16 KiB
| slug | sidebar_label | sidebar_position | description |
|---|---|---|---|
| /en/getting-started/example-datasets/stackoverflow | Stack Overflow | 1 | Analyzing Stack Overflow data with ClickHouse |
Analyzing Stack Overflow data with ClickHouse
This dataset contains every Posts, Users, Votes, Comments, Badges, PostHistory, and PostLinks that has occurred on Stack Overflow.
Users can either download pre-prepared Parquet versions of the data, containing every post up to April 2024, or download the latest data in XML format and load this. Stack Overflow provide updates to this data periodically - historically every 3 months.
The following diagram shows the schema for the available tables assuming Parquet format.
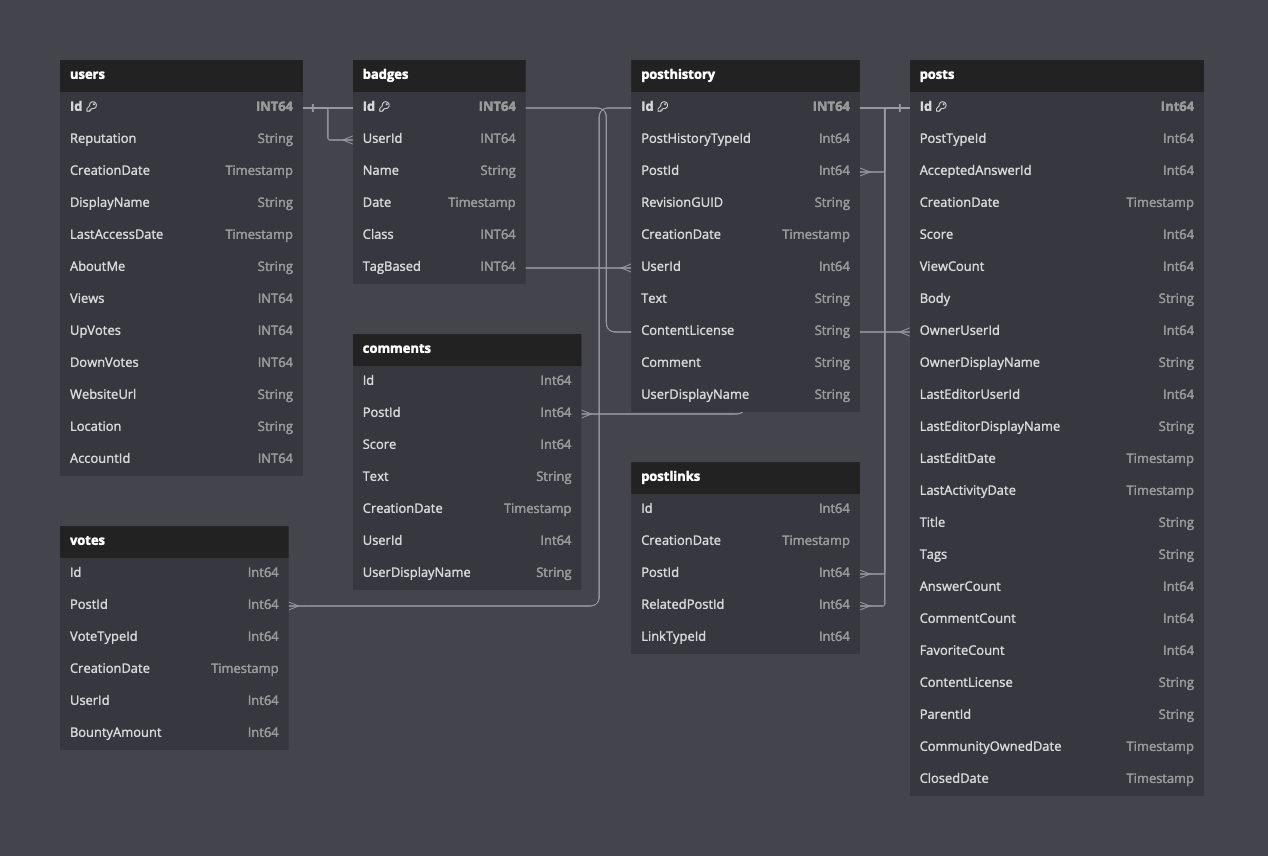
A description of the schema of this data can be found here.
