | ✔ | ✔ | ✔ |
|
||||
| [notIn](/docs/en/sql-reference/functions/in-functions#in-functions) | ✔ | ✔ | ✔ | ✔ | ✔ |
|
||||
| [less (<)](/docs/en/sql-reference/functions/comparison-functions.md/#function-less) | ✔ | ✔ | ✗ | ✗ | ✗ |
|
||||
| [greater (>)](/docs/en/sql-reference/functions/comparison-functions.md/#function-greater) | ✔ | ✔ | ✗ | ✗ | ✗ |
|
||||
| [lessOrEquals (<=)](/docs/en/sql-reference/functions/comparison-functions.md/#function-lessorequals) | ✔ | ✔ | ✗ | ✗ | ✗ |
|
||||
| [greaterOrEquals (>=)](/docs/en/sql-reference/functions/comparison-functions.md/#function-greaterorequals) | ✔ | ✔ | ✗ | ✗ | ✗ |
|
||||
| [empty](/docs/en/sql-reference/functions/array-functions#function-empty) | ✔ | ✔ | ✗ | ✗ | ✗ |
|
||||
| [notEmpty](/docs/en/sql-reference/functions/array-functions#function-notempty) | ✔ | ✔ | ✗ | ✗ | ✗ |
|
||||
| [has](/docs/en/sql-reference/functions/array-functions#function-has) | ✗ | ✗ | ✔ | ✔ | ✔ |
|
||||
| [hasAny](/docs/en/sql-reference/functions/array-functions#function-hasAny) | ✗ | ✗ | ✗ | ✗ | ✔ |
|
||||
| [hasAll](/docs/en/sql-reference/functions/array-functions#function-hasAll) | ✗ | ✗ | ✗ | ✗ | ✔ |
|
||||
| hasToken | ✗ | ✗ | ✗ | ✔ | ✗ |
|
||||
| hasTokenOrNull | ✗ | ✗ | ✗ | ✔ | ✗ |
|
||||
| hasTokenCaseInsensitive | ✗ | ✗ | ✗ | ✔ | ✗ |
|
||||
| hasTokenCaseInsensitiveOrNull | ✗ | ✗ | ✗ | ✔ | ✗ |
|
||||
| Function (operator) / Index | primary key | minmax | ngrambf_v1 | tokenbf_v1 | bloom_filter | inverted |
|
||||
|------------------------------------------------------------------------------------------------------------|-------------|--------|------------|------------|--------------|----------|
|
||||
| [equals (=, ==)](/docs/en/sql-reference/functions/comparison-functions.md/#function-equals) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
|
||||
| [notEquals(!=, <>)](/docs/en/sql-reference/functions/comparison-functions.md/#function-notequals) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
|
||||
| [like](/docs/en/sql-reference/functions/string-search-functions.md/#function-like) | ✔ | ✔ | ✔ | ✔ | ✗ | ✔ |
|
||||
| [notLike](/docs/en/sql-reference/functions/string-search-functions.md/#function-notlike) | ✔ | ✔ | ✔ | ✔ | ✗ | ✔ |
|
||||
| [startsWith](/docs/en/sql-reference/functions/string-functions.md/#startswith) | ✔ | ✔ | ✔ | ✔ | ✗ | ✔ |
|
||||
| [endsWith](/docs/en/sql-reference/functions/string-functions.md/#endswith) | ✗ | ✗ | ✔ | ✔ | ✗ | ✔ |
|
||||
| [multiSearchAny](/docs/en/sql-reference/functions/string-search-functions.md/#function-multisearchany) | ✗ | ✗ | ✔ | ✗ | ✗ | ✔ |
|
||||
| [in](/docs/en/sql-reference/functions/in-functions#in-functions) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
|
||||
| [notIn](/docs/en/sql-reference/functions/in-functions#in-functions) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
|
||||
| [less (<)](/docs/en/sql-reference/functions/comparison-functions.md/#function-less) | ✔ | ✔ | ✗ | ✗ | ✗ | ✗ |
|
||||
| [greater (>)](/docs/en/sql-reference/functions/comparison-functions.md/#function-greater) | ✔ | ✔ | ✗ | ✗ | ✗ | ✗ |
|
||||
| [lessOrEquals (<=)](/docs/en/sql-reference/functions/comparison-functions.md/#function-lessorequals) | ✔ | ✔ | ✗ | ✗ | ✗ | ✗ |
|
||||
| [greaterOrEquals (>=)](/docs/en/sql-reference/functions/comparison-functions.md/#function-greaterorequals) | ✔ | ✔ | ✗ | ✗ | ✗ | ✗ |
|
||||
| [empty](/docs/en/sql-reference/functions/array-functions#function-empty) | ✔ | ✔ | ✗ | ✗ | ✗ | ✗ |
|
||||
| [notEmpty](/docs/en/sql-reference/functions/array-functions#function-notempty) | ✔ | ✔ | ✗ | ✗ | ✗ | ✗ |
|
||||
| [has](/docs/en/sql-reference/functions/array-functions#function-has) | ✗ | ✗ | ✔ | ✔ | ✔ | ✔ |
|
||||
| [hasAny](/docs/en/sql-reference/functions/array-functions#function-hasAny) | ✗ | ✗ | ✗ | ✗ | ✔ | ✗ |
|
||||
| [hasAll](/docs/en/sql-reference/functions/array-functions#function-hasAll) | ✗ | ✗ | ✗ | ✗ | ✔ | ✗ |
|
||||
| hasToken | ✗ | ✗ | ✗ | ✔ | ✗ | ✔ |
|
||||
| hasTokenOrNull | ✗ | ✗ | ✗ | ✔ | ✗ | ✔ |
|
||||
| hasTokenCaseInsensitive (*) | ✗ | ✗ | ✗ | ✔ | ✗ | ✗ |
|
||||
| hasTokenCaseInsensitiveOrNull (*) | ✗ | ✗ | ✗ | ✔ | ✗ | ✗ |
|
||||
|
||||
Functions with a constant argument that is less than ngram size can’t be used by `ngrambf_v1` for query optimization.
|
||||
|
||||
(*) For `hasTokenCaseInsensitve` and `hasTokenCaseInsensitive` to be effective, the `tokenbf_v1` index must be created on lowercased data, for example `INDEX idx (lower(str_col)) TYPE tokenbf_v1(512, 3, 0)`.
|
||||
|
||||
:::note
|
||||
Bloom filters can have false positive matches, so the `ngrambf_v1`, `tokenbf_v1`, and `bloom_filter` indexes can not be used for optimizing queries where the result of a function is expected to be false.
|
||||
|
||||
@ -872,7 +874,7 @@ SETTINGS storage_policy = 'moving_from_ssd_to_hdd'
|
||||
The `default` storage policy implies using only one volume, which consists of only one disk given in `<path>`.
|
||||
You could change storage policy after table creation with [ALTER TABLE ... MODIFY SETTING] query, new policy should include all old disks and volumes with same names.
|
||||
|
||||
The number of threads performing background moves of data parts can be changed by [background_move_pool_size](/docs/en/operations/settings/settings.md/#background_move_pool_size) setting.
|
||||
The number of threads performing background moves of data parts can be changed by [background_move_pool_size](/docs/en/operations/server-configuration-parameters/settings.md/#background_move_pool_size) setting.
|
||||
|
||||
### Details {#details}
|
||||
|
||||
|
||||
@ -112,7 +112,7 @@ For each `INSERT` query, approximately ten entries are added to ZooKeeper throug
|
||||
|
||||
For very large clusters, you can use different ZooKeeper clusters for different shards. However, from our experience this has not proven necessary based on production clusters with approximately 300 servers.
|
||||
|
||||
Replication is asynchronous and multi-master. `INSERT` queries (as well as `ALTER`) can be sent to any available server. Data is inserted on the server where the query is run, and then it is copied to the other servers. Because it is asynchronous, recently inserted data appears on the other replicas with some latency. If part of the replicas are not available, the data is written when they become available. If a replica is available, the latency is the amount of time it takes to transfer the block of compressed data over the network. The number of threads performing background tasks for replicated tables can be set by [background_schedule_pool_size](/docs/en/operations/settings/settings.md/#background_schedule_pool_size) setting.
|
||||
Replication is asynchronous and multi-master. `INSERT` queries (as well as `ALTER`) can be sent to any available server. Data is inserted on the server where the query is run, and then it is copied to the other servers. Because it is asynchronous, recently inserted data appears on the other replicas with some latency. If part of the replicas are not available, the data is written when they become available. If a replica is available, the latency is the amount of time it takes to transfer the block of compressed data over the network. The number of threads performing background tasks for replicated tables can be set by [background_schedule_pool_size](/docs/en/operations/server-configuration-parameters/settings.md/#background_schedule_pool_size) setting.
|
||||
|
||||
`ReplicatedMergeTree` engine uses a separate thread pool for replicated fetches. Size of the pool is limited by the [background_fetches_pool_size](/docs/en/operations/settings/settings.md/#background_fetches_pool_size) setting which can be tuned with a server restart.
|
||||
|
||||
@ -320,8 +320,8 @@ If the data in ClickHouse Keeper was lost or damaged, you can save data by movin
|
||||
|
||||
**See Also**
|
||||
|
||||
- [background_schedule_pool_size](/docs/en/operations/settings/settings.md/#background_schedule_pool_size)
|
||||
- [background_fetches_pool_size](/docs/en/operations/settings/settings.md/#background_fetches_pool_size)
|
||||
- [background_schedule_pool_size](/docs/en/operations/server-configuration-parameters/settings.md/#background_schedule_pool_size)
|
||||
- [background_fetches_pool_size](/docs/en/operations/server-configuration-parameters/settings.md/#background_fetches_pool_size)
|
||||
- [execute_merges_on_single_replica_time_threshold](/docs/en/operations/settings/settings.md/#execute-merges-on-single-replica-time-threshold)
|
||||
- [max_replicated_fetches_network_bandwidth](/docs/en/operations/settings/merge-tree-settings.md/#max_replicated_fetches_network_bandwidth)
|
||||
- [max_replicated_sends_network_bandwidth](/docs/en/operations/settings/merge-tree-settings.md/#max_replicated_sends_network_bandwidth)
|
||||
|
||||
@ -141,6 +141,10 @@ Clusters are configured in the [server configuration file](../../../operations/c
|
||||
be used as current user for the query.
|
||||
-->
|
||||
<!-- <secret></secret> -->
|
||||
|
||||
<!-- Optional. Whether distributed DDL queries (ON CLUSTER clause) are allowed for this cluster. Default: true (allowed). -->
|
||||
<!-- <allow_distributed_ddl_queries>true</allow_distributed_ddl_queries> -->
|
||||
|
||||
<shard>
|
||||
<!-- Optional. Shard weight when writing data. Default: 1. -->
|
||||
<weight>1</weight>
|
||||
|
||||
476
docs/en/getting-started/example-datasets/amazon-reviews.md
Normal file
476
docs/en/getting-started/example-datasets/amazon-reviews.md
Normal file
@ -0,0 +1,476 @@
|
||||
---
|
||||
slug: /en/getting-started/example-datasets/amazon-reviews
|
||||
sidebar_label: Amazon customer reviews
|
||||
---
|
||||
|
||||
# Amazon customer reviews dataset
|
||||
|
||||
[**Amazon Customer Reviews**](https://s3.amazonaws.com/amazon-reviews-pds/readme.html) (a.k.a. Product Reviews) is one of Amazon’s iconic products. In a period of over two decades since the first review in 1995, millions of Amazon customers have contributed over a hundred million reviews to express opinions and describe their experiences regarding products on the Amazon.com website. This makes Amazon Customer Reviews a rich source of information for academic researchers in the fields of Natural Language Processing (NLP), Information Retrieval (IR), and Machine Learning (ML), amongst others. By accessing the dataset, you agree to the [license terms](https://s3.amazonaws.com/amazon-reviews-pds/license.txt).
|
||||
|
||||
The data is in a tab-separated format in gzipped files are up in AWS S3. Let's walk through the steps to insert it into ClickHouse.
|
||||
|
||||
:::note
|
||||
The queries below were executed on a **Production** instance of [ClickHouse Cloud](https://clickhouse.cloud).
|
||||
:::
|
||||
|
||||
|
||||
1. Without inserting the data into ClickHouse, we can query it in place. Let's grab some rows so we can see what they look like:
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM s3('https://s3.amazonaws.com/amazon-reviews-pds/tsv/amazon_reviews_us_Wireless_v1_00.tsv.gz',
|
||||
'TabSeparatedWithNames',
|
||||
'marketplace String,
|
||||
customer_id Int64,
|
||||
review_id String,
|
||||
product_id String,
|
||||
product_parent Int64,
|
||||
product_title String,
|
||||
product_category String,
|
||||
star_rating Int64,
|
||||
helpful_votes Int64,
|
||||
total_votes Int64,
|
||||
vine Bool,
|
||||
verified_purchase Bool,
|
||||
review_headline String,
|
||||
review_body String,
|
||||
review_date Date'
|
||||
)
|
||||
LIMIT 10;
|
||||
```
|
||||
|
||||
The rows look like:
|
||||
|
||||
```response
|
||||
┌─marketplace─┬─customer_id─┬─review_id──────┬─product_id─┬─product_parent─┬─product_title──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─product_category─┬─star_rating─┬─helpful_votes─┬─total_votes─┬─vine──┬─verified_purchase─┬─review_headline───────────┬─review_body────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─review_date─┐
|
||||
│ US │ 16414143 │ R3W4P9UBGNGH1U │ B00YL0EKWE │ 852431543 │ LG G4 Case Hard Transparent Slim Clear Cover for LG G4 │ Wireless │ 2 │ 1 │ 3 │ false │ true │ Looks good, functions meh │ 2 issues - Once I turned on the circle apps and installed this case, my battery drained twice as fast as usual. I ended up turning off the circle apps, which kind of makes the case just a case... with a hole in it. Second, the wireless charging doesn't work. I have a Motorola 360 watch and a Qi charging pad. The watch charges fine but this case doesn't. But hey, it looks nice. │ 2015-08-31 │
|
||||
│ US │ 50800750 │ R15V54KBMTQWAY │ B00XK95RPQ │ 516894650 │ Selfie Stick Fiblastiq™ Extendable Wireless Bluetooth Selfie Stick with built-in Bluetooth Adjustable Phone Holder │ Wireless │ 4 │ 0 │ 0 │ false │ false │ A fun little gadget │ I’m embarrassed to admit that until recently, I have had a very negative opinion about “selfie sticks” aka “monopods” aka “narcissticks.” But having reviewed a number of them recently, they’re growing on me. This one is pretty nice and simple to set up and with easy instructions illustrated on the back of the box (not sure why some reviewers have stated that there are no instructions when they are clearly printed on the box unless they received different packaging than I did). Once assembled, the pairing via bluetooth and use of the stick are easy and intuitive. Nothing to it.<br /><br />The stick comes with a USB charging cable but arrived with a charge so you can use it immediately, though it’s probably a good idea to charge it right away so that you have no interruption of use out of the box. Make sure the stick is switched to on (it will light up) and extend your stick to the length you desire up to about a yard’s length and snap away.<br /><br />The phone clamp held the phone sturdily so I wasn’t worried about it slipping out. But the longer you extend the stick, the harder it is to maneuver. But that will happen with any stick and is not specific to this one in particular.<br /><br />Two things that could improve this: 1) add the option to clamp this in portrait orientation instead of having to try and hold the stick at the portrait angle, which makes it feel unstable; 2) add the opening for a tripod so that this can be used to sit upright on a table for skyping and facetime eliminating the need to hold the phone up with your hand, causing fatigue.<br /><br />But other than that, this is a nice quality monopod for a variety of picture taking opportunities.<br /><br />I received a sample in exchange for my honest opinion. │ 2015-08-31 │
|
||||
│ US │ 15184378 │ RY8I449HNXSVF │ B00SXRXUKO │ 984297154 │ Tribe AB40 Water Resistant Sports Armband with Key Holder for 4.7-Inch iPhone 6S/6/5/5S/5C, Galaxy S4 + Screen Protector - Dark Pink │ Wireless │ 5 │ 0 │ 0 │ false │ true │ Five Stars │ Fits iPhone 6 well │ 2015-08-31 │
|
||||
│ US │ 10203548 │ R18TLJYCKJFLSR │ B009V5X1CE │ 279912704 │ RAVPower® Element 10400mAh External Battery USB Portable Charger (Dual USB Outputs, Ultra Compact Design), Travel Charger for iPhone 6,iPhone 6 plus,iPhone 5, 5S, 5C, 4S, 4, iPad Air, 4, 3, 2, Mini 2 (Apple adapters not included); Samsung Galaxy S5, S4, S3, S2, Note 3, Note 2; HTC One, EVO, Thunderbolt, Incredible, Droid DNA, Motorola ATRIX, Droid, Moto X, Google Glass, Nexus 4, Nexus 5, Nexus 7, │ Wireless │ 5 │ 0 │ 0 │ false │ true │ Great charger │ Great charger. I easily get 3+ charges on a Samsung Galaxy 3. Works perfectly for camping trips or long days on the boat. │ 2015-08-31 │
|
||||
│ US │ 488280 │ R1NK26SWS53B8Q │ B00D93OVF0 │ 662791300 │ Fosmon Micro USB Value Pack Bundle for Samsung Galaxy Exhilarate - Includes Home / Travel Charger, Car / Vehicle Charger and USB Cable │ Wireless │ 5 │ 0 │ 0 │ false │ true │ Five Stars │ Great for the price :-) │ 2015-08-31 │
|
||||
│ US │ 13334021 │ R11LOHEDYJALTN │ B00XVGJMDQ │ 421688488 │ iPhone 6 Case, Vofolen Impact Resistant Protective Shell iPhone 6S Wallet Cover Shockproof Rubber Bumper Case Anti-scratches Hard Cover Skin Card Slot Holder for iPhone 6 6S │ Wireless │ 5 │ 0 │ 0 │ false │ true │ Five Stars │ Great Case, better customer service! │ 2015-08-31 │
|
||||
│ US │ 27520697 │ R3ALQVQB2P9LA7 │ B00KQW1X1C │ 554285554 │ Nokia Lumia 630 RM-978 White Factory Unlocked - International Version No Warranty │ Wireless │ 4 │ 0 │ 0 │ false │ true │ Four Stars │ Easy to set up and use. Great functions for the price │ 2015-08-31 │
|
||||
│ US │ 48086021 │ R3MWLXLNO21PDQ │ B00IP1MQNK │ 488006702 │ Lumsing 10400mah external battery │ Wireless │ 5 │ 0 │ 0 │ false │ true │ Five Stars │ Works great │ 2015-08-31 │
|
||||
│ US │ 12738196 │ R2L15IS24CX0LI │ B00HVORET8 │ 389677711 │ iPhone 5S Battery Case - iPhone 5 Battery Case , Maxboost Atomic S [MFI Certified] External Protective Battery Charging Case Power Bank Charger All Versions of Apple iPhone 5/5S [Juice Battery Pack] │ Wireless │ 5 │ 0 │ 0 │ false │ true │ So far so good │ So far so good. It is essentially identical to the one it replaced from another company. That one stopped working after 7 months so I am a bit apprehensive about this one. │ 2015-08-31 │
|
||||
│ US │ 15867807 │ R1DJ8976WPWVZU │ B00HX3G6J6 │ 299654876 │ HTC One M8 Screen Protector, Skinomi TechSkin Full Coverage Screen Protector for HTC One M8 Clear HD Anti-Bubble Film │ Wireless │ 3 │ 0 │ 0 │ false │ true │ seems durable but these are always harder to get on ... │ seems durable but these are always harder to get on right than people make them out to be. also send to curl up at the edges after a while. with today's smartphones, you hardly need screen protectors anyway. │ 2015-08-31 │
|
||||
└─────────────┴─────────────┴────────────────┴────────────┴────────────────┴───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴──────────────────┴─────────────┴───────────────┴─────────────┴───────┴───────────────────┴─────────────────────────────────────────────────────────┴─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴─────────────┘
|
||||
```
|
||||
|
||||
:::note
|
||||
Normally you would not need to pass in the schema into the `s3` table function - ClickHouse can infer the names and data types of the columns. However, this particular dataset uses a non-standard tab-separated format, but the `s3` function seems to work fine with this non-standard format if you include the schema.
|
||||
:::
|
||||
|
||||
2. Let's define a new table named `amazon_reviews`. We'll optimize some of the column data types - and choose a primary key (the `ORDER BY` clause):
|
||||
|
||||
```sql
|
||||
CREATE TABLE amazon_reviews
|
||||
(
|
||||
review_date Date,
|
||||
marketplace LowCardinality(String),
|
||||
customer_id UInt64,
|
||||
review_id String,
|
||||
product_id String,
|
||||
product_parent UInt64,
|
||||
product_title String,
|
||||
product_category LowCardinality(String),
|
||||
star_rating UInt8,
|
||||
helpful_votes UInt32,
|
||||
total_votes UInt32,
|
||||
vine Bool,
|
||||
verified_purchase Bool,
|
||||
review_headline String,
|
||||
review_body String
|
||||
)
|
||||
ENGINE = MergeTree
|
||||
ORDER BY (marketplace, review_date, product_category);
|
||||
```
|
||||
|
||||
3. We are now ready to insert the data into ClickHouse. Before we do, check out the [list of files in the dataset](https://s3.amazonaws.com/amazon-reviews-pds/tsv/index.txt) and decide which ones you want to include.
|
||||
|
||||
4. We will insert all of the US reviews - which is about 151M rows. The following `INSERT` command uses the `s3Cluster` table function, which allows the processing of mulitple S3 files in parallel using all the nodes of your cluster. We also use a wildcard to insert any file that starts with the name `https://s3.amazonaws.com/amazon-reviews-pds/tsv/amazon_reviews_us_`:
|
||||
|
||||
```sql
|
||||
INSERT INTO amazon_reviews
|
||||
WITH
|
||||
transform(vine, ['Y','N'],[true, false]) AS vine,
|
||||
transform(verified_purchase, ['Y','N'],[true, false]) AS verified_purchase
|
||||
SELECT
|
||||
*
|
||||
FROM s3Cluster(
|
||||
'default',
|
||||
'https://s3.amazonaws.com/amazon-reviews-pds/tsv/amazon_reviews_us_*.tsv.gz',
|
||||
'TSVWithNames',
|
||||
'review_date Date,
|
||||
marketplace LowCardinality(String),
|
||||
customer_id UInt64,
|
||||
review_id String,
|
||||
product_id String,
|
||||
product_parent UInt64,
|
||||
product_title String,
|
||||
product_category LowCardinality(String),
|
||||
star_rating UInt8,
|
||||
helpful_votes UInt32,
|
||||
total_votes UInt32,
|
||||
vine FixedString(1),
|
||||
verified_purchase FixedString(1),
|
||||
review_headline String,
|
||||
review_body String'
|
||||
)
|
||||
SETTINGS input_format_allow_errors_num = 1000000;
|
||||
```
|
||||
|
||||
:::tip
|
||||
In ClickHouse Cloud, there is a cluster named `default`. Change `default` to the name of your cluster...or use the `s3` table function (instead of `s3Cluster`) if you do not have a cluster.
|
||||
:::
|
||||
|
||||
5. That query doesn't take long - within 5 minutes or so you should see all the rows inserted:
|
||||
|
||||
```sql
|
||||
SELECT formatReadableQuantity(count())
|
||||
FROM amazon_reviews
|
||||
```
|
||||
|
||||
```response
|
||||
┌─formatReadableQuantity(count())─┐
|
||||
│ 150.96 million │
|
||||
└─────────────────────────────────┘
|
||||
```
|
||||
|
||||
6. Let's see how much space our data is using:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
disk_name,
|
||||
formatReadableSize(sum(data_compressed_bytes) AS size) AS compressed,
|
||||
formatReadableSize(sum(data_uncompressed_bytes) AS usize) AS uncompressed,
|
||||
round(usize / size, 2) AS compr_rate,
|
||||
sum(rows) AS rows,
|
||||
count() AS part_count
|
||||
FROM system.parts
|
||||
WHERE (active = 1) AND (table = 'amazon_reviews')
|
||||
GROUP BY disk_name
|
||||
ORDER BY size DESC;
|
||||
```
|
||||
The original data was about 70G, but compressed in ClickHouse it takes up about 30G:
|
||||
|
||||
```response
|
||||
┌─disk_name─┬─compressed─┬─uncompressed─┬─compr_rate─┬──────rows─┬─part_count─┐
|
||||
│ s3disk │ 30.00 GiB │ 70.61 GiB │ 2.35 │ 150957260 │ 9 │
|
||||
└───────────┴────────────┴──────────────┴────────────┴───────────┴────────────┘
|
||||
```
|
||||
|
||||
7. Let's run some queries...here are the top 10 most-helpful reviews on Amazon:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
product_title,
|
||||
review_headline
|
||||
FROM amazon_reviews
|
||||
ORDER BY helpful_votes DESC
|
||||
LIMIT 10;
|
||||
```
|
||||
|
||||
Notice the query has to process all 151M rows, and it takes about 17 seconds:
|
||||
|
||||
```response
|
||||
┌─product_title────────────────────────────────────────────────────────────────────────────┬─review_headline───────────────────────────────────────────────────────┐
|
||||
│ Kindle: Amazon's Original Wireless Reading Device (1st generation) │ Why and how the Kindle changes everything │
|
||||
│ BIC Cristal For Her Ball Pen, 1.0mm, Black, 16ct (MSLP16-Blk) │ FINALLY! │
|
||||
│ The Mountain Kids 100% Cotton Three Wolf Moon T-Shirt │ Dual Function Design │
|
||||
│ Kindle Keyboard 3G, Free 3G + Wi-Fi, 6" E Ink Display │ Kindle vs. Nook (updated) │
|
||||
│ Kindle Fire HD 7", Dolby Audio, Dual-Band Wi-Fi │ You Get What You Pay For │
|
||||
│ Kindle Fire (Previous Generation - 1st) │ A great device WHEN you consider price and function, with a few flaws │
|
||||
│ Fifty Shades of Grey: Book One of the Fifty Shades Trilogy (Fifty Shades of Grey Series) │ Did a teenager write this??? │
|
||||
│ Wheelmate Laptop Steering Wheel Desk │ Perfect for an Starfleet Helmsman │
|
||||
│ Kindle Wireless Reading Device (6" Display, U.S. Wireless) │ BEWARE of the SIGNIFICANT DIFFERENCES between Kindle 1 and Kindle 2! │
|
||||
│ Tuscan Dairy Whole Vitamin D Milk, Gallon, 128 oz │ Make this your only stock and store │
|
||||
└──────────────────────────────────────────────────────────────────────────────────────────┴───────────────────────────────────────────────────────────────────────┘
|
||||
|
||||
10 rows in set. Elapsed: 17.595 sec. Processed 150.96 million rows, 15.36 GB (8.58 million rows/s., 872.89 MB/s.)
|
||||
```
|
||||
|
||||
8. Here are the top 10 products in Amazon with the most reviews:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
any(product_title),
|
||||
count()
|
||||
FROM amazon_reviews
|
||||
GROUP BY product_id
|
||||
ORDER BY 2 DESC
|
||||
LIMIT 10;
|
||||
```
|
||||
|
||||
```response
|
||||
┌─any(product_title)────────────────────────────┬─count()─┐
|
||||
│ Candy Crush Saga │ 50051 │
|
||||
│ The Secret Society® - Hidden Mystery │ 41255 │
|
||||
│ Google Chromecast HDMI Streaming Media Player │ 35977 │
|
||||
│ Minecraft │ 35129 │
|
||||
│ Bosch Season 1 │ 33610 │
|
||||
│ Gone Girl: A Novel │ 33240 │
|
||||
│ Subway Surfers │ 32328 │
|
||||
│ The Fault in Our Stars │ 30149 │
|
||||
│ Amazon.com eGift Cards │ 28879 │
|
||||
│ Crossy Road │ 28111 │
|
||||
└───────────────────────────────────────────────┴─────────┘
|
||||
|
||||
10 rows in set. Elapsed: 16.684 sec. Processed 195.05 million rows, 20.86 GB (11.69 million rows/s., 1.25 GB/s.)
