mirror of
https://github.com/ClickHouse/ClickHouse.git
synced 2024-12-14 18:32:29 +00:00
8.3 KiB
8.3 KiB
| slug | sidebar_label |
|---|---|
| /ja/getting-started/example-datasets/environmental-sensors | 環境センサーのデータ |
環境センサーのデータ
Sensor.Community は、オープン環境データを生成する共同作業型グローバルセンサーネットワークです。このデータは、世界中のセンサーから収集されています。誰でもセンサーを購入して、好きな場所に設置することができます。データをダウンロードするためのAPIは GitHub にあり、データは Database Contents License (DbCL) の下で自由に利用可能です。
:::important このデータセットには200億以上のレコードがあるため、以下のコマンドを単純にコピー&ペーストする場合は、リソースがこのボリュームに耐えられるか注意が必要です。以下のコマンドは、ClickHouse Cloud の本番インスタンスで実行されています。 :::
- データはS3にあるので、
s3テーブル関数を使用してファイルからテーブルを作成できます。また、データをそのままクエリすることもできます。ClickHouseに挿入する前にいくつかの行を見てみましょう:
SELECT *
FROM s3(
'https://clickhouse-public-datasets.s3.eu-central-1.amazonaws.com/sensors/monthly/2019-06_bmp180.csv.zst',
'CSVWithNames'
)
LIMIT 10
SETTINGS format_csv_delimiter = ';';
データはCSVファイルにあり、デリミタとしてセミコロンを使用しています。行の形式は次のようになっています:
┌─sensor_id─┬─sensor_type─┬─location─┬────lat─┬────lon─┬─timestamp───────────┬──pressure─┬─altitude─┬─pressure_sealevel─┬─temperature─┐
│ 9119 │ BMP180 │ 4594 │ 50.994 │ 7.126 │ 2019-06-01T00:00:00 │ 101471 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 19.9 │
│ 21210 │ BMP180 │ 10762 │ 42.206 │ 25.326 │ 2019-06-01T00:00:00 │ 99525 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 19.3 │
│ 19660 │ BMP180 │ 9978 │ 52.434 │ 17.056 │ 2019-06-01T00:00:04 │ 101570 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 15.3 │
│ 12126 │ BMP180 │ 6126 │ 57.908 │ 16.49 │ 2019-06-01T00:00:05 │ 101802.56 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 8.07 │
│ 15845 │ BMP180 │ 8022 │ 52.498 │ 13.466 │ 2019-06-01T00:00:05 │ 101878 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 23 │
│ 16415 │ BMP180 │ 8316 │ 49.312 │ 6.744 │ 2019-06-01T00:00:06 │ 100176 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 14.7 │
│ 7389 │ BMP180 │ 3735 │ 50.136 │ 11.062 │ 2019-06-01T00:00:06 │ 98905 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 12.1 │
│ 13199 │ BMP180 │ 6664 │ 52.514 │ 13.44 │ 2019-06-01T00:00:07 │ 101855.54 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 19.74 │
│ 12753 │ BMP180 │ 6440 │ 44.616 │ 2.032 │ 2019-06-01T00:00:07 │ 99475 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 17 │
│ 16956 │ BMP180 │ 8594 │ 52.052 │ 8.354 │ 2019-06-01T00:00:08 │ 101322 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 17.2 │
└───────────┴─────────────┴──────────┴────────┴────────┴─────────────────────┴───────────┴──────────┴───────────────────┴─────────────┘
- データをClickHouseに保存するために、以下の
MergeTreeテーブルを使用します:
CREATE TABLE sensors
(
sensor_id UInt16,
sensor_type Enum('BME280', 'BMP180', 'BMP280', 'DHT22', 'DS18B20', 'HPM', 'HTU21D', 'PMS1003', 'PMS3003', 'PMS5003', 'PMS6003', 'PMS7003', 'PPD42NS', 'SDS011'),
location UInt32,
lat Float32,
lon Float32,
timestamp DateTime,
P1 Float32,
P2 Float32,
P0 Float32,
durP1 Float32,
ratioP1 Float32,
durP2 Float32,
ratioP2 Float32,
pressure Float32,
altitude Float32,
pressure_sealevel Float32,
temperature Float32,
humidity Float32,
date Date MATERIALIZED toDate(timestamp)
)
ENGINE = MergeTree
ORDER BY (timestamp, sensor_id);
- ClickHouse Cloud サービスには
defaultという名前のクラスタがあります。s3Clusterテーブル関数を使用して、クラスタ内のノードからS3ファイルを並行して読み込みます。(クラスタがない場合は、単にs3関数を使用し、クラスタ名を削除してください。)
このクエリには時間がかかります - 圧縮されていないデータが約1.67Tあります:
INSERT INTO sensors
SELECT *
FROM s3Cluster(
'default',
'https://clickhouse-public-datasets.s3.amazonaws.com/sensors/monthly/*.csv.zst',
'CSVWithNames',
$$ sensor_id UInt16,
sensor_type String,
location UInt32,
lat Float32,
lon Float32,
timestamp DateTime,
P1 Float32,
P2 Float32,
P0 Float32,
durP1 Float32,
ratioP1 Float32,
durP2 Float32,
ratioP2 Float32,
pressure Float32,
altitude Float32,
pressure_sealevel Float32,
temperature Float32,
humidity Float32 $$
)
SETTINGS
format_csv_delimiter = ';',
input_format_allow_errors_ratio = '0.5',
input_format_allow_errors_num = 10000,
input_format_parallel_parsing = 0,
date_time_input_format = 'best_effort',
max_insert_threads = 32,
parallel_distributed_insert_select = 1;
以下はレスポンスです - 行数と処理速度を示しています。6M行/秒以上の速度で入力されています!