Pre-prepared data
We provide a copy of this data in Parquet format, up to date as of April 2024. While small for ClickHouse with respect to the number of rows (60 million posts), this dataset contains significant volumes of text and large String columns.
CREATE DATABASE stackoverflow
The following timings are for a 96 GiB, 24 vCPU ClickHouse Cloud cluster located in eu-west-2. The dataset is located in eu-west-3.
Posts
CREATE TABLE stackoverflow.posts
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`Score` Int32,
`ViewCount` UInt32 CODEC(Delta(4), ZSTD(1)),
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`LastActivityDate` DateTime64(3, 'UTC'),
`Title` String,
`Tags` String,
`AnswerCount` UInt16 CODEC(Delta(2), ZSTD(1)),
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime64(3, 'UTC'),
`ClosedDate` DateTime64(3, 'UTC')
)
ENGINE = MergeTree
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate)
INSERT INTO stackoverflow.posts SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
0 rows in set. Elapsed: 265.466 sec. Processed 59.82 million rows, 38.07 GB (225.34 thousand rows/s., 143.42 MB/s.)
Posts are also available by year e.g. https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2020.parquet
Votes
CREATE TABLE stackoverflow.votes
(
`Id` UInt32,
`PostId` Int32,
`VoteTypeId` UInt8,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`BountyAmount` UInt8
)
ENGINE = MergeTree
ORDER BY (VoteTypeId, CreationDate, PostId, UserId)
INSERT INTO stackoverflow.votes SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 21.605 sec. Processed 238.98 million rows, 2.13 GB (11.06 million rows/s., 98.46 MB/s.)
Votes are also available by year e.g. https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2020.parquet
Comments
CREATE TABLE stackoverflow.comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY CreationDate
INSERT INTO stackoverflow.comments SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/comments/*.parquet')
0 rows in set. Elapsed: 56.593 sec. Processed 90.38 million rows, 11.14 GB (1.60 million rows/s., 196.78 MB/s.)
Comments are also available by year e.g. https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2020.parquet
Users
CREATE TABLE stackoverflow.users
(
`Id` Int32,
`Reputation` LowCardinality(String),
`CreationDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`DisplayName` String,
`LastAccessDate` DateTime64(3, 'UTC'),
`AboutMe` String,
`Views` UInt32,
`UpVotes` UInt32,
`DownVotes` UInt32,
`WebsiteUrl` String,
`Location` LowCardinality(String),
`AccountId` Int32
)
ENGINE = MergeTree
ORDER BY (Id, CreationDate)
INSERT INTO stackoverflow.users SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/users.parquet')
0 rows in set. Elapsed: 10.988 sec. Processed 22.48 million rows, 1.36 GB (2.05 million rows/s., 124.10 MB/s.)
Badges
CREATE TABLE stackoverflow.badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
INSERT INTO stackoverflow.badges SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 6.635 sec. Processed 51.29 million rows, 797.05 MB (7.73 million rows/s., 120.13 MB/s.)
PostLinks
CREATE TABLE stackoverflow.postlinks
(
`Id` UInt64,
`CreationDate` DateTime64(3, 'UTC'),
`PostId` Int32,
`RelatedPostId` Int32,
`LinkTypeId` Enum8('Linked' = 1, 'Duplicate' = 3)
)
ENGINE = MergeTree
ORDER BY (PostId, RelatedPostId)
INSERT INTO stackoverflow.postlinks SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/postlinks.parquet')
0 rows in set. Elapsed: 1.534 sec. Processed 6.55 million rows, 129.70 MB (4.27 million rows/s., 84.57 MB/s.)
