mirror of
https://github.com/ClickHouse/ClickHouse.git
synced 2024-11-27 01:51:59 +00:00
Merge branch 'master' into client-allow-yaml
This commit is contained in:
commit
f86b65c466
@ -193,6 +193,19 @@ index creation, `L2Distance` is used as default. Parameter `NumTrees` is the num
|
|||||||
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
||||||
linearly) as well as larger index sizes.
|
linearly) as well as larger index sizes.
|
||||||
|
|
||||||
|
`L2Distance` is also called Euclidean distance, the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points.
|
||||||
|
For example: If we have point P(p1,p2), Q(q1,q2), their distance will be d(p,q)
|
||||||
|

|
||||||
|
|
||||||
|
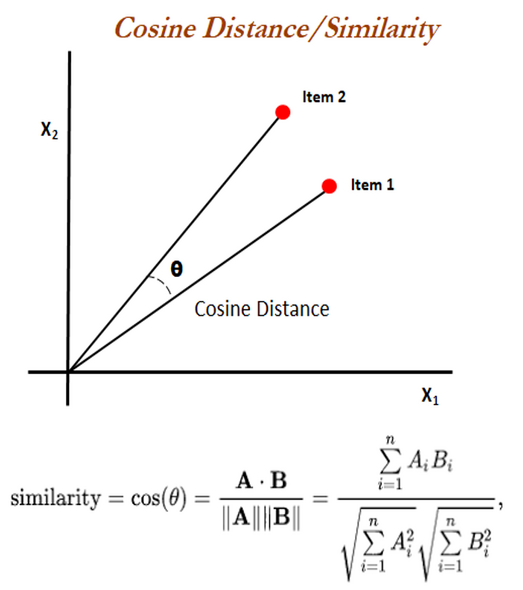
`cosineDistance` also called cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths.
|
||||||
|
|
||||||
|
|
||||||
|
The Euclidean distance corresponds to the L2-norm of a difference between vectors. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
|
||||||
|

|
||||||
|
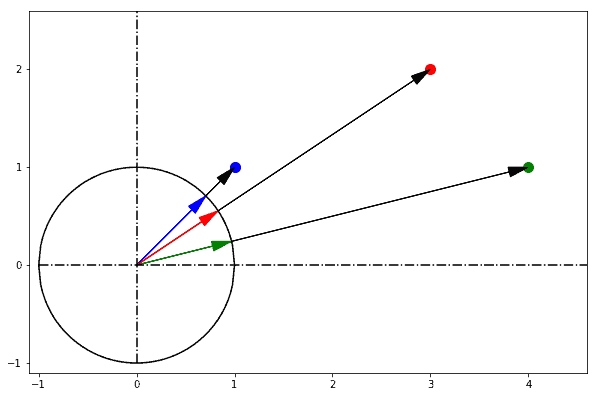
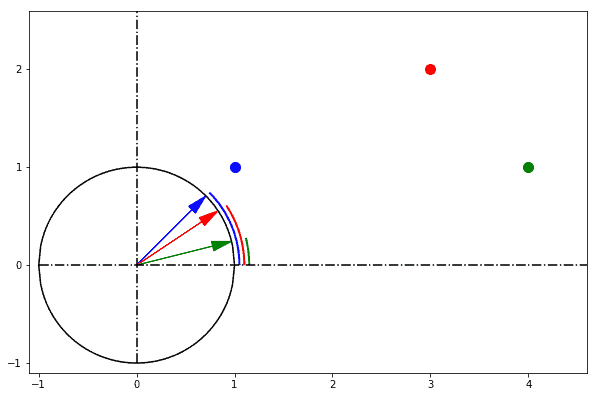
In one sentence: cosine similarity care only about the angle between them, but do not care about the "distance" we normally think.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
:::note
|
:::note
|
||||||
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
||||||
[CONSTRAINT](/docs/en/sql-reference/statements/create/table.md#constraints) to avoid errors. For example, `CONSTRAINT constraint_name_1
|
[CONSTRAINT](/docs/en/sql-reference/statements/create/table.md#constraints) to avoid errors. For example, `CONSTRAINT constraint_name_1
|
||||||
|
|||||||
@ -275,15 +275,6 @@ Pipe StorageSystemStackTrace::read(
|
|||||||
|
|
||||||
Block sample_block = storage_snapshot->metadata->getSampleBlock();
|
Block sample_block = storage_snapshot->metadata->getSampleBlock();
|
||||||
|
|
||||||
std::vector<UInt8> columns_mask(sample_block.columns());
|
|
||||||
for (size_t i = 0, size = columns_mask.size(); i < size; ++i)
|
|
||||||
{
|
|
||||||
if (names_set.contains(sample_block.getByPosition(i).name))
|
|
||||||
{
|
|
||||||
columns_mask[i] = 1;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
bool send_signal = names_set.contains("trace") || names_set.contains("query_id");
|
bool send_signal = names_set.contains("trace") || names_set.contains("query_id");
|
||||||
bool read_thread_names = names_set.contains("thread_name");
|
bool read_thread_names = names_set.contains("thread_name");
|
||||||
|
|
||||||
|
|||||||
@ -36,7 +36,7 @@ def gen_data(q):
|
|||||||
|
|
||||||
pattern = ''' or toString(number) = '{}'\n'''
|
pattern = ''' or toString(number) = '{}'\n'''
|
||||||
|
|
||||||
for i in range(1, 4 * 1024):
|
for i in range(0, 1024 * 2):
|
||||||
yield pattern.format(str(i).zfill(1024 - len(pattern) + 2)).encode()
|
yield pattern.format(str(i).zfill(1024 - len(pattern) + 2)).encode()
|
||||||
|
|
||||||
s = requests.Session()
|
s = requests.Session()
|
||||||
|
|||||||
@ -0,0 +1 @@
|
|||||||
|
1
|
||||||
9
tests/queries/0_stateless/02790_client_max_opening_fd.sh
Executable file
9
tests/queries/0_stateless/02790_client_max_opening_fd.sh
Executable file
@ -0,0 +1,9 @@
|
|||||||
|
#!/usr/bin/env bash
|
||||||
|
|
||||||
|
CUR_DIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
|
||||||
|
# shellcheck source=../shell_config.sh
|
||||||
|
. "$CUR_DIR"/../shell_config.sh
|
||||||
|
|
||||||
|
# Ensure that clickhouse-client does not open a large number of files.
|
||||||
|
ulimit -n 1024
|
||||||
|
${CLICKHOUSE_CLIENT} --query "SELECT 1"
|
||||||
Loading…
Reference in New Issue
Block a user