|
||||
```
|
||||
|
||||
9. Here are the average review ratings per month for each product (an actual [Amazon job interview question](https://datalemur.com/questions/sql-avg-review-ratings)!):
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
toStartOfMonth(review_date) AS month,
|
||||
any(product_title),
|
||||
avg(star_rating) AS avg_stars
|
||||
FROM amazon_reviews
|
||||
GROUP BY
|
||||
month,
|
||||
product_id
|
||||
ORDER BY
|
||||
month DESC,
|
||||
product_id ASC
|
||||
LIMIT 20;
|
||||
```
|
||||
|
||||
It calculates all the monthly averages for each product, but we only returned 20 rows:
|
||||
|
||||
```response
|
||||
┌──────month─┬─any(product_title)──────────────────────────────────────────────────────────────────────┬─avg_stars─┐
|
||||
│ 2015-08-01 │ Mystiqueshapes Girls Ballet Tutu Neon Lime Green │ 4 │
|
||||
│ 2015-08-01 │ Adult Ballet Tutu Yellow │ 5 │
|
||||
│ 2015-08-01 │ The Way Things Work: An Illustrated Encyclopedia of Technology │ 5 │
|
||||
│ 2015-08-01 │ Hilda Boswell's Treasury of Poetry │ 5 │
|
||||
│ 2015-08-01 │ Treasury of Poetry │ 5 │
|
||||
│ 2015-08-01 │ Uncle Remus Stories │ 5 │
|
||||
│ 2015-08-01 │ The Book of Daniel │ 5 │
|
||||
│ 2015-08-01 │ Berenstains' B Book │ 5 │
|
||||
│ 2015-08-01 │ The High Hills (Brambly Hedge) │ 4.5 │
|
||||
│ 2015-08-01 │ Fuzzypeg Goes to School (The Little Grey Rabbit library) │ 5 │
|
||||
│ 2015-08-01 │ Dictionary in French: The Cat in the Hat (Beginner Series) │ 5 │
|
||||
│ 2015-08-01 │ Windfallen │ 5 │
|
||||
│ 2015-08-01 │ The Monk Who Sold His Ferrari: A Remarkable Story About Living Your Dreams │ 5 │
|
||||
│ 2015-08-01 │ Illustrissimi: The Letters of Pope John Paul I │ 5 │
|
||||
│ 2015-08-01 │ Social Contract: A Personal Inquiry into the Evolutionary Sources of Order and Disorder │ 5 │
|
||||
│ 2015-08-01 │ Mexico The Beautiful Cookbook: Authentic Recipes from the Regions of Mexico │ 4.5 │
|
||||
│ 2015-08-01 │ Alanbrooke │ 5 │
|
||||
│ 2015-08-01 │ Back to Cape Horn │ 4 │
|
||||
│ 2015-08-01 │ Ovett: An Autobiography (Willow books) │ 5 │
|
||||
│ 2015-08-01 │ The Birds of West Africa (Collins Field Guides) │ 4 │
|
||||
└────────────┴─────────────────────────────────────────────────────────────────────────────────────────┴───────────┘
|
||||
|
||||
20 rows in set. Elapsed: 52.827 sec. Processed 251.46 million rows, 35.26 GB (4.76 million rows/s., 667.55 MB/s.)
|
||||
```
|
||||
|
||||
10. Here are the total number of votes per product category. This query is fast because `product_category` is in the primary key:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
sum(total_votes),
|
||||
product_category
|
||||
FROM amazon_reviews
|
||||
GROUP BY product_category
|
||||
ORDER BY 1 DESC;
|
||||
```
|
||||
|
||||
```response
|
||||
┌─sum(total_votes)─┬─product_category─────────┐
|
||||
│ 103877874 │ Books │
|
||||
│ 25330411 │ Digital_Ebook_Purchase │
|
||||
│ 23065953 │ Video DVD │
|
||||
│ 18048069 │ Music │
|
||||
│ 17292294 │ Mobile_Apps │
|
||||
│ 15977124 │ Health & Personal Care │
|
||||
│ 13554090 │ PC │
|
||||
│ 13065746 │ Kitchen │
|
||||
│ 12537926 │ Home │
|
||||
│ 11067538 │ Beauty │
|
||||
│ 10418643 │ Wireless │
|
||||
│ 9089085 │ Toys │
|
||||
│ 9071484 │ Sports │
|
||||
│ 7335647 │ Electronics │
|
||||
│ 6885504 │ Apparel │
|
||||
│ 6710085 │ Video Games │
|
||||
│ 6556319 │ Camera │
|
||||
│ 6305478 │ Lawn and Garden │
|
||||
│ 5954422 │ Office Products │
|
||||
│ 5339437 │ Home Improvement │
|
||||
│ 5284343 │ Outdoors │
|
||||
│ 5125199 │ Pet Products │
|
||||
│ 4733251 │ Grocery │
|
||||
│ 4697750 │ Shoes │
|
||||
│ 4666487 │ Automotive │
|
||||
│ 4361518 │ Digital_Video_Download │
|
||||
│ 4033550 │ Tools │
|
||||
│ 3559010 │ Baby │
|
||||
│ 3317662 │ Home Entertainment │
|
||||
│ 2559501 │ Video │
|
||||
│ 2204328 │ Furniture │
|
||||
│ 2157587 │ Musical Instruments │
|
||||
│ 1881662 │ Software │
|
||||
│ 1676081 │ Jewelry │
|
||||
│ 1499945 │ Watches │
|
||||
│ 1224071 │ Digital_Music_Purchase │
|
||||
│ 847918 │ Luggage │
|
||||
│ 503939 │ Major Appliances │
|
||||
│ 392001 │ Digital_Video_Games │
|
||||
│ 348990 │ Personal_Care_Appliances │
|
||||
│ 321372 │ Digital_Software │
|
||||
│ 169585 │ Mobile_Electronics │
|
||||
│ 72970 │ Gift Card │
|
||||
└──────────────────┴──────────────────────────┘
|
||||
|
||||
43 rows in set. Elapsed: 0.423 sec. Processed 150.96 million rows, 756.20 MB (356.70 million rows/s., 1.79 GB/s.)
|
||||
```
|
||||
|
||||
11. Let's find the products with the word **"awful"** occurring most frequently in the review. This is a big task - over 151M strings have to be parsed looking for a single word:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
product_id,
|
||||
any(product_title),
|
||||
avg(star_rating),
|
||||
count() AS count
|
||||
FROM amazon_reviews
|
||||
WHERE position(review_body, 'awful') > 0
|
||||
GROUP BY product_id
|
||||
ORDER BY count DESC
|
||||
LIMIT 50;
|
||||
```
|
||||
|
||||
The query takes a couple of minutes, but the results are a fun read:
|
||||
|
||||
```response
|
||||
|
||||
┌─product_id─┬─any(product_title)───────────────────────────────────────────────────────────────────────┬───avg(star_rating)─┬─count─┐
|
||||
│ 0345803485 │ Fifty Shades of Grey: Book One of the Fifty Shades Trilogy (Fifty Shades of Grey Series) │ 1.3870967741935485 │ 248 │
|
||||
│ B007J4T2G8 │ Fifty Shades of Grey (Fifty Shades, Book 1) │ 1.4439834024896265 │ 241 │
|
||||
│ B006LSZECO │ Gone Girl: A Novel │ 2.2986425339366514 │ 221 │
|
||||
│ B00008OWZG │ St. Anger │ 1.6565656565656566 │ 198 │
|
||||
│ B00BD99JMW │ Allegiant (Divergent Trilogy, Book 3) │ 1.8342541436464088 │ 181 │
|
||||
│ B0000YUXI0 │ Mavala Switzerland Mavala Stop Nail Biting │ 4.473684210526316 │ 171 │
|
||||
│ B004S8F7QM │ Cards Against Humanity │ 4.753012048192771 │ 166 │
|
||||
│ 031606792X │ Breaking Dawn (The Twilight Saga, Book 4) │ 1.796875 │ 128 │
|
||||
│ 006202406X │ Allegiant (Divergent Series) │ 1.4242424242424243 │ 99 │
|
||||
│ B0051VVOB2 │ Kindle Fire (Previous Generation - 1st) │ 2.7448979591836733 │ 98 │
|
||||
│ B00I3MP3SG │ Pilot │ 1.8762886597938144 │ 97 │
|
||||
│ 030758836X │ Gone Girl │ 2.15625 │ 96 │
|
||||
│ B0009X29WK │ Precious Cat Ultra Premium Clumping Cat Litter │ 3.0759493670886076 │ 79 │
|
||||
│ B00JB3MVCW │ Noah │ 1.2027027027027026 │ 74 │
|
||||
│ B00BAXFECK │ The Goldfinch: A Novel (Pulitzer Prize for Fiction) │ 2.643835616438356 │ 73 │
|
||||
│ B00N28818A │ Amazon Prime Video │ 1.4305555555555556 │ 72 │
|
||||
│ B007FTE2VW │ SimCity - Limited Edition │ 1.2794117647058822 │ 68 │
|
||||
│ 0439023513 │ Mockingjay (The Hunger Games) │ 2.6417910447761193 │ 67 │
|
||||
│ B00178630A │ Diablo III - PC/Mac │ 1.671875 │ 64 │
|
||||
│ B000OCEWGW │ Liquid Ass │ 4.8125 │ 64 │
|
||||
│ B005ZOBNOI │ The Fault in Our Stars │ 4.316666666666666 │ 60 │
|
||||
│ B00L9B7IKE │ The Girl on the Train: A Novel │ 2.0677966101694913 │ 59 │
|
||||
│ B007S6Y6VS │ Garden of Life Raw Organic Meal │ 2.8793103448275863 │ 58 │
|
||||
│ B0064X7B4A │ Words With Friends │ 2.2413793103448274 │ 58 │
|
||||
│ B003WUYPPG │ Unbroken: A World War II Story of Survival, Resilience, and Redemption │ 4.620689655172414 │ 58 │
|
||||
│ B00006HBUJ │ Star Wars: Episode II - Attack of the Clones (Widescreen Edition) │ 2.2982456140350878 │ 57 │
|
||||
│ B000XUBFE2 │ The Book Thief │ 4.526315789473684 │ 57 │
|
||||
│ B0006399FS │ How to Dismantle an Atomic Bomb │ 1.9821428571428572 │ 56 │
|
||||
│ B003ZSJ212 │ Star Wars: The Complete Saga (Episodes I-VI) (Packaging May Vary) [Blu-ray] │ 2.309090909090909 │ 55 │
|
||||
│ 193700788X │ Dead Ever After (Sookie Stackhouse/True Blood) │ 1.5185185185185186 │ 54 │
|
||||
│ B004FYEZMQ │ Mass Effect 3 │ 2.056603773584906 │ 53 │
|
||||
│ B000CFYAMC │ The Room │ 3.9615384615384617 │ 52 │
|
||||
│ B0031JK95S │ Garden of Life Raw Organic Meal │ 3.3137254901960786 │ 51 │
|
||||
│ B0012JY4G4 │ Color Oops Hair Color Remover Extra Strength 1 Each │ 3.9019607843137254 │ 51 │
|
||||
│ B007VTVRFA │ SimCity - Limited Edition │ 1.2040816326530612 │ 49 │
|
||||
│ B00CE18P0K │ Pilot │ 1.7142857142857142 │ 49 │
|
||||
│ 0316015849 │ Twilight (The Twilight Saga, Book 1) │ 1.8979591836734695 │ 49 │
|
||||
│ B00DR0PDNE │ Google Chromecast HDMI Streaming Media Player │ 2.5416666666666665 │ 48 │
|
||||
│ B000056OWC │ The First Years: 4-Stage Bath System │ 1.2127659574468086 │ 47 │
|
||||
│ B007IXWKUK │ Fifty Shades Darker (Fifty Shades, Book 2) │ 1.6304347826086956 │ 46 │
|
||||
│ 1892112000 │ To Train Up a Child │ 1.4130434782608696 │ 46 │
|
||||
│ 043935806X │ Harry Potter and the Order of the Phoenix (Book 5) │ 3.977272727272727 │ 44 │
|
||||
│ B00BGO0Q9O │ Fitbit Flex Wireless Wristband with Sleep Function, Black │ 1.9318181818181819 │ 44 │
|
||||
│ B003XF1XOQ │ Mockingjay (Hunger Games Trilogy, Book 3) │ 2.772727272727273 │ 44 │
|
||||
│ B00DD2B52Y │ Spring Breakers │ 1.2093023255813953 │ 43 │
|
||||
│ B0064X7FVE │ The Weather Channel: Forecast, Radar & Alerts │ 1.5116279069767442 │ 43 │
|
||||
│ B0083PWAPW │ Kindle Fire HD 7", Dolby Audio, Dual-Band Wi-Fi │ 2.627906976744186 │ 43 │
|
||||
│ B00192KCQ0 │ Death Magnetic │ 3.5714285714285716 │ 42 │
|
||||
│ B007S6Y74O │ Garden of Life Raw Organic Meal │ 3.292682926829268 │ 41 │
|
||||
│ B0052QYLUM │ Infant Optics DXR-5 Portable Video Baby Monitor │ 2.1463414634146343 │ 41 │
|
||||
└────────────┴──────────────────────────────────────────────────────────────────────────────────────────┴────────────────────┴───────┘
|
||||
|
||||
50 rows in set. Elapsed: 60.052 sec. Processed 150.96 million rows, 68.93 GB (2.51 million rows/s., 1.15 GB/s.)
|
||||
```
|
||||
|
||||
12. We can run the same query again, except this time we search for **awesome** in the reviews:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
product_id,
|
||||
any(product_title),
|
||||
avg(star_rating),
|
||||
count() AS count
|
||||
FROM amazon_reviews
|
||||
WHERE position(review_body, 'awesome') > 0
|
||||
GROUP BY product_id
|
||||
ORDER BY count DESC
|
||||
LIMIT 50;
|
||||
```
|
||||
|
||||
It runs quite a bit faster - which means the cache is helping us out here:
|
||||
|
||||
```response
|
||||
|
||||
┌─product_id─┬─any(product_title)────────────────────────────────────────────────────┬───avg(star_rating)─┬─count─┐
|
||||
│ B00992CF6W │ Minecraft │ 4.848130353039482 │ 4787 │
|
||||
│ B009UX2YAC │ Subway Surfers │ 4.866720955483171 │ 3684 │
|
||||
│ B00QW8TYWO │ Crossy Road │ 4.935217903415784 │ 2547 │
|
||||
│ B00DJFIMW6 │ Minion Rush: Despicable Me Official Game │ 4.850450450450451 │ 2220 │
|
||||
│ B00AREIAI8 │ My Horse │ 4.865313653136531 │ 2168 │
|
||||
│ B00I8Q77Y0 │ Flappy Wings (not Flappy Bird) │ 4.8246561886051085 │ 2036 │
|
||||
│ B0054JZC6E │ 101-in-1 Games │ 4.792542016806722 │ 1904 │
|
||||
│ B00G5LQ5MU │ Escape The Titanic │ 4.724673710379117 │ 1609 │
|
||||
│ B0086700CM │ Temple Run │ 4.87636130685458 │ 1561 │
|
||||
│ B009HKL4B8 │ The Sims Freeplay │ 4.763942931258106 │ 1542 │
|
||||
│ B00I6IKSZ0 │ Pixel Gun 3D (Pocket Edition) - multiplayer shooter with skin creator │ 4.849894291754757 │ 1419 │
|
||||
│ B006OC2ANS │ BLOOD & GLORY │ 4.8561538461538465 │ 1300 │
|
||||
│ B00FATEJYE │ Injustice: Gods Among Us (Kindle Tablet Edition) │ 4.789265982636149 │ 1267 │
|
||||
│ B00B2V66VS │ Temple Run 2 │ 4.764705882352941 │ 1173 │
|
||||
│ B00JOT3HQ2 │ Geometry Dash Lite │ 4.909747292418772 │ 1108 │
|
||||
│ B00DUGCLY4 │ Guess The Emoji │ 4.813606710158434 │ 1073 │
|
||||
│ B00DR0PDNE │ Google Chromecast HDMI Streaming Media Player │ 4.607276119402985 │ 1072 │
|
||||
│ B00FAPF5U0 │ Candy Crush Saga │ 4.825757575757576 │ 1056 │
|
||||
│ B0051VVOB2 │ Kindle Fire (Previous Generation - 1st) │ 4.600407747196738 │ 981 │
|
||||
│ B007JPG04E │ FRONTLINE COMMANDO │ 4.8125 │ 912 │
|
||||
│ B00PTB7B34 │ Call of Duty®: Heroes │ 4.876404494382022 │ 890 │
|
||||
│ B00846GKTW │ Style Me Girl - Free 3D Fashion Dressup │ 4.785714285714286 │ 882 │
|
||||
│ B004S8F7QM │ Cards Against Humanity │ 4.931034482758621 │ 754 │
|
||||
│ B00FAX6XQC │ DEER HUNTER CLASSIC │ 4.700272479564033 │ 734 │
|
||||
│ B00PSGW79I │ Buddyman: Kick │ 4.888736263736264 │ 728 │
|
||||
│ B00CTQ6SIG │ The Simpsons: Tapped Out │ 4.793948126801153 │ 694 │
|
||||
│ B008JK6W5K │ Logo Quiz │ 4.782106782106782 │ 693 │
|
||||
│ B00EDTSKLU │ Geometry Dash │ 4.942028985507246 │ 690 │
|
||||
│ B00CSR2J9I │ Hill Climb Racing │ 4.880059970014993 │ 667 │
|
||||
│ B005ZXWMUS │ Netflix │ 4.722306525037936 │ 659 │
|
||||
│ B00CRFAAYC │ Fab Tattoo Artist FREE │ 4.907435508345979 │ 659 │
|
||||
│ B00DHQHQCE │ Battle Beach │ 4.863287250384024 │ 651 │
|
||||
│ B00BGA9WK2 │ PlayStation 4 500GB Console [Old Model] │ 4.688751926040061 │ 649 │
|
||||
│ B008Y7SMQU │ Logo Quiz - Fun Plus Free │ 4.7888 │ 625 │
|
||||
│ B0083PWAPW │ Kindle Fire HD 7", Dolby Audio, Dual-Band Wi-Fi │ 4.593900481540931 │ 623 │
|
||||
│ B008XG1X18 │ Pinterest │ 4.8148760330578515 │ 605 │
|
||||
│ B007SYWFRM │ Ice Age Village │ 4.8566666666666665 │ 600 │
|
||||
│ B00K7WGUKA │ Don't Tap The White Tile (Piano Tiles) │ 4.922689075630252 │ 595 │
|
||||
│ B00BWYQ9YE │ Kindle Fire HDX 7", HDX Display (Previous Generation - 3rd) │ 4.649913344887349 │ 577 │
|
||||
│ B00IZLM8MY │ High School Story │ 4.840425531914893 │ 564 │
|
||||
│ B004MC8CA2 │ Bible │ 4.884476534296029 │ 554 │
|
||||
│ B00KNWYDU8 │ Dragon City │ 4.861111111111111 │ 540 │
|
||||
│ B009ZKSPDK │ Survivalcraft │ 4.738317757009346 │ 535 │
|
||||
│ B00A4O6NMG │ My Singing Monsters │ 4.845559845559846 │ 518 │
|
||||
│ B002MQYOFW │ The Hunger Games (Hunger Games Trilogy, Book 1) │ 4.846899224806202 │ 516 │
|
||||
│ B005ZFOOE8 │ iHeartRadio – Free Music & Internet Radio │ 4.837301587301587 │ 504 │
|
||||
│ B00AIUUXHC │ Hungry Shark Evolution │ 4.846311475409836 │ 488 │
|
||||
│ B00E8KLWB4 │ The Secret Society® - Hidden Mystery │ 4.669438669438669 │ 481 │
|
||||
│ B006D1ONE4 │ Where's My Water? │ 4.916317991631799 │ 478 │
|
||||
│ B00G6ZTM3Y │ Terraria │ 4.728421052631579 │ 475 │
|
||||
└────────────┴───────────────────────────────────────────────────────────────────────┴────────────────────┴───────┘
|
||||
|
||||
50 rows in set. Elapsed: 33.954 sec. Processed 150.96 million rows, 68.95 GB (4.45 million rows/s., 2.03 GB/s.)
|
||||
```
|
||||
@ -0,0 +1,172 @@
|
||||
---
|
||||
slug: /en/getting-started/example-datasets/environmental-sensors
|
||||
sidebar_label: Environmental Sensors Data
|
||||
---
|
||||
|
||||
# Environmental Sensors Data
|
||||
|
||||
[Sensor.Community](https://sensor.community/en/) is a contributors-driven global sensor network that creates Open Environmental Data. The data is collected from sensors all over the globe. Anyone can purchase a sensor and place it wherever they like. The APIs to download the data is in [GitHub](https://github.com/opendata-stuttgart/meta/wiki/APIs) and the data is freely available under the [Database Contents License (DbCL)](https://opendatacommons.org/licenses/dbcl/1-0/).
|
||||
|
||||
:::important
|
||||
The dataset has over 20 billion records, so be careful just copying-and-pasting the commands below unless your resources can handle that type of volume. The commands below were executed on a **Production** instance of [ClickHouse Cloud](https://clickhouse.cloud).
|
||||
:::
|
||||
|
||||
1. The data is in S3, so we can use the `s3` table function to create a table from the files. We can also query the data in place. Let's look at a few rows before attempting to insert it into ClickHouse:
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM s3(
|
||||
'https://clickhouse-public-datasets.s3.eu-central-1.amazonaws.com/sensors/monthly/2019-06_bmp180.csv.zst',
|
||||
'CSVWithNames'
|
||||
)
|
||||
LIMIT 10
|
||||
SETTINGS format_csv_delimiter = ';';
|
||||
```
|
||||
|
||||
The data is in CSV files but uses a semi-colon for the delimiter. The rows look like:
|
||||
|
||||
```response
|
||||
┌─sensor_id─┬─sensor_type─┬─location─┬────lat─┬────lon─┬─timestamp───────────┬──pressure─┬─altitude─┬─pressure_sealevel─┬─temperature─┐
|
||||
│ 9119 │ BMP180 │ 4594 │ 50.994 │ 7.126 │ 2019-06-01T00:00:00 │ 101471 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 19.9 │
|
||||
│ 21210 │ BMP180 │ 10762 │ 42.206 │ 25.326 │ 2019-06-01T00:00:00 │ 99525 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 19.3 │
|
||||
│ 19660 │ BMP180 │ 9978 │ 52.434 │ 17.056 │ 2019-06-01T00:00:04 │ 101570 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 15.3 │
|
||||
│ 12126 │ BMP180 │ 6126 │ 57.908 │ 16.49 │ 2019-06-01T00:00:05 │ 101802.56 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 8.07 │
|
||||
│ 15845 │ BMP180 │ 8022 │ 52.498 │ 13.466 │ 2019-06-01T00:00:05 │ 101878 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 23 │
|
||||
│ 16415 │ BMP180 │ 8316 │ 49.312 │ 6.744 │ 2019-06-01T00:00:06 │ 100176 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 14.7 │
|
||||
│ 7389 │ BMP180 │ 3735 │ 50.136 │ 11.062 │ 2019-06-01T00:00:06 │ 98905 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 12.1 │
|
||||
│ 13199 │ BMP180 │ 6664 │ 52.514 │ 13.44 │ 2019-06-01T00:00:07 │ 101855.54 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 19.74 │
|
||||
│ 12753 │ BMP180 │ 6440 │ 44.616 │ 2.032 │ 2019-06-01T00:00:07 │ 99475 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 17 │
|
||||
│ 16956 │ BMP180 │ 8594 │ 52.052 │ 8.354 │ 2019-06-01T00:00:08 │ 101322 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 17.2 │
|
||||
└───────────┴─────────────┴──────────┴────────┴───────┴─────────────────────┴──────────┴──────────┴───────────────────┴─────────────┘
|
||||
```
|
||||
|
||||
2. We will use the following `MergeTree` table to store the data in ClickHouse:
|
||||
|
||||
```sql
|
||||
CREATE TABLE sensors
|
||||
(
|
||||
sensor_id UInt16,
|
||||
sensor_type Enum('BME280', 'BMP180', 'BMP280', 'DHT22', 'DS18B20', 'HPM', 'HTU21D', 'PMS1003', 'PMS3003', 'PMS5003', 'PMS6003', 'PMS7003', 'PPD42NS', 'SDS011'),
|
||||
location UInt32,
|
||||
lat Float32,
|
||||
lon Float32,
|
||||
timestamp DateTime,
|
||||
P1 Float32,
|
||||
P2 Float32,
|
||||
P0 Float32,
|
||||
durP1 Float32,
|
||||
ratioP1 Float32,
|
||||
durP2 Float32,
|
||||
ratioP2 Float32,
|
||||
pressure Float32,
|
||||
altitude Float32,
|
||||
pressure_sealevel Float32,
|
||||
temperature Float32,
|
||||
humidity Float32,
|
||||
date Date MATERIALIZED toDate(timestamp)
|
||||
)
|
||||
ENGINE = MergeTree
|
||||
ORDER BY (timestamp, sensor_id);
|
||||
```
|
||||
|
||||
3. ClickHouse Cloud services have a cluster named `default`. We will use the `s3Cluster` table function, which reads S3 files in parallel from the nodes in your cluster. (If you do not have a cluster, just use the `s3` function and remove the cluster name.)
|
||||
|
||||
This query will take a while - it's about 1.67T of data uncompressed:
|
||||
|
||||
```sql
|
||||
INSERT INTO sensors
|
||||
SELECT *
|
||||
FROM s3Cluster(
|
||||
'default',
|
||||
'https://clickhouse-public-datasets.s3.amazonaws.com/sensors/monthly/*.csv.zst',
|
||||
'CSVWithNames',
|
||||
$$ sensor_id UInt16,
|
||||
sensor_type String,
|
||||
location UInt32,
|
||||
lat Float32,
|
||||
lon Float32,
|
||||
timestamp DateTime,
|
||||
P1 Float32,
|
||||
P2 Float32,
|
||||
P0 Float32,
|
||||
durP1 Float32,
|
||||
ratioP1 Float32,
|
||||
durP2 Float32,
|
||||
ratioP2 Float32,
|
||||
pressure Float32,
|
||||
altitude Float32,
|
||||
pressure_sealevel Float32,
|
||||
temperature Float32,
|
||||
humidity Float32 $$
|
||||
)
|
||||
SETTINGS
|
||||
format_csv_delimiter = ';',
|
||||
input_format_allow_errors_ratio = '0.5',
|
||||
input_format_allow_errors_num = 10000,
|
||||
input_format_parallel_parsing = 0,
|
||||
date_time_input_format = 'best_effort',
|
||||
max_insert_threads = 32,
|
||||
parallel_distributed_insert_select = 1;
|
||||
```
|
||||
|
||||
Here is the response - showing the number of rows and the speed of processing. It is input at a rate of over 6M rows per second!
|
||||
|
||||
```response
|
||||
0 rows in set. Elapsed: 3419.330 sec. Processed 20.69 billion rows, 1.67 TB (6.05 million rows/s., 488.52 MB/s.)
