mirror of
https://github.com/ClickHouse/ClickHouse.git
synced 2024-11-10 01:25:21 +00:00
Merge remote-tracking branch 'upstream/master' into impove-filecache-removal
This commit is contained in:
commit
dadf84f37b
@ -122,6 +122,23 @@ EOL
|
|||||||
<core_path>$PWD</core_path>
|
<core_path>$PWD</core_path>
|
||||||
</clickhouse>
|
</clickhouse>
|
||||||
EOL
|
EOL
|
||||||
|
|
||||||
|
# Setup a cluster for logs export to ClickHouse Cloud
|
||||||
|
# Note: these variables are provided to the Docker run command by the Python script in tests/ci
|
||||||
|
if [ -n "${CLICKHOUSE_CI_LOGS_HOST}" ]
|
||||||
|
then
|
||||||
|
echo "
|
||||||
|
remote_servers:
|
||||||
|
system_logs_export:
|
||||||
|
shard:
|
||||||
|
replica:
|
||||||
|
secure: 1
|
||||||
|
user: ci
|
||||||
|
host: '${CLICKHOUSE_CI_LOGS_HOST}'
|
||||||
|
port: 9440
|
||||||
|
password: '${CLICKHOUSE_CI_LOGS_PASSWORD}'
|
||||||
|
" > db/config.d/system_logs_export.yaml
|
||||||
|
fi
|
||||||
}
|
}
|
||||||
|
|
||||||
function filter_exists_and_template
|
function filter_exists_and_template
|
||||||
@ -223,7 +240,22 @@ quit
|
|||||||
done
|
done
|
||||||
clickhouse-client --query "select 1" # This checks that the server is responding
|
clickhouse-client --query "select 1" # This checks that the server is responding
|
||||||
kill -0 $server_pid # This checks that it is our server that is started and not some other one
|
kill -0 $server_pid # This checks that it is our server that is started and not some other one
|
||||||
echo Server started and responded
|
echo 'Server started and responded'
|
||||||
|
|
||||||
|
# Initialize export of system logs to ClickHouse Cloud
|
||||||
|
if [ -n "${CLICKHOUSE_CI_LOGS_HOST}" ]
|
||||||
|
then
|
||||||
|
export EXTRA_COLUMNS_EXPRESSION="$PR_TO_TEST AS pull_request_number, '$SHA_TO_TEST' AS commit_sha, '$CHECK_START_TIME' AS check_start_time, '$CHECK_NAME' AS check_name, '$INSTANCE_TYPE' AS instance_type"
|
||||||
|
# TODO: Check if the password will appear in the logs.
|
||||||
|
export CONNECTION_PARAMETERS="--secure --user ci --host ${CLICKHOUSE_CI_LOGS_HOST} --password ${CLICKHOUSE_CI_LOGS_PASSWORD}"
|
||||||
|
|
||||||
|
/setup_export_logs.sh
|
||||||
|
|
||||||
|
# Unset variables after use
|
||||||
|
export CONNECTION_PARAMETERS=''
|
||||||
|
export CLICKHOUSE_CI_LOGS_HOST=''
|
||||||
|
export CLICKHOUSE_CI_LOGS_PASSWORD=''
|
||||||
|
fi
|
||||||
|
|
||||||
# SC2012: Use find instead of ls to better handle non-alphanumeric filenames. They are all alphanumeric.
|
# SC2012: Use find instead of ls to better handle non-alphanumeric filenames. They are all alphanumeric.
|
||||||
# SC2046: Quote this to prevent word splitting. Actually I need word splitting.
|
# SC2046: Quote this to prevent word splitting. Actually I need word splitting.
|
||||||
|
|||||||
@ -36,6 +36,9 @@ then
|
|||||||
elif [ "${ARCH}" = "riscv64" ]
|
elif [ "${ARCH}" = "riscv64" ]
|
||||||
then
|
then
|
||||||
DIR="riscv64"
|
DIR="riscv64"
|
||||||
|
elif [ "${ARCH}" = "s390x" ]
|
||||||
|
then
|
||||||
|
DIR="s390x"
|
||||||
fi
|
fi
|
||||||
elif [ "${OS}" = "FreeBSD" ]
|
elif [ "${OS}" = "FreeBSD" ]
|
||||||
then
|
then
|
||||||
|
|||||||
@ -1,4 +1,4 @@
|
|||||||
# Approximate Nearest Neighbor Search Indexes [experimental] {#table_engines-ANNIndex}
|
# Approximate Nearest Neighbor Search Indexes [experimental]
|
||||||
|
|
||||||
Nearest neighborhood search is the problem of finding the M closest points for a given point in an N-dimensional vector space. The most
|
Nearest neighborhood search is the problem of finding the M closest points for a given point in an N-dimensional vector space. The most
|
||||||
straightforward approach to solve this problem is a brute force search where the distance between all points in the vector space and the
|
straightforward approach to solve this problem is a brute force search where the distance between all points in the vector space and the
|
||||||
@ -17,7 +17,7 @@ In terms of SQL, the nearest neighborhood problem can be expressed as follows:
|
|||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
SELECT *
|
SELECT *
|
||||||
FROM table
|
FROM table_with_ann_index
|
||||||
ORDER BY Distance(vectors, Point)
|
ORDER BY Distance(vectors, Point)
|
||||||
LIMIT N
|
LIMIT N
|
||||||
```
|
```
|
||||||
@ -32,7 +32,7 @@ An alternative formulation of the nearest neighborhood search problem looks as f
|
|||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
SELECT *
|
SELECT *
|
||||||
FROM table
|
FROM table_with_ann_index
|
||||||
WHERE Distance(vectors, Point) < MaxDistance
|
WHERE Distance(vectors, Point) < MaxDistance
|
||||||
LIMIT N
|
LIMIT N
|
||||||
```
|
```
|
||||||
@ -45,12 +45,12 @@ With brute force search, both queries are expensive (linear in the number of poi
|
|||||||
`Point` must be computed. To speed this process up, Approximate Nearest Neighbor Search Indexes (ANN indexes) store a compact representation
|
`Point` must be computed. To speed this process up, Approximate Nearest Neighbor Search Indexes (ANN indexes) store a compact representation
|
||||||
of the search space (using clustering, search trees, etc.) which allows to compute an approximate answer much quicker (in sub-linear time).
|
of the search space (using clustering, search trees, etc.) which allows to compute an approximate answer much quicker (in sub-linear time).
|
||||||
|
|
||||||
# Creating and Using ANN Indexes
|
# Creating and Using ANN Indexes {#creating_using_ann_indexes}
|
||||||
|
|
||||||
Syntax to create an ANN index over an [Array](../../../sql-reference/data-types/array.md) column:
|
Syntax to create an ANN index over an [Array](../../../sql-reference/data-types/array.md) column:
|
||||||
|
|
||||||
```sql
|
```sql
|
||||||
CREATE TABLE table
|
CREATE TABLE table_with_ann_index
|
||||||
(
|
(
|
||||||
`id` Int64,
|
`id` Int64,
|
||||||
`vectors` Array(Float32),
|
`vectors` Array(Float32),
|
||||||
@ -63,7 +63,7 @@ ORDER BY id;
|
|||||||
Syntax to create an ANN index over a [Tuple](../../../sql-reference/data-types/tuple.md) column:
|
Syntax to create an ANN index over a [Tuple](../../../sql-reference/data-types/tuple.md) column:
|
||||||
|
|
||||||
```sql
|
```sql
|
||||||
CREATE TABLE table
|
CREATE TABLE table_with_ann_index
|
||||||
(
|
(
|
||||||
`id` Int64,
|
`id` Int64,
|
||||||
`vectors` Tuple(Float32[, Float32[, ...]]),
|
`vectors` Tuple(Float32[, Float32[, ...]]),
|
||||||
@ -83,7 +83,7 @@ ANN indexes support two types of queries:
|
|||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
SELECT *
|
SELECT *
|
||||||
FROM table
|
FROM table_with_ann_index
|
||||||
[WHERE ...]
|
[WHERE ...]
|
||||||
ORDER BY Distance(vectors, Point)
|
ORDER BY Distance(vectors, Point)
|
||||||
LIMIT N
|
LIMIT N
|
||||||
@ -93,7 +93,7 @@ ANN indexes support two types of queries:
|
|||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
SELECT *
|
SELECT *
|
||||||
FROM table
|
FROM table_with_ann_index
|
||||||
WHERE Distance(vectors, Point) < MaxDistance
|
WHERE Distance(vectors, Point) < MaxDistance
|
||||||
LIMIT N
|
LIMIT N
|
||||||
```
|
```
|
||||||
@ -103,7 +103,7 @@ To avoid writing out large vectors, you can use [query
|
|||||||
parameters](/docs/en/interfaces/cli.md#queries-with-parameters-cli-queries-with-parameters), e.g.
|
parameters](/docs/en/interfaces/cli.md#queries-with-parameters-cli-queries-with-parameters), e.g.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
clickhouse-client --param_vec='hello' --query="SELECT * FROM table WHERE L2Distance(vectors, {vec: Array(Float32)}) < 1.0"
|
clickhouse-client --param_vec='hello' --query="SELECT * FROM table_with_ann_index WHERE L2Distance(vectors, {vec: Array(Float32)}) < 1.0"
|
||||||
```
|
```
|
||||||
:::
|
:::
|
||||||
|
|
||||||
@ -138,7 +138,7 @@ back to a smaller `GRANULARITY` values only in case of problems like excessive m
|
|||||||
was specified for ANN indexes, the default value is 100 million.
|
was specified for ANN indexes, the default value is 100 million.
|
||||||
|
|
||||||
|
|
||||||
# Available ANN Indexes
|
# Available ANN Indexes {#available_ann_indexes}
|
||||||
|
|
||||||
- [Annoy](/docs/en/engines/table-engines/mergetree-family/annindexes.md#annoy-annoy)
|
- [Annoy](/docs/en/engines/table-engines/mergetree-family/annindexes.md#annoy-annoy)
|
||||||
|
|
||||||
@ -165,7 +165,7 @@ space in random linear surfaces (lines in 2D, planes in 3D etc.).
|
|||||||
Syntax to create an Annoy index over an [Array](../../../sql-reference/data-types/array.md) column:
|
Syntax to create an Annoy index over an [Array](../../../sql-reference/data-types/array.md) column:
|
||||||
|
|
||||||
```sql
|
```sql
|
||||||
CREATE TABLE table
|
CREATE TABLE table_with_annoy_index
|
||||||
(
|
(
|
||||||
id Int64,
|
id Int64,
|
||||||
vectors Array(Float32),
|
vectors Array(Float32),
|
||||||
@ -178,7 +178,7 @@ ORDER BY id;
|
|||||||
Syntax to create an ANN index over a [Tuple](../../../sql-reference/data-types/tuple.md) column:
|
Syntax to create an ANN index over a [Tuple](../../../sql-reference/data-types/tuple.md) column:
|
||||||
|
|
||||||
```sql
|
```sql
|
||||||
CREATE TABLE table
|
CREATE TABLE table_with_annoy_index
|
||||||
(
|
(
|
||||||
id Int64,
|
id Int64,
|
||||||
vectors Tuple(Float32[, Float32[, ...]]),
|
vectors Tuple(Float32[, Float32[, ...]]),
|
||||||
@ -188,23 +188,17 @@ ENGINE = MergeTree
|
|||||||
ORDER BY id;
|
ORDER BY id;
|
||||||
```
|
```
|
||||||
|
|
||||||
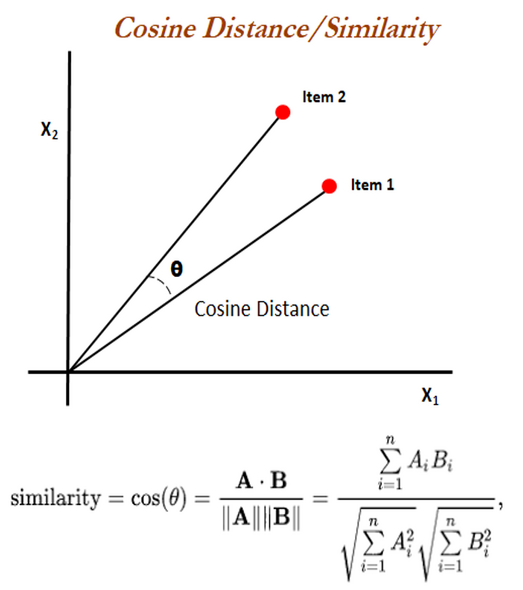
Annoy currently supports `L2Distance` and `cosineDistance` as distance function `Distance`. If no distance function was specified during
|
Annoy currently supports two distance functions:
|
||||||
index creation, `L2Distance` is used as default. Parameter `NumTrees` is the number of trees which the algorithm creates (default if not
|
- `L2Distance`, also called Euclidean distance, is the length of a line segment between two points in Euclidean space
|
||||||
specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
|
([Wikipedia](https://en.wikipedia.org/wiki/Euclidean_distance)).
|
||||||
linearly) as well as larger index sizes.
|
- `cosineDistance`, also called cosine similarity, is the cosine of the angle between two (non-zero) vectors
|
||||||
|
([Wikipedia](https://en.wikipedia.org/wiki/Cosine_similarity)).
|
||||||
|
|
||||||
`L2Distance` is also called Euclidean distance, the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points.
|
For normalized data, `L2Distance` is usually a better choice, otherwise `cosineDistance` is recommended to compensate for scale. If no
|
||||||
For example: If we have point P(p1,p2), Q(q1,q2), their distance will be d(p,q)
|
distance function was specified during index creation, `L2Distance` is used as default.
|
||||||

|
|
||||||
|
|
||||||
`cosineDistance` also called cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths.
|
Parameter `NumTrees` is the number of trees which the algorithm creates (default if not specified: 100). Higher values of `NumTree` mean
|
||||||
|
more accurate search results but slower index creation / query times (approximately linearly) as well as larger index sizes.
|
||||||
|
|
||||||
The Euclidean distance corresponds to the L2-norm of a difference between vectors. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
|
|
||||||

|
|
||||||
In one sentence: cosine similarity care only about the angle between them, but do not care about the "distance" we normally think.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
:::note
|
:::note
|
||||||
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
|
||||||
|
|||||||
@ -11,82 +11,83 @@ results of a `SELECT`, and to perform `INSERT`s into a file-backed table.
|
|||||||
The supported formats are:
|
The supported formats are:
|
||||||
|
|
||||||
| Format | Input | Output |
|
| Format | Input | Output |
|
||||||
|-------------------------------------------------------------------------------------------|------|--------|
|
|-------------------------------------------------------------------------------------------|------|-------|
|
||||||
| [TabSeparated](#tabseparated) | ✔ | ✔ |
|
| [TabSeparated](#tabseparated) | ✔ | ✔ |
|
||||||
| [TabSeparatedRaw](#tabseparatedraw) | ✔ | ✔ |
|
| [TabSeparatedRaw](#tabseparatedraw) | ✔ | ✔ |
|
||||||
| [TabSeparatedWithNames](#tabseparatedwithnames) | ✔ | ✔ |
|
| [TabSeparatedWithNames](#tabseparatedwithnames) | ✔ | ✔ |
|
||||||
| [TabSeparatedWithNamesAndTypes](#tabseparatedwithnamesandtypes) | ✔ | ✔ |
|
| [TabSeparatedWithNamesAndTypes](#tabseparatedwithnamesandtypes) | ✔ | ✔ |
|
||||||
| [TabSeparatedRawWithNames](#tabseparatedrawwithnames) | ✔ | ✔ |
|
| [TabSeparatedRawWithNames](#tabseparatedrawwithnames) | ✔ | ✔ |
|
||||||
| [TabSeparatedRawWithNamesAndTypes](#tabseparatedrawwithnamesandtypes) | ✔ | ✔ |
|
| [TabSeparatedRawWithNamesAndTypes](#tabseparatedrawwithnamesandtypes) | ✔ | ✔ |
|
||||||
| [Template](#format-template) | ✔ | ✔ |
|
| [Template](#format-template) | ✔ | ✔ |
|
||||||
| [TemplateIgnoreSpaces](#templateignorespaces) | ✔ | ✗ |
|
| [TemplateIgnoreSpaces](#templateignorespaces) | ✔ | ✗ |
|
||||||
| [CSV](#csv) | ✔ | ✔ |
|
| [CSV](#csv) | ✔ | ✔ |
|
||||||
| [CSVWithNames](#csvwithnames) | ✔ | ✔ |
|
| [CSVWithNames](#csvwithnames) | ✔ | ✔ |
|
||||||
| [CSVWithNamesAndTypes](#csvwithnamesandtypes) | ✔ | ✔ |
|
| [CSVWithNamesAndTypes](#csvwithnamesandtypes) | ✔ | ✔ |
|
||||||
| [CustomSeparated](#format-customseparated) | ✔ | ✔ |
|
| [CustomSeparated](#format-customseparated) | ✔ | ✔ |
|
||||||
| [CustomSeparatedWithNames](#customseparatedwithnames) | ✔ | ✔ |
|
| [CustomSeparatedWithNames](#customseparatedwithnames) | ✔ | ✔ |
|
||||||
| [CustomSeparatedWithNamesAndTypes](#customseparatedwithnamesandtypes) | ✔ | ✔ |
|
| [CustomSeparatedWithNamesAndTypes](#customseparatedwithnamesandtypes) | ✔ | ✔ |
|
||||||
| [SQLInsert](#sqlinsert) | ✗ | ✔ |
|
| [SQLInsert](#sqlinsert) | ✗ | ✔ |
|
||||||
| [Values](#data-format-values) | ✔ | ✔ |
|
| [Values](#data-format-values) | ✔ | ✔ |
|
||||||
| [Vertical](#vertical) | ✗ | ✔ |
|
| [Vertical](#vertical) | ✗ | ✔ |
|
||||||
| [JSON](#json) | ✔ | ✔ |
|
| [JSON](#json) | ✔ | ✔ |
|
||||||
| [JSONAsString](#jsonasstring) | ✔ | ✗ |
|
| [JSONAsString](#jsonasstring) | ✔ | ✗ |
|
||||||
| [JSONStrings](#jsonstrings) | ✔ | ✔ |
|
| [JSONStrings](#jsonstrings) | ✔ | ✔ |
|
||||||
| [JSONColumns](#jsoncolumns) | ✔ | ✔ |
|
| [JSONColumns](#jsoncolumns) | ✔ | ✔ |
|
||||||
| [JSONColumnsWithMetadata](#jsoncolumnsmonoblock)) | ✔ | ✔ |
|
| [JSONColumnsWithMetadata](#jsoncolumnsmonoblock)) | ✔ | ✔ |
|
||||||
| [JSONCompact](#jsoncompact) | ✔ | ✔ |
|
| [JSONCompact](#jsoncompact) | ✔ | ✔ |
|
||||||
| [JSONCompactStrings](#jsoncompactstrings) | ✗ | ✔ |
|
| [JSONCompactStrings](#jsoncompactstrings) | ✗ | ✔ |
|
||||||
| [JSONCompactColumns](#jsoncompactcolumns) | ✔ | ✔ |
|
| [JSONCompactColumns](#jsoncompactcolumns) | ✔ | ✔ |
|
||||||
| [JSONEachRow](#jsoneachrow) | ✔ | ✔ |
|
| [JSONEachRow](#jsoneachrow) | ✔ | ✔ |
|
||||||
| [PrettyJSONEachRow](#prettyjsoneachrow) | ✗ | ✔ |
|
| [PrettyJSONEachRow](#prettyjsoneachrow) | ✗ | ✔ |
|
||||||
| [JSONEachRowWithProgress](#jsoneachrowwithprogress) | ✗ | ✔ |
|
| [JSONEachRowWithProgress](#jsoneachrowwithprogress) | ✗ | ✔ |
|
||||||
| [JSONStringsEachRow](#jsonstringseachrow) | ✔ | ✔ |
|
| [JSONStringsEachRow](#jsonstringseachrow) | ✔ | ✔ |
|
||||||
| [JSONStringsEachRowWithProgress](#jsonstringseachrowwithprogress) | ✗ | ✔ |
|
| [JSONStringsEachRowWithProgress](#jsonstringseachrowwithprogress) | ✗ | ✔ |
|
||||||
| [JSONCompactEachRow](#jsoncompacteachrow) | ✔ | ✔ |
|
| [JSONCompactEachRow](#jsoncompacteachrow) | ✔ | ✔ |
|
||||||
| [JSONCompactEachRowWithNames](#jsoncompacteachrowwithnames) | ✔ | ✔ |
|
| [JSONCompactEachRowWithNames](#jsoncompacteachrowwithnames) | ✔ | ✔ |
|
||||||
| [JSONCompactEachRowWithNamesAndTypes](#jsoncompacteachrowwithnamesandtypes) | ✔ | ✔ |
|
| [JSONCompactEachRowWithNamesAndTypes](#jsoncompacteachrowwithnamesandtypes) | ✔ | ✔ |
|
||||||
| [JSONCompactStringsEachRow](#jsoncompactstringseachrow) | ✔ | ✔ |
|
| [JSONCompactStringsEachRow](#jsoncompactstringseachrow) | ✔ | ✔ |
|
||||||
| [JSONCompactStringsEachRowWithNames](#jsoncompactstringseachrowwithnames) | ✔ | ✔ |
|
| [JSONCompactStringsEachRowWithNames](#jsoncompactstringseachrowwithnames) | ✔ | ✔ |
|
||||||
| [JSONCompactStringsEachRowWithNamesAndTypes](#jsoncompactstringseachrowwithnamesandtypes) | ✔ | ✔ |
|
| [JSONCompactStringsEachRowWithNamesAndTypes](#jsoncompactstringseachrowwithnamesandtypes) | ✔ | ✔ |
|
||||||
| [JSONObjectEachRow](#jsonobjecteachrow) | ✔ | ✔ |
|
| [JSONObjectEachRow](#jsonobjecteachrow) | ✔ | ✔ |
|
||||||
| [BSONEachRow](#bsoneachrow) | ✔ | ✔ |
|
| [BSONEachRow](#bsoneachrow) | ✔ | ✔ |
|
||||||
| [TSKV](#tskv) | ✔ | ✔ |
|
| [TSKV](#tskv) | ✔ | ✔ |
|
||||||
| [Pretty](#pretty) | ✗ | ✔ |
|
| [Pretty](#pretty) | ✗ | ✔ |
|
||||||
| [PrettyNoEscapes](#prettynoescapes) | ✗ | ✔ |
|
| [PrettyNoEscapes](#prettynoescapes) | ✗ | ✔ |
|
||||||
| [PrettyMonoBlock](#prettymonoblock) | ✗ | ✔ |
|
| [PrettyMonoBlock](#prettymonoblock) | ✗ | ✔ |
|
||||||
| [PrettyNoEscapesMonoBlock](#prettynoescapesmonoblock) | ✗ | ✔ |
|
| [PrettyNoEscapesMonoBlock](#prettynoescapesmonoblock) | ✗ | ✔ |
|
||||||
| [PrettyCompact](#prettycompact) | ✗ | ✔ |
|
| [PrettyCompact](#prettycompact) | ✗ | ✔ |
|
||||||
| [PrettyCompactNoEscapes](#prettycompactnoescapes) | ✗ | ✔ |
|
| [PrettyCompactNoEscapes](#prettycompactnoescapes) | ✗ | ✔ |
|
||||||
| [PrettyCompactMonoBlock](#prettycompactmonoblock) | ✗ | ✔ |
|
| [PrettyCompactMonoBlock](#prettycompactmonoblock) | ✗ | ✔ |
|
||||||
| [PrettyCompactNoEscapesMonoBlock](#prettycompactnoescapesmonoblock) | ✗ | ✔ |
|
| [PrettyCompactNoEscapesMonoBlock](#prettycompactnoescapesmonoblock) | ✗ | ✔ |
|
||||||
| [PrettySpace](#prettyspace) | ✗ | ✔ |
|
| [PrettySpace](#prettyspace) | ✗ | ✔ |
|
||||||
| [PrettySpaceNoEscapes](#prettyspacenoescapes) | ✗ | ✔ |
|
| [PrettySpaceNoEscapes](#prettyspacenoescapes) | ✗ | ✔ |
|
||||||
| [PrettySpaceMonoBlock](#prettyspacemonoblock) | ✗ | ✔ |
|
| [PrettySpaceMonoBlock](#prettyspacemonoblock) | ✗ | ✔ |
|
||||||
| [PrettySpaceNoEscapesMonoBlock](#prettyspacenoescapesmonoblock) | ✗ | ✔ |
|
| [PrettySpaceNoEscapesMonoBlock](#prettyspacenoescapesmonoblock) | ✗ | ✔ |
|
||||||
| [Prometheus](#prometheus) | ✗ | ✔ |
|
| [Prometheus](#prometheus) | ✗ | ✔ |
|
||||||
| [Protobuf](#protobuf) | ✔ | ✔ |
|
| [Protobuf](#protobuf) | ✔ | ✔ |
|
||||||
| [ProtobufSingle](#protobufsingle) | ✔ | ✔ |
|
| [ProtobufSingle](#protobufsingle) | ✔ | ✔ |
|
||||||
| [Avro](#data-format-avro) | ✔ | ✔ |
|
| [Avro](#data-format-avro) | ✔ | ✔ |
|
||||||
| [AvroConfluent](#data-format-avro-confluent) | ✔ | ✗ |
|
| [AvroConfluent](#data-format-avro-confluent) | ✔ | ✗ |
|
||||||
| [Parquet](#data-format-parquet) | ✔ | ✔ |
|
| [Parquet](#data-format-parquet) | ✔ | ✔ |
|
||||||
| [ParquetMetadata](#data-format-parquet-metadata) | ✔ | ✗ |
|
| [ParquetMetadata](#data-format-parquet-metadata) | ✔ | ✗ |
|
||||||
| [Arrow](#data-format-arrow) | ✔ | ✔ |
|
| [Arrow](#data-format-arrow) | ✔ | ✔ |
|
||||||
| [ArrowStream](#data-format-arrow-stream) | ✔ | ✔ |
|
| [ArrowStream](#data-format-arrow-stream) | ✔ | ✔ |
|
||||||
| [ORC](#data-format-orc) | ✔ | ✔ |
|
| [ORC](#data-format-orc) | ✔ | ✔ |
|
||||||
| [RowBinary](#rowbinary) | ✔ | ✔ |
|
| [One](#data-format-one) | ✔ | ✗ |
|
||||||
| [RowBinaryWithNames](#rowbinarywithnamesandtypes) | ✔ | ✔ |
|
| [RowBinary](#rowbinary) | ✔ | ✔ |
|
||||||
| [RowBinaryWithNamesAndTypes](#rowbinarywithnamesandtypes) | ✔ | ✔ |
|
| [RowBinaryWithNames](#rowbinarywithnamesandtypes) | ✔ | ✔ |
|
||||||
| [RowBinaryWithDefaults](#rowbinarywithdefaults) | ✔ | ✔ |
|
| [RowBinaryWithNamesAndTypes](#rowbinarywithnamesandtypes) | ✔ | ✔ |
|
||||||
| [Native](#native) | ✔ | ✔ |
|
| [RowBinaryWithDefaults](#rowbinarywithdefaults) | ✔ | ✔ |
|
||||||
| [Null](#null) | ✗ | ✔ |
|
| [Native](#native) | ✔ | ✔ |
|
||||||
| [XML](#xml) | ✗ | ✔ |
|
| [Null](#null) | ✗ | ✔ |
|
||||||
| [CapnProto](#capnproto) | ✔ | ✔ |
|
| [XML](#xml) | ✗ | ✔ |
|
||||||
| [LineAsString](#lineasstring) | ✔ | ✔ |
|
| [CapnProto](#capnproto) | ✔ | ✔ |
|
||||||
| [Regexp](#data-format-regexp) | ✔ | ✗ |
|
| [LineAsString](#lineasstring) | ✔ | ✔ |
|
||||||
| [RawBLOB](#rawblob) | ✔ | ✔ |
|
| [Regexp](#data-format-regexp) | ✔ | ✗ |
|
||||||
| [MsgPack](#msgpack) | ✔ | ✔ |
|
| [RawBLOB](#rawblob) | ✔ | ✔ |
|
||||||
| [MySQLDump](#mysqldump) | ✔ | ✗ |
|
| [MsgPack](#msgpack) | ✔ | ✔ |
|
||||||
| [Markdown](#markdown) | ✗ | ✔ |
|
| [MySQLDump](#mysqldump) | ✔ | ✗ |
|
||||||
|
| [Markdown](#markdown) | ✗ | ✔ |
|
||||||
|
|
||||||
|
|
||||||
You can control some format processing parameters with the ClickHouse settings. For more information read the [Settings](/docs/en/operations/settings/settings-formats.md) section.