PostHistory
CREATE TABLE stackoverflow.posthistory
(
`Id` UInt64,
`PostHistoryTypeId` UInt8,
`PostId` Int32,
`RevisionGUID` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`Text` String,
`ContentLicense` LowCardinality(String),
`Comment` String,
`UserDisplayName` String
)
ENGINE = MergeTree
ORDER BY (CreationDate, PostId)
INSERT INTO stackoverflow.posthistory SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posthistory/*.parquet')
0 rows in set. Elapsed: 422.795 sec. Processed 160.79 million rows, 67.08 GB (380.30 thousand rows/s., 158.67 MB/s.)
Original dataset
The original dataset is available in compressed (7zip) XML format at https://archive.org/download/stackexchange - files with prefix stackoverflow.com*.
Download
wget https://archive.org/download/stackexchange/stackoverflow.com-Badges.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-Comments.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-PostHistory.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-PostLinks.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-Posts.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-Users.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-Votes.7z
These files are up to 35GB and can take around 30 mins to download depending on internet connection - the download server throttles at around 20MB/sec.
Convert to JSON
At the time of writing, ClickHouse does not have native support for XML as an input format. To load the data into ClickHouse we first convert to NDJSON.
To convert XML to JSON we recommend the xq linux tool, a simple jq wrapper for XML documents.
Install xq and jq:
sudo apt install jq
pip install yq
The following steps apply to any of the above files. We use the stackoverflow.com-Posts.7z file as an example. Modify as required.
Extract the file using p7zip. This will produce a single xml file - in this case Posts.xml.
Files are compressed approximately 4.5x. At 22GB compressed, the posts file requires around 97G uncompressed.
p7zip -d stackoverflow.com-Posts.7z
The following splits the xml file into files, each containing 10000 rows.
mkdir posts
cd posts
# the following splits the input xml file into sub files of 10000 rows
tail +3 ../Posts.xml | head -n -1 | split -l 10000 --filter='{ printf "<rows>\n"; cat - ; printf "</rows>\n"; } > $FILE' -
After running the above users will have a set of files, each with 10000 lines. This ensures the memory overhead of the next command is not excessive (xml to JSON conversion is done in memory).
find . -maxdepth 1 -type f -exec xq -c '.rows.row[]' {} \; | sed -e 's:"@:":g' > posts_v2.json
The above command will produce a single posts.json file.
Load into ClickHouse with the following command. Note the schema is specified for the posts.json file. This will need to be adjusted per data type to align with the target table.
clickhouse local --query "SELECT * FROM file('posts.json', JSONEachRow, 'Id Int32, PostTypeId UInt8, AcceptedAnswerId UInt32, CreationDate DateTime64(3, \'UTC\'), Score Int32, ViewCount UInt32, Body String, OwnerUserId Int32, OwnerDisplayName String, LastEditorUserId Int32, LastEditorDisplayName String, LastEditDate DateTime64(3, \'UTC\'), LastActivityDate DateTime64(3, \'UTC\'), Title String, Tags String, AnswerCount UInt16, CommentCount UInt8, FavoriteCount UInt8, ContentLicense String, ParentId String, CommunityOwnedDate DateTime64(3, \'UTC\'), ClosedDate DateTime64(3, \'UTC\')') FORMAT Native" | clickhouse client --host <host> --secure --password <password> --query "INSERT INTO stackoverflow.posts_v2 FORMAT Native"
Example queries
A few simple questions to you get started.
Most popular tags on Stack Overflow
SELECT
arrayJoin(arrayFilter(t -> (t != ''), splitByChar('|', Tags))) AS Tags,
count() AS c
FROM stackoverflow.posts
GROUP BY Tags
ORDER BY c DESC
LIMIT 10
┌─Tags───────┬───────c─┐
│ javascript │ 2527130 │
│ python │ 2189638 │
│ java │ 1916156 │
│ c# │ 1614236 │
│ php │ 1463901 │
│ android │ 1416442 │
│ html │ 1186567 │
│ jquery │ 1034621 │
│ c++ │ 806202 │
│ css │ 803755 │
└────────────┴─────────┘
10 rows in set. Elapsed: 1.013 sec. Processed 59.82 million rows, 1.21 GB (59.07 million rows/s., 1.19 GB/s.)
Peak memory usage: 224.03 MiB.
User with the most answers (active accounts)
Account requires a UserId.