|
||||
```
|
||||
|
||||
4. Let's see how much storage disk is needed for the `sensors` table:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
disk_name,
|
||||
formatReadableSize(sum(data_compressed_bytes) AS size) AS compressed,
|
||||
formatReadableSize(sum(data_uncompressed_bytes) AS usize) AS uncompressed,
|
||||
round(usize / size, 2) AS compr_rate,
|
||||
sum(rows) AS rows,
|
||||
count() AS part_count
|
||||
FROM system.parts
|
||||
WHERE (active = 1) AND (table = 'sensors')
|
||||
GROUP BY
|
||||
disk_name
|
||||
ORDER BY size DESC;
|
||||
```
|
||||
|
||||
The 1.67T is compressed down to 310 GiB, and there are 20.69 billion rows:
|
||||
|
||||
```response
|
||||
┌─disk_name─┬─compressed─┬─uncompressed─┬─compr_rate─┬────────rows─┬─part_count─┐
|
||||
│ s3disk │ 310.21 GiB │ 1.30 TiB │ 4.29 │ 20693971809 │ 472 │
|
||||
└───────────┴────────────┴──────────────┴────────────┴─────────────┴────────────┘
|
||||
```
|
||||
|
||||
5. Let's analyze the data now that it's in ClickHouse. Notice the quantity of data increases over time as more sensors are deployed:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
date,
|
||||
count()
|
||||
FROM sensors
|
||||
GROUP BY date
|
||||
ORDER BY date ASC;
|
||||
```
|
||||
|
||||
We can create a chart in the SQL Console to visualize the results:
|
||||
|
||||

|
||||
|
||||
6. This query counts the number of overly hot and humid days:
|
||||
|
||||
```sql
|
||||
WITH
|
||||
toYYYYMMDD(timestamp) AS day
|
||||
SELECT day, count() FROM sensors
|
||||
WHERE temperature >= 40 AND temperature <= 50 AND humidity >= 90
|
||||
GROUP BY day
|
||||
ORDER BY day asc;
|
||||
```
|
||||
|
||||
Here's a visualization of the result:
|
||||
|
||||

|
||||
|
||||
BIN
docs/en/getting-started/example-datasets/images/sensors_01.png
Normal file
BIN
docs/en/getting-started/example-datasets/images/sensors_01.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 418 KiB |
BIN
docs/en/getting-started/example-datasets/images/sensors_02.png
Normal file
BIN
docs/en/getting-started/example-datasets/images/sensors_02.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 204 KiB |
@ -67,7 +67,8 @@ CREATE TABLE youtube
|
||||
(
|
||||
`id` String,
|
||||
`fetch_date` DateTime,
|
||||
`upload_date` String,
|
||||
`upload_date_str` String,
|
||||
`upload_date` Date,
|
||||
`title` String,
|
||||
`uploader_id` String,
|
||||
`uploader` String,
|
||||
@ -87,7 +88,7 @@ CREATE TABLE youtube
|
||||
`video_badges` String
|
||||
)
|
||||
ENGINE = MergeTree
|
||||
ORDER BY (upload_date, uploader);
|
||||
ORDER BY (uploader, upload_date);
|
||||
```
|
||||
|
||||
3. The following command streams the records from the S3 files into the `youtube` table.
|
||||
@ -101,8 +102,9 @@ INSERT INTO youtube
|
||||
SETTINGS input_format_null_as_default = 1
|
||||
SELECT
|
||||
id,
|
||||
parseDateTimeBestEffortUS(toString(fetch_date)) AS fetch_date,
|
||||
upload_date,
|
||||
parseDateTimeBestEffortUSOrZero(toString(fetch_date)) AS fetch_date,
|
||||
upload_date AS upload_date_str,
|
||||
toDate(parseDateTimeBestEffortUSOrZero(upload_date::String)) AS upload_date,
|
||||
ifNull(title, '') AS title,
|
||||
uploader_id,
|
||||
ifNull(uploader, '') AS uploader,
|
||||
@ -124,10 +126,23 @@ FROM s3Cluster(
|
||||
'default',
|
||||
'https://clickhouse-public-datasets.s3.amazonaws.com/youtube/original/files/*.zst',
|
||||
'JSONLines'
|
||||
);
|
||||
)
|
||||
SETTINGS
|
||||
max_download_threads = 24,
|
||||
max_insert_threads = 64,
|
||||
max_insert_block_size = 100000000,
|
||||
min_insert_block_size_rows = 100000000,
|
||||
min_insert_block_size_bytes = 500000000;
|
||||
```
|
||||
|
||||
4. Open a new tab in the SQL Console of ClickHouse Cloud (or a new `clickhouse-client` window) and watch the count increase. It will take a while to insert 4.56B rows, depending on your server resources. (Withtout any tweaking of settings, it takes about 4.5 hours.)
|
||||
Some comments about our `INSERT` command:
|
||||
|
||||
- The `parseDateTimeBestEffortUSOrZero` function is handy when the incoming date fields may not be in the proper format. If `fetch_date` does not get parsed properly, it will be set to `0`
|
||||
- The `upload_date` column contains valid dates, but it also contains strings like "4 hours ago" - which is certainly not a valid date. We decided to store the original value in `upload_date_str` and attempt to parse it with `toDate(parseDateTimeBestEffortUSOrZero(upload_date::String))`. If the parsing fails we just get `0`
|
||||
- We used `ifNull` to avoid getting `NULL` values in our table. If an incoming value is `NULL`, the `ifNull` function is setting the value to an empty string
|
||||
- It takes a long time to download the data, so we added a `SETTINGS` clause to spread out the work over more threads while making sure the block sizes stayed fairly large
|
||||
|
||||
4. Open a new tab in the SQL Console of ClickHouse Cloud (or a new `clickhouse-client` window) and watch the count increase. It will take a while to insert 4.56B rows, depending on your server resources. (Without any tweaking of settings, it takes about 4.5 hours.)
|
||||
|
||||
```sql
|
||||
SELECT formatReadableQuantity(count())
|
||||
@ -200,7 +215,7 @@ FROM youtube
|
||||
WHERE (title ILIKE '%ClickHouse%') OR (description ILIKE '%ClickHouse%')
|
||||
ORDER BY
|
||||
like_count DESC,
|
||||
view_count DESC
|
||||
view_count DESC;
|
||||
```
|
||||
|
||||
This query has to process every row, and also parse through two columns of strings. Even then, we get decent performance at 4.15M rows/second:
|
||||
@ -217,3 +232,264 @@ The results look like:
|
||||
│ 8710 │ 62 │ 4 │ https://youtu.be/PeV1mC2z--M │ What is JDBC DriverManager? | JDBC │
|
||||
│ 3534 │ 62 │ 1 │ https://youtu.be/8nWRhK9gw10 │ CLICKHOUSE - Arquitetura Modular │
|
||||
```
|
||||
|
||||
## Questions
|
||||
|
||||
### If someone disables comments does it lower the chance someone will actually click like or dislike?
|
||||
|
||||
When commenting is disabled, are people more likely to like or dislike to express their feelings about a video?
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
concat('< ', formatReadableQuantity(view_range)) AS views,
|
||||
is_comments_enabled,
|
||||
total_clicks / num_views AS prob_like_dislike
|
||||
FROM
|
||||
(
|
||||
SELECT
|
||||
is_comments_enabled,
|
||||
power(10, CEILING(log10(view_count + 1))) AS view_range,
|
||||
sum(like_count + dislike_count) AS total_clicks,
|
||||
sum(view_count) AS num_views
|
||||
FROM youtube
|
||||
GROUP BY
|
||||
view_range,
|
||||
is_comments_enabled
|
||||
) WHERE view_range > 1
|
||||
ORDER BY
|
||||
is_comments_enabled ASC,
|
||||
num_views ASC;
|
||||
```
|
||||
|
||||
```response
|
||||
┌─views─────────────┬─is_comments_enabled─┬────prob_like_dislike─┐
|
||||
│ < 10.00 │ false │ 0.08224180712685371 │
|
||||
│ < 100.00 │ false │ 0.06346337759167248 │
|
||||
│ < 1.00 thousand │ false │ 0.03201883652987105 │
|
||||
│ < 10.00 thousand │ false │ 0.01716073540410903 │
|
||||
│ < 10.00 billion │ false │ 0.004555639481829971 │
|
||||
│ < 100.00 thousand │ false │ 0.01293351460515323 │
|
||||
│ < 1.00 billion │ false │ 0.004761811192464957 │
|
||||
│ < 1.00 million │ false │ 0.010472604018980551 │
|
||||
│ < 10.00 million │ false │ 0.00788902538420125 │
|
||||
│ < 100.00 million │ false │ 0.00579152804250582 │
|
||||
│ < 10.00 │ true │ 0.09819517478134059 │
|
||||
│ < 100.00 │ true │ 0.07403784478585775 │
|
||||
│ < 1.00 thousand │ true │ 0.03846294910067627 │
|
||||
│ < 10.00 billion │ true │ 0.005615217329358215 │
|
||||
│ < 10.00 thousand │ true │ 0.02505881391701455 │
|
||||
│ < 1.00 billion │ true │ 0.007434998802482997 │
|
||||
│ < 100.00 thousand │ true │ 0.022694648130822004 │
|
||||
│ < 100.00 million │ true │ 0.011761563746575625 │
|
||||
│ < 1.00 million │ true │ 0.020776022304589435 │
|
||||
│ < 10.00 million │ true │ 0.016917095718089584 │
|
||||
└───────────────────┴─────────────────────┴──────────────────────┘
|
||||
|
||||
22 rows in set. Elapsed: 8.460 sec. Processed 4.56 billion rows, 77.48 GB (538.73 million rows/s., 9.16 GB/s.)
|
||||
```
|
||||
|
||||
Enabling comments seems to be correlated with a higher rate of engagement.
|
||||
|
||||
|
||||
### How does the number of videos change over time - notable events?
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
toStartOfMonth(toDateTime(upload_date)) AS month,
|
||||
uniq(uploader_id) AS uploaders,
|
||||
count() as num_videos,
|
||||
sum(view_count) as view_count
|
||||
FROM youtube
|
||||
GROUP BY month
|
||||
ORDER BY month ASC;
|
||||
```
|
||||
|
||||
```response
|
||||
┌──────month─┬─uploaders─┬─num_videos─┬───view_count─┐
|
||||
│ 2005-04-01 │ 5 │ 6 │ 213597737 │
|
||||
│ 2005-05-01 │ 6 │ 9 │ 2944005 │
|
||||
│ 2005-06-01 │ 165 │ 351 │ 18624981 │
|
||||
│ 2005-07-01 │ 395 │ 1168 │ 94164872 │
|
||||
│ 2005-08-01 │ 1171 │ 3128 │ 124540774 │
|
||||
│ 2005-09-01 │ 2418 │ 5206 │ 475536249 │
|
||||
│ 2005-10-01 │ 6750 │ 13747 │ 737593613 │
|
||||
│ 2005-11-01 │ 13706 │ 28078 │ 1896116976 │
|
||||
│ 2005-12-01 │ 24756 │ 49885 │ 2478418930 │
|
||||
│ 2006-01-01 │ 49992 │ 100447 │ 4532656581 │
|
||||
│ 2006-02-01 │ 67882 │ 138485 │ 5677516317 │
|
||||
│ 2006-03-01 │ 103358 │ 212237 │ 8430301366 │
|
||||
│ 2006-04-01 │ 114615 │ 234174 │ 9980760440 │
|
||||
│ 2006-05-01 │ 152682 │ 332076 │ 14129117212 │
|
||||
│ 2006-06-01 │ 193962 │ 429538 │ 17014143263 │
|
||||
│ 2006-07-01 │ 234401 │ 530311 │ 18721143410 │
|
||||
│ 2006-08-01 │ 281280 │ 614128 │ 20473502342 │
|
||||
│ 2006-09-01 │ 312434 │ 679906 │ 23158422265 │
|
||||
│ 2006-10-01 │ 404873 │ 897590 │ 27357846117 │
|
||||
```
|
||||
|
||||
A spike of uploaders [around covid is noticeable](https://www.theverge.com/2020/3/27/21197642/youtube-with-me-style-videos-views-coronavirus-cook-workout-study-home-beauty).
|
||||
|
||||
|
||||
### More subtitiles over time and when
|
||||
|
||||
With advances in speech recognition, it’s easier than ever to create subtitles for video with youtube adding auto-captioning in late 2009 - was the jump then?
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
toStartOfMonth(upload_date) AS month,
|
||||
countIf(has_subtitles) / count() AS percent_subtitles,
|
||||
percent_subtitles - any(percent_subtitles) OVER (
|
||||
ORDER BY month ASC ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING
|
||||
) AS previous
|
||||
FROM youtube
|
||||
GROUP BY month
|
||||
ORDER BY month ASC;
|
||||
```
|
||||
|
||||
```response
|
||||
┌──────month─┬───percent_subtitles─┬────────────────previous─┐
|
||||
│ 2015-01-01 │ 0.2652653881082824 │ 0.2652653881082824 │
|
||||
│ 2015-02-01 │ 0.3147556050309162 │ 0.049490216922633834 │
|
||||
│ 2015-03-01 │ 0.32460464492371877 │ 0.009849039892802558 │
|
||||
│ 2015-04-01 │ 0.33471963051468445 │ 0.010114985590965686 │
|
||||
│ 2015-05-01 │ 0.3168087575501062 │ -0.017910872964578273 │
|
||||
│ 2015-06-01 │ 0.3162609788438222 │ -0.0005477787062839745 │
|
||||
│ 2015-07-01 │ 0.31828767677518033 │ 0.0020266979313581235 │
|
||||
│ 2015-08-01 │ 0.3045551564286859 │ -0.013732520346494415 │
|
||||
│ 2015-09-01 │ 0.311221133995152 │ 0.006665977566466086 │
|
||||
│ 2015-10-01 │ 0.30574870926812175 │ -0.005472424727030245 │
|
||||
│ 2015-11-01 │ 0.31125409712077234 │ 0.0055053878526505895 │
|
||||
│ 2015-12-01 │ 0.3190967954651779 │ 0.007842698344405541 │
|
||||
│ 2016-01-01 │ 0.32636021432496176 │ 0.007263418859783877 │
|
||||
|
||||
```
|
||||
|
||||
The data results show a spike in 2009. Apparently at that, time YouTube was removing their community captions feature, which allowed you to upload captions for other people's video.
|
||||
This prompted a very successful campaign to have creators add captions to their videos for hard of hearing and deaf viewers.
|
||||
|
||||
|
||||
### Top uploaders over time
|
||||
|
||||
```sql
|
||||
WITH uploaders AS
|
||||
(
|
||||
SELECT uploader
|
||||
FROM youtube
|
||||
GROUP BY uploader
|
||||
ORDER BY sum(view_count) DESC
|
||||
LIMIT 10
|
||||
)
|
||||
SELECT
|
||||
month,
|
||||
uploader,
|
||||
sum(view_count) AS total_views,
|
||||
avg(dislike_count / like_count) AS like_to_dislike_ratio
|
||||
FROM youtube
|
||||
WHERE uploader IN (uploaders)
|
||||
GROUP BY
|
||||
toStartOfMonth(upload_date) AS month,
|
||||
uploader
|
||||
ORDER BY
|
||||
month ASC,
|
||||
total_views DESC;
|
||||
```
|
||||
|
||||
```response
|
||||
┌──────month─┬─uploader───────────────────┬─total_views─┬─like_to_dislike_ratio─┐
|
||||
│ 1970-01-01 │ T-Series │ 10957099 │ 0.022784656361208206 │
|
||||
│ 1970-01-01 │ Ryan's World │ 0 │ 0.003035559410234172 │
|
||||
│ 1970-01-01 │ SET India │ 0 │ nan │
|
||||
│ 2006-09-01 │ Cocomelon - Nursery Rhymes │ 256406497 │ 0.7005566715978622 │
|
||||
│ 2007-06-01 │ Cocomelon - Nursery Rhymes │ 33641320 │ 0.7088650914344298 │
|
||||
│ 2008-02-01 │ WWE │ 43733469 │ 0.07198856488734842 │
|
||||
│ 2008-03-01 │ WWE │ 16514541 │ 0.1230603715431997 │
|
||||
│ 2008-04-01 │ WWE │ 5907295 │ 0.2089399470159618 │
|
||||
│ 2008-05-01 │ WWE │ 7779627 │ 0.09101676560436774 │
|
||||
│ 2008-06-01 │ WWE │ 7018780 │ 0.0974184753155297 │
|
||||
│ 2008-07-01 │ WWE │ 4686447 │ 0.1263845422065158 │
|
||||
│ 2008-08-01 │ WWE │ 4514312 │ 0.08384574274791441 │
|
||||
│ 2008-09-01 │ WWE │ 3717092 │ 0.07872802579349912 │
|
||||
```
|
||||
|
||||
### How do like ratio changes as views go up?
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
concat('< ', formatReadableQuantity(view_range)) AS view_range,
|
||||
is_comments_enabled,
|
||||
round(like_ratio, 2) AS like_ratio
|
||||
FROM
|
||||
(
|
||||
SELECT
|
||||
power(10, CEILING(log10(view_count + 1))) as view_range,
|
||||
is_comments_enabled,
|
||||
avg(like_count / dislike_count) as like_ratio
|
||||
FROM youtube WHERE dislike_count > 0
|
||||
GROUP BY
|
||||
view_range,
|
||||
is_comments_enabled HAVING view_range > 1
|
||||
ORDER BY
|
||||
view_range ASC,
|
||||
is_comments_enabled ASC
|
||||
);
|
||||
```
|
||||
|
||||
```response
|
||||
┌─view_range────────┬─is_comments_enabled─┬─like_ratio─┐
|
||||
│ < 10.00 │ false │ 0.66 │
|
||||
│ < 10.00 │ true │ 0.66 │
|
||||
│ < 100.00 │ false │ 3 │
|
||||
│ < 100.00 │ true │ 3.95 │
|
||||
│ < 1.00 thousand │ false │ 8.45 │
|
||||
│ < 1.00 thousand │ true │ 13.07 │
|
||||
│ < 10.00 thousand │ false │ 18.57 │
|
||||
│ < 10.00 thousand │ true │ 30.92 │
|
||||
│ < 100.00 thousand │ false │ 23.55 │
|
||||
│ < 100.00 thousand │ true │ 42.13 │
|
||||
│ < 1.00 million │ false │ 19.23 │
|
||||
│ < 1.00 million │ true │ 37.86 │
|
||||
│ < 10.00 million │ false │ 12.13 │
|
||||
│ < 10.00 million │ true │ 30.72 │
|
||||
│ < 100.00 million │ false │ 6.67 │
|
||||
│ < 100.00 million │ true │ 23.32 │
|
||||
│ < 1.00 billion │ false │ 3.08 │
|
||||
│ < 1.00 billion │ true │ 20.69 │
|
||||
│ < 10.00 billion │ false │ 1.77 │
|
||||
│ < 10.00 billion │ true │ 19.5 │
|
||||
└───────────────────┴─────────────────────┴────────────┘
|
||||
```
|
||||
|
||||
### How are views distributed?
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
labels AS percentile,
|
||||
round(quantiles) AS views
|
||||
FROM
|
||||
(
|
||||
SELECT
|
||||
quantiles(0.999, 0.99, 0.95, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1)(view_count) AS quantiles,
|
||||
['99.9th', '99th', '95th', '90th', '80th', '70th','60th', '50th', '40th', '30th', '20th', '10th'] AS labels
|
||||
FROM youtube
|
||||
)
|
||||
ARRAY JOIN
|
||||
quantiles,
|
||||
labels;
|
||||
```
|
||||
|
||||
```response
|
||||
┌─percentile─┬───views─┐
|
||||
│ 99.9th │ 1216624 │
|
||||
│ 99th │ 143519 │
|
||||
│ 95th │ 13542 │
|
||||
│ 90th │ 4054 │
|
||||
│ 80th │ 950 │
|
||||
│ 70th │ 363 │
|
||||
│ 60th │ 177 │
|
||||
│ 50th │ 97 │
|
||||
│ 40th │ 57 │
|
||||
│ 30th │ 32 │
|
||||
│ 20th │ 16 │
|
||||
│ 10th │ 6 │
|
||||
└────────────┴─────────┘
|
||||
```
|
||||
@ -1818,15 +1818,19 @@ The table below shows supported data types and how they match ClickHouse [data t
|
||||
| `bytes`, `string`, `fixed` | [FixedString(N)](/docs/en/sql-reference/data-types/fixedstring.md) | `fixed(N)` |
|
||||
| `enum` | [Enum(8\16)](/docs/en/sql-reference/data-types/enum.md) | `enum` |
|
||||
| `array(T)` | [Array(T)](/docs/en/sql-reference/data-types/array.md) | `array(T)` |
|
||||
| `map(V, K)` | [Map(V, K)](/docs/en/sql-reference/data-types/map.md) | `map(string, K)` |
|
||||
| `union(null, T)`, `union(T, null)` | [Nullable(T)](/docs/en/sql-reference/data-types/date.md) | `union(null, T)` |
|
||||
| `null` | [Nullable(Nothing)](/docs/en/sql-reference/data-types/special-data-types/nothing.md) | `null` |
|
||||
| `int (date)` \** | [Date](/docs/en/sql-reference/data-types/date.md), [Date32](docs/en/sql-reference/data-types/date32.md) | `int (date)` \** |
|
||||
| `long (timestamp-millis)` \** | [DateTime64(3)](/docs/en/sql-reference/data-types/datetime.md) | `long (timestamp-millis)` \** |
|
||||
| `long (timestamp-micros)` \** | [DateTime64(6)](/docs/en/sql-reference/data-types/datetime.md) | `long (timestamp-micros)` \** |
|
||||
| `bytes (decimal)` \** | [DateTime64(N)](/docs/en/sql-reference/data-types/datetime.md) | `bytes (decimal)` \** |
|
||||
| `int` | [IPv4](/docs/en/sql-reference/data-types/domains/ipv4.md) | `int` |
|
||||
| `fixed(16)` | [IPv6](/docs/en/sql-reference/data-types/domains/ipv6.md) | `fixed(16)` |
|
||||
| `bytes (decimal)` \** | [Decimal(P, S)](/docs/en/sql-reference/data-types/decimal.md) | `bytes (decimal)` \** |
|
||||
| `string (uuid)` \** | [UUID](/docs/en/sql-reference/data-types/uuid.md) | `string (uuid)` \** |
|
||||
| `fixed(16)` | [Int128/UInt128](/docs/en/sql-reference/data-types/int-uint.md) | `fixed(16)` |
|
||||
| `fixed(32)` | [Int256/UInt256](/docs/en/sql-reference/data-types/int-uint.md) | `fixed(32)` |
|
||||
|
||||
|
||||
\* `bytes` is default, controlled by [output_format_avro_string_column_pattern](/docs/en/operations/settings/settings-formats.md/#output_format_avro_string_column_pattern)
|
||||
@ -2282,7 +2286,7 @@ ClickHouse supports reading and writing [MessagePack](https://msgpack.org/) data
|
||||
### Data Types Matching {#data-types-matching-msgpack}
|
||||
|
||||
| MessagePack data type (`INSERT`) | ClickHouse data type | MessagePack data type (`SELECT`) |
|
||||
|--------------------------------------------------------------------|-----------------------------------------------------------------|------------------------------------|
|
||||
|--------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------|----------------------------------|
|
||||
| `uint N`, `positive fixint` | [UIntN](/docs/en/sql-reference/data-types/int-uint.md) | `uint N` |
|
||||
| `int N`, `negative fixint` | [IntN](/docs/en/sql-reference/data-types/int-uint.md) | `int N` |
|
||||
| `bool` | [UInt8](/docs/en/sql-reference/data-types/int-uint.md) | `uint 8` |
|
||||
@ -2291,12 +2295,18 @@ ClickHouse supports reading and writing [MessagePack](https://msgpack.org/) data
|
||||
| `float 32` | [Float32](/docs/en/sql-reference/data-types/float.md) | `float 32` |
|
||||
| `float 64` | [Float64](/docs/en/sql-reference/data-types/float.md) | `float 64` |
|
||||
| `uint 16` | [Date](/docs/en/sql-reference/data-types/date.md) | `uint 16` |
|
||||
| `int 32` | [Date32](/docs/en/sql-reference/data-types/date32.md) | `int 32` |
|
||||
| `uint 32` | [DateTime](/docs/en/sql-reference/data-types/datetime.md) | `uint 32` |
|
||||
| `uint 64` | [DateTime64](/docs/en/sql-reference/data-types/datetime.md) | `uint 64` |
|
||||
| `fixarray`, `array 16`, `array 32` | [Array](/docs/en/sql-reference/data-types/array.md) | `fixarray`, `array 16`, `array 32` |
|
||||
| `fixarray`, `array 16`, `array 32` | [Array](/docs/en/sql-reference/data-types/array.md)/[Tuple](/docs/en/sql-reference/data-types/tuple.md) | `fixarray`, `array 16`, `array 32` |
|
||||
| `fixmap`, `map 16`, `map 32` | [Map](/docs/en/sql-reference/data-types/map.md) | `fixmap`, `map 16`, `map 32` |
|
||||
| `uint 32` | [IPv4](/docs/en/sql-reference/data-types/domains/ipv4.md) | `uint 32` |
|
||||
| `bin 8` | [String](/docs/en/sql-reference/data-types/string.md) | `bin 8` |
|
||||
| `int 8` | [Enum8](/docs/en/sql-reference/data-types/enum.md) | `int 8` |
|
||||
| `bin 8` | [(U)Int128/(U)Int256](/docs/en/sql-reference/data-types/int-uint.md) | `bin 8` |
|
||||
| `int 32` | [Decimal32](/docs/en/sql-reference/data-types/decimal.md) | `int 32` |
|
||||
| `int 64` | [Decimal64](/docs/en/sql-reference/data-types/decimal.md) | `int 64` |
|
||||
| `bin 8` | [Decimal128/Decimal256](/docs/en/sql-reference/data-types/decimal.md) | `bin 8 ` |
|
||||
|
||||
Example:
|
||||
|
||||
|
||||
@ -383,3 +383,19 @@ Data can be restored from backup using the `ALTER TABLE ... ATTACH PARTITION ...
|
||||
For more information about queries related to partition manipulations, see the [ALTER documentation](../sql-reference/statements/alter/partition.md#alter_manipulations-with-partitions).
|
||||
|
||||
A third-party tool is available to automate this approach: [clickhouse-backup](https://github.com/AlexAkulov/clickhouse-backup).
|
||||
|
||||
## Settings to disallow concurrent backup/restore
|
||||
|
||||
To disallow concurrent backup/restore, you can use these settings respectively.
|
||||
|
||||
```xml
|
||||
<clickhouse>
|
||||
<backups>
|
||||
<allow_concurrent_backups>false</allow_concurrent_backups>
|
||||
<allow_concurrent_restores>false</allow_concurrent_restores>
|
||||
</backups>
|
||||
</clickhouse>
|
||||
```
|
||||
|
||||
The default value for both is true, so by default concurrent backup/restores are allowed.
|
||||
When these settings are false on a cluster, only 1 backup/restore is allowed to run on a cluster at a time.
|
||||
@ -244,10 +244,12 @@ Example of configuration:
|
||||
<database>system</database>
|
||||
<user>foo</user>
|
||||
<password>secret</password>
|
||||
<secure>1</secure>
|
||||
</remote1>
|
||||
</named_collections>
|
||||
</clickhouse>
|
||||
```
|
||||
`secure` is not needed for connection because of `remoteSecure`, but it can be used for dictionaries.
|
||||
|
||||
### Example of using named collections with the `remote`/`remoteSecure` functions
|
||||
|
||||
|
||||
@ -103,6 +103,20 @@ cached - for that use setting [query_cache_min_query_runs](settings/settings.md#
|
||||
Entries in the query cache become stale after a certain time period (time-to-live). By default, this period is 60 seconds but a different
|
||||
value can be specified at session, profile or query level using setting [query_cache_ttl](settings/settings.md#query-cache-ttl).
|
||||
|
||||
Entries in the query cache are compressed by default. This reduces the overall memory consumption at the cost of slower writes into / reads
|
||||
from the query cache. To disable compression, use setting [query_cache_compress_entries](settings/settings.md#query-cache-compress-entries).
|
||||
|
||||
ClickHouse reads table data in blocks of [max_block_size](settings/settings.md#settings-max_block_size) rows. Due to filtering, aggregation,
|
||||
etc., result blocks are typically much smaller than 'max_block_size' but there are also cases where they are much bigger. Setting
|
||||
[query_cache_squash_partial_results](settings/settings.md#query-cache-squash-partial-results) (enabled by default) controls if result blocks
|
||||
are squashed (if they are tiny) or split (if they are large) into blocks of 'max_block_size' size before insertion into the query result
|
||||
cache. This reduces performance of writes into the query cache but improves compression rate of cache entries and provides more natural
|
||||
block granularity when query results are later served from the query cache.
|
||||
|
||||
As a result, the query cache stores for each query multiple (partial)
|
||||
result blocks. While this behavior is a good default, it can be suppressed using setting
|
||||
[query_cache_squash_partial_query_results](settings/settings.md#query-cache-squash-partial-query-results).