|
You can control some format processing parameters with the ClickHouse settings. For more information read the [Settings](/docs/en/operations/settings/settings-formats.md) section.
|
||||||
@ -2131,6 +2132,7 @@ To exchange data with Hadoop, you can use [HDFS table engine](/docs/en/engines/t
|
|||||||
|
|
||||||
- [output_format_parquet_row_group_size](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_row_group_size) - row group size in rows while data output. Default value - `1000000`.
|
- [output_format_parquet_row_group_size](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_row_group_size) - row group size in rows while data output. Default value - `1000000`.
|
||||||
- [output_format_parquet_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_string_as_string) - use Parquet String type instead of Binary for String columns. Default value - `false`.
|
- [output_format_parquet_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_string_as_string) - use Parquet String type instead of Binary for String columns. Default value - `false`.
|
||||||
|
- [input_format_parquet_import_nested](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_import_nested) - allow inserting array of structs into [Nested](/docs/en/sql-reference/data-types/nested-data-structures/index.md) table in Parquet input format. Default value - `false`.
|
||||||
- [input_format_parquet_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_case_insensitive_column_matching) - ignore case when matching Parquet columns with ClickHouse columns. Default value - `false`.
|
- [input_format_parquet_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_case_insensitive_column_matching) - ignore case when matching Parquet columns with ClickHouse columns. Default value - `false`.
|
||||||
- [input_format_parquet_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_allow_missing_columns) - allow missing columns while reading Parquet data. Default value - `false`.
|
- [input_format_parquet_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_allow_missing_columns) - allow missing columns while reading Parquet data. Default value - `false`.
|
||||||
- [input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Parquet format. Default value - `false`.
|
- [input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Parquet format. Default value - `false`.
|
||||||
@ -2407,6 +2409,34 @@ $ clickhouse-client --query="SELECT * FROM {some_table} FORMAT ORC" > {filename.
|
|||||||
|
|
||||||
To exchange data with Hadoop, you can use [HDFS table engine](/docs/en/engines/table-engines/integrations/hdfs.md).
|
To exchange data with Hadoop, you can use [HDFS table engine](/docs/en/engines/table-engines/integrations/hdfs.md).
|
||||||
|
|
||||||
|
## One {#data-format-one}
|
||||||
|
|
||||||
|
Special input format that doesn't read any data from file and returns only one row with column of type `UInt8`, name `dummy` and value `0` (like `system.one` table).
|
||||||
|
Can be used with virtual columns `_file/_path` to list all files without reading actual data.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
Query:
|
||||||
|
```sql
|
||||||
|
SELECT _file FROM file('path/to/files/data*', One);
|
||||||
|
```
|
||||||
|
|
||||||
|
Result:
|
||||||
|
```text
|
||||||
|
┌─_file────┐
|
||||||
|
│ data.csv │
|
||||||
|
└──────────┘
|
||||||
|
┌─_file──────┐
|
||||||
|
│ data.jsonl │
|
||||||
|
└────────────┘
|
||||||
|
┌─_file────┐
|
||||||
|
│ data.tsv │
|
||||||
|
└──────────┘
|
||||||
|
┌─_file────────┐
|
||||||
|
│ data.parquet │
|
||||||
|
└──────────────┘
|
||||||
|
```
|
||||||
|
|
||||||
## LineAsString {#lineasstring}
|
## LineAsString {#lineasstring}
|
||||||
|
|
||||||
In this format, every line of input data is interpreted as a single string value. This format can only be parsed for table with a single field of type [String](/docs/en/sql-reference/data-types/string.md). The remaining columns must be set to [DEFAULT](/docs/en/sql-reference/statements/create/table.md/#default) or [MATERIALIZED](/docs/en/sql-reference/statements/create/table.md/#materialized), or omitted.
|
In this format, every line of input data is interpreted as a single string value. This format can only be parsed for table with a single field of type [String](/docs/en/sql-reference/data-types/string.md). The remaining columns must be set to [DEFAULT](/docs/en/sql-reference/statements/create/table.md/#default) or [MATERIALIZED](/docs/en/sql-reference/statements/create/table.md/#materialized), or omitted.
|
||||||
|
|||||||
@ -83,8 +83,8 @@ ClickHouse, Inc. does **not** maintain the tools and libraries listed below and
|
|||||||
- Python
|
- Python
|
||||||
- [SQLAlchemy](https://www.sqlalchemy.org)
|
- [SQLAlchemy](https://www.sqlalchemy.org)
|
||||||
- [sqlalchemy-clickhouse](https://github.com/cloudflare/sqlalchemy-clickhouse) (uses [infi.clickhouse_orm](https://github.com/Infinidat/infi.clickhouse_orm))
|
- [sqlalchemy-clickhouse](https://github.com/cloudflare/sqlalchemy-clickhouse) (uses [infi.clickhouse_orm](https://github.com/Infinidat/infi.clickhouse_orm))
|
||||||
- [pandas](https://pandas.pydata.org)
|
- [PyArrow/Pandas](https://pandas.pydata.org)
|
||||||
- [pandahouse](https://github.com/kszucs/pandahouse)
|
- [Ibis](https://github.com/ibis-project/ibis)
|
||||||
- PHP
|
- PHP
|
||||||
- [Doctrine](https://www.doctrine-project.org/)
|
- [Doctrine](https://www.doctrine-project.org/)
|
||||||
- [dbal-clickhouse](https://packagist.org/packages/friendsofdoctrine/dbal-clickhouse)
|
- [dbal-clickhouse](https://packagist.org/packages/friendsofdoctrine/dbal-clickhouse)
|
||||||
|
|||||||
@ -11,7 +11,7 @@ Inserts data into a table.
|
|||||||
**Syntax**
|
**Syntax**
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
|
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
|
||||||
```
|
```
|
||||||
|
|
||||||
You can specify a list of columns to insert using the `(c1, c2, c3)`. You can also use an expression with column [matcher](../../sql-reference/statements/select/index.md#asterisk) such as `*` and/or [modifiers](../../sql-reference/statements/select/index.md#select-modifiers) such as [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#except-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier).
|
You can specify a list of columns to insert using the `(c1, c2, c3)`. You can also use an expression with column [matcher](../../sql-reference/statements/select/index.md#asterisk) such as `*` and/or [modifiers](../../sql-reference/statements/select/index.md#select-modifiers) such as [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#except-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier).
|
||||||
@ -107,7 +107,7 @@ If table has [constraints](../../sql-reference/statements/create/table.md#constr
|
|||||||
**Syntax**
|
**Syntax**
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
|
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] SELECT ...
|
||||||
```
|
```
|
||||||
|
|
||||||
Columns are mapped according to their position in the SELECT clause. However, their names in the SELECT expression and the table for INSERT may differ. If necessary, type casting is performed.
|
Columns are mapped according to their position in the SELECT clause. However, their names in the SELECT expression and the table for INSERT may differ. If necessary, type casting is performed.
|
||||||
@ -126,7 +126,7 @@ To insert a default value instead of `NULL` into a column with not nullable data
|
|||||||
**Syntax**
|
**Syntax**
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
|
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
|
||||||
```
|
```
|
||||||
|
|
||||||
Use the syntax above to insert data from a file, or files, stored on the **client** side. `file_name` and `type` are string literals. Input file [format](../../interfaces/formats.md) must be set in the `FORMAT` clause.
|
Use the syntax above to insert data from a file, or files, stored on the **client** side. `file_name` and `type` are string literals. Input file [format](../../interfaces/formats.md) must be set in the `FORMAT` clause.
|
||||||
|
|||||||
@ -11,7 +11,7 @@ sidebar_label: INSERT INTO
|
|||||||
**Синтаксис**
|
**Синтаксис**
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
|
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
|
||||||
```
|
```
|
||||||
|
|
||||||
Вы можете указать список столбцов для вставки, используя синтаксис `(c1, c2, c3)`. Также можно использовать выражение cо [звездочкой](../../sql-reference/statements/select/index.md#asterisk) и/или модификаторами, такими как [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#except-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier).
|
Вы можете указать список столбцов для вставки, используя синтаксис `(c1, c2, c3)`. Также можно использовать выражение cо [звездочкой](../../sql-reference/statements/select/index.md#asterisk) и/или модификаторами, такими как [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#except-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier).
|
||||||
@ -100,7 +100,7 @@ INSERT INTO t FORMAT TabSeparated
|
|||||||
**Синтаксис**
|
**Синтаксис**
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
|
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] SELECT ...
|
||||||
```
|
```
|
||||||
|
|
||||||
Соответствие столбцов определяется их позицией в секции SELECT. При этом, их имена в выражении SELECT и в таблице для INSERT, могут отличаться. При необходимости выполняется приведение типов данных, эквивалентное соответствующему оператору CAST.
|
Соответствие столбцов определяется их позицией в секции SELECT. При этом, их имена в выражении SELECT и в таблице для INSERT, могут отличаться. При необходимости выполняется приведение типов данных, эквивалентное соответствующему оператору CAST.
|
||||||
@ -120,7 +120,7 @@ INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
|
|||||||
**Синтаксис**
|
**Синтаксис**
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
|
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
|
||||||
```
|
```
|
||||||
|
|
||||||
Используйте этот синтаксис, чтобы вставить данные из файла, который хранится на стороне **клиента**. `file_name` и `type` задаются в виде строковых литералов. [Формат](../../interfaces/formats.md) входного файла должен быть задан в секции `FORMAT`.
|
Используйте этот синтаксис, чтобы вставить данные из файла, который хранится на стороне **клиента**. `file_name` и `type` задаются в виде строковых литералов. [Формат](../../interfaces/formats.md) входного файла должен быть задан в секции `FORMAT`.
|
||||||
|
|||||||
@ -8,7 +8,7 @@ INSERT INTO 语句主要用于向系统中添加数据.
|
|||||||
查询的基本格式:
|
查询的基本格式:
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
|
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
|
||||||
```
|
```
|
||||||
|
|
||||||
您可以在查询中指定要插入的列的列表,如:`[(c1, c2, c3)]`。您还可以使用列[匹配器](../../sql-reference/statements/select/index.md#asterisk)的表达式,例如`*`和/或[修饰符](../../sql-reference/statements/select/index.md#select-modifiers),例如 [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#apply-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier)。
|
您可以在查询中指定要插入的列的列表,如:`[(c1, c2, c3)]`。您还可以使用列[匹配器](../../sql-reference/statements/select/index.md#asterisk)的表达式,例如`*`和/或[修饰符](../../sql-reference/statements/select/index.md#select-modifiers),例如 [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#apply-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier)。
|
||||||
@ -71,7 +71,7 @@ INSERT INTO [db.]table [(c1, c2, c3)] FORMAT format_name data_set
|
|||||||
例如,下面的查询所使用的输入格式就与上面INSERT … VALUES的中使用的输入格式相同:
|
例如,下面的查询所使用的输入格式就与上面INSERT … VALUES的中使用的输入格式相同:
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO [db.]table [(c1, c2, c3)] FORMAT Values (v11, v12, v13), (v21, v22, v23), ...
|
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] FORMAT Values (v11, v12, v13), (v21, v22, v23), ...
|
||||||
```
|
```
|
||||||
|
|
||||||
ClickHouse会清除数据前所有的空白字符与一个换行符(如果有换行符的话)。所以在进行查询时,我们建议您将数据放入到输入输出格式名称后的新的一行中去(如果数据是以空白字符开始的,这将非常重要)。
|
ClickHouse会清除数据前所有的空白字符与一个换行符(如果有换行符的话)。所以在进行查询时,我们建议您将数据放入到输入输出格式名称后的新的一行中去(如果数据是以空白字符开始的,这将非常重要)。
|
||||||
@ -93,7 +93,7 @@ INSERT INTO t FORMAT TabSeparated
|
|||||||
### 使用`SELECT`的结果写入 {#inserting-the-results-of-select}
|
### 使用`SELECT`的结果写入 {#inserting-the-results-of-select}
|
||||||
|
|
||||||
``` sql
|
``` sql
|
||||||
INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
|
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] SELECT ...
|
||||||
```
|
```
|
||||||
|
|
||||||
写入与SELECT的列的对应关系是使用位置来进行对应的,尽管它们在SELECT表达式与INSERT中的名称可能是不同的。如果需要,会对它们执行对应的类型转换。
|
写入与SELECT的列的对应关系是使用位置来进行对应的,尽管它们在SELECT表达式与INSERT中的名称可能是不同的。如果需要,会对它们执行对应的类型转换。
|
||||||
|
|||||||
@ -997,7 +997,9 @@ namespace
|
|||||||
{
|
{
|
||||||
/// sudo respects limits in /etc/security/limits.conf e.g. open files,
|
/// sudo respects limits in /etc/security/limits.conf e.g. open files,
|
||||||
/// that's why we are using it instead of the 'clickhouse su' tool.
|
/// that's why we are using it instead of the 'clickhouse su' tool.
|
||||||
command = fmt::format("sudo -u '{}' {}", user, command);
|
/// by default, sudo resets all the ENV variables, but we should preserve
|
||||||
|
/// the values /etc/default/clickhouse in /etc/init.d/clickhouse file
|
||||||
|
command = fmt::format("sudo --preserve-env -u '{}' {}", user, command);
|
||||||
}
|
}
|
||||||
|
|
||||||
fmt::print("Will run {}\n", command);
|
fmt::print("Will run {}\n", command);
|
||||||
|
|||||||
@ -105,6 +105,7 @@ namespace ErrorCodes
|
|||||||
extern const int LOGICAL_ERROR;
|
extern const int LOGICAL_ERROR;
|
||||||
extern const int CANNOT_OPEN_FILE;
|
extern const int CANNOT_OPEN_FILE;
|
||||||
extern const int FILE_ALREADY_EXISTS;
|
extern const int FILE_ALREADY_EXISTS;
|
||||||
|
extern const int USER_SESSION_LIMIT_EXCEEDED;
|
||||||
}
|
}
|
||||||
|
|
||||||
}
|
}
|
||||||
@ -2408,6 +2409,13 @@ void ClientBase::runInteractive()
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
if (suggest && suggest->getLastError() == ErrorCodes::USER_SESSION_LIMIT_EXCEEDED)
|
||||||
|
{
|
||||||
|
// If a separate connection loading suggestions failed to open a new session,
|
||||||
|
// use the main session to receive them.
|
||||||
|
suggest->load(*connection, connection_parameters.timeouts, config().getInt("suggestion_limit"));
|
||||||
|
}
|
||||||
|
|
||||||
try
|
try
|
||||||
{
|
{
|
||||||
if (!processQueryText(input))
|
if (!processQueryText(input))
|
||||||
|
|||||||
@ -22,9 +22,11 @@ namespace DB
|
|||||||
{
|
{
|
||||||
namespace ErrorCodes
|
namespace ErrorCodes
|
||||||
{
|
{
|
||||||
|
extern const int OK;
|
||||||
extern const int LOGICAL_ERROR;
|
extern const int LOGICAL_ERROR;
|
||||||
extern const int UNKNOWN_PACKET_FROM_SERVER;
|
extern const int UNKNOWN_PACKET_FROM_SERVER;
|
||||||
extern const int DEADLOCK_AVOIDED;
|
extern const int DEADLOCK_AVOIDED;
|
||||||
|
extern const int USER_SESSION_LIMIT_EXCEEDED;
|
||||||
}
|
}
|
||||||
|
|
||||||
Suggest::Suggest()
|
Suggest::Suggest()
|
||||||
@ -121,21 +123,24 @@ void Suggest::load(ContextPtr context, const ConnectionParameters & connection_p
|
|||||||
}
|
}
|
||||||
catch (const Exception & e)
|
catch (const Exception & e)
|
||||||
{
|
{
|
||||||
|
last_error = e.code();
|
||||||
if (e.code() == ErrorCodes::DEADLOCK_AVOIDED)
|
if (e.code() == ErrorCodes::DEADLOCK_AVOIDED)
|
||||||
continue;
|
continue;
|
||||||
|
else if (e.code() != ErrorCodes::USER_SESSION_LIMIT_EXCEEDED)
|
||||||
/// Client can successfully connect to the server and
|
{
|
||||||
/// get ErrorCodes::USER_SESSION_LIMIT_EXCEEDED for suggestion connection.
|
/// We should not use std::cerr here, because this method works concurrently with the main thread.
|
||||||
|
/// WriteBufferFromFileDescriptor will write directly to the file descriptor, avoiding data race on std::cerr.
|
||||||
/// We should not use std::cerr here, because this method works concurrently with the main thread.
|
///
|
||||||
/// WriteBufferFromFileDescriptor will write directly to the file descriptor, avoiding data race on std::cerr.
|
/// USER_SESSION_LIMIT_EXCEEDED is ignored here. The client will try to receive
|
||||||
|
/// suggestions using the main connection later.
|
||||||
WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
|
WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
|
||||||
out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
|
out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
|
||||||
out.next();
|
out.next();
|
||||||
|
}
|
||||||
}
|
}
|
||||||
catch (...)
|
catch (...)
|
||||||
{
|
{
|
||||||
|
last_error = getCurrentExceptionCode();
|
||||||
WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
|
WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
|
||||||
out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
|
out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
|
||||||
out.next();
|
out.next();
|
||||||
@ -148,6 +153,21 @@ void Suggest::load(ContextPtr context, const ConnectionParameters & connection_p
|
|||||||
});
|
});
|
||||||
}
|
}
|
||||||
|
|
||||||
|
void Suggest::load(IServerConnection & connection,
|
||||||
|
const ConnectionTimeouts & timeouts,
|
||||||
|
Int32 suggestion_limit)
|
||||||
|
{
|
||||||
|
try
|
||||||
|
{
|
||||||
|
fetch(connection, timeouts, getLoadSuggestionQuery(suggestion_limit, true));
|
||||||
|
}
|
||||||
|
catch (...)
|
||||||
|
{
|
||||||
|
std::cerr << "Suggestions loading exception: " << getCurrentExceptionMessage(false, true) << std::endl;
|
||||||
|
last_error = getCurrentExceptionCode();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
void Suggest::fetch(IServerConnection & connection, const ConnectionTimeouts & timeouts, const std::string & query)
|
void Suggest::fetch(IServerConnection & connection, const ConnectionTimeouts & timeouts, const std::string & query)
|
||||||
{
|
{
|
||||||
connection.sendQuery(
|
connection.sendQuery(
|
||||||
@ -176,6 +196,7 @@ void Suggest::fetch(IServerConnection & connection, const ConnectionTimeouts & t
|
|||||||
return;
|
return;
|
||||||
|
|
||||||
case Protocol::Server::EndOfStream:
|
case Protocol::Server::EndOfStream:
|
||||||
|
last_error = ErrorCodes::OK;
|
||||||
return;
|
return;
|
||||||
|
|
||||||
default:
|
default:
|
||||||
|
|||||||
@ -7,6 +7,7 @@
|
|||||||
#include <Client/LocalConnection.h>
|
#include <Client/LocalConnection.h>
|
||||||
#include <Client/LineReader.h>
|
#include <Client/LineReader.h>
|
||||||
#include <IO/ConnectionTimeouts.h>
|
#include <IO/ConnectionTimeouts.h>
|
||||||
|
#include <atomic>
|
||||||
#include <thread>
|
#include <thread>
|
||||||
|
|
||||||
|
|
||||||
@ -28,9 +29,15 @@ public:
|
|||||||
template <typename ConnectionType>
|
template <typename ConnectionType>
|
||||||
void load(ContextPtr context, const ConnectionParameters & connection_parameters, Int32 suggestion_limit);
|
void load(ContextPtr context, const ConnectionParameters & connection_parameters, Int32 suggestion_limit);
|
||||||
|
|
||||||
|
void load(IServerConnection & connection,
|
||||||
|
const ConnectionTimeouts & timeouts,
|
||||||
|
Int32 suggestion_limit);
|
||||||
|
|
||||||
/// Older server versions cannot execute the query loading suggestions.
|
/// Older server versions cannot execute the query loading suggestions.
|
||||||
static constexpr int MIN_SERVER_REVISION = DBMS_MIN_PROTOCOL_VERSION_WITH_VIEW_IF_PERMITTED;
|
static constexpr int MIN_SERVER_REVISION = DBMS_MIN_PROTOCOL_VERSION_WITH_VIEW_IF_PERMITTED;
|
||||||
|
|
||||||
|
int getLastError() const { return last_error.load(); }
|
||||||
|
|
||||||
private:
|
private:
|
||||||
void fetch(IServerConnection & connection, const ConnectionTimeouts & timeouts, const std::string & query);
|
void fetch(IServerConnection & connection, const ConnectionTimeouts & timeouts, const std::string & query);
|
||||||
|
|
||||||
@ -38,6 +45,8 @@ private:
|
|||||||
|
|
||||||
/// Words are fetched asynchronously.
|
/// Words are fetched asynchronously.
