9.5 KiB
| machine_translated | machine_translated_rev | toc_priority | toc_title |
|---|---|---|---|
| true | 3e185d24c9 |
3 | Descripción |
¿qué es clickhouse?
ClickHouse es un sistema de gestión de bases de datos orientado a columnas (DBMS) para el procesamiento analítico en línea de consultas (OLAP).
En un “normal” DBMS orientado a filas, los datos se almacenan en este orden:
| Fila | Argumento | JavaEnable | Titular | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Relaciones con inversores | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | Contáctenos | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | Mision | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
En otras palabras, todos los valores relacionados con una fila se almacenan físicamente uno junto al otro.
Ejemplos de un DBMS orientado a filas son MySQL, Postgres y MS SQL Server.
En un DBMS orientado a columnas, los datos se almacenan así:
| Fila: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| Argumento: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| Titular: | Relaciones con inversores | Contáctenos | Mision | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
Estos ejemplos solo muestran el orden en el que se organizan los datos. Los valores de diferentes columnas se almacenan por separado y los datos de la misma columna se almacenan juntos.
Ejemplos de un DBMS orientado a columnas: Vertica, Paraccel (Actian Matrix y Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise y Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid y kdb+.
Different orders for storing data are better suited to different scenarios. The data access scenario refers to what queries are made, how often, and in what proportion; how much data is read for each type of query – rows, columns, and bytes; the relationship between reading and updating data; the working size of the data and how locally it is used; whether transactions are used, and how isolated they are; requirements for data replication and logical integrity; requirements for latency and throughput for each type of query, and so on.
Cuanto mayor sea la carga en el sistema, más importante es personalizar el sistema configurado para que coincida con los requisitos del escenario de uso, y más fino será esta personalización. No existe un sistema que sea igualmente adecuado para escenarios significativamente diferentes. Si un sistema es adaptable a un amplio conjunto de escenarios, bajo una carga alta, el sistema manejará todos los escenarios igualmente mal, o funcionará bien para solo uno o algunos de los escenarios posibles.
Propiedades clave del escenario OLAP
- La gran mayoría de las solicitudes son para acceso de lectura.
- Los datos se actualizan en lotes bastante grandes (> 1000 filas), no por filas individuales; o no se actualiza en absoluto.
- Los datos se agregan a la base de datos pero no se modifican.
- Para las lecturas, se extrae un número bastante grande de filas de la base de datos, pero solo un pequeño subconjunto de columnas.
- Las tablas son “wide,” lo que significa que contienen un gran número de columnas.
- Las consultas son relativamente raras (generalmente cientos de consultas por servidor o menos por segundo).
- Para consultas simples, se permiten latencias de alrededor de 50 ms.
- Los valores de columna son bastante pequeños: números y cadenas cortas (por ejemplo, 60 bytes por URL).
- Requiere un alto rendimiento al procesar una sola consulta (hasta miles de millones de filas por segundo por servidor).
- Las transacciones no son necesarias.
- Bajos requisitos para la coherencia de los datos.
- Hay una tabla grande por consulta. Todas las mesas son pequeñas, excepto una.
- Un resultado de consulta es significativamente menor que los datos de origen. En otras palabras, los datos se filtran o se agregan, por lo que el resultado se ajusta a la RAM de un solo servidor.
Es fácil ver que el escenario OLAP es muy diferente de otros escenarios populares (como el acceso OLTP o Key-Value). Por lo tanto, no tiene sentido intentar usar OLTP o una base de datos de valor clave para procesar consultas analíticas si desea obtener un rendimiento decente. Por ejemplo, si intenta usar MongoDB o Redis para análisis, obtendrá un rendimiento muy bajo en comparación con las bases de datos OLAP.