0 rows in set. Elapsed: 3419.330 sec. Processed 20.69 billion rows, 1.67 TB (6.05 million rows/s., 488.52 MB/s.)
sensorsテーブルのストレージディスクがどれくらい必要か見てみましょう:
SELECT
disk_name,
formatReadableSize(sum(data_compressed_bytes) AS size) AS compressed,
formatReadableSize(sum(data_uncompressed_bytes) AS usize) AS uncompressed,
round(usize / size, 2) AS compr_rate,
sum(rows) AS rows,
count() AS part_count
FROM system.parts
WHERE (active = 1) AND (table = 'sensors')
GROUP BY
disk_name
ORDER BY size DESC;
1.67Tは310 GiBに圧縮されており、20.69億行があります:
┌─disk_name─┬─compressed─┬─uncompressed─┬─compr_rate─┬────────rows─┬─part_count─┐
│ s3disk │ 310.21 GiB │ 1.30 TiB │ 4.29 │ 20693971809 │ 472 │
└───────────┴────────────┴──────────────┴────────────┴─────────────┴────────────┘
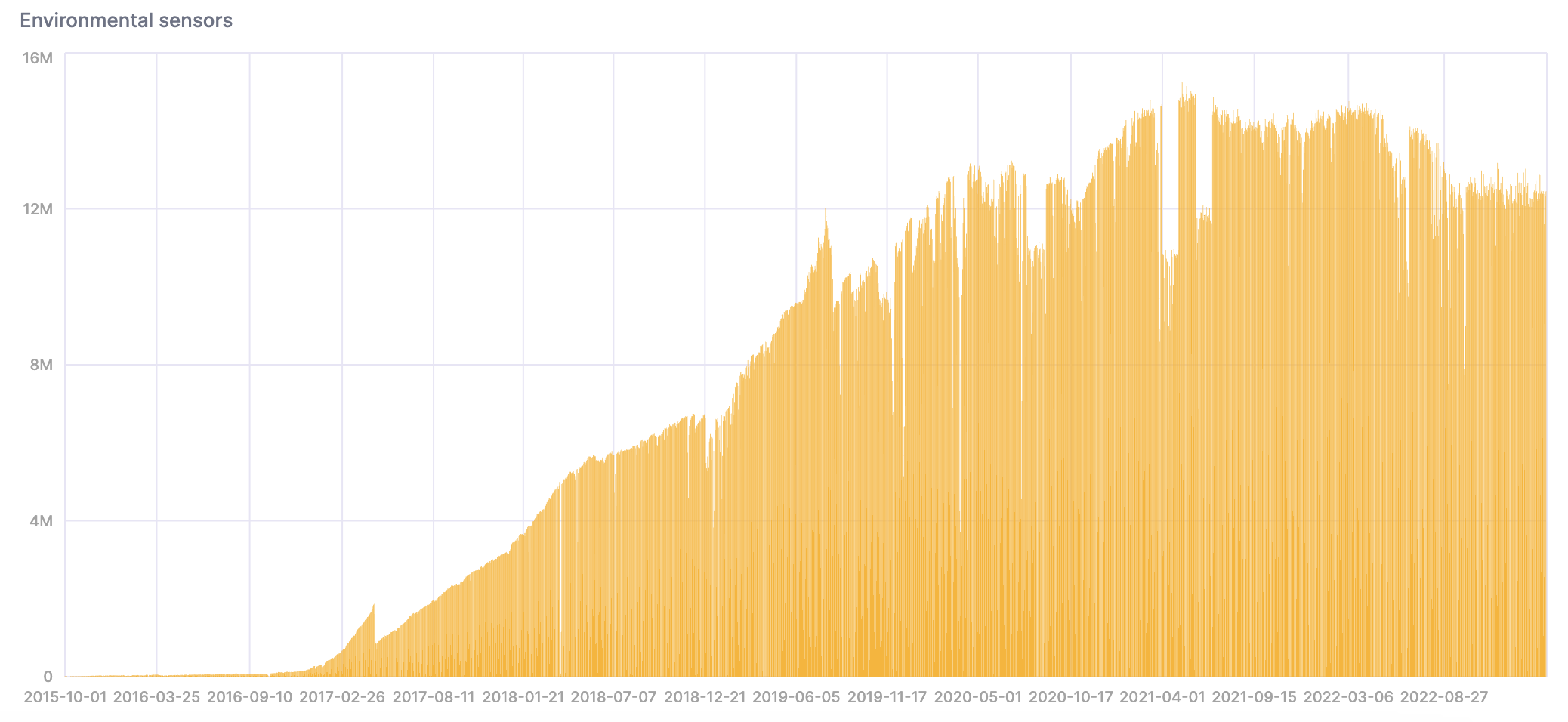
- それでは、データをClickHouseにインポートしたので、分析を行いましょう。センサーが増えたことで、データの量が時間とともに増加していることに注目してください:
SELECT
date,
count()
FROM sensors
GROUP BY date
ORDER BY date ASC;
SQLコンソールで結果を可視化するためにチャートを作成できます:
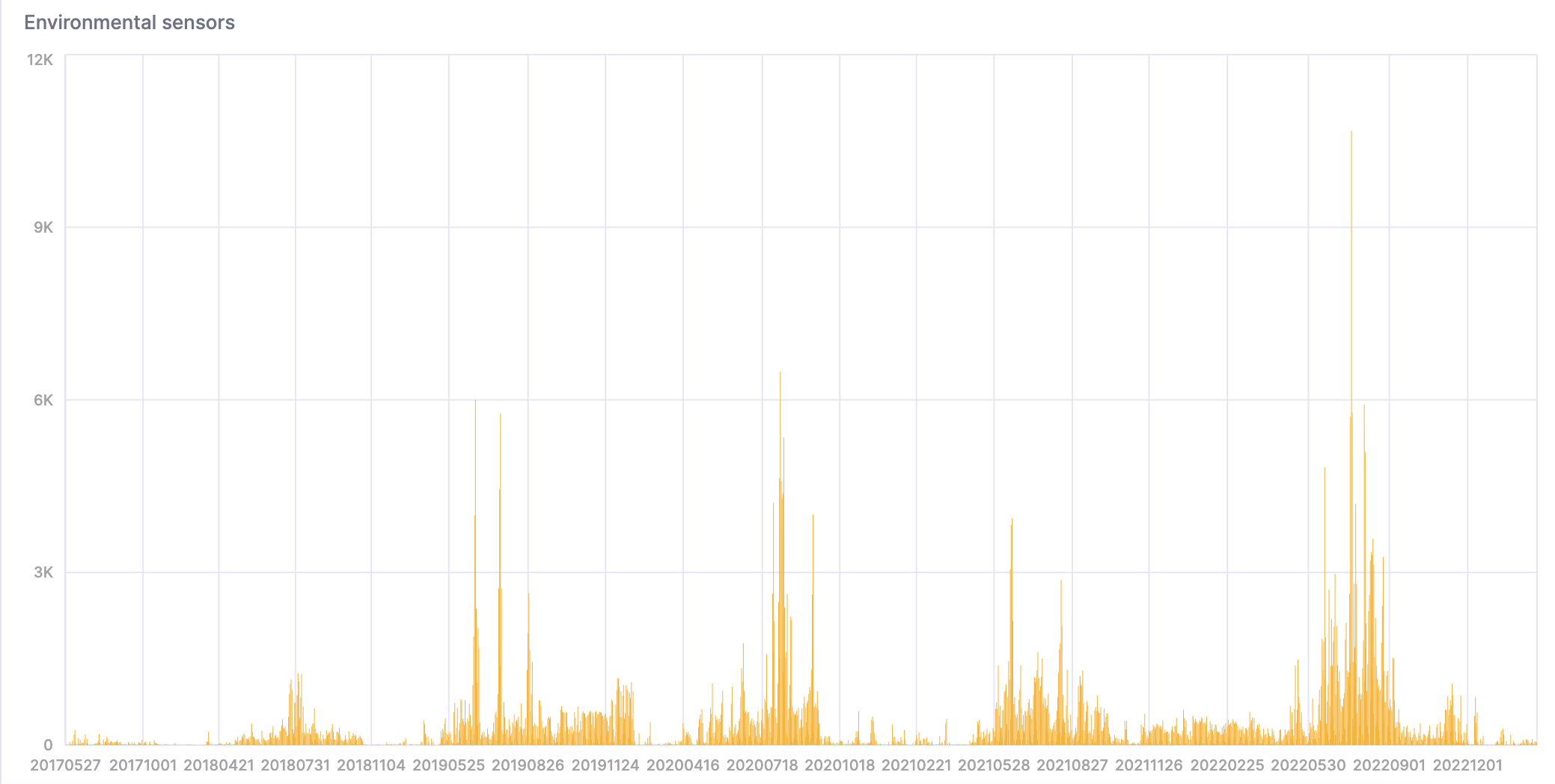
- 次のクエリは、非常に暑く湿度の高い日数をカウントします:
WITH
toYYYYMMDD(timestamp) AS day
SELECT day, count() FROM sensors
WHERE temperature >= 40 AND temperature <= 50 AND humidity >= 90
GROUP BY day
ORDER BY day asc;
こちらがその結果の視覚化です: