* improve hidden page title * adjust docsearch menu colors * enable pymdownx.details * some <details> styling * remove useless example
9.0 KiB
| toc_priority | toc_title |
|---|---|
| 3 | 概観 |
ClickHouseとは?
ClickHouseは、クエリのオンライン分析処理(OLAP)用の列指向のデータベース管理システム(DBMS)です。
「通常の」行指向のDBMSでは、データは次の順序で保存されます。
| Row | WatchID | JavaEnable | Title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | Contact us | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | Mission | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
つまり、行に関連するすべての値は物理的に隣り合わせに格納されます。
行指向のDBMSの例:MySQL, Postgres および MS SQL Server {: .grey }
列指向のDBMSでは、データは次のように保存されます:
| Row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| WatchID: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| Title: | Investor Relations | Contact us | Mission | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
これらの例は、データが配置される順序のみを示しています。 異なる列の値は別々に保存され、同じ列のデータは一緒に保存されます。
列指向DBMSの例:Vertica, Paraccel (Actian Matrix and Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise and Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid および kdb+ {: .grey }
異なったデータ格納の順序は、異なったシナリオにより適します。 データアクセスシナリオとは、クエリの実行内容、頻度、割合を指します。クエリで読み取られるの各種データの量(行、列、バイト)。データの読み取りと更新の関係。作業データのサイズとローカルでの使用方法。トランザクションが使用されるかどうか、およびそれらがどの程度分離されているか。データ複製と論理的整合性の要件。クエリの種類ごとの遅延とスループットの要件など。
システムの負荷が高いほど、使用シナリオの要件に一致するようにセットアップされたシステムをカスタマイズすることがより重要になり、このカスタマイズはより細かくなります。大きく異なるシナリオに等しく適したシステムはありません。システムがさまざまなシナリオに適応可能である場合、高負荷下では、システムはすべてのシナリオを同等に不十分に処理するか、1つまたはいくつかの可能なシナリオでうまく機能します。
OLAPシナリオの主要なプロパティ
- リクエストの大部分は読み取りアクセス用である。
- データは、単一行ではなく、かなり大きなバッチ(> 1000行)で更新されます。または、まったく更新されない。
- データはDBに追加されるが、変更されない。
- 読み取りの場合、非常に多くの行がDBから抽出されるが、一部の列のみ。
- テーブルは「幅が広く」、多数の列が含まれる。
- クエリは比較的まれ(通常、サーバーあたり毎秒数百あるいはそれ以下の数のクエリ)。
- 単純なクエリでは、約50ミリ秒の遅延が容認される。
- 列の値はかなり小さく、数値や短い文字列(たとえば、URLごとに60バイト)。
- 単一のクエリを処理する場合、高いスループットが必要(サーバーあたり毎秒最大数十億行)。
- トランザクションは必要ない。
- データの一貫性の要件が低い。