SELECT
any(OwnerUserId) UserId,
OwnerDisplayName,
count() AS c
FROM stackoverflow.posts WHERE OwnerDisplayName != '' AND PostTypeId='Answer' AND OwnerUserId != 0
GROUP BY OwnerDisplayName
ORDER BY c DESC
LIMIT 5
┌─UserId─┬─OwnerDisplayName─┬────c─┐
│ 22656 │ Jon Skeet │ 2727 │
│ 23354 │ Marc Gravell │ 2150 │
│ 12950 │ tvanfosson │ 1530 │
│ 3043 │ Joel Coehoorn │ 1438 │
│ 10661 │ S.Lott │ 1087 │
└────────┴──────────────────┴──────┘
5 rows in set. Elapsed: 0.154 sec. Processed 35.83 million rows, 193.39 MB (232.33 million rows/s., 1.25 GB/s.)
Peak memory usage: 206.45 MiB.
ClickHouse related posts with the most views
SELECT
Id,
Title,
ViewCount,
AnswerCount
FROM stackoverflow.posts
WHERE Title ILIKE '%ClickHouse%'
ORDER BY ViewCount DESC
LIMIT 10
┌───────Id─┬─Title────────────────────────────────────────────────────────────────────────────┬─ViewCount─┬─AnswerCount─┐
│ 52355143 │ Is it possible to delete old records from clickhouse table? │ 41462 │ 3 │
│ 37954203 │ Clickhouse Data Import │ 38735 │ 3 │
│ 37901642 │ Updating data in Clickhouse │ 36236 │ 6 │
│ 58422110 │ Pandas: How to insert dataframe into Clickhouse │ 29731 │ 4 │
│ 63621318 │ DBeaver - Clickhouse - SQL Error [159] .. Read timed out │ 27350 │ 1 │
│ 47591813 │ How to filter clickhouse table by array column contents? │ 27078 │ 2 │
│ 58728436 │ How to search the string in query with case insensitive on Clickhouse database? │ 26567 │ 3 │
│ 65316905 │ Clickhouse: DB::Exception: Memory limit (for query) exceeded │ 24899 │ 2 │
│ 49944865 │ How to add a column in clickhouse │ 24424 │ 1 │
│ 59712399 │ How to cast date Strings to DateTime format with extended parsing in ClickHouse? │ 22620 │ 1 │
└──────────┴──────────────────────────────────────────────────────────────────────────────────┴───────────┴─────────────┘
10 rows in set. Elapsed: 0.472 sec. Processed 59.82 million rows, 1.91 GB (126.63 million rows/s., 4.03 GB/s.)
Peak memory usage: 240.01 MiB.
Most controversial posts
SELECT
Id,
Title,
UpVotes,
DownVotes,
abs(UpVotes - DownVotes) AS Controversial_ratio
FROM stackoverflow.posts
INNER JOIN
(
SELECT
PostId,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM stackoverflow.votes
GROUP BY PostId
HAVING (UpVotes > 10) AND (DownVotes > 10)
) AS votes ON posts.Id = votes.PostId
WHERE Title != ''
ORDER BY Controversial_ratio ASC
LIMIT 3
┌───────Id─┬─Title─────────────────────────────────────────────┬─UpVotes─┬─DownVotes─┬─Controversial_ratio─┐
│ 583177 │ VB.NET Infinite For Loop │ 12 │ 12 │ 0 │
│ 9756797 │ Read console input as enumerable - one statement? │ 16 │ 16 │ 0 │
│ 13329132 │ What's the point of ARGV in Ruby? │ 22 │ 22 │ 0 │
└──────────┴───────────────────────────────────────────────────┴─────────┴───────────┴─────────────────────┘
3 rows in set. Elapsed: 4.779 sec. Processed 298.80 million rows, 3.16 GB (62.52 million rows/s., 661.05 MB/s.)
Peak memory usage: 6.05 GiB.
Attribution
We thank Stack Overflow for providing this data under the cc-by-sa 4.0 license, acknowledging their efforts and the original source of the data at https://archive.org/details/stackexchange.