|
||||||
std::thread loading_thread;
|
std::thread loading_thread;
|
||||||
|
|
||||||
|
std::atomic<int> last_error { -1 };
|
||||||
};
|
};
|
||||||
|
|
||||||
}
|
}
|
||||||
|
|||||||
@ -3,23 +3,25 @@
|
|||||||
#include <base/Decimal_fwd.h>
|
#include <base/Decimal_fwd.h>
|
||||||
#include <base/extended_types.h>
|
#include <base/extended_types.h>
|
||||||
|
|
||||||
|
#include <city.h>
|
||||||
|
|
||||||
#include <utility>
|
#include <utility>
|
||||||
|
|
||||||
namespace DB
|
namespace DB
|
||||||
{
|
{
|
||||||
template <std::endian endian, typename T>
|
template <std::endian ToEndian, std::endian FromEndian = std::endian::native, typename T>
|
||||||
requires std::is_integral_v<T>
|
requires std::is_integral_v<T>
|
||||||
inline void transformEndianness(T & value)
|
inline void transformEndianness(T & value)
|
||||||
{
|
{
|
||||||
if constexpr (endian != std::endian::native)
|
if constexpr (ToEndian != FromEndian)
|
||||||
value = std::byteswap(value);
|
value = std::byteswap(value);
|
||||||
}
|
}
|
||||||
|
|
||||||
template <std::endian endian, typename T>
|
template <std::endian ToEndian, std::endian FromEndian = std::endian::native, typename T>
|
||||||
requires is_big_int_v<T>
|
requires is_big_int_v<T>
|
||||||
inline void transformEndianness(T & x)
|
inline void transformEndianness(T & x)
|
||||||
{
|
{
|
||||||
if constexpr (std::endian::native != endian)
|
if constexpr (ToEndian != FromEndian)
|
||||||
{
|
{
|
||||||
auto & items = x.items;
|
auto & items = x.items;
|
||||||
std::transform(std::begin(items), std::end(items), std::begin(items), [](auto & item) { return std::byteswap(item); });
|
std::transform(std::begin(items), std::end(items), std::begin(items), [](auto & item) { return std::byteswap(item); });
|
||||||
@ -27,42 +29,49 @@ inline void transformEndianness(T & x)
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
template <std::endian endian, typename T>
|
template <std::endian ToEndian, std::endian FromEndian = std::endian::native, typename T>
|
||||||
requires is_decimal<T>
|
requires is_decimal<T>
|
||||||
inline void transformEndianness(T & x)
|
inline void transformEndianness(T & x)
|
||||||
{
|
{
|
||||||
transformEndianness<endian>(x.value);
|
transformEndianness<ToEndian, FromEndian>(x.value);
|
||||||
}
|
}
|
||||||
|
|
||||||
template <std::endian endian, typename T>
|
template <std::endian ToEndian, std::endian FromEndian = std::endian::native, typename T>
|
||||||
requires std::is_floating_point_v<T>
|
requires std::is_floating_point_v<T>
|
||||||
inline void transformEndianness(T & value)
|
inline void transformEndianness(T & value)
|
||||||
{
|
{
|
||||||
if constexpr (std::endian::native != endian)
|
if constexpr (ToEndian != FromEndian)
|
||||||
{
|
{
|
||||||
auto * start = reinterpret_cast<std::byte *>(&value);
|
auto * start = reinterpret_cast<std::byte *>(&value);
|
||||||
std::reverse(start, start + sizeof(T));
|
std::reverse(start, start + sizeof(T));
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
template <std::endian endian, typename T>
|
template <std::endian ToEndian, std::endian FromEndian = std::endian::native, typename T>
|
||||||
requires std::is_scoped_enum_v<T>
|
requires std::is_scoped_enum_v<T>
|
||||||
inline void transformEndianness(T & x)
|
inline void transformEndianness(T & x)
|
||||||
{
|
{
|
||||||
using UnderlyingType = std::underlying_type_t<T>;
|
using UnderlyingType = std::underlying_type_t<T>;
|
||||||
transformEndianness<endian>(reinterpret_cast<UnderlyingType &>(x));
|
transformEndianness<ToEndian, FromEndian>(reinterpret_cast<UnderlyingType &>(x));
|
||||||
}
|
}
|
||||||
|
|
||||||
template <std::endian endian, typename A, typename B>
|
template <std::endian ToEndian, std::endian FromEndian = std::endian::native, typename A, typename B>
|
||||||
inline void transformEndianness(std::pair<A, B> & pair)
|
inline void transformEndianness(std::pair<A, B> & pair)
|
||||||
{
|
{
|
||||||
transformEndianness<endian>(pair.first);
|
transformEndianness<ToEndian, FromEndian>(pair.first);
|
||||||
transformEndianness<endian>(pair.second);
|
transformEndianness<ToEndian, FromEndian>(pair.second);
|
||||||
}
|
}
|
||||||
|
|
||||||
template <std::endian endian, typename T, typename Tag>
|
template <std::endian ToEndian, std::endian FromEndian = std::endian::native, typename T, typename Tag>
|
||||||
inline void transformEndianness(StrongTypedef<T, Tag> & x)
|
inline void transformEndianness(StrongTypedef<T, Tag> & x)
|
||||||
{
|
{
|
||||||
transformEndianness<endian>(x.toUnderType());
|
transformEndianness<ToEndian, FromEndian>(x.toUnderType());
|
||||||
|
}
|
||||||
|
|
||||||
|
template <std::endian ToEndian, std::endian FromEndian = std::endian::native>
|
||||||
|
inline void transformEndianness(CityHash_v1_0_2::uint128 & x)
|
||||||
|
{
|
||||||
|
transformEndianness<ToEndian, FromEndian>(x.low64);
|
||||||
|
transformEndianness<ToEndian, FromEndian>(x.high64);
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
@ -152,7 +152,7 @@ void ZooKeeper::init(ZooKeeperArgs args_)
|
|||||||
throw KeeperException(code, "/");
|
throw KeeperException(code, "/");
|
||||||
|
|
||||||
if (code == Coordination::Error::ZNONODE)
|
if (code == Coordination::Error::ZNONODE)
|
||||||
throw KeeperException("ZooKeeper root doesn't exist. You should create root node " + args.chroot + " before start.", Coordination::Error::ZNONODE);
|
throw KeeperException(Coordination::Error::ZNONODE, "ZooKeeper root doesn't exist. You should create root node {} before start.", args.chroot);
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
@ -491,7 +491,7 @@ std::string ZooKeeper::get(const std::string & path, Coordination::Stat * stat,
|
|||||||
if (tryGet(path, res, stat, watch, &code))
|
if (tryGet(path, res, stat, watch, &code))
|
||||||
return res;
|
return res;
|
||||||
else
|
else
|
||||||
throw KeeperException("Can't get data for node " + path + ": node doesn't exist", code);
|
throw KeeperException(code, "Can't get data for node '{}': node doesn't exist", path);
|
||||||
}
|
}
|
||||||
|
|
||||||
std::string ZooKeeper::getWatch(const std::string & path, Coordination::Stat * stat, Coordination::WatchCallback watch_callback)
|
std::string ZooKeeper::getWatch(const std::string & path, Coordination::Stat * stat, Coordination::WatchCallback watch_callback)
|
||||||
@ -501,7 +501,7 @@ std::string ZooKeeper::getWatch(const std::string & path, Coordination::Stat * s
|
|||||||
if (tryGetWatch(path, res, stat, watch_callback, &code))
|
if (tryGetWatch(path, res, stat, watch_callback, &code))
|
||||||
return res;
|
return res;
|
||||||
else
|
else
|
||||||
throw KeeperException("Can't get data for node " + path + ": node doesn't exist", code);
|
throw KeeperException(code, "Can't get data for node '{}': node doesn't exist", path);
|
||||||
}
|
}
|
||||||
|
|
||||||
bool ZooKeeper::tryGet(
|
bool ZooKeeper::tryGet(
|
||||||
|
|||||||
@ -213,7 +213,7 @@ void ZooKeeperArgs::initFromKeeperSection(const Poco::Util::AbstractConfiguratio
|
|||||||
};
|
};
|
||||||
}
|
}
|
||||||
else
|
else
|
||||||
throw KeeperException(std::string("Unknown key ") + key + " in config file", Coordination::Error::ZBADARGUMENTS);
|
throw KeeperException(Coordination::Error::ZBADARGUMENTS, "Unknown key {} in config file", key);
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@ -10,6 +10,8 @@
|
|||||||
#include <Formats/ProtobufReader.h>
|
#include <Formats/ProtobufReader.h>
|
||||||
#include <Core/Field.h>
|
#include <Core/Field.h>
|
||||||
|
|
||||||
|
#include <ranges>
|
||||||
|
|
||||||
namespace DB
|
namespace DB
|
||||||
{
|
{
|
||||||
|
|
||||||
@ -135,13 +137,25 @@ template <typename T>
|
|||||||
void SerializationNumber<T>::serializeBinaryBulk(const IColumn & column, WriteBuffer & ostr, size_t offset, size_t limit) const
|
void SerializationNumber<T>::serializeBinaryBulk(const IColumn & column, WriteBuffer & ostr, size_t offset, size_t limit) const
|
||||||
{
|
{
|
||||||
const typename ColumnVector<T>::Container & x = typeid_cast<const ColumnVector<T> &>(column).getData();
|
const typename ColumnVector<T>::Container & x = typeid_cast<const ColumnVector<T> &>(column).getData();
|
||||||
|
if (const size_t size = x.size(); limit == 0 || offset + limit > size)
|
||||||
size_t size = x.size();
|
|
||||||
|
|
||||||
if (limit == 0 || offset + limit > size)
|
|
||||||
limit = size - offset;
|
limit = size - offset;
|
||||||
|
|
||||||
if (limit)
|
if (limit == 0)
|
||||||
|
return;
|
||||||
|
|
||||||
|
if constexpr (std::endian::native == std::endian::big && sizeof(T) >= 2)
|
||||||
|
{
|
||||||
|
static constexpr auto to_little_endian = [](auto i)
|
||||||
|
{
|
||||||
|
transformEndianness<std::endian::little>(i);
|
||||||
|
return i;
|
||||||
|
};
|
||||||
|
|
||||||
|
std::ranges::for_each(
|
||||||
|
x | std::views::drop(offset) | std::views::take(limit) | std::views::transform(to_little_endian),
|
||||||
|
[&ostr](const auto & i) { ostr.write(reinterpret_cast<const char *>(&i), sizeof(typename ColumnVector<T>::ValueType)); });
|
||||||
|
}
|
||||||
|
else
|
||||||
ostr.write(reinterpret_cast<const char *>(&x[offset]), sizeof(typename ColumnVector<T>::ValueType) * limit);
|
ostr.write(reinterpret_cast<const char *>(&x[offset]), sizeof(typename ColumnVector<T>::ValueType) * limit);
|
||||||
}
|
}
|
||||||
|
|
||||||
@ -149,10 +163,13 @@ template <typename T>
|
|||||||
void SerializationNumber<T>::deserializeBinaryBulk(IColumn & column, ReadBuffer & istr, size_t limit, double /*avg_value_size_hint*/) const
|
void SerializationNumber<T>::deserializeBinaryBulk(IColumn & column, ReadBuffer & istr, size_t limit, double /*avg_value_size_hint*/) const
|
||||||
{
|
{
|
||||||
typename ColumnVector<T>::Container & x = typeid_cast<ColumnVector<T> &>(column).getData();
|
typename ColumnVector<T>::Container & x = typeid_cast<ColumnVector<T> &>(column).getData();
|
||||||
size_t initial_size = x.size();
|
const size_t initial_size = x.size();
|
||||||
x.resize(initial_size + limit);
|
x.resize(initial_size + limit);
|
||||||
size_t size = istr.readBig(reinterpret_cast<char*>(&x[initial_size]), sizeof(typename ColumnVector<T>::ValueType) * limit);
|
const size_t size = istr.readBig(reinterpret_cast<char*>(&x[initial_size]), sizeof(typename ColumnVector<T>::ValueType) * limit);
|
||||||
x.resize(initial_size + size / sizeof(typename ColumnVector<T>::ValueType));
|
x.resize(initial_size + size / sizeof(typename ColumnVector<T>::ValueType));
|
||||||
|
|
||||||
|
if constexpr (std::endian::native == std::endian::big && sizeof(T) >= 2)
|
||||||
|
std::ranges::for_each(x | std::views::drop(initial_size), [](auto & i) { transformEndianness<std::endian::big, std::endian::little>(i); });
|
||||||
}
|
}
|
||||||
|
|
||||||
template class SerializationNumber<UInt8>;
|
template class SerializationNumber<UInt8>;
|
||||||
|
|||||||
@ -101,6 +101,7 @@ void registerInputFormatJSONAsObject(FormatFactory & factory);
|
|||||||
void registerInputFormatLineAsString(FormatFactory & factory);
|
void registerInputFormatLineAsString(FormatFactory & factory);
|
||||||
void registerInputFormatMySQLDump(FormatFactory & factory);
|
void registerInputFormatMySQLDump(FormatFactory & factory);
|
||||||
void registerInputFormatParquetMetadata(FormatFactory & factory);
|
void registerInputFormatParquetMetadata(FormatFactory & factory);
|
||||||
|
void registerInputFormatOne(FormatFactory & factory);
|
||||||
|
|
||||||
#if USE_HIVE
|
#if USE_HIVE
|
||||||
void registerInputFormatHiveText(FormatFactory & factory);
|
void registerInputFormatHiveText(FormatFactory & factory);
|
||||||
@ -142,6 +143,7 @@ void registerTemplateSchemaReader(FormatFactory & factory);
|
|||||||
void registerMySQLSchemaReader(FormatFactory & factory);
|
void registerMySQLSchemaReader(FormatFactory & factory);
|
||||||
void registerBSONEachRowSchemaReader(FormatFactory & factory);
|
void registerBSONEachRowSchemaReader(FormatFactory & factory);
|
||||||
void registerParquetMetadataSchemaReader(FormatFactory & factory);
|
void registerParquetMetadataSchemaReader(FormatFactory & factory);
|
||||||
|
void registerOneSchemaReader(FormatFactory & factory);
|
||||||
|
|
||||||
void registerFileExtensions(FormatFactory & factory);
|
void registerFileExtensions(FormatFactory & factory);
|
||||||
|
|
||||||
@ -243,6 +245,7 @@ void registerFormats()
|
|||||||
registerInputFormatMySQLDump(factory);
|
registerInputFormatMySQLDump(factory);
|
||||||
|
|
||||||
registerInputFormatParquetMetadata(factory);
|
registerInputFormatParquetMetadata(factory);
|
||||||
|
registerInputFormatOne(factory);
|
||||||
|
|
||||||
registerNonTrivialPrefixAndSuffixCheckerJSONEachRow(factory);
|
registerNonTrivialPrefixAndSuffixCheckerJSONEachRow(factory);
|
||||||
registerNonTrivialPrefixAndSuffixCheckerJSONAsString(factory);
|
registerNonTrivialPrefixAndSuffixCheckerJSONAsString(factory);
|
||||||
@ -279,6 +282,7 @@ void registerFormats()
|
|||||||
registerMySQLSchemaReader(factory);
|
registerMySQLSchemaReader(factory);
|
||||||
registerBSONEachRowSchemaReader(factory);
|
registerBSONEachRowSchemaReader(factory);
|
||||||
registerParquetMetadataSchemaReader(factory);
|
registerParquetMetadataSchemaReader(factory);
|
||||||
|
registerOneSchemaReader(factory);
|
||||||
}
|
}
|
||||||
|
|
||||||
}
|
}
|
||||||
|
|||||||
@ -1374,8 +1374,8 @@ public:
|
|||||||
|
|
||||||
if constexpr (std::is_same_v<ToType, UInt128>) /// backward-compatible
|
if constexpr (std::is_same_v<ToType, UInt128>) /// backward-compatible
|
||||||
{
|
{
|
||||||
if (std::endian::native == std::endian::big)
|
if constexpr (std::endian::native == std::endian::big)
|
||||||
std::ranges::for_each(col_to->getData(), transformEndianness<std::endian::little, ToType>);
|
std::ranges::for_each(col_to->getData(), transformEndianness<std::endian::little, std::endian::native, ToType>);
|
||||||
|
|
||||||
auto col_to_fixed_string = ColumnFixedString::create(sizeof(UInt128));
|
auto col_to_fixed_string = ColumnFixedString::create(sizeof(UInt128));
|
||||||
const auto & data = col_to->getData();
|
const auto & data = col_to->getData();
|
||||||
|
|||||||
@ -188,7 +188,7 @@ Client::Client(
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
LOG_TRACE(log, "API mode: {}", toString(api_mode));
|
LOG_TRACE(log, "API mode of the S3 client: {}", api_mode);
|
||||||
|
|
||||||
detect_region = provider_type == ProviderType::AWS && explicit_region == Aws::Region::AWS_GLOBAL;
|
detect_region = provider_type == ProviderType::AWS && explicit_region == Aws::Region::AWS_GLOBAL;
|
||||||
|
|
||||||
|
|||||||
@ -60,9 +60,6 @@ public:
|
|||||||
/// (When there is a local replica with big delay).
|
/// (When there is a local replica with big delay).
|
||||||
bool lazy = false;
|
bool lazy = false;
|
||||||
time_t local_delay = 0;
|
time_t local_delay = 0;
|
||||||
|
|
||||||
/// Set only if parallel reading from replicas is used.
|
|
||||||
std::shared_ptr<ParallelReplicasReadingCoordinator> coordinator;
|
|
||||||
};
|
};
|
||||||
|
|
||||||
using Shards = std::vector<Shard>;
|
using Shards = std::vector<Shard>;
|
||||||
|
|||||||
@ -28,7 +28,6 @@ namespace DB
|
|||||||
namespace ErrorCodes
|
namespace ErrorCodes
|
||||||
{
|
{
|
||||||
extern const int TOO_LARGE_DISTRIBUTED_DEPTH;
|
extern const int TOO_LARGE_DISTRIBUTED_DEPTH;
|
||||||
extern const int LOGICAL_ERROR;
|
|
||||||
extern const int SUPPORT_IS_DISABLED;
|
extern const int SUPPORT_IS_DISABLED;
|
||||||
}
|
}
|
||||||
|
|
||||||
@ -281,7 +280,6 @@ void executeQueryWithParallelReplicas(
|
|||||||
auto all_replicas_count = std::min(static_cast<size_t>(settings.max_parallel_replicas), new_cluster->getShardCount());
|
auto all_replicas_count = std::min(static_cast<size_t>(settings.max_parallel_replicas), new_cluster->getShardCount());
|
||||||
auto coordinator = std::make_shared<ParallelReplicasReadingCoordinator>(all_replicas_count);
|
auto coordinator = std::make_shared<ParallelReplicasReadingCoordinator>(all_replicas_count);
|
||||||
auto remote_plan = std::make_unique<QueryPlan>();
|
auto remote_plan = std::make_unique<QueryPlan>();
|
||||||
auto plans = std::vector<QueryPlanPtr>();
|
|
||||||
|
|
||||||
/// This is a little bit weird, but we construct an "empty" coordinator without
|
/// This is a little bit weird, but we construct an "empty" coordinator without
|
||||||
/// any specified reading/coordination method (like Default, InOrder, InReverseOrder)
|
/// any specified reading/coordination method (like Default, InOrder, InReverseOrder)
|
||||||
@ -309,20 +307,7 @@ void executeQueryWithParallelReplicas(
|
|||||||
&Poco::Logger::get("ReadFromParallelRemoteReplicasStep"),
|
&Poco::Logger::get("ReadFromParallelRemoteReplicasStep"),
|
||||||
query_info.storage_limits);
|
query_info.storage_limits);
|
||||||
|
|
||||||
remote_plan->addStep(std::move(read_from_remote));
|
query_plan.addStep(std::move(read_from_remote));
|
||||||
remote_plan->addInterpreterContext(context);
|
|
||||||
plans.emplace_back(std::move(remote_plan));
|
|
||||||
|
|
||||||
if (std::all_of(plans.begin(), plans.end(), [](const QueryPlanPtr & plan) { return !plan; }))
|
|
||||||
throw Exception(ErrorCodes::LOGICAL_ERROR, "No plans were generated for reading from shard. This is a bug");
|
|
||||||
|
|
||||||
DataStreams input_streams;
|
|
||||||
input_streams.reserve(plans.size());
|
|
||||||
for (const auto & plan : plans)
|
|
||||||
input_streams.emplace_back(plan->getCurrentDataStream());
|
|
||||||
|
|
||||||
auto union_step = std::make_unique<UnionStep>(std::move(input_streams));
|
|
||||||
query_plan.unitePlans(std::move(union_step), std::move(plans));
|
|
||||||
}
|
}
|
||||||
|
|
||||||
}
|
}
|
||||||
|
|||||||
@ -184,7 +184,7 @@ InterpreterSelectQueryAnalyzer::InterpreterSelectQueryAnalyzer(
|
|||||||
, context(buildContext(context_, select_query_options_))
|
, context(buildContext(context_, select_query_options_))
|
||||||
, select_query_options(select_query_options_)
|
, select_query_options(select_query_options_)
|
||||||
, query_tree(query_tree_)
|
, query_tree(query_tree_)
|
||||||
, planner(query_tree_, select_query_options_)
|
, planner(query_tree_, select_query_options)
|
||||||
{
|
{
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@ -299,6 +299,7 @@ Session::~Session()
|
|||||||
|
|
||||||
if (notified_session_log_about_login)
|
if (notified_session_log_about_login)
|
||||||
{
|
{
|
||||||
|
LOG_DEBUG(log, "{} Logout, user_id: {}", toString(auth_id), toString(*user_id));
|
||||||
if (auto session_log = getSessionLog())
|
if (auto session_log = getSessionLog())
|
||||||
{
|
{
|
||||||
/// TODO: We have to ensure that the same info is added to the session log on a LoginSuccess event and on the corresponding Logout event.
|
/// TODO: We have to ensure that the same info is added to the session log on a LoginSuccess event and on the corresponding Logout event.
|
||||||
@ -320,6 +321,7 @@ AuthenticationType Session::getAuthenticationTypeOrLogInFailure(const String & u
|
|||||||
}
|
}
|
||||||
catch (const Exception & e)
|
catch (const Exception & e)
|
||||||
{
|
{
|
||||||
|
LOG_ERROR(log, "{} Authentication failed with error: {}", toString(auth_id), e.what());
|
||||||
if (auto session_log = getSessionLog())
|
if (auto session_log = getSessionLog())
|
||||||
session_log->addLoginFailure(auth_id, getClientInfo(), user_name, e);
|
session_log->addLoginFailure(auth_id, getClientInfo(), user_name, e);
|
||||||
|
|
||||||
|
|||||||
@ -45,6 +45,7 @@
|
|||||||
#include <Interpreters/Context.h>
|
#include <Interpreters/Context.h>
|
||||||
#include <Interpreters/InterpreterFactory.h>
|
#include <Interpreters/InterpreterFactory.h>
|
||||||
#include <Interpreters/InterpreterInsertQuery.h>
|
#include <Interpreters/InterpreterInsertQuery.h>
|
||||||
|
#include <Interpreters/InterpreterSelectQueryAnalyzer.h>
|
||||||
#include <Interpreters/InterpreterSetQuery.h>
|
#include <Interpreters/InterpreterSetQuery.h>
|
||||||
#include <Interpreters/InterpreterTransactionControlQuery.h>
|
#include <Interpreters/InterpreterTransactionControlQuery.h>
|
||||||
#include <Interpreters/NormalizeSelectWithUnionQueryVisitor.h>
|
#include <Interpreters/NormalizeSelectWithUnionQueryVisitor.h>
|
||||||
@ -1033,6 +1034,11 @@ static std::tuple<ASTPtr, BlockIO> executeQueryImpl(
|
|||||||
|
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// InterpreterSelectQueryAnalyzer does not build QueryPlan in the constructor.
|
||||||
|
// We need to force to build it here to check if we need to ignore quota.