|
||||
|
||||
Also, results of queries with non-deterministic functions such as `rand()` and `now()` are not cached. This can be overruled using
|
||||
setting [query_cache_store_results_of_queries_with_nondeterministic_functions](settings/settings.md#query-cache-store-results-of-queries-with-nondeterministic-functions).
|
||||
|
||||
|
||||
@ -257,6 +257,7 @@ The path to the table in ZooKeeper.
|
||||
``` xml
|
||||
<default_replica_path>/clickhouse/tables/{uuid}/{shard}</default_replica_path>
|
||||
```
|
||||
|
||||
## default_replica_name {#default_replica_name}
|
||||
|
||||
The replica name in ZooKeeper.
|
||||
@ -418,6 +419,7 @@ Opens `https://tabix.io/` when accessing `http://localhost: http_port`.
|
||||
<![CDATA[<html ng-app="SMI2"><head><base href="http://ui.tabix.io/"></head><body><div ui-view="" class="content-ui"></div><script src="http://loader.tabix.io/master.js"></script></body></html>]]>
|
||||
</http_server_default_response>
|
||||
```
|
||||
|
||||
## hsts_max_age {#hsts-max-age}
|
||||
|
||||
Expired time for HSTS in seconds. The default value is 0 means clickhouse disabled HSTS. If you set a positive number, the HSTS will be enabled and the max-age is the number you set.
|
||||
@ -1045,7 +1047,7 @@ Default value: `0`.
|
||||
|
||||
Sets the number of threads performing background merges and mutations for tables with MergeTree engines. This setting is also could be applied at server startup from the `default` profile configuration for backward compatibility at the ClickHouse server start. You can only increase the number of threads at runtime. To lower the number of threads you have to restart the server. By adjusting this setting, you manage CPU and disk load. Smaller pool size utilizes less CPU and disk resources, but background processes advance slower which might eventually impact query performance.
|
||||
|
||||
Before changing it, please also take a look at related MergeTree settings, such as `number_of_free_entries_in_pool_to_lower_max_size_of_merge` and `number_of_free_entries_in_pool_to_execute_mutation`.
|
||||
Before changing it, please also take a look at related MergeTree settings, such as [number_of_free_entries_in_pool_to_lower_max_size_of_merge](../../operations/settings/merge-tree-settings.md#number-of-free-entries-in-pool-to-lower-max-size-of-merge) and [number_of_free_entries_in_pool_to_execute_mutation](../../operations/settings/merge-tree-settings.md#number-of-free-entries-in-pool-to-execute-mutation).
|
||||
|
||||
Possible values:
|
||||
|
||||
@ -1113,7 +1115,7 @@ Default value: 8.
|
||||
|
||||
## background_fetches_pool_size {#background_fetches_pool_size}
|
||||
|
||||
Sets the number of threads performing background fetches for tables with ReplicatedMergeTree engines. Could be increased at runtime and could be applied at server startup from the `default` profile for backward compatibility.
|
||||
Sets the number of threads performing background fetches for tables with ReplicatedMergeTree engines. Could be increased at runtime.
|
||||
|
||||
Possible values:
|
||||
|
||||
@ -1129,7 +1131,7 @@ Default value: 8.
|
||||
|
||||
## background_common_pool_size {#background_common_pool_size}
|
||||
|
||||
Sets the number of threads performing background non-specialized operations like cleaning the filesystem etc. for tables with MergeTree engines. Could be increased at runtime and could be applied at server startup from the `default` profile for backward compatibility.
|
||||
Sets the number of threads performing background non-specialized operations like cleaning the filesystem etc. for tables with MergeTree engines. Could be increased at runtime.
|
||||
|
||||
Possible values:
|
||||
|
||||
@ -1143,6 +1145,25 @@ Default value: 8.
|
||||
<background_common_pool_size>36</background_common_pool_size>
|
||||
```
|
||||
|
||||
## background_buffer_flush_schedule_pool_size {#background_buffer_flush_schedule_pool_size}
|
||||
|
||||
Sets the number of threads performing background flush in [Buffer](../../engines/table-engines/special/buffer.md)-engine tables.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 16.
|
||||
|
||||
## background_schedule_pool_size {#background_schedule_pool_size}
|
||||
|
||||
Sets the number of threads performing background tasks for [replicated](../../engines/table-engines/mergetree-family/replication.md) tables, [Kafka](../../engines/table-engines/integrations/kafka.md) streaming, [DNS cache updates](../../operations/server-configuration-parameters/settings.md/#server-settings-dns-cache-update-period).
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 128.
|
||||
|
||||
|
||||
## merge_tree {#server_configuration_parameters-merge_tree}
|
||||
|
||||
@ -553,6 +553,32 @@ Default value: 8192
|
||||
|
||||
Merge reads rows from parts in blocks of `merge_max_block_size` rows, then merges and writes the result into a new part. The read block is placed in RAM, so `merge_max_block_size` affects the size of the RAM required for the merge. Thus, merges can consume a large amount of RAM for tables with very wide rows (if the average row size is 100kb, then when merging 10 parts, (100kb * 10 * 8192) = ~ 8GB of RAM). By decreasing `merge_max_block_size`, you can reduce the amount of RAM required for a merge but slow down a merge.
|
||||
|
||||
## number_of_free_entries_in_pool_to_lower_max_size_of_merge {#number-of-free-entries-in-pool-to-lower-max-size-of-merge}
|
||||
|
||||
When there is less than specified number of free entries in pool (or replicated queue), start to lower maximum size of merge to process (or to put in queue).
|
||||
This is to allow small merges to process - not filling the pool with long running merges.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 8
|
||||
|
||||
## number_of_free_entries_in_pool_to_execute_mutation {#number-of-free-entries-in-pool-to-execute-mutation}
|
||||
|
||||
When there is less than specified number of free entries in pool, do not execute part mutations.
|
||||
This is to leave free threads for regular merges and avoid "Too many parts".
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 20
|
||||
|
||||
**Usage**
|
||||
|
||||
The value of the `number_of_free_entries_in_pool_to_execute_mutation` setting should be less than the value of the [background_pool_size](/docs/en/operations/server-configuration-parameters/settings#background_pool_size) * [background_pool_size](/docs/en/operations/server-configuration-parameters/settings#background_merges_mutations_concurrency_ratio). Otherwise, ClickHouse throws an exception.
|
||||
|
||||
## max_part_loading_threads {#max-part-loading-threads}
|
||||
|
||||
The maximum number of threads that read parts when ClickHouse starts.
|
||||
|
||||
@ -1128,7 +1128,7 @@ Default value: `2.latest`.
|
||||
|
||||
Compression method used in output Parquet format. Supported codecs: `snappy`, `lz4`, `brotli`, `zstd`, `gzip`, `none` (uncompressed)
|
||||
|
||||
Default value: `snappy`.
|
||||
Default value: `lz4`.
|
||||
|
||||
## Hive format settings {#hive-format-settings}
|
||||
|
||||
|
||||
@ -1435,6 +1435,28 @@ Possible values:
|
||||
|
||||
Default value: `0`
|
||||
|
||||
## query_cache_compress_entries {#query-cache-compress-entries}
|
||||
|
||||
Compress entries in the [query cache](../query-cache.md). Lessens the memory consumption of the query cache at the cost of slower inserts into / reads from it.
|
||||
|
||||
Possible values:
|
||||
|
||||
- 0 - Disabled
|
||||
- 1 - Enabled
|
||||
|
||||
Default value: `1`
|
||||
|
||||
## query_cache_squash_partial_results {#query-cache-squash-partial-results}
|
||||
|
||||
Squash partial result blocks to blocks of size [max_block_size](#setting-max_block_size). Reduces performance of inserts into the [query cache](../query-cache.md) but improves the compressability of cache entries (see [query_cache_compress-entries](#query_cache_compress_entries)).
|
||||
|
||||
Possible values:
|
||||
|
||||
- 0 - Disabled
|
||||
- 1 - Enabled
|
||||
|
||||
Default value: `1`
|
||||
|
||||
## query_cache_ttl {#query-cache-ttl}
|
||||
|
||||
After this time in seconds entries in the [query cache](../query-cache.md) become stale.
|
||||
@ -1552,6 +1574,7 @@ For the replicated tables by default the only 100 of the most recent blocks for
|
||||
For not replicated tables see [non_replicated_deduplication_window](merge-tree-settings.md/#non-replicated-deduplication-window).
|
||||
|
||||
## Asynchronous Insert settings
|
||||
|
||||
### async_insert {#async-insert}
|
||||
|
||||
Enables or disables asynchronous inserts. This makes sense only for insertion over HTTP protocol. Note that deduplication isn't working for such inserts.
|
||||
@ -1645,6 +1668,7 @@ Possible values:
|
||||
- 0 — Timeout disabled.
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
### async_insert_deduplicate {#settings-async-insert-deduplicate}
|
||||
|
||||
Enables or disables insert deduplication of `ASYNC INSERT` (for Replicated\* tables).
|
||||
@ -2449,43 +2473,19 @@ Default value: `1`.
|
||||
|
||||
## background_buffer_flush_schedule_pool_size {#background_buffer_flush_schedule_pool_size}
|
||||
|
||||
Sets the number of threads performing background flush in [Buffer](../../engines/table-engines/special/buffer.md)-engine tables. This setting is applied at the ClickHouse server start and can’t be changed in a user session.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 16.
|
||||
That setting was moved to the [server configuration parameters](../../operations/server-configuration-parameters/settings.md/#background_buffer_flush_schedule_pool_size).
|
||||
|
||||
## background_move_pool_size {#background_move_pool_size}
|
||||
|
||||
Sets the number of threads performing background moves of data parts for [MergeTree](../../engines/table-engines/mergetree-family/mergetree.md/#table_engine-mergetree-multiple-volumes)-engine tables. This setting is applied at the ClickHouse server start and can’t be changed in a user session.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 8.
|
||||
That setting was moved to the [server configuration parameters](../../operations/server-configuration-parameters/settings.md/#background_move_pool_size).
|
||||
|
||||
## background_schedule_pool_size {#background_schedule_pool_size}
|
||||
|
||||
Sets the number of threads performing background tasks for [replicated](../../engines/table-engines/mergetree-family/replication.md) tables, [Kafka](../../engines/table-engines/integrations/kafka.md) streaming, [DNS cache updates](../../operations/server-configuration-parameters/settings.md/#server-settings-dns-cache-update-period). This setting is applied at ClickHouse server start and can’t be changed in a user session.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 128.
|
||||
That setting was moved to the [server configuration parameters](../../operations/server-configuration-parameters/settings.md/#background_schedule_pool_size).
|
||||
|
||||
## background_fetches_pool_size {#background_fetches_pool_size}
|
||||
|
||||
Sets the number of threads performing background fetches for [replicated](../../engines/table-engines/mergetree-family/replication.md) tables. This setting is applied at the ClickHouse server start and can’t be changed in a user session. For production usage with frequent small insertions or slow ZooKeeper cluster it is recommended to use default value.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 8.
|
||||
That setting was moved to the [server configuration parameters](../../operations/server-configuration-parameters/settings.md/#background_fetches_pool_size).
|
||||
|
||||
## always_fetch_merged_part {#always_fetch_merged_part}
|
||||
|
||||
@ -2506,28 +2506,11 @@ Default value: 0.
|
||||
|
||||
## background_distributed_schedule_pool_size {#background_distributed_schedule_pool_size}
|
||||
|
||||
Sets the number of threads performing background tasks for [distributed](../../engines/table-engines/special/distributed.md) sends. This setting is applied at the ClickHouse server start and can’t be changed in a user session.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 16.
|
||||
That setting was moved to the [server configuration parameters](../../operations/server-configuration-parameters/settings.md/#background_distributed_schedule_pool_size).
|
||||
|
||||
## background_message_broker_schedule_pool_size {#background_message_broker_schedule_pool_size}
|
||||
|
||||
Sets the number of threads performing background tasks for message streaming. This setting is applied at the ClickHouse server start and can’t be changed in a user session.
|
||||
|
||||
Possible values:
|
||||
|
||||
- Any positive integer.
|
||||
|
||||
Default value: 16.
|
||||
|
||||
**See Also**
|
||||
|
||||
- [Kafka](../../engines/table-engines/integrations/kafka.md/#kafka) engine.
|
||||
- [RabbitMQ](../../engines/table-engines/integrations/rabbitmq.md/#rabbitmq-engine) engine.
|
||||
That setting was moved to the [server configuration parameters](../../operations/server-configuration-parameters/settings.md/#background_message_broker_schedule_pool_size).
|
||||
|
||||
## validate_polygons {#validate_polygons}
|
||||
|
||||
@ -2769,7 +2752,7 @@ Default value: `120` seconds.
|
||||
|
||||
## cast_keep_nullable {#cast_keep_nullable}
|
||||
|
||||
Enables or disables keeping of the `Nullable` data type in [CAST](../../sql-reference/functions/type-conversion-functions.md/#type_conversion_function-cast) operations.
|
||||
Enables or disables keeping of the `Nullable` data type in [CAST](../../sql-reference/functions/type-conversion-functions.md/#castx-t) operations.
|
||||
|
||||
When the setting is enabled and the argument of `CAST` function is `Nullable`, the result is also transformed to `Nullable` type. When the setting is disabled, the result always has the destination type exactly.
|
||||
|
||||
@ -4060,8 +4043,8 @@ Possible values:
|
||||
|
||||
Default value: `0`.
|
||||
|
||||
## stop_reading_on_first_cancel {#stop_reading_on_first_cancel}
|
||||
When set to `true` and the user wants to interrupt a query (for example using `Ctrl+C` on the client), then the query continues execution only on data that was already read from the table. Afterward, it will return a partial result of the query for the part of the table that was read. To fully stop the execution of a query without a partial result, the user should send 2 cancel requests.
|
||||
## partial_result_on_first_cancel {#partial_result_on_first_cancel}
|
||||
When set to `true` and the user wants to interrupt a query (for example using `Ctrl+C` on the client), then the query continues execution only on data that was already read from the table. Afterwards, it will return a partial result of the query for the part of the table that was read. To fully stop the execution of a query without a partial result, the user should send 2 cancel requests.
|
||||
|
||||
**Example without setting on Ctrl+C**
|
||||
```sql
|
||||
@ -4076,7 +4059,7 @@ Query was cancelled.
|
||||
|
||||
**Example with setting on Ctrl+C**
|
||||
```sql
|
||||
SELECT sum(number) FROM numbers(10000000000) SETTINGS stop_reading_on_first_cancel=true
|
||||
SELECT sum(number) FROM numbers(10000000000) SETTINGS partial_result_on_first_cancel=true
|
||||
|
||||
┌──────sum(number)─┐
|
||||
│ 1355411451286266 │
|
||||
@ -4088,3 +4071,44 @@ SELECT sum(number) FROM numbers(10000000000) SETTINGS stop_reading_on_first_canc
|
||||
Possible values: `true`, `false`
|
||||
|
||||
Default value: `false`
|
||||
## function_json_value_return_type_allow_nullable
|
||||
|
||||
Control whether allow to return `NULL` when value is not exist for JSON_VALUE function.
|
||||
|
||||
```sql
|
||||
SELECT JSON_VALUE('{"hello":"world"}', '$.b') settings function_json_value_return_type_allow_nullable=true;
|
||||
|
||||
┌─JSON_VALUE('{"hello":"world"}', '$.b')─┐
|
||||
│ ᴺᵁᴸᴸ │
|
||||
└────────────────────────────────────────┘
|
||||
|
||||
1 row in set. Elapsed: 0.001 sec.
|
||||
```
|
||||
|
||||
Possible values:
|
||||
|
||||
- true — Allow.
|
||||
- false — Disallow.
|
||||
|
||||
Default value: `false`.
|
||||
|
||||
## function_json_value_return_type_allow_complex
|
||||
|
||||
Control whether allow to return complex type (such as: struct, array, map) for json_value function.
|
||||
|
||||
```sql
|
||||
SELECT JSON_VALUE('{"hello":{"world":"!"}}', '$.hello') settings function_json_value_return_type_allow_complex=true
|
||||
|
||||
┌─JSON_VALUE('{"hello":{"world":"!"}}', '$.hello')─┐
|
||||
│ {"world":"!"} │
|
||||
└──────────────────────────────────────────────────┘
|
||||
|
||||
1 row in set. Elapsed: 0.001 sec.
|
||||
```
|
||||
|
||||
Possible values:
|
||||
|
||||
- true — Allow.
|
||||
- false — Disallow.
|
||||
|
||||
Default value: `false`.
|
||||
|
||||
@ -14,6 +14,10 @@ Columns:
|
||||
- `query_id` ([String](../../sql-reference/data-types/string.md)) — Query identifier that can be used to get details about a query that was running from the [query_log](../system-tables/query_log.md) system table.
|
||||
- `trace` ([Array(UInt64)](../../sql-reference/data-types/array.md)) — A [stack trace](https://en.wikipedia.org/wiki/Stack_trace) which represents a list of physical addresses where the called methods are stored.
|
||||
|
||||
:::tip
|
||||
Check out the Knowledge Base for some handy queries, including [how to see what threads are currently running](https://clickhouse.com/docs/knowledgebase/find-expensive-queries) and [useful queries for troubleshooting](https://clickhouse.com/docs/knowledgebase/useful-queries-for-troubleshooting).
|
||||
:::
|
||||
|
||||
**Example**
|
||||
|
||||
Enabling introspection functions:
|
||||
|
||||
@ -51,10 +51,14 @@ But for storing archives with rare queries, shelves will work.
|
||||
## RAID {#raid}
|
||||
|
||||
When using HDD, you can combine their RAID-10, RAID-5, RAID-6 or RAID-50.
|
||||
For Linux, software RAID is better (with `mdadm`). We do not recommend using LVM.
|
||||
For Linux, software RAID is better (with `mdadm`).
|
||||
When creating RAID-10, select the `far` layout.
|
||||
If your budget allows, choose RAID-10.
|
||||
|
||||
LVM by itself (without RAID or `mdadm`) is ok, but making RAID with it or combining it with `mdadm` is a less explored option, and there will be more chances for mistakes
|
||||
(selecting wrong chunk size; misalignment of chunks; choosing a wrong raid type; forgetting to cleanup disks). If you are confident
|
||||
in using LVM, there is nothing against using it.
|
||||
|
||||
If you have more than 4 disks, use RAID-6 (preferred) or RAID-50, instead of RAID-5.
|
||||
When using RAID-5, RAID-6 or RAID-50, always increase stripe_cache_size, since the default value is usually not the best choice.
|
||||
|
||||
|
||||
@ -1463,28 +1463,28 @@ Result:
|
||||
└───────────────────────┘
|
||||
```
|
||||
|
||||
## FROM\_UNIXTIME
|
||||
## fromUnixTimestamp
|
||||
|
||||
Function converts Unix timestamp to a calendar date and a time of a day. When there is only a single argument of [Integer](../../sql-reference/data-types/int-uint.md) type, it acts in the same way as [toDateTime](../../sql-reference/functions/type-conversion-functions.md#todatetime) and return [DateTime](../../sql-reference/data-types/datetime.md) type.
|
||||
|
||||
FROM_UNIXTIME uses MySQL datetime format style, refer to https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_date-format.
|
||||
fromUnixTimestamp uses MySQL datetime format style, refer to https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_date-format.
|
||||
|
||||
Alias: `fromUnixTimestamp`.
|
||||
Alias: `FROM_UNIXTIME`.
|
||||
|
||||
**Example:**
|
||||
|
||||
Query:
|
||||
|
||||
```sql
|
||||
SELECT FROM_UNIXTIME(423543535);
|
||||
SELECT fromUnixTimestamp(423543535);
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```text
|
||||
┌─FROM_UNIXTIME(423543535)─┐
|
||||
┌─fromUnixTimestamp(423543535)─┐
|
||||
│ 1983-06-04 10:58:55 │
|
||||
└──────────────────────────┘
|
||||
└──────────────────────────────┘
|
||||
```
|
||||
|
||||
When there are two or three arguments, the first an [Integer](../../sql-reference/data-types/int-uint.md), [Date](../../sql-reference/data-types/date.md), [Date32](../../sql-reference/data-types/date32.md), [DateTime](../../sql-reference/data-types/datetime.md) or [DateTime64](../../sql-reference/data-types/datetime64.md), the second a constant format string and the third an optional constant time zone string — it acts in the same way as [formatDateTime](#formatdatetime) and return [String](../../sql-reference/data-types/string.md#string) type.
|
||||
@ -1492,7 +1492,7 @@ When there are two or three arguments, the first an [Integer](../../sql-referenc
|
||||
For example:
|
||||
|
||||
```sql
|
||||
SELECT FROM_UNIXTIME(1234334543, '%Y-%m-%d %R:%S') AS DateTime;
|
||||
SELECT fromUnixTimestamp(1234334543, '%Y-%m-%d %R:%S') AS DateTime;
|
||||
```
|
||||
|
||||
```text
|
||||
@ -1505,11 +1505,12 @@ SELECT FROM_UNIXTIME(1234334543, '%Y-%m-%d %R:%S') AS DateTime;
|
||||
|
||||
- [fromUnixTimestampInJodaSyntax](##fromUnixTimestampInJodaSyntax)
|
||||
|
||||
|
||||
## fromUnixTimestampInJodaSyntax
|
||||
Similar to FROM_UNIXTIME, except that it formats time in Joda style instead of MySQL style. Refer to https://joda-time.sourceforge.net/apidocs/org/joda/time/format/DateTimeFormat.html.
|
||||
|
||||
Similar to fromUnixTimestamp, except that it formats time in Joda style instead of MySQL style. Refer to https://joda-time.sourceforge.net/apidocs/org/joda/time/format/DateTimeFormat.html.
|
||||
|
||||
**Example:**
|
||||
|
||||
Query:
|
||||
``` sql
|
||||
SELECT fromUnixTimestampInJodaSyntax(1669804872, 'yyyy-MM-dd HH:mm:ss', 'UTC');
|
||||
@ -1517,12 +1518,11 @@ SELECT fromUnixTimestampInJodaSyntax(1669804872, 'yyyy-MM-dd HH:mm:ss', 'UTC');
|
||||
|
||||
Result:
|
||||
```
|
||||
┌─fromUnixTimestampInJodaSyntax(1669804872, 'yyyy-MM-dd HH:mm:ss', 'UTC')─┐
|
||||
┌─fromUnixTimestampInJodaSyntax(1669804872, 'yyyy-MM-dd HH:mm:ss', 'UTC')────┐
|
||||
│ 2022-11-30 10:41:12 │
|
||||
└────────────────────────────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
|
||||
## toModifiedJulianDay
|
||||
|
||||
Converts a [Proleptic Gregorian calendar](https://en.wikipedia.org/wiki/Proleptic_Gregorian_calendar) date in text form `YYYY-MM-DD` to a [Modified Julian Day](https://en.wikipedia.org/wiki/Julian_day#Variants) number in Int32. This function supports date from `0000-01-01` to `9999-12-31`. It raises an exception if the argument cannot be parsed as a date, or the date is invalid.
|
||||
|
||||
@ -91,7 +91,7 @@ The command must read arguments from `STDIN` and must output the result to `STDO
|
||||
**Example**
|
||||
|
||||
Creating `test_function` using XML configuration.
|
||||
File test_function.xml.
|
||||
File `test_function.xml` (`/etc/clickhouse-server/test_function.xml` with default path settings).
|
||||
```xml
|
||||
<functions>
|
||||
<function>
|
||||
@ -108,7 +108,7 @@ File test_function.xml.
|
||||
</functions>
|
||||
```
|
||||
|
||||
Script file inside `user_scripts` folder `test_function.py`.
|
||||
Script file inside `user_scripts` folder `test_function.py` (`/var/lib/clickhouse/user_scripts/test_function.py` with default path settings).
|
||||
|
||||
```python
|
||||
#!/usr/bin/python3
|
||||
@ -136,7 +136,7 @@ Result:
|
||||
```
|
||||
|
||||
Creating `test_function_sum` manually specifying `execute_direct` to `0` using XML configuration.
|
||||
File test_function.xml.
|
||||
File `test_function.xml` (`/etc/clickhouse-server/test_function.xml` with default path settings).
|
||||
```xml
|
||||
<functions>
|
||||
<function>
|
||||
@ -173,7 +173,7 @@ Result:
|
||||
```
|
||||
|
||||
Creating `test_function_sum_json` with named arguments and format [JSONEachRow](../../interfaces/formats.md#jsoneachrow) using XML configuration.
|
||||
File test_function.xml.
|
||||
File `test_function.xml` (`/etc/clickhouse-server/test_function.xml` with default path settings).
|
||||
```xml
|
||||
<functions>
|
||||
<function>
|
||||
@ -195,7 +195,7 @@ File test_function.xml.
|
||||
</functions>
|
||||
```
|
||||
|
||||
Script file inside `user_scripts` folder `test_function_sum_json.py`.
|
||||
Script file inside `user_scripts` folder `test_function_sum_json.py` (`/var/lib/clickhouse/user_scripts/test_function_sum_json.py` with default path settings).
|
||||
|
||||
```python
|
||||
#!/usr/bin/python3
|
||||
@ -228,7 +228,7 @@ Result:
|
||||
```
|
||||
|
||||
Executable user defined functions can take constant parameters configured in `command` setting (works only for user defined functions with `executable` type).
|
||||
File test_function_parameter_python.xml.
|
||||
File `test_function_parameter_python.xml` (`/etc/clickhouse-server/test_function_parameter_python.xml` with default path settings).
|
||||
```xml
|
||||
<functions>
|
||||
<function>
|
||||
@ -244,7 +244,7 @@ File test_function_parameter_python.xml.
|
||||
</functions>
|
||||
```
|
||||
|
||||
Script file inside `user_scripts` folder `test_function_parameter_python.py`.
|
||||
Script file inside `user_scripts` folder `test_function_parameter_python.py` (`/var/lib/clickhouse/user_scripts/test_function_parameter_python.py` with default path settings).
|
||||
|
||||
```python
|
||||
#!/usr/bin/python3
|
||||
|
||||
@ -401,7 +401,7 @@ Before version 21.11 the order of arguments was wrong, i.e. JSON_QUERY(path, jso
|
||||
|
||||
Parses a JSON and extract a value as JSON scalar.
|
||||
|
||||
If the value does not exist, an empty string will be returned.
|
||||
If the value does not exist, an empty string will be returned by default, and by SET `function_return_type_allow_nullable` = `true`, `NULL` will be returned. If the value is complex type (such as: struct, array, map), an empty string will be returned by default, and by SET `function_json_value_return_type_allow_complex` = `true`, the complex value will be returned.
|
||||
|
||||
Example:
|
||||
|
||||
@ -410,6 +410,8 @@ SELECT JSON_VALUE('{"hello":"world"}', '$.hello');
|
||||
SELECT JSON_VALUE('{"array":[[0, 1, 2, 3, 4, 5], [0, -1, -2, -3, -4, -5]]}', '$.array[*][0 to 2, 4]');
|
||||
SELECT JSON_VALUE('{"hello":2}', '$.hello');
|
||||
SELECT toTypeName(JSON_VALUE('{"hello":2}', '$.hello'));
|
||||
select JSON_VALUE('{"hello":"world"}', '$.b') settings function_return_type_allow_nullable=true;
|
||||
select JSON_VALUE('{"hello":{"world":"!"}}', '$.hello') settings function_json_value_return_type_allow_complex=true;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
@ -208,7 +208,7 @@ Type: [Array](../../sql-reference/data-types/array.md)([Tuple](../../sql-referen
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
CREATE TABLE tupletest (`col` Tuple(user_ID UInt64, session_ID UInt64) ENGINE = Memory;
|
||||
CREATE TABLE tupletest (col Tuple(user_ID UInt64, session_ID UInt64)) ENGINE = Memory;
|
||||
|
||||
INSERT INTO tupletest VALUES (tuple( 100, 2502)), (tuple(1,100));
|
||||
|
||||
@ -227,11 +227,11 @@ Result:
|
||||
It is possible to transform colums to rows using this function:
|
||||
|
||||
``` sql
|
||||
CREATE TABLE tupletest (`col` Tuple(CPU Float64, Memory Float64, Disk Float64)) ENGINE = Memory;
|
||||
CREATE TABLE tupletest (col Tuple(CPU Float64, Memory Float64, Disk Float64)) ENGINE = Memory;
|
||||
|
||||
INSERT INTO tupletest VALUES(tuple(3.3, 5.5, 6.6));
|
||||
|
||||
SELECT arrayJoin(tupleToNameValuePairs(col))FROM tupletest;
|
||||
SELECT arrayJoin(tupleToNameValuePairs(col)) FROM tupletest;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
@ -13,6 +13,40 @@ incompatible datatypes (for example from `String` to `Int`). Make sure to check
|
||||
|
||||
ClickHouse generally uses the [same behavior as C++ programs](https://en.cppreference.com/w/cpp/language/implicit_conversion).