Por qué las bases de datos orientadas a columnas funcionan mejor en el escenario OLAP
Las bases de datos orientadas a columnas son más adecuadas para los escenarios OLAP: son al menos 100 veces más rápidas en el procesamiento de la mayoría de las consultas. Las razones se explican en detalle a continuación, pero el hecho es más fácil de demostrar visualmente:
DBMS orientado a filas
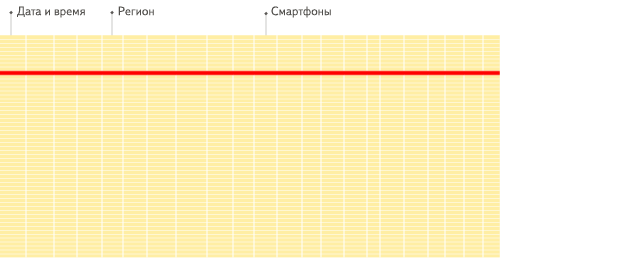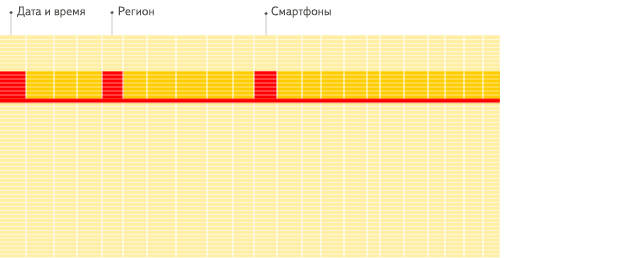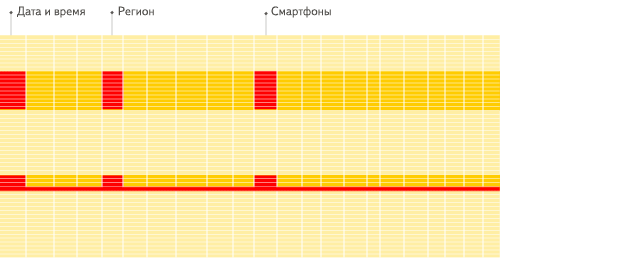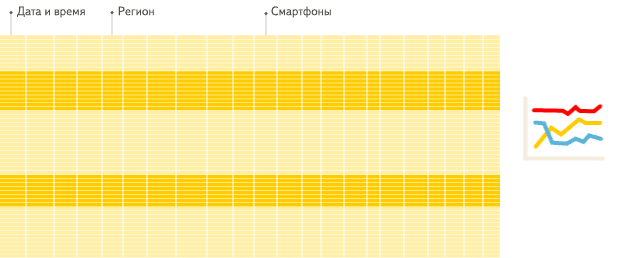
DBMS orientado a columnas
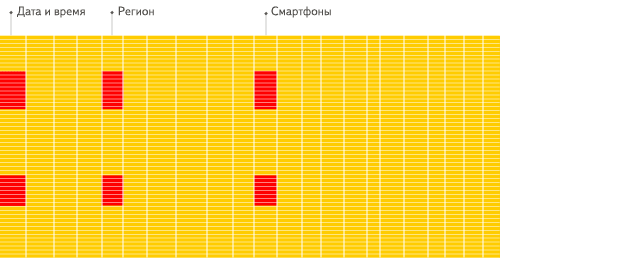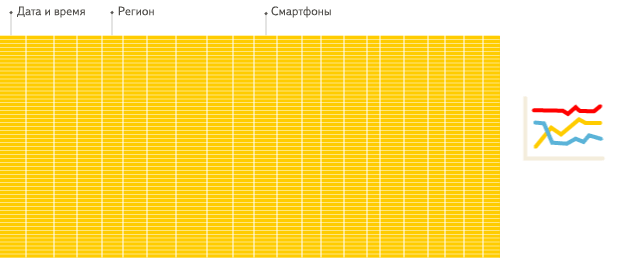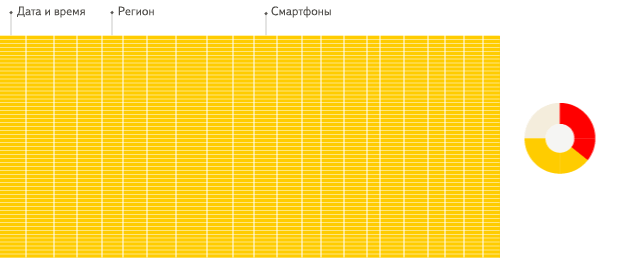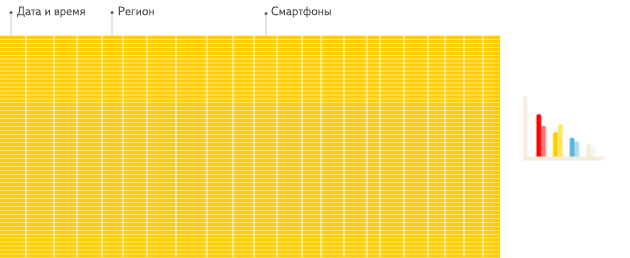
Ver la diferencia?
