---
slug: /ja/operations/monitoring
sidebar_position: 45
sidebar_label: 監視
description: ハードウェアリソースの利用状況とClickHouseサーバーメトリクスを監視できます。
keywords: [監視, 観測性, 高度なダッシュボード, ダッシュボード, 観測性ダッシュボード]
---
# 監視
import SelfManaged from '@site/docs/ja/_snippets/_self_managed_only_automated.md';
監視できる内容:
- ハードウェアリソースの利用状況。
- ClickHouseサーバーメトリクス。
## 組み込みの高度な観測性ダッシュボード
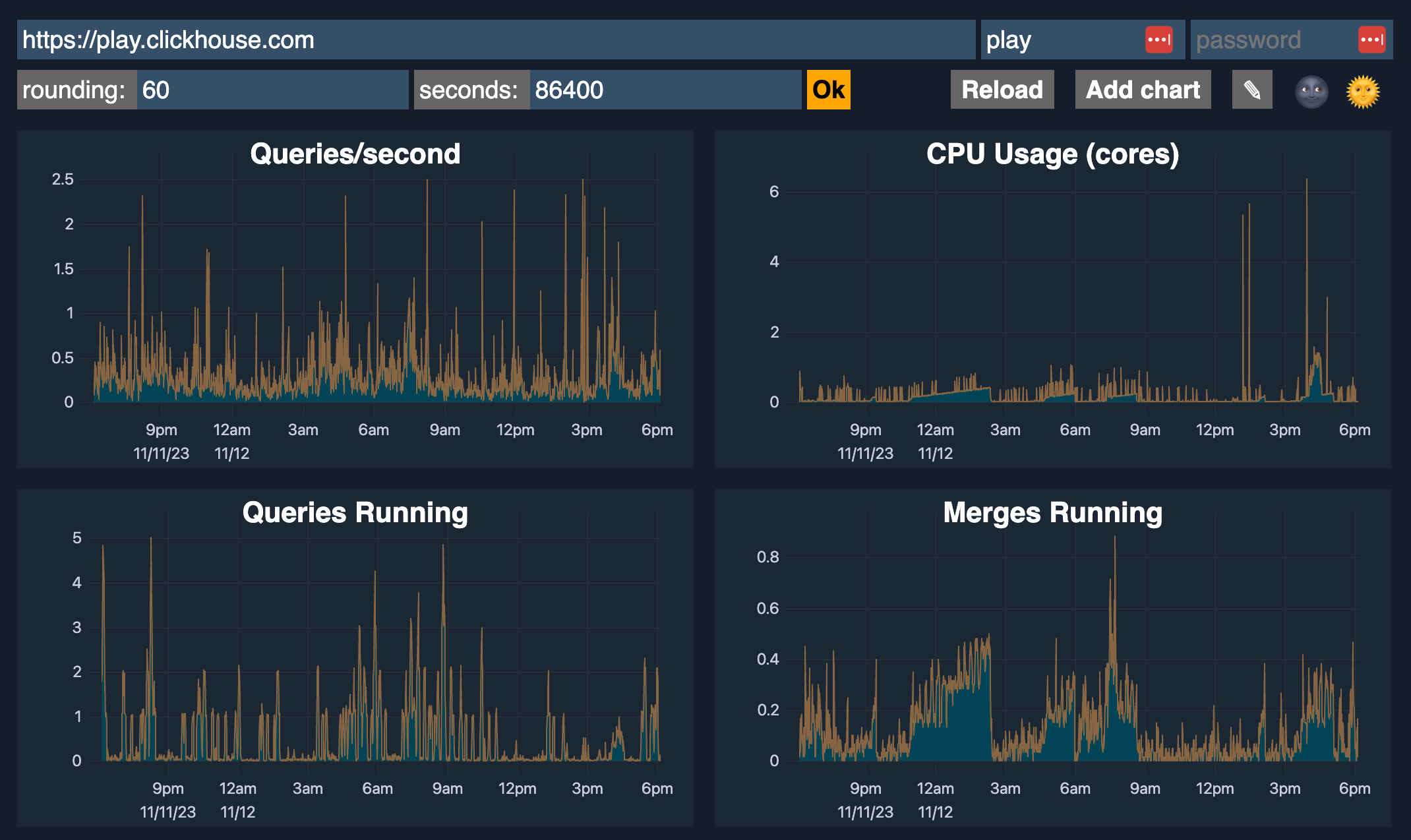 ClickHouseには組み込みの高度な観測性ダッシュボード機能があり、`$HOST:$PORT/dashboard`(ユーザーとパスワードが必要)でアクセスできます。このダッシュボードでは以下のメトリクスを表示します:
- クエリ数/秒
- CPU使用率 (コア)
- 実行中のクエリ
- 実行中マージ
- 選択されたバイト/秒
- IO待機
- CPU待機
- OS CPU使用率 (ユーザースペース)
- OS CPU使用率 (カーネル)
- ディスクからの読み込み
- ファイルシステムからの読み込み
- メモリ(トラッキング済み)
- 挿入された行数/秒
- 合計MergeTreeパーツ
- パーティションごとの最大パーツ
## リソース利用状況 {#resource-utilization}
ClickHouseはハードウェアリソースの状態を自動で監視します。例えば以下のようなものがあります:
- プロセッサの負荷と温度。
- ストレージシステム、RAM、ネットワークの利用状況。
このデータは`system.asynchronous_metric_log`テーブルに収集されます。
## ClickHouseサーバーメトリクス {#clickhouse-server-metrics}
ClickHouseサーバーには自己状態監視用の組み込み計器があります。
サーバーイベントを追跡するには、サーバーログを使用します。設定ファイルの[logger](../operations/server-configuration-parameters/settings.md#logger)セクションを参照してください。
ClickHouseでは以下を収集します:
- サーバーが計算リソースを使用する際のさまざまなメトリクス。
- クエリ処理に関する一般的な統計。
メトリクスは[system.metrics](../operations/system-tables/metrics.md#system_tables-metrics)、[system.events](../operations/system-tables/events.md#system_tables-events)、および[system.asynchronous_metrics](../operations/system-tables/asynchronous_metrics.md#system_tables-asynchronous_metrics)テーブルにあります。
ClickHouseを[Graphite](https://github.com/graphite-project)にメトリクスをエクスポートするよう設定できます。ClickHouseサーバーの構成ファイルの[Graphiteセクション](../operations/server-configuration-parameters/settings.md#graphite)を参照してください。メトリクスのエクスポートを設定する前に、公式[ガイド](https://graphite.readthedocs.io/en/latest/install.html)に従ってGraphiteをセットアップする必要があります。
ClickHouseを[Prometheus](https://prometheus.io)にメトリクスをエクスポートするよう設定できます。ClickHouseサーバーの構成ファイルの[Prometheusセクション](../operations/server-configuration-parameters/settings.md#prometheus)を参照してください。メトリクスのエクスポートを設定する前に、Prometheusの公式[ガイド](https://prometheus.io/docs/prometheus/latest/installation/)に従ってセットアップする必要があります。
さらに、HTTP APIを通じてサーバーの可用性を監視できます。`/ping`に`HTTP GET`リクエストを送信すると、サーバーが利用可能であれば`200 OK`が返されます。