|
||||
|
||||
`to<type>` functions and [cast](#castx-t) have different behaviour in some cases, for example in case of [LowCardinality](../data-types/lowcardinality.md): [cast](#castx-t) removes [LowCardinality](../data-types/lowcardinality.md) trait `to<type>` functions don't. The same with [Nullable](../data-types/nullable.md), this behaviour is not compatible with SQL standard, and it can be changed using [cast_keep_nullable](../../operations/settings/settings.md/#cast_keep_nullable) setting.
|
||||
|
||||
Example:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
toTypeName(toLowCardinality('') AS val) AS source_type,
|
||||
toTypeName(toString(val)) AS to_type_result_type,
|
||||
toTypeName(CAST(val, 'String')) AS cast_result_type
|
||||
|
||||
┌─source_type────────────┬─to_type_result_type────┬─cast_result_type─┐
|
||||
│ LowCardinality(String) │ LowCardinality(String) │ String │
|
||||
└────────────────────────┴────────────────────────┴──────────────────┘
|
||||
|
||||
SELECT
|
||||
toTypeName(toNullable('') AS val) AS source_type,
|
||||
toTypeName(toString(val)) AS to_type_result_type,
|
||||
toTypeName(CAST(val, 'String')) AS cast_result_type
|
||||
|
||||
┌─source_type──────┬─to_type_result_type─┬─cast_result_type─┐
|
||||
│ Nullable(String) │ Nullable(String) │ String │
|
||||
└──────────────────┴─────────────────────┴──────────────────┘
|
||||
|
||||
SELECT
|
||||
toTypeName(toNullable('') AS val) AS source_type,
|
||||
toTypeName(toString(val)) AS to_type_result_type,
|
||||
toTypeName(CAST(val, 'String')) AS cast_result_type
|
||||
SETTINGS cast_keep_nullable = 1
|
||||
|
||||
┌─source_type──────┬─to_type_result_type─┬─cast_result_type─┐
|
||||
│ Nullable(String) │ Nullable(String) │ Nullable(String) │
|
||||
└──────────────────┴─────────────────────┴──────────────────┘
|
||||
```
|
||||
|
||||
## toInt(8\|16\|32\|64\|128\|256)
|
||||
|
||||
Converts an input value to a value the [Int](/docs/en/sql-reference/data-types/int-uint.md) data type. This function family includes:
|
||||
@ -737,6 +771,44 @@ Result:
|
||||
└────────────┴───────┘
|
||||
```
|
||||
|
||||
## toDecimalString
|
||||
|
||||
Converts a numeric value to String with the number of fractional digits in the output specified by the user.
|
||||
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
toDecimalString(number, scale)
|
||||
```
|
||||
|
||||
**Parameters**
|
||||
|
||||
- `number` — Value to be represented as String, [Int, UInt](/docs/en/sql-reference/data-types/int-uint.md), [Float](/docs/en/sql-reference/data-types/float.md), [Decimal](/docs/en/sql-reference/data-types/decimal.md),
|
||||
- `scale` — Number of fractional digits, [UInt8](/docs/en/sql-reference/data-types/int-uint.md).
|
||||
* Maximum scale for [Decimal](/docs/en/sql-reference/data-types/decimal.md) and [Int, UInt](/docs/en/sql-reference/data-types/int-uint.md) types is 77 (it is the maximum possible number of significant digits for Decimal),
|
||||
* Maximum scale for [Float](/docs/en/sql-reference/data-types/float.md) is 60.
|
||||
|
||||
**Returned value**
|
||||
|
||||
- Input value represented as [String](/docs/en/sql-reference/data-types/string.md) with given number of fractional digits (scale).
|
||||
The number is rounded up or down according to common arithmetics in case requested scale is smaller than original number's scale.
|
||||
|
||||
**Example**
|
||||
|
||||
Query:
|
||||
|
||||
``` sql
|
||||
SELECT toDecimalString(CAST('64.32', 'Float64'), 5);
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```response
|
||||
┌toDecimalString(CAST('64.32', 'Float64'), 5)─┐
|
||||
│ 64.32000 │
|
||||
└─────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
## reinterpretAsUInt(8\|16\|32\|64)
|
||||
|
||||
## reinterpretAsInt(8\|16\|32\|64)
|
||||
@ -956,7 +1028,7 @@ Result:
|
||||
|
||||
**See also**
|
||||
|
||||
- [cast_keep_nullable](/docs/en/operations/settings/settings.md/#cast_keep_nullable) setting
|
||||
- [cast_keep_nullable](../../operations/settings/settings.md/#cast_keep_nullable) setting
|
||||
|
||||
## accurateCast(x, T)
|
||||
|
||||
@ -1188,6 +1260,16 @@ SELECT parseDateTime('2021-01-04+23:00:00', '%Y-%m-%d+%H:%i:%s')
|
||||
|
||||
Alias: `TO_TIMESTAMP`.
|
||||
|
||||
## parseDateTimeOrZero
|
||||
|
||||
Same as for [parseDateTime](#type_conversion_functions-parseDateTime) except that it returns zero date when it encounters a date format that cannot be processed.
|
||||
|
||||
## parseDateTimeOrNull
|
||||
|
||||
Same as for [parseDateTime](#type_conversion_functions-parseDateTime) except that it returns `NULL` when it encounters a date format that cannot be processed.
|
||||
|
||||
Alias: `str_to_date`.
|
||||
|
||||
## parseDateTimeInJodaSyntax {#type_conversion_functions-parseDateTimeInJodaSyntax}
|
||||
|
||||
Similar to [parseDateTime](#parsedatetime), except that the format string is in [Joda](https://joda-time.sourceforge.net/apidocs/org/joda/time/format/DateTimeFormat.html) instead of MySQL syntax.
|
||||
@ -1227,6 +1309,14 @@ SELECT parseDateTimeInJodaSyntax('2023-02-24 14:53:31', 'yyyy-MM-dd HH:mm:ss', '
|
||||
└─────────────────────────────────────────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
## parseDateTimeInJodaSyntaxOrZero
|
||||
|
||||
Same as for [parseDateTimeInJodaSyntax](#type_conversion_functions-parseDateTimeInJodaSyntax) except that it returns zero date when it encounters a date format that cannot be processed.
|
||||
|
||||
## parseDateTimeInJodaSyntaxOrNull
|
||||
|
||||
Same as for [parseDateTimeInJodaSyntax](#type_conversion_functions-parseDateTimeInJodaSyntax) except that it returns `NULL` when it encounters a date format that cannot be processed.
|
||||
|
||||
## parseDateTimeBestEffort
|
||||
## parseDateTime32BestEffort
|
||||
|
||||
|
||||
@ -48,6 +48,39 @@ SELECT generateULID(1), generateULID(2)
|
||||
└────────────────────────────┴────────────────────────────┘
|
||||
```
|
||||
|
||||
## ULIDStringToDateTime
|
||||
|
||||
This function extracts the timestamp from a ULID.
|
||||
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
ULIDStringToDateTime(ulid[, timezone])
|
||||
```
|
||||
|
||||
**Arguments**
|
||||
|
||||
- `ulid` — Input ULID. [String](/docs/en/sql-reference/data-types/string.md) or [FixedString(26)](/docs/en/sql-reference/data-types/fixedstring.md).
|
||||
- `timezone` — [Timezone name](../../operations/server-configuration-parameters/settings.md#server_configuration_parameters-timezone) for the returned value (optional). [String](../../sql-reference/data-types/string.md).
|
||||
|
||||
**Returned value**
|
||||
|
||||
- Timestamp with milliseconds precision.
|
||||
|
||||
Type: [DateTime64(3)](/docs/en/sql-reference/data-types/datetime64.md).
|
||||
|
||||
**Usage example**
|
||||
|
||||
``` sql
|
||||
SELECT ULIDStringToDateTime('01GNB2S2FGN2P93QPXDNB4EN2R')
|
||||
```
|
||||
|
||||
``` text
|
||||
┌─ULIDStringToDateTime('01GNB2S2FGN2P93QPXDNB4EN2R')─┐
|
||||
│ 2022-12-28 00:40:37.616 │
|
||||
└────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
## See Also
|
||||
|
||||
- [UUID](../../sql-reference/functions/uuid-functions.md)
|
||||
|
||||
@ -21,15 +21,6 @@ DELETE FROM hits WHERE Title LIKE '%hello%';
|
||||
|
||||
Lightweight deletes are asynchronous by default. Set `mutations_sync` equal to 1 to wait for one replica to process the statement, and set `mutations_sync` to 2 to wait for all replicas.
|
||||
|
||||
:::note
|
||||
This feature is experimental and requires you to set `allow_experimental_lightweight_delete` to true:
|
||||
|
||||
```sql
|
||||
SET allow_experimental_lightweight_delete = true;
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
:::note
|
||||
`DELETE FROM` requires the `ALTER DELETE` privilege:
|
||||
```sql
|
||||
@ -64,6 +55,3 @@ With the described implementation now we can see what can negatively affect 'DEL
|
||||
- Table having a very large number of data parts
|
||||
- Having a lot of data in Compact parts—in a Compact part, all columns are stored in one file.
|
||||
|
||||
:::note
|
||||
This implementation might change in the future.
|
||||
:::
|
||||
|
||||
@ -47,6 +47,7 @@ The default join type can be overridden using [join_default_strictness](../../..
|
||||
|
||||
The behavior of ClickHouse server for `ANY JOIN` operations depends on the [any_join_distinct_right_table_keys](../../../operations/settings/settings.md#any_join_distinct_right_table_keys) setting.
|
||||
|
||||
|
||||
**See also**
|
||||
|
||||
- [join_algorithm](../../../operations/settings/settings.md#settings-join_algorithm)
|
||||
@ -57,6 +58,8 @@ The behavior of ClickHouse server for `ANY JOIN` operations depends on the [any_
|
||||
- [join_on_disk_max_files_to_merge](../../../operations/settings/settings.md#join_on_disk_max_files_to_merge)
|
||||
- [any_join_distinct_right_table_keys](../../../operations/settings/settings.md#any_join_distinct_right_table_keys)
|
||||
|
||||
Use the `cross_to_inner_join_rewrite` setting to define the behavior when ClickHouse fails to rewrite a `CROSS JOIN` as an `INNER JOIN`. The default value is `1`, which allows the join to continue but it will be slower. Set `cross_to_inner_join_rewrite` to `0` if you want an error to be thrown, and set it to `2` to not run the cross joins but instead force a rewrite of all comma/cross joins. If the rewriting fails when the value is `2`, you will receive an error message stating "Please, try to simplify `WHERE` section".
|
||||
|
||||
## ON Section Conditions
|
||||
|
||||
An `ON` section can contain several conditions combined using the `AND` and `OR` operators. Conditions specifying join keys must refer both left and right tables and must use the equality operator. Other conditions may use other logical operators but they must refer either the left or the right table of a query.
|
||||
|
||||
@ -30,7 +30,7 @@ This statement is identical to the query:
|
||||
SELECT name FROM system.databases [WHERE name [NOT] LIKE | ILIKE '<pattern>'] [LIMIT <N>] [INTO OUTFILE filename] [FORMAT format]
|
||||
```
|
||||
|
||||
### Examples
|
||||
**Examples**
|
||||
|
||||
Getting database names, containing the symbols sequence 'de' in their names:
|
||||
|
||||
@ -92,7 +92,7 @@ Result:
|
||||
└────────────────────────────────┘
|
||||
```
|
||||
|
||||
### See Also
|
||||
**See also**
|
||||
|
||||
- [CREATE DATABASE](https://clickhouse.com/docs/en/sql-reference/statements/create/database/#query-language-create-database)
|
||||
|
||||
@ -128,7 +128,7 @@ This statement is identical to the query:
|
||||
SELECT name FROM system.tables [WHERE name [NOT] LIKE | ILIKE '<pattern>'] [LIMIT <N>] [INTO OUTFILE <filename>] [FORMAT <format>]
|
||||
```
|
||||
|
||||
### Examples
|
||||
**Examples**
|
||||
|
||||
Getting table names, containing the symbols sequence 'user' in their names:
|
||||
|
||||
@ -191,11 +191,59 @@ Result:
|
||||
└────────────────────────────────┘
|
||||
```
|
||||
|
||||
### See Also
|
||||
**See also**
|
||||
|
||||
- [Create Tables](https://clickhouse.com/docs/en/getting-started/tutorial/#create-tables)
|
||||
- [SHOW CREATE TABLE](https://clickhouse.com/docs/en/sql-reference/statements/show/#show-create-table)
|
||||
|
||||
## SHOW COLUMNS
|
||||
|
||||
Displays a list of columns
|
||||
|
||||
```sql
|
||||
SHOW [EXTENDED] [FULL] COLUMNS {FROM | IN} <table> [{FROM | IN} <db>] [{[NOT] {LIKE | ILIKE} '<pattern>' | WHERE <expr>}] [LIMIT <N>] [INTO
|
||||
OUTFILE <filename>] [FORMAT <format>]
|
||||
```
|
||||
|
||||
The database and table name can be specified in abbreviated form as `<db>.<table>`, i.e. `FROM tab FROM db` and `FROM db.tab` are
|
||||
equivalent. If no database is specified, the query returns the list of columns from the current database.
|
||||
|
||||
The optional keyword `EXTENDED` currently has no effect, it only exists for MySQL compatibility.
|
||||
|
||||
The optional keyword `FULL` causes the output to include the collation, comment and privilege columns.
|
||||
|
||||
`SHOW COLUMNS` produces a result table with the following structure:
|
||||
- field - The name of the column (String)
|
||||
- type - The column data type (String)
|
||||
- null - If the column data type is Nullable (UInt8)
|
||||
- key - `PRI` if the column is part of the primary key, `SOR` if the column is part of the sorting key, empty otherwise (String)
|
||||
- default - Default expression of the column if it is of type `ALIAS`, `DEFAULT`, or `MATERIALIZED`, otherwise `NULL`. (Nullable(String))
|
||||
- extra - Additional information, currently unused (String)
|
||||
- collation - (only if `FULL` keyword was specified) Collation of the column, always `NULL` because ClickHouse has no per-column collations (Nullable(String))
|
||||
- comment - (only if `FULL` keyword was specified) Comment on the column (String)
|
||||
- privilege - (only if `FULL` keyword was specified) The privilege you have on this column, currently not available (String)
|
||||
|
||||
**Examples**
|
||||
|
||||
Getting information about all columns in table 'order' starting with 'delivery_':
|
||||
|
||||
```sql
|
||||
SHOW COLUMNS FROM 'orders' LIKE 'delivery_%'
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
``` text
|
||||
┌─field───────────┬─type─────┬─null─┬─key─────┬─default─┬─extra─┐
|
||||
│ delivery_date │ DateTime │ 0 │ PRI SOR │ ᴺᵁᴸᴸ │ │
|
||||
│ delivery_status │ Bool │ 0 │ │ ᴺᵁᴸᴸ │ │
|
||||
└─────────────────┴──────────┴──────┴─────────┴─────────┴───────┘
|
||||
```
|
||||
|
||||
**See also**
|
||||
|
||||
- [system.columns](https://clickhouse.com/docs/en/operations/system-tables/columns)
|
||||
|
||||
## SHOW DICTIONARIES
|
||||
|
||||
Displays a list of [Dictionaries](../../sql-reference/dictionaries/index.md).
|
||||
@ -212,7 +260,7 @@ You can get the same results as the `SHOW DICTIONARIES` query in the following w
|
||||
SELECT name FROM system.dictionaries WHERE database = <db> [AND name LIKE <pattern>] [LIMIT <N>] [INTO OUTFILE <filename>] [FORMAT <format>]
|
||||
```
|
||||
|
||||
**Example**
|
||||
**Examples**
|
||||
|
||||
The following query selects the first two rows from the list of tables in the `system` database, whose names contain `reg`.
|
||||
|
||||
@ -231,7 +279,7 @@ SHOW DICTIONARIES FROM db LIKE '%reg%' LIMIT 2
|
||||
|
||||
Shows privileges for a user.
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW GRANTS [FOR user1 [, user2 ...]]
|
||||
@ -245,7 +293,7 @@ Shows parameters that were used at a [user creation](../../sql-reference/stateme
|
||||
|
||||
`SHOW CREATE USER` does not output user passwords.
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW CREATE USER [name1 [, name2 ...] | CURRENT_USER]
|
||||
@ -255,7 +303,7 @@ SHOW CREATE USER [name1 [, name2 ...] | CURRENT_USER]
|
||||
|
||||
Shows parameters that were used at a [role creation](../../sql-reference/statements/create/role.md).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW CREATE ROLE name1 [, name2 ...]
|
||||
@ -265,7 +313,7 @@ SHOW CREATE ROLE name1 [, name2 ...]
|
||||
|
||||
Shows parameters that were used at a [row policy creation](../../sql-reference/statements/create/row-policy.md).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW CREATE [ROW] POLICY name ON [database1.]table1 [, [database2.]table2 ...]
|
||||
@ -275,7 +323,7 @@ SHOW CREATE [ROW] POLICY name ON [database1.]table1 [, [database2.]table2 ...]
|
||||
|
||||
Shows parameters that were used at a [quota creation](../../sql-reference/statements/create/quota.md).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW CREATE QUOTA [name1 [, name2 ...] | CURRENT]
|
||||
@ -285,7 +333,7 @@ SHOW CREATE QUOTA [name1 [, name2 ...] | CURRENT]
|
||||
|
||||
Shows parameters that were used at a [settings profile creation](../../sql-reference/statements/create/settings-profile.md).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW CREATE [SETTINGS] PROFILE name1 [, name2 ...]
|
||||
@ -295,7 +343,7 @@ SHOW CREATE [SETTINGS] PROFILE name1 [, name2 ...]
|
||||
|
||||
Returns a list of [user account](../../guides/sre/user-management/index.md#user-account-management) names. To view user accounts parameters, see the system table [system.users](../../operations/system-tables/users.md#system_tables-users).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW USERS
|
||||
@ -305,7 +353,7 @@ SHOW USERS
|
||||
|
||||
Returns a list of [roles](../../guides/sre/user-management/index.md#role-management). To view another parameters, see system tables [system.roles](../../operations/system-tables/roles.md#system_tables-roles) and [system.role_grants](../../operations/system-tables/role-grants.md#system_tables-role_grants).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW [CURRENT|ENABLED] ROLES
|
||||
@ -314,7 +362,7 @@ SHOW [CURRENT|ENABLED] ROLES
|
||||
|
||||
Returns a list of [setting profiles](../../guides/sre/user-management/index.md#settings-profiles-management). To view user accounts parameters, see the system table [settings_profiles](../../operations/system-tables/settings_profiles.md#system_tables-settings_profiles).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW [SETTINGS] PROFILES
|
||||
@ -324,7 +372,7 @@ SHOW [SETTINGS] PROFILES
|
||||
|
||||
Returns a list of [row policies](../../guides/sre/user-management/index.md#row-policy-management) for the specified table. To view user accounts parameters, see the system table [system.row_policies](../../operations/system-tables/row_policies.md#system_tables-row_policies).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW [ROW] POLICIES [ON [db.]table]
|
||||
@ -334,7 +382,7 @@ SHOW [ROW] POLICIES [ON [db.]table]
|
||||
|
||||
Returns a list of [quotas](../../guides/sre/user-management/index.md#quotas-management). To view quotas parameters, see the system table [system.quotas](../../operations/system-tables/quotas.md#system_tables-quotas).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW QUOTAS
|
||||
@ -344,7 +392,7 @@ SHOW QUOTAS
|
||||
|
||||
Returns a [quota](../../operations/quotas.md) consumption for all users or for current user. To view another parameters, see system tables [system.quotas_usage](../../operations/system-tables/quotas_usage.md#system_tables-quotas_usage) and [system.quota_usage](../../operations/system-tables/quota_usage.md#system_tables-quota_usage).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW [CURRENT] QUOTA
|
||||
@ -353,7 +401,7 @@ SHOW [CURRENT] QUOTA
|
||||
|
||||
Shows all [users](../../guides/sre/user-management/index.md#user-account-management), [roles](../../guides/sre/user-management/index.md#role-management), [profiles](../../guides/sre/user-management/index.md#settings-profiles-management), etc. and all their [grants](../../sql-reference/statements/grant.md#grant-privileges).
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW ACCESS
|
||||
@ -366,13 +414,14 @@ Returns a list of clusters. All available clusters are listed in the [system.clu
|
||||
`SHOW CLUSTER name` query displays the contents of system.clusters table for this cluster.
|
||||
:::
|
||||
|
||||
### Syntax
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
SHOW CLUSTER '<name>'
|
||||
SHOW CLUSTERS [[NOT] LIKE|ILIKE '<pattern>'] [LIMIT <N>]
|
||||
```
|
||||
### Examples
|
||||
|
||||
**Examples**
|
||||
|
||||
Query:
|
||||
|
||||
|
||||
@ -283,10 +283,14 @@ SYSTEM START REPLICATION QUEUES [[db.]replicated_merge_tree_family_table_name]
|
||||
Wait until a `ReplicatedMergeTree` table will be synced with other replicas in a cluster, but no more than `receive_timeout` seconds.
|
||||
|
||||
``` sql
|
||||
SYSTEM SYNC REPLICA [ON CLUSTER cluster_name] [db.]replicated_merge_tree_family_table_name [STRICT]
|
||||
SYSTEM SYNC REPLICA [ON CLUSTER cluster_name] [db.]replicated_merge_tree_family_table_name [STRICT | LIGHTWEIGHT | PULL]
|
||||
```
|
||||
|
||||
After running this statement the `[db.]replicated_merge_tree_family_table_name` fetches commands from the common replicated log into its own replication queue, and then the query waits till the replica processes all of the fetched commands. If a `STRICT` modifier was specified then the query waits for the replication queue to become empty. The `STRICT` version may never succeed if new entries constantly appear in the replication queue.
|
||||
After running this statement the `[db.]replicated_merge_tree_family_table_name` fetches commands from the common replicated log into its own replication queue, and then the query waits till the replica processes all of the fetched commands. The following modifiers are supported:
|
||||
|
||||
- If a `STRICT` modifier was specified then the query waits for the replication queue to become empty. The `STRICT` version may never succeed if new entries constantly appear in the replication queue.
|
||||
- If a `LIGHTWEIGHT` modifier was specified then the query waits only for `GET_PART`, `ATTACH_PART`, `DROP_RANGE`, `REPLACE_RANGE` and `DROP_PART` entries to be processed.
|
||||
- If a `PULL` modifier was specified then the query pulls new replication queue entries from ZooKeeper, but does not wait for anything to be processed.
|
||||
|
||||
### RESTART REPLICA
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@ Provides a table-like interface to select/insert files in [Amazon S3](https://aw
|
||||
**Syntax**
|
||||
|
||||
``` sql
|
||||
s3(path [,aws_access_key_id, aws_secret_access_key] [,format] [,structure] [,compression])
|
||||
s3(path [, NOSIGN | aws_access_key_id, aws_secret_access_key] [,format] [,structure] [,compression])
|
||||
```
|
||||
|
||||
:::tip GCS
|
||||
@ -33,6 +33,7 @@ For GCS, substitute your HMAC key and HMAC secret where you see `aws_access_key_
|
||||
and not ~~https://storage.cloud.google.com~~.
|
||||
:::
|
||||
|
||||
- `NOSIGN` - If this keyword is provided in place of credentials, all the requests will not be signed.
|
||||
- `format` — The [format](../../interfaces/formats.md#formats) of the file.
|
||||
- `structure` — Structure of the table. Format `'column1_name column1_type, column2_name column2_type, ...'`.
|
||||
- `compression` — Parameter is optional. Supported values: `none`, `gzip/gz`, `brotli/br`, `xz/LZMA`, `zstd/zst`. By default, it will autodetect compression by file extension.
|
||||
@ -185,6 +186,21 @@ INSERT INTO TABLE FUNCTION
|
||||
```
|
||||
As a result, the data is written into three files in different buckets: `my_bucket_1/file.csv`, `my_bucket_10/file.csv`, and `my_bucket_20/file.csv`.
|
||||
|
||||
## Accessing public buckets
|
||||
|
||||
ClickHouse tries to fetch credentials from many different types of sources.
|
||||
Sometimes, it can produce problems when accessing some buckets that are public causing the client to return `403` error code.
|
||||
This issue can be avoided by using `NOSIGN` keyword, forcing the client to ignore all the credentials, and not sign the requests.
|
||||
|
||||
``` sql
|
||||
SELECT *
|
||||
FROM s3(
|
||||
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/aapl_stock.csv',
|
||||
NOSIGN,
|
||||
'CSVWithNames'
|
||||
)
|
||||
LIMIT 5;
|
||||
```
|
||||
|
||||
**See Also**
|
||||
|
||||
|
||||
54
docs/get-clickhouse-docs.sh
Executable file
54
docs/get-clickhouse-docs.sh
Executable file
@ -0,0 +1,54 @@
|
||||
#!/usr/bin/env bash
|
||||
set -e
|
||||
# The script to clone or update the user-guides documentation repo
|
||||
# https://github.com/ClickHouse/clickhouse-docs
|
||||
|
||||
WORKDIR=$(dirname "$0")
|
||||
WORKDIR=$(readlink -f "${WORKDIR}")
|
||||
cd "$WORKDIR"
|
||||
|
||||
UPDATE_PERIOD_HOURS=${UPDATE_PERIOD_HOURS:=24}
|
||||
|
||||
if [ -d "clickhouse-docs" ]; then
|
||||
git -C clickhouse-docs pull
|
||||
else
|
||||
if [ -n "$1" ]; then
|
||||
url_type="$1"
|
||||
else
|
||||
read -rp "Enter the URL type (ssh | https): " url_type
|
||||
fi
|
||||
case "$url_type" in
|
||||
ssh)
|
||||
git_url=git@github.com:ClickHouse/clickhouse-docs.git
|
||||
;;
|
||||
https)
|
||||
git_url=https://github.com/ClickHouse/clickhouse-docs.git
|
||||
;;
|
||||
*)
|
||||
echo "Url type must be 'ssh' or 'https'"
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
|
||||
if [ -n "$2" ]; then
|
||||
set_git_hook="$2"
|
||||
elif [ -z "$1" ]; then
|
||||
read -rp "Would you like to setup git hook for automatic update? (y|n): " set_git_hook
|
||||
fi
|
||||
|
||||
git clone "$git_url" "clickhouse-docs"
|
||||
|
||||
if [ "$set_git_hook" = "y" ]; then
|
||||
hook_command="$(pwd)/pull-clickhouse-docs-hook.sh $UPDATE_PERIOD_HOURS ||:"
|
||||
hook_file=$(realpath "$(pwd)/../.git/hooks/post-checkout")
|
||||
if grep -Faq "pull-clickhouse-docs-hook.sh" "$hook_file" 2>/dev/null; then
|
||||
echo "Looks like the update hook already exists, will not add another one"
|
||||
else
|
||||
echo "Appending '$hook_command' to $hook_file"
|
||||
echo "$hook_command" >> "$hook_file"
|
||||
chmod u+x "$hook_file" # Just in case it did not exist before append
|
||||
fi
|
||||
elif [ ! "$set_git_hook" = "n" ]; then
|
||||
echo "Expected 'y' or 'n', got '$set_git_hook', will not setup git hook"
|
||||
fi
|
||||
fi
|
||||
27
docs/pull-clickhouse-docs-hook.sh
Executable file
27
docs/pull-clickhouse-docs-hook.sh
Executable file
@ -0,0 +1,27 @@
|
||||
#!/usr/bin/env bash
|
||||
set -e
|
||||
# The script to update user-guides documentation repo
|
||||
# https://github.com/ClickHouse/clickhouse-docs
|
||||
|
||||
WORKDIR=$(dirname "$0")
|
||||
WORKDIR=$(readlink -f "${WORKDIR}")
|
||||
cd "$WORKDIR"
|
||||
|
||||
UPDATE_PERIOD_HOURS="${1:-24}" # By default update once per 24 hours; 0 means "always update"
|
||||
|
||||
if [ ! -d "clickhouse-docs" ]; then
|
||||
echo "There's no clickhouse-docs/ dir, run get-clickhouse-docs.sh first to clone the repo"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Do not update it too often
|
||||
LAST_FETCH_TS=$(stat -c %Y clickhouse-docs/.git/FETCH_HEAD 2>/dev/null || echo 0)
|
||||
CURRENT_TS=$(date +%s)
|
||||
HOURS_SINCE_LAST_FETCH=$(( (CURRENT_TS - LAST_FETCH_TS) / 60 / 60 ))
|
||||
|
||||
if [ "$HOURS_SINCE_LAST_FETCH" -lt "$UPDATE_PERIOD_HOURS" ]; then
|
||||
exit 0;
|
||||
fi
|
||||
|
||||
echo "Updating clickhouse-docs..."