|
||||||
|
if (auto * interpreter_with_analyzer = dynamic_cast<InterpreterSelectQueryAnalyzer *>(interpreter.get()))
|
||||||
|
interpreter_with_analyzer->getQueryPlan();
|
||||||
|
|
||||||
if (!interpreter->ignoreQuota() && !quota_checked)
|
if (!interpreter->ignoreQuota() && !quota_checked)
|
||||||
{
|
{
|
||||||
quota = context->getQuota();
|
quota = context->getQuota();
|
||||||
|
|||||||
@ -1047,7 +1047,7 @@ PlannerContextPtr buildPlannerContext(const QueryTreeNodePtr & query_tree_node,
|
|||||||
}
|
}
|
||||||
|
|
||||||
Planner::Planner(const QueryTreeNodePtr & query_tree_,
|
Planner::Planner(const QueryTreeNodePtr & query_tree_,
|
||||||
const SelectQueryOptions & select_query_options_)
|
SelectQueryOptions & select_query_options_)
|
||||||
: query_tree(query_tree_)
|
: query_tree(query_tree_)
|
||||||
, select_query_options(select_query_options_)
|
, select_query_options(select_query_options_)
|
||||||
, planner_context(buildPlannerContext(query_tree, select_query_options, std::make_shared<GlobalPlannerContext>()))
|
, planner_context(buildPlannerContext(query_tree, select_query_options, std::make_shared<GlobalPlannerContext>()))
|
||||||
@ -1055,7 +1055,7 @@ Planner::Planner(const QueryTreeNodePtr & query_tree_,
|
|||||||
}
|
}
|
||||||
|
|
||||||
Planner::Planner(const QueryTreeNodePtr & query_tree_,
|
Planner::Planner(const QueryTreeNodePtr & query_tree_,
|
||||||
const SelectQueryOptions & select_query_options_,
|
SelectQueryOptions & select_query_options_,
|
||||||
GlobalPlannerContextPtr global_planner_context_)
|
GlobalPlannerContextPtr global_planner_context_)
|
||||||
: query_tree(query_tree_)
|
: query_tree(query_tree_)
|
||||||
, select_query_options(select_query_options_)
|
, select_query_options(select_query_options_)
|
||||||
@ -1064,7 +1064,7 @@ Planner::Planner(const QueryTreeNodePtr & query_tree_,
|
|||||||
}
|
}
|
||||||
|
|
||||||
Planner::Planner(const QueryTreeNodePtr & query_tree_,
|
Planner::Planner(const QueryTreeNodePtr & query_tree_,
|
||||||
const SelectQueryOptions & select_query_options_,
|
SelectQueryOptions & select_query_options_,
|
||||||
PlannerContextPtr planner_context_)
|
PlannerContextPtr planner_context_)
|
||||||
: query_tree(query_tree_)
|
: query_tree(query_tree_)
|
||||||
, select_query_options(select_query_options_)
|
, select_query_options(select_query_options_)
|
||||||
|
|||||||
@ -22,16 +22,16 @@ class Planner
|
|||||||
public:
|
public:
|
||||||
/// Initialize planner with query tree after analysis phase
|
/// Initialize planner with query tree after analysis phase
|
||||||
Planner(const QueryTreeNodePtr & query_tree_,
|
Planner(const QueryTreeNodePtr & query_tree_,
|
||||||
const SelectQueryOptions & select_query_options_);
|
SelectQueryOptions & select_query_options_);
|
||||||
|
|
||||||
/// Initialize planner with query tree after query analysis phase and global planner context
|
/// Initialize planner with query tree after query analysis phase and global planner context
|
||||||
Planner(const QueryTreeNodePtr & query_tree_,
|
Planner(const QueryTreeNodePtr & query_tree_,
|
||||||
const SelectQueryOptions & select_query_options_,
|
SelectQueryOptions & select_query_options_,
|
||||||
GlobalPlannerContextPtr global_planner_context_);
|
GlobalPlannerContextPtr global_planner_context_);
|
||||||
|
|
||||||
/// Initialize planner with query tree after query analysis phase and planner context
|
/// Initialize planner with query tree after query analysis phase and planner context
|
||||||
Planner(const QueryTreeNodePtr & query_tree_,
|
Planner(const QueryTreeNodePtr & query_tree_,
|
||||||
const SelectQueryOptions & select_query_options_,
|
SelectQueryOptions & select_query_options_,
|
||||||
PlannerContextPtr planner_context_);
|
PlannerContextPtr planner_context_);
|
||||||
|
|
||||||
const QueryPlan & getQueryPlan() const
|
const QueryPlan & getQueryPlan() const
|
||||||
@ -66,7 +66,7 @@ private:
|
|||||||
void buildPlanForQueryNode();
|
void buildPlanForQueryNode();
|
||||||
|
|
||||||
QueryTreeNodePtr query_tree;
|
QueryTreeNodePtr query_tree;
|
||||||
SelectQueryOptions select_query_options;
|
SelectQueryOptions & select_query_options;
|
||||||
PlannerContextPtr planner_context;
|
PlannerContextPtr planner_context;
|
||||||
QueryPlan query_plan;
|
QueryPlan query_plan;
|
||||||
StorageLimitsList storage_limits;
|
StorageLimitsList storage_limits;
|
||||||
|
|||||||
@ -113,6 +113,20 @@ void checkAccessRights(const TableNode & table_node, const Names & column_names,
|
|||||||
query_context->checkAccess(AccessType::SELECT, storage_id, column_names);
|
query_context->checkAccess(AccessType::SELECT, storage_id, column_names);
|
||||||
}
|
}
|
||||||
|
|
||||||
|
bool shouldIgnoreQuotaAndLimits(const TableNode & table_node)
|
||||||
|
{
|
||||||
|
const auto & storage_id = table_node.getStorageID();
|
||||||
|
if (!storage_id.hasDatabase())
|
||||||
|
return false;
|
||||||
|
if (storage_id.database_name == DatabaseCatalog::SYSTEM_DATABASE)
|
||||||
|
{
|
||||||
|
static const boost::container::flat_set<String> tables_ignoring_quota{"quotas", "quota_limits", "quota_usage", "quotas_usage", "one"};
|
||||||
|
if (tables_ignoring_quota.count(storage_id.table_name))
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
|
||||||
NameAndTypePair chooseSmallestColumnToReadFromStorage(const StoragePtr & storage, const StorageSnapshotPtr & storage_snapshot)
|
NameAndTypePair chooseSmallestColumnToReadFromStorage(const StoragePtr & storage, const StorageSnapshotPtr & storage_snapshot)
|
||||||
{
|
{
|
||||||
/** We need to read at least one column to find the number of rows.
|
/** We need to read at least one column to find the number of rows.
|
||||||
@ -828,8 +842,9 @@ JoinTreeQueryPlan buildQueryPlanForTableExpression(QueryTreeNodePtr table_expres
|
|||||||
}
|
}
|
||||||
else
|
else
|
||||||
{
|
{
|
||||||
|
SelectQueryOptions analyze_query_options = SelectQueryOptions(from_stage).analyze();
|
||||||
Planner planner(select_query_info.query_tree,
|
Planner planner(select_query_info.query_tree,
|
||||||
SelectQueryOptions(from_stage).analyze(),
|
analyze_query_options,
|
||||||
select_query_info.planner_context);
|
select_query_info.planner_context);
|
||||||
planner.buildQueryPlanIfNeeded();
|
planner.buildQueryPlanIfNeeded();
|
||||||
|
|
||||||
@ -1375,7 +1390,7 @@ JoinTreeQueryPlan buildQueryPlanForArrayJoinNode(const QueryTreeNodePtr & array_
|
|||||||
|
|
||||||
JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
|
JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
|
||||||
const SelectQueryInfo & select_query_info,
|
const SelectQueryInfo & select_query_info,
|
||||||
const SelectQueryOptions & select_query_options,
|
SelectQueryOptions & select_query_options,
|
||||||
const ColumnIdentifierSet & outer_scope_columns,
|
const ColumnIdentifierSet & outer_scope_columns,
|
||||||
PlannerContextPtr & planner_context)
|
PlannerContextPtr & planner_context)
|
||||||
{
|
{
|
||||||
@ -1386,6 +1401,16 @@ JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
|
|||||||
std::vector<ColumnIdentifierSet> table_expressions_outer_scope_columns(table_expressions_stack_size);
|
std::vector<ColumnIdentifierSet> table_expressions_outer_scope_columns(table_expressions_stack_size);
|
||||||
ColumnIdentifierSet current_outer_scope_columns = outer_scope_columns;
|
ColumnIdentifierSet current_outer_scope_columns = outer_scope_columns;
|
||||||
|
|
||||||
|
if (is_single_table_expression)
|
||||||
|
{
|
||||||
|
auto * table_node = table_expressions_stack[0]->as<TableNode>();
|
||||||
|
if (table_node && shouldIgnoreQuotaAndLimits(*table_node))
|
||||||
|
{
|
||||||
|
select_query_options.ignore_quota = true;
|
||||||
|
select_query_options.ignore_limits = true;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
/// For each table, table function, query, union table expressions prepare before query plan build
|
/// For each table, table function, query, union table expressions prepare before query plan build
|
||||||
for (size_t i = 0; i < table_expressions_stack_size; ++i)
|
for (size_t i = 0; i < table_expressions_stack_size; ++i)
|
||||||
{
|
{
|
||||||
|
|||||||
@ -20,7 +20,7 @@ struct JoinTreeQueryPlan
|
|||||||
/// Build JOIN TREE query plan for query node
|
/// Build JOIN TREE query plan for query node
|
||||||
JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
|
JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
|
||||||
const SelectQueryInfo & select_query_info,
|
const SelectQueryInfo & select_query_info,
|
||||||
const SelectQueryOptions & select_query_options,
|
SelectQueryOptions & select_query_options,
|
||||||
const ColumnIdentifierSet & outer_scope_columns,
|
const ColumnIdentifierSet & outer_scope_columns,
|
||||||
PlannerContextPtr & planner_context);
|
PlannerContextPtr & planner_context);
|
||||||
|
|
||||||
|
|||||||
57
src/Processors/Formats/Impl/OneFormat.cpp
Normal file
57
src/Processors/Formats/Impl/OneFormat.cpp
Normal file
@ -0,0 +1,57 @@
|
|||||||
|
#include <Processors/Formats/Impl/OneFormat.h>
|
||||||
|
#include <Formats/FormatFactory.h>
|
||||||
|
#include <Columns/ColumnsNumber.h>
|
||||||
|
|
||||||
|
namespace DB
|
||||||
|
{
|
||||||
|
|
||||||
|
namespace ErrorCodes
|
||||||
|
{
|
||||||
|
extern const int BAD_ARGUMENTS;
|
||||||
|
}
|
||||||
|
|
||||||
|
OneInputFormat::OneInputFormat(const Block & header, ReadBuffer & in_) : IInputFormat(header, &in_)
|
||||||
|
{
|
||||||
|
if (header.columns() != 1)
|
||||||
|
throw Exception(ErrorCodes::BAD_ARGUMENTS,
|
||||||
|
"One input format is only suitable for tables with a single column of type UInt8 but the number of columns is {}",
|
||||||
|
header.columns());
|
||||||
|
|
||||||
|
if (!WhichDataType(header.getByPosition(0).type).isUInt8())
|
||||||
|
throw Exception(ErrorCodes::BAD_ARGUMENTS,
|
||||||
|
"One input format is only suitable for tables with a single column of type String but the column type is {}",
|
||||||
|
header.getByPosition(0).type->getName());
|
||||||
|
}
|
||||||
|
|
||||||
|
Chunk OneInputFormat::generate()
|
||||||
|
{
|
||||||
|
if (done)
|
||||||
|
return {};
|
||||||
|
|
||||||
|
done = true;
|
||||||
|
auto column = ColumnUInt8::create();
|
||||||
|
column->insertDefault();
|
||||||
|
return Chunk(Columns{std::move(column)}, 1);
|
||||||
|
}
|
||||||
|
|
||||||
|
void registerInputFormatOne(FormatFactory & factory)
|
||||||
|
{
|
||||||
|
factory.registerInputFormat("One", [](
|
||||||
|
ReadBuffer & buf,
|
||||||
|
const Block & sample,
|
||||||
|
const RowInputFormatParams &,
|
||||||
|
const FormatSettings &)
|
||||||
|
{
|
||||||
|
return std::make_shared<OneInputFormat>(sample, buf);
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
void registerOneSchemaReader(FormatFactory & factory)
|
||||||
|
{
|
||||||
|
factory.registerExternalSchemaReader("One", [](const FormatSettings &)
|
||||||
|
{
|
||||||
|
return std::make_shared<OneSchemaReader>();
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
32
src/Processors/Formats/Impl/OneFormat.h
Normal file
32
src/Processors/Formats/Impl/OneFormat.h
Normal file
@ -0,0 +1,32 @@
|
|||||||
|
#pragma once
|
||||||
|
#include <Processors/Formats/IInputFormat.h>
|
||||||
|
#include <Processors/Formats/ISchemaReader.h>
|
||||||
|
#include <DataTypes/DataTypesNumber.h>
|
||||||
|
|
||||||
|
namespace DB
|
||||||
|
{
|
||||||
|
|
||||||
|
class OneInputFormat final : public IInputFormat
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
OneInputFormat(const Block & header, ReadBuffer & in_);
|
||||||
|
|
||||||
|
String getName() const override { return "One"; }
|
||||||
|
|
||||||
|
protected:
|
||||||
|
Chunk generate() override;
|
||||||
|
|
||||||
|
private:
|
||||||
|
bool done = false;
|
||||||
|
};
|
||||||
|
|
||||||
|
class OneSchemaReader: public IExternalSchemaReader
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
NamesAndTypesList readSchema() override
|
||||||
|
{
|
||||||
|
return {{"dummy", std::make_shared<DataTypeUInt8>()}};
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|
||||||
|
}
|
||||||
@ -8435,7 +8435,7 @@ void MergeTreeData::incrementMergedPartsProfileEvent(MergeTreeDataPartType type)
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
MergeTreeData::MutableDataPartPtr MergeTreeData::createEmptyPart(
|
std::pair<MergeTreeData::MutableDataPartPtr, scope_guard> MergeTreeData::createEmptyPart(
|
||||||
MergeTreePartInfo & new_part_info, const MergeTreePartition & partition, const String & new_part_name,
|
MergeTreePartInfo & new_part_info, const MergeTreePartition & partition, const String & new_part_name,
|
||||||
const MergeTreeTransactionPtr & txn)
|
const MergeTreeTransactionPtr & txn)
|
||||||
{
|
{
|
||||||
@ -8454,6 +8454,7 @@ MergeTreeData::MutableDataPartPtr MergeTreeData::createEmptyPart(
|
|||||||
ReservationPtr reservation = reserveSpacePreferringTTLRules(metadata_snapshot, 0, move_ttl_infos, time(nullptr), 0, true);
|
ReservationPtr reservation = reserveSpacePreferringTTLRules(metadata_snapshot, 0, move_ttl_infos, time(nullptr), 0, true);
|
||||||
VolumePtr data_part_volume = createVolumeFromReservation(reservation, volume);
|
VolumePtr data_part_volume = createVolumeFromReservation(reservation, volume);
|
||||||
|
|
||||||
|
auto tmp_dir_holder = getTemporaryPartDirectoryHolder(EMPTY_PART_TMP_PREFIX + new_part_name);
|
||||||
auto new_data_part = getDataPartBuilder(new_part_name, data_part_volume, EMPTY_PART_TMP_PREFIX + new_part_name)
|
auto new_data_part = getDataPartBuilder(new_part_name, data_part_volume, EMPTY_PART_TMP_PREFIX + new_part_name)
|
||||||
.withBytesAndRowsOnDisk(0, 0)
|
.withBytesAndRowsOnDisk(0, 0)
|
||||||
.withPartInfo(new_part_info)
|
.withPartInfo(new_part_info)
|
||||||
@ -8513,7 +8514,7 @@ MergeTreeData::MutableDataPartPtr MergeTreeData::createEmptyPart(
|
|||||||
out.finalizePart(new_data_part, sync_on_insert);
|
out.finalizePart(new_data_part, sync_on_insert);
|
||||||
|
|
||||||
new_data_part_storage->precommitTransaction();
|
new_data_part_storage->precommitTransaction();
|
||||||
return new_data_part;
|
return std::make_pair(std::move(new_data_part), std::move(tmp_dir_holder));
|
||||||
}
|
}
|
||||||
|
|
||||||
bool MergeTreeData::allowRemoveStaleMovingParts() const
|
bool MergeTreeData::allowRemoveStaleMovingParts() const
|
||||||
|
|||||||
@ -936,7 +936,9 @@ public:
|
|||||||
WriteAheadLogPtr getWriteAheadLog();
|
WriteAheadLogPtr getWriteAheadLog();
|
||||||
|
|
||||||
constexpr static auto EMPTY_PART_TMP_PREFIX = "tmp_empty_";
|
constexpr static auto EMPTY_PART_TMP_PREFIX = "tmp_empty_";
|
||||||
MergeTreeData::MutableDataPartPtr createEmptyPart(MergeTreePartInfo & new_part_info, const MergeTreePartition & partition, const String & new_part_name, const MergeTreeTransactionPtr & txn);
|
std::pair<MergeTreeData::MutableDataPartPtr, scope_guard> createEmptyPart(
|
||||||
|
MergeTreePartInfo & new_part_info, const MergeTreePartition & partition,
|
||||||
|
const String & new_part_name, const MergeTreeTransactionPtr & txn);
|
||||||
|
|
||||||
MergeTreeDataFormatVersion format_version;
|
MergeTreeDataFormatVersion format_version;
|
||||||
|
|
||||||
|
|||||||
@ -187,15 +187,15 @@ bool MergeTreeDataPartChecksums::readV3(ReadBuffer & in)
|
|||||||
String name;
|
String name;
|
||||||
Checksum sum;
|
Checksum sum;
|
||||||
|
|
||||||
readBinary(name, in);
|
readStringBinary(name, in);
|
||||||
readVarUInt(sum.file_size, in);
|
readVarUInt(sum.file_size, in);
|
||||||
readPODBinary(sum.file_hash, in);
|
readBinaryLittleEndian(sum.file_hash, in);
|
||||||
readBinary(sum.is_compressed, in);
|
readBinaryLittleEndian(sum.is_compressed, in);
|
||||||
|
|
||||||
if (sum.is_compressed)
|
if (sum.is_compressed)
|
||||||
{
|
{
|
||||||
readVarUInt(sum.uncompressed_size, in);
|
readVarUInt(sum.uncompressed_size, in);
|
||||||
readPODBinary(sum.uncompressed_hash, in);
|
readBinaryLittleEndian(sum.uncompressed_hash, in);
|
||||||
}
|
}
|
||||||
|
|
||||||
files.emplace(std::move(name), sum);
|
files.emplace(std::move(name), sum);
|
||||||
@ -223,15 +223,15 @@ void MergeTreeDataPartChecksums::write(WriteBuffer & to) const
|
|||||||
const String & name = it.first;
|
const String & name = it.first;
|
||||||
const Checksum & sum = it.second;
|
const Checksum & sum = it.second;
|
||||||
|
|
||||||
writeBinary(name, out);
|
writeStringBinary(name, out);
|
||||||
writeVarUInt(sum.file_size, out);
|
writeVarUInt(sum.file_size, out);
|
||||||
writePODBinary(sum.file_hash, out);
|
writeBinaryLittleEndian(sum.file_hash, out);
|
||||||
writeBinary(sum.is_compressed, out);
|
writeBinaryLittleEndian(sum.is_compressed, out);
|
||||||
|
|
||||||
if (sum.is_compressed)
|
if (sum.is_compressed)
|
||||||
{
|
{
|
||||||
writeVarUInt(sum.uncompressed_size, out);
|
writeVarUInt(sum.uncompressed_size, out);
|
||||||
writePODBinary(sum.uncompressed_hash, out);
|
writeBinaryLittleEndian(sum.uncompressed_hash, out);
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@ -339,9 +339,9 @@ void MinimalisticDataPartChecksums::serializeWithoutHeader(WriteBuffer & to) con
|
|||||||
writeVarUInt(num_compressed_files, to);
|
writeVarUInt(num_compressed_files, to);
|
||||||
writeVarUInt(num_uncompressed_files, to);
|
writeVarUInt(num_uncompressed_files, to);
|
||||||
|
|
||||||
writePODBinary(hash_of_all_files, to);
|
writeBinaryLittleEndian(hash_of_all_files, to);
|
||||||
writePODBinary(hash_of_uncompressed_files, to);
|
writeBinaryLittleEndian(hash_of_uncompressed_files, to);
|
||||||
writePODBinary(uncompressed_hash_of_compressed_files, to);
|
writeBinaryLittleEndian(uncompressed_hash_of_compressed_files, to);
|
||||||
}
|
}
|
||||||
|
|
||||||
String MinimalisticDataPartChecksums::getSerializedString() const
|
String MinimalisticDataPartChecksums::getSerializedString() const
|
||||||
@ -382,9 +382,9 @@ void MinimalisticDataPartChecksums::deserializeWithoutHeader(ReadBuffer & in)
|
|||||||
readVarUInt(num_compressed_files, in);
|
readVarUInt(num_compressed_files, in);
|
||||||
readVarUInt(num_uncompressed_files, in);
|
readVarUInt(num_uncompressed_files, in);
|
||||||
|
|
||||||
readPODBinary(hash_of_all_files, in);
|
readBinaryLittleEndian(hash_of_all_files, in);
|
||||||
readPODBinary(hash_of_uncompressed_files, in);
|
readBinaryLittleEndian(hash_of_uncompressed_files, in);
|
||||||
readPODBinary(uncompressed_hash_of_compressed_files, in);
|
readBinaryLittleEndian(uncompressed_hash_of_compressed_files, in);
|
||||||
}
|
}
|
||||||
|
|
||||||
void MinimalisticDataPartChecksums::computeTotalChecksums(const MergeTreeDataPartChecksums & full_checksums_)
|
void MinimalisticDataPartChecksums::computeTotalChecksums(const MergeTreeDataPartChecksums & full_checksums_)
|
||||||
|
|||||||
@ -365,8 +365,9 @@ void MergeTreeDataPartWriterCompact::addToChecksums(MergeTreeDataPartChecksums &
|
|||||||
{
|
{
|
||||||
uncompressed_size += stream->hashing_buf.count();
|
uncompressed_size += stream->hashing_buf.count();
|
||||||
auto stream_hash = stream->hashing_buf.getHash();
|
auto stream_hash = stream->hashing_buf.getHash();
|
||||||
|
transformEndianness<std::endian::little>(stream_hash);
|
||||||
uncompressed_hash = CityHash_v1_0_2::CityHash128WithSeed(
|
uncompressed_hash = CityHash_v1_0_2::CityHash128WithSeed(
|
||||||
reinterpret_cast<char *>(&stream_hash), sizeof(stream_hash), uncompressed_hash);
|
reinterpret_cast<const char *>(&stream_hash), sizeof(stream_hash), uncompressed_hash);
|
||||||
}
|
}
|
||||||
|
|
||||||
checksums.files[data_file_name].is_compressed = true;
|
checksums.files[data_file_name].is_compressed = true;
|
||||||
|
|||||||
@ -691,7 +691,11 @@ QueryTreeNodePtr buildQueryTreeDistributed(SelectQueryInfo & query_info,
|
|||||||
if (remote_storage_id.hasDatabase())
|
if (remote_storage_id.hasDatabase())
|
||||||
resolved_remote_storage_id = query_context->resolveStorageID(remote_storage_id);
|
resolved_remote_storage_id = query_context->resolveStorageID(remote_storage_id);
|
||||||
|
|
||||||
auto storage = std::make_shared<StorageDummy>(resolved_remote_storage_id, distributed_storage_snapshot->metadata->getColumns(), distributed_storage_snapshot->object_columns);
|
auto get_column_options = GetColumnsOptions(GetColumnsOptions::All).withExtendedObjects().withVirtuals();
|
||||||
|
|
||||||
|
auto column_names_and_types = distributed_storage_snapshot->getColumns(get_column_options);
|
||||||
|
|
||||||
|
auto storage = std::make_shared<StorageDummy>(resolved_remote_storage_id, ColumnsDescription{column_names_and_types});
|
||||||
auto table_node = std::make_shared<TableNode>(std::move(storage), query_context);
|
auto table_node = std::make_shared<TableNode>(std::move(storage), query_context);
|
||||||
|
|
||||||
if (table_expression_modifiers)
|
if (table_expression_modifiers)
|
||||||
|
|||||||
@ -1653,11 +1653,7 @@ struct FutureNewEmptyPart
|
|||||||
MergeTreePartition partition;
|
MergeTreePartition partition;
|
||||||
std::string part_name;
|
std::string part_name;
|
||||||
|
|
||||||
scope_guard tmp_dir_guard;
|
|
||||||
|
|
||||||
StorageMergeTree::MutableDataPartPtr data_part;
|
StorageMergeTree::MutableDataPartPtr data_part;
|
||||||
|
|
||||||
std::string getDirName() const { return StorageMergeTree::EMPTY_PART_TMP_PREFIX + part_name; }
|
|
||||||
};
|
};
|
||||||
|
|
||||||
using FutureNewEmptyParts = std::vector<FutureNewEmptyPart>;
|
using FutureNewEmptyParts = std::vector<FutureNewEmptyPart>;
|
||||||
@ -1688,19 +1684,19 @@ FutureNewEmptyParts initCoverageWithNewEmptyParts(const DataPartsVector & old_pa
|
|||||||
return future_parts;
|
return future_parts;
|
||||||
}
|
}
|
||||||
|
|
||||||
StorageMergeTree::MutableDataPartsVector createEmptyDataParts(MergeTreeData & data, FutureNewEmptyParts & future_parts, const MergeTreeTransactionPtr & txn)
|
std::pair<StorageMergeTree::MutableDataPartsVector, std::vector<scope_guard>> createEmptyDataParts(
|
||||||
|
MergeTreeData & data, FutureNewEmptyParts & future_parts, const MergeTreeTransactionPtr & txn)
|
||||||
{
|
{
|
||||||
StorageMergeTree::MutableDataPartsVector data_parts;
|
std::pair<StorageMergeTree::MutableDataPartsVector, std::vector<scope_guard>> data_parts;
|
||||||
for (auto & part: future_parts)
|
for (auto & part: future_parts)
|
||||||
data_parts.push_back(data.createEmptyPart(part.part_info, part.partition, part.part_name, txn));
|
{
|
||||||
|
auto [new_data_part, tmp_dir_holder] = data.createEmptyPart(part.part_info, part.partition, part.part_name, txn);
|
||||||
|
data_parts.first.emplace_back(std::move(new_data_part));
|
||||||
|
data_parts.second.emplace_back(std::move(tmp_dir_holder));
|
||||||
|
}
|
||||||
return data_parts;
|
return data_parts;
|
||||||
}
|
}
|
||||||
|
|
||||||
void captureTmpDirectoryHolders(MergeTreeData & data, FutureNewEmptyParts & future_parts)
|
|
||||||
{
|
|
||||||
for (auto & part : future_parts)
|
|
||||||
part.tmp_dir_guard = data.getTemporaryPartDirectoryHolder(part.getDirName());
|
|
||||||
}
|
|
||||||
|
|
||||||
void StorageMergeTree::renameAndCommitEmptyParts(MutableDataPartsVector & new_parts, Transaction & transaction)
|
void StorageMergeTree::renameAndCommitEmptyParts(MutableDataPartsVector & new_parts, Transaction & transaction)
|
||||||
{
|
{
|
||||||
@ -1767,9 +1763,7 @@ void StorageMergeTree::truncate(const ASTPtr &, const StorageMetadataPtr &, Cont
|
|||||||
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames(parts), ", "),
|
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames(parts), ", "),
|
||||||
transaction.getTID());
|
transaction.getTID());
|
||||||
|
|
||||||
captureTmpDirectoryHolders(*this, future_parts);
|
auto [new_data_parts, tmp_dir_holders] = createEmptyDataParts(*this, future_parts, txn);
|
||||||
|
|
||||||
auto new_data_parts = createEmptyDataParts(*this, future_parts, txn);
|
|
||||||
renameAndCommitEmptyParts(new_data_parts, transaction);
|
renameAndCommitEmptyParts(new_data_parts, transaction);
|
||||||
|
|
||||||
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
|
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
|
||||||
@ -1828,9 +1822,7 @@ void StorageMergeTree::dropPart(const String & part_name, bool detach, ContextPt
|
|||||||
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames({part}), ", "),
|
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames({part}), ", "),
|
||||||
transaction.getTID());
|
transaction.getTID());
|
||||||
|
|
||||||
captureTmpDirectoryHolders(*this, future_parts);
|
auto [new_data_parts, tmp_dir_holders] = createEmptyDataParts(*this, future_parts, txn);
|
||||||
|
|
||||||
auto new_data_parts = createEmptyDataParts(*this, future_parts, txn);
|
|
||||||
renameAndCommitEmptyParts(new_data_parts, transaction);
|
renameAndCommitEmptyParts(new_data_parts, transaction);
|
||||||
|
|
||||||
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
|
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
|
||||||
@ -1914,9 +1906,8 @@ void StorageMergeTree::dropPartition(const ASTPtr & partition, bool detach, Cont
|
|||||||
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames(parts), ", "),
|
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames(parts), ", "),
|
||||||
transaction.getTID());
|
transaction.getTID());
|
||||||
|
|
||||||
captureTmpDirectoryHolders(*this, future_parts);
|
|
||||||
|
|
||||||
auto new_data_parts = createEmptyDataParts(*this, future_parts, txn);
|
auto [new_data_parts, tmp_dir_holders] = createEmptyDataParts(*this, future_parts, txn);
|
||||||
renameAndCommitEmptyParts(new_data_parts, transaction);
|
renameAndCommitEmptyParts(new_data_parts, transaction);
|
||||||
|
|
||||||
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
|
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
|
||||||
|
|||||||
@ -9509,7 +9509,7 @@ bool StorageReplicatedMergeTree::createEmptyPartInsteadOfLost(zkutil::ZooKeeperP
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
MergeTreeData::MutableDataPartPtr new_data_part = createEmptyPart(new_part_info, partition, lost_part_name, NO_TRANSACTION_PTR);
|
auto [new_data_part, tmp_dir_holder] = createEmptyPart(new_part_info, partition, lost_part_name, NO_TRANSACTION_PTR);
|
||||||
new_data_part->setName(lost_part_name);
|
new_data_part->setName(lost_part_name);
|
||||||
|
|
||||||
try
|
try
|
||||||
|
|||||||
@ -108,6 +108,22 @@ static ColumnPtr getFilteredTables(const ASTPtr & query, const ColumnPtr & filte
|
|||||||
return block.getByPosition(0).column;
|
return block.getByPosition(0).column;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
/// Avoid heavy operation on tables if we only queried columns that we can get without table object.