- クエリごとに1つの大きなテーブルがある。 1つを除くすべてのテーブルは小さい。
- クエリ結果は、ソースデータよりも大幅に小さくなる。つまり、データはフィルター処理または集計されるため、結果は単一サーバーのRAMに収まる。
OLAPシナリオは、他の一般的なシナリオ(OLTPやKey-Valueアクセスなど)とは非常に異なることが容易にわかります。 したがって、まともなパフォーマンスを得るには、OLTPまたはKey-Value DBを使用して分析クエリを処理しようとするのは無意味です。 たとえば、分析にMongoDBまたはRedisを使用しようとすると、OLAPデータベースに比べてパフォーマンスが非常に低下します。
OLAPシナリオで列指向データベースがよりよく機能する理由
列指向データベースは、OLAPシナリオにより適しています。ほとんどのクエリの処理が少なくとも100倍高速です。 理由を以下に詳しく説明しますが、その根拠は視覚的に簡単に説明できます:
行指向DBMS
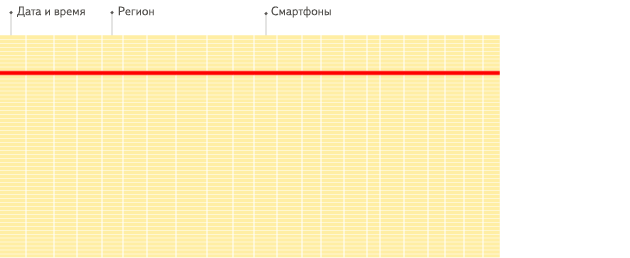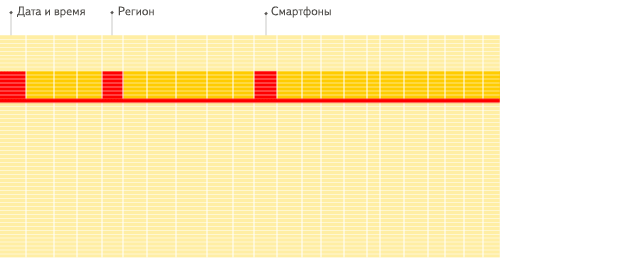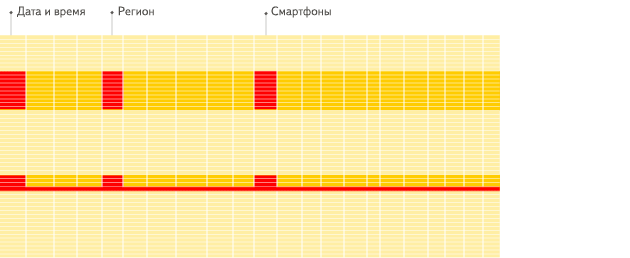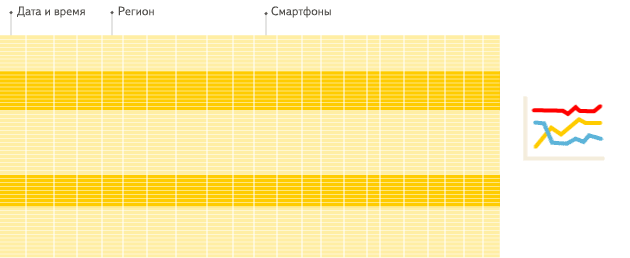
列指向DBMS
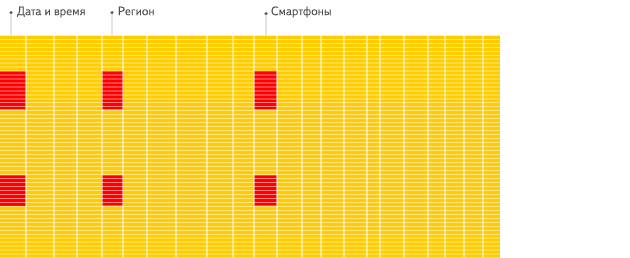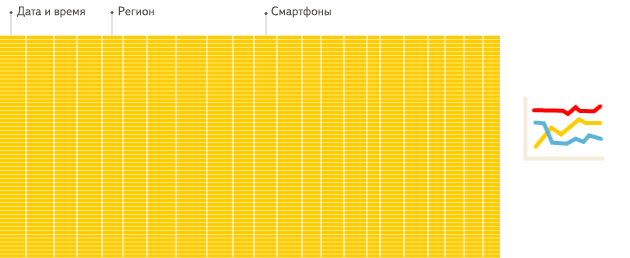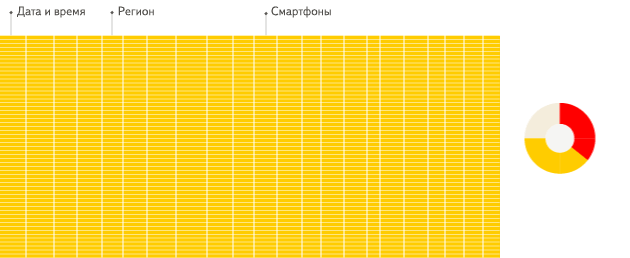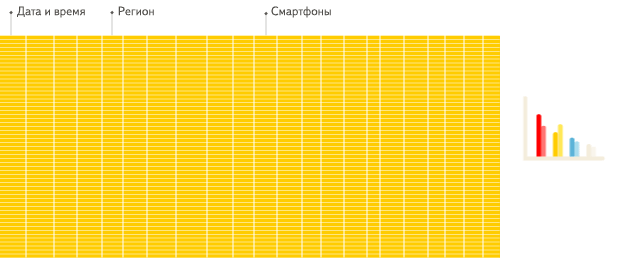
違いがわかりましたか?
Input/output
- 分析クエリでは、少数のテーブル列のみを読み取る必要があります。列指向のデータベースでは、必要なデータのみを読み取ることができます。たとえば、100のうち5つの列が必要な場合、I/Oが20倍削減されることが期待できます。
- データはパケットで読み取られるため、圧縮が容易です。列のデータも圧縮が簡単です。これにより、I/Oボリュームがさらに削減されます。
- I/Oの削減により、より多くのデータがシステムキャッシュに収まります。
たとえば、「各広告プラットフォームのレコード数をカウントする」クエリでは、1つの「広告プラットフォームID」列を読み取る必要がありますが、これは非圧縮では1バイトの領域を要します。トラフィックのほとんどが広告プラットフォームからのものではない場合、この列は少なくとも10倍の圧縮が期待できます。高速な圧縮アルゴリズムを使用すれば、1秒あたり少なくとも非圧縮データに換算して数ギガバイトの速度でデータを展開できます。つまり、このクエリは、単一のサーバーで1秒あたり約数十億行の速度で処理できます。この速度はまさに実際に達成されます。
CPU
クエリを実行するには大量の行を処理する必要があるため、個別の行ではなくベクター全体のすべての操作をディスパッチするか、ディスパッチコストがほとんどないようにクエリエンジンを実装すると効率的です。 適切なディスクサブシステムでこれを行わないと、クエリインタープリターが必然的にCPUを失速させます。 データを列に格納し、可能な場合は列ごとに処理することは理にかなっています。
これを行うには2つの方法があります:
-
ベクトルエンジン。 すべての操作は、個別の値ではなく、ベクトルに対して記述されます。 これは、オペレーションを頻繁に呼び出す必要がなく、ディスパッチコストが無視できることを意味します。 操作コードには、最適化された内部サイクルが含まれています。
-
コード生成。 クエリ用に生成されたコードには、すべての間接的な呼び出しが含まれています。
これは、単純なクエリを実行する場合には意味がないため、「通常の」データベースでは実行されません。 ただし、例外があります。 たとえば、MemSQLはコード生成を使用して、SQLクエリを処理する際の遅延を減らします。 (比較のために、分析DBMSではレイテンシではなくスループットの最適化が必要です。)
CPU効率のために、クエリ言語は宣言型(SQLまたはMDX)、または少なくともベクトル(J、K)でなければなりません。 クエリには、最適化を可能にする暗黙的なループのみを含める必要があります。