|
||||
git -C clickhouse-docs pull
|
||||
@ -211,4 +211,4 @@ ClickHouse может поддерживать учетные данные Kerbe
|
||||
**Смотрите также**
|
||||
|
||||
- [Виртуальные столбцы](index.md#table_engines-virtual_columns)
|
||||
- [background_message_broker_schedule_pool_size](../../../operations/settings/settings.md#background_message_broker_schedule_pool_size)
|
||||
- [background_message_broker_schedule_pool_size](../../../operations/server-configuration-parameters/settings.md#background_message_broker_schedule_pool_size)
|
||||
|
||||
@ -752,7 +752,7 @@ SETTINGS storage_policy = 'moving_from_ssd_to_hdd'
|
||||
Изменить политику хранения после создания таблицы можно при помощи запроса [ALTER TABLE ... MODIFY SETTING]. При этом необходимо учесть, что новая политика должна содержать все тома и диски предыдущей политики с теми же именами.
|
||||
|
||||
|
||||
Количество потоков для фоновых перемещений кусков между дисками можно изменить с помощью настройки [background_move_pool_size](../../../operations/settings/settings.md#background_move_pool_size)
|
||||
Количество потоков для фоновых перемещений кусков между дисками можно изменить с помощью настройки [background_move_pool_size](../../../operations/server-configuration-parameters/settings.md#background_move_pool_size)
|
||||
|
||||
### Особенности работы {#details}
|
||||
|
||||
|
||||
@ -64,9 +64,9 @@ ClickHouse хранит метаинформацию о репликах в [Apa
|
||||
|
||||
Для очень больших кластеров, можно использовать разные кластеры ZooKeeper для разных шардов. Впрочем, на кластере Яндекс.Метрики (примерно 300 серверов) такой необходимости не возникает.
|
||||
|
||||
Репликация асинхронная, мульти-мастер. Запросы `INSERT` и `ALTER` можно направлять на любой доступный сервер. Данные вставятся на сервер, где выполнен запрос, а затем скопируются на остальные серверы. В связи с асинхронностью, только что вставленные данные появляются на остальных репликах с небольшой задержкой. Если часть реплик недоступна, данные на них запишутся тогда, когда они станут доступны. Если реплика доступна, то задержка составляет столько времени, сколько требуется для передачи блока сжатых данных по сети. Количество потоков для выполнения фоновых задач можно задать с помощью настройки [background_schedule_pool_size](../../../operations/settings/settings.md#background_schedule_pool_size).
|
||||
Репликация асинхронная, мульти-мастер. Запросы `INSERT` и `ALTER` можно направлять на любой доступный сервер. Данные вставятся на сервер, где выполнен запрос, а затем скопируются на остальные серверы. В связи с асинхронностью, только что вставленные данные появляются на остальных репликах с небольшой задержкой. Если часть реплик недоступна, данные на них запишутся тогда, когда они станут доступны. Если реплика доступна, то задержка составляет столько времени, сколько требуется для передачи блока сжатых данных по сети. Количество потоков для выполнения фоновых задач можно задать с помощью настройки [background_schedule_pool_size](../../../operations/server-configuration-parameters/settings.md#background_schedule_pool_size).
|
||||
|
||||
Движок `ReplicatedMergeTree` использует отдельный пул потоков для скачивания кусков данных. Размер пула ограничен настройкой [background_fetches_pool_size](../../../operations/settings/settings.md#background_fetches_pool_size), которую можно указать при перезапуске сервера.
|
||||
Движок `ReplicatedMergeTree` использует отдельный пул потоков для скачивания кусков данных. Размер пула ограничен настройкой [background_fetches_pool_size](../../../operations/server-configuration-parameters/settings.md#background_fetches_pool_size), которую можно указать при перезапуске сервера.
|
||||
|
||||
По умолчанию, запрос INSERT ждёт подтверждения записи только от одной реплики. Если данные были успешно записаны только на одну реплику, и сервер с этой репликой перестал существовать, то записанные данные будут потеряны. Вы можете включить подтверждение записи от нескольких реплик, используя настройку `insert_quorum`.
|
||||
|
||||
@ -251,8 +251,8 @@ $ sudo -u clickhouse touch /var/lib/clickhouse/flags/force_restore_data
|
||||
|
||||
**Смотрите также**
|
||||
|
||||
- [background_schedule_pool_size](../../../operations/settings/settings.md#background_schedule_pool_size)
|
||||
- [background_fetches_pool_size](../../../operations/settings/settings.md#background_fetches_pool_size)
|
||||
- [background_schedule_pool_size](../../../operations/server-configuration-parameters/settings.md#background_schedule_pool_size)
|
||||
- [background_fetches_pool_size](../../../operations/server-configuration-parameters/settings.md#background_fetches_pool_size)
|
||||
- [execute_merges_on_single_replica_time_threshold](../../../operations/settings/settings.md#execute-merges-on-single-replica-time-threshold)
|
||||
- [max_replicated_fetches_network_bandwidth](../../../operations/settings/merge-tree-settings.md#max_replicated_fetches_network_bandwidth)
|
||||
- [max_replicated_sends_network_bandwidth](../../../operations/settings/merge-tree-settings.md#max_replicated_sends_network_bandwidth)
|
||||
|
||||
@ -225,6 +225,7 @@ ClickHouse проверяет условия для `min_part_size` и `min_part
|
||||
``` xml
|
||||
<default_replica_path>/clickhouse/tables/{uuid}/{shard}</default_replica_path>
|
||||
```
|
||||
|
||||
## default_replica_name {#default_replica_name}
|
||||
|
||||
Имя реплики в ZooKeeper.
|
||||
@ -916,6 +917,72 @@ ClickHouse использует потоки из глобального пул
|
||||
<thread_pool_queue_size>12000</thread_pool_queue_size>
|
||||
```
|
||||
|
||||
## background_buffer_flush_schedule_pool_size {#background_buffer_flush_schedule_pool_size}
|
||||
|
||||
Задает количество потоков для выполнения фонового сброса данных в таблицах с движком [Buffer](../../engines/table-engines/special/buffer.md).
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 16.
|
||||
|
||||
## background_move_pool_size {#background_move_pool_size}
|
||||
|
||||
Задает количество потоков для фоновых перемещений кусков между дисками. Работает для таблиц с движком [MergeTree](../../engines/table-engines/mergetree-family/mergetree.md#table_engine-mergetree-multiple-volumes).
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 8.
|
||||
|
||||
## background_schedule_pool_size {#background_schedule_pool_size}
|
||||
|
||||
Задает количество потоков для выполнения фоновых задач. Работает для [реплицируемых](../../engines/table-engines/mergetree-family/replication.md) таблиц, стримов в [Kafka](../../engines/table-engines/integrations/kafka.md) и обновления IP адресов у записей во внутреннем [DNS кеше](../server-configuration-parameters/settings.md#server-settings-dns-cache-update-period).
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 128.
|
||||
|
||||
## background_fetches_pool_size {#background_fetches_pool_size}
|
||||
|
||||
Задает количество потоков для скачивания кусков данных для [реплицируемых](../../engines/table-engines/mergetree-family/replication.md) таблиц. Для использования в продакшене с частыми небольшими вставками или медленным кластером ZooKeeper рекомендуется использовать значение по умолчанию.
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 8.
|
||||
|
||||
## background_distributed_schedule_pool_size {#background_distributed_schedule_pool_size}
|
||||
|
||||
Задает количество потоков для выполнения фоновых задач. Работает для таблиц с движком [Distributed](../../engines/table-engines/special/distributed.md).
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 16.
|
||||
|
||||
## background_message_broker_schedule_pool_size {#background_message_broker_schedule_pool_size}
|
||||
|
||||
Задает количество потоков для фонового потокового вывода сообщений.
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 16.
|
||||
|
||||
**Смотрите также**
|
||||
|
||||
- Движок [Kafka](../../engines/table-engines/integrations/kafka.md#kafka).
|
||||
- Движок [RabbitMQ](../../engines/table-engines/integrations/rabbitmq.md#rabbitmq-engine).
|
||||
|
||||
|
||||
## merge_tree {#server_configuration_parameters-merge_tree}
|
||||
|
||||
Тонкая настройка таблиц семейства [MergeTree](../../operations/server-configuration-parameters/settings.md).
|
||||
|
||||
@ -1122,6 +1122,7 @@ SELECT type, query FROM system.query_log WHERE log_comment = 'log_comment test'
|
||||
:::note "Предупреждение"
|
||||
Эта настройка экспертного уровня, не используйте ее, если вы только начинаете работать с Clickhouse.
|
||||
:::
|
||||
|
||||
## max_query_size {#settings-max_query_size}
|
||||
|
||||
Максимальный кусок запроса, который будет считан в оперативку для разбора парсером языка SQL.
|
||||
@ -2517,68 +2518,27 @@ SELECT idx, i FROM null_in WHERE i IN (1, NULL) SETTINGS transform_null_in = 1;
|
||||
|
||||
## background_buffer_flush_schedule_pool_size {#background_buffer_flush_schedule_pool_size}
|
||||
|
||||
Задает количество потоков для выполнения фонового сброса данных в таблицах с движком [Buffer](../../engines/table-engines/special/buffer.md). Настройка применяется при запуске сервера ClickHouse и не может быть изменена в пользовательском сеансе.
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 16.
|
||||
Параметр перенесен в [серверную конфигурацию](../../operations/server-configuration-parameters/settings.md/#background_buffer_flush_schedule_pool_size).
|
||||
|
||||
## background_move_pool_size {#background_move_pool_size}
|
||||
|
||||
Задает количество потоков для фоновых перемещений кусков между дисками. Работает для таблиц с движком [MergeTree](../../engines/table-engines/mergetree-family/mergetree.md#table_engine-mergetree-multiple-volumes). Настройка применяется при запуске сервера ClickHouse и не может быть изменена в пользовательском сеансе.
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 8.
|
||||
Параметр перенесен в [серверную конфигурацию](../../operations/server-configuration-parameters/settings.md/#background_move_pool_size).
|
||||
|
||||
## background_schedule_pool_size {#background_schedule_pool_size}
|
||||
|
||||
Задает количество потоков для выполнения фоновых задач. Работает для [реплицируемых](../../engines/table-engines/mergetree-family/replication.md) таблиц, стримов в [Kafka](../../engines/table-engines/integrations/kafka.md) и обновления IP адресов у записей во внутреннем [DNS кеше](../server-configuration-parameters/settings.md#server-settings-dns-cache-update-period). Настройка применяется при запуске сервера ClickHouse и не может быть изменена в пользовательском сеансе.
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 128.
|
||||
Параметр перенесен в [серверную конфигурацию](../../operations/server-configuration-parameters/settings.md/#background_schedule_pool_size).
|
||||
|
||||
## background_fetches_pool_size {#background_fetches_pool_size}
|
||||
|
||||
Задает количество потоков для скачивания кусков данных для [реплицируемых](../../engines/table-engines/mergetree-family/replication.md) таблиц. Настройка применяется при запуске сервера ClickHouse и не может быть изменена в пользовательском сеансе. Для использования в продакшене с частыми небольшими вставками или медленным кластером ZooKeeper рекомендуется использовать значение по умолчанию.
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 8.
|
||||
Параметр перенесен в [серверную конфигурацию](../../operations/server-configuration-parameters/settings.md/#background_fetches_pool_size).
|
||||
|
||||
## background_distributed_schedule_pool_size {#background_distributed_schedule_pool_size}
|
||||
|
||||
Задает количество потоков для выполнения фоновых задач. Работает для таблиц с движком [Distributed](../../engines/table-engines/special/distributed.md). Настройка применяется при запуске сервера ClickHouse и не может быть изменена в пользовательском сеансе.
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 16.
|
||||
Параметр перенесен в [серверную конфигурацию](../../operations/server-configuration-parameters/settings.md/#background_distributed_schedule_pool_size).
|
||||
|
||||
## background_message_broker_schedule_pool_size {#background_message_broker_schedule_pool_size}
|
||||
|
||||
Задает количество потоков для фонового потокового вывода сообщений. Настройка применяется при запуске сервера ClickHouse и не может быть изменена в пользовательском сеансе.
|
||||
|
||||
Допустимые значения:
|
||||
|
||||
- Положительное целое число.
|
||||
|
||||
Значение по умолчанию: 16.
|
||||
|
||||
**Смотрите также**
|
||||
|
||||
- Движок [Kafka](../../engines/table-engines/integrations/kafka.md#kafka).
|
||||
- Движок [RabbitMQ](../../engines/table-engines/integrations/rabbitmq.md#rabbitmq-engine).
|
||||
Параметр перенесен в [серверную конфигурацию](../../operations/server-configuration-parameters/settings.md/#background_message_broker_schedule_pool_size).
|
||||
|
||||
## format_avro_schema_registry_url {#format_avro_schema_registry_url}
|
||||
|
||||
@ -3388,6 +3348,7 @@ SELECT * FROM test LIMIT 10 OFFSET 100;
|
||||
│ 109 │
|
||||
└─────┘
|
||||
```
|
||||
|
||||
## http_connection_timeout {#http_connection_timeout}
|
||||
|
||||
Тайм-аут для HTTP-соединения (в секундах).
|
||||
@ -4085,7 +4046,7 @@ ALTER TABLE test FREEZE SETTINGS alter_partition_verbose_result = 1;
|
||||
|
||||
Значение по умолчанию: `''`.
|
||||
|
||||
## stop_reading_on_first_cancel {#stop_reading_on_first_cancel}
|
||||
## partial_result_on_first_cancel {#partial_result_on_first_cancel}
|
||||
Если установлено значение `true` и пользователь хочет прервать запрос (например, с помощью `Ctrl+C` на клиенте), то запрос продолжает выполнение только для данных, которые уже были считаны из таблицы. После этого он вернет частичный результат запроса для той части таблицы, которая была прочитана. Чтобы полностью остановить выполнение запроса без частичного результата, пользователь должен отправить 2 запроса отмены.
|
||||
|
||||
**Пример с выключенной настройкой при нажатии Ctrl+C**
|
||||
@ -4101,7 +4062,7 @@ Query was cancelled.
|
||||
|
||||
**Пример с включенной настройкой при нажатии Ctrl+C**
|
||||
```sql
|
||||
SELECT sum(number) FROM numbers(10000000000) SETTINGS stop_reading_on_first_cancel=true
|
||||
SELECT sum(number) FROM numbers(10000000000) SETTINGS partial_result_on_first_cancel=true
|
||||
|
||||
┌──────sum(number)─┐
|
||||
│ 1355411451286266 │
|
||||
|
||||
@ -553,6 +553,44 @@ SELECT toFixedString('foo\0bar', 8) AS s, toStringCutToZero(s) AS s_cut;
|
||||
└────────────┴───────┘
|
||||
```
|
||||
|
||||
## toDecimalString
|
||||
|
||||
Принимает любой численный тип первым аргументом, возвращает строковое десятичное представление числа с точностью, заданной вторым аргументом.
|
||||
|
||||
**Синтаксис**
|
||||
|
||||
``` sql
|
||||
toDecimalString(number, scale)
|
||||
```
|
||||
|
||||
**Параметры**
|
||||
|
||||
- `number` — Значение любого числового типа: [Int, UInt](/docs/ru/sql-reference/data-types/int-uint.md), [Float](/docs/ru/sql-reference/data-types/float.md), [Decimal](/docs/ru/sql-reference/data-types/decimal.md),
|
||||
- `scale` — Требуемое количество десятичных знаков после запятой, [UInt8](/docs/ru/sql-reference/data-types/int-uint.md).
|
||||
* Значение `scale` для типов [Decimal](/docs/ru/sql-reference/data-types/decimal.md) и [Int, UInt](/docs/ru/sql-reference/data-types/int-uint.md) должно не превышать 77 (так как это наибольшее количество значимых символов для этих типов),
|
||||
* Значение `scale` для типа [Float](/docs/ru/sql-reference/data-types/float.md) не должно превышать 60.
|
||||
|
||||
**Возвращаемое значение**
|
||||
|
||||
- Строка ([String](/docs/en/sql-reference/data-types/string.md)), представляющая собой десятичное представление входного числа с заданной длиной дробной части.
|
||||
При необходимости число округляется по стандартным правилам арифметики.
|
||||
|
||||
**Пример использования**
|
||||
|
||||
Запрос:
|
||||
|
||||
``` sql
|
||||
SELECT toDecimalString(CAST('64.32', 'Float64'), 5);
|
||||
```
|
||||
|
||||
Результат:
|
||||
|
||||
```response
|
||||
┌─toDecimalString(CAST('64.32', 'Float64'), 5)┐
|
||||
│ 64.32000 │
|
||||
└─────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
## reinterpretAsUInt(8\|16\|32\|64) {#reinterpretasuint8163264}
|
||||
|
||||
## reinterpretAsInt(8\|16\|32\|64) {#reinterpretasint8163264}
|
||||
|
||||
@ -272,10 +272,14 @@ SYSTEM START REPLICATION QUEUES [[db.]replicated_merge_tree_family_table_name]
|
||||
Ждет когда таблица семейства `ReplicatedMergeTree` будет синхронизирована с другими репликами в кластере, но не более `receive_timeout` секунд:
|
||||
|
||||
``` sql
|
||||
SYSTEM SYNC REPLICA [db.]replicated_merge_tree_family_table_name [STRICT]
|
||||
SYSTEM SYNC REPLICA [db.]replicated_merge_tree_family_table_name [STRICT | LIGHTWEIGHT | PULL]
|
||||
```
|
||||
|
||||
После выполнения этого запроса таблица `[db.]replicated_merge_tree_family_table_name` загружает команды из общего реплицированного лога в свою собственную очередь репликации. Затем запрос ждет, пока реплика не обработает все загруженные команды. Если указан модификатор `STRICT`, то запрос ждёт когда очередь репликации станет пустой. Строгий вариант запроса может никогда не завершиться успешно, если в очереди репликации постоянно появляются новые записи.
|
||||
После выполнения этого запроса таблица `[db.]replicated_merge_tree_family_table_name` загружает команды из общего реплицированного лога в свою собственную очередь репликации. Затем запрос ждет, пока реплика не обработает все загруженные команды. Поддерживаются следующие модификаторы:
|
||||
|
||||
- Если указан модификатор `STRICT`, то запрос ждёт когда очередь репликации станет пустой. Строгий вариант запроса может никогда не завершиться успешно, если в очереди репликации постоянно появляются новые записи.
|
||||
- Если указан модификатор `LIGHTWEIGHT`, то запрос ждёт когда будут обработаны записи `GET_PART`, `ATTACH_PART`, `DROP_RANGE`, `REPLACE_RANGE` и `DROP_PART`.
|
||||
- Если указан модификатор `PULL`, то запрос только загружает записи очереди репликации из ZooKeeper и не ждёт выполнения чего-либо.
|
||||
|
||||
### RESTART REPLICA {#query_language-system-restart-replica}
|
||||
|
||||
|
||||
@ -163,4 +163,4 @@ clickhouse也支持自己使用keyfile的方式来维护kerbros的凭证。配
|
||||
**另请参阅**
|
||||
|
||||
- [虚拟列](../../../engines/table-engines/index.md#table_engines-virtual_columns)
|
||||
- [后台消息代理调度池大小](../../../operations/settings/settings.md#background_message_broker_schedule_pool_size)
|
||||
- [后台消息代理调度池大小](../../../operations/server-configuration-parameters/settings.md#background_message_broker_schedule_pool_size)
|
||||
|
||||
@ -689,7 +689,7 @@ SETTINGS storage_policy = 'moving_from_ssd_to_hdd'
|
||||
|
||||
`default` 存储策略意味着只使用一个卷,这个卷只包含一个在 `<path>` 中定义的磁盘。您可以使用[ALTER TABLE ... MODIFY SETTING]来修改存储策略,新的存储策略应该包含所有以前的磁盘和卷,并使用相同的名称。
|
||||
|
||||
可以通过 [background_move_pool_size](../../../operations/settings/settings.md#background_move_pool_size) 设置调整执行后台任务的线程数。
|
||||
可以通过 [background_move_pool_size](../../../operations/server-configuration-parameters/settings.md#background_move_pool_size) 设置调整执行后台任务的线程数。
|
||||
|
||||
### 详细说明 {#details}
|
||||
|
||||
|
||||
@ -98,7 +98,7 @@ CREATE TABLE table_name ( ... ) ENGINE = ReplicatedMergeTree('zookeeper_name_con
|
||||
|
||||
对于非常大的集群,你可以把不同的 ZooKeeper 集群用于不同的分片。然而,即使 Yandex.Metrica 集群(大约300台服务器)也证明还不需要这么做。
|
||||
|
||||
复制是多主异步。 `INSERT` 语句(以及 `ALTER` )可以发给任意可用的服务器。数据会先插入到执行该语句的服务器上,然后被复制到其他服务器。由于它是异步的,在其他副本上最近插入的数据会有一些延迟。如果部分副本不可用,则数据在其可用时再写入。副本可用的情况下,则延迟时长是通过网络传输压缩数据块所需的时间。为复制表执行后台任务的线程数量,可以通过 [background_schedule_pool_size](../../../operations/settings/settings.md#background_schedule_pool_size) 进行设置。
|
||||
复制是多主异步。 `INSERT` 语句(以及 `ALTER` )可以发给任意可用的服务器。数据会先插入到执行该语句的服务器上,然后被复制到其他服务器。由于它是异步的,在其他副本上最近插入的数据会有一些延迟。如果部分副本不可用,则数据在其可用时再写入。副本可用的情况下,则延迟时长是通过网络传输压缩数据块所需的时间。为复制表执行后台任务的线程数量,可以通过 [background_schedule_pool_size](../../../operations/server-configuration-parameters/settings.md#background_schedule_pool_size) 进行设置。
|
||||
|
||||
`ReplicatedMergeTree` 引擎采用一个独立的线程池进行复制拉取。线程池的大小通过 [background_fetches_pool_size](../../../operations/settings/settings.md#background_fetches_pool_size) 进行限定,它可以在重启服务器时进行调整。
|
||||
|
||||
@ -282,8 +282,8 @@ sudo -u clickhouse touch /var/lib/clickhouse/flags/force_restore_data
|
||||
|
||||
**参考**
|
||||
|
||||
- [background_schedule_pool_size](../../../operations/settings/settings.md#background_schedule_pool_size)
|
||||
- [background_fetches_pool_size](../../../operations/settings/settings.md#background_fetches_pool_size)
|
||||
- [background_schedule_pool_size](../../../operations/server-configuration-parameters/settings.md#background_schedule_pool_size)
|
||||
- [background_fetches_pool_size](../../../operations/server-configuration-parameters/settings.md#background_fetches_pool_size)
|
||||
- [execute_merges_on_single_replica_time_threshold](../../../operations/settings/settings.md#execute-merges-on-single-replica-time-threshold)
|
||||
- [max_replicated_fetches_network_bandwidth](../../../operations/settings/merge-tree-settings.mdx#max_replicated_fetches_network_bandwidth)
|
||||
- [max_replicated_sends_network_bandwidth](../../../operations/settings/merge-tree-settings.mdx#max_replicated_sends_network_bandwidth)
|
||||
|
||||
@ -240,7 +240,7 @@ SYSTEM START REPLICATION QUEUES [[db.]replicated_merge_tree_family_table_name]
|
||||
|
||||
|
||||
``` sql
|
||||
SYSTEM SYNC REPLICA [db.]replicated_merge_tree_family_table_name
|
||||
SYSTEM SYNC REPLICA [db.]replicated_merge_tree_family_table_name [STRICT | LIGHTWEIGHT | PULL]
|
||||
```
|
||||
|
||||
### RESTART REPLICA {#query_language-system-restart-replica}
|
||||
|
||||
@ -34,6 +34,7 @@
|
||||
#include <Common/Config/configReadClient.h>
|
||||
#include <Common/TerminalSize.h>
|
||||
#include <Common/StudentTTest.h>
|
||||
#include <Common/CurrentMetrics.h>
|
||||
#include <filesystem>
|
||||
|
||||
|
||||
@ -43,6 +44,12 @@ namespace fs = std::filesystem;
|
||||
* The tool emulates a case with fixed amount of simultaneously executing queries.