|
||||||
|
/// Otherwise it will require table initialization for Lazy database.
|
||||||
|
static bool needTable(const DatabasePtr & database, const Block & header)
|
||||||
|
{
|
||||||
|
if (database->getEngineName() != "Lazy")
|
||||||
|
return true;
|
||||||
|
|
||||||
|
static const std::set<std::string> columns_without_table = { "database", "name", "uuid", "metadata_modification_time" };
|
||||||
|
for (const auto & column : header.getColumnsWithTypeAndName())
|
||||||
|
{
|
||||||
|
if (columns_without_table.find(column.name) == columns_without_table.end())
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
class TablesBlockSource : public ISource
|
class TablesBlockSource : public ISource
|
||||||
{
|
{
|
||||||
@ -266,6 +282,8 @@ protected:
|
|||||||
if (!tables_it || !tables_it->isValid())
|
if (!tables_it || !tables_it->isValid())
|
||||||
tables_it = database->getTablesIterator(context);
|
tables_it = database->getTablesIterator(context);
|
||||||
|
|
||||||
|
const bool need_table = needTable(database, getPort().getHeader());
|
||||||
|
|
||||||
for (; rows_count < max_block_size && tables_it->isValid(); tables_it->next())
|
for (; rows_count < max_block_size && tables_it->isValid(); tables_it->next())
|
||||||
{
|
{
|
||||||
auto table_name = tables_it->name();
|
auto table_name = tables_it->name();
|
||||||
@ -275,23 +293,27 @@ protected:
|
|||||||
if (check_access_for_tables && !access->isGranted(AccessType::SHOW_TABLES, database_name, table_name))
|
if (check_access_for_tables && !access->isGranted(AccessType::SHOW_TABLES, database_name, table_name))
|
||||||
continue;
|
continue;
|
||||||
|
|
||||||
StoragePtr table = tables_it->table();
|
StoragePtr table = nullptr;
|
||||||
if (!table)
|
|
||||||
// Table might have just been removed or detached for Lazy engine (see DatabaseLazy::tryGetTable())
|
|
||||||
continue;
|
|
||||||
|
|
||||||
TableLockHolder lock;
|
TableLockHolder lock;
|
||||||
/// The only column that requires us to hold a shared lock is data_paths as rename might alter them (on ordinary tables)
|
if (need_table)
|
||||||
/// and it's not protected internally by other mutexes
|
|
||||||
static const size_t DATA_PATHS_INDEX = 5;
|
|
||||||
if (columns_mask[DATA_PATHS_INDEX])
|
|
||||||
{
|
{
|
||||||
lock = table->tryLockForShare(context->getCurrentQueryId(), context->getSettingsRef().lock_acquire_timeout);
|
table = tables_it->table();
|
||||||
if (!lock)
|
if (!table)
|
||||||
// Table was dropped while acquiring the lock, skipping table
|
// Table might have just been removed or detached for Lazy engine (see DatabaseLazy::tryGetTable())
|
||||||
continue;
|
continue;
|
||||||
}
|
|
||||||
|
|
||||||
|
/// The only column that requires us to hold a shared lock is data_paths as rename might alter them (on ordinary tables)
|
||||||
|
/// and it's not protected internally by other mutexes
|
||||||
|
static const size_t DATA_PATHS_INDEX = 5;
|
||||||
|
if (columns_mask[DATA_PATHS_INDEX])
|
||||||
|
{
|
||||||
|
lock = table->tryLockForShare(context->getCurrentQueryId(),
|
||||||
|
context->getSettingsRef().lock_acquire_timeout);
|
||||||
|
if (!lock)
|
||||||
|
// Table was dropped while acquiring the lock, skipping table
|
||||||
|
continue;
|
||||||
|
}
|
||||||
|
}
|
||||||
++rows_count;
|
++rows_count;
|
||||||
|
|
||||||
size_t src_index = 0;
|
size_t src_index = 0;
|
||||||
@ -308,6 +330,7 @@ protected:
|
|||||||
|
|
||||||
if (columns_mask[src_index++])
|
if (columns_mask[src_index++])
|
||||||
{
|
{
|
||||||
|
chassert(table != nullptr);
|
||||||
res_columns[res_index++]->insert(table->getName());
|
res_columns[res_index++]->insert(table->getName());
|
||||||
}
|
}
|
||||||
|
|
||||||
@ -397,7 +420,9 @@ protected:
|
|||||||
else
|
else
|
||||||
src_index += 3;
|
src_index += 3;
|
||||||
|
|
||||||
StorageMetadataPtr metadata_snapshot = table->getInMemoryMetadataPtr();
|
StorageMetadataPtr metadata_snapshot;
|
||||||
|
if (table)
|
||||||
|
metadata_snapshot = table->getInMemoryMetadataPtr();
|
||||||
|
|
||||||
ASTPtr expression_ptr;
|
ASTPtr expression_ptr;
|
||||||
if (columns_mask[src_index++])
|
if (columns_mask[src_index++])
|
||||||
@ -434,7 +459,7 @@ protected:
|
|||||||
|
|
||||||
if (columns_mask[src_index++])
|
if (columns_mask[src_index++])
|
||||||
{
|
{
|
||||||
auto policy = table->getStoragePolicy();
|
auto policy = table ? table->getStoragePolicy() : nullptr;
|
||||||
if (policy)
|
if (policy)
|
||||||
res_columns[res_index++]->insert(policy->getName());
|
res_columns[res_index++]->insert(policy->getName());
|
||||||
else
|
else
|
||||||
@ -445,7 +470,7 @@ protected:
|
|||||||
settings.select_sequential_consistency = 0;
|
settings.select_sequential_consistency = 0;
|
||||||
if (columns_mask[src_index++])
|
if (columns_mask[src_index++])
|
||||||
{
|
{
|
||||||
auto total_rows = table->totalRows(settings);
|
auto total_rows = table ? table->totalRows(settings) : std::nullopt;
|
||||||
if (total_rows)
|
if (total_rows)
|
||||||
res_columns[res_index++]->insert(*total_rows);
|
res_columns[res_index++]->insert(*total_rows);
|
||||||
else
|
else
|
||||||
@ -490,7 +515,7 @@ protected:
|
|||||||
|
|
||||||
if (columns_mask[src_index++])
|
if (columns_mask[src_index++])
|
||||||
{
|
{
|
||||||
auto lifetime_rows = table->lifetimeRows();
|
auto lifetime_rows = table ? table->lifetimeRows() : std::nullopt;
|
||||||
if (lifetime_rows)
|
if (lifetime_rows)
|
||||||
res_columns[res_index++]->insert(*lifetime_rows);
|
res_columns[res_index++]->insert(*lifetime_rows);
|
||||||
else
|
else
|
||||||
@ -499,7 +524,7 @@ protected:
|
|||||||
|
|
||||||
if (columns_mask[src_index++])
|
if (columns_mask[src_index++])
|
||||||
{
|
{
|
||||||
auto lifetime_bytes = table->lifetimeBytes();
|
auto lifetime_bytes = table ? table->lifetimeBytes() : std::nullopt;
|
||||||
if (lifetime_bytes)
|
if (lifetime_bytes)
|
||||||
res_columns[res_index++]->insert(*lifetime_bytes);
|
res_columns[res_index++]->insert(*lifetime_bytes);
|
||||||
else
|
else
|
||||||
|
|||||||
@ -96,22 +96,6 @@ test_executable_table_function/test.py::test_executable_function_input_python
|
|||||||
test_settings_profile/test.py::test_show_profiles
|
test_settings_profile/test.py::test_show_profiles
|
||||||
test_sql_user_defined_functions_on_cluster/test.py::test_sql_user_defined_functions_on_cluster
|
test_sql_user_defined_functions_on_cluster/test.py::test_sql_user_defined_functions_on_cluster
|
||||||
test_postgresql_protocol/test.py::test_python_client
|
test_postgresql_protocol/test.py::test_python_client
|
||||||
test_quota/test.py::test_add_remove_interval
|
|
||||||
test_quota/test.py::test_add_remove_quota
|
|
||||||
test_quota/test.py::test_consumption_of_show_clusters
|
|
||||||
test_quota/test.py::test_consumption_of_show_databases
|
|
||||||
test_quota/test.py::test_consumption_of_show_privileges
|
|
||||||
test_quota/test.py::test_consumption_of_show_processlist
|
|
||||||
test_quota/test.py::test_consumption_of_show_tables
|
|
||||||
test_quota/test.py::test_dcl_introspection
|
|
||||||
test_quota/test.py::test_dcl_management
|
|
||||||
test_quota/test.py::test_exceed_quota
|
|
||||||
test_quota/test.py::test_query_inserts
|
|
||||||
test_quota/test.py::test_quota_from_users_xml
|
|
||||||
test_quota/test.py::test_reload_users_xml_by_timer
|
|
||||||
test_quota/test.py::test_simpliest_quota
|
|
||||||
test_quota/test.py::test_tracking_quota
|
|
||||||
test_quota/test.py::test_users_xml_is_readonly
|
|
||||||
test_mysql_database_engine/test.py::test_mysql_ddl_for_mysql_database
|
test_mysql_database_engine/test.py::test_mysql_ddl_for_mysql_database
|
||||||
test_profile_events_s3/test.py::test_profile_events
|
test_profile_events_s3/test.py::test_profile_events
|
||||||
test_user_defined_object_persistence/test.py::test_persistence
|
test_user_defined_object_persistence/test.py::test_persistence
|
||||||
@ -121,22 +105,6 @@ test_select_access_rights/test_main.py::test_alias_columns
|
|||||||
test_select_access_rights/test_main.py::test_select_count
|
test_select_access_rights/test_main.py::test_select_count
|
||||||
test_select_access_rights/test_main.py::test_select_join
|
test_select_access_rights/test_main.py::test_select_join
|
||||||
test_postgresql_protocol/test.py::test_python_client
|
test_postgresql_protocol/test.py::test_python_client
|
||||||
test_quota/test.py::test_add_remove_interval
|
|
||||||
test_quota/test.py::test_add_remove_quota
|
|
||||||
test_quota/test.py::test_consumption_of_show_clusters
|
|
||||||
test_quota/test.py::test_consumption_of_show_databases
|
|
||||||
test_quota/test.py::test_consumption_of_show_privileges
|
|
||||||
test_quota/test.py::test_consumption_of_show_processlist
|
|
||||||
test_quota/test.py::test_consumption_of_show_tables
|
|
||||||
test_quota/test.py::test_dcl_introspection
|
|
||||||
test_quota/test.py::test_dcl_management
|
|
||||||
test_quota/test.py::test_exceed_quota
|
|
||||||
test_quota/test.py::test_query_inserts
|
|
||||||
test_quota/test.py::test_quota_from_users_xml
|
|
||||||
test_quota/test.py::test_reload_users_xml_by_timer
|
|
||||||
test_quota/test.py::test_simpliest_quota
|
|
||||||
test_quota/test.py::test_tracking_quota
|
|
||||||
test_quota/test.py::test_users_xml_is_readonly
|
|
||||||
test_replicating_constants/test.py::test_different_versions
|
test_replicating_constants/test.py::test_different_versions
|
||||||
test_merge_tree_s3/test.py::test_heavy_insert_select_check_memory[node]
|
test_merge_tree_s3/test.py::test_heavy_insert_select_check_memory[node]
|
||||||
test_wrong_db_or_table_name/test.py::test_wrong_table_name
|
test_wrong_db_or_table_name/test.py::test_wrong_table_name
|
||||||
|
|||||||
@ -8,7 +8,11 @@ import sys
|
|||||||
from github import Github
|
from github import Github
|
||||||
|
|
||||||
from build_download_helper import get_build_name_for_check, read_build_urls
|
from build_download_helper import get_build_name_for_check, read_build_urls
|
||||||
from clickhouse_helper import ClickHouseHelper, prepare_tests_results_for_clickhouse
|
from clickhouse_helper import (
|
||||||
|
ClickHouseHelper,
|
||||||
|
prepare_tests_results_for_clickhouse,
|
||||||
|
get_instance_type,
|
||||||
|
)
|
||||||
from commit_status_helper import (
|
from commit_status_helper import (
|
||||||
RerunHelper,
|
RerunHelper,
|
||||||
format_description,
|
format_description,
|
||||||
@ -30,15 +34,32 @@ from stopwatch import Stopwatch
|
|||||||
IMAGE_NAME = "clickhouse/fuzzer"
|
IMAGE_NAME = "clickhouse/fuzzer"
|
||||||
|
|
||||||
|
|
||||||
def get_run_command(pr_number, sha, download_url, workspace_path, image):
|
def get_run_command(
|
||||||
|
check_start_time, check_name, pr_number, sha, download_url, workspace_path, image
|
||||||
|
):
|
||||||
|
instance_type = get_instance_type()
|
||||||
|
|
||||||
|
envs = [
|
||||||
|
"-e CLICKHOUSE_CI_LOGS_HOST",
|
||||||
|
"-e CLICKHOUSE_CI_LOGS_PASSWORD",
|
||||||
|
f"-e CHECK_START_TIME='{check_start_time}'",
|
||||||
|
f"-e CHECK_NAME='{check_name}'",
|
||||||
|
f"-e INSTANCE_TYPE='{instance_type}'",
|
||||||
|
f"-e PR_TO_TEST={pr_number}",
|
||||||
|
f"-e SHA_TO_TEST={sha}",
|
||||||
|
f"-e BINARY_URL_TO_DOWNLOAD='{download_url}'",
|
||||||
|
]
|
||||||
|
|
||||||
|
env_str = " ".join(envs)
|
||||||
|
|
||||||
return (
|
return (
|
||||||
f"docker run "
|
f"docker run "
|
||||||
# For sysctl
|
# For sysctl
|
||||||
"--privileged "
|
"--privileged "
|
||||||
"--network=host "
|
"--network=host "
|
||||||
f"--volume={workspace_path}:/workspace "
|
f"--volume={workspace_path}:/workspace "
|
||||||
|
f"{env_str} "
|
||||||
"--cap-add syslog --cap-add sys_admin --cap-add=SYS_PTRACE "
|
"--cap-add syslog --cap-add sys_admin --cap-add=SYS_PTRACE "
|
||||||
f'-e PR_TO_TEST={pr_number} -e SHA_TO_TEST={sha} -e BINARY_URL_TO_DOWNLOAD="{download_url}" '
|
|
||||||
f"{image}"
|
f"{image}"
|
||||||
)
|
)
|
||||||
|
|
||||||
@ -88,11 +109,19 @@ def main():
|
|||||||
os.makedirs(workspace_path)
|
os.makedirs(workspace_path)
|
||||||
|
|
||||||
run_command = get_run_command(
|
run_command = get_run_command(
|
||||||
pr_info.number, pr_info.sha, build_url, workspace_path, docker_image
|
stopwatch.start_time_str,
|
||||||
|
check_name,
|
||||||
|
pr_info.number,
|
||||||
|
pr_info.sha,
|
||||||
|
build_url,
|
||||||
|
workspace_path,
|
||||||
|
docker_image,
|
||||||
)
|
)
|
||||||
logging.info("Going to run %s", run_command)
|
logging.info("Going to run %s", run_command)
|
||||||
|
|
||||||
run_log_path = os.path.join(temp_path, "run.log")
|
run_log_path = os.path.join(temp_path, "run.log")
|
||||||
|
main_log_path = os.path.join(workspace_path, "main.log")
|
||||||
|
|
||||||
with open(run_log_path, "w", encoding="utf-8") as log:
|
with open(run_log_path, "w", encoding="utf-8") as log:
|
||||||
with subprocess.Popen(
|
with subprocess.Popen(
|
||||||
run_command, shell=True, stderr=log, stdout=log
|
run_command, shell=True, stderr=log, stdout=log
|
||||||
@ -105,20 +134,47 @@ def main():
|
|||||||
|
|
||||||
subprocess.check_call(f"sudo chown -R ubuntu:ubuntu {temp_path}", shell=True)
|
subprocess.check_call(f"sudo chown -R ubuntu:ubuntu {temp_path}", shell=True)
|
||||||
|
|
||||||
|
# Cleanup run log from the credentials of CI logs database.
|
||||||
|
# Note: a malicious user can still print them by splitting the value into parts.
|
||||||
|
# But we will be warned when a malicious user modifies CI script.
|
||||||
|
# Although they can also print them from inside tests.
|
||||||
|
# Nevertheless, the credentials of the CI logs have limited scope
|
||||||
|
# and does not provide access to sensitive info.
|
||||||
|
|
||||||
|
ci_logs_host = os.getenv("CLICKHOUSE_CI_LOGS_HOST", "CLICKHOUSE_CI_LOGS_HOST")
|
||||||
|
ci_logs_password = os.getenv(
|
||||||
|
"CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
|
||||||
|
)
|
||||||
|
|
||||||
|
if ci_logs_host != "CLICKHOUSE_CI_LOGS_HOST":
|
||||||
|
subprocess.check_call(
|
||||||
|
f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}' '{main_log_path}'",
|
||||||
|
shell=True,
|
||||||
|
)
|
||||||
|
|
||||||
check_name_lower = (
|
check_name_lower = (
|
||||||
check_name.lower().replace("(", "").replace(")", "").replace(" ", "")
|
check_name.lower().replace("(", "").replace(")", "").replace(" ", "")
|
||||||
)
|
)
|
||||||
s3_prefix = f"{pr_info.number}/{pr_info.sha}/fuzzer_{check_name_lower}/"
|
s3_prefix = f"{pr_info.number}/{pr_info.sha}/fuzzer_{check_name_lower}/"
|
||||||
paths = {
|
paths = {
|
||||||
"run.log": run_log_path,
|
"run.log": run_log_path,
|
||||||
"main.log": os.path.join(workspace_path, "main.log"),
|
"main.log": main_log_path,
|
||||||
"server.log.zst": os.path.join(workspace_path, "server.log.zst"),
|
|
||||||
"fuzzer.log": os.path.join(workspace_path, "fuzzer.log"),
|
"fuzzer.log": os.path.join(workspace_path, "fuzzer.log"),
|
||||||
"report.html": os.path.join(workspace_path, "report.html"),
|
"report.html": os.path.join(workspace_path, "report.html"),
|
||||||
"core.zst": os.path.join(workspace_path, "core.zst"),
|
"core.zst": os.path.join(workspace_path, "core.zst"),
|
||||||
"dmesg.log": os.path.join(workspace_path, "dmesg.log"),
|
"dmesg.log": os.path.join(workspace_path, "dmesg.log"),
|
||||||
}
|
}
|
||||||
|
|
||||||
|
compressed_server_log_path = os.path.join(workspace_path, "server.log.zst")
|
||||||
|
if os.path.exists(compressed_server_log_path):
|
||||||
|
paths["server.log.zst"] = compressed_server_log_path
|
||||||
|
|
||||||
|
# The script can fail before the invocation of `zstd`, but we are still interested in its log:
|
||||||
|
|
||||||
|
not_compressed_server_log_path = os.path.join(workspace_path, "server.log")
|
||||||
|
if os.path.exists(not_compressed_server_log_path):
|
||||||
|
paths["server.log"] = not_compressed_server_log_path
|
||||||
|
|
||||||
s3_helper = S3Helper()
|
s3_helper = S3Helper()
|
||||||
for f in paths:
|
for f in paths:
|
||||||
try:
|
try:
|
||||||
|
|||||||
@ -394,10 +394,11 @@ def main():
|
|||||||
ci_logs_password = os.getenv(
|
ci_logs_password = os.getenv(
|
||||||
"CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
|
"CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
|
||||||
)
|
)
|
||||||
subprocess.check_call(
|
if ci_logs_host != "CLICKHOUSE_CI_LOGS_HOST":
|
||||||
f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
|
subprocess.check_call(
|
||||||
shell=True,
|
f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
|
||||||
)
|
shell=True,
|
||||||
|
)
|
||||||
|
|
||||||
report_url = upload_results(
|
report_url = upload_results(
|
||||||
s3_helper,
|
s3_helper,
|
||||||
|
|||||||
@ -279,7 +279,7 @@ class PRInfo:
|
|||||||
"user_orgs": self.user_orgs,
|
"user_orgs": self.user_orgs,
|
||||||
}
|
}
|
||||||
|
|
||||||
def has_changes_in_documentation(self):
|
def has_changes_in_documentation(self) -> bool:
