8.1 KiB
| machine_translated | machine_translated_rev |
|---|---|
| true | b111334d66 |
什么是ClickHouse?
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
在传统的行式数据库系统中,数据按如下顺序存储:
| 行 | 小心点 | JavaEnable | 标题 | GoodEvent | 活动时间 |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | 投资者关系 | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | 联系我们 | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | 任务 | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
处于同一行中的数据总是被物理的存储在一起。
常见的行式数据库系统有: MySQL、Postgres和MS SQL Server。 {: .灰色 }
在列式数据库系统中,数据按如下的顺序存储:
| 行: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| 小心点: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| 标题: | 投资者关系 | 联系我们 | 任务 | … |
| GoodEvent: | 1 | 1 | 1 | … |
| 活动时间: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
该示例中只展示了数据在列式数据库中数据的排列顺序。 对于存储而言,列式数据库总是将同一列的数据存储在一起,不同列的数据也总是分开存储。
常见的列式数据库有: Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。 {: .灰色 }
不同的存储方式适合不同的场景,这里的查询场景包括: 进行了哪些查询,多久查询一次以及各类查询的比例; 每种查询读取多少数据————行、列和字节;读取数据和写入数据之间的关系;使用的数据集大小以及如何使用本地的数据集;是否使用事务,以及它们是如何进行隔离的;数据的复制机制与数据的完整性要求;每种类型的查询要求的延迟与吞吐量等等。
系统负载越高,根据使用场景进行定制化就越重要,并且定制将会变的越精细。没有一个系统同样适用于明显不同的场景。如果系统适用于广泛的场景,在负载高的情况下,所有的场景可以会被公平但低效处理,或者高效处理一小部分场景。
OLAP场景的关键特征
- 大多数是读请求
- 数据总是以相当大的批(> 1000 rows)进行写入
- 不修改已添加的数据
- 每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- 宽表,即每个表包含着大量的列
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小: 数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每一个查询除了一个大表外都很小
- 查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
很容易可以看出,OLAP场景与其他流行场景(例如,OLTP或K/V)有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询是没有意义的,例如,使用OLAP数据库去处理分析请求通常要优于使用MongoDB或Redis去处理分析请求。
列式数据库更适合OLAP场景的原因
列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),下面详细解释了原因(通过图片更有利于直观理解):
行式
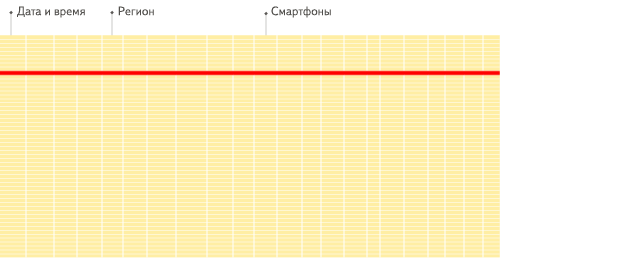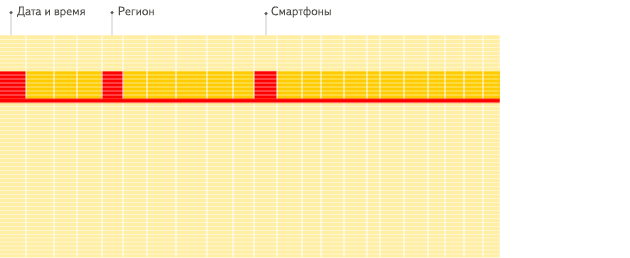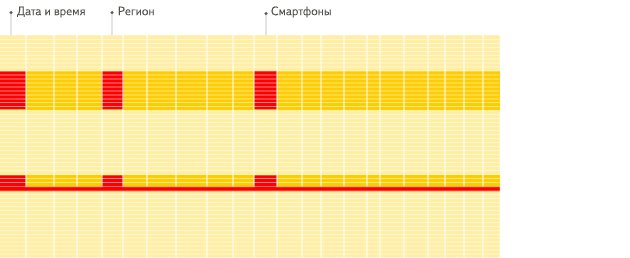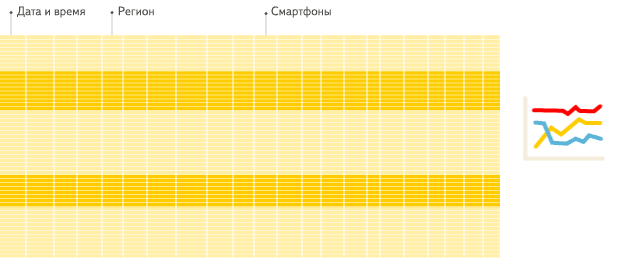
列式
看到差别了么?下面将详细介绍为什么会发生这种情况。
输入/输出
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
例如,查询«统计每个广告平台的记录数量»需要读取«广告平台ID»这一列,它在未压缩的情况下需要1个字节进行存储。如果大部分流量不是来自广告平台,那么这一列至少可以以十倍的压缩率被压缩。当采用快速压缩算法,它的解压速度最少在十亿字节(未压缩数据)每秒。换句话说,这个查询可以在单个服务器上以每秒大约几十亿行的速度进行处理。这实际上是当前实现的速度。
示例
$ clickhouse-client
ClickHouse client version 0.0.52053.
Connecting to localhost:9000.
Connected to ClickHouse server version 0.0.52053.
:) SELECT CounterID, count() FROM hits GROUP BY CounterID ORDER BY count() DESC LIMIT 20
SELECT
CounterID,
count()
FROM hits
GROUP BY CounterID
ORDER BY count() DESC
LIMIT 20
┌─CounterID─┬──count()─┐
│ 114208 │ 56057344 │
│ 115080 │ 51619590 │
│ 3228 │ 44658301 │
│ 38230 │ 42045932 │
│ 145263 │ 42042158 │
│ 91244 │ 38297270 │
│ 154139 │ 26647572 │
│ 150748 │ 24112755 │
│ 242232 │ 21302571 │
│ 338158 │ 13507087 │
│ 62180 │ 12229491 │
│ 82264 │ 12187441 │
│ 232261 │ 12148031 │
│ 146272 │ 11438516 │
│ 168777 │ 11403636 │
│ 4120072 │ 11227824 │
│ 10938808 │ 10519739 │
│ 74088 │ 9047015 │
│ 115079 │ 8837972 │
│ 337234 │ 8205961 │
└───────────┴──────────┘
20 rows in set. Elapsed: 0.153 sec. Processed 1.00 billion rows, 4.00 GB (6.53 billion rows/s., 26.10 GB/s.)
:)
CPU
由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。同时这将有助于实现一个几乎没有调用成本的查询引擎。如果你不这样做,使用任何一个机械硬盘,查询引擎都不可避免的停止CPU进行等待。所以,在数据按列存储并且按列执行是很有意义的。
有两种方法可以做到这一点:
-
向量引擎:所有的操作都是为向量而不是为单个值编写的。这意味着多个操作之间的不再需要频繁的调用,并且调用的成本基本可以忽略不计。操作代码包含一个优化的内部循环。
-
代码生成:生成一段代码,包含查询中的所有操作。
这是不应该在一个通用数据库中实现的,因为这在运行简单查询时是没有意义的。但是也有例外,例如,MemSQL使用代码生成来减少处理SQL查询的延迟(只是为了比较,分析型数据库通常需要优化的是吞吐而不是延迟)。
请注意,为了提高CPU效率,查询语言必须是声明型的(SQL或MDX), 或者至少一个向量(J,K)。 查询应该只包含隐式循环,允许进行优化。