|
||||
*/
|
||||
|
||||
namespace CurrentMetrics
|
||||
{
|
||||
extern const Metric LocalThread;
|
||||
extern const Metric LocalThreadActive;
|
||||
}
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
@ -103,7 +110,7 @@ public:
|
||||
settings(settings_),
|
||||
shared_context(Context::createShared()),
|
||||
global_context(Context::createGlobal(shared_context.get())),
|
||||
pool(concurrency)
|
||||
pool(CurrentMetrics::LocalThread, CurrentMetrics::LocalThreadActive, concurrency)
|
||||
{
|
||||
const auto secure = secure_ ? Protocol::Secure::Enable : Protocol::Secure::Disable;
|
||||
size_t connections_cnt = std::max(ports_.size(), hosts_.size());
|
||||
|
||||
@ -6,6 +6,7 @@
|
||||
#include <Common/ZooKeeper/ZooKeeper.h>
|
||||
#include <Common/ZooKeeper/KeeperException.h>
|
||||
#include <Common/setThreadName.h>
|
||||
#include <Common/CurrentMetrics.h>
|
||||
#include <Interpreters/InterpreterInsertQuery.h>
|
||||
#include <Interpreters/InterpreterSelectWithUnionQuery.h>
|
||||
#include <Parsers/ASTFunction.h>
|
||||
@ -19,6 +20,12 @@
|
||||
#include <Processors/QueryPlan/BuildQueryPipelineSettings.h>
|
||||
#include <Processors/QueryPlan/Optimizations/QueryPlanOptimizationSettings.h>
|
||||
|
||||
namespace CurrentMetrics
|
||||
{
|
||||
extern const Metric LocalThread;
|
||||
extern const Metric LocalThreadActive;
|
||||
}
|
||||
|
||||
namespace DB
|
||||
{
|
||||
|
||||
@ -192,7 +199,7 @@ void ClusterCopier::discoverTablePartitions(const ConnectionTimeouts & timeouts,
|
||||
{
|
||||
/// Fetch partitions list from a shard
|
||||
{
|
||||
ThreadPool thread_pool(num_threads ? num_threads : 2 * getNumberOfPhysicalCPUCores());
|
||||
ThreadPool thread_pool(CurrentMetrics::LocalThread, CurrentMetrics::LocalThreadActive, num_threads ? num_threads : 2 * getNumberOfPhysicalCPUCores());
|
||||
|
||||
for (const TaskShardPtr & task_shard : task_table.all_shards)
|
||||
thread_pool.scheduleOrThrowOnError([this, timeouts, task_shard]()
|
||||
|
||||
@ -315,12 +315,12 @@ struct Keeper::KeeperHTTPContext : public IHTTPContext
|
||||
|
||||
Poco::Timespan getReceiveTimeout() const override
|
||||
{
|
||||
return context->getConfigRef().getUInt64("keeper_server.http_receive_timeout", DEFAULT_HTTP_READ_BUFFER_TIMEOUT);
|
||||
return {context->getConfigRef().getInt64("keeper_server.http_receive_timeout", DBMS_DEFAULT_RECEIVE_TIMEOUT_SEC), 0};
|
||||
}
|
||||
|
||||
Poco::Timespan getSendTimeout() const override
|
||||
{
|
||||
return context->getConfigRef().getUInt64("keeper_server.http_send_timeout", DEFAULT_HTTP_READ_BUFFER_TIMEOUT);
|
||||
return {context->getConfigRef().getInt64("keeper_server.http_send_timeout", DBMS_DEFAULT_SEND_TIMEOUT_SEC), 0};
|
||||
}
|
||||
|
||||
TinyContextPtr context;
|
||||
@ -445,6 +445,9 @@ try
|
||||
return tiny_context->getConfigRef();
|
||||
};
|
||||
|
||||
auto tcp_receive_timeout = config().getInt64("keeper_server.socket_receive_timeout_sec", DBMS_DEFAULT_RECEIVE_TIMEOUT_SEC);
|
||||
auto tcp_send_timeout = config().getInt64("keeper_server.socket_send_timeout_sec", DBMS_DEFAULT_SEND_TIMEOUT_SEC);
|
||||
|
||||
for (const auto & listen_host : listen_hosts)
|
||||
{
|
||||
/// TCP Keeper
|
||||
@ -453,8 +456,8 @@ try
|
||||
{
|
||||
Poco::Net::ServerSocket socket;
|
||||
auto address = socketBindListen(socket, listen_host, port);
|
||||
socket.setReceiveTimeout(config().getUInt64("keeper_server.socket_receive_timeout_sec", DBMS_DEFAULT_RECEIVE_TIMEOUT_SEC));
|
||||
socket.setSendTimeout(config().getUInt64("keeper_server.socket_send_timeout_sec", DBMS_DEFAULT_SEND_TIMEOUT_SEC));
|
||||
socket.setReceiveTimeout(Poco::Timespan{tcp_receive_timeout, 0});
|
||||
socket.setSendTimeout(Poco::Timespan{tcp_send_timeout, 0});
|
||||
servers->emplace_back(
|
||||
listen_host,
|
||||
port_name,
|
||||
@ -462,8 +465,7 @@ try
|
||||
std::make_unique<TCPServer>(
|
||||
new KeeperTCPHandlerFactory(
|
||||
config_getter, tiny_context->getKeeperDispatcher(),
|
||||
config().getUInt64("keeper_server.socket_receive_timeout_sec", DBMS_DEFAULT_RECEIVE_TIMEOUT_SEC),
|
||||
config().getUInt64("keeper_server.socket_send_timeout_sec", DBMS_DEFAULT_SEND_TIMEOUT_SEC), false), server_pool, socket));
|
||||
tcp_receive_timeout, tcp_send_timeout, false), server_pool, socket));
|
||||
});
|
||||
|
||||
const char * secure_port_name = "keeper_server.tcp_port_secure";
|
||||
@ -472,8 +474,8 @@ try
|
||||
#if USE_SSL
|
||||
Poco::Net::SecureServerSocket socket;
|
||||
auto address = socketBindListen(socket, listen_host, port, /* secure = */ true);
|
||||
socket.setReceiveTimeout(config().getUInt64("keeper_server.socket_receive_timeout_sec", DBMS_DEFAULT_RECEIVE_TIMEOUT_SEC));
|
||||
socket.setSendTimeout(config().getUInt64("keeper_server.socket_send_timeout_sec", DBMS_DEFAULT_SEND_TIMEOUT_SEC));
|
||||
socket.setReceiveTimeout(Poco::Timespan{tcp_receive_timeout, 0});
|
||||
socket.setSendTimeout(Poco::Timespan{tcp_send_timeout, 0});
|
||||
servers->emplace_back(
|
||||
listen_host,
|
||||
secure_port_name,
|
||||
@ -481,8 +483,7 @@ try
|
||||
std::make_unique<TCPServer>(
|
||||
new KeeperTCPHandlerFactory(
|
||||
config_getter, tiny_context->getKeeperDispatcher(),
|
||||
config().getUInt64("keeper_server.socket_receive_timeout_sec", DBMS_DEFAULT_RECEIVE_TIMEOUT_SEC),
|
||||
config().getUInt64("keeper_server.socket_send_timeout_sec", DBMS_DEFAULT_SEND_TIMEOUT_SEC), true), server_pool, socket));
|
||||
tcp_receive_timeout, tcp_send_timeout, true), server_pool, socket));
|
||||
#else
|
||||
UNUSED(port);
|
||||
throw Exception(ErrorCodes::SUPPORT_IS_DISABLED, "SSL support for TCP protocol is disabled because Poco library was built without NetSSL support.");
|
||||
@ -490,18 +491,18 @@ try
|
||||
});
|
||||
|
||||
const auto & config = config_getter();
|
||||
auto http_context = httpContext();
|
||||
Poco::Timespan keep_alive_timeout(config.getUInt("keep_alive_timeout", 10), 0);
|
||||
Poco::Net::HTTPServerParams::Ptr http_params = new Poco::Net::HTTPServerParams;
|
||||
http_params->setTimeout(DBMS_DEFAULT_RECEIVE_TIMEOUT_SEC);
|
||||
http_params->setTimeout(http_context->getReceiveTimeout());
|
||||
http_params->setKeepAliveTimeout(keep_alive_timeout);
|
||||
|
||||
/// Prometheus (if defined and not setup yet with http_port)
|
||||
port_name = "prometheus.port";
|
||||
createServer(listen_host, port_name, listen_try, [&](UInt16 port)
|
||||
createServer(listen_host, port_name, listen_try, [&, http_context = std::move(http_context)](UInt16 port) mutable
|
||||
{
|
||||
Poco::Net::ServerSocket socket;
|
||||
auto address = socketBindListen(socket, listen_host, port);
|
||||
auto http_context = httpContext();
|
||||
socket.setReceiveTimeout(http_context->getReceiveTimeout());
|
||||
socket.setSendTimeout(http_context->getSendTimeout());
|
||||
servers->emplace_back(
|
||||
|
||||
@ -30,7 +30,6 @@
|
||||
#include <Processors/Executors/PullingPipelineExecutor.h>
|
||||
#include <Processors/Executors/PushingPipelineExecutor.h>
|
||||
#include <Core/Block.h>
|
||||
#include <base/StringRef.h>
|
||||
#include <Common/DateLUT.h>
|
||||
#include <IO/ReadBufferFromFileDescriptor.h>
|
||||
#include <IO/WriteBufferFromFileDescriptor.h>
|
||||
|
||||
354
programs/obfuscator/README.md
Normal file
354
programs/obfuscator/README.md
Normal file
@ -0,0 +1,354 @@
|
||||
## clickhouse-obfuscator — a tool for dataset anonymization
|
||||
|
||||
### Installation And Usage
|
||||
|
||||
```
|
||||
curl https://clickhouse.com/ | sh
|
||||
./clickhouse obfuscator --help
|
||||
```
|
||||
|
||||
### Example
|
||||
|
||||
```
|
||||
./clickhouse obfuscator --seed 123 --input-format TSV --output-format TSV \
|
||||
--structure 'CounterID UInt32, URLDomain String, URL String, SearchPhrase String, Title String' \
|
||||
< source.tsv > result.tsv
|
||||
```
|
||||
|
||||
|
||||
### A long, long time ago...
|
||||
|
||||
ClickHouse users already know that its biggest advantage is its high-speed processing of analytical queries. But claims like this need to be confirmed with reliable performance testing. That's what we want to talk about today.
|
||||
|
||||
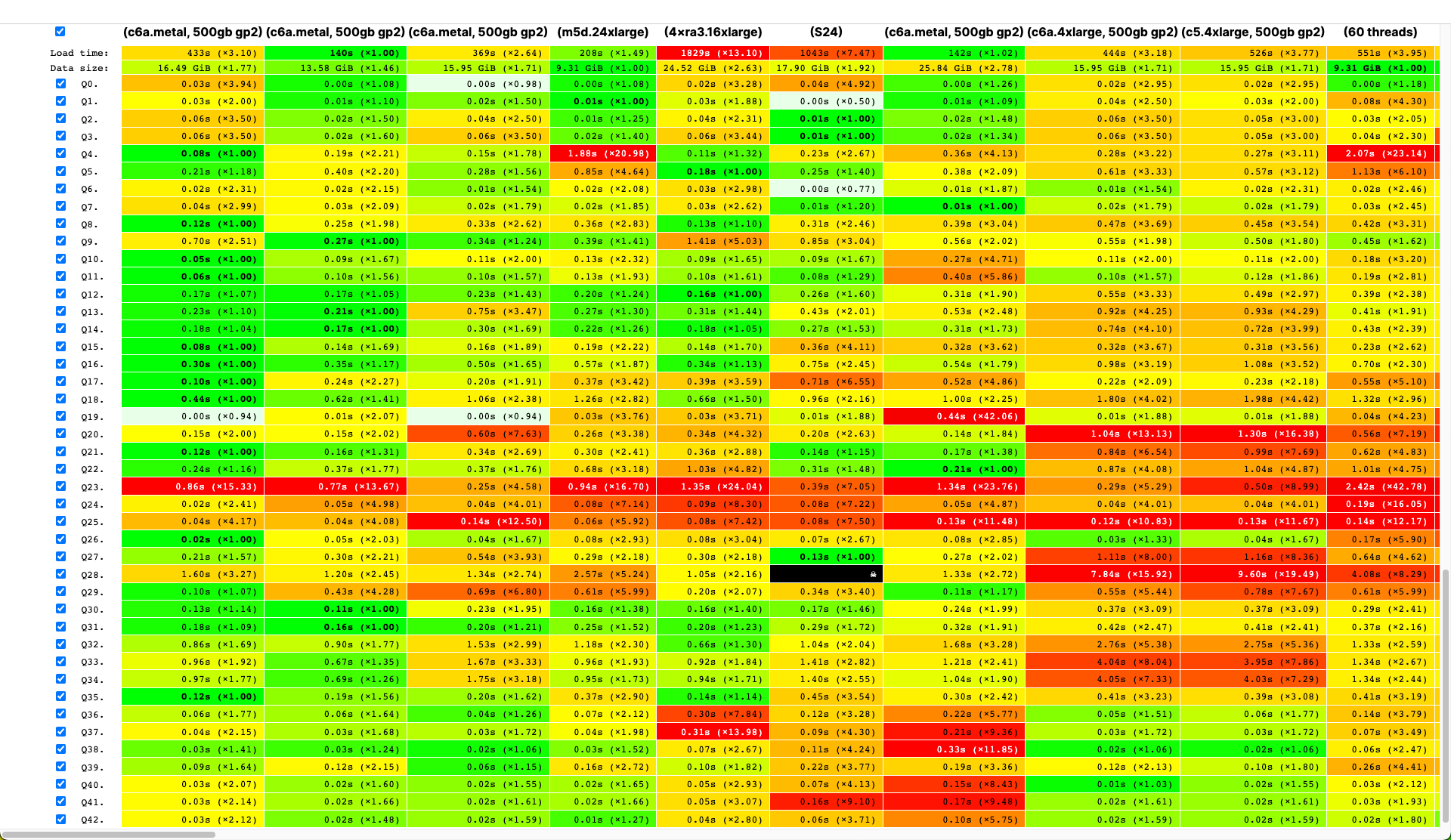
|
||||
|
||||
We started running tests in 2013, long before ClickHouse was available as open source. Back then, our main concern was data processing speed for a web analytics product. We started storing this data, which we would later store in ClickHouse, in January 2009. Part of the data had been written to a database starting in 2012, and part was converted from OLAPServer and Metrage (data structures previously used by the solution). For testing, we took the first subset at random from data for 1 billion pageviews. Our web analytics platform didn't have any queries at that point, so we came up with queries that interested us, using all the possible ways to filter, aggregate, and sort the data.
|
||||
|
||||
ClickHouse performance was compared with similar systems like Vertica and MonetDB. To avoid bias, testing was performed by an employee who hadn't participated in ClickHouse development, and special cases in the code were not optimized until all the results were obtained. We used the same approach to get a data set for functional testing.
|
||||
|
||||
After ClickHouse was released as open source in 2016, people began questioning these tests.
|
||||
|
||||
## Shortcomings of tests on private data
|
||||
|
||||
Our performance tests:
|
||||
|
||||
- Couldn't be reproduced independently because they used private data that can't be published. Some of the functional tests are not available to external users for the same reason.
|
||||
- Needed further development. The set of tests needed to be substantially expanded in order to isolate performance changes in individual parts of the system.
|
||||
- Didn't run on a per-commit basis or for individual pull requests. External developers couldn't check their code for performance regressions.
|
||||
|
||||
We could solve these problems by throwing out the old tests and writing new ones based on open data, like [flight data for the USA](https://clickhouse.com/docs/en/getting-started/example-datasets/ontime/) and [taxi rides in New York](https://clickhouse.com/docs/en/getting-started/example-datasets/nyc-taxi). Or we could use benchmarks like TPC-H, TPC-DS, and [Star Schema Benchmark](https://clickhouse.com/docs/en/getting-started/example-datasets/star-schema). The disadvantage is that this data was very different from web analytics data, and we would rather keep the test queries.
|
||||
|
||||
### Why it's important to use real data
|
||||
|
||||
Performance should only be tested on real data from a production environment. Let's look at some examples.
|
||||
|
||||
### Example 1
|
||||
|
||||
Let's say you fill a database with evenly distributed pseudorandom numbers. Data compression isn't going to work in this case, although data compression is essential to analytical databases. There is no silver bullet solution to the challenge of choosing the right compression algorithm and the right way to integrate it into the system since data compression requires a compromise between the speed of compression and decompression and the potential compression efficiency. But systems that can't compress data are guaranteed losers. If your tests use evenly distributed pseudorandom numbers, this factor is ignored, and the results will be distorted.
|
||||
|
||||
Bottom line: Test data must have a realistic compression ratio.
|
||||
|
||||
### Example 2
|
||||
|
||||
Let's say we are interested in the execution speed of this SQL query:
|
||||
|
||||
```sql
|
||||
SELECT RegionID, uniq(UserID) AS visitors
|
||||
FROM test.hits
|
||||
GROUP BY RegionID
|
||||
ORDER BY visitors DESC
|
||||
LIMIT 10
|
||||
```
|
||||
|
||||
This was a typical query for web analytics product. What affects the processing speed?
|
||||
|
||||
- How `GROUP BY` is executed.
|
||||
- Which data structure is used for calculating the `uniq` aggregate function.
|
||||
- How many different RegionIDs there are and how much RAM each state of the `uniq` function requires.
|
||||
|
||||
But another important factor is that the amount of data is distributed unevenly between regions. (It probably follows a power law. I put the distribution on a log-log graph, but I can't say for sure.) If this is the case, the states of the `uniq` aggregate function with fewer values must use very little memory. When there are a lot of different aggregation keys, every single byte counts. How can we get generated data that has all these properties? The obvious solution is to use real data.
|
||||
|
||||
Many DBMSs implement the HyperLogLog data structure for an approximation of COUNT(DISTINCT), but none of them work very well because this data structure uses a fixed amount of memory. ClickHouse has a function that uses [a combination of three different data structures](https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference/uniqcombined), depending on the size of the data set.
|
||||
|
||||
Bottom line: Test data must represent distribution properties of the real data well enough, meaning cardinality (number of distinct values per column) and cross-column cardinality (number of different values counted across several different columns).
|
||||
|
||||
### Example 3
|
||||
|
||||
Instead of testing the performance of the ClickHouse DBMS, let's take something simpler, like hash tables. For hash tables, it's essential to choose the right hash function. This is not as important for `std::unordered_map`, because it's a hash table based on chaining, and a prime number is used as the array size. The standard library implementation in GCC and Clang uses a trivial hash function as the default hash function for numeric types. However, `std::unordered_map` is not the best choice when we are looking for maximum speed. With an open-addressing hash table, we can't just use a standard hash function. Choosing the right hash function becomes the deciding factor.
|
||||
|
||||
It's easy to find hash table performance tests using random data that don't take the hash functions used into account. Many hash function tests also focus on the calculation speed and certain quality criteria, even though they ignore the data structures used. But the fact is that hash tables and HyperLogLog require different hash function quality criteria.
|
||||
|
||||
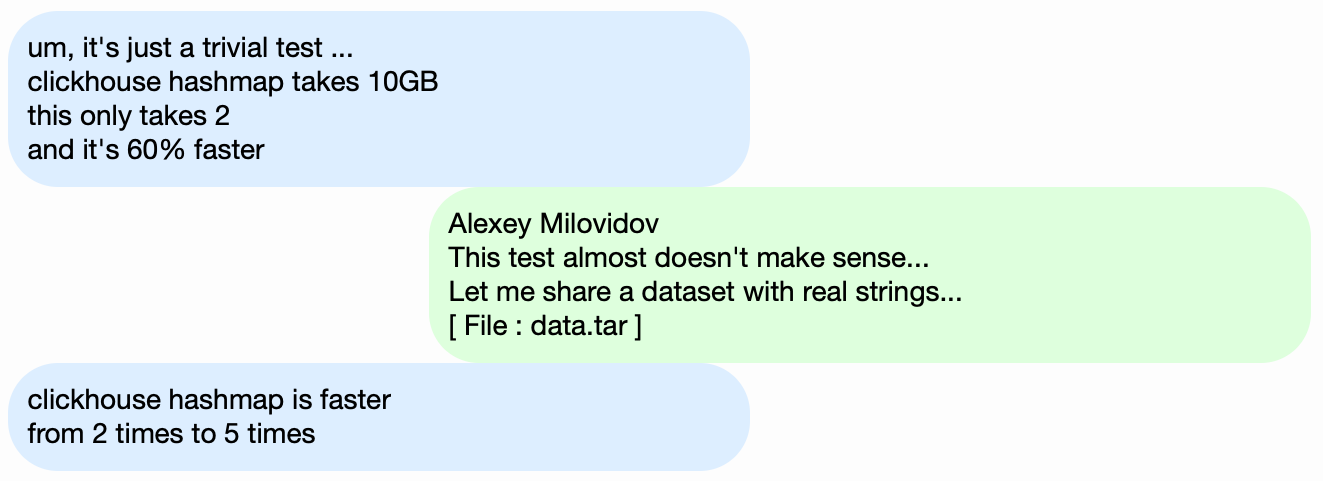
|
||||
|
||||
## Challenge
|
||||
|
||||
Our goal was to obtain data for testing performance that had the same structure as our web analytics data with all the properties that are important for benchmarks, but in such a way that there remain no traces of real website users in this data. In other words, the data must be anonymized and still preserve its:
|
||||
|
||||
* Compression ratio.
|
||||
* Cardinality (the number of distinct values).
|
||||
* Mutual cardinality between several different columns.
|
||||
* Properties of probability distributions that can be used for data modeling (for example, if we believe that regions are distributed according to a power law, then the exponent — the distribution parameter — should be approximately the same for artificial data and for real data).
|
||||
|
||||
How can we get a similar compression ratio for the data? If LZ4 is used, substrings in binary data must be repeated at approximately the same distance, and the repetitions must be approximately the same length. For ZSTD, entropy per byte must also coincide.
|
||||
|
||||
The ultimate goal was to create a publicly available tool that anyone can use to anonymize their data sets for publication. This would allow us to debug and test performance on other people's data similar to our production data. We would also like the generated data to be interesting.
|
||||
|
||||
However, these are very loosely-defined requirements, and we aren't planning to write up a formal problem statement or specification for this task.
|
||||
|
||||
## Possible solutions
|
||||
|
||||
I don't want to make it sound like this problem was particularly important. It was never actually included in planning, and no one had intentions to work on it. I hoped that an idea would come up someday, and suddenly I would be in a good mood and be able to put everything else off until later.
|
||||
|
||||
### Explicit probabilistic models
|
||||
|
||||
- We want to preserve the continuity of time series data. This means that for some types of data, we need to model the difference between neighboring values rather than the value itself.
|
||||
- To model "joint cardinality" of columns, we would also have to explicitly reflect dependencies between columns. For instance, there are usually very few IP addresses per user ID, so to generate an IP address, we would have to use a hash value of the user ID as a seed and add a small amount of other pseudorandom data.
|
||||
- We weren't sure how to express the dependency that the same user frequently visits URLs with matching domains at approximately the same time.
|
||||
|
||||
All this can be written in a C++ "script" with the distributions and dependencies hard coded. However, Markov models are obtained from a combination of statistics with smoothing and adding noise. I started writing a script like this, but after writing explicit models for ten columns, it became unbearably boring — and the "hits" table in the web analytics product had more than 100 columns way back in 2012.
|
||||
|
||||
```c++
|
||||
EventTime.day(std::discrete_distribution<>({
|
||||
0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random));
|
||||
EventTime.hour(std::discrete_distribution<>({
|
||||
13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random));
|
||||
EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random));
|
||||
EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random));
|
||||
|
||||
UInt64 UserID = hash(4, powerLaw(5000, 1.1));
|
||||
UserID = UserID / 10000000000ULL * 10000000000ULL
|
||||
+ static_cast<time_t>(EventTime) + UserID % 1000000;
|
||||
|
||||
random_with_seed.seed(powerLaw(5000, 1.1));
|
||||
auto get_random_with_seed = [&]{ return random_with_seed(); };
|
||||
```
|
||||
|
||||
Advantages:
|
||||
|
||||
- Conceptual simplicity.
|
||||
|
||||
Disadvantages:
|
||||
|
||||
- A large amount of work is required.
|
||||
- The solution only applies to one type of data.
|
||||
|
||||
And I preferred a more general solution that can be used for obfuscating any dataset.
|
||||
|
||||
In any case, this solution could be improved. Instead of manually selecting models, we could implement a catalog of models and choose the best among them (best fit plus some form of regularization). Or maybe we could use Markov models for all types of fields, not just for text. Dependencies between data could also be extracted automatically. This would require calculating the [relative entropy](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence) (the relative amount of information) between columns. A simpler alternative is to calculate relative cardinalities for each pair of columns (something like "how many different values of A are there on average for a fixed value B"). For instance, this will make it clear that `URLDomain` fully depends on the `URL`, and not vice versa.
|
||||
|
||||
But I also rejected this idea because there are too many factors to consider, and it would take too long to write.
|
||||
|
||||
### Neural networks
|
||||
|
||||
As I've already mentioned, this task wasn't high on the priority list — no one was even thinking about trying to solve it. But as luck would have it, our colleague Ivan Puzirevsky was teaching at the Higher School of Economics. He asked me if I had any interesting problems that would work as suitable thesis topics for his students. When I offered him this one, he assured me it had potential. So I handed this challenge off to a nice guy "off the street" Sharif (he did have to sign an NDA to access the data, though).
|
||||
|
||||
I shared all my ideas with him but emphasized that there were no restrictions on how the problem could be solved, and a good option would be to try approaches that I know nothing about, like using LSTM to generate a text dump of data. This seemed promising after coming across the article [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/).
|
||||
|
||||
The first challenge is that we need to generate structured data, not just text. But it wasn't clear whether a recurrent neural network could generate data with the desired structure. There are two ways to solve this. The first solution is to use separate models for generating the structure and the "filler", and only use the neural network for generating values. But this approach was postponed and then never completed. The second solution is to simply generate a TSV dump as text. Experience has shown that some of the rows in the text won't match the structure, but these rows can be thrown out when loading the data.
|
||||
|
||||
The second challenge is that the recurrent neural network generates a sequence of data, and thus dependencies in data must follow in the order of the sequence. But in our data, the order of columns can potentially be in reverse to dependencies between them. We didn't do anything to resolve this problem.
|
||||
|
||||
As summer approached, we had the first working Python script that generated data. The data quality seemed decent at first glance:
|
||||
|
||||
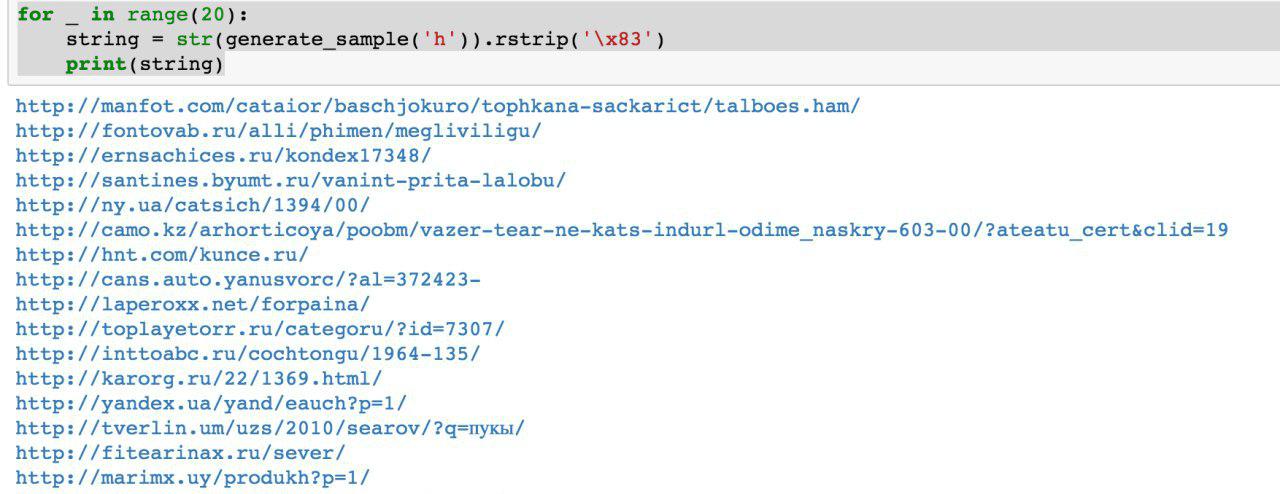
|
||||
|
||||
However, we did run into some difficulties:
|
||||
|
||||
1. The size of the model was about a gigabyte. We tried to create a model for data that was several gigabytes in size (for a start). The fact that the resulting model is so large raised concerns. Would it be possible to extract the real data that it was trained on? Unlikely. But I don't know much about machine learning and neural networks, and I haven't read this developer's Python code, so how can I be sure? There were several articles published at the time about how to compress neural networks without loss of quality, but it wasn't implemented. On the one hand, this doesn't seem to be a serious problem since we can opt out of publishing the model and just publish the generated data. On the other hand, if overfitting occurs, the generated data may contain some part of the source data.
|
||||
|
||||
2. On a machine with a single CPU, the data generation speed is approximately 100 rows per second. Our goal was to generate at least a billion rows. Calculations showed that this wouldn't be completed before the date of the thesis defense. It didn't make sense to use additional hardware because the goal was to make a data generation tool that anyone could use.
|
||||
|
||||
Sharif tried to analyze the quality of data by comparing statistics. Among other things, he calculated the frequency of different characters occurring in the source data and in the generated data. The result was stunning: the most frequent characters were Ð and Ñ.
|
||||
|
||||
Don't worry about Sharif, though. He successfully defended his thesis, and we happily forgot about the whole thing.
|
||||
|
||||
### Mutation of compressed data
|
||||
|
||||
Let's assume that the problem statement has been reduced to a single point: we need to generate data that has the same compression ratio as the source data, and the data must decompress at the same speed. How can we achieve this? We need to edit compressed data bytes directly! This allows us to change the data without changing the size of the compressed data, plus everything will work fast. I wanted to try out this idea right away, despite the fact that the problem it solves is different from what we started with. But that's how it always is.
|
||||
|
||||
So how do we edit a compressed file? Let's say we are only interested in LZ4. LZ4 compressed data is composed of sequences, which in turn are strings of not-compressed bytes (literals), followed by a match copy:
|
||||
|
||||
1. Literals (copy the following N bytes as is).
|
||||
2. Matches with a minimum repeat length of 4 (repeat N bytes in the file at a distance of M).
|
||||
|
||||
Source data:
|
||||
|
||||
`Hello world Hello.`
|
||||
|
||||
Compressed data (arbitrary example):
|
||||
|
||||
`literals 12 "Hello world " match 5 12.`
|
||||
|
||||
In the compressed file, we leave "match" as-is and change the byte values in "literals". As a result, after decompressing, we get a file in which all repeating sequences at least 4 bytes long are also repeated at the same distance, but they consist of a different set of bytes (basically, the modified file doesn't contain a single byte that was taken from the source file).