|
||||||
# If the list wasn't built yet the best we can do is to
|
# If the list wasn't built yet the best we can do is to
|
||||||
# assume that there were changes.
|
# assume that there were changes.
|
||||||
if self.changed_files is None or not self.changed_files:
|
if self.changed_files is None or not self.changed_files:
|
||||||
@ -287,10 +287,9 @@ class PRInfo:
|
|||||||
|
|
||||||
for f in self.changed_files:
|
for f in self.changed_files:
|
||||||
_, ext = os.path.splitext(f)
|
_, ext = os.path.splitext(f)
|
||||||
path_in_docs = "docs" in f
|
path_in_docs = f.startswith("docs/")
|
||||||
path_in_website = "website" in f
|
|
||||||
if (
|
if (
|
||||||
ext in DIFF_IN_DOCUMENTATION_EXT and (path_in_docs or path_in_website)
|
ext in DIFF_IN_DOCUMENTATION_EXT and path_in_docs
|
||||||
) or "docker/docs" in f:
|
) or "docker/docs" in f:
|
||||||
return True
|
return True
|
||||||
return False
|
return False
|
||||||
|
|||||||
@ -137,17 +137,20 @@ def main():
|
|||||||
if pr_labels_to_remove:
|
if pr_labels_to_remove:
|
||||||
remove_labels(gh, pr_info, pr_labels_to_remove)
|
remove_labels(gh, pr_info, pr_labels_to_remove)
|
||||||
|
|
||||||
if FEATURE_LABEL in pr_info.labels:
|
if FEATURE_LABEL in pr_info.labels and not pr_info.has_changes_in_documentation():
|
||||||
print(f"The '{FEATURE_LABEL}' in the labels, expect the 'Docs Check' status")
|
print(
|
||||||
|
f"The '{FEATURE_LABEL}' in the labels, "
|
||||||
|
"but there's no changed documentation"
|
||||||
|
)
|
||||||
post_commit_status( # do not pass pr_info here intentionally
|
post_commit_status( # do not pass pr_info here intentionally
|
||||||
commit,
|
commit,
|
||||||
"pending",
|
"failure",
|
||||||
NotSet,
|
NotSet,
|
||||||
f"expect adding docs for {FEATURE_LABEL}",
|
f"expect adding docs for {FEATURE_LABEL}",
|
||||||
DOCS_NAME,
|
DOCS_NAME,
|
||||||
|
pr_info,
|
||||||
)
|
)
|
||||||
elif not description_error:
|
sys.exit(1)
|
||||||
set_mergeable_check(commit, "skipped")
|
|
||||||
|
|
||||||
if description_error:
|
if description_error:
|
||||||
print(
|
print(
|
||||||
@ -173,6 +176,7 @@ def main():
|
|||||||
)
|
)
|
||||||
sys.exit(1)
|
sys.exit(1)
|
||||||
|
|
||||||
|
set_mergeable_check(commit, "skipped")
|
||||||
ci_report_url = create_ci_report(pr_info, [])
|
ci_report_url = create_ci_report(pr_info, [])
|
||||||
if not can_run:
|
if not can_run:
|
||||||
print("::notice ::Cannot run")
|
print("::notice ::Cannot run")
|
||||||
|
|||||||
@ -92,7 +92,7 @@ class S3Helper:
|
|||||||
file_path,
|
file_path,
|
||||||
)
|
)
|
||||||
else:
|
else:
|
||||||
logging.info("No content type provied for %s", file_path)
|
logging.info("No content type provided for %s", file_path)
|
||||||
else:
|
else:
|
||||||
if re.search(r"\.(txt|log|err|out)$", s3_path) or re.search(
|
if re.search(r"\.(txt|log|err|out)$", s3_path) or re.search(
|
||||||
r"\.log\..*(?<!\.zst)$", s3_path
|
r"\.log\..*(?<!\.zst)$", s3_path
|
||||||
@ -114,11 +114,12 @@ class S3Helper:
|
|||||||
logging.info("File is too large, do not provide content type")
|
logging.info("File is too large, do not provide content type")
|
||||||
|
|
||||||
self.client.upload_file(file_path, bucket_name, s3_path, ExtraArgs=metadata)
|
self.client.upload_file(file_path, bucket_name, s3_path, ExtraArgs=metadata)
|
||||||
logging.info("Upload %s to %s. Meta: %s", file_path, s3_path, metadata)
|
|
||||||
# last two replacements are specifics of AWS urls:
|
# last two replacements are specifics of AWS urls:
|
||||||
# https://jamesd3142.wordpress.com/2018/02/28/amazon-s3-and-the-plus-symbol/
|
# https://jamesd3142.wordpress.com/2018/02/28/amazon-s3-and-the-plus-symbol/
|
||||||
url = f"{self.download_host}/{bucket_name}/{s3_path}"
|
url = f"{self.download_host}/{bucket_name}/{s3_path}"
|
||||||
return url.replace("+", "%2B").replace(" ", "%20")
|
url = url.replace("+", "%2B").replace(" ", "%20")
|
||||||
|
logging.info("Upload %s to %s. Meta: %s", file_path, url, metadata)
|
||||||
|
return url
|
||||||
|
|
||||||
def upload_test_report_to_s3(self, file_path: str, s3_path: str) -> str:
|
def upload_test_report_to_s3(self, file_path: str, s3_path: str) -> str:
|
||||||
if CI:
|
if CI:
|
||||||
|
|||||||
@ -209,10 +209,11 @@ def run_stress_test(docker_image_name):
|
|||||||
ci_logs_password = os.getenv(
|
ci_logs_password = os.getenv(
|
||||||
"CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
|
"CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
|
||||||
)
|
)
|
||||||
subprocess.check_call(
|
if ci_logs_host != "CLICKHOUSE_CI_LOGS_HOST":
|
||||||
f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
|
subprocess.check_call(
|
||||||
shell=True,
|
f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
|
||||||
)
|
shell=True,
|
||||||
|
)
|
||||||
|
|
||||||
report_url = upload_results(
|
report_url = upload_results(
|
||||||
s3_helper,
|
s3_helper,
|
||||||
|
|||||||
@ -64,6 +64,7 @@ NEED_RERUN_WORKFLOWS = {
|
|||||||
"DocsCheck",
|
"DocsCheck",
|
||||||
"MasterCI",
|
"MasterCI",
|
||||||
"NightlyBuilds",
|
"NightlyBuilds",
|
||||||
|
"PublishedReleaseCI",
|
||||||
"PullRequestCI",
|
"PullRequestCI",
|
||||||
"ReleaseBranchCI",
|
"ReleaseBranchCI",
|
||||||
}
|
}
|
||||||
|
|||||||
@ -2152,7 +2152,7 @@ def reportLogStats(args):
|
|||||||
print("\n")
|
print("\n")
|
||||||
|
|
||||||
query = """
|
query = """
|
||||||
SELECT message_format_string, count(), substr(any(message), 1, 120) AS any_message
|
SELECT message_format_string, count(), any(message) AS any_message
|
||||||
FROM system.text_log
|
FROM system.text_log
|
||||||
WHERE (now() - toIntervalMinute(240)) < event_time
|
WHERE (now() - toIntervalMinute(240)) < event_time
|
||||||
AND (message NOT LIKE (replaceRegexpAll(message_format_string, '{[:.0-9dfx]*}', '%') AS s))
|
AND (message NOT LIKE (replaceRegexpAll(message_format_string, '{[:.0-9dfx]*}', '%') AS s))
|
||||||
|
|||||||
@ -91,5 +91,6 @@
|
|||||||
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_http_named_session",
|
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_http_named_session",
|
||||||
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_grpc",
|
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_grpc",
|
||||||
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_tcp_and_others",
|
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_tcp_and_others",
|
||||||
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_setting_in_query"
|
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_setting_in_query",
|
||||||
|
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_client_suggestions_load"
|
||||||
]
|
]
|
||||||
|
|||||||
@ -10,6 +10,7 @@ import threading
|
|||||||
from helpers.cluster import ClickHouseCluster, run_and_check
|
from helpers.cluster import ClickHouseCluster, run_and_check
|
||||||
from helpers.test_tools import assert_logs_contain_with_retry
|
from helpers.test_tools import assert_logs_contain_with_retry
|
||||||
|
|
||||||
|
from helpers.uclient import client, prompt
|
||||||
|
|
||||||
MAX_SESSIONS_FOR_USER = 2
|
MAX_SESSIONS_FOR_USER = 2
|
||||||
POSTGRES_SERVER_PORT = 5433
|
POSTGRES_SERVER_PORT = 5433
|
||||||
@ -209,3 +210,36 @@ def test_profile_max_sessions_for_user_tcp_and_others(started_cluster):
|
|||||||
|
|
||||||
def test_profile_max_sessions_for_user_setting_in_query(started_cluster):
|
def test_profile_max_sessions_for_user_setting_in_query(started_cluster):
|
||||||
instance.query_and_get_error("SET max_sessions_for_user = 10")
|
instance.query_and_get_error("SET max_sessions_for_user = 10")
|
||||||
|
|
||||||
|
|
||||||
|
def test_profile_max_sessions_for_user_client_suggestions_connection(started_cluster):
|
||||||
|
command_text = f"{started_cluster.get_client_cmd()} --host {instance.ip_address} --port 9000 -u {TEST_USER} --password {TEST_PASSWORD}"
|
||||||
|
command_text_without_suggestions = command_text + " --disable_suggestion"
|
||||||
|
|
||||||
|
# Launch client1 without suggestions to avoid a race condition:
|
||||||
|
# Client1 opens a session.
|
||||||
|
# Client1 opens a session for suggestion connection.
|
||||||
|
# Client2 fails to open a session and gets the USER_SESSION_LIMIT_EXCEEDED error.
|
||||||
|
#
|
||||||
|
# Expected order:
|
||||||
|
# Client1 opens a session.
|
||||||
|
# Client2 opens a session.
|
||||||
|
# Client2 fails to open a session for suggestions and with USER_SESSION_LIMIT_EXCEEDED (No error printed).
|
||||||
|
# Client3 fails to open a session.
|
||||||
|
# Client1 executes the query.
|
||||||
|
# Client2 loads suggestions from the server using the main connection and executes a query.
|
||||||
|
with client(
|
||||||
|
name="client1>", log=None, command=command_text_without_suggestions
|
||||||
|
) as client1:
|
||||||
|
client1.expect(prompt)
|
||||||
|
with client(name="client2>", log=None, command=command_text) as client2:
|
||||||
|
client2.expect(prompt)
|
||||||
|
with client(name="client3>", log=None, command=command_text) as client3:
|
||||||
|
client3.expect("USER_SESSION_LIMIT_EXCEEDED")
|
||||||
|
|
||||||
|
client1.send("SELECT 'CLIENT_1_SELECT' FORMAT CSV")
|
||||||
|
client1.expect("CLIENT_1_SELECT")
|
||||||
|
client1.expect(prompt)
|
||||||
|
client2.send("SELECT 'CLIENT_2_SELECT' FORMAT CSV")
|
||||||
|
client2.expect("CLIENT_2_SELECT")
|
||||||
|
client2.expect(prompt)
|
||||||
|
|||||||
@ -9,10 +9,10 @@ create view logs as select * from system.text_log where now() - toIntervalMinute
|
|||||||
|
|
||||||
-- Check that we don't have too many messages formatted with fmt::runtime or strings concatenation.
|
-- Check that we don't have too many messages formatted with fmt::runtime or strings concatenation.
|
||||||
-- 0.001 threshold should be always enough, the value was about 0.00025
|
-- 0.001 threshold should be always enough, the value was about 0.00025
|
||||||
select 'runtime messages', max2(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.001) from logs;
|
select 'runtime messages', greatest(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.001) from logs;
|
||||||
|
|
||||||
-- Check the same for exceptions. The value was 0.03
|
-- Check the same for exceptions. The value was 0.03
|
||||||
select 'runtime exceptions', max2(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.05) from logs where message like '%DB::Exception%';
|
select 'runtime exceptions', greatest(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.05) from logs where message like '%DB::Exception%';
|
||||||
|
|
||||||
-- FIXME some of the following messages are not informative and it has to be fixed
|
-- FIXME some of the following messages are not informative and it has to be fixed
|
||||||
create temporary table known_short_messages (s String) as select * from (select
|
create temporary table known_short_messages (s String) as select * from (select
|
||||||
@ -36,7 +36,7 @@ create temporary table known_short_messages (s String) as select * from (select
|
|||||||
'Database {} does not exist', 'Dictionary ({}) not found', 'Unknown table function {}',
|
'Database {} does not exist', 'Dictionary ({}) not found', 'Unknown table function {}',
|
||||||
'Unknown format {}', 'Unknown explain kind ''{}''', 'Unknown setting {}', 'Unknown input format {}',
|
'Unknown format {}', 'Unknown explain kind ''{}''', 'Unknown setting {}', 'Unknown input format {}',
|
||||||
'Unknown identifier: ''{}''', 'User name is empty', 'Expected function, got: {}',
|
'Unknown identifier: ''{}''', 'User name is empty', 'Expected function, got: {}',
|
||||||
'Attempt to read after eof', 'String size is too big ({}), maximum: {}', 'API mode: {}',
|
'Attempt to read after eof', 'String size is too big ({}), maximum: {}',
|
||||||
'Processed: {}%', 'Creating {}: {}', 'Table {}.{} doesn''t exist', 'Invalid cache key hex: {}',
|
'Processed: {}%', 'Creating {}: {}', 'Table {}.{} doesn''t exist', 'Invalid cache key hex: {}',
|
||||||
'User has been dropped', 'Illegal type {} of argument of function {}. Should be DateTime or DateTime64'
|
'User has been dropped', 'Illegal type {} of argument of function {}. Should be DateTime or DateTime64'
|
||||||
] as arr) array join arr;
|
] as arr) array join arr;
|
||||||
|
|||||||
@ -13,13 +13,13 @@ SET group_by_two_level_threshold = 100000;
|
|||||||
SET max_bytes_before_external_group_by = '1Mi';
|
SET max_bytes_before_external_group_by = '1Mi';
|
||||||
|
|
||||||
-- method: key_string & key_string_two_level
|
-- method: key_string & key_string_two_level
|
||||||
CREATE TABLE t_00284_str(s String) ENGINE = MergeTree() ORDER BY tuple();
|
CREATE TABLE t_00284_str(s String) ENGINE = MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO t_00284_str SELECT toString(number) FROM numbers_mt(1e6);
|
INSERT INTO t_00284_str SELECT toString(number) FROM numbers_mt(1e6);
|
||||||
INSERT INTO t_00284_str SELECT toString(number) FROM numbers_mt(1e6);
|
INSERT INTO t_00284_str SELECT toString(number) FROM numbers_mt(1e6);
|
||||||
SELECT s, count() FROM t_00284_str GROUP BY s ORDER BY s LIMIT 10 OFFSET 42;
|
SELECT s, count() FROM t_00284_str GROUP BY s ORDER BY s LIMIT 10 OFFSET 42;
|
||||||
|
|
||||||
-- method: low_cardinality_key_string & low_cardinality_key_string_two_level
|
-- method: low_cardinality_key_string & low_cardinality_key_string_two_level
|
||||||
CREATE TABLE t_00284_lc_str(s LowCardinality(String)) ENGINE = MergeTree() ORDER BY tuple();
|
CREATE TABLE t_00284_lc_str(s LowCardinality(String)) ENGINE = MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO t_00284_lc_str SELECT toString(number) FROM numbers_mt(1e6);
|
INSERT INTO t_00284_lc_str SELECT toString(number) FROM numbers_mt(1e6);
|
||||||
INSERT INTO t_00284_lc_str SELECT toString(number) FROM numbers_mt(1e6);
|
INSERT INTO t_00284_lc_str SELECT toString(number) FROM numbers_mt(1e6);
|
||||||
SELECT s, count() FROM t_00284_lc_str GROUP BY s ORDER BY s LIMIT 10 OFFSET 42;
|
SELECT s, count() FROM t_00284_lc_str GROUP BY s ORDER BY s LIMIT 10 OFFSET 42;
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
DROP TABLE IF EXISTS multidimensional;
|
DROP TABLE IF EXISTS multidimensional;
|
||||||
CREATE TABLE multidimensional ENGINE = MergeTree ORDER BY number AS SELECT number, arrayMap(x -> (x, [x], [[x]], (x, toString(x))), arrayMap(x -> range(x), range(number % 10))) AS value FROM system.numbers LIMIT 100000;
|
CREATE TABLE multidimensional ENGINE = MergeTree ORDER BY number SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi' AS SELECT number, arrayMap(x -> (x, [x], [[x]], (x, toString(x))), arrayMap(x -> range(x), range(number % 10))) AS value FROM system.numbers LIMIT 100000;
|
||||||
|
|
||||||
SELECT sum(cityHash64(toString(value))) FROM multidimensional;
|
SELECT sum(cityHash64(toString(value))) FROM multidimensional;
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
DROP TABLE IF EXISTS nested;
|
DROP TABLE IF EXISTS nested;
|
||||||
|
|
||||||
CREATE TABLE nested (x UInt64, filter UInt8, n Nested(a UInt64)) ENGINE = MergeTree ORDER BY x;
|
CREATE TABLE nested (x UInt64, filter UInt8, n Nested(a UInt64)) ENGINE = MergeTree ORDER BY x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO nested SELECT number, number % 2, range(number % 10) FROM system.numbers LIMIT 100000;
|
INSERT INTO nested SELECT number, number % 2, range(number % 10) FROM system.numbers LIMIT 100000;
|
||||||
|
|
||||||
ALTER TABLE nested ADD COLUMN n.b Array(UInt64);
|
ALTER TABLE nested ADD COLUMN n.b Array(UInt64);
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
DROP TABLE IF EXISTS count;
|
DROP TABLE IF EXISTS count;
|
||||||
|
|
||||||
CREATE TABLE count (x UInt64) ENGINE = MergeTree ORDER BY tuple();
|
CREATE TABLE count (x UInt64) ENGINE = MergeTree ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO count SELECT * FROM numbers(1234567);
|
INSERT INTO count SELECT * FROM numbers(1234567);
|
||||||
|
|
||||||
SELECT count() FROM count;
|
SELECT count() FROM count;
|
||||||
|
|||||||
@ -1,6 +1,5 @@
|
|||||||
drop table if exists lc_dict_reading;
|
drop table if exists lc_dict_reading;
|
||||||
create table lc_dict_reading (val UInt64, str StringWithDictionary, pat String) engine = MergeTree order by val;
|
create table lc_dict_reading (val UInt64, str StringWithDictionary, pat String) engine = MergeTree order by val SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into lc_dict_reading select number, if(number < 8192 * 4, number % 100, number) as s, s from system.numbers limit 1000000;
|
insert into lc_dict_reading select number, if(number < 8192 * 4, number % 100, number) as s, s from system.numbers limit 1000000;
|
||||||
select sum(toUInt64(str)), sum(toUInt64(pat)) from lc_dict_reading where val < 8129 or val > 8192 * 4;
|
select sum(toUInt64(str)), sum(toUInt64(pat)) from lc_dict_reading where val < 8129 or val > 8192 * 4;
|
||||||
drop table if exists lc_dict_reading;
|
drop table if exists lc_dict_reading;
|
||||||
|
|
||||||
|
|||||||
@ -8,8 +8,8 @@ select 'MergeTree';
|
|||||||
drop table if exists lc_small_dict;
|
drop table if exists lc_small_dict;
|
||||||
drop table if exists lc_big_dict;
|
drop table if exists lc_big_dict;
|
||||||
|
|
||||||
create table lc_small_dict (str StringWithDictionary) engine = MergeTree order by str;
|
create table lc_small_dict (str StringWithDictionary) engine = MergeTree order by str SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
create table lc_big_dict (str StringWithDictionary) engine = MergeTree order by str;
|
create table lc_big_dict (str StringWithDictionary) engine = MergeTree order by str SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
insert into lc_small_dict select toString(number % 1000) from system.numbers limit 1000000;
|
insert into lc_small_dict select toString(number % 1000) from system.numbers limit 1000000;
|
||||||
insert into lc_big_dict select toString(number) from system.numbers limit 1000000;
|
insert into lc_big_dict select toString(number) from system.numbers limit 1000000;
|
||||||
@ -25,4 +25,3 @@ select sum(toUInt64OrZero(str)) from lc_big_dict;
|
|||||||
|
|
||||||
drop table if exists lc_small_dict;
|
drop table if exists lc_small_dict;
|
||||||
drop table if exists lc_big_dict;
|
drop table if exists lc_big_dict;
|
||||||
|
|
||||||
|
|||||||
@ -13,7 +13,7 @@ uuid=$(${CLICKHOUSE_CLIENT} --query "SELECT reinterpretAsUUID(currentDatabase())
|
|||||||
|
|
||||||
echo "DROP TABLE IF EXISTS tab_00738 SYNC;
|
echo "DROP TABLE IF EXISTS tab_00738 SYNC;
|
||||||
DROP TABLE IF EXISTS mv SYNC;
|
DROP TABLE IF EXISTS mv SYNC;
|
||||||
CREATE TABLE tab_00738(a Int) ENGINE = MergeTree() ORDER BY a;
|
CREATE TABLE tab_00738(a Int) ENGINE = MergeTree() ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
-- The matview will take at least 2 seconds to be finished (10000000 * 0.0000002)
|
-- The matview will take at least 2 seconds to be finished (10000000 * 0.0000002)
|
||||||
CREATE MATERIALIZED VIEW mv UUID '$uuid' ENGINE = Log AS SELECT sleepEachRow(0.0000002) FROM tab_00738;" | ${CLICKHOUSE_CLIENT} -n
|
CREATE MATERIALIZED VIEW mv UUID '$uuid' ENGINE = Log AS SELECT sleepEachRow(0.0000002) FROM tab_00738;" | ${CLICKHOUSE_CLIENT} -n
|
||||||
|
|
||||||
@ -63,4 +63,3 @@ drop_inner_id
|
|||||||
wait
|
wait
|
||||||
|
|
||||||
drop_at_exit
|
drop_at_exit
|
||||||
|
|
||||||
|
|||||||
@ -6,14 +6,14 @@ CREATE TABLE IF NOT EXISTS test_move_partition_src (
|
|||||||
val UInt32
|
val UInt32
|
||||||
) Engine = MergeTree()
|
) Engine = MergeTree()
|
||||||
PARTITION BY pk
|
PARTITION BY pk
|
||||||
ORDER BY (pk, val);
|
ORDER BY (pk, val) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
CREATE TABLE IF NOT EXISTS test_move_partition_dest (
|
CREATE TABLE IF NOT EXISTS test_move_partition_dest (
|
||||||
pk UInt8,
|
pk UInt8,
|
||||||
val UInt32
|
val UInt32
|
||||||
) Engine = MergeTree()
|
) Engine = MergeTree()
|
||||||
PARTITION BY pk
|
PARTITION BY pk
|
||||||
ORDER BY (pk, val);
|
ORDER BY (pk, val) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO test_move_partition_src SELECT number % 2, number FROM system.numbers LIMIT 10000000;
|
INSERT INTO test_move_partition_src SELECT number % 2, number FROM system.numbers LIMIT 10000000;
|
||||||
|
|
||||||
|
|||||||
@ -2,7 +2,7 @@
|
|||||||
|
|
||||||
DROP TABLE IF EXISTS topk;
|
DROP TABLE IF EXISTS topk;
|
||||||
|
|
||||||
CREATE TABLE topk (val1 String, val2 UInt32) ENGINE = MergeTree ORDER BY val1;
|
CREATE TABLE topk (val1 String, val2 UInt32) ENGINE = MergeTree ORDER BY val1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO topk WITH number % 7 = 0 AS frequent SELECT toString(frequent ? number % 10 : number), frequent ? 999999999 : number FROM numbers(4000000);
|
INSERT INTO topk WITH number % 7 = 0 AS frequent SELECT toString(frequent ? number % 10 : number), frequent ? 999999999 : number FROM numbers(4000000);
|
||||||
|
|
||||||
|
|||||||
@ -59,7 +59,8 @@ function thread6()
|
|||||||
CREATE TABLE alter_table_$REPLICA (a UInt8, b Int16, c Float32, d String, e Array(UInt8), f Nullable(UUID), g Tuple(UInt8, UInt16))
|
CREATE TABLE alter_table_$REPLICA (a UInt8, b Int16, c Float32, d String, e Array(UInt8), f Nullable(UUID), g Tuple(UInt8, UInt16))
|
||||||
ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/alter_table', 'r_$REPLICA') ORDER BY a PARTITION BY b % 10
|
ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/alter_table', 'r_$REPLICA') ORDER BY a PARTITION BY b % 10
|
||||||
SETTINGS old_parts_lifetime = 1, cleanup_delay_period = 0, cleanup_delay_period_random_add = 0,
|
SETTINGS old_parts_lifetime = 1, cleanup_delay_period = 0, cleanup_delay_period_random_add = 0,
|
||||||
cleanup_thread_preferred_points_per_iteration=0, replicated_max_mutations_in_one_entry = $(($RANDOM / 50));";
|
cleanup_thread_preferred_points_per_iteration=0, replicated_max_mutations_in_one_entry = $(($RANDOM / 50)),
|
||||||
|
index_granularity = 8192, index_granularity_bytes = '10Mi';";
|
||||||
sleep 0.$RANDOM;
|
sleep 0.$RANDOM;
|
||||||
done
|
done
|
||||||
}
|
}
|
||||||
|
|||||||
@ -3,7 +3,7 @@
|
|||||||
set allow_experimental_parallel_reading_from_replicas = 0;
|
set allow_experimental_parallel_reading_from_replicas = 0;
|
||||||
|
|
||||||
drop table if exists sample_final;
|
drop table if exists sample_final;
|
||||||