クラスター構成でサーバーを監視するには、[max_replica_delay_for_distributed_queries](../operations/settings/settings.md#max_replica_delay_for_distributed_queries)パラメータを設定し、HTTPリソース`/replicas_status`を使用する必要があります。`/replicas_status`へのリクエストは、レプリカが利用可能で他のレプリカより遅れていない場合、`200 OK`を返します。レプリカが遅れている場合は、遅延に関する情報を含む`503 HTTP_SERVICE_UNAVAILABLE`を返します。
ClickHouseには組み込みの高度な観測性ダッシュボード機能があり、`$HOST:$PORT/dashboard`(ユーザーとパスワードが必要)でアクセスできます。このダッシュボードでは以下のメトリクスを表示します:
- クエリ数/秒
- CPU使用率 (コア)
- 実行中のクエリ
- 実行中マージ
- 選択されたバイト/秒
- IO待機
- CPU待機
- OS CPU使用率 (ユーザースペース)
- OS CPU使用率 (カーネル)
- ディスクからの読み込み
- ファイルシステムからの読み込み
- メモリ(トラッキング済み)
- 挿入された行数/秒
- 合計MergeTreeパーツ
- パーティションごとの最大パーツ
## リソース利用状況 {#resource-utilization}
ClickHouseはハードウェアリソースの状態を自動で監視します。例えば以下のようなものがあります:
- プロセッサの負荷と温度。
- ストレージシステム、RAM、ネットワークの利用状況。
このデータは`system.asynchronous_metric_log`テーブルに収集されます。
## ClickHouseサーバーメトリクス {#clickhouse-server-metrics}
ClickHouseサーバーには自己状態監視用の組み込み計器があります。
サーバーイベントを追跡するには、サーバーログを使用します。設定ファイルの[logger](../operations/server-configuration-parameters/settings.md#logger)セクションを参照してください。
ClickHouseでは以下を収集します:
- サーバーが計算リソースを使用する際のさまざまなメトリクス。
- クエリ処理に関する一般的な統計。
メトリクスは[system.metrics](../operations/system-tables/metrics.md#system_tables-metrics)、[system.events](../operations/system-tables/events.md#system_tables-events)、および[system.asynchronous_metrics](../operations/system-tables/asynchronous_metrics.md#system_tables-asynchronous_metrics)テーブルにあります。
ClickHouseを[Graphite](https://github.com/graphite-project)にメトリクスをエクスポートするよう設定できます。ClickHouseサーバーの構成ファイルの[Graphiteセクション](../operations/server-configuration-parameters/settings.md#graphite)を参照してください。メトリクスのエクスポートを設定する前に、公式[ガイド](https://graphite.readthedocs.io/en/latest/install.html)に従ってGraphiteをセットアップする必要があります。
ClickHouseを[Prometheus](https://prometheus.io)にメトリクスをエクスポートするよう設定できます。ClickHouseサーバーの構成ファイルの[Prometheusセクション](../operations/server-configuration-parameters/settings.md#prometheus)を参照してください。メトリクスのエクスポートを設定する前に、Prometheusの公式[ガイド](https://prometheus.io/docs/prometheus/latest/installation/)に従ってセットアップする必要があります。
さらに、HTTP APIを通じてサーバーの可用性を監視できます。`/ping`に`HTTP GET`リクエストを送信すると、サーバーが利用可能であれば`200 OK`が返されます。
クラスター構成でサーバーを監視するには、[max_replica_delay_for_distributed_queries](../operations/settings/settings.md#max_replica_delay_for_distributed_queries)パラメータを設定し、HTTPリソース`/replicas_status`を使用する必要があります。`/replicas_status`へのリクエストは、レプリカが利用可能で他のレプリカより遅れていない場合、`200 OK`を返します。レプリカが遅れている場合は、遅延に関する情報を含む`503 HTTP_SERVICE_UNAVAILABLE`を返します。