|
||||
|
||||
But how do we change the bytes? The answer isn't obvious because, in addition to the column types, the data also has its own internal, implicit structure that we would like to preserve. For example, text data is often stored in UTF-8 encoding, and we want the generated data also to be valid UTF-8. I developed a simple heuristic that involves meeting several criteria:
|
||||
|
||||
- Null bytes and ASCII control characters are kept as-is.
|
||||
- Some punctuation characters remain as-is.
|
||||
- ASCII is converted to ASCII, and for everything else, the most significant bit is preserved (or an explicit set of "if" statements is written for different UTF-8 lengths). In one byte class, a new value is picked uniformly at random.
|
||||
- Fragments like `https://` are preserved; otherwise, it looks a bit silly.
|
||||
|
||||
The only caveat to this approach is that the data model is the source data itself, which means it cannot be published. The model is only fit for generating amounts of data no larger than the source. On the contrary, the previous approaches provide models allowing the generation of data of arbitrary size.
|
||||
|
||||
```
|
||||
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
|
||||
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
|
||||
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
|
||||
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
|
||||
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
|
||||
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
|
||||
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
|
||||
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
|
||||
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
|
||||
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
|
||||
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
|
||||
```
|
||||
|
||||
The results were positive, and the data was interesting, but something wasn't quite right. The URLs kept the same structure, but in some of them, it was too easy to recognize the original terms, such as "avito" (a popular marketplace in Russia), so I created a heuristic that swapped some of the bytes around.
|
||||
|
||||
There were other concerns as well. For example, sensitive information could possibly reside in a FixedString column in binary representation and potentially consist of ASCII control characters and punctuation, which I decided to preserve. However, I didn't take data types into consideration.
|
||||
|
||||
Another problem is that if a column stores data in the "length, value" format (this is how String columns are stored), how do I ensure that the length remains correct after the mutation? When I tried to fix this, I immediately lost interest.
|
||||
|
||||
### Random permutations
|
||||
|
||||
Unfortunately, the problem wasn't solved. We performed a few experiments, and it just got worse. The only thing left was to sit around doing nothing and surf the web randomly since the magic was gone. Luckily, I came across a page that [explained the algorithm](http://fabiensanglard.net/fizzlefade/index.php) for rendering the death of the main character in the game Wolfenstein 3D.
|
||||
|
||||
<img src="https://clickhouse.com/uploads/wolfenstein_bb259bd741.gif" alt="wolfenstein.gif" style="width: 764px;">
|
||||
|
||||
<br/>
|
||||
|
||||
The animation is really well done — the screen fills up with blood. The article explains that this is actually a pseudorandom permutation. A random permutation of a set of elements is a randomly picked bijective (one-to-one) transformation of the set. In other words, a mapping where each and every derived element corresponds to exactly one original element (and vice versa). In other words, it is a way to randomly iterate through all the elements of a data set. And that is exactly the process shown in the picture: each pixel is filled in random order, without any repetition. If we were to just choose a random pixel at each step, it would take a long time to get to the last one.
|
||||
|
||||
The game uses a very simple algorithm for pseudorandom permutation called linear feedback shift register ([LFSR](https://en.wikipedia.org/wiki/Linear-feedback_shift_register)). Similar to pseudorandom number generators, random permutations, or rather their families, can be cryptographically strong when parametrized by a key. This is exactly what we needed for our data transformation. However, the details were trickier. For example, cryptographically strong encryption of N bytes to N bytes with a pre-determined key and initialization vector seems like it would work for a pseudorandom permutation of a set of N-byte strings. Indeed, this is a one-to-one transformation, and it appears to be random. But if we use the same transformation for all of our data, the result may be susceptible to cryptoanalysis because the same initialization vector and key value are used multiple times. This is similar to the [Electronic Codebook](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#ECB) mode of operation for a block cipher.
|
||||
|
||||
For example, three multiplications and two xorshift operations are used for the [murmurhash](https://github.com/ClickHouse/ClickHouse/blob/master/dbms/src/Common/HashTable/Hash.h#L18) finalizer. This operation is a pseudorandom permutation. However, I should point out that hash functions don't have to be one-to-one (even hashes of N bits to N bits).
|
||||
|
||||
Or here's another interesting [example from elementary number theory](https://preshing.com/20121224/how-to-generate-a-sequence-of-unique-random-integers/) from Jeff Preshing's website.
|
||||
|
||||
How can we use pseudorandom permutations to solve our problem? We can use them to transform all numeric fields so we can preserve the cardinalities and mutual cardinalities of all combinations of fields. In other words, COUNT(DISTINCT) will return the same value as before the transformation and, furthermore, with any GROUP BY.
|
||||
|
||||
It is worth noting that preserving all cardinalities somewhat contradicts our goal of data anonymization. Let's say someone knows that the source data for site sessions contains a user who visited sites from 10 different countries, and they want to find that user in the transformed data. The transformed data also shows that the user visited sites from 10 different countries, which makes it easy to narrow down the search. However, even if they find out what the user was transformed into, it won't be very useful; all of the other data has also been transformed, so they won't be able to figure out what sites the user visited or anything else. But these rules can be applied in a chain. For example, suppose someone knows that the most frequently occurring website in our data is Google, with Yahoo in second place. In that case, they can use the ranking to determine which transformed site identifiers actually mean Yahoo and Google. There's nothing surprising about this since we are working with an informal problem statement, and we are trying to find a balance between the anonymization of data (hiding information) and preserving data properties (disclosure of information). For information about how to approach the data anonymization issue more reliably, read this [article](https://medium.com/georgian-impact-blog/a-brief-introduction-to-differential-privacy-eacf8722283b).
|
||||
|
||||
In addition to keeping the original cardinality of values, I also wanted to keep the order of magnitude of the values. What I mean is that if the source data contained numbers under 10, then I want the transformed numbers to also be small. How can we achieve this?
|
||||
|
||||
For example, we can divide a set of possible values into size classes and perform permutations within each class separately (maintaining the size classes). The easiest way to do this is to take the nearest power of two or the position of the most significant bit in the number as the size class (these are the same thing). The numbers 0 and 1 will always remain as is. The numbers 2 and 3 will sometimes remain as is (with a probability of 1/2) and will sometimes be swapped (with a probability of 1/2). The set of numbers 1024..2047 will be mapped to one of 1024! (factorial) variants, and so on. For signed numbers, we will keep the sign.
|
||||
|
||||
It's also doubtful whether we need a one-to-one function. We can probably just use a cryptographically strong hash function. The transformation won't be one-to-one, but the cardinality will be close to the same.
|
||||
|
||||
However, we need a cryptographically strong random permutation so that when we define a key and derive a permutation with that key, restoring the original data from the rearranged data without knowing the key would be difficult.
|
||||
|
||||
There is one problem: in addition to knowing nothing about neural networks and machine learning, I am also quite ignorant when it comes to cryptography. That leaves just my courage. I was still reading random web pages and found a link on [Hackers News](https://news.ycombinator.com/item?id=15122540) to a discussion on Fabien Sanglard's page. It had a link to a [blog post](http://antirez.com/news/113) by Redis developer Salvatore Sanfilippo that talked about using a wonderful generic way of getting random permutations, known as a [Feistel network](https://en.wikipedia.org/wiki/Feistel_cipher).
|
||||
|
||||
The Feistel network is iterative, consisting of rounds. Each round is a remarkable transformation that allows you to get a one-to-one function from any function. Let's look at how it works.
|
||||
|
||||
1. The argument's bits are divided into two halves:
|
||||
```
|
||||
arg: xxxxyyyy
|
||||
arg_l: xxxx
|
||||
arg_r: yyyy
|
||||
```
|
||||
2. The right half replaces the left. In its place, we put the result of XOR on the initial value of the left half and the result of the function applied to the initial value of the right half, like this:
|
||||
|
||||
```
|
||||
res: yyyyzzzz
|
||||
res_l = yyyy = arg_r
|
||||
res_r = zzzz = arg_l ^ F(arg_r)
|
||||
```
|
||||
|
||||
There is also a claim that if we use a cryptographically strong pseudorandom function for F and apply a Feistel round at least four times, we'll get a cryptographically strong pseudorandom permutation.
|
||||
|
||||
This is like a miracle: we take a function that produces random garbage based on data, insert it into the Feistel network, and we now have a function that produces random garbage based on data, but yet is invertible!
|
||||
|
||||
The Feistel network is at the heart of several data encryption algorithms. What we're going to do is something like encryption, only it's really bad. There are two reasons for this:
|
||||
|
||||
1. We are encrypting individual values independently and in the same way, similar to the Electronic Codebook mode of operation.
|
||||
2. We are storing information about the order of magnitude (the nearest power of two) and the sign of the value, which means that some values do not change at all.
|
||||
|
||||
This way, we can obfuscate numeric fields while preserving the properties we need. For example, after using LZ4, the compression ratio should remain approximately the same because the duplicate values in the source data will be repeated in the converted data and at the same distances from each other.
|
||||
|
||||
### Markov models
|
||||
|
||||
Text models are used for data compression, predictive input, speech recognition, and random string generation. A text model is a probability distribution of all possible strings. Let's say we have an imaginary probability distribution of the texts of all the books that humanity could ever write. To generate a string, we just take a random value with this distribution and return the resulting string (a random book that humanity could write). But how do we find out the probability distribution of all possible strings?
|
||||
|
||||
First, this would require too much information. There are 256^10 possible strings that are 10 bytes in length, and it would take quite a lot of memory to explicitly write a table with the probability of each string. Second, we don't have enough statistics to accurately assess the distribution.
|
||||
|
||||
This is why we use a probability distribution obtained from rough statistics as the text model. For example, we could calculate the probability of each letter occurring in the text and then generate strings by selecting each next letter with the same probability. This primitive model works, but the strings are still very unnatural.
|
||||
|
||||
To improve the model slightly, we could also make use of the conditional probability of the letter's occurrence if it is preceded by N-specific letters. N is a pre-set constant. Let's say N = 5, and we are calculating the probability of the letter "e" occurring after the letters "compr". This text model is called an Order-N Markov model.
|
||||
|
||||
```
|
||||
P(cata | cat) = 0.8
|
||||
P(catb | cat) = 0.05
|
||||
P(catc | cat) = 0.1
|
||||
...
|
||||
```
|
||||
|
||||
Let's look at how Markov models work on the website [of Hay Kranen](https://projects.haykranen.nl/markov/demo/). Unlike LSTM neural networks, the models only have enough memory for a small context of fixed-length N, so they generate funny nonsensical texts. Markov models are also used in primitive methods for generating spam, and the generated texts can be easily distinguished from real ones by counting statistics that don't fit the model. There is one advantage: Markov models work much faster than neural networks, which is exactly what we need.
|
||||
|
||||
Example for Title (our examples are in Turkish because of the data used):
|
||||
|
||||
<blockquote style="font-size: 15px;">
|
||||
<p>Hyunday Butter'dan anket shluha — Politika head manşetleri | STALKER BOXER Çiftede book — Yanudistkarışmanlı Mı Kanal | League el Digitalika Haberler Haberleri — Haberlerisi — Hotels with Centry'ler Neden babah.com</p>
|
||||
</blockquote>
|
||||
|
||||
We can calculate statistics from the source data, create a Markov model, and generate new data. Note that the model needs smoothing to avoid disclosing information about rare combinations in the source data, but this is not a problem. We use a combination of models from 0 to N. If statistics are insufficient for order N, the N−1 model is used instead.
|
||||
|
||||
But we still want to preserve the cardinality of data. In other words, if the source data had 123456 unique URL values, the result should have approximately the same number of unique values. We can use a deterministically initialized random number generator to achieve this. The easiest way is to use a hash function and apply it to the original value. In other words, we get a pseudorandom result that is explicitly determined by the original value.
|
||||
|
||||
Another requirement is that the source data may have many different URLs that start with the same prefix but aren't identical. For example: `https://www.clickhouse.com/images/cats/?id=xxxxxx`. We want the result to also have URLs that all start with the same prefix, but a different one. For example: http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx. As a random number generator for generating the next character using a Markov model, we'll take a hash function from a moving window of 8 bytes at the specified position (instead of taking it from the entire string).
|
||||
|
||||
<pre class='code-with-play'>
|
||||
<div class='code'>
|
||||
https://www.clickhouse.com/images/cats/?id=12345
|
||||
^^^^^^^^
|
||||
|
||||
distribution: [aaaa][b][cc][dddd][e][ff][ggggg][h]...
|
||||
hash("images/c") % total_count: ^
|
||||
</div>
|
||||
</pre>
|
||||
|
||||
It turns out to be exactly what we need. Here's the example of page titles:
|
||||
|
||||
<pre class='code-with-play'>
|
||||
<div class='code'>
|
||||
PhotoFunia - Haber7 - Have mükemment.net Oynamak içinde şaşıracak haber, Oyunu Oynanılmaz • apród.hu kínálatában - RT Arabic
|
||||
PhotoFunia - Kinobar.Net - apród: Ingyenes | Posti
|
||||
PhotoFunia - Peg Perfeo - Castika, Sıradışı Deniz Lokoning Your Code, sire Eminema.tv/
|
||||
PhotoFunia - TUT.BY - Your Ayakkanın ve Son Dakika Spor,
|
||||
PhotoFunia - big film izle, Del Meireles offilim, Samsung DealeXtreme Değerler NEWSru.com.tv, Smotri.com Mobile yapmak Okey
|
||||
PhotoFunia 5 | Galaxy, gt, după ce anal bilgi yarak Ceza RE050A V-Stranç
|
||||
PhotoFunia :: Miami olacaksını yerel Haberler Oyun Young video
|
||||
PhotoFunia Monstelli'nin En İyi kisa.com.tr –Star Thunder Ekranı
|
||||
PhotoFunia Seks - Politika,Ekonomi,Spor GTA SANAYİ VE
|
||||
PhotoFunia Taker-Rating Star TV Resmi Söylenen Yatağa każdy dzież wierzchnie
|
||||
PhotoFunia TourIndex.Marketime oyunu Oyna Geldolları Mynet Spor,Magazin,Haberler yerel Haberleri ve Solvia, korkusuz Ev SahneTv
|
||||
PhotoFunia todo in the Gratis Perky Parti'nin yapıyı by fotogram
|
||||
PhotoFunian Dünyasın takımız halles en kulları - TEZ
|
||||
</div>
|
||||
</pre>
|
||||
|
||||
## Results
|
||||
|
||||
After trying four methods, I got so tired of this problem that it was time just to choose something, make it into a usable tool, and announce the solution. I chose the solution that uses random permutations and Markov models parametrized by a key. It is implemented as the clickhouse-obfuscator program, which is very easy to use. The input is a table dump in any supported format (such as CSV or JSONEachRow), and the command line parameters specify the table structure (column names and types) and the secret key (any string, which you can forget immediately after use). The output is the same number of rows of obfuscated data.
|
||||
|
||||
The program is installed with `clickhouse-client`, has no dependencies, and works on almost any flavor of Linux. You can apply it to any database dump, not just ClickHouse. For instance, you can generate test data from MySQL or PostgreSQL databases or create development databases that are similar to your production databases.
|
||||
|
||||
```bash
|
||||
clickhouse-obfuscator \
|
||||
--seed "$(head -c16 /dev/urandom | base64)" \
|
||||
--input-format TSV --output-format TSV \
|
||||
--structure 'CounterID UInt32, URLDomain String, \
|
||||
URL String, SearchPhrase String, Title String' \
|
||||
< table.tsv > result.tsv
|
||||
```
|
||||
|
||||
```bash
|
||||
clickhouse-obfuscator --help
|
||||
```
|
||||
|
||||
Of course, everything isn't so cut and dry because data transformed by this program is almost completely reversible. The question is whether it is possible to perform the reverse transformation without knowing the key. If the transformation used a cryptographic algorithm, this operation would be as difficult as a brute-force search. Although the transformation uses some cryptographic primitives, they are not used in the correct way, and the data is susceptible to certain methods of analysis. To avoid problems, these issues are covered in the documentation for the program (access it using --help).
|
||||
|
||||
In the end, we transformed the data set we needed [for functional and performance testing](https://clickhouse.com/docs/en/getting-started/example-datasets/metrica/), and received approval from our data security team to publish.
|
||||
|
||||
Our developers and members of our community use this data for real performance testing when optimizing algorithms inside ClickHouse. Third-party users can provide us with their obfuscated data so that we can make ClickHouse even faster for them. We also released an independent open benchmark for hardware and cloud providers on top of this data: [https://benchmark.clickhouse.com/](https://benchmark.clickhouse.com/)
|
||||
@ -87,7 +87,7 @@ void MetricsTransmitter::transmit(std::vector<ProfileEvents::Count> & prev_count
|
||||
|
||||
if (send_events)
|
||||
{
|
||||
for (size_t i = 0, end = ProfileEvents::end(); i < end; ++i)
|
||||
for (ProfileEvents::Event i = ProfileEvents::Event(0), end = ProfileEvents::end(); i < end; ++i)
|
||||
{
|
||||
const auto counter = ProfileEvents::global_counters[i].load(std::memory_order_relaxed);
|
||||
const auto counter_increment = counter - prev_counters[i];
|
||||
@ -100,7 +100,7 @@ void MetricsTransmitter::transmit(std::vector<ProfileEvents::Count> & prev_count
|
||||
|
||||
if (send_events_cumulative)
|
||||
{
|
||||
for (size_t i = 0, end = ProfileEvents::end(); i < end; ++i)
|
||||
for (ProfileEvents::Event i = ProfileEvents::Event(0), end = ProfileEvents::end(); i < end; ++i)
|
||||
{
|
||||
const auto counter = ProfileEvents::global_counters[i].load(std::memory_order_relaxed);
|
||||
std::string key{ProfileEvents::getName(static_cast<ProfileEvents::Event>(i))};
|
||||
@ -110,7 +110,7 @@ void MetricsTransmitter::transmit(std::vector<ProfileEvents::Count> & prev_count
|
||||
|
||||
if (send_metrics)
|
||||
{
|
||||
for (size_t i = 0, end = CurrentMetrics::end(); i < end; ++i)
|
||||
for (CurrentMetrics::Metric i = CurrentMetrics::Metric(0), end = CurrentMetrics::end(); i < end; ++i)
|
||||
{
|
||||
const auto value = CurrentMetrics::values[i].load(std::memory_order_relaxed);
|
||||
|
||||
|
||||
@ -1272,7 +1272,7 @@ try
|
||||
{
|
||||
auto new_pool_size = server_settings.background_pool_size;
|
||||
auto new_ratio = server_settings.background_merges_mutations_concurrency_ratio;
|
||||
global_context->getMergeMutateExecutor()->increaseThreadsAndMaxTasksCount(new_pool_size, new_pool_size * new_ratio);
|
||||
global_context->getMergeMutateExecutor()->increaseThreadsAndMaxTasksCount(new_pool_size, static_cast<size_t>(new_pool_size * new_ratio));
|
||||
global_context->getMergeMutateExecutor()->updateSchedulingPolicy(server_settings.background_merges_mutations_scheduling_policy.toString());
|
||||
}
|
||||
|
||||
|
||||
@ -104,6 +104,8 @@ enum class AccessType
|
||||
M(DROP_NAMED_COLLECTION, "", NAMED_COLLECTION, NAMED_COLLECTION_CONTROL) /* allows to execute DROP NAMED COLLECTION */\
|
||||
M(DROP, "", GROUP, ALL) /* allows to execute {DROP|DETACH} */\
|
||||
\
|
||||
M(UNDROP_TABLE, "", TABLE, ALL) /* allows to execute {UNDROP} TABLE */\
|
||||
\
|
||||
M(TRUNCATE, "TRUNCATE TABLE", TABLE, ALL) \
|
||||
M(OPTIMIZE, "OPTIMIZE TABLE", TABLE, ALL) \
|
||||
M(BACKUP, "", TABLE, ALL) /* allows to backup tables */\
|
||||
|
||||
@ -48,7 +48,7 @@ TEST(AccessRights, Union)
|
||||
ASSERT_EQ(lhs.toString(),
|
||||
"GRANT INSERT ON *.*, "
|
||||
"GRANT SHOW, SELECT, ALTER, CREATE DATABASE, CREATE TABLE, CREATE VIEW, "
|
||||
"CREATE DICTIONARY, DROP DATABASE, DROP TABLE, DROP VIEW, DROP DICTIONARY, "
|
||||
"CREATE DICTIONARY, DROP DATABASE, DROP TABLE, DROP VIEW, DROP DICTIONARY, UNDROP TABLE, "
|
||||
"TRUNCATE, OPTIMIZE, BACKUP, CREATE ROW POLICY, ALTER ROW POLICY, DROP ROW POLICY, "
|
||||
"SHOW ROW POLICIES, SYSTEM MERGES, SYSTEM TTL MERGES, SYSTEM FETCHES, "
|
||||
"SYSTEM MOVES, SYSTEM SENDS, SYSTEM REPLICATION QUEUES, "
|
||||
|
||||
@ -288,7 +288,8 @@ public:
|
||||
readVarUInt(size, buf);
|
||||
|
||||
if (unlikely(size > AGGREGATE_FUNCTION_GROUP_ARRAY_MAX_ARRAY_SIZE))
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size (maximum: {})", AGGREGATE_FUNCTION_GROUP_ARRAY_MAX_ARRAY_SIZE);
|
||||
|
||||
if (limit_num_elems && unlikely(size > max_elems))
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size, it should not exceed {}", max_elems);
|
||||
@ -367,7 +368,8 @@ struct GroupArrayNodeBase
|
||||
UInt64 size;
|
||||
readVarUInt(size, buf);
|
||||
if (unlikely(size > AGGREGATE_FUNCTION_GROUP_ARRAY_MAX_ARRAY_SIZE))
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size (maximum: {})", AGGREGATE_FUNCTION_GROUP_ARRAY_MAX_ARRAY_SIZE);
|
||||
|
||||
Node * node = reinterpret_cast<Node *>(arena->alignedAlloc(sizeof(Node) + size, alignof(Node)));
|
||||
node->size = size;
|
||||
@ -621,7 +623,8 @@ public:
|
||||
return;
|
||||
|
||||
if (unlikely(elems > AGGREGATE_FUNCTION_GROUP_ARRAY_MAX_ARRAY_SIZE))
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size (maximum: {})", AGGREGATE_FUNCTION_GROUP_ARRAY_MAX_ARRAY_SIZE);
|
||||
|
||||
if (limit_num_elems && unlikely(elems > max_elems))
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size, it should not exceed {}", max_elems);
|
||||
|
||||
@ -79,7 +79,8 @@ public:
|
||||
{
|
||||
length_to_resize = applyVisitor(FieldVisitorConvertToNumber<UInt64>(), params[1]);
|
||||
if (length_to_resize > AGGREGATE_FUNCTION_GROUP_ARRAY_INSERT_AT_MAX_SIZE)
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size (maximum: {})", AGGREGATE_FUNCTION_GROUP_ARRAY_INSERT_AT_MAX_SIZE);
|
||||
}
|
||||
}
|
||||
|
||||
@ -167,7 +168,8 @@ public:
|
||||
readVarUInt(size, buf);
|
||||
|
||||
if (size > AGGREGATE_FUNCTION_GROUP_ARRAY_INSERT_AT_MAX_SIZE)
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size (maximum: {})", AGGREGATE_FUNCTION_GROUP_ARRAY_INSERT_AT_MAX_SIZE);
|
||||
|
||||
Array & arr = data(place).value;
|
||||
|
||||
|
||||
@ -21,18 +21,21 @@ namespace ErrorCodes
|
||||
namespace
|
||||
{
|
||||
|
||||
/// TODO Proper support for Decimal256.
|
||||
template <typename T, typename LimitNumberOfElements>
|
||||
struct MovingSum
|
||||
{
|
||||
using Data = MovingSumData<std::conditional_t<is_decimal<T>, Decimal128, NearestFieldType<T>>>;
|
||||
using Data = MovingSumData<std::conditional_t<is_decimal<T>,
|
||||
std::conditional_t<sizeof(T) <= sizeof(Decimal128), Decimal128, Decimal256>,
|
||||
NearestFieldType<T>>>;
|
||||
using Function = MovingImpl<T, LimitNumberOfElements, Data>;
|
||||
};
|
||||
|
||||
template <typename T, typename LimitNumberOfElements>
|
||||
struct MovingAvg
|
||||
{
|
||||
using Data = MovingAvgData<std::conditional_t<is_decimal<T>, Decimal128, Float64>>;
|
||||
using Data = MovingAvgData<std::conditional_t<is_decimal<T>,
|
||||
std::conditional_t<sizeof(T) <= sizeof(Decimal128), Decimal128, Decimal256>,
|
||||
Float64>>;
|
||||
using Function = MovingImpl<T, LimitNumberOfElements, Data>;
|
||||
};
|
||||
|
||||
|
||||
@ -144,7 +144,8 @@ public:
|
||||
readVarUInt(size, buf);
|
||||
|
||||
if (unlikely(size > AGGREGATE_FUNCTION_MOVING_MAX_ARRAY_SIZE))
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size (maximum: {})", AGGREGATE_FUNCTION_MOVING_MAX_ARRAY_SIZE);
|
||||
|
||||
if (size > 0)
|
||||
{
|
||||
|
||||
@ -127,7 +127,8 @@ public:
|
||||
if (size == 0)
|
||||
throw Exception(ErrorCodes::INCORRECT_DATA, "Incorrect size (0) in groupBitmap.");
|
||||
if (size > max_size)
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size in groupBitmap.");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size in groupBitmap (maximum: {})", max_size);
|
||||
|
||||
/// TODO: this is unnecessary copying - it will be better to read and deserialize in one pass.
|
||||
std::unique_ptr<char[]> buf(new char[size]);
|
||||
|
||||
@ -294,7 +294,8 @@ public:
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too many bins");
|
||||
static constexpr size_t max_size = 1_GiB;
|
||||
if (size > max_size)
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size in histogram.");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size in histogram (maximum: {})", max_size);
|
||||
|
||||
buf.readStrict(reinterpret_cast<char *>(points), size * sizeof(WeightedValue));
|
||||
}
|
||||
|
||||
@ -117,7 +117,7 @@ struct AggregateFunctionIntervalLengthSumData
|
||||
readBinary(size, buf);
|
||||
|
||||
if (unlikely(size > MAX_ARRAY_SIZE))
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size (maximum: {})", MAX_ARRAY_SIZE);
|
||||
|
||||
segments.clear();
|
||||
segments.reserve(size);
|
||||
|
||||
@ -140,7 +140,8 @@ public:
|
||||
readVarUInt(size, buf);
|
||||
|
||||
if (unlikely(size > AGGREGATE_FUNCTION_MAX_INTERSECTIONS_MAX_ARRAY_SIZE))
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size (maximum: {})", AGGREGATE_FUNCTION_MAX_INTERSECTIONS_MAX_ARRAY_SIZE);
|
||||
|
||||
auto & value = this->data(place).value;
|
||||
|
||||
|
||||
@ -125,8 +125,15 @@ public:
|
||||
if constexpr (std::is_same_v<Data, QuantileTiming<Value>>)
|
||||
{
|
||||
/// QuantileTiming only supports unsigned integers. Too large values are also meaningless.
|
||||
#ifdef OS_DARWIN
|
||||
# pragma clang diagnostic push
|
||||
# pragma clang diagnostic ignored "-Wimplicit-const-int-float-conversion"
|
||||
#endif
|
||||
if (isNaN(value) || value > std::numeric_limits<Int64>::max() || value < 0)
|
||||
return;
|
||||
#ifdef OS_DARWIN
|
||||
# pragma clang diagnostic pop
|
||||
#endif
|
||||
}
|
||||
|
||||
if constexpr (has_second_arg)
|
||||
|
||||
@ -324,7 +324,8 @@ public:
|
||||
return;
|
||||
|
||||
if (unlikely(size > max_node_size_deserialize))
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE, "Too large array size");
|
||||
throw Exception(ErrorCodes::TOO_LARGE_ARRAY_SIZE,
|
||||
"Too large array size (maximum: {})", max_node_size_deserialize);
|
||||
|
||||
auto & value = data(place).value;
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user