create table sample_final (CounterID UInt32, EventDate Date, EventTime DateTime, UserID UInt64, Sign Int8) engine = CollapsingMergeTree(Sign) order by (CounterID, EventDate, intHash32(UserID), EventTime) sample by intHash32(UserID);
|
create table sample_final (CounterID UInt32, EventDate Date, EventTime DateTime, UserID UInt64, Sign Int8) engine = CollapsingMergeTree(Sign) order by (CounterID, EventDate, intHash32(UserID), EventTime) sample by intHash32(UserID) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into sample_final select number / (8192 * 4), toDate('2019-01-01'), toDateTime('2019-01-01 00:00:01') + number, number / (8192 * 2), number % 3 = 1 ? -1 : 1 from numbers(1000000);
|
insert into sample_final select number / (8192 * 4), toDate('2019-01-01'), toDateTime('2019-01-01 00:00:01') + number, number / (8192 * 2), number % 3 = 1 ? -1 : 1 from numbers(1000000);
|
||||||
|
|
||||||
select 'count';
|
select 'count';
|
||||||
|
|||||||
@ -22,7 +22,7 @@ CREATE TABLE IF NOT EXISTS test_01035_avg (
|
|||||||
d64 Decimal64(18) DEFAULT toDecimal64(u64 / 1000000, 8),
|
d64 Decimal64(18) DEFAULT toDecimal64(u64 / 1000000, 8),
|
||||||
d128 Decimal128(20) DEFAULT toDecimal128(i128 / 100000, 20),
|
d128 Decimal128(20) DEFAULT toDecimal128(i128 / 100000, 20),
|
||||||
d256 Decimal256(40) DEFAULT toDecimal256(i256 / 100000, 40)
|
d256 Decimal256(40) DEFAULT toDecimal256(i256 / 100000, 40)
|
||||||
) ENGINE = MergeTree() ORDER BY i64;
|
) ENGINE = MergeTree() ORDER BY i64 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
SELECT avg(i8), avg(i16), avg(i32), avg(i64), avg(i128), avg(i256),
|
SELECT avg(i8), avg(i16), avg(i32), avg(i64), avg(i128), avg(i256),
|
||||||
avg(u8), avg(u16), avg(u32), avg(u64), avg(u128), avg(u256),
|
avg(u8), avg(u16), avg(u32), avg(u64), avg(u128), avg(u256),
|
||||||
|
|||||||
@ -21,7 +21,7 @@ function wait_mutation_to_start()
|
|||||||
|
|
||||||
${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS table_for_mutations"
|
${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS table_for_mutations"
|
||||||
|
|
||||||
${CLICKHOUSE_CLIENT} --query="CREATE TABLE table_for_mutations(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k PARTITION BY modulo(k, 2)"
|
${CLICKHOUSE_CLIENT} --query="CREATE TABLE table_for_mutations(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k PARTITION BY modulo(k, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
|
||||||
|
|
||||||
${CLICKHOUSE_CLIENT} --query="SYSTEM STOP MERGES table_for_mutations"
|
${CLICKHOUSE_CLIENT} --query="SYSTEM STOP MERGES table_for_mutations"
|
||||||
|
|
||||||
@ -48,7 +48,7 @@ ${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS table_for_mutations"
|
|||||||
|
|
||||||
${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS replicated_table_for_mutations"
|
${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS replicated_table_for_mutations"
|
||||||
|
|
||||||
${CLICKHOUSE_CLIENT} --query="CREATE TABLE replicated_table_for_mutations(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/replicated_table_for_mutations', '1') ORDER BY k PARTITION BY modulo(k, 2)"
|
${CLICKHOUSE_CLIENT} --query="CREATE TABLE replicated_table_for_mutations(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/replicated_table_for_mutations', '1') ORDER BY k PARTITION BY modulo(k, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
|
||||||
|
|
||||||
${CLICKHOUSE_CLIENT} --query="SYSTEM STOP MERGES replicated_table_for_mutations"
|
${CLICKHOUSE_CLIENT} --query="SYSTEM STOP MERGES replicated_table_for_mutations"
|
||||||
|
|
||||||
|
|||||||
@ -5,9 +5,9 @@ DROP TABLE IF EXISTS table_for_synchronous_mutations2;
|
|||||||
|
|
||||||
SELECT 'Replicated';
|
SELECT 'Replicated';
|
||||||
|
|
||||||
CREATE TABLE table_for_synchronous_mutations1(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '1') ORDER BY k;
|
CREATE TABLE table_for_synchronous_mutations1(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '1') ORDER BY k SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
CREATE TABLE table_for_synchronous_mutations2(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '2') ORDER BY k;
|
CREATE TABLE table_for_synchronous_mutations2(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '2') ORDER BY k SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO table_for_synchronous_mutations1 select number, number from numbers(100000);
|
INSERT INTO table_for_synchronous_mutations1 select number, number from numbers(100000);
|
||||||
|
|
||||||
@ -29,7 +29,7 @@ SELECT 'Normal';
|
|||||||
|
|
||||||
DROP TABLE IF EXISTS table_for_synchronous_mutations_no_replication;
|
DROP TABLE IF EXISTS table_for_synchronous_mutations_no_replication;
|
||||||
|
|
||||||
CREATE TABLE table_for_synchronous_mutations_no_replication(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k;
|
CREATE TABLE table_for_synchronous_mutations_no_replication(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO table_for_synchronous_mutations_no_replication select number, number from numbers(100000);
|
INSERT INTO table_for_synchronous_mutations_no_replication select number, number from numbers(100000);
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
-- Tags: no-parallel
|
-- Tags: no-parallel
|
||||||
|
|
||||||
DROP TABLE IF EXISTS test;
|
DROP TABLE IF EXISTS test;
|
||||||
CREATE TABLE test Engine = MergeTree ORDER BY number AS SELECT number, toString(rand()) x from numbers(10000000);
|
CREATE TABLE test Engine = MergeTree ORDER BY number SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi' AS SELECT number, toString(rand()) x from numbers(10000000);
|
||||||
|
|
||||||
SELECT count() FROM test;
|
SELECT count() FROM test;
|
||||||
|
|
||||||
|
|||||||
@ -7,7 +7,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
|
|||||||
|
|
||||||
$CLICKHOUSE_CLIENT --query "DROP TABLE IF EXISTS movement"
|
$CLICKHOUSE_CLIENT --query "DROP TABLE IF EXISTS movement"
|
||||||
|
|
||||||
$CLICKHOUSE_CLIENT -n --query "CREATE TABLE movement (date DateTime('Asia/Istanbul')) Engine = MergeTree ORDER BY (toStartOfHour(date));"
|
$CLICKHOUSE_CLIENT -n --query "CREATE TABLE movement (date DateTime('Asia/Istanbul')) Engine = MergeTree ORDER BY (toStartOfHour(date)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
|
||||||
|
|
||||||
$CLICKHOUSE_CLIENT --query "insert into movement select toDateTime('2020-01-22 00:00:00', 'Asia/Istanbul') + number%(23*3600) from numbers(1000000);"
|
$CLICKHOUSE_CLIENT --query "insert into movement select toDateTime('2020-01-22 00:00:00', 'Asia/Istanbul') + number%(23*3600) from numbers(1000000);"
|
||||||
|
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
DROP TABLE IF EXISTS mt_pk;
|
DROP TABLE IF EXISTS mt_pk;
|
||||||
|
|
||||||
CREATE TABLE mt_pk ENGINE = MergeTree PARTITION BY d ORDER BY x
|
CREATE TABLE mt_pk ENGINE = MergeTree PARTITION BY d ORDER BY x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'
|
||||||
AS SELECT toDate(number % 32) AS d, number AS x FROM system.numbers LIMIT 10000010;
|
AS SELECT toDate(number % 32) AS d, number AS x FROM system.numbers LIMIT 10000010;
|
||||||
SELECT x FROM mt_pk ORDER BY x ASC LIMIT 10000000, 1;
|
SELECT x FROM mt_pk ORDER BY x ASC LIMIT 10000000, 1;
|
||||||
|
|
||||||
|
|||||||
@ -15,7 +15,7 @@ done
|
|||||||
|
|
||||||
|
|
||||||
for i in $(seq $REPLICAS); do
|
for i in $(seq $REPLICAS); do
|
||||||
$CLICKHOUSE_CLIENT --query "CREATE TABLE concurrent_alter_add_drop_$i (key UInt64, value0 UInt8) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/concurrent_alter_add_drop_column', '$i') ORDER BY key SETTINGS max_replicated_mutations_in_queue=1000, number_of_free_entries_in_pool_to_execute_mutation=0,max_replicated_merges_in_queue=1000"
|
$CLICKHOUSE_CLIENT --query "CREATE TABLE concurrent_alter_add_drop_$i (key UInt64, value0 UInt8) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/concurrent_alter_add_drop_column', '$i') ORDER BY key SETTINGS max_replicated_mutations_in_queue = 1000, number_of_free_entries_in_pool_to_execute_mutation = 0, max_replicated_merges_in_queue = 1000, index_granularity = 8192, index_granularity_bytes = '10Mi'"
|
||||||
done
|
done
|
||||||
|
|
||||||
$CLICKHOUSE_CLIENT --query "INSERT INTO concurrent_alter_add_drop_1 SELECT number, number + 10 from numbers(100000)"
|
$CLICKHOUSE_CLIENT --query "INSERT INTO concurrent_alter_add_drop_1 SELECT number, number + 10 from numbers(100000)"
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
DROP TABLE IF EXISTS pk_func;
|
DROP TABLE IF EXISTS pk_func;
|
||||||
CREATE TABLE pk_func(d DateTime, ui UInt32) ENGINE = MergeTree ORDER BY toDate(d);
|
CREATE TABLE pk_func(d DateTime, ui UInt32) ENGINE = MergeTree ORDER BY toDate(d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO pk_func SELECT '2020-05-05 01:00:00', number FROM numbers(1000000);
|
INSERT INTO pk_func SELECT '2020-05-05 01:00:00', number FROM numbers(1000000);
|
||||||
INSERT INTO pk_func SELECT '2020-05-06 01:00:00', number FROM numbers(1000000);
|
INSERT INTO pk_func SELECT '2020-05-06 01:00:00', number FROM numbers(1000000);
|
||||||
@ -10,7 +10,7 @@ SELECT * FROM pk_func ORDER BY toDate(d), ui LIMIT 5;
|
|||||||
DROP TABLE pk_func;
|
DROP TABLE pk_func;
|
||||||
|
|
||||||
DROP TABLE IF EXISTS nORX;
|
DROP TABLE IF EXISTS nORX;
|
||||||
CREATE TABLE nORX (`A` Int64, `B` Int64, `V` Int64) ENGINE = MergeTree ORDER BY (A, negate(B));
|
CREATE TABLE nORX (`A` Int64, `B` Int64, `V` Int64) ENGINE = MergeTree ORDER BY (A, negate(B)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO nORX SELECT 111, number, number FROM numbers(10000000);
|
INSERT INTO nORX SELECT 111, number, number FROM numbers(10000000);
|
||||||
|
|
||||||
SELECT *
|
SELECT *
|
||||||
|
|||||||
@ -6,7 +6,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
|
|||||||
. "$CURDIR"/../shell_config.sh
|
. "$CURDIR"/../shell_config.sh
|
||||||
|
|
||||||
$CLICKHOUSE_CLIENT -q "drop table if exists huge_strings"
|
$CLICKHOUSE_CLIENT -q "drop table if exists huge_strings"
|
||||||
$CLICKHOUSE_CLIENT -q "create table huge_strings (n UInt64, l UInt64, s String, h UInt64) engine=MergeTree order by n"
|
$CLICKHOUSE_CLIENT -q "create table huge_strings (n UInt64, l UInt64, s String, h UInt64) engine=MergeTree order by n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
|
||||||
|
|
||||||
# Timeouts are increased, because test can be slow with sanitizers and parallel runs.
|
# Timeouts are increased, because test can be slow with sanitizers and parallel runs.
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
DROP TABLE IF EXISTS null_in;
|
DROP TABLE IF EXISTS null_in;
|
||||||
CREATE TABLE null_in (dt DateTime, idx int, i Nullable(int), s Nullable(String)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx;
|
CREATE TABLE null_in (dt DateTime, idx int, i Nullable(int), s Nullable(String)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO null_in VALUES (1, 1, 1, '1') (2, 2, NULL, NULL) (3, 3, 3, '3') (4, 4, NULL, NULL) (5, 5, 5, '5');
|
INSERT INTO null_in VALUES (1, 1, 1, '1') (2, 2, NULL, NULL) (3, 3, 3, '3') (4, 4, NULL, NULL) (5, 5, 5, '5');
|
||||||
|
|
||||||
@ -81,7 +81,7 @@ DROP TABLE IF EXISTS null_in;
|
|||||||
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS null_in_subquery;
|
DROP TABLE IF EXISTS null_in_subquery;
|
||||||
CREATE TABLE null_in_subquery (dt DateTime, idx int, i Nullable(UInt64)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx;
|
CREATE TABLE null_in_subquery (dt DateTime, idx int, i Nullable(UInt64)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO null_in_subquery SELECT number % 3, number, number FROM system.numbers LIMIT 99999;
|
INSERT INTO null_in_subquery SELECT number % 3, number, number FROM system.numbers LIMIT 99999;
|
||||||
|
|
||||||
SELECT count() == 33333 FROM null_in_subquery WHERE i in (SELECT i FROM null_in_subquery WHERE dt = 0);
|
SELECT count() == 33333 FROM null_in_subquery WHERE i in (SELECT i FROM null_in_subquery WHERE dt = 0);
|
||||||
@ -111,7 +111,7 @@ DROP TABLE IF EXISTS null_in_subquery;
|
|||||||
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS null_in_tuple;
|
DROP TABLE IF EXISTS null_in_tuple;
|
||||||
CREATE TABLE null_in_tuple (dt DateTime, idx int, t Tuple(Nullable(UInt64), Nullable(String))) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx;
|
CREATE TABLE null_in_tuple (dt DateTime, idx int, t Tuple(Nullable(UInt64), Nullable(String))) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO null_in_tuple VALUES (1, 1, (1, '1')) (2, 2, (2, NULL)) (3, 3, (NULL, '3')) (4, 4, (NULL, NULL))
|
INSERT INTO null_in_tuple VALUES (1, 1, (1, '1')) (2, 2, (2, NULL)) (3, 3, (NULL, '3')) (4, 4, (NULL, NULL))
|
||||||
|
|
||||||
SET transform_null_in = 0;
|
SET transform_null_in = 0;
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
DROP TABLE IF EXISTS ES;
|
DROP TABLE IF EXISTS ES;
|
||||||
|
|
||||||
create table ES(A String) Engine=MergeTree order by tuple();
|
create table ES(A String) Engine=MergeTree order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into ES select toString(number) from numbers(10000000);
|
insert into ES select toString(number) from numbers(10000000);
|
||||||
|
|
||||||
SET max_execution_time = 100,
|
SET max_execution_time = 100,
|
||||||
|
|||||||
@ -4,7 +4,7 @@ DROP TABLE IF EXISTS tt_01373;
|
|||||||
|
|
||||||
CREATE TABLE tt_01373
|
CREATE TABLE tt_01373
|
||||||
(a Int64, d Int64, val Int64)
|
(a Int64, d Int64, val Int64)
|
||||||
ENGINE = SummingMergeTree PARTITION BY (a) ORDER BY (d);
|
ENGINE = SummingMergeTree PARTITION BY (a) ORDER BY (d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
SYSTEM STOP MERGES tt_01373;
|
SYSTEM STOP MERGES tt_01373;
|
||||||
|
|
||||||
|
|||||||
@ -4,7 +4,7 @@ CREATE TABLE t_01411(
|
|||||||
str LowCardinality(String),
|
str LowCardinality(String),
|
||||||
arr Array(LowCardinality(String)) default [str]
|
arr Array(LowCardinality(String)) default [str]
|
||||||
) ENGINE = MergeTree()
|
) ENGINE = MergeTree()
|
||||||
ORDER BY tuple();
|
ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO t_01411 (str) SELECT concat('asdf', toString(number % 10000)) FROM numbers(1000000);
|
INSERT INTO t_01411 (str) SELECT concat('asdf', toString(number % 10000)) FROM numbers(1000000);
|
||||||
|
|
||||||
@ -24,7 +24,7 @@ CREATE TABLE t_01411_num(
|
|||||||
num UInt8,
|
num UInt8,
|
||||||
arr Array(LowCardinality(Int64)) default [num]
|
arr Array(LowCardinality(Int64)) default [num]
|
||||||
) ENGINE = MergeTree()
|
) ENGINE = MergeTree()
|
||||||
ORDER BY tuple();
|
ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO t_01411_num (num) SELECT number % 1000 FROM numbers(1000000);
|
INSERT INTO t_01411_num (num) SELECT number % 1000 FROM numbers(1000000);
|
||||||
|
|
||||||
|
|||||||
@ -4,7 +4,7 @@ SET allow_asynchronous_read_from_io_pool_for_merge_tree = 0;
|
|||||||
SET do_not_merge_across_partitions_select_final = 1;
|
SET do_not_merge_across_partitions_select_final = 1;
|
||||||
SET max_threads = 16;
|
SET max_threads = 16;
|
||||||
|
|
||||||
CREATE TABLE select_final (t DateTime, x Int32, string String) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(t) ORDER BY (x, t);
|
CREATE TABLE select_final (t DateTime, x Int32, string String) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(t) ORDER BY (x, t) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO select_final SELECT toDate('2000-01-01'), number, '' FROM numbers(2);
|
INSERT INTO select_final SELECT toDate('2000-01-01'), number, '' FROM numbers(2);
|
||||||
INSERT INTO select_final SELECT toDate('2000-01-01'), number + 1, '' FROM numbers(2);
|
INSERT INTO select_final SELECT toDate('2000-01-01'), number + 1, '' FROM numbers(2);
|
||||||
|
|||||||
@ -9,14 +9,14 @@ drop table if exists table_map;
|
|||||||
|
|
||||||
|
|
||||||
drop table if exists table_map;
|
drop table if exists table_map;
|
||||||
create table table_map (a Map(String, UInt64)) engine = MergeTree() order by a;
|
create table table_map (a Map(String, UInt64)) engine = MergeTree() order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into table_map select map('key1', number, 'key2', number * 2) from numbers(1111, 3);
|
insert into table_map select map('key1', number, 'key2', number * 2) from numbers(1111, 3);
|
||||||
select a['key1'], a['key2'] from table_map;
|
select a['key1'], a['key2'] from table_map;
|
||||||
drop table if exists table_map;
|
drop table if exists table_map;
|
||||||
|
|
||||||
-- MergeTree Engine
|
-- MergeTree Engine
|
||||||
drop table if exists table_map;
|
drop table if exists table_map;
|
||||||
create table table_map (a Map(String, String), b String) engine = MergeTree() order by a;
|
create table table_map (a Map(String, String), b String) engine = MergeTree() order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into table_map values ({'name':'zhangsan', 'gender':'male'}, 'name'), ({'name':'lisi', 'gender':'female'}, 'gender');
|
insert into table_map values ({'name':'zhangsan', 'gender':'male'}, 'name'), ({'name':'lisi', 'gender':'female'}, 'gender');
|
||||||
select a[b] from table_map;
|
select a[b] from table_map;
|
||||||
select b from table_map where a = map('name','lisi', 'gender', 'female');
|
select b from table_map where a = map('name','lisi', 'gender', 'female');
|
||||||
@ -24,21 +24,21 @@ drop table if exists table_map;
|
|||||||
|
|
||||||
-- Big Integer type
|
-- Big Integer type
|
||||||
|
|
||||||
create table table_map (d DATE, m Map(Int8, UInt256)) ENGINE = MergeTree() order by d;
|
create table table_map (d DATE, m Map(Int8, UInt256)) ENGINE = MergeTree() order by d SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into table_map values ('2020-01-01', map(1, 0, 2, 1));
|
insert into table_map values ('2020-01-01', map(1, 0, 2, 1));
|
||||||
select * from table_map;
|
select * from table_map;
|
||||||
drop table table_map;
|
drop table table_map;
|
||||||
|
|
||||||
-- Integer type
|
-- Integer type
|
||||||
|
|
||||||
create table table_map (d DATE, m Map(Int8, Int8)) ENGINE = MergeTree() order by d;
|
create table table_map (d DATE, m Map(Int8, Int8)) ENGINE = MergeTree() order by d SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into table_map values ('2020-01-01', map(1, 0, 2, -1));
|
insert into table_map values ('2020-01-01', map(1, 0, 2, -1));
|
||||||
select * from table_map;
|
select * from table_map;
|
||||||
drop table table_map;
|
drop table table_map;
|
||||||
|
|
||||||
-- Unsigned Int type
|
-- Unsigned Int type
|
||||||
drop table if exists table_map;
|
drop table if exists table_map;
|
||||||
create table table_map(a Map(UInt8, UInt64), b UInt8) Engine = MergeTree() order by b;
|
create table table_map(a Map(UInt8, UInt64), b UInt8) Engine = MergeTree() order by b SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into table_map select map(number, number+5), number from numbers(1111,4);
|
insert into table_map select map(number, number+5), number from numbers(1111,4);
|
||||||
select a[b] from table_map;
|
select a[b] from table_map;
|
||||||
drop table if exists table_map;
|
drop table if exists table_map;
|
||||||
@ -46,7 +46,7 @@ drop table if exists table_map;
|
|||||||
|
|
||||||
-- Array Type
|
-- Array Type
|
||||||
drop table if exists table_map;
|
drop table if exists table_map;
|
||||||
create table table_map(a Map(String, Array(UInt8))) Engine = MergeTree() order by a;
|
create table table_map(a Map(String, Array(UInt8))) Engine = MergeTree() order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into table_map values(map('k1', [1,2,3], 'k2', [4,5,6])), (map('k0', [], 'k1', [100,20,90]));
|
insert into table_map values(map('k1', [1,2,3], 'k2', [4,5,6])), (map('k0', [], 'k1', [100,20,90]));
|
||||||
insert into table_map select map('k1', [number, number + 2, number * 2]) from numbers(6);
|
insert into table_map select map('k1', [number, number + 2, number * 2]) from numbers(6);
|
||||||
insert into table_map select map('k2', [number, number + 2, number * 2]) from numbers(6);
|
insert into table_map select map('k2', [number, number + 2, number * 2]) from numbers(6);
|
||||||
@ -56,7 +56,7 @@ drop table if exists table_map;
|
|||||||
SELECT CAST(([1, 2, 3], ['1', '2', 'foo']), 'Map(UInt8, String)') AS map, map[1];
|
SELECT CAST(([1, 2, 3], ['1', '2', 'foo']), 'Map(UInt8, String)') AS map, map[1];
|
||||||
|
|
||||||
CREATE TABLE table_map (n UInt32, m Map(String, Int))
|
CREATE TABLE table_map (n UInt32, m Map(String, Int))
|
||||||
ENGINE = MergeTree ORDER BY n SETTINGS min_bytes_for_wide_part = 0;
|
ENGINE = MergeTree ORDER BY n SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
-- coversion from Tuple(Array(K), Array(V))
|
-- coversion from Tuple(Array(K), Array(V))
|
||||||
INSERT INTO table_map SELECT number, (arrayMap(x -> toString(x), range(number % 10 + 2)), range(number % 10 + 2)) FROM numbers(100000);
|
INSERT INTO table_map SELECT number, (arrayMap(x -> toString(x), range(number % 10 + 2)), range(number % 10 + 2)) FROM numbers(100000);
|
||||||
@ -67,7 +67,7 @@ SELECT sum(m['1']), sum(m['7']), sum(m['100']) FROM table_map;
|
|||||||
DROP TABLE IF EXISTS table_map;
|
DROP TABLE IF EXISTS table_map;
|
||||||
|
|
||||||
CREATE TABLE table_map (n UInt32, m Map(String, Int))
|
CREATE TABLE table_map (n UInt32, m Map(String, Int))
|
||||||
ENGINE = MergeTree ORDER BY n;
|
ENGINE = MergeTree ORDER BY n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
-- coversion from Tuple(Array(K), Array(V))
|
-- coversion from Tuple(Array(K), Array(V))
|
||||||
INSERT INTO table_map SELECT number, (arrayMap(x -> toString(x), range(number % 10 + 2)), range(number % 10 + 2)) FROM numbers(100000);
|
INSERT INTO table_map SELECT number, (arrayMap(x -> toString(x), range(number % 10 + 2)), range(number % 10 + 2)) FROM numbers(100000);
|
||||||
|
|||||||
@ -7,7 +7,7 @@ set max_insert_threads = 4;
|
|||||||
create table stack(item_id Int64, brand_id Int64, rack_id Int64, dt DateTime, expiration_dt DateTime, quantity UInt64)
|
create table stack(item_id Int64, brand_id Int64, rack_id Int64, dt DateTime, expiration_dt DateTime, quantity UInt64)
|
||||||
Engine = MergeTree
|
Engine = MergeTree
|
||||||
partition by toYYYYMM(dt)
|
partition by toYYYYMM(dt)
|
||||||