Entrada/salida
- Para una consulta analítica, solo es necesario leer un pequeño número de columnas de tabla. En una base de datos orientada a columnas, puede leer solo los datos que necesita. Por ejemplo, si necesita 5 columnas de 100, puede esperar una reducción de 20 veces en E/S.
- Dado que los datos se leen en paquetes, es más fácil de comprimir. Los datos en columnas también son más fáciles de comprimir. Esto reduce aún más el volumen de E/S.
- Debido a la reducción de E / S, más datos se ajustan a la memoria caché del sistema.
Por ejemplo, la consulta “count the number of records for each advertising platform” requiere leer uno “advertising platform ID” columna, que ocupa 1 byte sin comprimir. Si la mayor parte del tráfico no proviene de plataformas publicitarias, puede esperar al menos una compresión de 10 veces de esta columna. Cuando se utiliza un algoritmo de compresión rápida, la descompresión de datos es posible a una velocidad de al menos varios gigabytes de datos sin comprimir por segundo. En otras palabras, esta consulta se puede procesar a una velocidad de aproximadamente varios miles de millones de filas por segundo en un único servidor. Esta velocidad se logra realmente en la práctica.
Ejemplo
$ clickhouse-client
ClickHouse client version 0.0.52053.
Connecting to localhost:9000.
Connected to ClickHouse server version 0.0.52053.
SELECT CounterID, count() FROM hits GROUP BY CounterID ORDER BY count() DESC LIMIT 20
┌─CounterID─┬──count()─┐
│ 114208 │ 56057344 │
│ 115080 │ 51619590 │
│ 3228 │ 44658301 │
│ 38230 │ 42045932 │
│ 145263 │ 42042158 │
│ 91244 │ 38297270 │
│ 154139 │ 26647572 │
│ 150748 │ 24112755 │
│ 242232 │ 21302571 │
│ 338158 │ 13507087 │
│ 62180 │ 12229491 │
│ 82264 │ 12187441 │
│ 232261 │ 12148031 │
│ 146272 │ 11438516 │
│ 168777 │ 11403636 │
│ 4120072 │ 11227824 │
│ 10938808 │ 10519739 │
│ 74088 │ 9047015 │
│ 115079 │ 8837972 │
│ 337234 │ 8205961 │
└───────────┴──────────┘
CPU
Dado que la ejecución de una consulta requiere procesar un gran número de filas, ayuda enviar todas las operaciones para vectores completos en lugar de para filas separadas, o implementar el motor de consultas para que casi no haya costo de envío. Si no hace esto, con cualquier subsistema de disco medio decente, el intérprete de consultas inevitablemente detiene la CPU. Tiene sentido almacenar datos en columnas y procesarlos, cuando sea posible, por columnas.
Hay dos formas de hacer esto:
-
Un vector motor. Todas las operaciones se escriben para vectores, en lugar de para valores separados. Esto significa que no necesita llamar a las operaciones con mucha frecuencia, y los costos de envío son insignificantes. El código de operación contiene un ciclo interno optimizado.
-
Generación de código. El código generado para la consulta tiene todas las llamadas indirectas.
Esto no se hace en “normal” bases de datos, porque no tiene sentido cuando se ejecutan consultas simples. Sin embargo, hay excepciones. Por ejemplo, MemSQL utiliza la generación de código para reducir la latencia al procesar consultas SQL. (A modo de comparación, los DBMS analíticos requieren la optimización del rendimiento, no la latencia.)
Tenga en cuenta que para la eficiencia de la CPU, el lenguaje de consulta debe ser declarativo (SQL o MDX), o al menos un vector (J, K). La consulta solo debe contener bucles implícitos, lo que permite la optimización.
{## Artículo Original ##}