order by (brand_id, toStartOfHour(dt));
|
order by (brand_id, toStartOfHour(dt)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
insert into stack
|
insert into stack
|
||||||
select number%99991, number%11, number%1111, toDateTime('2020-01-01 00:00:00')+number/100,
|
select number%99991, number%11, number%1111, toDateTime('2020-01-01 00:00:00')+number/100,
|
||||||
|
|||||||
@ -35,7 +35,7 @@ $CLICKHOUSE_CLIENT --database_atomic_wait_for_drop_and_detach_synchronously=1 --
|
|||||||
# InMemory - [0..5]
|
# InMemory - [0..5]
|
||||||
# Compact - (5..10]
|
# Compact - (5..10]
|
||||||
# Wide - >10
|
# Wide - >10
|
||||||
$CLICKHOUSE_CLIENT --query="CREATE TABLE data_01600 (part_type String, key Int) ENGINE = MergeTree PARTITION BY part_type ORDER BY key SETTINGS min_bytes_for_wide_part=0, min_rows_for_wide_part=10"
|
$CLICKHOUSE_CLIENT --query="CREATE TABLE data_01600 (part_type String, key Int) ENGINE = MergeTree PARTITION BY part_type ORDER BY key SETTINGS min_bytes_for_wide_part=0, min_rows_for_wide_part=10, index_granularity = 8192, index_granularity_bytes = '10Mi'"
|
||||||
|
|
||||||
# InMemory
|
# InMemory
|
||||||
$CLICKHOUSE_CLIENT --query="INSERT INTO data_01600 SELECT 'InMemory', number FROM system.numbers LIMIT 1"
|
$CLICKHOUSE_CLIENT --query="INSERT INTO data_01600 SELECT 'InMemory', number FROM system.numbers LIMIT 1"
|
||||||
|
|||||||
@ -5,7 +5,7 @@ set enable_filesystem_cache=0;
|
|||||||
set enable_filesystem_cache_on_write_operations=0;
|
set enable_filesystem_cache_on_write_operations=0;
|
||||||
drop table if exists t;
|
drop table if exists t;
|
||||||
|
|
||||||
create table t (x UInt64, s String) engine = MergeTree order by x;
|
create table t (x UInt64, s String) engine = MergeTree order by x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO t SELECT
|
INSERT INTO t SELECT
|
||||||
number,
|
number,
|
||||||
if(number < (8129 * 1024), arrayStringConcat(arrayMap(x -> toString(x), range(number % 128)), ' '), '')
|
if(number < (8129 * 1024), arrayStringConcat(arrayMap(x -> toString(x), range(number % 128)), ' '), '')
|
||||||
|
|||||||
@ -5,7 +5,8 @@ CREATE TABLE wide_to_comp (a Int, b Int, c Int)
|
|||||||
settings vertical_merge_algorithm_min_rows_to_activate = 1,
|
settings vertical_merge_algorithm_min_rows_to_activate = 1,
|
||||||
vertical_merge_algorithm_min_columns_to_activate = 1,
|
vertical_merge_algorithm_min_columns_to_activate = 1,
|
||||||
min_bytes_for_wide_part = 0,
|
min_bytes_for_wide_part = 0,
|
||||||
min_rows_for_wide_part = 0;
|
min_rows_for_wide_part = 0,
|
||||||
|
index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
SYSTEM STOP merges wide_to_comp;
|
SYSTEM STOP merges wide_to_comp;
|
||||||
|
|
||||||
|
|||||||
@ -23,12 +23,12 @@ select * from tbl WHERE indexHint(p in (select toInt64(number) - 2 from numbers(
|
|||||||
0 3 0
|
0 3 0
|
||||||
drop table tbl;
|
drop table tbl;
|
||||||
drop table if exists XXXX;
|
drop table if exists XXXX;
|
||||||
create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128;
|
create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128, index_granularity_bytes = '10Mi';
|
||||||
insert into XXXX select number*60, 0 from numbers(100000);
|
insert into XXXX select number*60, 0 from numbers(100000);
|
||||||
SELECT sum(t) FROM XXXX WHERE indexHint(t = 42);
|
SELECT sum(t) FROM XXXX WHERE indexHint(t = 42);
|
||||||
487680
|
487680
|
||||||
drop table if exists XXXX;
|
drop table if exists XXXX;
|
||||||
create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192;
|
create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192, index_granularity_bytes = '10Mi';
|
||||||
insert into XXXX select number*60, 0 from numbers(100000);
|
insert into XXXX select number*60, 0 from numbers(100000);
|
||||||
SELECT count() FROM XXXX WHERE indexHint(t = toDateTime(0)) SETTINGS optimize_use_implicit_projections = 1;
|
SELECT count() FROM XXXX WHERE indexHint(t = toDateTime(0)) SETTINGS optimize_use_implicit_projections = 1;
|
||||||
100000
|
100000
|
||||||
|
|||||||
@ -18,7 +18,7 @@ drop table tbl;
|
|||||||
|
|
||||||
drop table if exists XXXX;
|
drop table if exists XXXX;
|
||||||
|
|
||||||
create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128;
|
create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
insert into XXXX select number*60, 0 from numbers(100000);
|
insert into XXXX select number*60, 0 from numbers(100000);
|
||||||
|
|
||||||
@ -26,7 +26,7 @@ SELECT sum(t) FROM XXXX WHERE indexHint(t = 42);
|
|||||||
|
|
||||||
drop table if exists XXXX;
|
drop table if exists XXXX;
|
||||||
|
|
||||||
create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192;
|
create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
insert into XXXX select number*60, 0 from numbers(100000);
|
insert into XXXX select number*60, 0 from numbers(100000);
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
DROP TABLE IF EXISTS ttt01746;
|
DROP TABLE IF EXISTS ttt01746;
|
||||||
CREATE TABLE ttt01746 (d Date, n UInt64) ENGINE = MergeTree() PARTITION BY toMonday(d) ORDER BY n;
|
CREATE TABLE ttt01746 (d Date, n UInt64) ENGINE = MergeTree() PARTITION BY toMonday(d) ORDER BY n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO ttt01746 SELECT toDate('2021-02-14') + (number % 30) AS d, number AS n FROM numbers(1500000);
|
INSERT INTO ttt01746 SELECT toDate('2021-02-14') + (number % 30) AS d, number AS n FROM numbers(1500000);
|
||||||
set optimize_move_to_prewhere=0;
|
set optimize_move_to_prewhere=0;
|
||||||
SELECT arraySort(x -> x.2, [tuple('a', 10)]) AS X FROM ttt01746 WHERE d >= toDate('2021-03-03') - 2 ORDER BY n LIMIT 1;
|
SELECT arraySort(x -> x.2, [tuple('a', 10)]) AS X FROM ttt01746 WHERE d >= toDate('2021-03-03') - 2 ORDER BY n LIMIT 1;
|
||||||
|
|||||||
@ -9,6 +9,7 @@ CREATE TABLE Test
|
|||||||
ENGINE = MergeTree()
|
ENGINE = MergeTree()
|
||||||
PRIMARY KEY (String1,String2)
|
PRIMARY KEY (String1,String2)
|
||||||
ORDER BY (String1,String2)
|
ORDER BY (String1,String2)
|
||||||
|
SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'
|
||||||
AS
|
AS
|
||||||
SELECT
|
SELECT
|
||||||
'String1_' || toString(number) as String1,
|
'String1_' || toString(number) as String1,
|
||||||
@ -39,15 +40,15 @@ DROP TABLE IF EXISTS Test;
|
|||||||
select x, y from (select [0, 1, 2] as y, 1 as a, 2 as b) array join y as x where a = 1 and b = 2 and (x = 1 or x != 1) and x = 1;
|
select x, y from (select [0, 1, 2] as y, 1 as a, 2 as b) array join y as x where a = 1 and b = 2 and (x = 1 or x != 1) and x = 1;
|
||||||
|
|
||||||
DROP TABLE IF EXISTS t;
|
DROP TABLE IF EXISTS t;
|
||||||
create table t(a UInt8) engine=MergeTree order by a;
|
create table t(a UInt8) engine=MergeTree order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into t select * from numbers(2);
|
insert into t select * from numbers(2);
|
||||||
select a from t t1 join t t2 on t1.a = t2.a where t1.a;
|
select a from t t1 join t t2 on t1.a = t2.a where t1.a;
|
||||||
DROP TABLE IF EXISTS t;
|
DROP TABLE IF EXISTS t;
|
||||||
|
|
||||||
DROP TABLE IF EXISTS t1;
|
DROP TABLE IF EXISTS t1;
|
||||||
DROP TABLE IF EXISTS t2;
|
DROP TABLE IF EXISTS t2;
|
||||||
CREATE TABLE t1 (id Int64, create_time DateTime) ENGINE = MergeTree ORDER BY id;
|
CREATE TABLE t1 (id Int64, create_time DateTime) ENGINE = MergeTree ORDER BY id SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
CREATE TABLE t2 (delete_time DateTime) ENGINE = MergeTree ORDER BY delete_time;
|
CREATE TABLE t2 (delete_time DateTime) ENGINE = MergeTree ORDER BY delete_time SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
insert into t1 values (101, '2023-05-28 00:00:00'), (102, '2023-05-28 00:00:00');
|
insert into t1 values (101, '2023-05-28 00:00:00'), (102, '2023-05-28 00:00:00');
|
||||||
insert into t2 values ('2023-05-31 00:00:00');
|
insert into t2 values ('2023-05-31 00:00:00');
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
-- Tags: no-parallel, long
|
-- Tags: no-parallel, long
|
||||||
DROP TABLE IF EXISTS bloom_filter_null_array;
|
DROP TABLE IF EXISTS bloom_filter_null_array;
|
||||||
CREATE TABLE bloom_filter_null_array (v Array(Int32), INDEX idx v TYPE bloom_filter GRANULARITY 3) ENGINE = MergeTree() ORDER BY v;
|
CREATE TABLE bloom_filter_null_array (v Array(Int32), INDEX idx v TYPE bloom_filter GRANULARITY 3) ENGINE = MergeTree() ORDER BY v SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO bloom_filter_null_array SELECT [number] FROM numbers(10000000);
|
INSERT INTO bloom_filter_null_array SELECT [number] FROM numbers(10000000);
|
||||||
SELECT COUNT() FROM bloom_filter_null_array;
|
SELECT COUNT() FROM bloom_filter_null_array;
|
||||||
SELECT COUNT() FROM bloom_filter_null_array WHERE has(v, 0);
|
SELECT COUNT() FROM bloom_filter_null_array WHERE has(v, 0);
|
||||||
|
|||||||
@ -2,7 +2,7 @@ DROP TABLE IF EXISTS t_sparse;
|
|||||||
|
|
||||||
CREATE TABLE t_sparse (id UInt64, u UInt64, s String)
|
CREATE TABLE t_sparse (id UInt64, u UInt64, s String)
|
||||||
ENGINE = MergeTree ORDER BY id
|
ENGINE = MergeTree ORDER BY id
|
||||||
SETTINGS ratio_of_defaults_for_sparse_serialization = 0.9;
|
SETTINGS ratio_of_defaults_for_sparse_serialization = 0.9, index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO t_sparse SELECT
|
INSERT INTO t_sparse SELECT
|
||||||
number,
|
number,
|
||||||
|
|||||||
@ -7,7 +7,7 @@ SET allow_experimental_object_type = 1;
|
|||||||
CREATE TABLE t_json_sparse (data JSON)
|
CREATE TABLE t_json_sparse (data JSON)
|
||||||
ENGINE = MergeTree ORDER BY tuple()
|
ENGINE = MergeTree ORDER BY tuple()
|
||||||
SETTINGS ratio_of_defaults_for_sparse_serialization = 0.1,
|
SETTINGS ratio_of_defaults_for_sparse_serialization = 0.1,
|
||||||
min_bytes_for_wide_part = 0;
|
min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
SYSTEM STOP MERGES t_json_sparse;
|
SYSTEM STOP MERGES t_json_sparse;
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
DROP TABLE IF EXISTS test;
|
DROP TABLE IF EXISTS test;
|
||||||
CREATE TABLE test(a Int, b Int) Engine=ReplacingMergeTree order by a;
|
CREATE TABLE test(a Int, b Int) Engine=ReplacingMergeTree order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO test select number, number from numbers(5);
|
INSERT INTO test select number, number from numbers(5);
|
||||||
INSERT INTO test select number, number from numbers(5,2);
|
INSERT INTO test select number, number from numbers(5,2);
|
||||||
set max_threads =1;
|
set max_threads =1;
|
||||||
|
|||||||
@ -8,6 +8,6 @@ select count() as c, x in ('a', 'bb') as g from tab group by g order by c;
|
|||||||
drop table if exists tab;
|
drop table if exists tab;
|
||||||
|
|
||||||
-- https://github.com/ClickHouse/ClickHouse/issues/44503
|
-- https://github.com/ClickHouse/ClickHouse/issues/44503
|
||||||
CREATE TABLE test(key Int32) ENGINE = MergeTree ORDER BY (key);
|
CREATE TABLE test(key Int32) ENGINE = MergeTree ORDER BY (key) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into test select intDiv(number,100) from numbers(10000000);
|
insert into test select intDiv(number,100) from numbers(10000000);
|
||||||
SELECT COUNT() FROM test WHERE key <= 100000 AND (NOT (toLowCardinality('') IN (SELECT '')));
|
SELECT COUNT() FROM test WHERE key <= 100000 AND (NOT (toLowCardinality('') IN (SELECT '')));
|
||||||
|
|||||||
@ -5,7 +5,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
|
|||||||
. "$CURDIR"/../shell_config.sh
|
. "$CURDIR"/../shell_config.sh
|
||||||
|
|
||||||
${CLICKHOUSE_CLIENT} --query "DROP TABLE IF EXISTS d"
|
${CLICKHOUSE_CLIENT} --query "DROP TABLE IF EXISTS d"
|
||||||
${CLICKHOUSE_CLIENT} --query "CREATE TABLE d (oid UInt64) ENGINE = MergeTree ORDER BY oid"
|
${CLICKHOUSE_CLIENT} --query "CREATE TABLE d (oid UInt64) ENGINE = MergeTree ORDER BY oid SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
|
||||||
${CLICKHOUSE_CLIENT} --min_insert_block_size_rows 0 --min_insert_block_size_bytes 0 --max_block_size 8192 --query "insert into d select * from numbers(1000000)"
|
${CLICKHOUSE_CLIENT} --min_insert_block_size_rows 0 --min_insert_block_size_bytes 0 --max_block_size 8192 --query "insert into d select * from numbers(1000000)"
|
||||||
|
|
||||||
# In previous ClickHouse versions there was a mistake that makes quantileDeterministic functions not really deterministic (in edge cases).
|
# In previous ClickHouse versions there was a mistake that makes quantileDeterministic functions not really deterministic (in edge cases).
|
||||||
|
|||||||
@ -6,15 +6,18 @@ DROP TABLE IF EXISTS partslost_2;
|
|||||||
|
|
||||||
CREATE TABLE partslost_0 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '0') ORDER BY tuple()
|
CREATE TABLE partslost_0 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '0') ORDER BY tuple()
|
||||||
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
|
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
|
||||||
cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0;
|
cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0,
|
||||||
|
index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
CREATE TABLE partslost_1 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '1') ORDER BY tuple()
|
CREATE TABLE partslost_1 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '1') ORDER BY tuple()
|
||||||
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
|
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
|
||||||
cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0;
|
cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0,
|
||||||
|
index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
CREATE TABLE partslost_2 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '2') ORDER BY tuple()
|
CREATE TABLE partslost_2 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '2') ORDER BY tuple()
|
||||||
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
|
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
|
||||||
cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0;
|
cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0,
|
||||||
|
index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
|
|
||||||
INSERT INTO partslost_0 SELECT toString(number) AS x from system.numbers LIMIT 10000;
|
INSERT INTO partslost_0 SELECT toString(number) AS x from system.numbers LIMIT 10000;
|
||||||
|
|||||||
@ -5,7 +5,7 @@ SET read_in_order_two_level_merge_threshold=100;
|
|||||||
DROP TABLE IF EXISTS t_read_in_order;
|
DROP TABLE IF EXISTS t_read_in_order;
|
||||||
|
|
||||||
CREATE TABLE t_read_in_order(date Date, i UInt64, v UInt64)
|
CREATE TABLE t_read_in_order(date Date, i UInt64, v UInt64)
|
||||||
ENGINE = MergeTree ORDER BY (date, i);
|
ENGINE = MergeTree ORDER BY (date, i) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO t_read_in_order SELECT '2020-10-10', number % 10, number FROM numbers(100000);
|
INSERT INTO t_read_in_order SELECT '2020-10-10', number % 10, number FROM numbers(100000);
|
||||||
INSERT INTO t_read_in_order SELECT '2020-10-11', number % 10, number FROM numbers(100000);
|
INSERT INTO t_read_in_order SELECT '2020-10-11', number % 10, number FROM numbers(100000);
|
||||||
@ -55,7 +55,7 @@ SELECT a, b FROM t_read_in_order WHERE a = 1 ORDER BY b DESC SETTINGS read_in_or
|
|||||||
DROP TABLE t_read_in_order;
|
DROP TABLE t_read_in_order;
|
||||||
|
|
||||||
CREATE TABLE t_read_in_order(dt DateTime, d Decimal64(5), v UInt64)
|
CREATE TABLE t_read_in_order(dt DateTime, d Decimal64(5), v UInt64)
|
||||||
ENGINE = MergeTree ORDER BY (toStartOfDay(dt), d);
|
ENGINE = MergeTree ORDER BY (toStartOfDay(dt), d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO t_read_in_order SELECT toDateTime('2020-10-10 00:00:00') + number, 1 / (number % 100 + 1), number FROM numbers(1000);
|
INSERT INTO t_read_in_order SELECT toDateTime('2020-10-10 00:00:00') + number, 1 / (number % 100 + 1), number FROM numbers(1000);
|
||||||
|
|
||||||
|
|||||||
@ -6,7 +6,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
|
|||||||
|
|
||||||
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS t_index_hypothesis"
|
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS t_index_hypothesis"
|
||||||
|
|
||||||
$CLICKHOUSE_CLIENT -q "CREATE TABLE t_index_hypothesis (a UInt32, b UInt32, INDEX t a != b TYPE hypothesis GRANULARITY 1) ENGINE = MergeTree ORDER BY a"
|
$CLICKHOUSE_CLIENT -q "CREATE TABLE t_index_hypothesis (a UInt32, b UInt32, INDEX t a != b TYPE hypothesis GRANULARITY 1) ENGINE = MergeTree ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
|
||||||
|
|
||||||
$CLICKHOUSE_CLIENT -q "INSERT INTO t_index_hypothesis SELECT number, number + 1 FROM numbers(10000000)"
|
$CLICKHOUSE_CLIENT -q "INSERT INTO t_index_hypothesis SELECT number, number + 1 FROM numbers(10000000)"
|
||||||
|
|
||||||
|
|||||||
@ -17,9 +17,9 @@ prepare_table() {
|
|||||||
table_name="t_hash_table_sizes_stats_$RANDOM$RANDOM"
|
table_name="t_hash_table_sizes_stats_$RANDOM$RANDOM"
|
||||||
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS $table_name;"
|
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS $table_name;"
|
||||||
if [ -z "$1" ]; then
|
if [ -z "$1" ]; then
|
||||||
$CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple();"
|
$CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
|
||||||
else
|
else
|
||||||
$CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1;"
|
$CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
|
||||||
fi
|
fi
|
||||||
$CLICKHOUSE_CLIENT -q "SYSTEM STOP MERGES $table_name;"
|
$CLICKHOUSE_CLIENT -q "SYSTEM STOP MERGES $table_name;"
|
||||||
for ((i = 1; i <= max_threads; i++)); do
|
for ((i = 1; i <= max_threads; i++)); do
|
||||||
|
|||||||
@ -19,9 +19,9 @@ prepare_table() {
|
|||||||
table_name="t_hash_table_sizes_stats_$RANDOM$RANDOM"
|
table_name="t_hash_table_sizes_stats_$RANDOM$RANDOM"
|
||||||
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS $table_name;"
|
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS $table_name;"
|
||||||
if [ -z "$1" ]; then
|
if [ -z "$1" ]; then
|
||||||
$CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple();"
|
$CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
|
||||||
else
|
else
|
||||||
$CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1;"
|
$CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
|
||||||
fi
|
fi
|
||||||
$CLICKHOUSE_CLIENT -q "SYSTEM STOP MERGES $table_name;"
|
$CLICKHOUSE_CLIENT -q "SYSTEM STOP MERGES $table_name;"
|
||||||
for ((i = 1; i <= max_threads; i++)); do
|
for ((i = 1; i <= max_threads; i++)); do
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
-- Tags: no-tsan, no-asan, no-ubsan, no-msan, no-debug
|
-- Tags: no-tsan, no-asan, no-ubsan, no-msan, no-debug
|
||||||
drop table if exists tab_lc;
|
drop table if exists tab_lc;
|
||||||
CREATE TABLE tab_lc (x UInt64, y LowCardinality(String)) engine = MergeTree order by x;
|
CREATE TABLE tab_lc (x UInt64, y LowCardinality(String)) engine = MergeTree order by x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
insert into tab_lc select number, toString(number % 10) from numbers(20000000);
|
insert into tab_lc select number, toString(number % 10) from numbers(20000000);
|
||||||
optimize table tab_lc;
|
optimize table tab_lc;
|
||||||
select count() from tab_lc where y == '0' settings local_filesystem_read_prefetch=1;
|
select count() from tab_lc where y == '0' settings local_filesystem_read_prefetch=1;
|
||||||
|
|||||||
@ -5,8 +5,8 @@ SET max_threads=0;
|
|||||||
DROP TABLE IF EXISTS left;
|
DROP TABLE IF EXISTS left;
|
||||||
DROP TABLE IF EXISTS right;
|
DROP TABLE IF EXISTS right;
|
||||||
|
|
||||||
CREATE TABLE left ( key UInt32, value String ) ENGINE = MergeTree ORDER BY key;
|
CREATE TABLE left ( key UInt32, value String ) ENGINE = MergeTree ORDER BY key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
CREATE TABLE right ( key UInt32, value String ) ENGINE = MergeTree ORDER BY tuple();
|
CREATE TABLE right ( key UInt32, value String ) ENGINE = MergeTree ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
INSERT INTO left SELECT number, toString(number) FROM numbers(25367182);
|
INSERT INTO left SELECT number, toString(number) FROM numbers(25367182);
|
||||||
INSERT INTO right SELECT number, toString(number) FROM numbers(23124707);
|
INSERT INTO right SELECT number, toString(number) FROM numbers(23124707);
|
||||||
|
|||||||
@ -1,8 +1,8 @@
|
|||||||
DROP TABLE IF EXISTS ev;
|
DROP TABLE IF EXISTS ev;
|
||||||
DROP TABLE IF EXISTS idx;
|
DROP TABLE IF EXISTS idx;
|
||||||
|
|
||||||
CREATE TABLE ev (a Int32, b Int32) Engine=MergeTree() ORDER BY a;
|
CREATE TABLE ev (a Int32, b Int32) Engine=MergeTree() ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
CREATE TABLE idx (a Int32) Engine=MergeTree() ORDER BY a;
|
CREATE TABLE idx (a Int32) Engine=MergeTree() ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
INSERT INTO ev SELECT number, number FROM numbers(10000000);
|
INSERT INTO ev SELECT number, number FROM numbers(10000000);
|
||||||
INSERT INTO idx SELECT number * 5 FROM numbers(1000);
|
INSERT INTO idx SELECT number * 5 FROM numbers(1000);
|
||||||
|
|
||||||
|
|||||||
@ -12,7 +12,8 @@ CREATE TABLE t_1
|
|||||||
)
|
)
|
||||||
ENGINE = MergeTree
|
ENGINE = MergeTree
|
||||||
PARTITION BY toYYYYMM(p_time)
|
PARTITION BY toYYYYMM(p_time)
|
||||||
ORDER BY order_0;
|
ORDER BY order_0
|
||||||
|
SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
CREATE TABLE t_random_1
|
CREATE TABLE t_random_1
|
||||||
(
|
(
|
||||||
|
|||||||
@ -2,8 +2,8 @@
|
|||||||
DROP TABLE IF EXISTS t1;
|
DROP TABLE IF EXISTS t1;
|
||||||
DROP TABLE IF EXISTS t2;
|
DROP TABLE IF EXISTS t2;
|
||||||
|
|
||||||
CREATE TABLE t1 (key UInt32, s String) ENGINE = MergeTree ORDER BY key;
|
CREATE TABLE t1 (key UInt32, s String) ENGINE = MergeTree ORDER BY key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
CREATE TABLE t2 (key UInt32, s String) ENGINE = MergeTree ORDER BY key;
|
CREATE TABLE t2 (key UInt32, s String) ENGINE = MergeTree ORDER BY key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
|
||||||
|
|
||||||
{% set ltable_size = 10000000 -%}
|
{% set ltable_size = 10000000 -%}
|
||||||
{% set rtable_size = 1000000 -%}
|
{% set rtable_size = 1000000 -%}
|
||||||
|
|||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user